
07.05.2023
1 хв
2653

Користуючись інтернетом, всі ми рано чи пізно відкриваємо браузер і відвідуємо безліч сайтів. Кожен з цих сайтів може, а іноді дуже хоче збирати про нас якомога більше інформації. Ця інформація може як і допомагати нам в користуванні тим або іншим ресурсом, так і може бути(можете бути впевнені, точно буде) використана проти нас самих. Ні, ми зараз не говоримо про таємничих хакерів, які так хочуть отримати інформацію саме про тебе, тому що ти така важлива персона і всі за тобою стежать. Здебільшого, методи ідентифікації користувачів використовуються для збору інформації про користувача: хто, де, коли і яку інформацію отримував, з якого пристрою, що саме шукав в інтернеті, як довго знаходився на тій чи іншій сторінці і яким саме блоком інформації цікавився.

Ця інформація в майбутньому використовується щоб показувати біль таргетовану рекламу, підлаштовувати інтерфейс сайту під ваш пристрій або, в деяких випадках, змінювати ціни товару в залежності від регіону, в якому знаходиться користувач. І так, цю інформацію можуть збирати про вас більш зацікавлені особи, ті самі хакери, які хочуть ідентифікувати абстрактного Миколу, який зайшов подивитися на оголених дівчат, або Софію, яка гуглить рецепт полтавських галушок. Хоча, мабуть, ніхто так завзято не полює за інформацією користувачів, як рекламні сервіси. Давайте розбиратися, які саме методи можуть бути використані проти нас і на які хитрощі йдуть ті чи інші сервіси щоб отримати якомога більше інформації, щоб використовувати у власних цілях, або продавати третім сторона
Browser Fingerprint це набір даних, які можна отримати за допомогою різних даних, якими оперує браузер. Чим більше даних можна отримати з браузера, тим точніше можна ідентифікувати унікального користувача. А коли ми знаємо що до нас на сторінку завітав конкретний юзер, ми можемо показувати або рекламувати йому саме ту інформацію або товари які він шукає. Або які ми хочемо йому продати.Спокійно, ідентифікація унікального користувача не означає, що компанія або третя особа буде знати Вашу особисту інформацію у вигляді імені, номеру телефону або імейлу(хоча це і можливо, якщо ви раніше авторизувалися на цьому сервісі). Здебільшого це означає що компанія буде знати що конкретний юзер А завітав на сторінку Б де дивився ціну пачки солі. Тобто ми можемо припустити, що юзеру необхідна сіль. В нас є магазин Х, який також продає сіль і коли юзер А завітає на будь-який інший сайт, який користується нашими послугами(наприклад з показу реклами), ми покажемо йому банер з пропозицією купити пачку солі в магазині Х.

