
08.04.2025
1 хв
891

Хочете зрозуміти, як влаштовані анонімні мережі та як вони допомагають зберегти конфіденційність в інтернеті? У цій статті ви знайдете просте пояснення п’яти головних протоколів анонімізації: від класичних Proxy-серверів до складних моделей, як Dining Cryptographers або Entropy Increase. Ми розповідаємо, як працюють мережі типу Tor, I2P, Freenet, чим вони відрізняються між собою та які з них краще захищають від спостереження.

Анонімні мережі — це особливий тип мережевих комунікацій, головною метою яких є приховати зв’язок між учасниками від спостерігачів. Ці спостерігачі можуть бути як локальними, так і глобальними, і діяти як пасивно, так і активно. Головна складність таких мереж — знайти баланс між рівнем анонімності та зручністю користування. Саме тому існує багато різних рішень, які пропонують різний ступінь захисту.
Існує чимало способів класифікації анонімних мереж. Наприклад, за архітектурою — децентралізовані чи гібридні, за відкритістю коду, або за принципами маршрутизації даних. Проте один із найчіткіших і найзрозуміліших підходів — це поділ за типом задачі анонімізації, тобто за тим, як саме мережа приховує інформацію про зв’язок між відправником і одержувачем.
Під завданням анонімізації мається на увазі криптографічний протокол, що має на меті забезпечити доведену анонімність суб’єктів стосовно певних груп спостерігачів. Анонімність при цьому може означати не лише приховування зв’язку між абонентами (що є базовим аспектом), а й маскування ініціатора чи навіть самого факту комунікації — залежно від конкретного завдання. Відповідно, саме завдання анонімізації є основою функціонування будь-якої анонімної мережі.
Загалом і на даний час відомо п’ять завдань анонімізації: Proxy , Onion , DC (Dining Cryptographers), QB (Queue Based) і EI (Entropy Increase). У цій статті ми спробуємо розібратися у кожній із них.
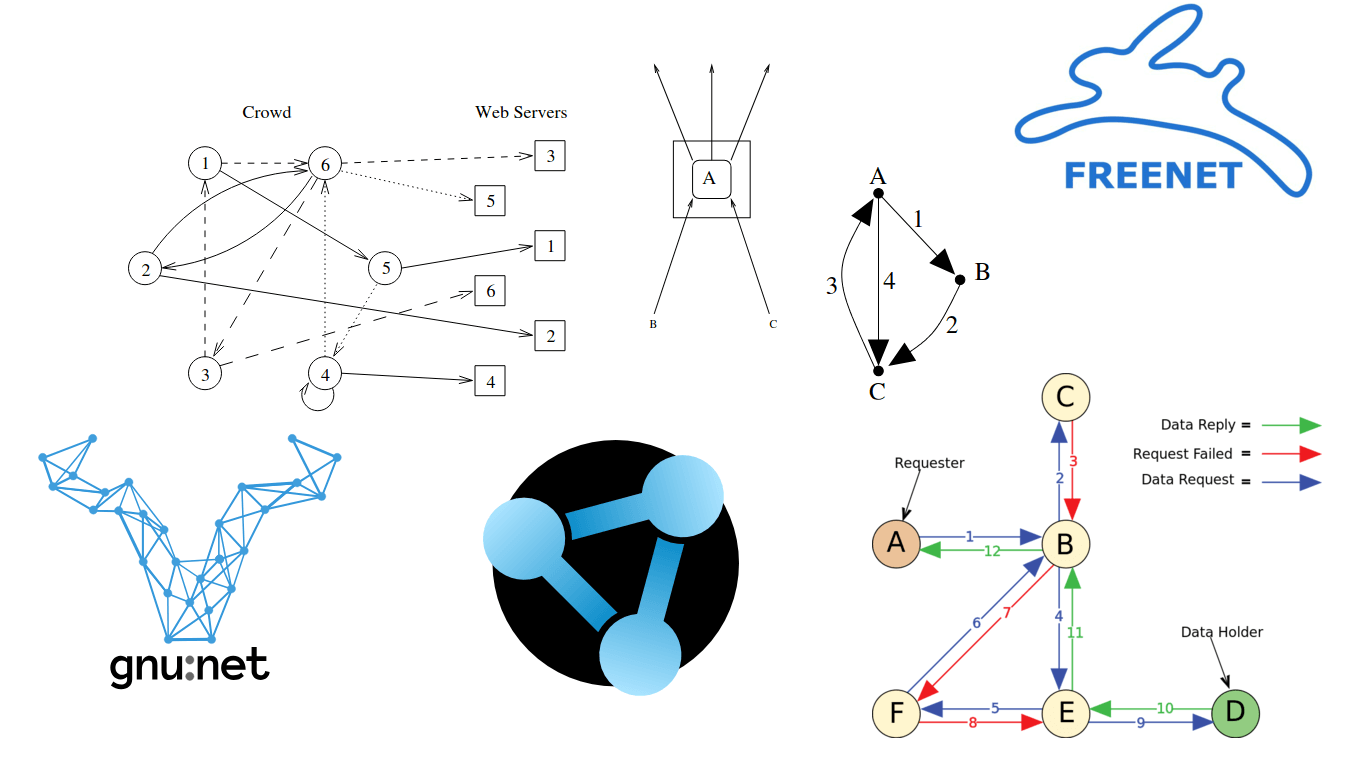
Завдання проксування є одним із найпростіших завдань анонімізації з високою продуктивністю і гарною масштабованістю, але найчастіше зі слабкою моделлю загроз. Як представники даної задачі можна виділити такі мережі, як: Crowds, Freenet ( Hyphanet ), GNUnet, RetroShare, MUTE .
