
08.04.2025
6 min
890

Do you want to understand how anonymous networks work and how they help you stay private online? In this article, you will find a simple explanation of the five main anonymization protocols: from classic Proxy servers to complex models like Dining Cryptographers or Entropy Increase. We will tell you how networks like Tor, I2P, Freenet work, how they differ from each other, and which ones protect you better from surveillance.

Anonymous networks are a special type of network communications, the main purpose of which is to hide the connection between participants from observers. These observers can be both local and global, and act both passively and actively. The main difficulty of such networks is to find a balance between the level of anonymity and ease of use. That is why there are many different solutions that offer different degrees of protection.
There are many ways to classify anonymous networks. For example, by architecture – decentralized or hybrid, by open source, or by data routing principles. However, one of the clearest and most understandable approaches is the division by the type of anonymization task, that is, by how the network hides information about the connection between the sender and the recipient.
The anonymization task refers to a cryptographic protocol that aims to ensure proven anonymity of subjects in relation to certain groups of observers. Anonymity can mean not only hiding the connection between subscribers (which is a basic aspect), but also masking the initiator or even the fact of communication itself – depending on the specific task. Accordingly, it is the anonymization task that is the basis for the functioning of any anonymous network.
In general, there are currently five anonymization tasks: Proxy, Onion, DC (Dining Cryptographers), QB (Queue Based) and EI (Entropy Increase). In this article, we will try to understand each of them.
The proxying task is one of the simplest anonymization tasks with high performance and good scalability, but most often with a weak threat model. As representatives of this task, we can distinguish such networks as: Crowds, Freenet ( Hyphanet ), GNUnet, RetroShare, MUTE .
The essence of the task is quite simple: to route traffic from point A to point B through many proxy servers that are not connected by common ownership or deanonymization purposes. Each routing must be accompanied by re-encryption of messages with their subsequent relay to the next proxy server.
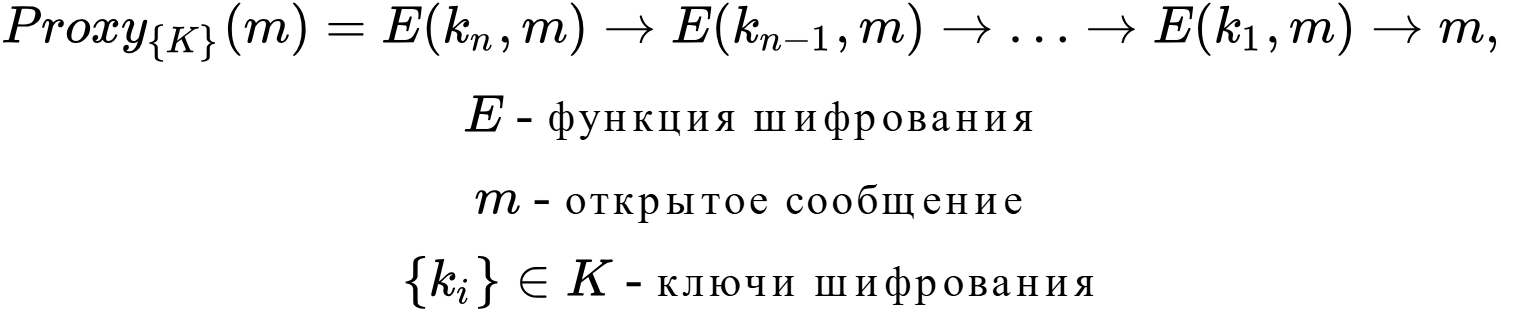
An interesting feature of the Proxy task is its flexibility (or freedom) to modifications, due to which: 1) anonymous networks can differ quite significantly from each other, 2) anonymous networks can be created implicitly, using public proxy servers with encryption such as Tor or I2P, to eliminate the weak threat model from the proxy task.