Окей, досить лірики, давайте до деталей. Існує декілька способів отримати інформацію про середовище, з якого користувач завітав до нашого сервісу. Тут все просто: кожен запит містить інформацію про IP адресу клієнта, на яку має бути відправлена відповідь. В нашому випадку це веб сторінка. Існує безліч сервісів в інтернеті для отримання інформації про IP адресу, наприклад https://www.hashemian.com/whoami/ або https://www.whois.com/whois/whoami.com . Деякі сервіси можуть навіть показати геодані, наприклад країну, місто та іноді координати місця, до якого прив’язана конкретна IP адреса.
Ідентифікація з використанням IP це окрема тема, яка вже освітлена на нашому порталі, але для прикладу візьмемо видиму IP адресу одного з користувачів Вікіпедії, який редагував сторінку про крейсер москва(той самий). Цю інформацію можна легко знайти у історії редагувань сторінки. Для ідентифікації можемо використати один із доступних в інтернеті сервісів, наприклад https://iplocation.com/
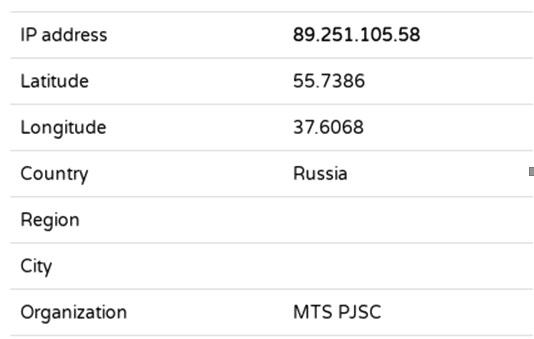
В результаті нескладних маніпуляцій, ми знаємо, що то був користувач з міста москва(як іронічно), провайдер якого приписаний до району якіманка. Так само і власник ресурсу, який ви відвідуєте, може приблизно, або більш менш точно(у випадку публічних мереж), ідентифікувати ваше місцезнаходження.
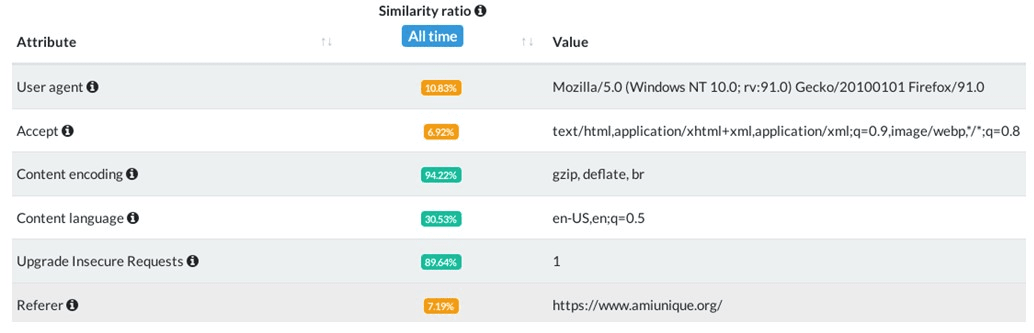
В кожному запиті до сервера містяться так звані Headers – HTTP заголовки, які містять службову інформацію про клієнта, з якого був відправлений запит. Далі приведено перелік даних, які можна отримати з хедерів, які відправляє браузер: Із того, що ми бачимо, адресат запиту вже може дізнатися з якого браузеру ми зайшли, які формати даних ми можемо прийняти. Цікавий параметр тут це Content Languages: він вказує якими мовами користувач відкривав контент в браузері, незважаючи на домен. Тобто, якщо юзер колись читав новини українською і читав наукові статті англійською – хедер буде містити інформацію про обидві мови.
Кожен браузер за замовчуванням підтримує виконання скриптів Javascript і надає доступ до великої кількості властивостей системи. Ці властивості використовуються для правильного відображення сторінки в браузері, а також можуть бути використані(і використовуються) для визначення відбитку браузера(browser fingerprint). Список атрибутів досить великий, рекомендую ознайомитись з ними особисто. Для цього можна використовувати сервіси типу https://www.amiunique.org/ або https://fingerprintjs.github.io/fingerprintjs/
Як ми можемо бачити, власник веб ресурсу, який ми відвідуємо може отримати дуже багато інформації про браузер та пристрій, яким ми користуємось. На основі цього можна сформувати унікальний ідентифікатор користувача(наприклад, fingerprint.js робить це за нас) і прив’язати до нього будь-яку потрібну інформацію, зібрану про нас за час користування тим чи іншим ресурсом. А якщо ми пройшли авторизацію – то і конкретні персональні дані. Є навіть способи поширювати цю інформацію між окремими веб ресурсами за допомогою Supercookies, Zombie cookies, HSTS тощо. Про ці методи ми поговоримо нижче.

