
11.08.2024
1 хв
1041

Перевірка даних з витоків є важливим кроком для забезпечення достовірності та надійності інформації. Процес включає аналіз джерела витоку, перевірку метаданих, хешів та інші методи, що дозволяють підтвердити автентичність даних. Ця стаття пропонує покрокову інструкцію для журналістів та дослідників, як ефективно перевіряти витік даних, щоб уникнути розповсюдження фальшивих або маніпулятивних матеріалів. Ви як дослідник можете отримати дані про витік. Але як переконатися, що це справжня справа? Це контрольний список перевірки витоку даних для слідчих.

Один із останніх проектів залучив анонімного інформатора, який передав тисячі документів від компанії, яка, можливо, пов’язана з чутливими секторами російської безпеки та військових операцій. Ці документи, написані російською мовою, містили різні формати, включаючи електронні листи (TXT), текстові документи (Word), PDF-файли, таблиці (xls) та структури папок.
Замість детального аналізу цих матеріалів, ми зосередилися на перевірці їх достовірності. Було використано ряд методологій для впевненості в автентичності отриманих даних.
Сьогодні опублікування історій, заснованих на фейкових або неперевірених витоках, може завдати непоправної шкоди кар’єрі журналістів-розслідувачів.
Якщо ви дотримувалися деяких інших моїх посібників, які я публікую, ви знаєте, що я дуже люблю хороший контрольний список. Це запобігає забуттю будь-чого. Ви завжди можете перестрибувати предмети. І це просто і зрозуміло.
Метадані: датуйте це!
Перевірте вміст: Графіки/Графіки/фотографії
Перевірте будь-які імена та організаційні зв’язки
Перевірте електронні листи в даних — витік даних за допомогою Breachdata
Фізичні адреси та інші компанії
Соціальні мережі, щоб підтвердити витік вмісту
Сенс: чому ми отримуємо документи
«Зміщення відбору»: чого не вистачає в даних?
Остаточний вердикт: чи дані реальні та безпечні?
Для того щоб приблизно визначити, коли документи були створені або оновлені, ми звертаємо увагу на метадані файлів. Однак слід пам’ятати, що метадані можуть бути змінені. Наприклад, ви можете правою кнопкою миші змінити атрибути PDF-файлу. Але маніпулювати тисячами документів вручну дуже складно.
Це підводить нас до ключового питання перевірки витоків даних: наскільки ймовірно, що хтось вручну змінюватиме метадані тисяч документів, залишаючись при цьому непоміченим. Це вимагало б значних ресурсів.
Звичайно, можна припустити, що для цього міг бути використаний штучний інтелект, який випадковим чином змінював би дати створення документів у метаданих. Це теоретично можливо, але також піддається перевірці.
Дата створення документа містить мітку часу. Її можна перевірити, щоб з’ясувати, чи вона відповідає звичайному робочому часу в часовому поясі, звідки походить витік, або ж документ був створений вночі чи у вихідний день. Хоча ці деталі можуть бути сфальсифіковані, організація такого процесу була б дуже складною. Врахуйте обсяг роботи, необхідної для цього, та можливу вигоду для «іншої сторони» від надання неправдивих даних.
Витягніть метадані з кількох зображень і збережіть їх у списку
metadata2go.com — Інтернет-інструмент для перегляду метаданих, у тому числі Exif-даних зображень (метаданих, вбудованих у зображення), таких як налаштування камери, що використовуються під час фотографування, інформація про дату та місце розташування та ескізи. Також можна використовувати для відео, і, як правило, справляється з цим краще, ніж інші інструменти.
Jimpl — засіб перегляду Exif — також можна використовувати для видалення метаданих
VerEXIF — засіб перегляду Exif — також можна використовувати для видалення метаданих
Metadata Interrogator — настільний засіб перегляду метаданих, який працює в автономному режимі та витягує метадані з кількох типів файлів
Якщо є бажання автоматизувати збір метаданих, розширення сценарію Python 3, таке як наведене нижче, може збирати дати створення та зберігати їх для аналізу в хронологічному порядку.
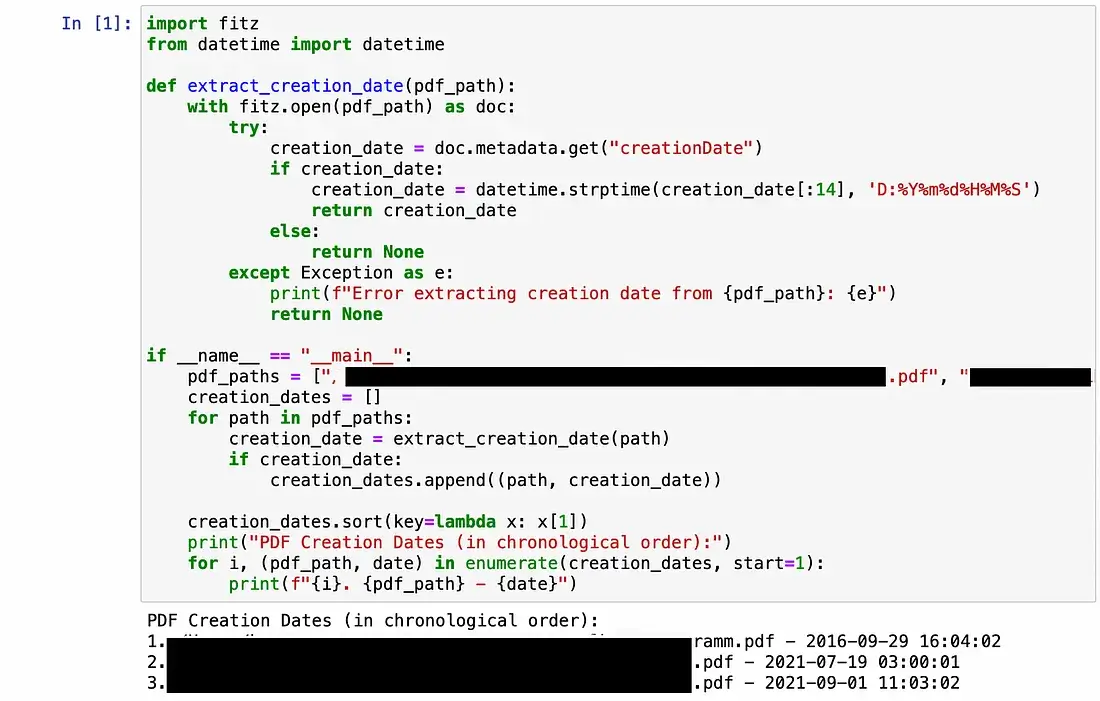
Під час роботи з даними, отриманими з витоків, завжди корисно проводити сканування на віруси, особливо якщо журналісти отримують файли з обіцянкою важливої інформації. Рекомендується використовувати окремий комп’ютер, підключений через Tor, і запускати два різні антивірусні програми. Якщо дані зберігаються на зовнішньому жорсткому диску, його також слід перевірити на наявність вірусів і шкідливого ПЗ.