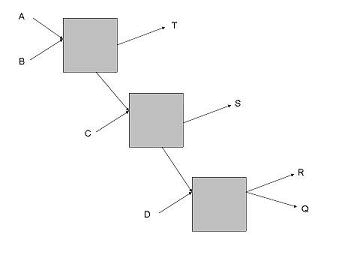
The weakness of the threat model is not related to the proxying task itself, but rather to the lack of additional modifications such as probabilistic routing (Crowds) or false positives (GNUnet). Due to the lack of these, RetroShare recommends using Tor/I2P. For Freenet, it is also recommended to pass traffic through Tor/I2P.
The main disadvantage of the proxying task is its vulnerability to cooperative attacks from the routing nodes. For example, if nodes 1, 3 are cooperative, then they can connect the sender and recipient by comparing the received message. It is worth noting that the second routing node becomes completely useless – it does not affect the quality of anonymity in any way. If we continue in the same way and put another N-th number of nodes between nodes 1, 3, then the quality of anonymity will also not change. As a result, we get the following conclusion:
If there is a system X based on the proxying problem in which there are N nodes, i.e. X = (1, 2, …, N), and nodes i, j, where j > i, are cooperating, then the routing system takes the form X’ = (1, 2, …, i, j, …, N), and as a result | X’ | <= |X| . The system is broken if |X’| becomes equal to the number of cooperating nodes.
The proxy task is the most controversial task in terms of terminology/description, because not every network that uses the proxy task is truly anonymous.
Onion routing is one of the most popular anonymization tasks due to the ability to build a relatively good compromise between the quality of anonymity and comfort of use. As representatives of this task, the following networks can be distinguished: Tor , I2P , Mixminion.
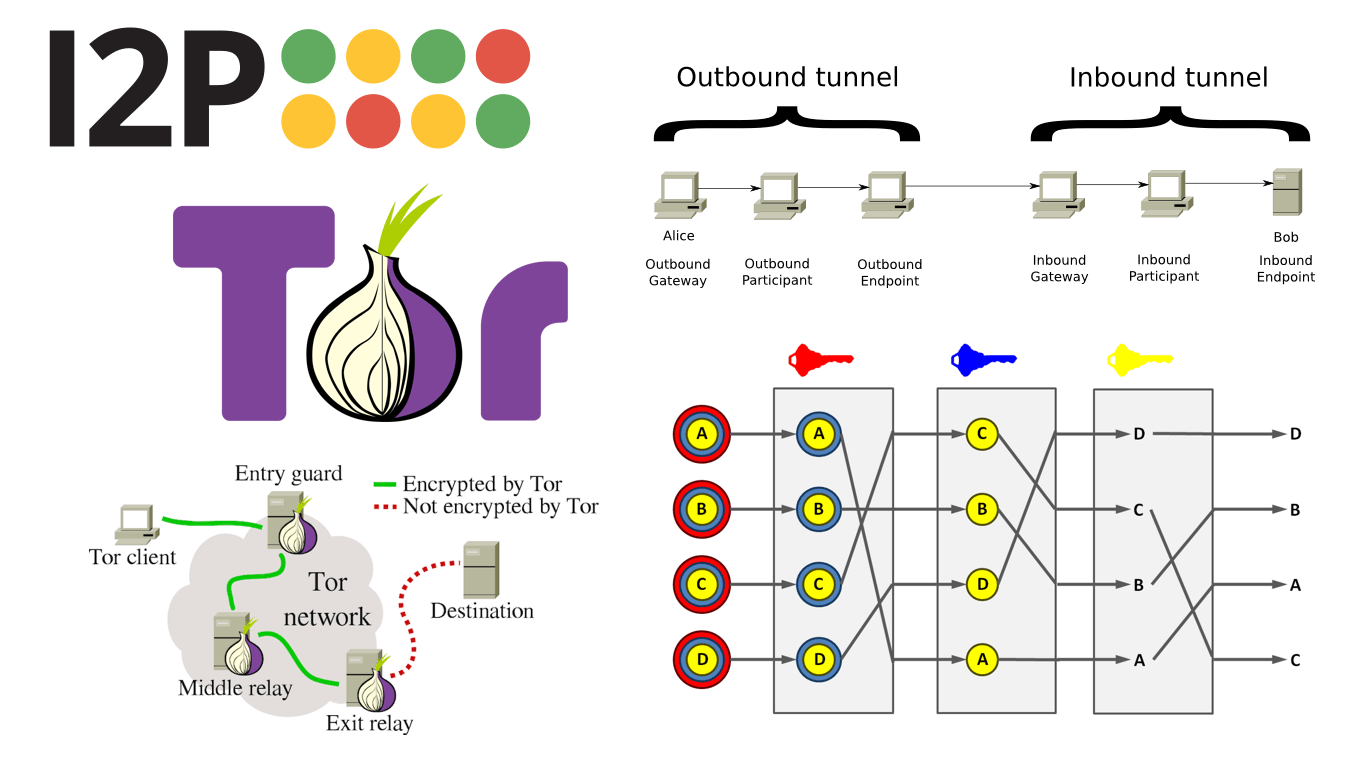
The essence of the task is similar to Proxy, but unlike the latter, there is no message re-encryption procedure, which makes the problem of truncation of the routing chain much more difficult to implement.