До найцікавіших параметрів можна віднести назву та версію браузера, операційну систему, мову системи, поточний час(можливо його треба буде отримати власноруч, але це не є проблемою), плагіни, встановлені в браузері а також багато інформації про сам девайс: операційна система, розмір екрану, розмір оперативної пам’яті, наявність тачскріну, батареї, акселерометра тощо, а також чи має браузер доступ до мікрофону та/або камери.
Стандартний рівень безпеки не вимикає жодних функцій браузеру, тому сховатись це не допоможе. Використовуючи сервіс https://www.amiunique.org подивимось які дані можуть бути отримані:

Ми бачимо, що наш відбиток унікальний. Це означає, що нас можна ідентифікувати як унікального користувача.
Безпечний рівень вимикає Javascript на http ресурсах(без SSL) та обмежує доступ до медіа.

Найбезпечніший рівень працює так само як і безпечний, але відключає виконання Javascript на всіх сторінках.

Як бачимо, сервіс більше не може ідентифікувати нас як унікального користувача, тому що більшість інформації, яка доступна за допомогою Javascript недоступна, а інформація про версію браузера і мову контенту не є достатньою для того, щоб згенерувати унікальний ідентифікатор, тому що цей сервіс відвідало ще 3982 користувача з такими самими параметрами. Проте, в нас навряд вийде комфортно відвідувати веб ресурси з вимкненим Javascript, тому що більшість веб сайтів використовує його для забезпечення необхідного функціоналу сторінки. Але хоча б ми знаємо як сховатися у випадку потреби.
Ще одним способом сховатися від ідентифікації за допомогою Fingerprint є так звані Anti-detect браузери. Основна мета таких браузерів – підміна середовища браузера таким чином, щоб компанія, яка володіє або співпрацює з ресурсом, який ви відкриваєте не мала доступу до вашого реального оточення, натомість, браузер буде повідомляти дані в залежності від профілю, який ми налаштували заздалегідь. Anti-detect браузери використовуються як і просто людьми, які хочуть залишатися максимально анонімними в інтернеті, так і в деяких професіях, наприклад маркетологами, SMM спеціалістами, програмістами, або, наприклад, коли необхідно працювати з декількох облікових записів на одному сервісі.
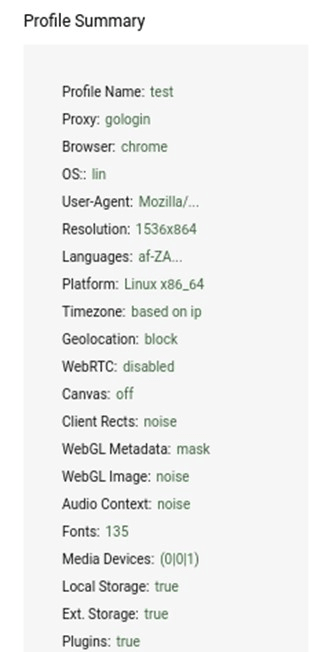
Як правило, антидетект браузери працюють на тих самих платформах що і звичайні популярні: Chromium чи Firefox. Такі браузери часто не безкоштовні, але можна використовувати пробний період для того, щоб ознайомитися з можливостями браузера. Не рекомендується використовувати піратські версії. Давайте розглянемо роботу з антидетект браузером на прикладі GoLogin. За замовчуванням, в GoLogin вже доступний передустановлений профіль. Давайте скористаємось вже знайомим нам Amiunique щоб подивитися деталі про наш відбиток:
