
29.10.2024
1 хв
1257

Багато розробників вважають, що після видалення файла з Git — він зник назавжди. Але це хибне уявлення може дорого коштувати. Навіть після git rm дані лишаються в історії репозиторію, зокрема в .pack-файлах і недосяжних об’єктах. Саме це використав дослідник, який заробив понад $64 000, знаходячи секрети в GitHub-репозиторіях.

TL;DR : я побудував систему, яка клонує і сканує тисячі публічних GitHub-репозиторіїв — і знаходить у них секрети, що втекли.
У кожному репозиторії я відновлював видалені файли, знаходив недосяжні об’єкти, розпаковував .pack-файли та знаходив API-ключі, активні токени та обліки. А коли повідомив компаніям про витік, заробив понад $64 000 на баг-баунті.
Мене звуть Шарон Бризинов Я займаюся дослідженням низькорівневих експлойтів в пристроях OT/IoT і час від часу полюю за вразливістю в рамках баг-баунті.
Багато багхантерів сканують репозиторії GitHub у пошуках випадково засвічених облікових даних. Я вирішив копнути глибше: відновлювати секрети із файлів, які автори вважали віддаленими. Розробники часто забувають: якщо щось потрапило до Git, воно залишається в історії, навіть якщо з робочої директорії все підчистили.
Щоб перевірити гіпотезу, я просканував десятки тисяч корпоративних репозиторіїв, аналізуючи їхню історію коммітів у пошуках конфіденційних даних. Результати вразили: я виявив безліч видалених файлів з API-ключами, логінами, паролями і навіть токенами сесій, що діють.
Нижче розповім, як збирав репозиторії, писав скрипти, знаходив секрети та надсилав звіти про їхній витік.
Для початку раджу прочитати статтю How Git Internally Works – вона ясно і просто пояснює внутрішній пристрій Git.
Git – це розподілена система керування версіями, яка відстежує зміни у файлах та дозволяє розробникам спільно працювати над проектами. Вона зберігає повну історію змін, дозволяючи при необхідності повертатися до попередніх станів, створювати гілки та поєднувати зміни. По суті Git влаштований як файлова система з адресацією вмісту, в якій кожна версія файлу зберігається в репозиторії як унікальний об’єкт.
Git відстежує все – файли, папки, комміти – у вигляді об’єктів, кожен з яких ідентифікується хеш SHA-1 або SHA-256 (залежно від конфігурації).
Блоб ( blob , binary large object) – об’єкт із вмістом файлу.
Дерево (tree) відбиває структуру каталогів.
Коміт ( commit ) – Снепшот + метадані.
Тег (tag) – анотована мітка.
Блоб – це об’єкт, у якому Git зберігає вміст файлу. Він не містить інформації про ім’я файлу або його розташування — лише дані.
Коли Git вперше зберігає об’єкт, він записує його як незв’язаний об’єкт (loose object) приблизно в такому вигляді:
.git/objects/ab/cdef1234567890...
Тут abце перші два символи SHA-хеша, а cdef1234567890…його продовження. Дані стискаються за допомогою алгоритму zlib і є вмістом одного файлу.
Для економії простору та підвищення продуктивності Git пакує незв’язані об’єкти в .pack-файли. За промовчанням це відбувається, коли число loose-об’єктів досягає 6700.
.git/objects/pack/pack-<hash>.pack
.pack – файли мають складну і дуже цікаву структуру .git-unpack-objects
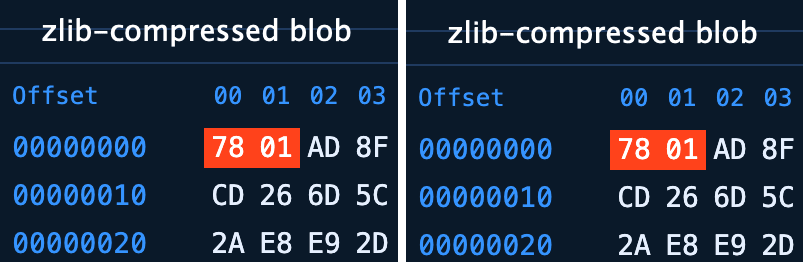
Іноді в репозиторії з’являються недосяжні об’єкти (dangling objects) — валідні комміти, блоби, дерева чи теги, які більше не посилається жодна гілка, тег, stash чи reflog. Зазвичай вони виникають при переписуванні історії – наприклад, при використанні команд git commit --amend, rebase, reset або при видаленні гілки. Хоча такі об’єкти вже не входять до активної історії, Git за замовчуванням зберігає їх ще протягом двох тижнів, щоб їх можна було відновити. Знайти такі об’єкти можна за допомогою команди git fsck --dangling.