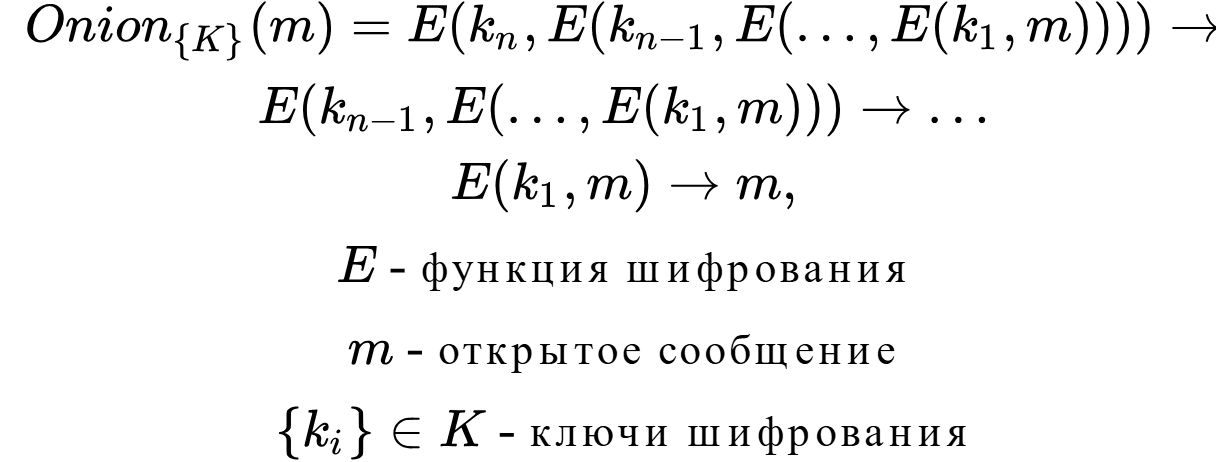
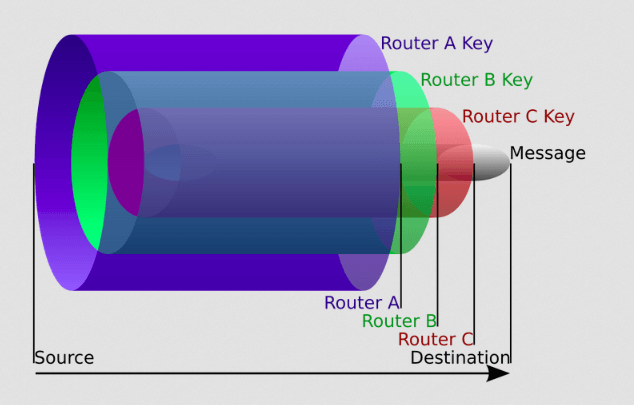
Assuming that nodes 1, 3 cooperate again, node 1 will not be able to uniquely determine that the message was sent by node 3, since it is impossible to link the two routing messages due to their polymorphic (modifiable) nature due to the presence of multiple encryption. This becomes possible provided that the encryption function E and the key k 2 are reliable. As a result, if node 3 has the message: C 3 = { E (k 3 , E (k 2 , E (k 1 , m))), E (k 2 , E (k 1 , m)) }, and node 1 has the message: C 1 = { E (k 1 , m ) , m}; 3 ∩ C 1 = ∅.
