
11.08.2024
1 min
1041

Verification of source data is an important step in ensuring the authenticity and reliability of the information. The process includes analysis of the source of the leak, verification of metadata, hashes and other methods to confirm the authenticity of the data. This article offers a step-by-step guide for journalists and researchers on how to effectively investigate data leaks to avoid the spread of false or manipulative material. As a researcher, you can get the leaked data. But how do you make sure it’s the real deal? This is a data breach investigation checklist for investigators.

One recent project involved an anonymous whistleblower who handed over thousands of documents from a company possibly linked to sensitive sectors of Russian security and military operations. These documents, written in Russian, contained various formats, including emails (TXT), text documents (Word), PDF files, spreadsheets (xls), and folder structures.
Instead of a detailed analysis of these materials, we focused on checking their authenticity. A number of methodologies were used to ensure the authenticity of the data obtained.
Today, publishing stories based on fake or unverified sources can cause irreparable damage to the careers of investigative journalists.
If you’ve followed some of my other guides that I post, you know that I absolutely love a good checklist. This prevents you from forgetting anything. You can always jump over objects. And it’s simple and clear.
Metadata: Date it!
Check the content: Charts/Graphics/Photos
Check any names and organizational connections
Check emails in data – data leak with Breachdata
Physical addresses and other companies
Social networks to confirm the leaked content
Meaning: why we receive documents
“Selection Bias”: What’s Missing in the Data?
Final verdict: Is the data real and secure?
In order to roughly determine when documents were created or updated, we pay attention to file metadata. However, it should be remembered that metadata can be changed. For example, you can right-click to change the attributes of a PDF file. But manipulating thousands of documents manually is very difficult.
This brings us to a key question in data breach investigation: how likely is it that someone would manually change the metadata of thousands of documents without being noticed. This would require significant resources.
Of course, it can be assumed that artificial intelligence could be used for this purpose, which would randomly change the creation dates of documents in the metadata. This is theoretically possible, but also testable.
The document creation date contains a time stamp. It can be checked to see if it corresponds to normal business hours in the time zone where the leak originated, or if the document was created at night or on a weekend. Although these details could be falsified, organizing such a process would be very difficult. Consider the amount of work required to do this and the potential benefit to the “other party” from providing false information.
Витягніть метадані з кількох зображень і збережіть їх у списку
metadata2go.com — An online tool for viewing metadata, including image Exif data (metadata embedded in images), such as camera settings used when taking photos, date and location information, and thumbnails. Can also be used for video, and generally does a better job than other tools.
Jimpl — Exif Viewer – Can also be used to remove metadata
VerEXIF — Exif Viewer – Can also be used to remove metadata
Metadata Interrogator — a desktop metadata viewer that works offline and extracts metadata from multiple file types
If one wishes to automate metadata collection, a Python 3 script extension such as the one below can collect creation dates and store them for analysis in chronological order.
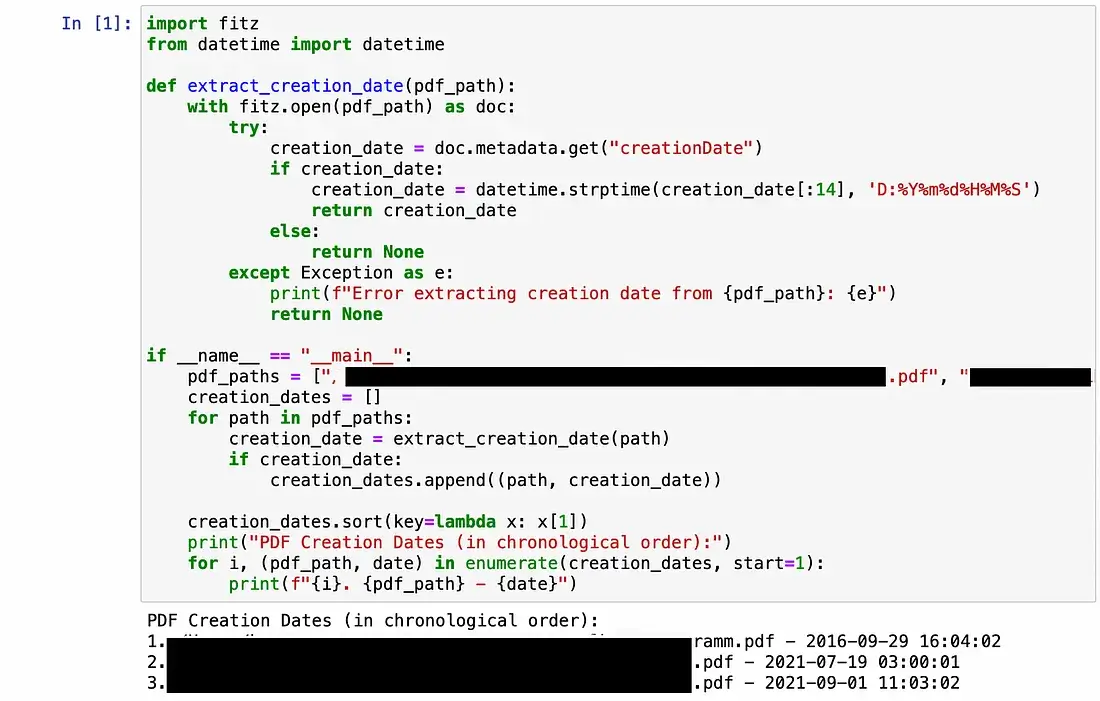
When working with leaked data, it’s always a good idea to run a virus scan, especially if journalists receive files with the promise of important information. It is recommended to use a separate computer connected through Tor and run two different antivirus programs. If data is stored on an external hard drive, it should also be checked for viruses and malware.