Кожен коміт в Git є снепшот репозиторію в певний момент часу. Коміти незмінні, вони ідентифікуються за хешем SHA-1/SHA-256.
Коміт містить:
Посилання на об’єкт дерева, який описує структуру файлів.
Покажчики на батьківські комміти, що формують граф з історією змін.
Метадані, у тому числі ім’я автора, тимчасову мітку та повідомлення комміту.
Завдяки дельта-стиску Git ефективно зберігає комміти: записує лише зміни, а не повні копії файлів.
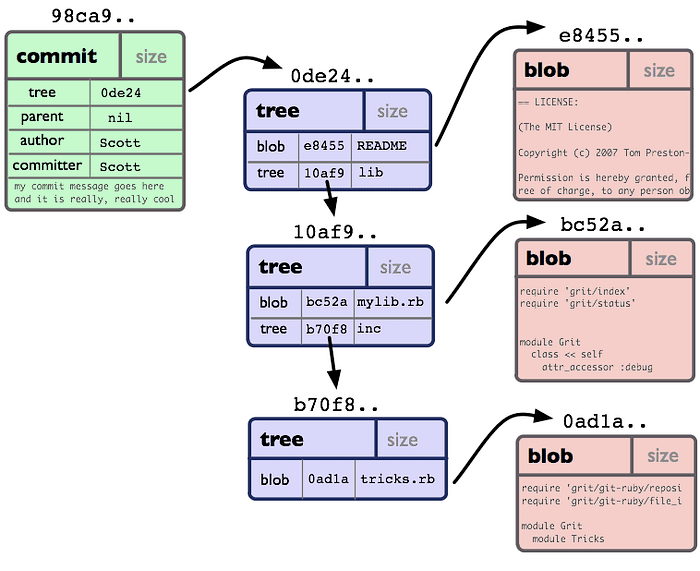
Коли файл видаляється за допомогою git rmабо просто переміщається з робочої директорії та зміни комітуються, він зникає з поточного снепшота, але продовжує зберігатися в історії репозиторію. Це відбувається з двох причин:
Комміти у Git незмінні. Після створення кожен коміт і всі пов’язані з ним об’єкти зберігаються
.git/objectsі продовжують існувати, навіть якщо на них більше не посилаються жодна гілка, жоден тег. Об’єкти, на які ніщо не посилається (недосяжні), не видаляються відразу – зазвичай вони зберігаються близько двох тижнів, перш ніж будуть видалені системою зі збирання сміття.
Посилання (refs) утримують об’єкти від видалення. Git зберігає посилання в head, тегах та віддалених репозиторіях. Навіть якщо у пізнішому коміті файл було видалено, старі комміти все ще містять його.
Щоб дійсно видалити файл з історії, потрібно переписати історію або за допомогою інструментів на кшталт git filter-branch і git-filter-repo, або вручну через rebaseнаступне складання сміття (с prune) — це потрібно для видалення недосяжних об’єктів. Але якщо публічний репозиторій, файл вже могли скопіювати або клонувати, і тоді важливо якнайшвидше відкликати всі API-ключі, токени, сесійні ідентифікатори та інші секрети.
Щоб краще зрозуміти, як Git обробляє файли та каталоги, я написав невеликий інструмент, що візуалізує зміни у структурі репозиторію: які об’єкти створюються, які видаляються. Це була, звичайно, надмірна витівка для цього проекту — але в дусі «вайб-кодингу» я впорався за п’ять хвилин, тож чому б і ні.

Головне питання: як отримати всі віддалені файли?
Можна відновити видалені файли, порівнюючи батьківські та дочірні коміти за допомогою
git diff.
Розпакувати всі файли .pack за допомогою
git unpack-objects < .git/objects/pack/pack-<SHA>.pack.
Знайти недосяжні об’єкти через
git fsck — full — unreachable — dangling.
Щоб зібрати всі видалені файли, я пройшов по кожному коміту і порівняв його з батьківським ( git diff). Якщо у списку були файли зі статусом D (віддалений), я відновлював їх git showі зберігав на диск.