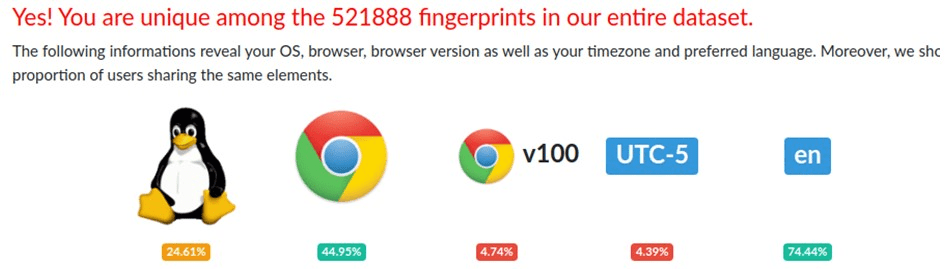
Як бачимо, сервіс ідентифікує нас як користувача Chrome(хоча, говорячи по правді, такого браузера в мене на комп’ютері не встановлено). Основна мова – англійська. При цьому наш fingerprint ідентифікується як унікальний, а тому ніяких підозр, що ми якось уникаємо ідентифікації не буде виявлено. Для порівняння створимо власний профіль і подивимось на результати:
Для того, щоб побачити різницю, я налаштував використання африканського проксі і обрав мову контенту також африканьску ПАР. Дуже рекомендую погратися з налаштуваннями профайлу. там багато цікавих налаштувань, але вони можуть відрізнятися в залежності від того, який антидетект браузер ви обрали, тому затримуватися на цьому не будемо.
Давайте подивимось на наш новий fingerprint:
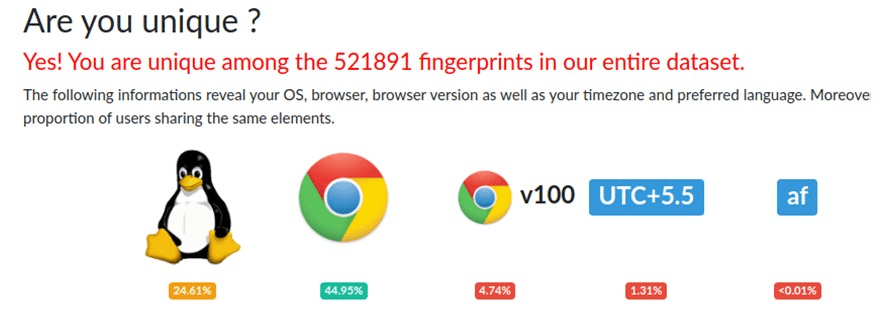
Як бачимо, ми тепер маємо інший часовий пояс і іншу системну мову. Якщо подивитися інші параметри, то і мова контенту в нас також буде та, яку ми обрали при створенні профайлу. І ми все ще маємо унікальний fingerprint. Таким чином, антидетект браузери допомагають нам сховатися від ідентифікації нашого реального середовища, а значить і нас самих.
Browser fingerprint не єдиний спосіб ідентифікувати унікального користувача. Далі розглянемо деякі поширені методи ідентифікації. Тут дуже просто. Cookie це невеликий файл з даними про користувача, який призначений для тимчасового або тривалого зберігання даних про користувача. Це можуть бути як службові дані для відображення сторінки, так і, наприклад, товари, які користувач додав у кошик, або дані про сесію користувача, що надає можливість авторизувати юзера під час наступного відвідування сторінки. Як ми зрозуміли, у файлах Cookie про нас можуть зберігати будь-яку інформацію, яка необхідна компанії або третім особам. Саме тому останнім часом впроваджується контроль за використанням Cookie, попередження про використання сервісом Cookie можна побачити на багатьох веб сайтах. Як правило, Cookies прив’язані до домену сайту, але вони також можуть бути прив’язані до частки цього домену, наприклад до всіх сайтів, які мають в домені .com. У цьому випадку, Cookies будуть доступні всім сайтам, домен яких містить .com. Браузери пропонують нам можливість видаляти Cookies автоматично, або вручну, а також режим інкогніто, який видаляє Cookies після завершення сеансу.