Якщо виявлено багато шкідливих програм, це слід розглядати як серйозний попереджувальний знак. Для журналістів-розслідувачів це сигнал до перегляду подальших дій. Можливо, варто проаналізувати знайдене шкідливе ПЗ, що може привести до хакерської групи з росії. У будь-якому випадку, слід ретельно обміркувати наступні кроки.
Останнім пунктом, який варто розглянути в цьому контексті, є імена файлів. Змінювати імена файлів вручну для великої кількості документів досить складно. Якщо файли мають систематизовані імена з певною нумерацією, варто задуматися про те, що це може бути штучним, і хтось спеціально витратив час, щоб організувати їх таким чином. Це може бути ще одним сигналом до уважної перевірки.
Назва файлу повинна відображати його зміст. Важливо критично підходити до аналізу назв і перевірити їхню логіку.
Для зручності аналізу можна використовувати сценарії, які автоматично витягують всі назви файлів з отриманих даних і сортують їх за типом. Це допомагає ефективніше аналізувати великий обсяг інформації.
#OSINT — це не #OSINT без зворотного пошуку зображень. У згаданому проекті, присвяченому витоку файлів російських компаній, насправді не було залучено чудових зображень. Замість цього була купа ілюстрацій — технічного характеру, в основному архітектури системи та модулів тощо. Зворотні зображення в поєднанні Google Dorking (пошук зображень + пошуковий термін) для назв модулів могли б вийти процвітаючими.
Хоча реверсивний пошук зображень Яндекса часто має проблеми з інтелектуальними картами або графічним представленням, колірна палітра та структури можуть зробити його достатньо помітним, щоб отримати деякі звернення у відкритому російському Інтернеті.
Іноді подібні ілюстрації присутні на платформі презентацій з відкритим кодом. Однак розумний пошук у Google Dork може запропонувати кращі результати, ніж зворотний пошук зображень (ви можете бути здивовані, скільки російської розвідки просочується на платформу Slideshare ).
Використання зворотного пошуку зображень для перевірки логотипів компаній або партнерських організацій допомогло на ранніх етапах підтвердити достовірність отриманих даних, що зміцнило впевненість у подальшій роботі.
Іноді PDF-файли можуть містити карти з координатами, які варто перевірити. Це допомагає краще зрозуміти контекст інформації.
У випадку з російськими файлами, місцезнаходження, таке як геолокація атомної електростанції у Швейцарії, могло бути макетом. Без контексту складно визначити, чи це має значення, тому перехресна перевірка стає важливою.
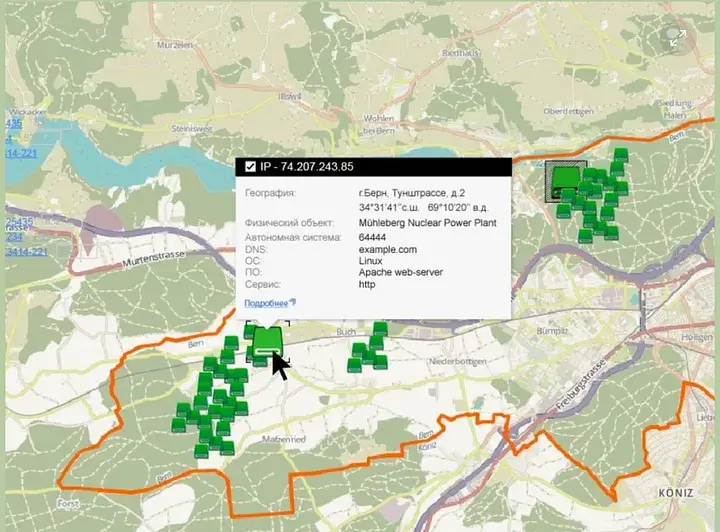
Кілька років тому було проведено перевірку даних, отриманих від урядової установи однієї з європейських країн. Фотографії, що містилися в цих документах, включали супутникові знімки з ілюстраціями потенційних військових цілей для бомбардування.
Виявилося, що документ був лише частиною фіктивного оборонного сценарію. Супутниковий знімок показав злітно-посадкову смугу, яка знаходилася в Азії, далеко від основних військових об’єктів.
Для точного визначення місця розташування злітно-посадкової смуги використовувалася база даних міжнародних аеропортів, що допомогло встановити координати.

Справа, однак, у тому, що з секретного документу військового планування стало зрозуміло, що цей супутниковий знімок був «знятий» із Google Earth або Google Maps у той час, коли документ був виготовлений. Це дало можливість приблизно « хронологізувати » дату створення.
Супутникове зображення можна легко співставити з кадром у Google Earth Pro, використовуючи функцію історичних зображень для порівняння. Хоча доступних знімків небагато, правильний знімок можна визначити за колірною композицією та загальним виглядом.