Звичайно, це не найкращий та ефективний спосіб, але для моїх цілей він спрацював. Ось невеликий proof-of-concept-скрипт, який виконує це завдання:
#!/bin/bash
# Переходимо в клонований репозиторій
mkdir -p "__ANALYSIS/del"
# Витягуємо всі коміти та обробляємо кожен
git rev-list --all | while read -r commit; do
echo "Обробка коміту: $commit"
# Отримуємо батьківський коміт
parent_commit=$(git log --pretty=format:"%P" -n 1 "$commit")
if [ -z "$parent_commit" ]; then
continue
fi
parent_commit=$(echo "$parent_commit" | awk '{print $1}')
# Отримуємо diff коміту
git diff --name-status "$parent_commit" "$commit" | while read -r file_status file; do
# Замінюємо / на _ для імен файлів у binary_files_dir
safe_file_name=$(echo "$file" | sed 's/\//_/g')
# Обробляємо видалені файли
if [ "$file_status" = "D" ]; then
# Обробляємо бінарні файли
echo "Видалено бінарний файл: $file" | tee -a "__ANALYSIS/del.log"
echo "Збереження до __ANALYSIS/del/${commit}__${safe_file_name}"
git show "$parent_commit:$file" > "__ANALYSIS/del/${commit}__${safe_file_name}"
fi
done
done
А ось однорядок, який я використав для вилучення всіх недосяжних блобів:
mkdir -p unreachable_blobs && git fsck --unreachable --dangling --no-reflogs --full - | grep 'unreachable blob' | awk '{print $3}' | while read h; do git cat-file -p "$h" > "unreachable_blobs/$h.blob"; done
Тепер, коли PoC-скрипт з відновлення віддалених файлів був готовий, потрібно було зібрати якомога більше релевантних GitHub-репозиторіїв.
Насамперед я склав список компаній, що беруть участь у публічних та приватних програмах.
Де шукати інформацію про публічні програми:
Крім того, я вирішив вивчити GitHub-акаунти компаній, які мають хоча б один репозиторій з 5000+ зірок. Для цього я скористався таким однорядником:
for page in {1..100}; do gh api "search/repositories?q=stars:>5000&sort=stars&order=desc&per_page=50&page=$page" --jq '.items[].full_name'; done | cut -d '/' -f 1
Я зібрав величезний список із назвами компаній і зберіг його у файл companies.txt . Тепер потрібно було знайти їхні публічні облікові записи на Github. Можна було придумати щось розумне, але я вибрав найлінивіший спосіб використовувати ІІ. Просто відправляв нейромережам найменування компаній з проханням знайти GitHub-акаунти, пов’язані з тією чи іншою організацією. Декілька акаунтів ІІ вигадав, але в цілому спрацювало непогано.
Ще я досить швидко помітив, що багато компаній тримають по кілька акаунтів на GitHub: окремий для основної розробки, окремий для QA і так далі. З цього моменту я шукав облікові записи за ключовими словами на кшталт: lab, research, test, qa, samples, hq, community .
Потім я прошерстив зібрані акаунти та репозиторії, щоб знайти форки інших проектів. Для кожного форка я знаходив оригінальний репозиторій і додавав до списку моніторингу облікові записи, пов’язані з цим вихідним проектом.
Я міркував так: якщо якась компанія опублікувала код, який активно форкають інші учасники з мого списку, значить, у цієї компанії можуть бути й інші репозиторії з секретами, що втекли, — і ці секрети цілком можуть потрапити в чужі проекти разом з кодом.
У результаті я зібрав кілька тисяч корпоративних GitHub-акаунтів. Настав час було переходити до технічної частини.
Сама система була досить простою: я клонував проекти всіх компаній, відновлював видалені файли і шукав у них активні секрети, що зберегли актуальність.
Спрощений псевдокод:
- foreach company in companies:
- foreach repo in comapny.repos:
- restore all deleted files
- foreach file in files:
- collect secrets
- foreach secret in secrets:
- is secret active?
- notify via Telegram bot
Весь процес складався з кількох етапів:
підготовка машин;
клонування репозиторіїв;
відновлення віддалених файлів;
пошук секретів;
надсилання повідомлення про знайдені секрети мені в Telegram;
видалення репозиторіїв.

Я використовував 10 серверів: частина з них – хмарні машини (наприклад, EC2), частина – VPS, і навіть пара фізичних пристроїв із Raspberry Pi. Я простежив, щоб на кожному вузлі було достатньо вільного простору – щонайменше 120 ГБ. Потім розбив список компаній на десять блоків та розподілив їх між серверами.