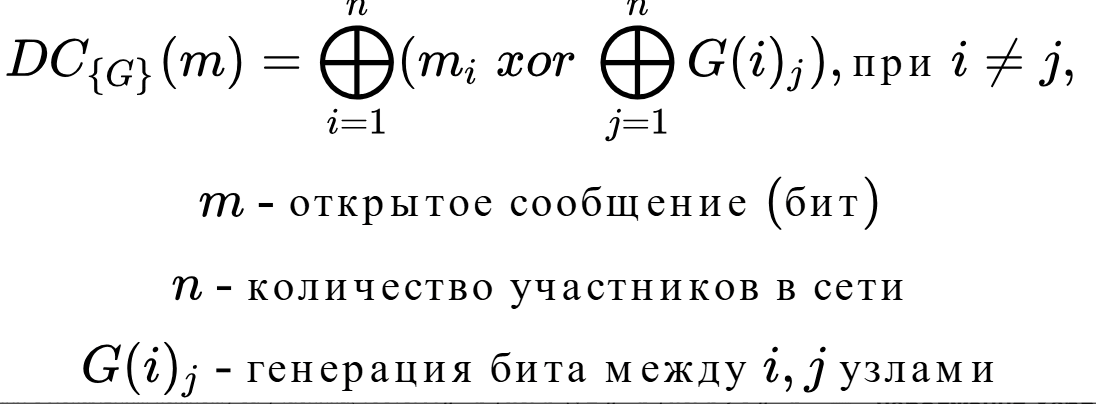
The essence of the problem is as follows: there are three participants {A, B, C}. In each connection of participants, i.e. {AB, BC, CA}, there is a pseudorandom number generator with the same state (key). It is assumed that the generator, as well as the keys, are secure. Each period = T, all participants start generating one bit of information. As a result, any of the participants in the connection, for example AB, can generate exactly the same bit as another participant in the same connection. When all connections generate one bit, i.e. AB=b1 BC=b2 CA=b3, the first stage of summation begins.
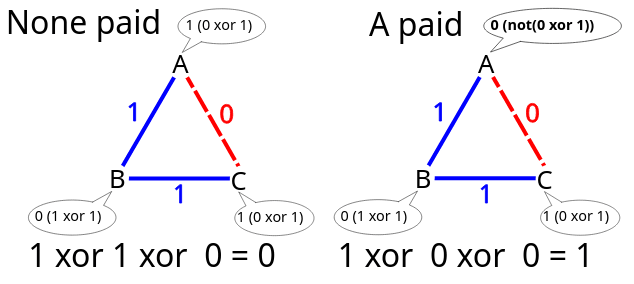
The first stage of summation is local to each participant, i.e. Ab=b1xor b3, Bb=b1xor b2, Cb=b2xor b3. Next comes the second stage of summation – global, when all participants exchange their local summation results: A b xor B b xor C b . Suppose that one of the participants is the sender and he wants to send a zero bit, in this case he does nothing in the first stage of summation, the result of A b xor B b xor C b will be m = 0 . If the sender, for example A, wants to send a single bit, in this case in the first stage of summation he applies the NOT operation, the result of not (A b ) xor B b xor C b will be m = 1 . Thus, one bit was transmitted completely anonymously.
Previously, we believed that the main goal of any anonymization task is to hide the connection between the sender and the recipient. But who in the DC system acts as the recipient? The answer is simple: the entire network. In DC networks, the transmission is broadcast in nature, that is, everyone receives the message. There is no privacy, but complete anonymity is maintained, since it is not known who exactly initiated the transmission, and the very fact of communication is hidden.
