
07.05.2023
18 min
2653

When using the Internet, sooner or later, all of us open a browser and visit many sites. Each of these sites can, and sometimes very much wants to, collect as much information about us as possible. This information can both help us in using this or that resource, and can be (you can be sure, it will be) used against us. No, we are not talking about mysterious hackers who want to get information about you because you are such an important person and everyone is watching you. For the most part, user identification methods are used to collect information about the user: who, where, when and what information was received, from which device, what exactly he was looking for on the Internet, how long he was on this or that page and what block of information he was interested in.

This information is used in the future to show targeted advertising, adjust the site interface to your device or, in some cases, change product prices depending on the region in which the user is located. And yes, this information can be collected about you by more interested persons, the same hackers who want to identify the abstract Mykola, who came to look at naked girls, or Sofia, who googles the recipe for Poltava dumplings. Although, apparently, no one hunts for user information as zealously as advertising services. Let’s understand what methods can be used against us and what tricks certain services use to get as much information as possible to use for their own purposes or to sell to third parties
Browser Fingerprint is a set of data that can be obtained using various data that the browser operates on. The more data that can be obtained from a browser, the more precisely a unique user can be identified. And when we know that a specific user visited our page, we can show or advertise to him exactly the information or products he is looking for. Or that we want to sell to him. Don’t worry, the identification of a unique user does not mean that the company or a third party will know your personal information in the form of a name, phone number or email (although it is possible if you have previously authorized yourself on this service). Mostly this means that the company will know that a specific user A visited page B where he looked at the price of a pack of salt. That is, we can assume that the user needs salt. We have store X, which also sells salt, and when user A visits any other site that uses our services (for example, from displaying advertisements), we will show him a banner with an offer to buy a pack of salt in store X.

Okay, enough of the lyrics, let’s get to the details. There are several ways to obtain information about the environment from which the user visited our service. Everything is simple here: each request contains information about the IP address of the client, to which a response should be sent. In our case, this is a web page. There are many services on the Internet for obtaining information about the IP address, for example https://www.hashemian.com/whoami/ or https://www.whois.com/whois/whoami.com. Some services can even show geo-data, such as the country, city, and sometimes the coordinates of the location to which a specific IP address is tied.
Identification using IP is a separate topic that has already been covered on our portal, but as an example, let’s take the visible IP address of one of the Wikipedia users who edited the page about the Moscow cruiser (the same one). This information can be easily found in the page’s edit history. For identification, we can use one of the services available on the Internet, for example https://iplocation.com/
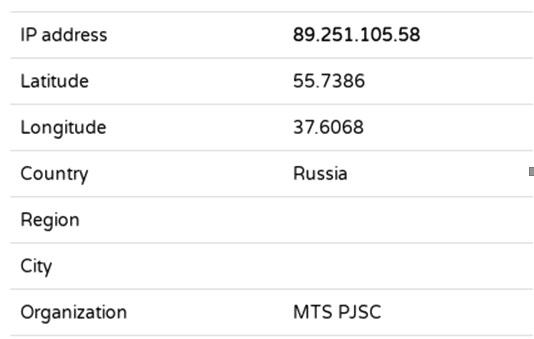
As a result of simple manipulations, we know that it was a user from the city of Moscow (how ironic), whose provider is assigned to the Yakimanka district. In the same way, the owner of the resource you visit can approximately, or more or less precisely (in the case of public networks), identify your location.
Each request to the server contains so-called Headers – HTTP headers that contain service information about the client from which the request was sent. The following is a list of data that can be obtained from the headers sent by the browser: From what we can see, the addressee of the request can already find out from which browser we came, what data formats we can accept. An interesting parameter here is Content Languages: it indicates in which languages the user opened the content in the browser, regardless of the domain. That is, if the user once read news in Ukrainian and read scientific articles in English, the header will contain information about both languages.
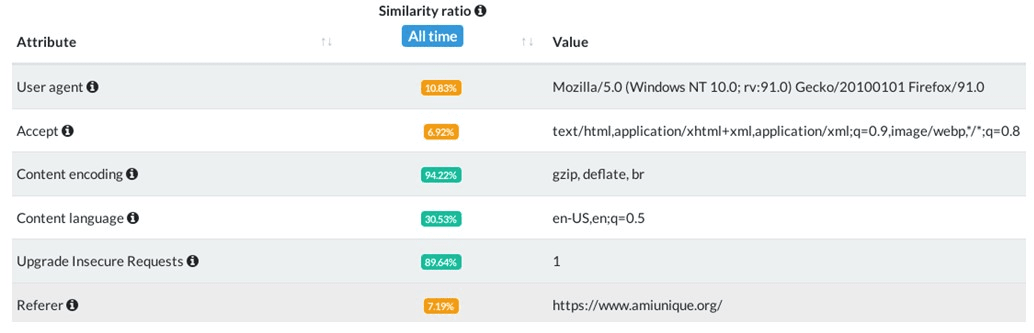
Every browser by default supports the execution of Javascript scripts and provides access to a large number of system properties. These properties are used to correctly display the page in the browser, and can also be used (and are used) to determine the browser fingerprint. The list of attributes is quite large, I recommend that you familiarize yourself with them. For this, you can use services like https://www.amiunique.org/ or https://fingerprintjs.github.io/fingerprintjs/
As we can see, the owner of the web resource we visit can get a lot of information about the browser and the device we use. Based on this, you can create a unique user ID (for example, fingerprint.js does it for us) and attach to it any necessary information collected about us during the use of this or that resource. And if we have passed authorization – then also specific personal data. There are even ways to share this information between individual web resources using Supercookies, Zombie cookies, HSTS, etc. We will talk about these methods below.

