
28.09.2023
1 хв
1913

Скрейпінг (парсинг) – автоматизоване вилучення даних із веб-додатків. Існує безліч мотивів для парсингу: від хакерів, які намагаються зібрати велику кількість телефонних номерів та адрес електронної пошти для подальшого продажу, до правоохоронних органів, які отримують фотографії та дані користувача з соціальних мереж, щоб допомогти у розкритті справ про зниклих безвісти. Запобігання парсингу – це комплекс заходів, спрямованих на обмеження або контроль доступу до автоматизованого видобування даних з веб-сайтів або інших джерел в Інтернеті. Цей процес може бути важливим для забезпечення безпеки, конфіденційності та нормальної роботи веб-сайтів і онлайн-ресурсів. Основна мета запобігання парсингу полягає в тому, щоб обмежити або контролювати доступ до веб-контенту, щоб запобігти надмірному, незаконному або шкідливому збору інформації.

Запобігання парсингу важливе з кількох причин: Захист конфіденційності: Запобігання парсингу допомагає захистити конфіденційні дані та особисту інформацію, які можуть бути використані для недобросовісних цілей, якщо вони потраплять в руки сторонніх осіб. Захист від надмірного трафіку: Парсинг може призвести до надмірного навантаження на сервери веб-сайту. Запобігання надмірному парсингу допомагає забезпечити доступність сайту для інших користувачів та уникнути відмов в обслуговуванні. Захист від незаконного збору інформації: Деякі парсери можуть використовуватися для незаконного збору даних, таких як контент веб-сайту, електронні адреси або інша інформація. Запобігання цьому допомагає запобігти недозволеному використанню даних. Збереження ресурсів: Запобігання парсингу дозволяє зберігати обчислювальні ресурси сервера та мережі, оскільки парсинг може бути дуже ресурсозатратним процесом. Основні принципи запобігання парсингу включають в себе встановлення правил і обмежень для доступу до вмісту веб-сайту, контроль швидкості запитів, використання захисних технологій, таких як CAPTCHA, та встановлення правил для використання веб-ресурсів. Контроль та обмеження парсингу може забезпечити безпеку, ефективність та стабільність роботи веб-сайту чи онлайн-ресурсу.
У техніці Anti-Scraping є 5 основних принципів:
Вимога аутентифікації;
встановлення обмеження кількості запитів (Rate Limits);
Блокування створення облікових записів;
встановлення обмеження на дані;
Повернення повідомлень про помилки.
У теорії принципи здаються простими, але на практиці вони стають все більш складними в міру збільшення масштабу. Захист програми на сервері з сотнями користувачів і 10 кінцевими точками є справжньою проблемою.
Однак робота з кількома додатками, розподіленими по глобальних центрах обробки даних з мільйонами одночасних користувачів, — це інша справа. Крім того, будь-яке неправильно реалізоване правило може перешкоджати роботі користувача.
Якщо встановити обмеження на кількість запитів, скільки запитів може надіслати користувач за хвилину? Якщо обмеження буде занадто суворим, звичайні користувачі не зможуть використовувати додаток, що неприйнятно для бізнесу. Ми сподіваємося, що глибше вивчення цих тем допоможе зрозуміти, які рішення можуть прагнути запровадити організації та які перешкоди можуть стати на цьому шляху.
Підроблений сайт з публікаціями користувачів буде використовуватися для демонстрації взаємодії між захисниками, що посилюють захист свого додатка, та парсерами, що обходять ці засоби захисту. Всі користувачі та дані були згенеровані випадковим чином. Програма має типові робочі процеси входу в систему, створення облікового запису та відновлення забутого пароля.