Why is anonymity in the DC task considered proven? Let us imagine three participants — {A, B, C}, where C acts as an internal observer. Let us also assume that there is a global observer with a full overview of the network. If all observers are active, that is, they have the ability to change data, delay or block participants, then any such action against one node will paralyze the operation of the entire system.
If C tries to influence the exchange by occasionally NOTing bits, this will create conflicts and the data will be corrupted. The same will happen if he intentionally changes the bits of other participants. The result: the system either freezes before the full cycle is completed, or it transmits corrupted information. However, in either scenario, the identity of the sender remains unknown. Attacks affect the stability of the network, but do not violate the principle of anonymity itself.
As can be seen from all of the above, the DC-task in its pure implementation cannot boast of stability or comfort of use. Any active attacks will lead the system either to a deadlock until one of the participants is killed, or to the loss of transmitted information. With an increase in the number of participants, the probability of collisions will increase, and blocking will become more and more noticeable. In other words, the DC-task inherits the scalability problem.
As a result, all currently known anonymous networks based on the DC-task are actually not completely provable. while anonymous networks taking into account the Proxy-task are supplemented with modifications to improve the threat model; networks based on the DC-task, on the contrary, are supplemented with modifications to worsen it instead of comfort of use.
The queue-based problem has theoretically proven anonymity. It is able to resist any passive observation, but unlike absolute anonymity, it is unable to resist all active actions by attackers. Because of this, the QB problem intentionally limits the number of actions, and as a result, the application uses, in order to reduce or eliminate the probability of active attacks. As representatives of this problem, the following networks can be distinguished, як: Hidden Lake, Micro-Anon .

The essence of the problem is as follows: there is a queue Q, which is a repository of generated ciphertexts. If the queue ever becomes empty, then a false ciphertext E(r,v) (with a random key + bytes) is generated and immediately placed in queue Q. If a real message appears, it is encrypted with the recipient’s key E(k,m) and is also placed in queue Q. Each participant sets the generation period = t, i.e. the period during which one ciphertext will be sent from the queue to the network.
In this case, unlike the DC problem, the generation period is not global, and therefore can be set by each participant autonomously and without cooperation. After sending the ciphertext, each participant in the network tries to decrypt the message. If it is successfully decrypted, then you are the recipient, otherwise, the message is ignored.
Passive observers can only record the very fact of the appearance of messages on the network, but are not able to determine whether it is a real message or random noise. The peculiarity of the QB model is that it not only hides the identity of the sender, but also generally masks the very fact of data exchange. This is similar to steganography: encrypted messages constantly appear inside the usual appearance of the system, and it is almost impossible to distinguish real from fake ones.
The greatest threat to the QB task comes from active attacks that arise when an internal observer cooperates with a global one. For example, an internal participant sends a request, and when the response arrives, it passes it on to the global observer, who tries to calculate where exactly it came from. In such a situation, not the sender, but the recipient is revealed. To avoid this, the QB system assumes that both parties already know each other and do not need additional anonymity in this part – so the point of such an attack simply disappears.
Another, more subtle tactic is to monitor the message queue of a particular user. If an insider sends requests to several people at the same time and then notices that replies from several subscribers appear with a delay, this may indicate that they are interconnected. However, even in this case, the attacker’s options are still limited – it is more of a hint of a connection than a full disclosure.
Unfortunately, the QB model faces a serious scaling problem. Since each message is sent to all participants in the network, this creates a significant load on the communication channel. To partially solve this, proof-of-work is sometimes used to reduce the number of redundant messages. But even this does not completely eliminate the problem.
An alternative is the localized approach: instead of sending messages to everyone, the system creates a separate queue for each interlocutor. This is somewhat similar to the multi-queue model, but here messages are sent only to those with whom the exchange is actually taking place, and not to the entire network. As a result, the queues (Q₁, Q₂, …, Qₙ) operate in parallel.
This approach has three important drawbacks:
It requires knowledge of the IP addresses of the interlocutors. This does not reduce anonymity directly, but it complicates integration with other systems.
