
19.01.2024
1 хв
2578

Хочете зрозуміти, яка версія DeepSeek-R1 краще працює у реальних умовах? У цьому огляді ми порівняли чотири моделі з різним рівнем квантування: Q5_K_XL, Q4_K_XL, Q3_K_XL та IQ2_M. Тестували швидкість генерації, споживання RAM/VRAM і якість відповіді на прикладі генерації гри «змійка» на Python. Дізнайтеся, як поводяться моделі на CPU та GPU+CPU, що реально впливає на продуктивність, і чи варто економити ресурси за рахунок якості. Детальний технічний аналіз — у нашій статті.

Після того як я зібрав домашній сервер для запуску LLM DeepSeek-R1 (детальніше про це в статті «Локальний DeepSeek-R1-0528. Коли швидкість равлика — не вирок, а точка старту»), виникла потреба порівняти різні типи квантизації, щоб краще збалансувати швидкість і якість.
Під час запуску різних моделей я помітив цікаву закономірність: квантизація часто не тільки зменшує розмір, а й пришвидшує генерацію токенів.
Зараз майже кожна нова популярна модель, яка з’являється, досить швидко отримує кілька квантизованих версій на huggingface. Визначити, яка з них краща за співвідношенням розміру, швидкості та точності — непросте завдання. Саме тому я вирішив завантажити кілька таких варіантів і самостійно протестувати їх: заміряти швидкість та оцінити якість відповіді у форматі суб’єктивного аналізу.
Для тесту я обрав чотири варіанти квантизованої DeepSeek-R1 0528 від команди unsloth.
UD-Q5_K_XL 481GB
UD-Q4_K_XL 384GB
UD-Q3_K_XL 296GB
UD-IQ2_M 229GB
EPYC 7K62
Supermicro H11SSL-i Version: 2.00
8 x hynix 64GB 2Rx4 PC4-3200AA-RB4-12. (Total 512GB)
NVIDIA RTX 3090
Сервер дозволяє запускати LLM як із використанням GPU+CPU так і з використанням лише CPU.
Для кожної моделі буде проведено тестування тільки на CPU і на CPU+GPU. Будемо просити LLM написати гру змійка. Сам промпт буде максимально простий та наївний.
'''text Напиши гру змійка на Python. - Ігрове поле має мати сітку - гра повинна мати приємну кольорову гаму - меню - анімацію поїдання їжі - Цікаву особливість '''
Значення температури встановимо 0 відповідно до рекомендацій із сайту DeepSeek. Тестове середовище llama.cpp в контейнері docker запущено в ubuntu 24. Приклади docker compose файлів.
services:
cpu-llm:
container_name: cpu-${MODEL_NAME}-${TEMP:-0.0}
image: ${IMAGE_CPU:-ghcr.io/ggml-org/llama.cpp:server}
user: "${UID:-1000}:${GID:-1000}"
ports:
- "${PORT:-29004}:${PORT:-29004}"
volumes:
- ./${MODEL_DIR}:/models:ro
security_opt:
- no-new-privileges:true
read_only: true
tmpfs:
- /tmp
command: [
"-m", "/models/${MODEL_FILE}",
"--cache-type-k", "${CACHE_TYPE_K:-q4_0}",
"--threads", "${THREADS:--1}",
"--ctx-size", "${CTX_SIZE:-16384}",
"--prio", "${PRIO:-3}",
"--temp", "${TEMP:-0.0}",
"--min-p", "${MIN_P:-0.01}",
"--top-p", "${TOP_P:-0.95}",
"--port", "${PORT:-29004}",
"--host", "${HOST:-0.0.0.0}"
]
healthcheck:
test: ["CMD-SHELL", "curl -f http://localhost:${PORT:-29004}/health || exit 1"]
interval: 30s
timeout: 10s
retries: 5
start_period: 2m
restart: unless-stopped
services:
gpu_cpu-llm:
container_name: gpu_cpu-${MODEL_NAME}-${TEMP:-0.0}
image: ${IMAGE_GPU:-ghcr.io/ggml-org/llama.cpp:server-cuda}
user: "${UID:-1000}:${GID:-1000}"
deploy:
resources:
reservations:
devices:
- driver: nvidia
capabilities: [gpu]
ports:
- "${PORT:-29004}:${PORT:-29004}"
volumes:
- ./${MODEL_DIR}:/models:ro
security_opt:
- no-new-privileges:true
read_only: true
tmpfs:
- /tmp
command: [
"-m", "/models/${MODEL_FILE}",
"--cache-type-k", "${CACHE_TYPE_K:-q4_0}",
"--threads", "${THREADS:--1}",
"--ctx-size", "${CTX_SIZE:-16384}",
"--n-gpu-layers", "${GPU_LAYERS:-998}",
"-ot", ".ffn_.*_exps.=CPU",
"--prio", "${PRIO:-3}",
"--temp", "${TEMP:-0.0}",
"--min-p", "${MIN_P:-0.01}",
"--top-p", "${TOP_P:-0.95}",
"--port", "${PORT:-29004}",
"--host", "${HOST:-0.0.0.0}"
]
healthcheck:
test: ["CMD-SHELL", "curl -f http://localhost:${PORT:-29004}/health || exit 1"]
interval: 30s
timeout: 10s
retries: 5
start_period: 2m
restart: unless-stopped
Для початку наведу порівняння споживаних ресурсів. Як видно що для всіх моделей крім найменшої потрібен сервер з більш ніж 256 гігабайтами пам’яті. І тільки з UD-IQ2_M з представлених у тесті можливий перехід у збірці на бюджетніші модулі пам’яті по 32GB замість модулів по 64GB.