The most interesting parameters include the name and version of the browser, operating system, system language, current time (you may have to get it manually, but this is not a problem), plugins installed in the browser, as well as a lot of information about the device itself: operating system, size screen size, RAM size, presence of a touchscreen, battery, accelerometer, etc., and whether the browser has access to a microphone and/or camera.
Standard security doesn’t disable any browser features, so it won’t help you hide. Using the https://www.amiunique.org service, let’s see what data can be obtained:

We see that our imprint is unique. This means that we can be identified as a unique user.
The secure level disables Javascript on http resources (without SSL) and restricts access to media.

The most secure level works the same as secure, but disables Javascript execution on all pages.

As you can see, the service can no longer identify us as a unique user, because most of the information that is available with Javascript is not available, and the information about the browser version and the language of the content is not enough to generate a unique identifier, because this service has been visited by 3982 users with the same parameters. However, it is unlikely that we will be able to comfortably visit web resources with Javascript disabled, because most websites use it to provide the necessary functionality of the page. But at least we know how to hide in case of need.
Another way to hide from fingerprint identification is the so-called Anti-detect browsers. The main purpose of such browsers is to replace the browser environment in such a way that the company that owns or cooperates with the resource that you open does not have access to your real environment, instead, the browser will report data depending on the profile that we have configured in advance. Anti-detect browsers are used both by people who want to remain as anonymous as possible on the Internet, and in some professions, for example, marketers, SMM specialists, programmers, or, for example, when it is necessary to work from several accounts on the same service.
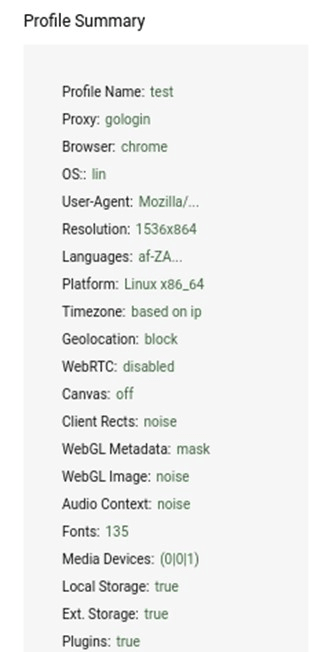
As a rule, anti-detection browsers work on the same platforms as the usual popular ones: Chromium or Firefox. These browsers are often not free, but you can use a trial period to familiarize yourself with the browser’s capabilities. It is not recommended to use pirated versions. Let’s consider the work with browser anti-detection using GoLogin as an example. By default, a pre-installed profile is already available in GoLogin. Let’s use the already familiar Amiunique to see details about our fingerprint:
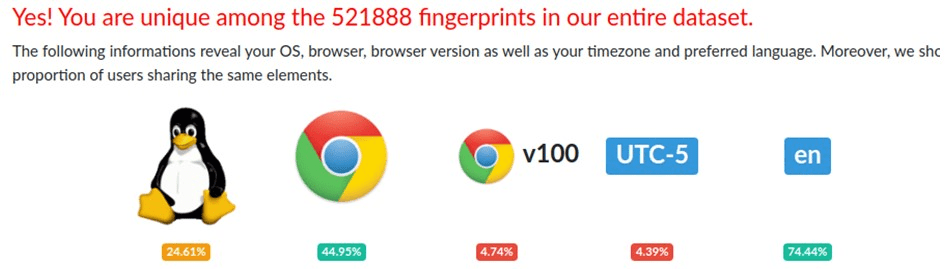
As you can see, the service identifies us as a Chrome user (although, to be honest, I don’t have such a browser installed on my computer). The main language is English. At the same time, our fingerprint is identified as unique, and therefore no suspicions that we somehow avoid identification will be detected. For comparison, let’s create our own profile and look at the results:
In order to see the difference, I configured to use an African proxy and set the content language to also African South Africa. I highly recommend playing around with your profile settings. there are many interesting settings, but they may differ depending on which anti-detection browser you have chosen, so we will not dwell on it.
Let’s take a look at our new fingerprint:
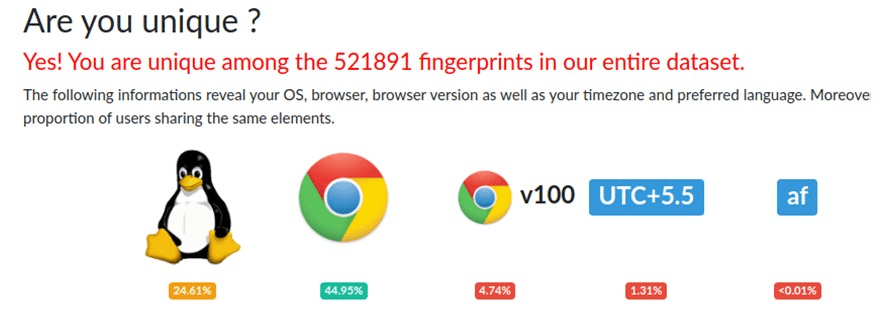
As you can see, we now have a different time zone and a different system language. If you look at other parameters, then the language of the content will also be the one that we chose when creating the profile. And we still have a unique fingerprint. Thus, anti-detection browsers help us to hide from the identification of our real environment, and therefore ourselves.
Browser fingerprint is not the only way to identify a unique user. Next, we will consider some common methods of identification. It’s very simple here. A cookie is a small file with user data that is intended for temporary or long-term storage of user data. These can be both service data for displaying the page, and, for example, products that the user added to the cart, or data about the user’s session, which provides the opportunity to authorize the user during the next visit to the page. As we understood, cookies can store any information about us that is necessary for the company or third parties. That is why control over the use of cookies has recently been implemented, warnings about the use of cookies by the service can be seen on many websites. As a rule, Cookies are bound to the domain of the site, but they can also be bound to a part of this domain, for example to all sites that have a .com domain. In this case, Cookies will be available to all sites whose domain contains .com. Browsers offer us the option to delete cookies automatically or manually, as well as an incognito mode that deletes cookies after the session ends.