Для розслідування витоку даних це означає, що супутникове зображення не могло бути створене раніше, ніж воно з’явилося в Google Earth. Якщо хтось стверджує, що документи були створені задовго до появи знімка, цей аргумент не має підстав.
Передісторія цієї справи: напад на країну ЄАВТ, який, очевидно, є неминучим, принаймні це те, що просочив секретний документ захисту. Щоб запобігти нападу, важкоозброєні винищувачі цієї країни піднімаються в повітря і повинні бомбити протиборчі цілі за кордоном: наприклад, міст і аеродром. Ці фіктивні сценарії бойових завдань описані у внутрішніх документах Управління озброєнь країни.
Це завдання, які виробники кількох винищувачів повинні були представити уряду, залученому до процесу торгів/тендерів на оборонні закупівлі. Згідно з документами, мета полягала в тому, щоб випробувати системи гармат і перевірити, наскільки реактивні літаки придатні для виконання завдань.
Найпростішим способом перевірки достовірності витоку є перехресне посилання на імена, згадані в документах.
У витоку про російський кіберстартап згадувалися імена керівників та представників урядових організацій, що викликало підозру, що клієнтами цієї компанії могли бути російські спецслужби та військові. Перша перевірка полягала у копіюванні імен із PDF або Excel файлів і їх подальшому пошуку через Яндекс. Важливим аспектом для перевірки в росії є підтвердження ІНН, який слугує ідентифікатором особи і дозволяє знайти інформацію про неї.
Після підтвердження імен можна використовувати російські платформи з відкритим кодом для перехресної перевірки інформації про компанії та їхню податкову інформацію.
L ist-org.com , C ompanies.rbc.ru , sbis.ru … серед деяких (є більше)
Слідство встановило, що основними клієнтами компанії були військові частини 33949 (в/ч СВР) і 64829 (Центр інформаційної безпеки ФСБ).
Знаючи деякі імена клієнтів, адреси науково-дослідних інститутів або регіони, де зареєстровані люди, ми могли б перевірити, чи мають імена, згадані в витікаючих документах, якусь вагу.
Пам’ятайте, що підроблені імена є варіантом. Але також запитайте себе, скільки зусиль хтось, хто має намір обдурити вас, хоче докласти клопоту, щоб «вигадати» підроблені особи.
На примітку: варто розглянути можливість написання сценарію, який автоматично витягує всі російські назви з документів .PDF, .Xls і .txt. Я підійшов до теми, як зайнятий журналіст, у якого мало часу, і доручив ChatGPT створити спрощений сценарій python3, який виконує цей пошук у кількох PDF-файлах. Таким чином, російські імена, згадані в PDF-документах, можна потім перераховувати та використовувати в скриптах Google/Yandex Dorking.
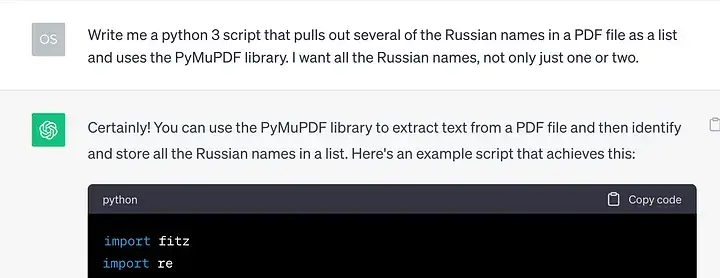
Однак він ігнорує російську чи англійську мови. Це один із способів отримати значну колекцію імен із документів для їх перехресної перевірки.

Інформації про російські військові частини у відкритих джерелах небагато, оскільки росія прагне запобігти її поширенню. Проте деякі ресурси все ж існують, як, наприклад, сайт gostevushka.ru.
Перехресна перевірка провідних фігур та організаційної структури російських військових і силових структур може бути корисною. Наприклад, звіти, такі як звіт RAND про російський генеральний штаб (2023), можуть надати необхідну інформацію.
Важливо перевірити, чи відповідає знайдена у витоку інформація організаційній структурі. Якщо ні, це варто вважати потенційним попереджувальним сигналом.
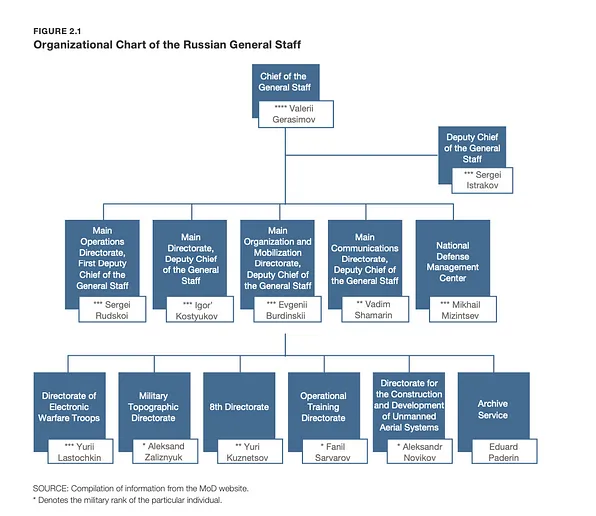
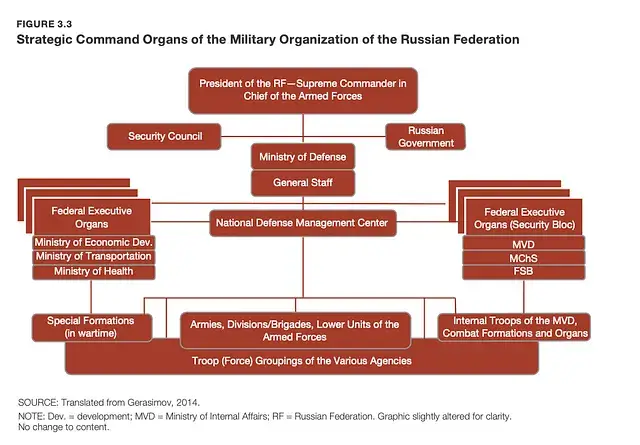
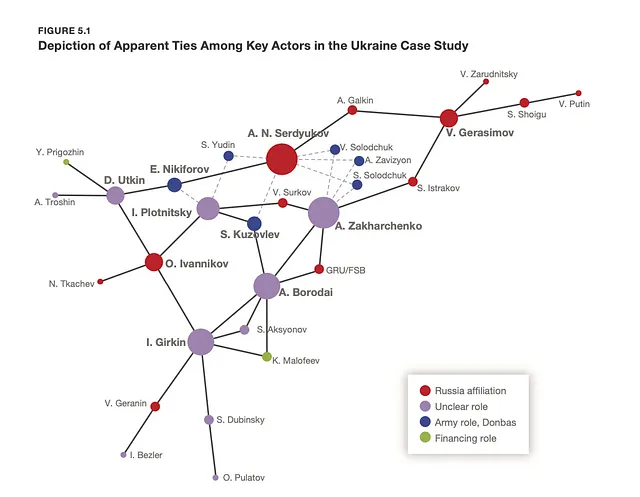
Пов’язування імен, які можуть з’явитися в документах, що витікають, з організаційними структурами російського військового комплексу.