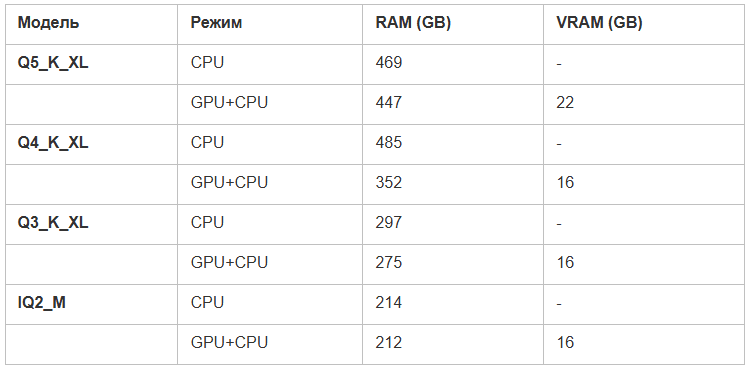
Якщо є знавці чому q5-k-xl споживає менше пам’яті, ніж q4-k-xl при запуску тільки на CPU поділіться будь ласка в коментарях
Ігри вийшли різні, але загалом — цілком вдалі. Жодна з них не була зразком ідеального коду, та цього вистачило, щоб оцінити швидкість генерації та загальний рівень реалізації.
Оскільки метою було саме вимірювання продуктивності, я не заглиблювався в якість контенту. Щоб не розпорошуватись, зібрав усі результати в один GitHub-репозиторій. Там доступні 24 варіанти гри — можна переглянути й сформувати власне враження.
Мої спостереження такі: чим більша модель, тим кращі результати. У них цікавіший візуальний стиль і логічніші ігрові механіки, наскільки це дозволяв короткий запит. Варіанти, які не запускались або в яких змійка не реагувала на їжу, я зарахував до невдалих. Ці результати також врахував під час побудови графіка.
Нижче — кілька прикладів, що здались найвдалішими. Решту можна знайти в репозиторії — вони дають ширше уявлення про загальну якість генерації.