If a lot of malware is detected, it should be considered a serious warning sign. For investigative journalists, this is a signal to review further actions. It may be worth analyzing the malware found, which may lead to a hacker group from Russia. In any case, the following steps should be carefully considered.
The last point to consider in this context is file names. Changing file names manually for a large number of documents is quite difficult. If the files have systematic names with a certain numbering, it is worth considering that this may be artificial, and someone took the time to organize them that way. This may be another signal for careful inspection.
The file name should reflect its content. It is important to critically approach the analysis of names and check their logic.
For ease of analysis, you can use scripts that automatically extract all file names from the received data and sort them by type. This helps to analyze a large volume of information more efficiently.
#OSINT isn’t #OSINT without reverse image retrieval. In the mentioned project on the leaking of files of Russian companies, no great images were actually involved. Instead, there were a bunch of illustrations — technical in nature, mostly system architecture and modules, etc. Reverse images combined with Google Dorking (image search + search term) for module names could turn out to be prosperous.
Although Yandex Reverse Image Search often has problems with smart maps or graphical representation, the color palette and structures can make it stand out enough to get some hits on the open Russian Internet.
Sometimes similar illustrations are present on the open source presentation platform. However, a clever Google Dork search can offer better results than a reverse image search (you might be surprised how much Russian intelligence is leaking onto the Slideshare platform).
The use of reverse image search to verify the logos of companies or partner organizations helped in the early stages to confirm the validity of the obtained data, which strengthened confidence in further work.
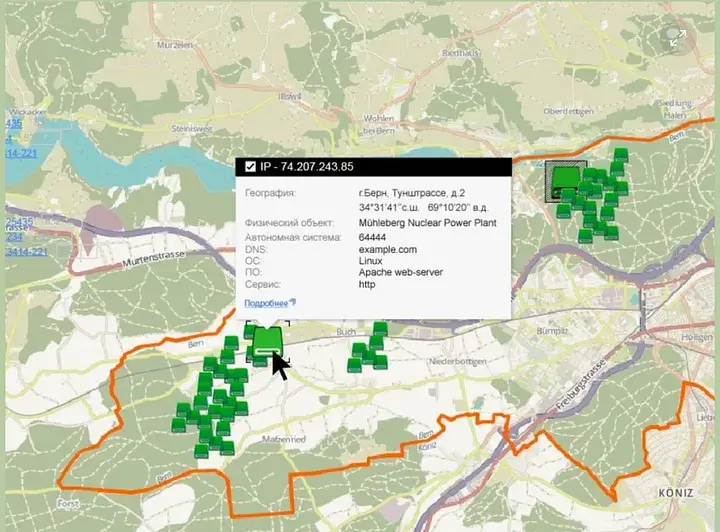
Sometimes PDF files may contain maps with coordinates that are worth checking out. This helps to better understand the context of the information.
In the case of the Russian files, the location, such as the geolocation of a nuclear power plant in Switzerland, could be a mock-up. Without context, it’s hard to tell if it matters, so cross-validation becomes important.
A few years ago, a review of data received from a government agency in one of the European countries was conducted. The photographs contained in these documents included satellite imagery illustrating potential military targets for bombing.