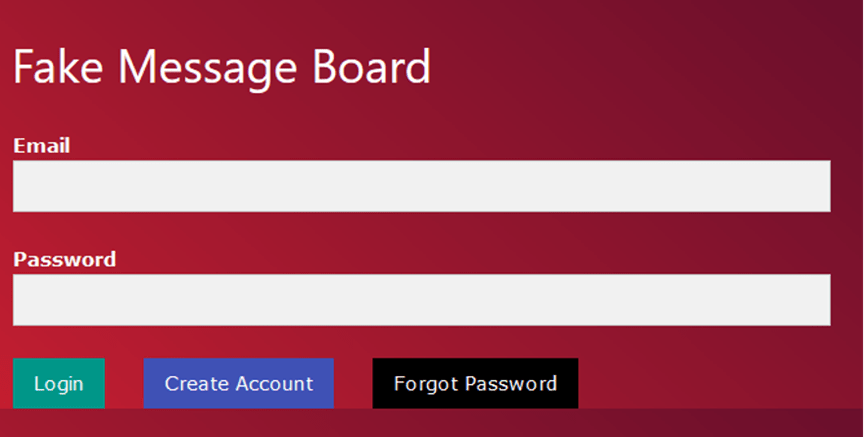
Після входу в програму користувачеві показуються 8 рекомендованих постів. У верхньому правому куті є панель пошуку, яку можна використовувати для пошуку конкретних користувачів.
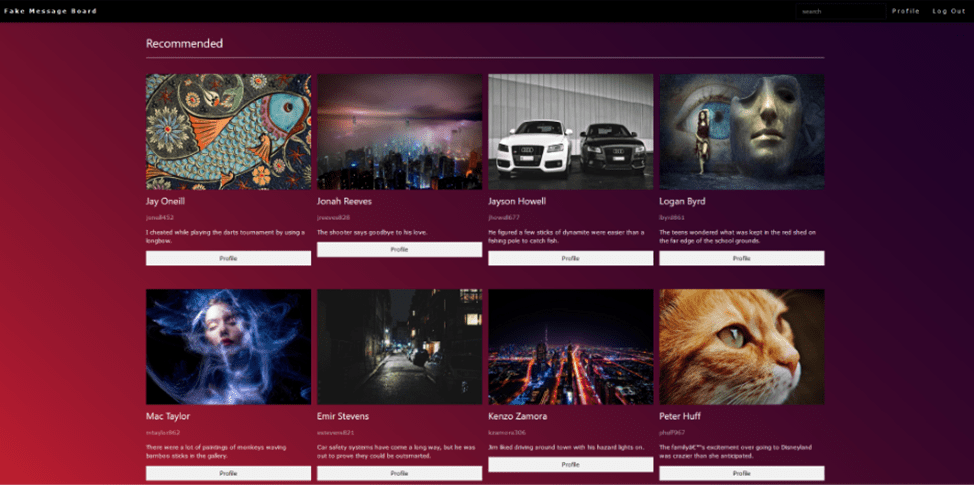
Крім того, у кожного користувача є сторінка профілю з інформацією про нього (ім’я, email-адреса, біографія, дата народження, номер телефону) та його посади (дата, зміст, коментарі).
Спроб обмежити скрейпінг не було. Погляньмо, наскільки складно зібрати всі 500 000 фальшивих користувачів на платформі.
Одним із перших кроків парсера буде проксіювання трафіку для веб-програми за допомогою інструменту Burp Suite. Мета полягає в тому, щоб знайти кінцеві точки, які повертають дані користувача.
У цьому випадку є кілька різних областей програми, на які варто звернути увагу:
Функціональність постів, що рекомендуються;
Панель пошуку;
Сторінки профілю користувача;
Створення облікового запису;
Функція відновлення забутого пароля.
Функціональність постів, що рекомендуються, повертає 8 різних постів при кожному оновленні домашньої сторінки. Як показано нижче, дані користувача вбудовані в HTML.