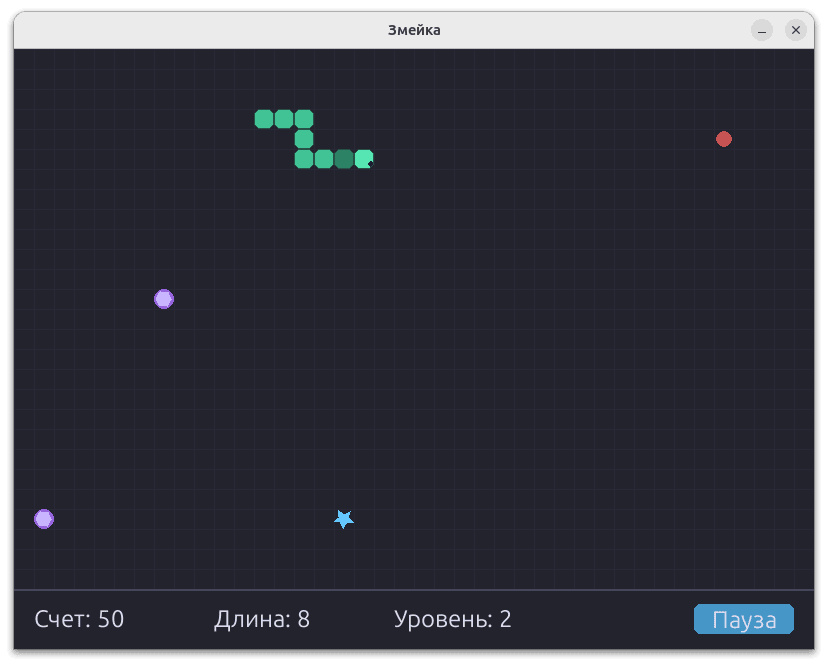
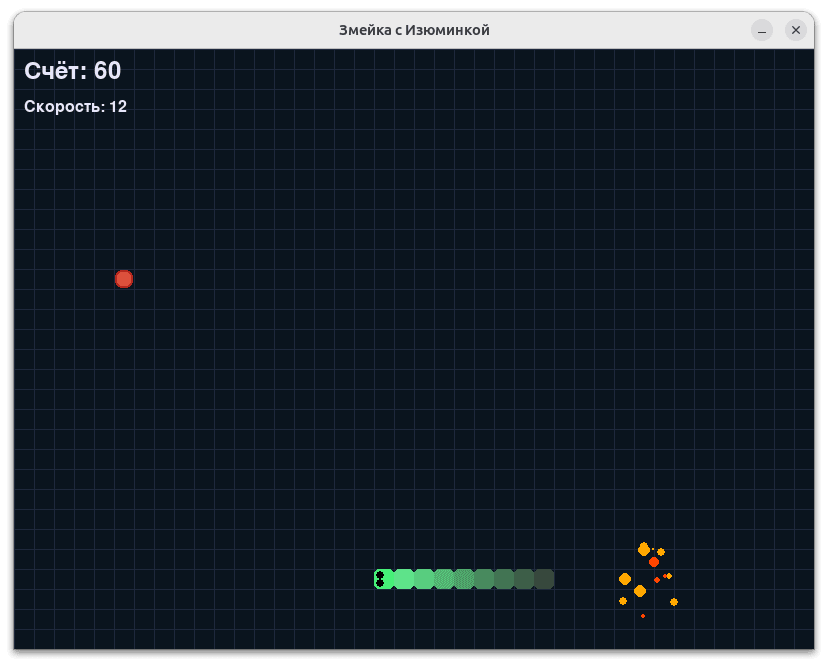
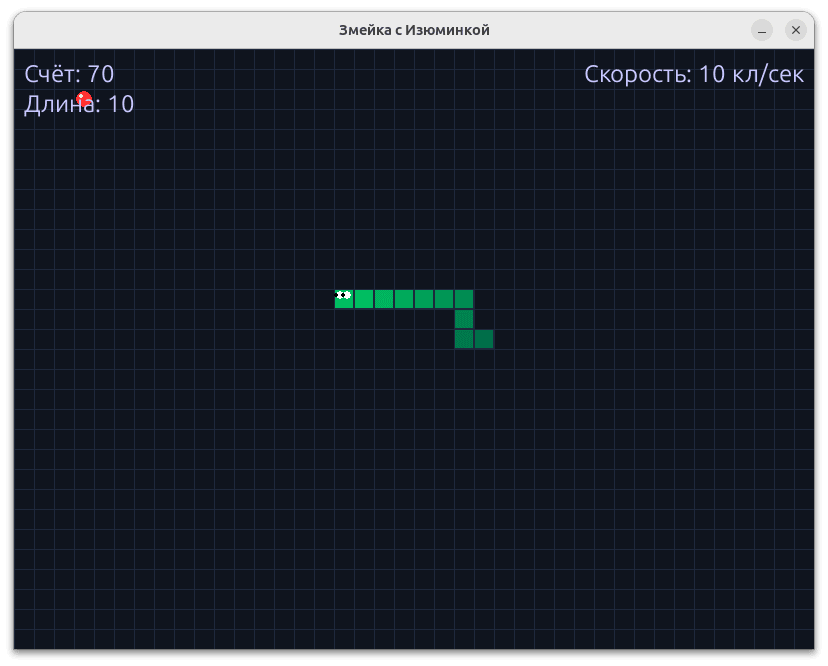
Для оцінки швидкості роботи не проводилися окремі виміри на 1000, 2000 та 5000 токенів — замість цього було зібрано всі підсумкові значення генерації й побудовано зведені графіки. На діаграмах чітко простежується залежність: зі зменшенням розміру моделі швидкість генерації токенів зростає. Ця тенденція зберігається як для CPU, так і для конфігурації GPU+CPU.