Аналіз підписів підписників секретних документів може бути корисним методом перевірки їхньої особи. Підписи, які можна знайти на паспортах та інших посвідченнях особи, також можуть слугувати важливим джерелом для перехресної перевірки. Якщо є доступ до російських Telegram-ботів, які надають інформацію про такі документи, це може значно підвищити достовірність перевірки.

Подібно до порівняння облич, існують інструменти для порівняння підписів, як-от fileproinfo — альтернативно, деякі системи можуть робити це вже в режимі реального часу (наприклад, signotec «Biometrics API» ).
Проведено аналіз метаданих PDF, проте часто забувають, що документи Word можуть бути цінним джерелом інформації. Для визначення часу роботи над документом і перевірки авторства або внесених змін документи Word можуть відігравати важливу роль в аналізі витоків.
Незважаючи на відсутність експертних знань у сфері OSINT щодо документів Word, корисно звертатися до рекомендацій дослідників, таких як Ніл Сміт. Він надає вказівки щодо прихованих криміналістичних аспектів документів Microsoft, які можуть бути дуже корисними.

Насправді Microsoft настільки болісно усвідомлює, скільки даних зберігається в їхніх документах, що запобіжно попереджає користувачів на своєму веб-сайті.
Таким чином, для оцінки автентичності витоку даних корисно використовувати Word Docs. У випадку одного розслідування один користувач залишив ім’я та коментарі в документах. Це був співробітник. Його вдалося знайти в соцмережах і згодом вистежити. У нього можна було проконсультуватися, чи справжня решта даних.
Інструменти, які варто пам’ятати: FOCA
FOCA — це інструмент, який використовується переважно для пошуку метаданих і прихованої інформації в сканованих документах. Ці документи можуть бути на веб-сторінках, їх можна завантажити та проаналізувати за допомогою FOCA. Він здатний аналізувати широкий спектр документів, найпоширенішими з яких є файли Microsoft Office, Open Office або PDF, хоча він також аналізує, наприклад, файли Adobe InDesign або SVG. (Github)
Як і в попередньому прикладі, можна використовувати код регулярного виразу на Python для вилучення електронних адрес із даних, таких як PDF-файли. Потім ці адреси можна перевірити на предмет «закладених» даних, що може вказувати на порушення безпеки.
Це дозволяє перевірити автентичність учасників і, можливо, отримати більше інформації про їхню діяльність та роль у витоку. Також можна знайти номери телефонів і профілі в соціальних мережах, що стане безцінним ресурсом для журналістів. Наприклад, електронні адреси компанії можуть вказувати на витік загальнодоступних даних.
Ми використовуємо інструмент Hunter компанії Constella Intelligence , зовнішньої служби розвідки загроз.