Для отримання списку репозиторіїв окремої компанії на GitHub я використовував CLI-інструмент gh :
for REPO_NAME in $(gh repo list $ORG_NAME -L 1000 --json name --jq '.[].name');
do
FULL_REPO_URL="https://github.com/$ORG_NAME/$REPO_NAME.git"
git clone "$FULL_REPO_URL" "$REPO_NAME"
done;
В рамках цього кроку віддалені файли відновлювалися за допомогою методів, описаних вище.
Тепер потрібно просканувати відновлені файли на наявність активних секретів. Тут мені допоміг TruffleHog — потужний інструмент пошуку секретів, який глибоко перевіряє вміст репозиторію.
TruffleHog підтримує більше 800 типів ключів і вміє верифікувати знайдені секрети, щоб відсіяти помилкові спрацьовування. Крім цього він здатний виявляти дані в base64 та деяких архівних форматах.
Я запускав Trufflehog з прапором only-verified, щоб зберігати ті секрети, які пройшли перевірку і з високою ймовірністю зберегли актуальність. Ще використав аргумент filesystem, щоб просканувати диск і знайти відновлені файли:
trufflehog filesystem --only-verified --print-avg-detector-time --include-detectors="all" ./ > secrets.txt
Однією з ключових переваг використання TruffleHog для локальних клонів було те, що він сканує директорію .git. Завдяки тому, що він вміє розпаковувати та аналізувати потоки, стислі через zlib, більшість незв’язаних об’єктів автоматично опинялися в області видимості без зайвої метушні. TruffleHog також аналізував .pack-файли і вони кілька разів приємно мене здивували.
Ви запитаєте: якщо TruffleHog вміє розпаковувати і сканувати об’єкти Git, навіщо тоді вручну відновлювати віддалені файли? Відповідь проста – це значно підвищувало ефективність знаходження секретів. Вилучення максимально можливої кількості файлів значно підвищувало мої шанси виявити секрети, що втекли.
Як тільки TruffleHog знаходив активний секрет, я отримував повідомлення у Telegram:
curl -F chat_id="XXXXXXXXXXXXX" \
-F document=@"$ORG_NAME.$REPO_NAME.secrets.txt" \
-F caption="New secerts - $ORG_NAME - $REPO_NAME" \
'https://api.telegram.org/botXXXXXXXXXXXXX:XXXXXXXXXXXXX/sendDocument'
Чому Telegram? Просто звичний мені спосіб отримання повідомлень. Звичайно, під це завдання можна було зробити окремий бекенд із базою даних, але до чого ці напруження? 🙂
Після обробки репозиторій видалявся, щоб звільнити місце і скрипт переходив до наступного.
Що мені вдалося знайти? Сотні секретів, які втекли, — і при цьому залишалися актуальними. Втім, крім секретів, які реально використовувалися в production-середовищі, траплялася і всяка нісенітниця – наприклад, тестові акаунти і canary-токени.
Нижче є список найцінніших токенів і ключів, які мені вдалося виявити, а також зразкові суми винагород.
Токени GCP/AWS — $5000–$15000 🔥🔥🔥
Токени Slack – $3000-$10000 🔥🔥
Токени Github – $5000-$10000 🔥🔥
Токени OpenAPI – $500-$2000 🔥
Токени HuggingFace – $500-$2000 🔥
Токени Algolia Admin – $300-$1000 🔥
Облікові дані SMTP – $500-$1000 🔥
Токени та сесії розробників конкретних платформ — $500–$2000 🔥
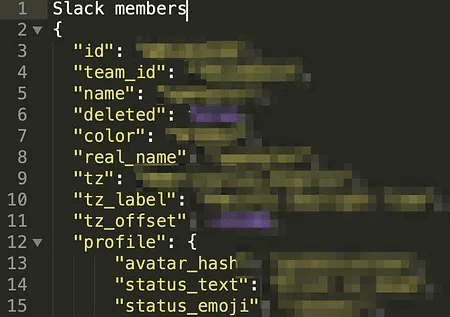
Незважаючи на велику кількість дійсно цінних токенів, багато з них виявилися марними: вони належали тестовим акаунтам або були canary-токенами (пастками для зловмисників). Такі пастки генеруються за допомогою сервісів на зразок CanaryTokens: при спрацьовуванні токена власнику навіть надходить повідомлення на пошту. Це зручний та ефективний спосіб відстеження витоків.
Інші види секретів-пустушок:
Тестові ключі для Github. Багато проектів містили приватні ключі, пов’язані з тестовими користувачами – наприклад, aaron1234567890123. Такі ключі зустрічалися у сотнях репозиторіїв.