A global observer will be able to see who on the network is communicating — even if he does not know the content of the communication.
This method hides the fact of the exchange of messages, but does not hide the connection between the two parties, if it has already been established.
Thus, the localized QB model helps reduce the load, but requires compromises in the flexibility and privacy level of the network structure.
You can read more about QB tasks here.
The task of increasing entropy is more esoteric than practical. Although it belongs to the theoretically proven tasks, providing the possibility of hiding the initiator of the connection, it is also: difficult to implement, susceptible to active observations, it has many pitfalls, and in terms of comfort of use it can compete with the DC-task. But not to talk about it is also not entirely correct. Representatives of such a task, at the moment, are absent.

The EI task incorporates the ideas of several networks at once: Crowds (probabilistic routing), Onion-task (onion routing) and Bitmessage (flooding routing). In fact, the EI task can be attributed to the Onion-like task, or rather, it is some sophisticated development of Onion.
The essence of the task is as follows: there are three network participants – {A, B, C}. Suppose that A is the sender of the message. A generates a ciphertext with probability 1/2 – either it will be encrypted once with the recipient’s key, or it will be encrypted twice: first with the recipient’s key, and then with the router’s key. It is assumed that the twice encrypted text has the same size as the once encrypted text.
After that, the ciphertext is sent to the network. At this point in time, the initiator of the communication is completely known to the global observer, only the recipient is unknown. One of the two nodes {B, C} receives the ciphertext and either starts to route it further (peeling off one layer of encryption) or to respond (thus generating the ciphertext anew). In this case, the response generation also starts to follow the probabilistic logic of 1/2.
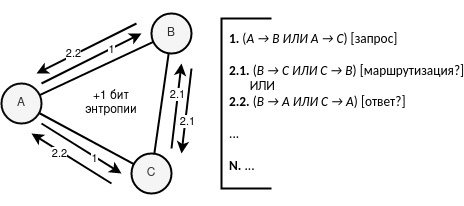
Further, when sending ciphertext from one of the participants {B, C}, the observer faces a dilemma – either the attacker begins to perceive the act of sending as routing, or as the generation of a new message (i.e., a response). Since the initial request was generated with probability 1/2, then event = routing OR event = response also contains probability 1/2.
If after the event all further actions are interrupted – the observer believes that this was a response (because two actions were performed: request, response). If after the event further actions continue – the observer faces a dilemma again: either this is a response (after two actions: request, routing), or a new request (after two actions: request, response). At this stage, the request is not unambiguous, as it was before, which indicates an increase in entropy.
The same model/example can be depicted like this:
запит(1)-відповідь(1)-запит(2)-відповідь(2)-... запит(1)-маршрутизація(1)-відповідь(1)-запит(2)-... => запит(1) = запит(1) - певний відправник (ініціатор) відповідь(1) ~ маршрутизація(1) - невизначений одержувач запит(2) ~ відповідь(1) - невизначений відправник (перетин сеансів зв'язку) +1 біт ентропії
Thus, EI requires that traffic generation be continuous by all its participants for the sole purpose of generating uncertainty between multiple overlapping communication sessions/states. Through this concept, we arrive at a new definition – spam power. Spam power | S t | – the number of unique packets generated in the system over a certain period of time t by heterogeneous (unrelated by common goals and interests) network participants.