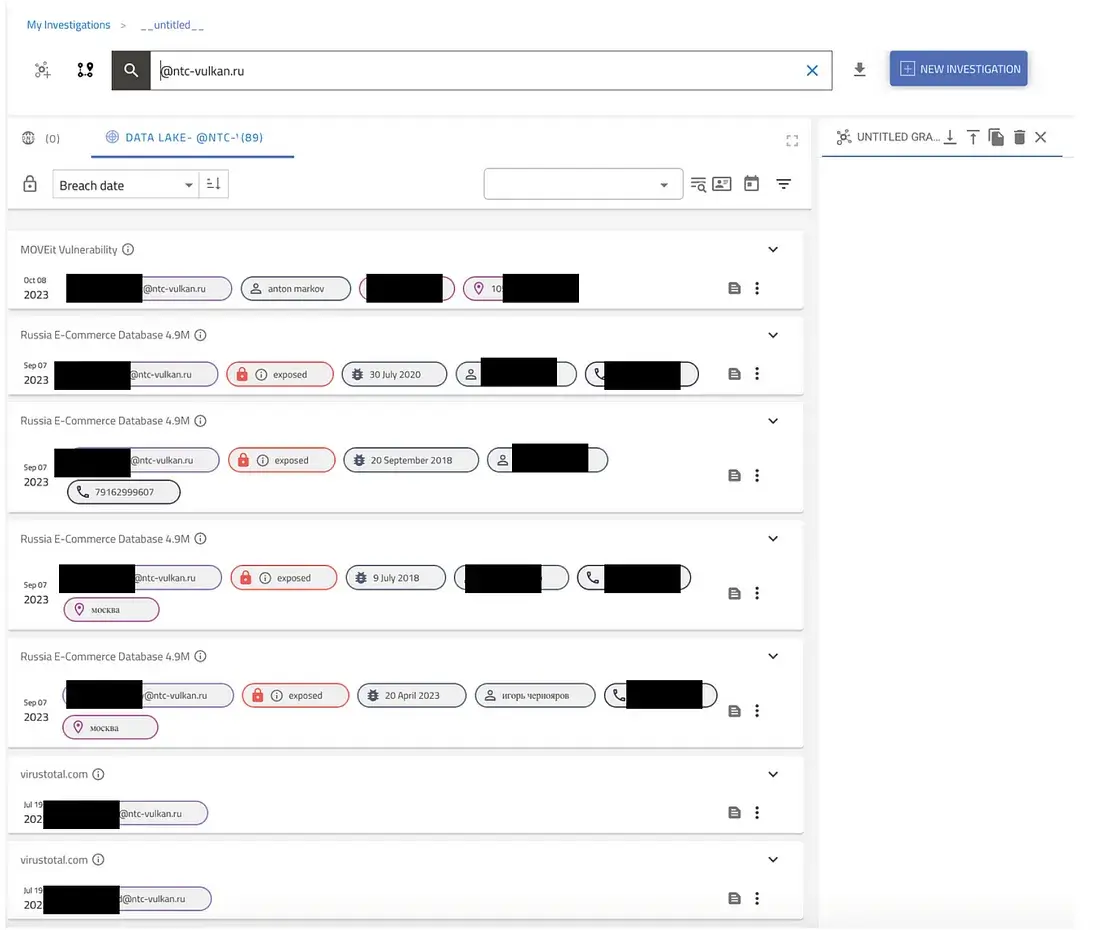
Перевірка компанії NTC Vulkan, яка опинилася під санкціями, виявила присутність кількох співробітників у даних про порушення, разом із розкриттям деяких деталей.
Для первинної перевірки даних можна використовувати інформацію з інших витоків, такі як імена, номери, IP-адреси, імена користувачів у соціальних мережах або домени, що допомагає підтвердити достовірність витоку.
Якщо на Hunter або в базі даних Constella, яка містить 15 мільярдів точок даних про порушення, знайдено співпадіння, це варто розглядати як серйозний попереджувальний знак.
Згадування адрес у документах про витік даних може додати контекст і підвищити впевненість у їхній автентичності. Хоча не завжди можливо перевірити кожне ім’я, військову частину або компанію, адреси вулиць підробити значно складніше.
Адреси можуть бути фальшивими, але вони піддаються перевірці. російські адреси мають специфічну структуру, якої дотримуються в офіційних документах. Використовуючи Яндекс Карти, можна перевірити організації, що знаходяться за певною адресою, і навіть побачити фотографії будівлі.

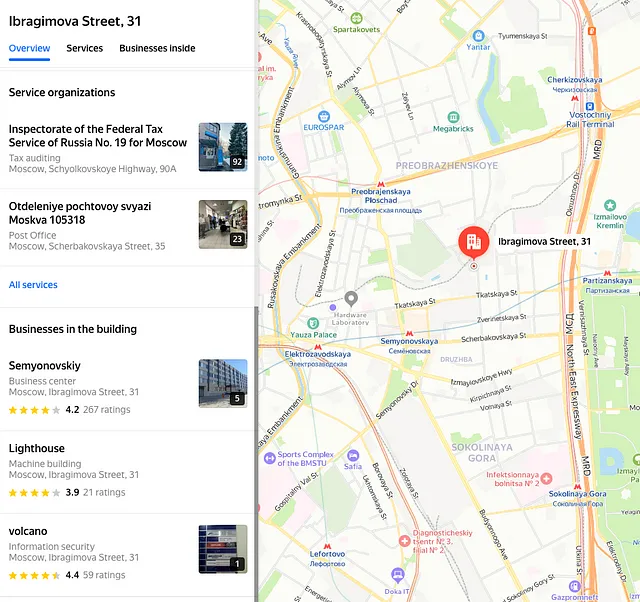
Якщо вдасться витягти всі релевантні адреси з документів, їх можна буде візуалізувати. Це дозволить виявити, чи вони розташовані поблизу один від одного або збігаються з відомими адресами компаній, які підлягають перевірці.
Це може вказувати на партнерську фірму або філію. Наприклад, у випадку з файлами Vulkan було знайдено адресу підприємства, розташованого неподалік від поточної локації компанії.
Це дало змогу зрозуміти, де компанія веде діяльність, підтримує зв’язки та куди їздять її співробітники.
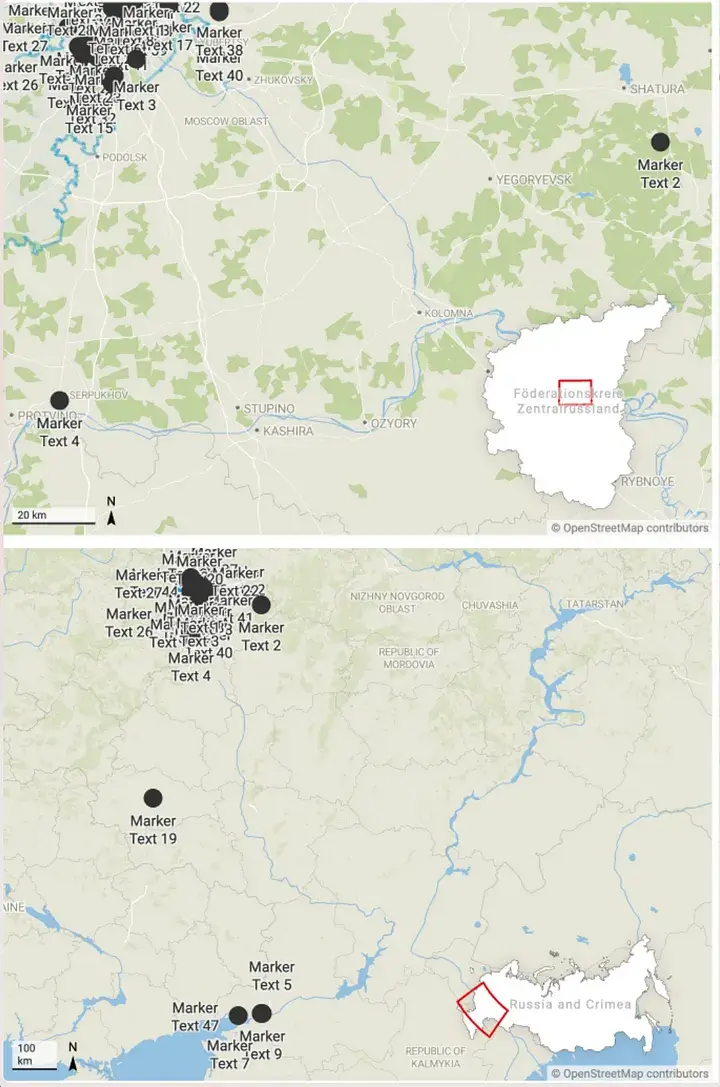
Давайте зробимо крок вперед і спробуємо автоматизувати.