Суть завдання досить проста: проводити трафік від точки A до точки B через безліч проксі-серверів, які не пов’язані між собою загальними власниками або цілями деанонімізації. При цьому кожна маршрутизація повинна супроводжуватися перешифруванням повідомлень з подальшою їх ретрансляцією на наступний проксі-сервер.
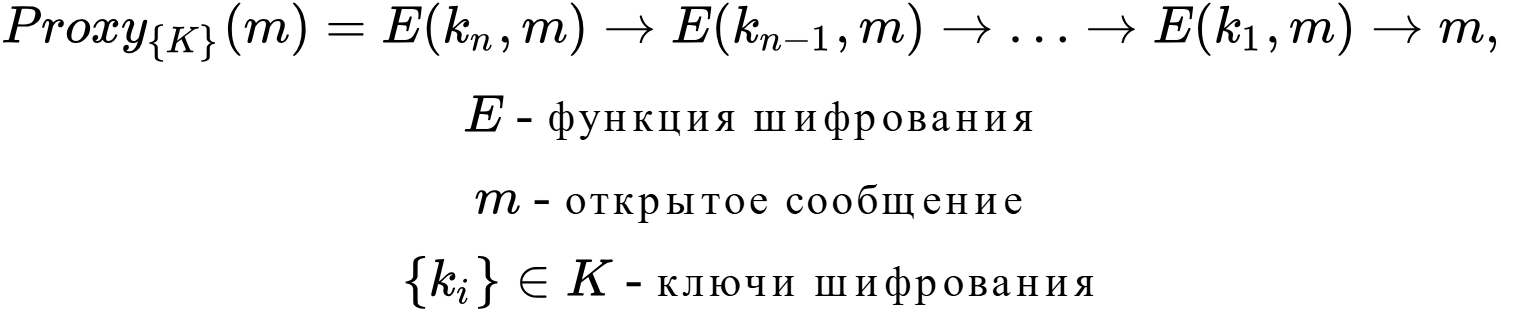
Цікавою особливістю Proxy-завдання є її гнучкість (або вільність) до модифікацій, завдяки чому / через що: 1) анонімні мережі досить сильно можуть відрізнятися одна від одної, 2) анонімні мережі можуть бути створені неявним чином, задіявши для цього публічні проксі-сервера з шифруванням типу Tor або I2P, щоб нівелювати слабку модель загроз з боку завдання проксування.
Слабкість моделі загроз пов’язана не як з таким завданням проксіювання безпосередньо, як з відсутністю додаткових модифікацій на кшталт ймовірнісної маршрутизації (Crowds) або хибних повідомлень (GNUnet). Через відсутність таких, RetroShare пропонує використовувати Tor/I2P. Для Freenet також рекомендується пропускати трафік через Tor/I2P.
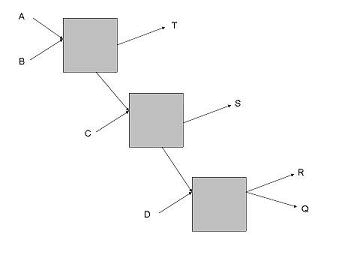
Основний недолік завдання проксування – це вразливість до кооперуючих атак з боку вузлів, що маршрутизують. Так наприклад, якщо вузли 1, 3 є кооперуючими, тоді їм стає можливим зв’язувати відправника та одержувача за допомогою порівняння прийнятого повідомлення. При цьому варто зауважити, що другий вузол, що маршрутизує, стає повністю марним – він ніяк не впливає на якість анонімності. Якщо так само продовжити далі, і поставити між вузлами 1, 3 ще N-е кількість вузлів, то якість анонімності також не зміниться. В результаті ми отримуємо наступний висновок:
Якщо існує система X на основі завдання проксування в якій знаходиться N вузлів, тобто. X = (1, 2, …, N) , і при цьому вузли i, j , де j > i, виявляються кооперуючими, тоді система, що маршрутизує, набуває вигляду X’ = (1, 2, …, i, j, …, N) , і як наслідок | X’ | <= |X| . Система виявляється зламана, якщо |X’| стає дорівнює кількості кооперуючих вузлів.
Завдання проксування є найбільш суперечливим завданням у плані термінології/опису, тому що не кожна мережа, яка використовує Proxy-завдання, є насправді анонімною.
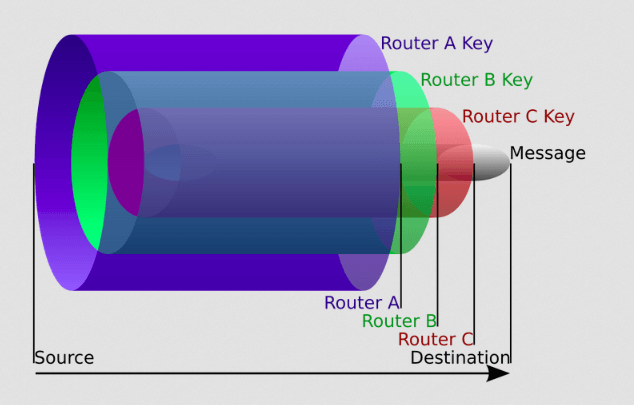
Лукова маршрутизація є одним із найпопулярніших завдань анонімізації через можливість вибудувати відносно гарний компроміс між якістю анонімності та комфортністю користування. Як представники даної задачі можна виділити такі мережі, як: Tor , I2P , Mixminion .