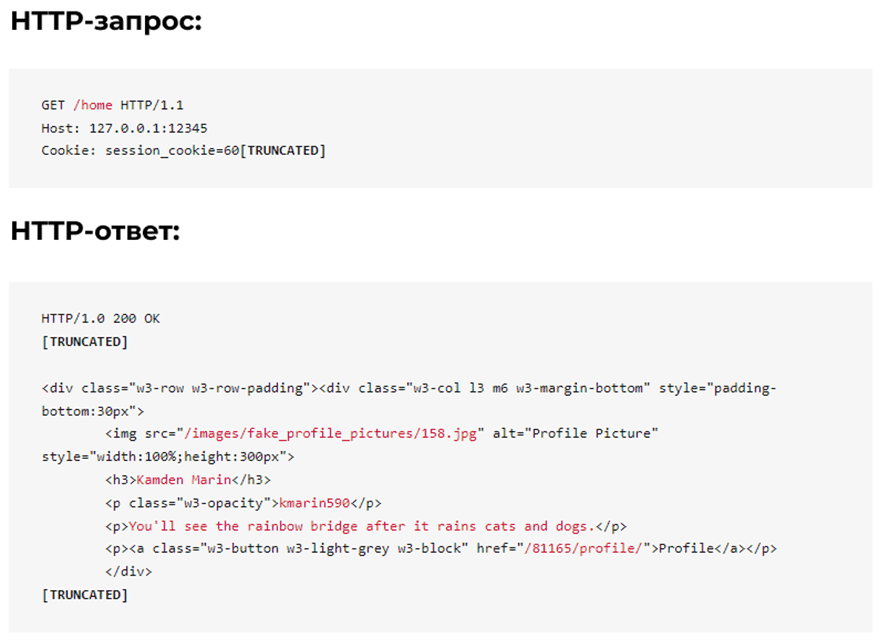
Як парсер, який намагається з’ясувати, на яку кінцеву точку націлитись, ось кілька ключових питань, які ми можемо собі поставити:
Чи потрібна аутентифікація : Так;
Скільки даних повертається : 8 користувачів/відповідь;
Які дані повертаються : ідентифікатор користувача, ім’я, нікнейм, біографія;
Чи легко аналізувати дані : легко, в HTML.
Панель пошуку за промовчанням повертає 8 користувачів, пов’язаних із зазначеним пошуковим запитом. Як показано нижче, пошук має кілька цікавих аспектів.

Однією з перших функцій, яку потрібно перевірити, є необхідність автентифікації. У цьому випадку сервер все ще повертає дані навіть після видалення файлу cookie сеансу користувача. Крім того, кожен параметр повідомляє серверу, скільки даних повертати як потенційну ціль для аналізатора.
Що станеться, якщо ми збільшимо параметр «ліміт» з 8 до більшого значення? Чи є максимальний ліміт? Як показано нижче, якщо змінити параметр «ліміт» на 500 000 і виконати пошук значення «t», в одній відповіді буде повернено 121 069 користувачів.
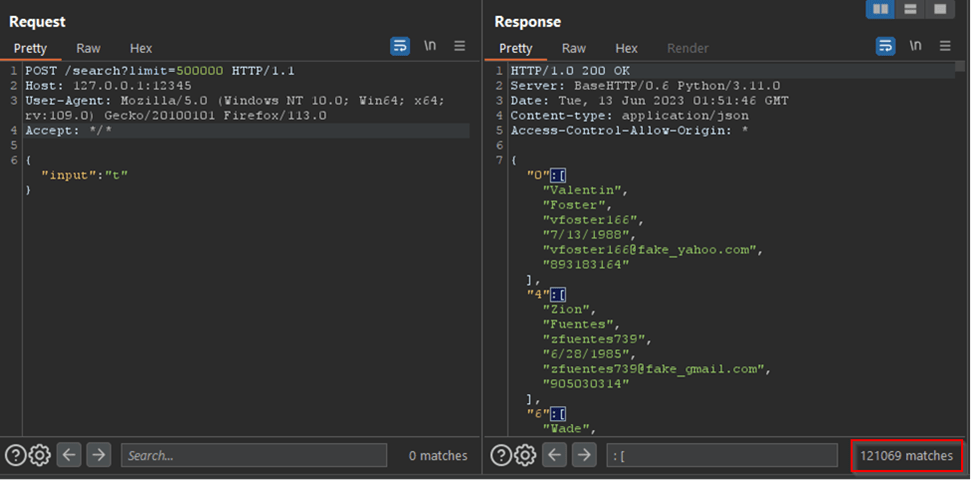
Чи потрібна аутентифікація : Ні;
Скільки даних повертається : без максимального обмеження;
Які дані повертаються : ID користувача, ім’я, нікнейм, день народження, адреса електронної пошти, номер телефону;
Чи легко аналізувати дані : так, це просто JSON;
Відвідування сторінки профілю користувача повертає інформацію про користувача, опубліковані ним посади та коментарі до них.