Одноразові акаунти . Облікові записи, що використовуються для read-only або для обходу обмежень частоти запитів.
Відкриті токени API Web3. Сотні проектів Web3 містили відкриті ключі, призначені для звернення до блокчейну, щоб отримати, наприклад, інформацію про транзакції або курси криптовалют. Найчастіше зустрічалися токени Infura та Alchemy.
Фронтенд-ключі API : деякі сервіси (наприклад, Algolia) припускають, що ключ використовуватиметься у фронтенді. Зазвичай такі ключі мають лише права читання. Проблема виникає, коли розробник випадково використовує токен із правами адміністратора замість безпечного ключа для пошуку.
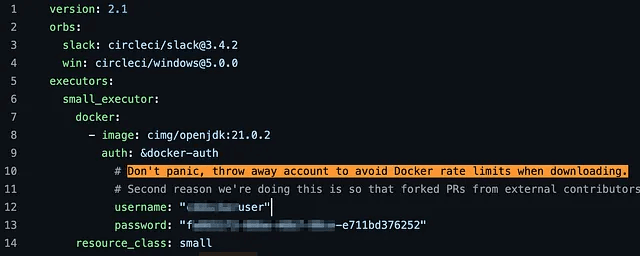
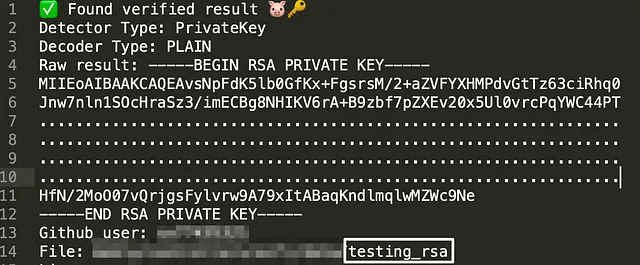
Проаналізувавши десятки критичних випадків, я дійшов висновку, що секрети найчастіше витікали з однієї з трьох причин: нерозуміння роботи Git, незнання складу файлів, що потрапляють до комміту, і надмірна віра в інструменти переписування історії.
Деякі розробники просто не знали, як Git фактично зберігає дані. Вони могли випадково закомітити незашифровані токени, секрети чи облікові дані. Усвідомивши помилку, вони видаляли файл або вирізали секрет вручну, але не відкликали його. Git зберігає всю історію, і якщо відновити старі стани, ці секрети, як і раніше, можна знайти.
У ряді випадків розробники не використовували .gitignore і випадково коммітували двійкові файли – наприклад, .pyc (компільовані Python-файли), які містили секрети.
Були й випадки, коли до комміту потрапляли приховані файли (наприклад, .env) або архіви .zip, що містять такі файли. Навіть після видалення цих артефактів відновлення було можливим, і секрети виявлялися вразливими.
В одному прикладі команда випадково закомітила секрети до свого репозиторію. Пізніше вони застосували інструменти для переписування історії, щоб видалити сліди, але в .pack-файлі все ще зберігалося посилання на об’єкт. Я зміг відновити цей секрет і повідомив розробників, щоб вони вирішили проблему до її експлуатації.
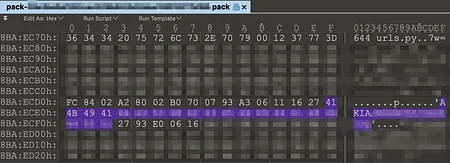


Більшість секретів, що втекли, було знайдено в двійкових файлах, які закоммітували в репозиторій, а пізніше видалили. Ці файли зазвичай були згенеровані компіляторами чи автоматизованими процесами. Найчастіший приклад – .pyc-файли , в яких Python-інтерпретатор зберігає байт-код. Ці файли часто потрапляють до комміту випадково.
Інший найпоширеніший випадок – файли налагодження .pdb , створювані компіляторами. Вони також містять чутливі дані і нерідко опиняються в історії репозиторію.
Проект видався не просто корисним, а страшенно захоплюючим. Масове локальне клонування репозиторіїв GitHub і відновлення видалених файлів виявилося ефективною (і дуже прибутковою) тактикою для полювання на секрети, що втекли.
Заодно я ґрунтовно прокачався в анатомії Git і навіть створив у процесі кілька власних інструментів. Один з них – HexShare – відкритий для всіх бажаючих.
А далі — більше. Відправив звіти, отримав фідбек, допоміг покращити безпеку декільком великим компаніям.