Zombie or Permacookies are a type of cookie, a type of regular cookie with the difference that when the browser deletes cookie data, it can be restored. The localStorage of the browser can be used to store the data for recovery. When the user opens the page, the scripts find the data to reproduce the cookie and restore it as a regular cookie.
Supercookies are not a type of cookie from the two examples above. This is a separate name for the approaches and techniques used to identify the user, but, unlike regular cookies, they are not stored on the user’s device or browser. Such approaches are very different from each other, so let’s consider some of them.
UIDH(Unique IDentifier Headers) is a header that our provider adds to each request to identify the device from which the request was sent. This header does not contain specific information about the device and is necessary so that the provider knows to whom it is necessary to send a response.
Before SSL, all requests to the server were unencrypted, so the server we’re contacting could easily access this header and, in the future, use it as a unique user ID.
This method has two main advantages:
UIDH is present in every request from our device, so the third party does not depend on the domain or browser from which this request was sent.
UIDH is added to the request on the provider’s side, so the user cannot influence the sending of this data and may not even know that this header was added to the request
HSTS-Supercookie appeared as a consequence of the use of SSL. Now, for each site, our browser stores a certain table of domains that were opened using https and which were opened using regular http. Example
hackyourmom.com: 1;
Where 1 means use https. If the site was opened via http, it will not be in the table. Thus, we can create n domains that we will open in random order using http and https and thus get a table with unique data for each user. These n domains can be opened for the user in several ways:
Redirects before displaying the main page. With the modern Internet, up to two dozen redirects can be processed without significantly slowing down the page load time.
Placing an image on the page that is one pixel in size or that is outside the background of the page, which will also be opened through multiple redirects.
Placing the favicon of the page on a separate service, which will also make the necessary redirects. Modern browsers are able to cache the favicon, but a solution was found for this as well: during the last redirect, the server returns a 404 code, which means that the icon was not found and the next time the page is displayed, the browser will again send a request to receive the favicon
By the way, today the HSTS method is used for SEO promotion of web resources. In view of the listed methods, we also cannot do anything with this type of identification. Some browsers began to limit the number of redirects when loading a page. Also, browsers are able to delete this table together with Cookies.

This method consists in encoding a unique user ID (obtained from an account or fingerprint) into one of the images cached by the browser. In the future, by finding this image, you can get a user ID. Modern browsers today try to combat this by separating cache accesses for individual pages, meaning that only the site for which those images were cached has access to the cache.
As we have seen, there are many ways to identify us as unique users for the purpose of collecting personal data, such as the history of page visits, product or information searches, list of devices we use, etc. This data helps companies get as much information as possible about your habits, what you are interested in and what information you are looking for. For the most part, this information is used to promote services or products, and may also be transferred to a third party that is also interested in this data. The more people know about you, the more things can be sold to you. And in some cases, this information can be used against us.

There are a number of programs, browsers, and browser extensions that help hide some of the information used to uniquely identify users. Well, it is up to us to decide whether we need to mask ourselves from such identification.