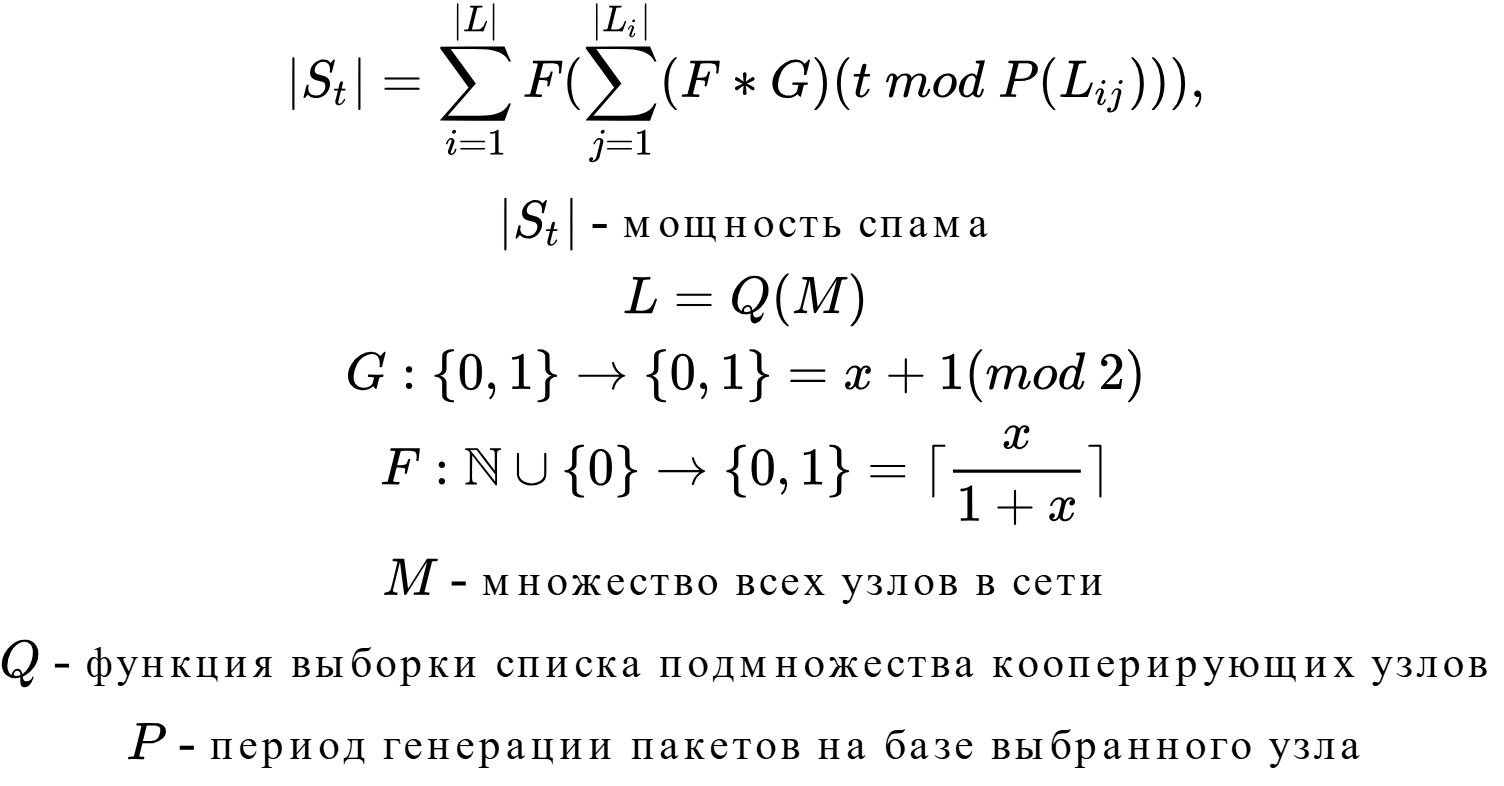
As mentioned earlier, every anonymous network should be based on a certain anonymization task, be it Proxy, Onion, DC, QB, EI or any other – new and not yet open. But this does not mean that there should be only one anonymization task in the network – it is quite possible to use several tasks at once, one of which takes the main role. In this case, we are talking about hybridity.