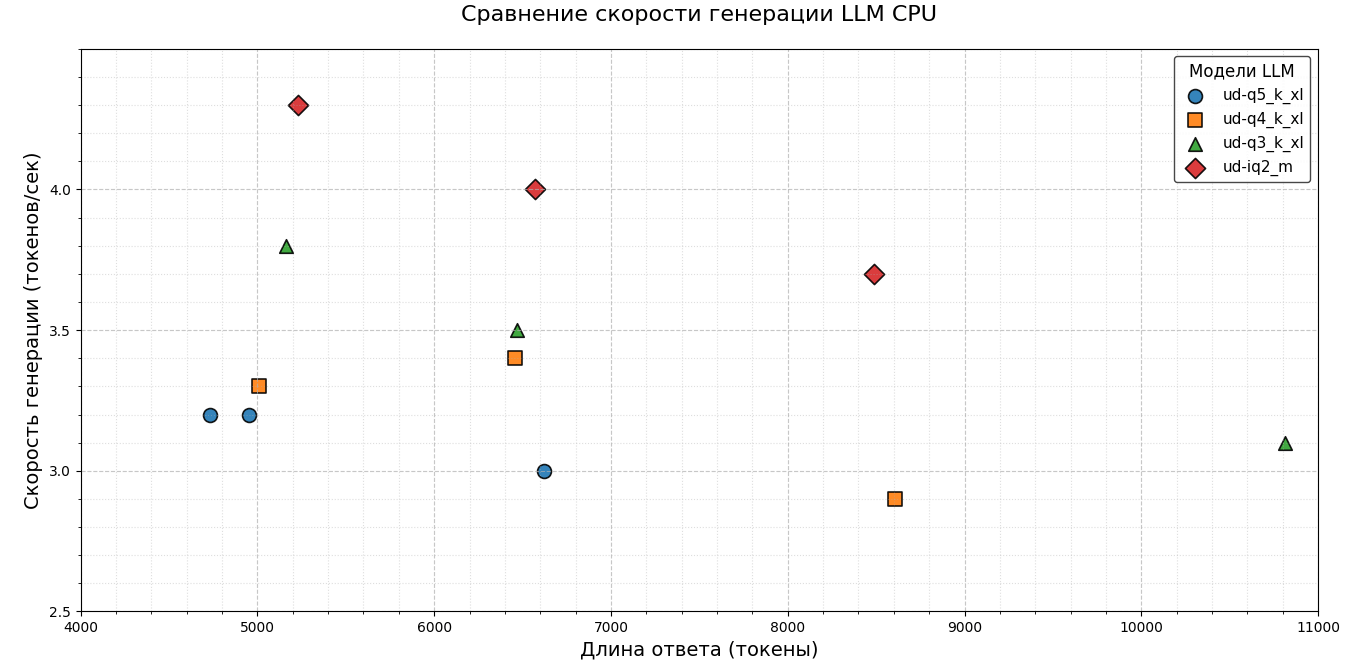
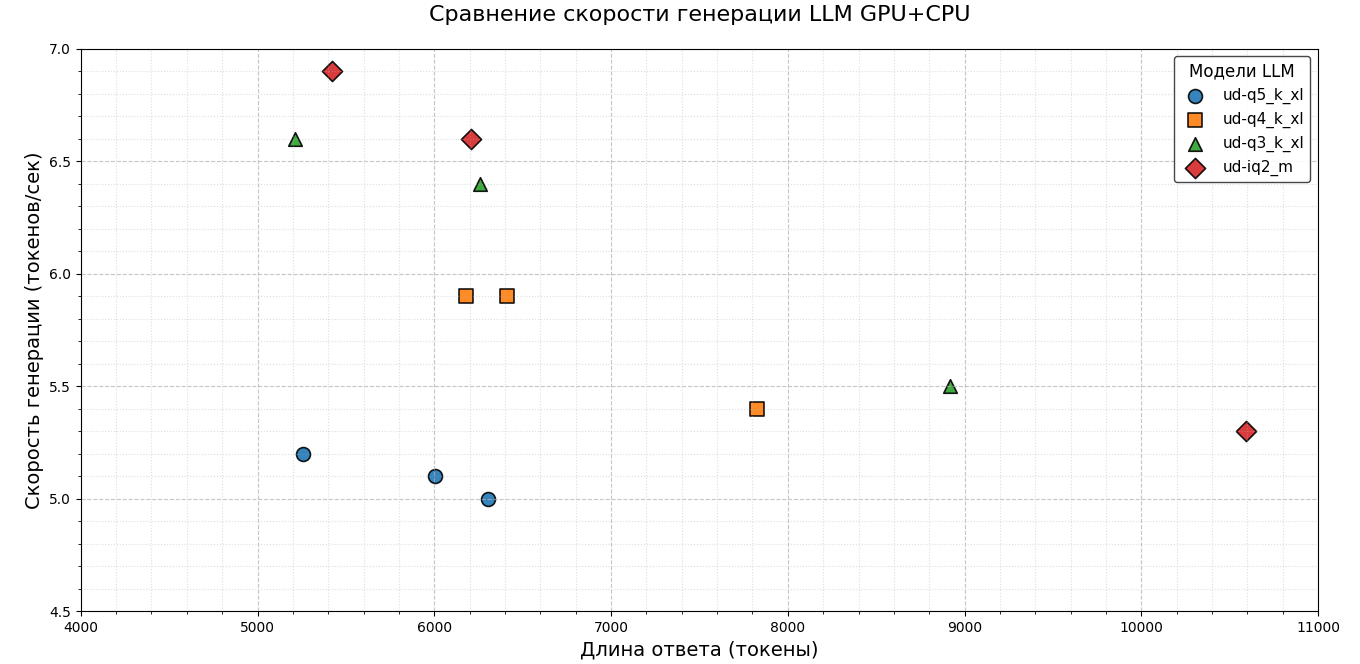
Спочатку я планував оцінювати лише швидкість генерації токенів. Але під час тестування стало помітно: у компактніших версіях моделей маркери відповідей зміщуються праворуч. Це свідчить про те, що такі моделі формують довші відповіді.
Результати я оформив у зрозумілі графіки. На них окремо позначені випадки, де модель повертала некоректні рішення.