Поштова служба рф розпізнає таку структуру поштової адреси, як пояснюється в цьому посібнику. Ми можемо написати сценарій, який підкоряється цим правилам і відновлює адреси з усіх російських документів.
Щоб проілюструвати цю тезу, ми надали H hunter, Ddosecret s platform, адресу ФСБ ( Луб’янська площа , 2).
Тоді ми відновили один PDF російською мовою. Досить цікаве вийшло на «Звіті про проведення Навального 21 квітня 2021 року».

Сценарій python 3 допоможе витягти всі російські адреси вулиць, площ і регіонів, згадані в PDF-документах.
Видає список. Якщо ми запустимо сценарій, ми отримаємо 7. Луб’янську площу (у) будівлі ФСБ (яка, як ми знаємо, була там), а також Пушкінську площу, Арбатську станцію, Манежну площу, Сибірський федеральний округ, Приволзький федеральний округ, Двірцову площу. і так далі.
Усе це може допомогти перевірити, чи справжній матеріал. (згодом це допомогло хоча б перевірити справжність цього матеріалу).

У випадку з тією російською компанією, яка була піддана аналізу, було виявлено понад десяток зв’язків з іншими організаціями, благодійними фондами та фірмами, які вже знаходяться в червоному списку або під санкціями західних країн. На момент складання карти зв’язків сама компанія ще не перебувала під санкціями, але багато її партнерів вже були під обмеженнями. Це додатково підкреслює важливість перевірки таких зв’язків при розслідуванні.
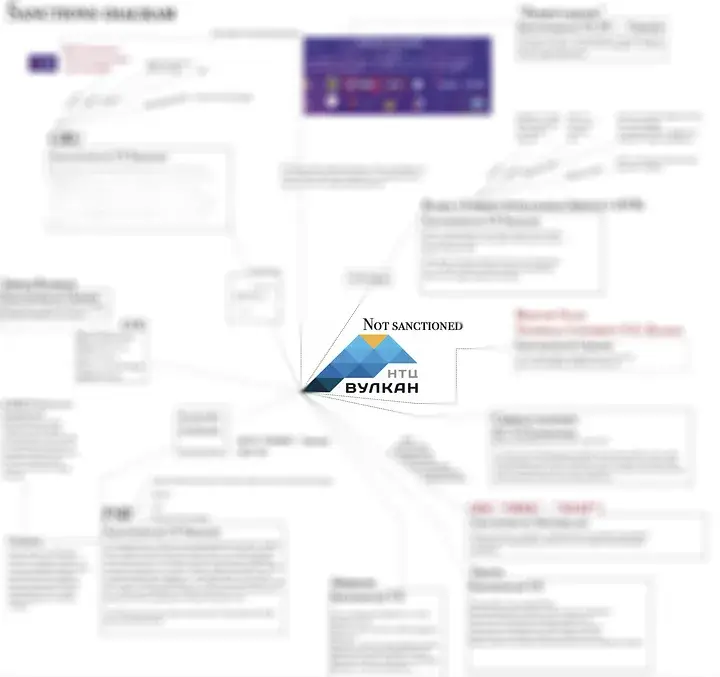
У росії існують різні способи встановлення зв’язків між бізнесом та іншими структурами, включаючи державні установи. Одним з таких способів є судові справи, які часто доступні у відкритих джерелах. Наприклад, запис судової справи 2018 року показав, що засновник підозрілої російської компанії мав ділові відносини з науково-дослідним інститутом, пов’язаним із російськими збройними силами. Ця інформація допомогла підтвердити зв’язки компанії з військовими структурами, що підтвердило достовірність даних, знайдених у витоках.