It turned out that the document was only part of a fictitious defense script. A satellite image showed the airstrip, which was located in Asia, far from the main military facilities.
A database of international airports was used to pinpoint the location of the runway, which helped establish the coordinates.

The point, however, is that a classified military planning document made it clear that this satellite image was “taken” from Google Earth or Google Maps at the time the document was produced. This made it possible to roughly “chronologize” the date of creation.
A satellite image can be easily compared to a frame in Google Earth Pro using the historical images feature for comparison. Although there aren’t many pictures available, the correct picture can be determined by the color composition and general appearance.
For the data leak investigation, this means that the satellite image could not have been created before it appeared in Google Earth. If someone claims that the documents were created long before the picture appeared, that argument has no merit.
The background to this case: an attack on an EFTA country that is apparently imminent, at least that’s what a secret defense document leaked. To prevent an attack, heavily armed fighters of this country take to the air and must bomb enemy targets abroad: for example, a bridge and an airfield. These fictitious scenarios of combat missions are described in internal documents of the country’s Armaments Department.
These are the tasks that the manufacturers of several fighter jets had to present to the government involved in the bidding/tendering process for defense procurement. According to the documents, the purpose was to test the gun systems and see how fit the jets were for the missions.
The easiest way to verify the authenticity of the leak is to cross-reference the names mentioned in the documents.
In the leak about the Russian cyber startup, the names of managers and representatives of government organizations were mentioned, which raised the suspicion that the clients of this company could be the Russian special services and the military. The first check consisted of copying names from PDF or Excel files and their subsequent search through Yandex. An important aspect for checking in Russia is confirmation of the TIN, which serves as an identifier of a person and allows you to find information about him.
Once names are confirmed, Russian open source platforms can be used to cross-check information about companies and their tax information.
L ist-org.com , C ompanies.rbc.ru , sbis.ru … among some (there are more)
Слідство встановило, що основними клієнтами компанії були військові частини 33949 (в/ч СВР) і 64829 (Центр інформаційної безпеки ФСБ).
Knowing some customer names, addresses of research institutes or regions where people are registered, we could check if the names mentioned in the leaked documents have any weight.
Remember that fake names are an option. But also ask yourself how much effort someone intent on scamming you is willing to go to the trouble of “inventing” fake identities.
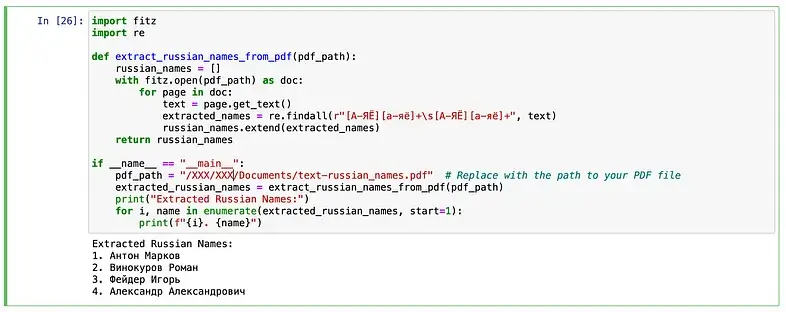
On a side note: it is worth considering writing a script that automatically extracts all Russian names from .PDF, .Xls and .txt documents. I approached the topic as a busy journalist short on time and had ChatGPT create a simple python3 script that performs this search on multiple PDFs. Thus, the Russian names mentioned in the PDF documents can then be listed and used in Google/Yandex Dorking scripts.
However, it ignores Russian or English. This is one way to get a large collection of names from documents to cross-check.

There is little information about Russian military units in open sources, as Russia seeks to prevent its spread. However, some resources still exist, such as the site gostevushka.ru.
Cross-checking the leading figures and organizational structure of the Russian military and law enforcement agencies can be useful. For example, reports such as the RAND Report on the Russian General Staff (2023) can provide the necessary information.
It is important to check whether the information found in the leak corresponds to the organizational structure. If not, this should be considered a potential red flag.