Дані виявилися доволі показовими. Хоч окремі токени генеруються швидше, загальний час відповіді зростає. Причина — моделі формують довші відповіді з більшою кількістю токенів.
Крім того, помітне зниження загальної якості відповідей — вони стали менш точними та менш корисними.
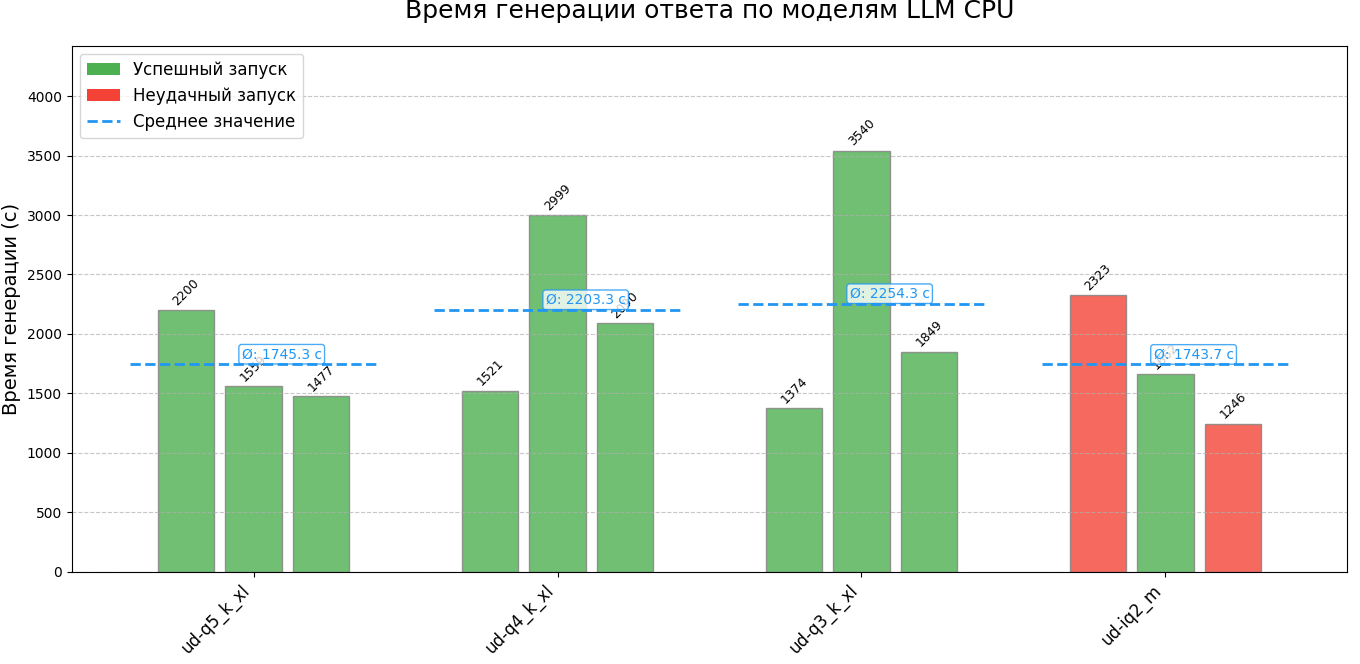
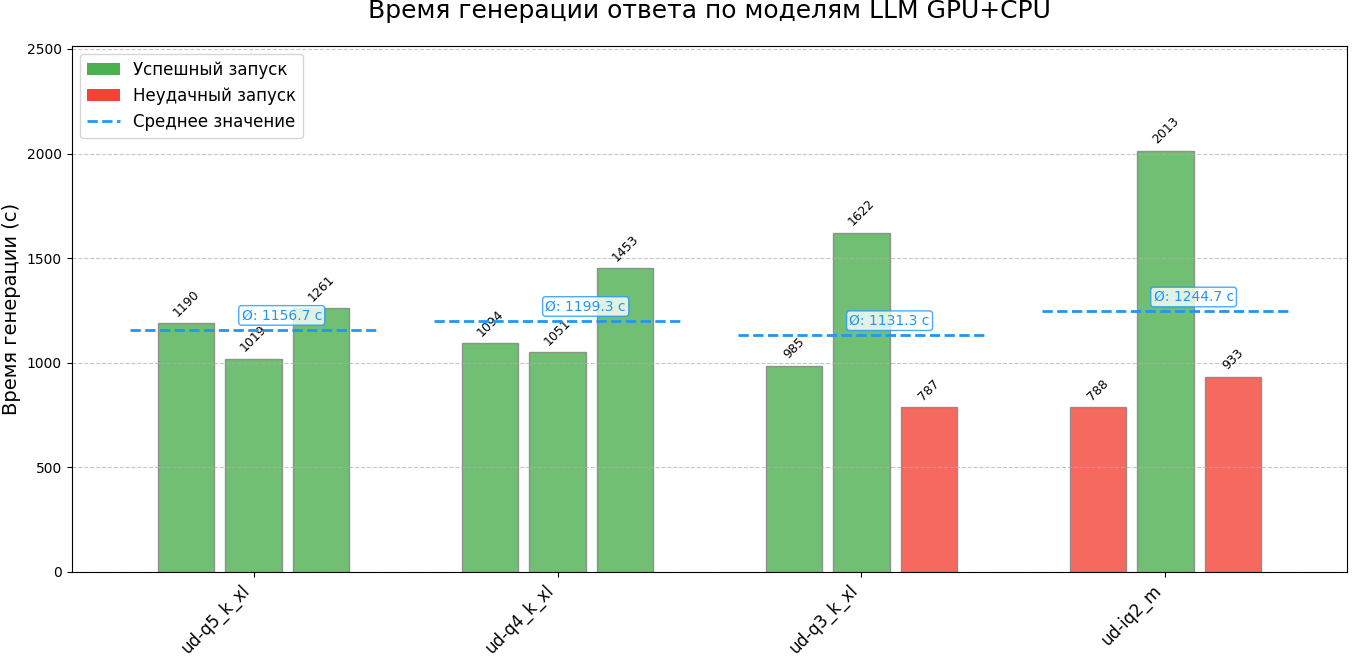
У репозиторії міститься два json файли з чисельними значеннями результатів кожного запуску. Для кожного запуску зроблено два файли:
.md містить всю відповідь повністю включаючи секцію роздумів
.py містить лише код програми для зручності запуску
Перехід на більш компактні версії моделі у випадку генерації коду з використанням DeepSeek-R1 0528 виявився недоцільним. Це не лише знижує якість згенерованого контенту, а й призводить до збільшення загального часу відповіді через зростання її довжини. Якщо додатково враховувати час, витрачений на невдалі запуски, ситуація погіршується ще більше.