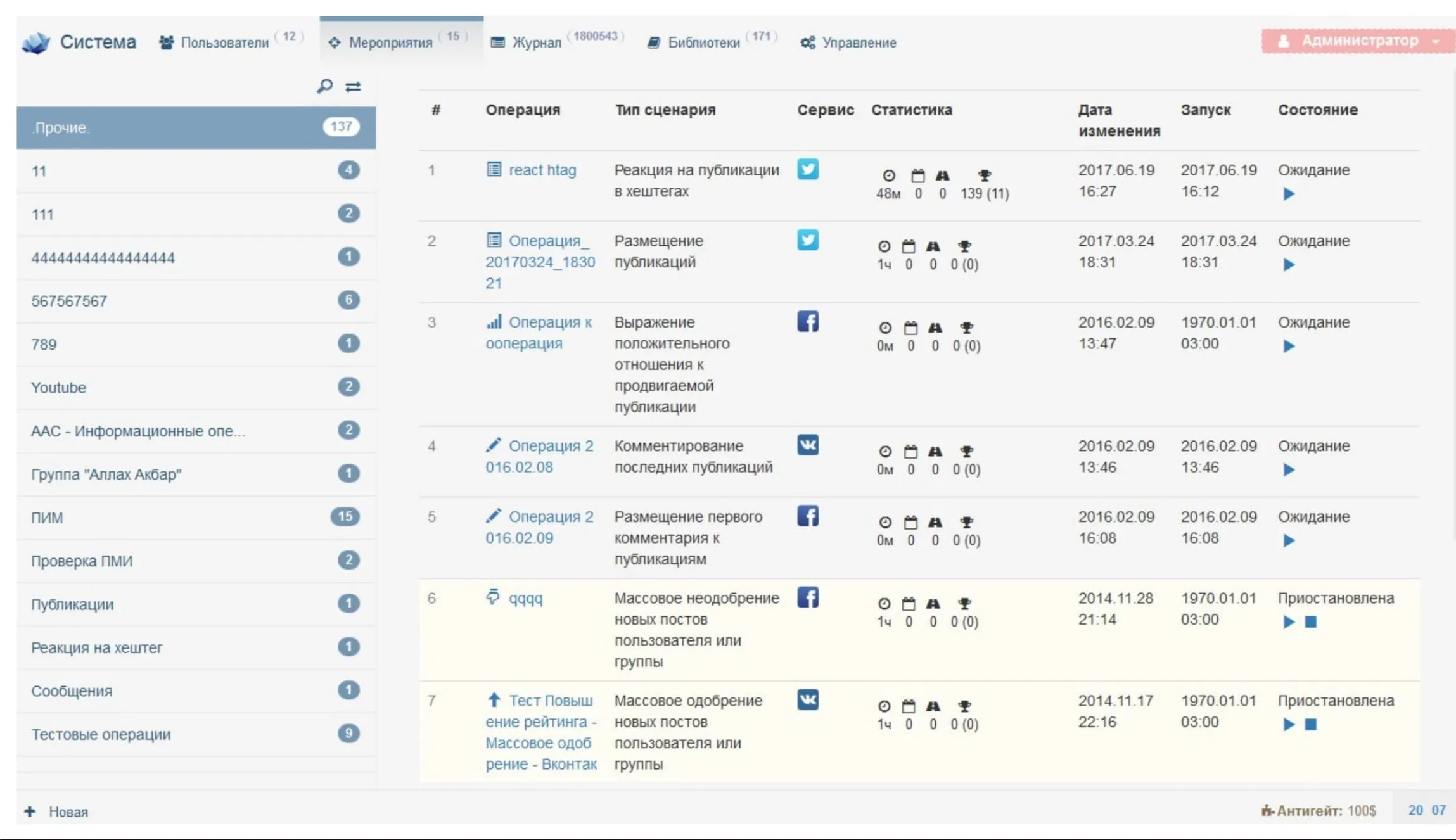
Аналіз даних соціальних медіа залишається важливим інструментом перевірки, навіть у найтаємніших колах. Профілі в соціальних мережах, облікові записи, хештеги та згадки компаній можуть допомогти підтвердити достовірність витоку.
У випадку з російським витоком та технічною документацією, які вказували на можливість використання систем для поширення дезінформації, спочатку було незрозуміло, чи ці системи справді використовуються. Однак команда розслідувачів знайшла в документах хештег, який свідчив про те, що кампанії з дезінформації могли бути частково перевірені.
Хештег Twitter X ( #htagreact, історія тут ) на скріншоті призвів до виявлення сотень облікових записів Twitter із досить дивною — потенційно автоматизованою — поведінкою.
Поставте під сумнів особистість джерела даних: які його мотиви? Як поводиться джерело?
Зазвичай ми шукаємо мотив, який відповідає вимогам. Його можна легко підробити, особливо якщо джерело не хоче розкривати свою особу. Але вони часто пропонують щось, можливо, ім’я користувача або абревіатуру, що може привести до імені користувача в соціальних мережах ( великий посібник щодо імен користувачів тут ).
Для фонового пошуку джерела є способи продовжити. Важливо те, що завдяки пошуку джерело залишається захищеним. Зрештою, важливо, щоб ті, хто працює над витоком, могли довіряти джерелу. І що джерело може довіряти залученим журналістам. Якщо щось порушує цю довіру, додайте це до червоних прапорців
Навіть така тривіальна річ, як структура папок, що містять документи, може допомогти перевірити автентичність витоку.
Розглянемо це: якщо компанія або окрема особа зберігає дані на своєму комп’ютері, вони рідко зберігаються в одній папці і зазвичай організовані хаотично, з каталогами та підкаталогами. Якщо дані зберігаються надто акуратно або з чіткою структурою, це може бути ознакою підробки.
Варто звернути увагу на будь-які незвичайні чи порожні папки. Якщо структура папок виглядає занадто впорядкованою, це може бути червоним прапорцем.