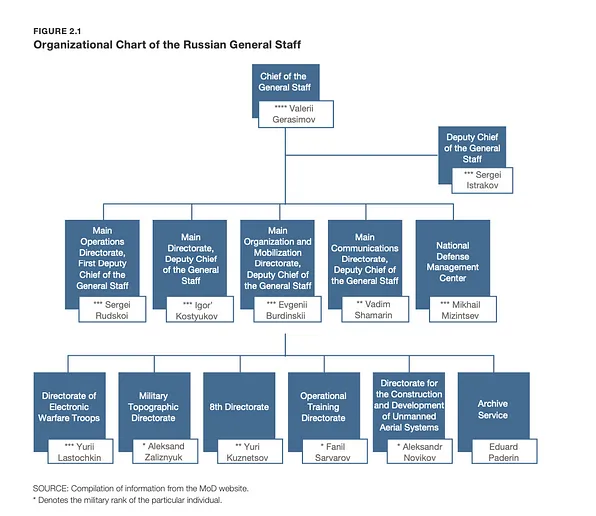
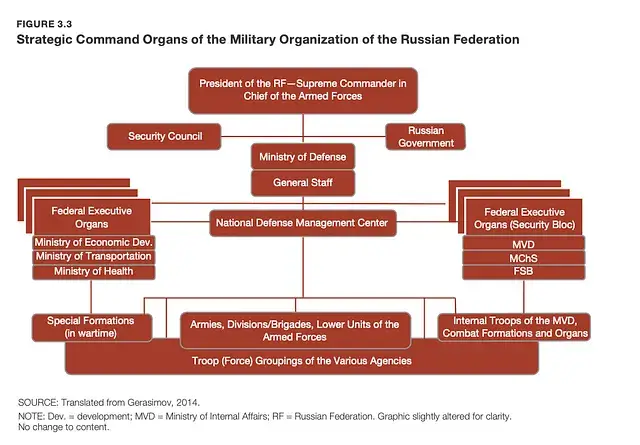
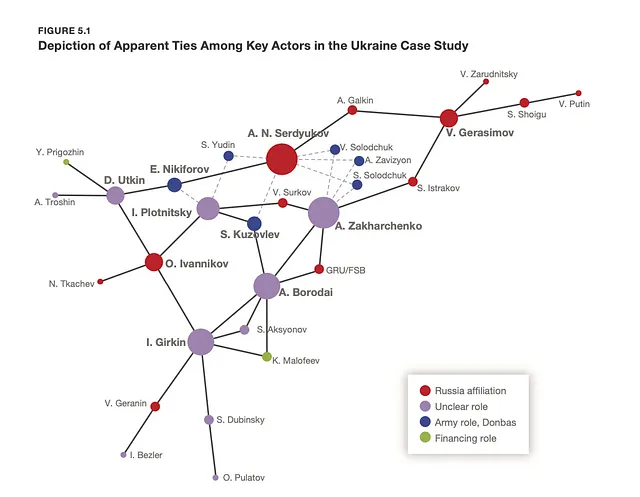
Linking the names that may appear in the leaked documents to the organizational structures of the Russian military complex.
Analyzing the signatures of the signatories of classified documents can be a useful method of verifying their identity. Signatures found on passports and other forms of identification can also be an important source for cross-checking. If there is access to Russian Telegram bots that provide information about such documents, this can significantly increase the reliability of the verification.

Similar to face comparison, there are signature comparison tools like fileproinfo – alternatively, some systems can already do this in real-time (eg signotec “Biometrics API”).
PDF metadata has been analyzed, but it is often forgotten that Word documents can be a valuable source of information. To determine the time of work on a document and verify authorship or changes made, Word documents can play an important role in the analysis of leaks.
Despite not having OSINT expertise on Word documents, it’s useful to refer to the recommendations of researchers such as Neil Smith. It provides guidance on hidden forensic aspects of Microsoft documents that can be very useful.

In fact, Microsoft is so painfully aware of how much data is stored in their documents that they preemptively warn users on their website.
Thus, it is useful to use Word Docs to assess the authenticity of a data leak. In the case of one investigation, one user left a name and comments on the documents. It was an employee. It was possible to find him in social networks and later track him down. He could be consulted to see if the rest of the data was true.
Tools to remember: FOCA
FOCA is a tool used primarily to find metadata and hidden information in scanned documents. These documents can be on web pages and can be downloaded and analyzed by FOCA. It is capable of analyzing a wide range of documents, the most common of which are Microsoft Office, Open Office or PDF files, although it also analyzes, for example, Adobe InDesign or SVG files. (Github)
As in the previous example, you can use regular expression code in Python to extract email addresses from data such as PDF files. These addresses can then be checked for “spoiled” data, which could indicate a security breach.