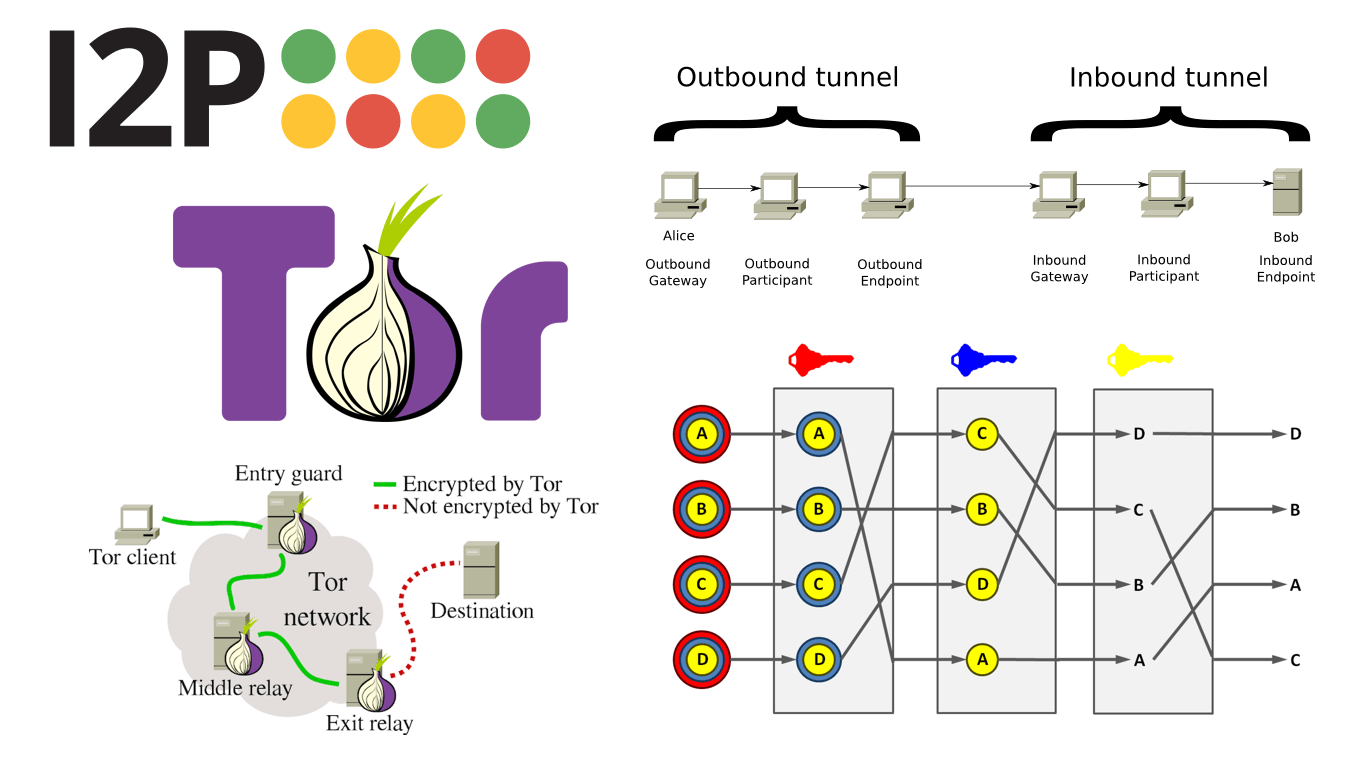
Суть завдання схожа з Proxy, але на відміну від останньої – відсутня процедура перешифрування повідомлень, завдяки чому проблема усічення ланцюжка, що маршрутизує, стає куди складніше здійсненною.
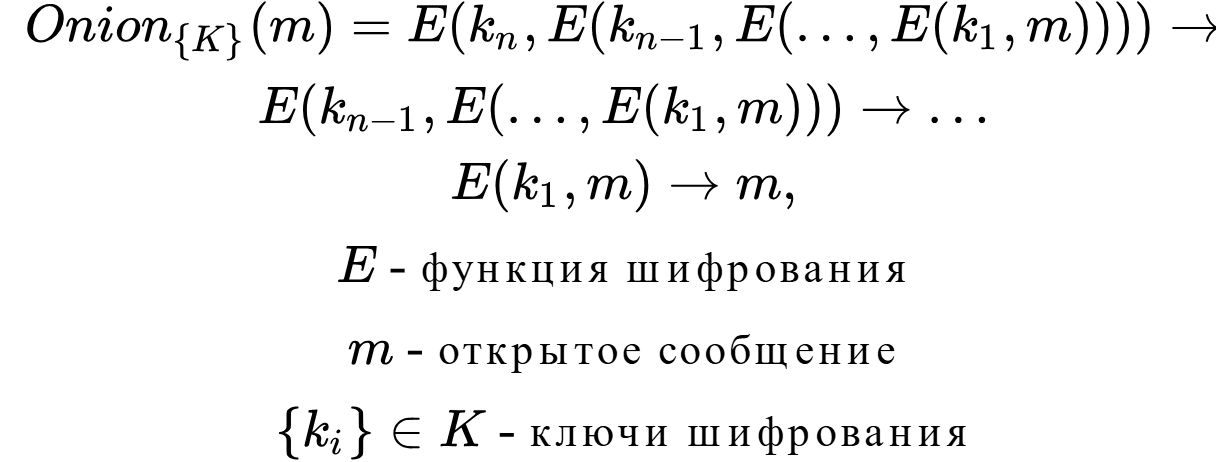
Якщо припустити, що вузли 1, 3 знову кооперують, то вузол 1 не зможе однозначно визначити, що повідомлення було відправлено за допомогою вузла 3, т.к. зв’язати два маршрутизуючих повідомлення неможливо через їх поліморфного (видозмінюється) характеру рахунок наявності множинного шифрування. Це стає можливим за умови, якщо функція шифрування E і ключ k 2 є надійними. В результаті, якщо вузол 3 має повідомлення: C 3 = { E (k 3 , E (k 2 , E (k 1 , m))), E (k 2 , E (k 1 , m)) } , а вузол 1 має повідомлення: C 1 = { E (k 1 , m ) , m } ; 3 ∩ C 1 = ∅ .