Zombie або Permacookies це різновид Cookie різновид звичайних Cookie з відмінністю у тому, що при видаленні браузером даних Cookie – вони можуть бути відновлені. Для зберігання даних для відновлення може використовуватись localStorage браузера, Коли користувач відкриває сторінку, скріпти знаходять дані для відтворення Cookie і відновлюють їх як звичайні Cookie.
Supercookies не є різновидом Cookie з двох вищезгаданих прикладів. Це обособлена назва підходів та технік, які використовуються для ідентифікації користувача, але, на відміну від звичайних Cookie не зберігаються на самому девайсі або браузері юзера. Такі підходи дуже відрізняються один від одного, то ж розглянемо деякі з них.
UIDH(Unique IDentifier Headers) зе хедер(заголовок), який додає наш провайдер до кожного запиту для ідентифікації пристрою, з якого був надісланий запит. Цей хедер не містить конкретної інформації про девайс і необхідний для того, щоб провайдер знав кому саме необхідно відправити відповідь.
До появи SSL всі запити до сервера не були зашифровані, тому сервер, до якого ми звертаємось, міг легко отримати доступ до цього хедера і, в подальшому, використовувати його як унікальний ідентифікатор користувача.
В цього методу є дві основні переваги:
UIDH присутній в кожному запиті з нашого девайсу, тому третя сторона не залежить від домену чи браузеру, з якого цей запит був надісланий.
UIDH додається до запиту на стороні провайдера, тому користувач не може вплинути на відправку цих даних і взагалі може не знати що цей хедер був доданий до запиту
HSTS-Supercookie з’явилася як слідство використання SSL. Тепер, для кожного сайту наш браузер зберігає певну таблицю доменів, які були відкриті за допомогою https та які за допомогою звичайного http. Наприклад
hackyourmom.com: 1;
Де 1 означає використання https. Якщо сайт був відкритий через http, в таблиці він буде відсутній. Таким чином, ми можемо створити n доменів, які будемо відкривати в довільному порядку за допомогою http та https і таким чином отримаємо таблицю з унікальними даними для кожного користувача. Ці n доменів можна відкрити для користувача декількома способами:
Редиректи перед відображенням основної сторінки. Маючи сучасний інтернет, до двох десятків редиректів можуть бути оброблені без суттєвого уповільнення часу завантаження сторінки.
Розміщення на сторінці зображення розміром в один піксель або яке знаходиться поза фоном сторінки, яка також буде відкрита через декілька редиректів.
Розміщення favicon сторінки на окремому сервісі, який так само буде робити необхідні редиректи. Сучасні браузери вміють кешувати favicon, але і для цього було знайдено рішення: під час останнього редіректу, сервер повертає код 404, що означає що іконка не була знайдена і при наступному відображенні сторінки браузер знов буде відправляти запит на отримання favicon
До речі, на сьогодні метод HSTS використовується для SEO просування веб ресурсів. З огляду на перелічені способи, ми так само не можемо нічого вдіяти з цим видом ідентифікації. Окремі браузери почали робити обмеження на кількість редиректів при завантаженні сторінки. Також, браузери вміють видаляти цю таблицю разом з Cookies.

Цей метод полягає у кодуванні унікального ідентифікатора користувача(отриманий з облікового запису або fingerprint) у одне з зображень, які кешуються браузером. В подальшому, знаходячи це зображення можна отримати ідентифікатор користувача. Сучасні браузери сьогодні намагаються боротися з цим за допомогою розділення доступів до кешу для окремих сторінок, тобто доступ до кешу має лише той сайт, для якого ці зображення були закешовані.
Як ми побачили, існує багато способів ідентифікації нас як унікальних користувачів з метою збору персональних даних, таких як історія відвідувань сторінок, пошуку товарів або інформації, списку пристроїв, якими ми користуємося тощо. Ці дані допомагають компаніям отримати якомога більше інформації про ваші звички, чим ви цікавитесь та яку інформацію шукаєте. Здебільшого, ця інформація використовується для просування реклами послуг або товарів, а також може бути передена третій стороні, яка також зацікавлена в цих даних. Чим більше про вас знають – тим більше всього можна вам продати. Ну і в окремих випадках ця інформація може бути використана проти нас самих.

Існує набір програм, браузерів та розширень для браузерів, які допомагають приховати частину інформації, що використовується для унікальної ідентифікації користувачів. Ну а нам залишається на власний розсуд вирішувати чи треба нам маскуватися від такої ідентифікації.