This allows you to verify the authenticity of the participants and possibly gain more information about their activities and role in the leak. You can also find phone numbers and social media profiles, which will be an invaluable resource for journalists. For example, company email addresses may indicate a leak of publicly available data.
We use the Hunter tool from Constella Intelligence, an external threat intelligence service.
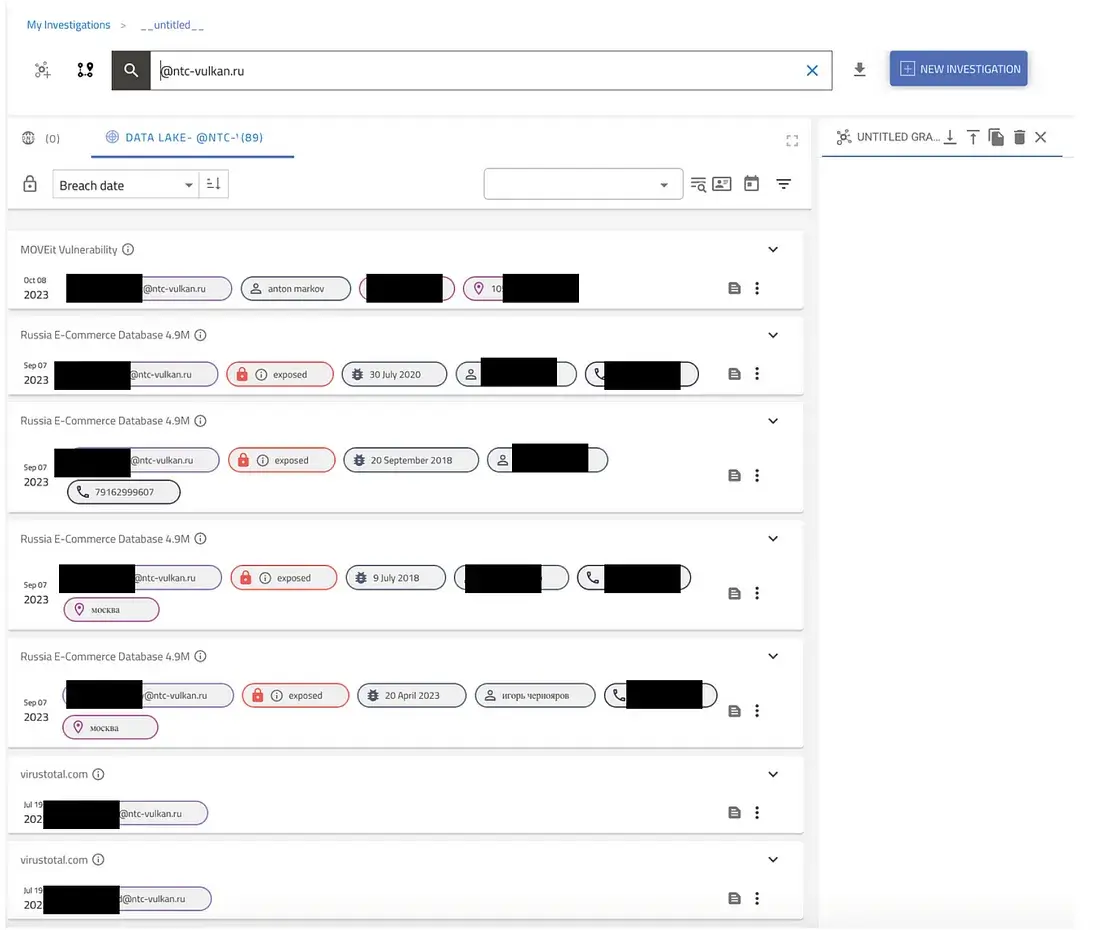
NTC’s review of sanctioned company Vulkan identified several employees in the data breach, along with revealing some of the details.
Information from other sources, such as names, numbers, IP addresses, social media usernames or domains, can be used for initial data verification to help confirm the authenticity of the leak.
If a match is found on Hunter or Constella’s database of 15 billion breach data points, it should be taken as a serious warning sign.
Mentioning addresses in leaked documents can add context and increase confidence in their authenticity. While it is not always possible to verify every name, military unit or company, street addresses are much more difficult to forge.
The addresses may be fake, but they are verifiable. Russian addresses have a specific structure that is followed in official documents. Using Yandex Maps, you can check the organizations located at a certain address, and even see photos of the building.