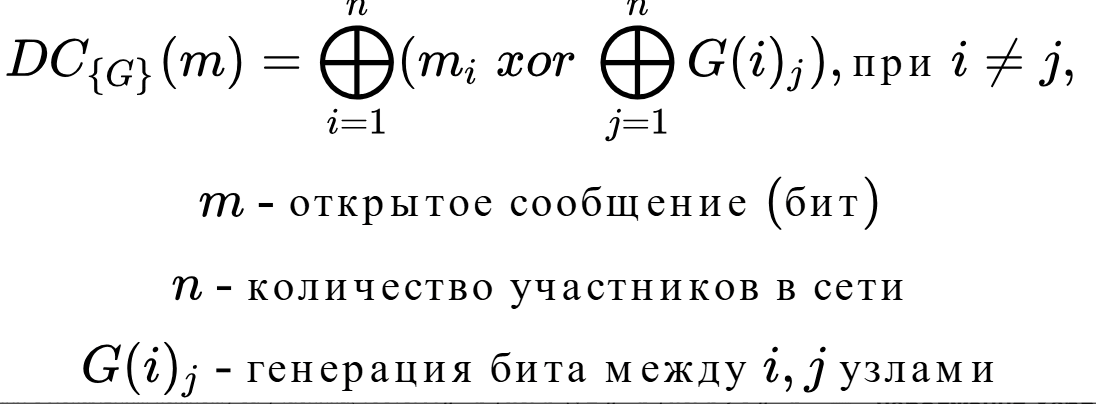
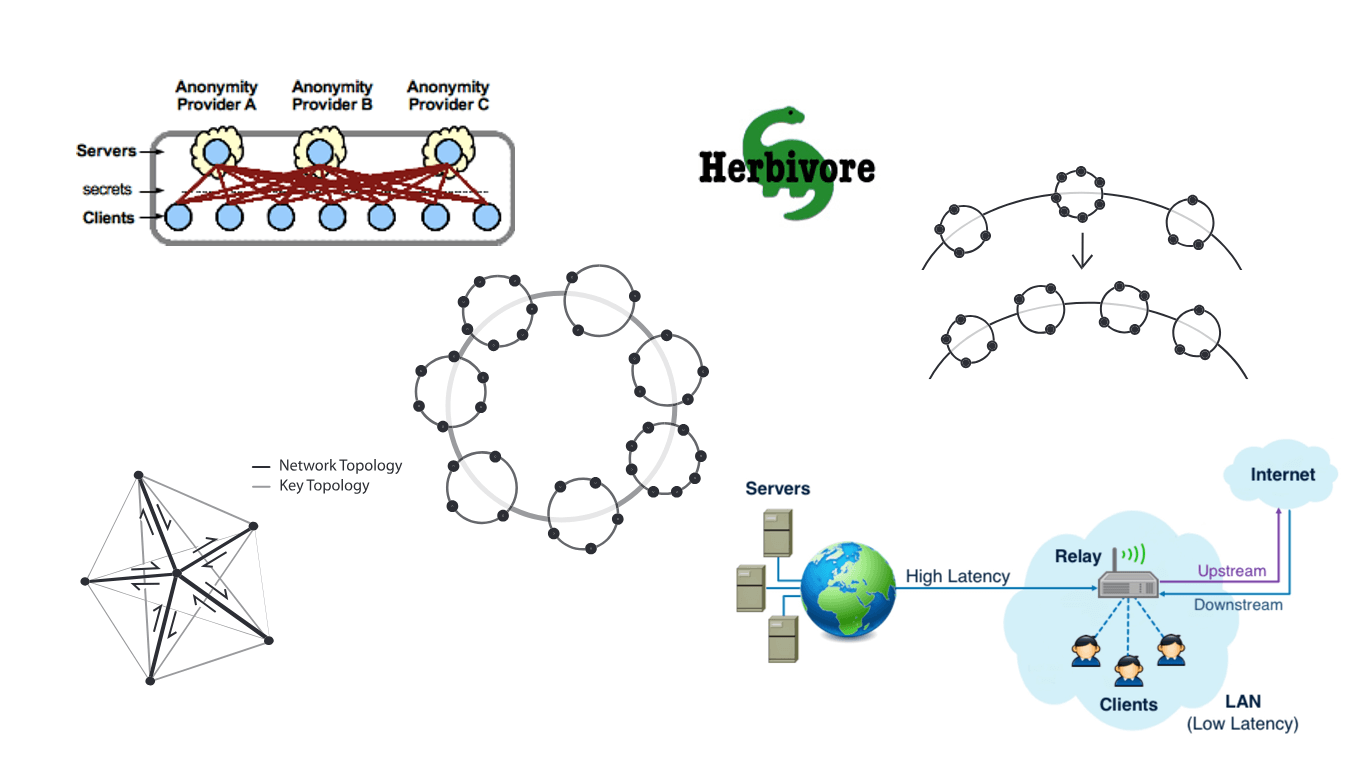
Суть завдання така: є три учасники {A, B, C} . У кожному зв’язку учасників, тобто. {AB, BC, CA} існує генератор псевдовипадкових чисел з однаковим станом (ключом). Передбачається, що генератор, а також ключі є безпечними. Кожен період = T , всі учасники починають генерувати один біт інформації. Внаслідок цього, будь-який з учасників зв’язку, наприклад AB може згенерувати рівно такий же біт, як і інший учасник цього ж зв’язку. Коли всі зв’язки згенерують по одному біту, тобто. AB=b 1 BC=b 2 CA=b 3 – починається перший етап підсумовування.