For example, the following representatives may well be considered (or are considered a priori) anonymous networks with a hybrid task:
RetroShare (hereinafter RS) with the Tor/I2P option enabled. In this case, the network does not exclude the basic proxying task, but only adds onion routing as a new layer. In fact, the defects inherent in the Proxy task are fully preserved here. Then a completely logical question may arise – why add the Onion task, if the deanonymization procedure will still be reduced to the Proxy task? Answer: to hide the network addresses of friends from each other, no more, no less. If there are several cooperating observers in the routing chain, then Onion will not be able to counteract this in any way, because:
![]()
Herbivore. Although this anonymous network is a representative of the DC task, it also has a Proxy task. The following scheme:
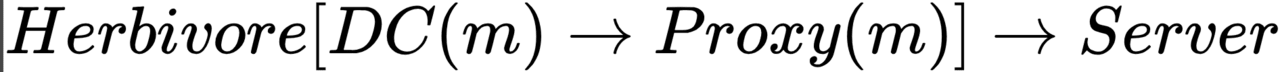
You can also propose your own hybrid scheme based on QB and Onion tasks. For example, the main problem of the Onion task is attacks from a global observer. The main problem of the QB task is the scalability problem and the connectivity problem of communication subscribers. You can combine both of these tasks and thus create a new network – Noisy (noisy). Unlike the classic QB task, where each message is sent to all participants in the network, in Noisy there are many QB networks, but each of them has only one connection (two participants). That is. The QB task is localized, which is why the scalability problem is not projected onto the entire system. The disadvantage of such a network is a reduced threat model – now the network does not try to hide the fact of communication, but is limited only to hiding the connection between subscribers. The Noisy network can be depicted as follows:
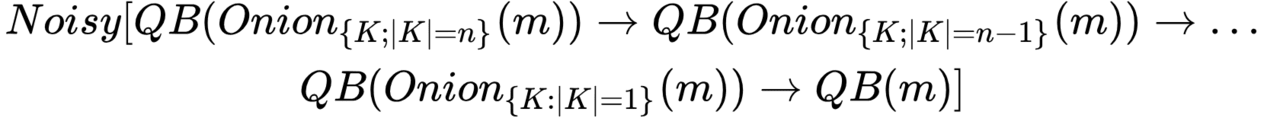
In a similar way, you can formulate a variety of hybrid tasks. The main condition here is the correct consideration of the threat model, and also – why should you combine several tasks at all? If you miscalculate the capabilities of attackers/observers, it may turn out that no improvement will occur. Plus, combining tasks will in any case worsen the performance of at least one of the selected tasks. Therefore, if the issue of creating an anonymous network lies not only in the realm of uncompromising approaches, then this should also be considered – can it be possible to limit yourself to only one task?
Even after we have examined all the types of anonymization tasks known today, open questions may remain – especially regarding which networks can really be considered anonymous. The most doubts usually arise precisely with Proxy and Onion models, while there are fewer such questions with DC, QB and EI tasks, since their logic does not depend so much on the number of nodes.
For example, if a system uses only one Proxy server – can it be called anonymous? What if two or three? Can a system built on only one VPN service be considered anonymous? What if VPN services are used in a cascade? From a theoretical point of view, two nodes (proxy or VPN) are enough to provide a certain level of anonymity, according to the described models. But in practice, this is not enough.
The thing is that there is always a possibility of collusion between nodes, so the mere presence of several servers does not guarantee anonymity. A truly anonymous network must constantly change (rotate) routes and nodes so that no one can know or guess in advance the path that traffic will take. And it is precisely by this criterion that many existing systems – for example, Freenet, RetroShare or MUTE – fail the test, because their routes are fixed or built according to a predetermined speed principle, without dynamic change.
Therefore, one should not automatically equate the presence of the anonymization problem with the fact that the network itself is already anonymous. It is not only the type of routing that makes it anonymous, but the ability to flexibly and unpredictably change the path of data exchange in order to preserve the privacy of users.
As a result, we classified modern anonymous networks by types of cryptographic anonymization tasks and considered the features of each of them. Each model — from a simple proxy to complex DC or Entropy Increase schemes — has its own advantages, disadvantages, and areas of application.
We also saw that the actual level of anonymity depends not only on the type of task, but also on the network architecture, the chosen threat model, and the system’s ability to resist active or global observers. Understanding these principles allows you to more consciously choose secure solutions for private communication.