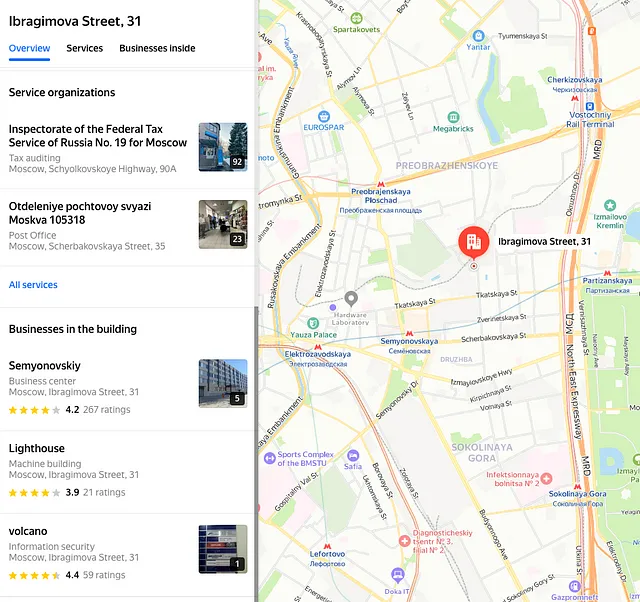
If all relevant addresses can be extracted from the documents, they can be visualized. This will reveal whether they are located close to each other or match known addresses of companies to be verified.
This may indicate a partner firm or branch. For example, in the case of the Vulkan files, a business address was found that was located not far from the company’s current location.
This made it possible to understand where the company conducts its activities, maintains connections and where its employees go.
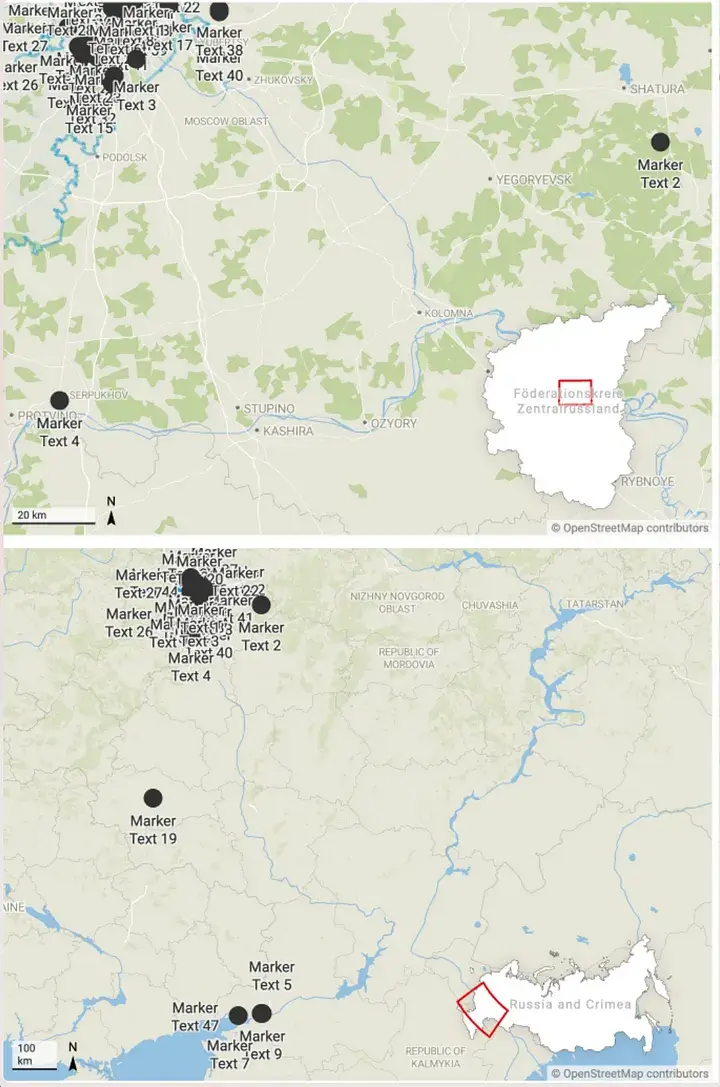
Let’s take it a step further and try to automate.
The postal service of the Russian Federation recognizes the following structure of the postal address, as explained in this manual. We can write a script that obeys these rules and recovers addresses from all Russian documents.
To illustrate this thesis, we have provided H hunter, Ddosecret’s platform, the address of the FSB (Lubyanskaya Square, 2).