Перший етап підсумовування є локальним кожному за учасника, тобто. A b = b 1 xor b 3 , B b = b 1 xor b 2 C b = b 2 xor b 3 . Далі йде другий етап підсумовування – глобальний, коли всі учасники обмінюються своїми локальними результатами підсумовування: A b xor B b xor C b . Припустимо, що один із учасників є відправником і він хоче відправити нульовий біт, у такому випадку на першому етапі підсумовування він нічого не робить, результатом A b xor B b xor C b стане m = 0 . Якщо ж відправник, наприклад A, хоче відправити одиничний біт, у такому разі на першому етапі підсумовування він застосовує операцію НЕ (not), результатом not (A b ) xor B b xor C b стане m = 1 . Таким чином, було передано один біт повністю анонімно.
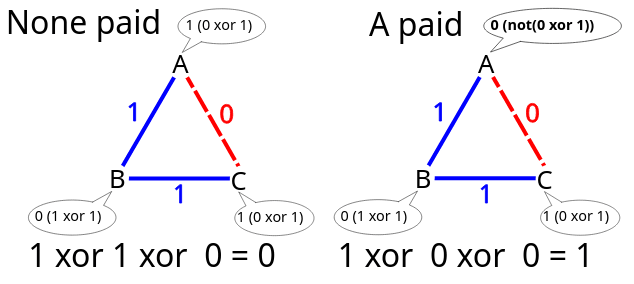
Раніше ми вважали, що головна мета будь-якого завдання анонімізації — приховати зв’язок між відправником і одержувачем. Але хто в системі DC виступає одержувачем? Відповідь проста: уся мережа. У DC-мережах передача має широкомовний характер, тобто всі отримують повідомлення. Приватності при цьому немає, однак зберігається повна анонімність, оскільки невідомо, хто саме є ініціатором передавання, і сам факт зв’язку приховується.
Чому ж анонімність у DC-завданні вважається доведеною? Уявімо трьох учасників — {A, B, C}, де C виступає внутрішнім спостерігачем. Припустімо також, що існує глобальний спостерігач із повним оглядом мережі. Якщо всі спостерігачі активні, тобто мають змогу змінювати дані, затримувати чи блокувати учасників, то будь-яка така дія проти одного вузла паралізує роботу всієї системи.
Якщо C намагатиметься вплинути на обмін, час від часу застосовуючи операцію NOT при обробці бітів, це створить конфлікти, і дані будуть спотворені. Те ж саме станеться, якщо він навмисно змінюватиме біти інших учасників. У підсумку: система або зависає до завершення повного циклу, або передає спотворену інформацію. Проте за будь-якого сценарію особа відправника лишається невідомою. Атаки впливають на стабільність мережі, але не порушують сам принцип анонімності.
Як видно з усього вищеописаного, DC-завдання у своєму чистому виконанні не може похвалитися стабільністю або комфортністю використання. Будь-які активні атаки будуть приводити систему або до deadlock’у доти, доки один з учасників не оклемається, або до втрати інформації, що передається. При збільшенні кількості учасників ймовірність колізій збільшуватиметься, а блокування ставатимуть все більш відчутними. Іншими словами, DC-завдання успадковує проблему масштабованості.
Внаслідок цього, всі нині відомі анонімні мережі, що базуються на DC-задачі насправді не є абсолютно доказованими. тоді як анонімні мережі з урахуванням Proxy-задачи доповнюються модифікаціями поліпшення моделі загроз; мережі на базі DC-задачи, навпаки, доповнюються модифікаціями щодо її погіршення замість комфортності використання.
Проблема з урахуванням черг має теоретично доведеної анонімністю. Така здатна протистояти будь-яким пасивним спостереженням, але на відміну абсолютної анонімності, неспроможна протистояти всім активним діям із боку зловмисників. Через це QB-завдання навмисно обмежує ряд дій, і як наслідок, прикладних використань, щоб знизити або виключити ймовірність активних атак. Як представники даної задачі можна виділити такі мережі, як: Hidden Lake, Micro-Anon .

Суть завдання така: існує черга Q , яка є сховищем згенерованих шифртекстів. Якщо черга колись стає порожньою, то генерується хибний шифртекст E(r,v) (з випадковим ключем + байтами) і відразу поміщається в чергу Q . Якщо з’являється справжнє повідомлення, воно шифрується ключем одержувача E(k,m) і також міститься у чергу Q . Кожен учасник виставляє період генерації = t , тобто. період при якому з черги вирушатиме один шифртекст до мережі.
При цьому, на відміну від DC-завдання, період генерації не є глобальним, а тому може задаватися кожним учасником автономно та без кооперації. Після надсилання шифртексту кожен учасник мережі намагається розшифрувати повідомлення. Якщо воно успішно розшифровується – значить одержувачем є безпосередньо ви, інакше – повідомлення ігнорується.