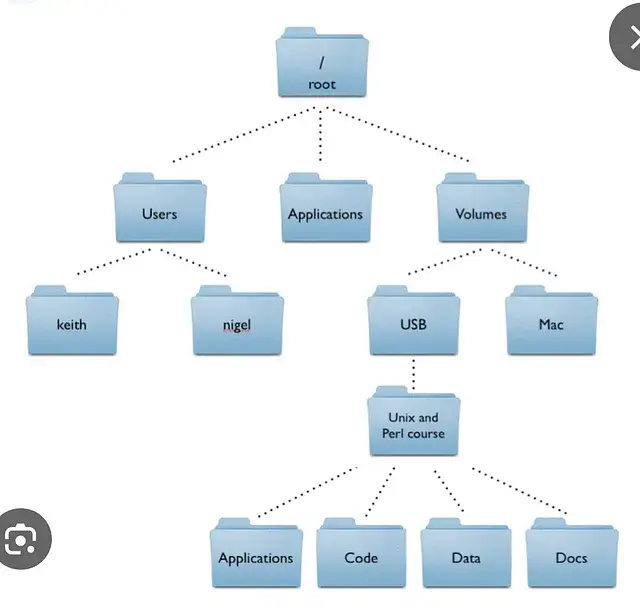
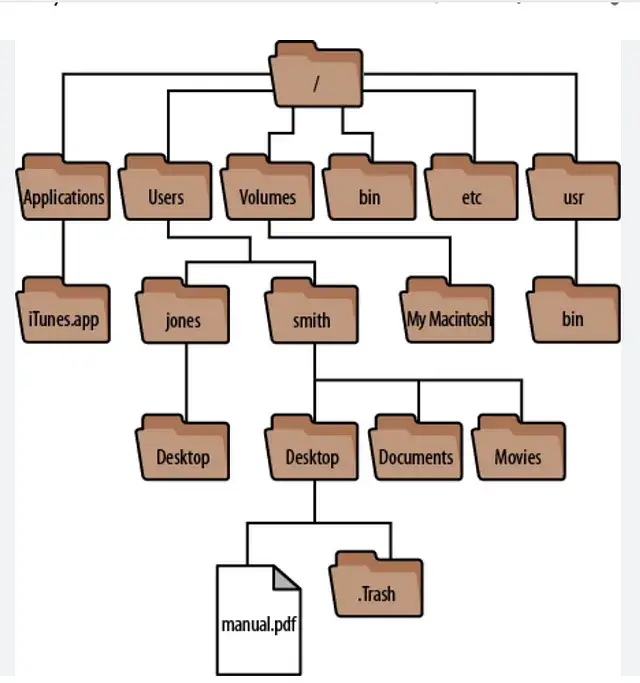
Приклади типової файлової структури папок персонального комп’ютера. У бізнесі це може виглядати інакше, навіть в уряді.
Коли мова йде про відсутні дані, важливо повернутися до аналізу метаданих. Перевірка дат створення файлів допомагає побудувати часову шкалу для виявлення “стрибків” або прогалин у датах. Якщо такі аномалії виявляються, варто розглянути можливість їх навмисного характеру і додати до червоних прапорців.
Щоб полегшити цей процес, можна написати скрипт на Python. Він обробляє файли, витягує метадані, зберігає часові позначки та організовує їх у фрейм даних. Це дозволяє легко помітити будь-які незвичайні патерни або дублікати.
Далі, коли визначено дати створення файлів, корисно провести OSINT-дослідження, щоб зрозуміти, що відбувалося в світі паралельно з цими подіями, що може допомогти краще зрозуміти контекст створення даних.
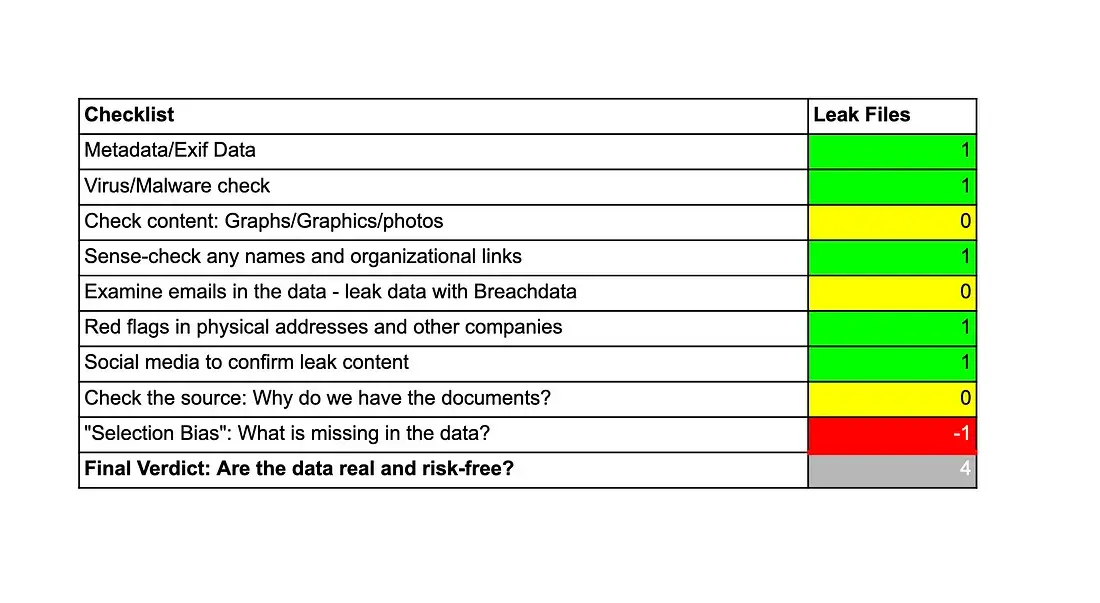
У процесі перевірки достовірності даних витоку ризик завжди присутній. Щоб мінімізувати його, варто дотримуватися структурованого підходу. Використання рейтингової системи може допомогти в оцінці різних аспектів витоку: від -1 (не пройшов перевірку або виявив червоні прапорці) до 0 (нерелевантний) і 1 (успішно пройшов перевірку). Остаточний бал допоможе вирішити, чи слід продовжувати глибше дослідження. Такий підхід дозволяє систематично оцінювати автентичність даних і приймати обґрунтовані рішення.
Хоча це не безпосередньо стосується перевірки автентичності витоків, миттєвий переклад PDF може бути дуже корисним для аналізу даних. Для безпечного перекладу рекомендується виконувати його локально на вашому комп’ютері.
Можна використовувати локальний обліковий запис DeepL або налаштувати систему плагінів. Якщо документи мають конфіденційний характер, для зображень можна використовувати Python-бібліотеки, що працюють локально. Для менш чутливих матеріалів можна скористатися Google Images OCR і перекладом.