Then we restored one PDF in Russian. A rather interesting thing appeared on the “Report on the conduct of Navalny on April 21, 2021”.

The python 3 script will help to extract all Russian addresses of streets, squares and regions mentioned in PDF documents.
Gives a list. If we run the script, we get 7. Lubyansk Square (in) the FSB building (which we know was there), as well as Pushkin Square, Arbat Station, Manezhnaya Square, Siberian Federal District, Volga Federal District, Dvirtsova Square . and so on.
All of these can help verify that the material is genuine. (later it helped to at least verify the authenticity of this material).

In the case of the Russian company that was subjected to analysis, more than a dozen connections were found with other organizations, charitable foundations and firms that are already on the red list or under sanctions of Western countries. At the time of drawing up the map of connections, the company itself was not yet under sanctions, but many of its partners were already under restrictions. This further emphasizes the importance of testing such relationships in an investigation.
In Russia, there are various ways of establishing connections between business and other structures, including state institutions. One such way is through court cases, which are often available in open sources. For example, a 2018 court case record revealed that the founder of a suspicious Russian company had business dealings with a research institute linked to the Russian military. This information helped confirm the company’s ties to military structures, which confirmed the authenticity of the data found in the leaks.
Social media data analysis remains an important verification tool, even in the most secretive circles. Social media profiles, accounts, hashtags, and company mentions can help confirm the authenticity of a leak.
In the case of the Russian leak and technical documentation that indicated the possibility of the systems being used to spread disinformation, it was initially unclear whether the systems were actually being used. However, the investigative team found a hashtag in the documents that suggested the disinformation campaigns may have been partially verified.
The Twitter hashtag X (#htagreact, story here ) in the screenshot led to the discovery of hundreds of Twitter accounts with some pretty weird — potentially automated — behavior.
Question the identity of the data source: What are their motives? How does the source behave?
We usually look for a motif that fits the bill. It can be easily faked, especially if the source does not want to reveal their identity. But they often suggest something, maybe a username or an acronym that can lead to a social media username (a great guide to usernames here).
For background source searches, there are ways to proceed. The important thing is that the source remains protected thanks to the search. Ultimately, it’s important that those working on the leak can trust the source. And that the source can trust the journalists involved. If something violates that trust, add it to the red flags
Even something as trivial as the folder structure containing documents can help verify the authenticity of a leak.
Consider this: if a company or individual stores data on their computer, it is rarely stored in a single folder and is usually organized in a haphazard manner, with directories and subdirectories. If the data is stored too neatly or with a clear structure, this may be a sign of forgery.
Any unusual or empty folders should be noted. If the folder structure looks too organized, that could be a red flag.
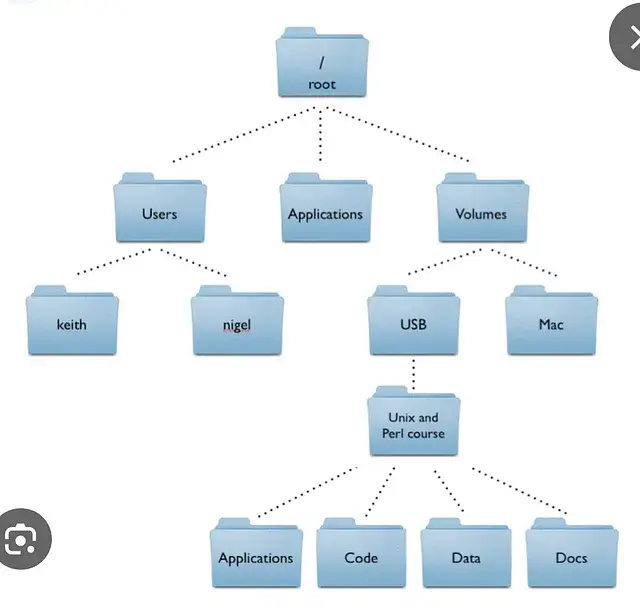
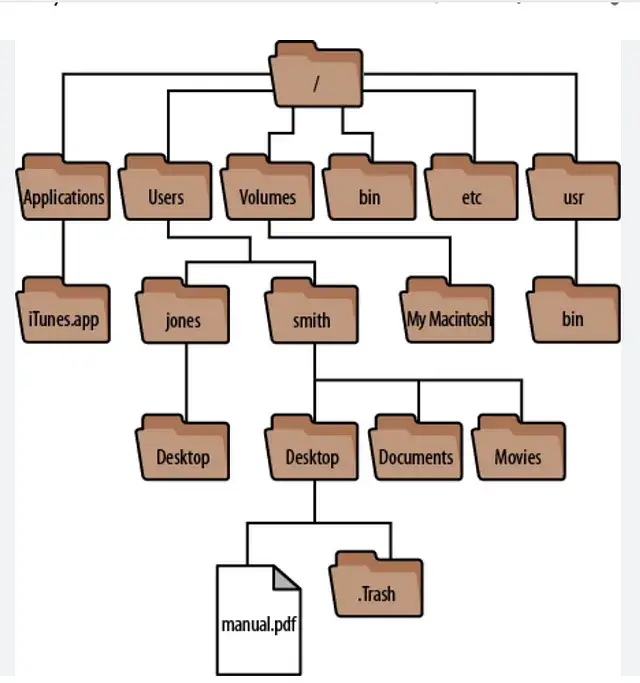
Examples of a typical file structure of folders on a personal computer. It can look different in business, even in government.