Пасивні спостерігачі можуть лише зафіксувати сам факт появи повідомлень у мережі, але не здатні визначити — це справжнє повідомлення чи випадковий шум. Особливість QB-моделі в тому, що вона не просто приховує особу відправника, а й узагалі маскує сам факт обміну даними. Це схоже на стеганографію: всередині звичного вигляду системи постійно з’являються зашифровані повідомлення, і майже неможливо відрізнити справжні від фальшивих.
Найбільша загроза для QB-завдання походить від активних атак, які виникають, коли внутрішній спостерігач співпрацює з глобальним. Наприклад, внутрішній учасник надсилає запит, а коли приходить відповідь, передає її глобальному спостерігачу, який намагається вирахувати, звідки саме вона надійшла. У такій ситуації розкривається не відправник, а одержувач. Щоб уникнути цього, система QB передбачає, що обидві сторони вже знають одна одну і не потребують додаткової анонімності у цій частині — так сенс подібної атаки просто зникає.
Існує й інша, більш хитра тактика: стежити за чергою повідомлень у певного користувача. Якщо внутрішній спостерігач буде одночасно надсилати запити кільком людям, а потім помітить, що відповіді від кількох абонентів з’являються із затримкою, це може свідчити про їхній взаємозв’язок. Проте навіть у такому разі можливості атакуючого залишаються обмеженими — це радше натяк на зв’язок, ніж повне розкриття.
На жаль, QB-модель стикається з серйозною проблемою масштабування. Оскільки кожне повідомлення розсилається всім учасникам мережі, це створює значне навантаження на канал зв’язку. Щоб частково вирішити це, іноді використовують підтвердження виконаної роботи (proof-of-work), аби зменшити кількість зайвих повідомлень. Але навіть це не усуває проблему повністю.
Альтернативою є локалізований підхід: замість розсилки повідомлень усім, система створює окрему чергу для кожного співрозмовника. Це дещо нагадує модель кількох черг, проте тут повідомлення надсилаються лише тим, з ким реально ведеться обмін, а не всій мережі. У результаті черги (Q₁, Q₂, …, Qₙ) працюють паралельно.
Такий підхід має три важливих недоліки:
Він вимагає знання IP-адрес співрозмовників. Це не знижує анонімність напряму, але ускладнює інтеграцію з іншими системами.
Глобальний спостерігач зможе бачити, між ким у мережі можливий зв’язок — навіть якщо не знає змісту спілкування.
Такий спосіб приховує сам факт обміну повідомленнями, але не приховує сам зв’язок між двома сторонами, якщо він уже встановлений.
Таким чином, локалізована QB-модель допомагає знизити навантаження, але вимагає компромісів у гнучкості та рівні приватності структури мережі.
Детальніше про QB-завдання можна почитати тут .
Завдання збільшення ентропії є швидше езотеричним, ніж практичним. Хоча вона і відноситься до теоретично доведених завдань, надаючи можливість приховування ініціатора зв’язку, але при цьому вона ж: складно реалізована, сприйнятлива до активних спостережень, в ній присутня безліч підводних каменів, а за комфортністю використання може тягатися з DC-завданням. Але не говорити про неї також не зовсім коректно. Представники такого завдання, зараз часу, відсутні .

EI-завдання вбирає в себе ідеї декількох мереж одночасно: Crowds ( імовірнісна маршрутизація ), Onion-завдання ( цибульна маршрутизація ) і Bitmessage ( заливальна маршрутизація ). Фактично, EI-завдання можна віднести до Onion-like задачі, чи вірніше сказати, вона є деяким витонченим розвитком Onion’а.
Суть завдання така: існує три учасники мережі – {A, B, C} . Припустимо, що A є відправником повідомлення. A генерує з ймовірністю 1/2 шифртекст – або він буде зашифрований один раз ключем одержувача, або він буде зашифрований двічі: спочатку ключем одержувача, а потім ключем маршрутизатора. Передбачається, що двічі зашифрований текст має той самий розмір, що й один раз зашифрований.
Після цього шифртекст вирушає до мережі. На даний момент часу для глобального спостерігача ініціатор зв’язку повністю відомий, не відомий лише одержувач. Якийсь із двох вузлів {B, C } отримує шифртекст і починає або його маршрутизувати далі (здираючи один шар шифрування), або відповідати (генеруючи тим самим заново шифртекст). При цьому генерація відповіді точно також починає дотримуватися імовірнісної логіки 1/2 .
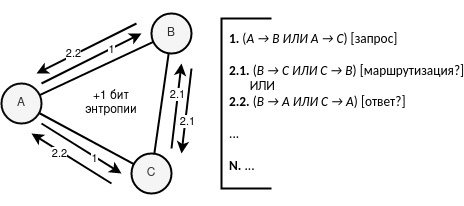
Далі, при відправленні шифртексту з боку одного з учасників {B, C} у спостерігача виникає дилема – або атакуючий починає сприймати акт відправлення як маршрутизацію, або як генерацію нового повідомлення (тобто відповідь). Так як початковий запит був згенерований з ймовірністю 1/2 , то подія = маршрутизація АБО подія = відповідь також містить ймовірність 1/2.
Якщо після події всі подальші дії перериваються – спостерігач вважає, що це була відповідь (бо було зроблено дві дії: запит, відповідь). Якщо ж після події подальші дії продовжуються – у спостерігача знову виникає дилема: або це відповідь (після двох дій: запит, маршрутизація), або новий запит (після двох дій: запит, відповідь). На даному етапі запит не є однозначним, як він був раніше, що свідчить про збільшення ентропії.
Цю ж модель / приклад можна зобразити так:
запит(1)-відповідь(1)-запит(2)-відповідь(2)-... запит(1)-маршрутизація(1)-відповідь(1)-запит(2)-... => запит(1) = запит(1) - певний відправник (ініціатор) відповідь(1) ~ маршрутизація(1) - невизначений одержувач запит(2) ~ відповідь(1) - невизначений відправник (перетин сеансів зв'язку) +1 біт ентропії
Таким чином, EI вимагає, щоб генерація трафіку тривала постійно всіма її учасниками з тією лише метою, щоб породжувати невизначеність між кількома сеансами зв’язку / станами, що перетинаються. Через цю концепцію ми приходимо до нового визначення – потужності спаму . Потужності спаму | S t | – кількість згенерованих унікальних пакетів у системі за певний період часу t скоєний різнорідними (не пов’язаними між собою загальними цілями та інтересами) учасниками мережі.
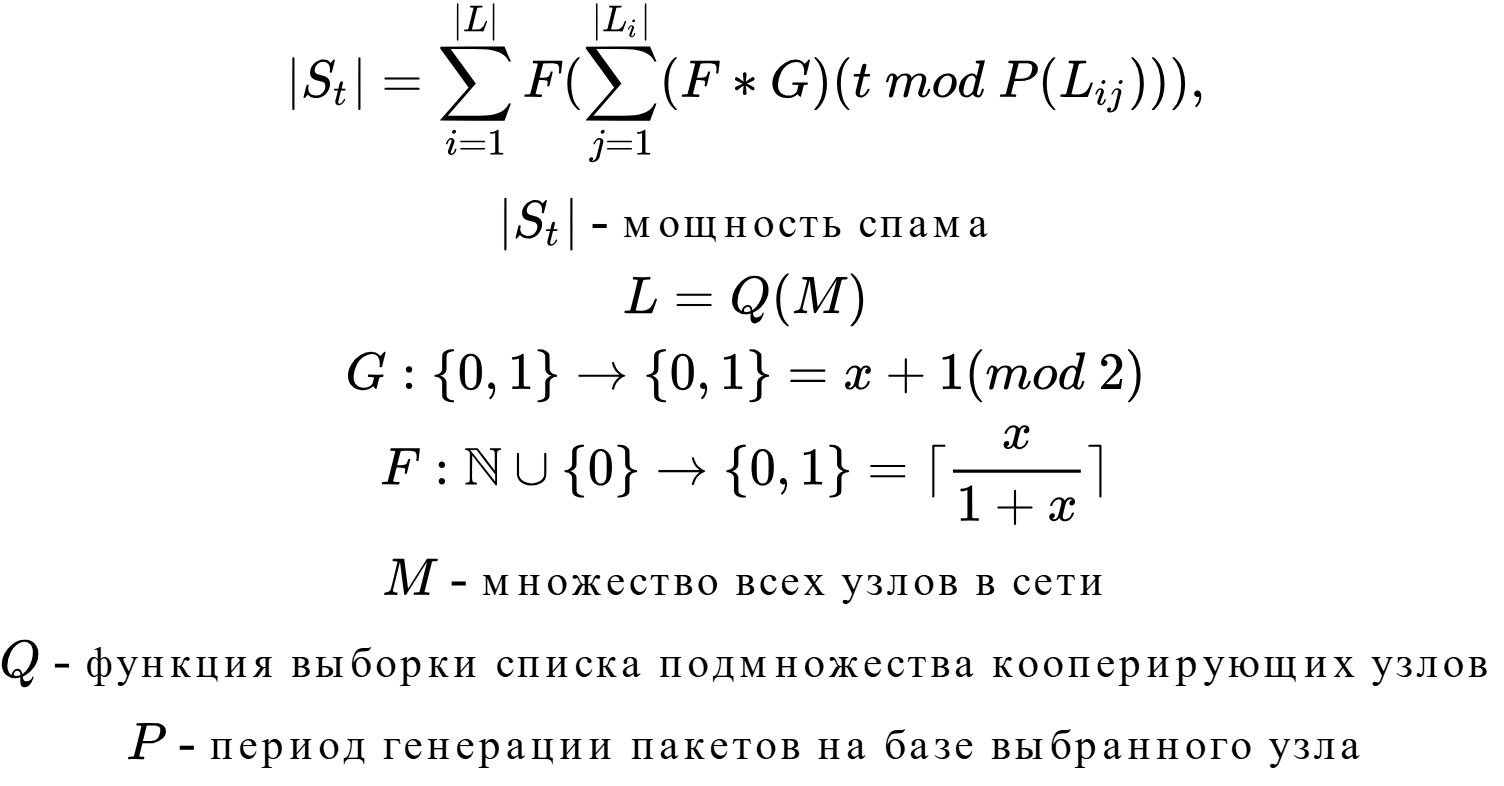
Як говорилося раніше, кожна анонімна мережа повинна базуватися на певному завданні анонімізації, чи то Proxy, Onion, DC, QB, EI чи будь-якій іншій – новій і ще не відкритій. Але це не говорить про те, що в мережі має бути тільки одне завдання анонімізації – цілком можливою подією є використання відразу декількох завдань, одна з яких бере головну роль. У такому разі ми говоримо вже про гібридність.