When it comes to missing data, it’s important to return to metadata analysis. Checking file creation dates helps build a timeline to identify “jumps” or gaps in dates. If such anomalies are detected, it is worth considering the possibility of their intentional nature and adding them to the red flags.
To facilitate this process, you can write a script in Python. It processes files, extracts metadata, stores timestamps, and organizes them into a data frame. This makes it easy to spot any unusual patterns or duplicates.
Next, once the dates of creation of the files are determined, it is useful to conduct OSINT research to understand what was happening in the world concurrently with these events, which can help to better understand the context of the creation of the data.
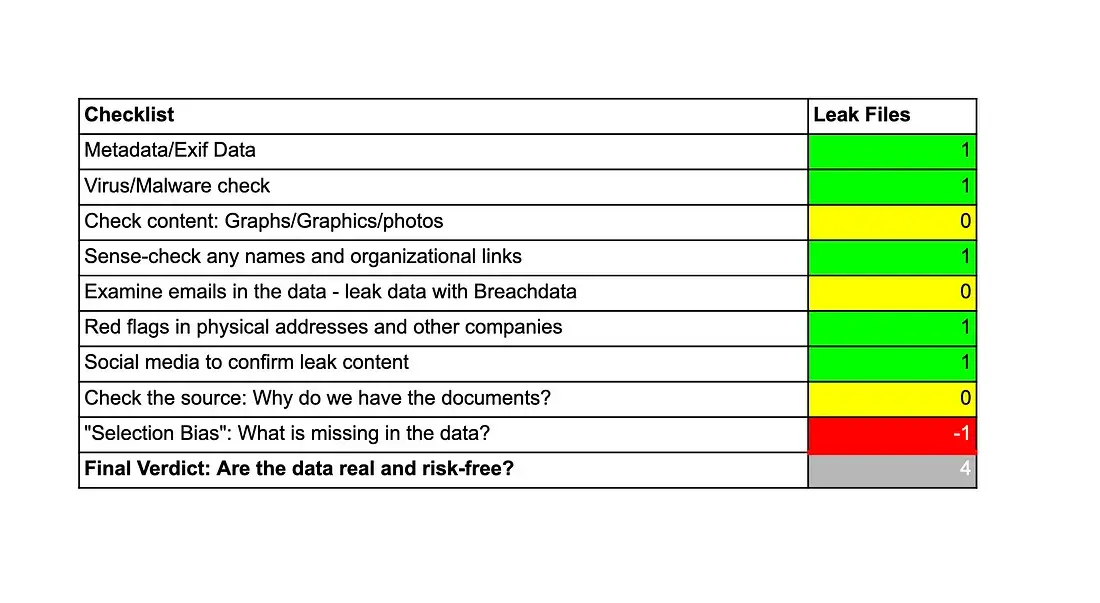
Risk is always present in the process of verifying the authenticity of leaked data. To minimize it, you should follow a structured approach. Using a rating system can help assess different aspects of a leak, from -1 (did not pass inspection or revealed red flags) to 0 (not relevant) and 1 (passed inspection). The final score will help decide whether to continue with a deeper study. This approach allows you to systematically assess the authenticity of data and make informed decisions.
Although not directly relevant to leak authentication, instant PDF translation can be very useful for data analysis. For safe translation, it is recommended to perform it locally on your computer.
You can use a local DeepL account or set up a plugin system. If the documents are sensitive, local Python libraries can be used for images. For less sensitive material, you can use Google Images OCR and translation.