Так наприклад, анонімними мережами з гібридним завданням цілком можуть вважатися (або вважаються апріорі) наступні представники:
RetroShare (далі RS) із включеною опцією Tor/I2P . У такому випадку, мережа ніяк не виключає базове завдання проксування, а лише додає як новий шар цибульну маршрутизацію. Фактично, дефекти, властиві Proxy-завданню зберігаються тут повною мірою. Тоді може виникнути цілком логічне питання – навіщо додавати Onion-завдання , якщо процедура деанонімізації все одно зводитиметься до Proxy-задачі? Відповідь: щоб приховати мережеві адреси друзів один від одного, ні більше, ні менше. Якщо в ланцюжку маршрутизації будуть кілька кооперуючих спостерігачів, то Onion ніяк не зможе протидіяти цьому, тому що:
![]()
Herbivore . Хоча дана анонімна мережа і є представником DC-завдання , але крім неї має також Proxy-завданням . наступну схему:
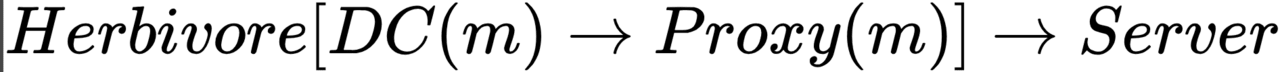
Можна запропонувати і власну гібридну схему на основі QB та Onion задач . Так, наприклад, основна проблема Onion-завдання – це атаки з боку глобального спостерігача. Основною ж проблемою QB-завдання є проблема масштабованості та проблема зв’язності абонентів комунікації. Можна об’єднати обидві ці завдання та скласти, тим самим, нову мережу – Noisy (шумний ). На відміну від класичної QB-завдання, де кожне повідомлення відправляється всім учасникам в мережі, в Noisy – QB-мереж безліч, але в кожній з них всього по одному зв’язку (два учасники). Тобто. QB-завдання є локалізованою, через що проблема масштабованості не проектується на всю систему. Недоліком такої мережі є знижена модель погроз – тепер мережа не намагається приховувати факт комунікації, а обмежується лише прихованням зв’язку між абонентами. Мережа Noisy можна зобразити так:
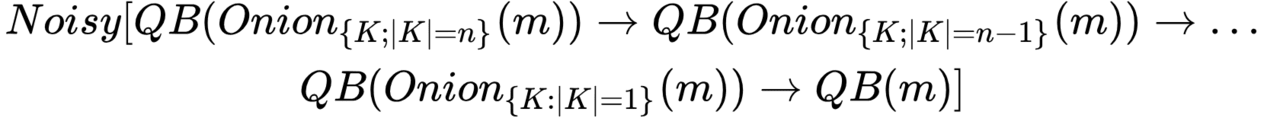
Подібним способом можна сформулювати безліч різноманітних гібридних завдань. Головною умовою тут є правильний розгляд моделі загроз, а також – заради чого взагалі слід поєднувати кілька завдань? Якщо неправильно розрахувати можливості зловмисників/спостерігачів, то може вийти й так, що жодного покращення не станеться. Плюс до всього цього, комбінування завдань у будь-якому випадку погіршуватиме продуктивність як мінімум одного з вибраних завдань. Тому якщо питання створення анонімної мережі лежить не тільки в площині безкомпромісних підходів, то про це теж слід задуматися – чи може бути можливість обмежитися лише одним завданням?
Навіть після того, як ми розібрали всі відомі на сьогодні типи завдань анонімізації, можуть залишатися відкриті питання — особливо щодо того, які мережі дійсно можна вважати анонімними. Найбільше сумнівів зазвичай виникає саме з Proxy- та Onion-моделями, тоді як до DC-, QB- і EI-задач подібних запитань менше, оскільки їхня логіка не так сильно залежить від кількості вузлів.
Наприклад, якщо система використовує лише один Proxy-сервер — чи можна її назвати анонімною? А якщо два або три? Чи можна вважати анонімною систему, побудовану лише на одному VPN-сервісі? А якщо VPN-сервіси використовуються каскадом? З теоретичної точки зору достатньо двох вузлів (проксі чи VPN), щоб забезпечити певний рівень анонімності, згідно з описаними моделями. Але на практиці цього недостатньо.
Річ у тім, що завжди існує ймовірність змови між вузлами, тож просто наявність кількох серверів ще не гарантує анонімність. По-справжньому анонімна мережа повинна постійно змінювати (ротаційно обирати) маршрути та вузли, щоб ніхто не міг заздалегідь знати або вгадати шлях, яким рухається трафік. І саме за цим критерієм багато існуючих систем — наприклад, Freenet, RetroShare або MUTE — не проходять перевірку, бо їхні маршрути фіксовані або будуються за наперед визначеним принципом швидкості, без динамічної зміни.
Отже, не варто автоматично прирівнювати наявність задачі анонімізації до того, що сама мережа вже є анонімною. Анонімною її робить не лише тип маршрутизації, а здатність гнучко й непередбачувано змінювати шлях обміну даними, аби зберегти приватність користувачів.
У підсумку ми класифікували сучасні анонімні мережі за типами криптографічних завдань анонімізації та розглянули особливості кожного з них. Кожна модель — від простого проксі до складних схем DC чи Entropy Increase — має свої переваги, недоліки й сфери застосування.
Ми також побачили, що реальний рівень анонімності залежить не лише від типу завдання, а й від архітектури мережі, обраної моделі загроз та здатності системи протистояти активним чи глобальним спостерігачам. Розуміння цих принципів дозволяє більш усвідомлено обирати безпечні рішення для приватної комунікації.