Оскільки ID користувачів генеруються послідовно, ми можемо почати з ID 1 та збільшувати його до 500 000.
Чи потрібна аутентифікація : Так;
Скільки даних повертається : 1 цільовий користувач і 3 коментатори на пост;
Які дані повертаються : ідентифікатор користувача, ім’я, нікнейм, біографія, дата народження, електронна пошта, номер телефону;
Чи легко аналізувати дані : так, в HTML.
Для створення облікового запису потрібне ім’я користувача, адреса електронної пошти, пароль та номер телефону.

Сервер відповідає повідомленням “success” при отриманні нового імені користувача/електронної пошти/телефону. Що станеться, якщо ім’я користувача/адреса електронної пошти/номер телефону вже використовується користувачем?
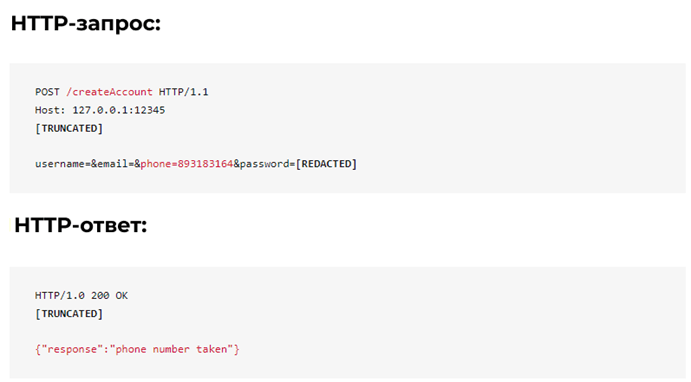
У цьому випадку обліковий запис використовував номер телефону «893183164», а сервер проігнорував цю інформацію. Навіть якщо кінцева точка не повертає дані користувача, дані все одно витікають.
Ця вразливість може бути використана аналізатором, наприклад, для сканування всіх можливих телефонних номерів і збору списку всіх номерів, якими користуються користувачі платформи. Таким чином під час створення облікового запису немає жодного захисту, тому ми можемо створити велику кількість підроблених облікових записів, які можна використовувати для подальшого аналізу.
Функція відновлення забутого пароля вимагає імені користувача та надсилає електронного листа/смс для відновлення, якщо обліковий запис існує.
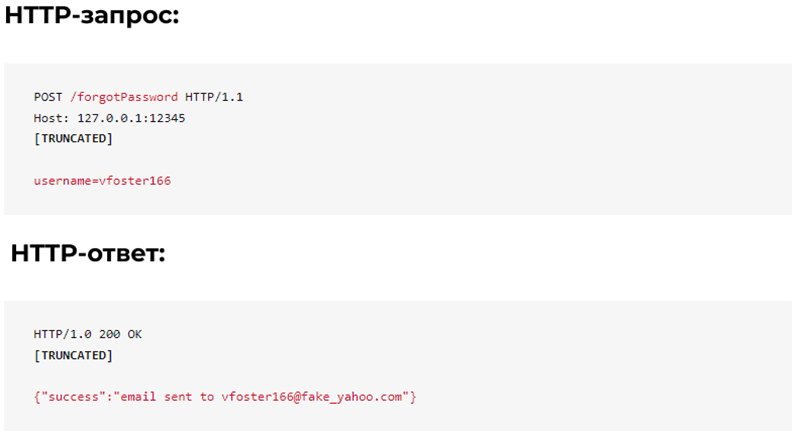
Зауважте, що якщо вказано дійсне ім’я користувача, сервер повертає адресу електронної пошти облікового запису. Така дія може використовуватися парсером для збирання email-адрес шляхом перебору імен користувачів або збору імен користувачів з інших місць програми.
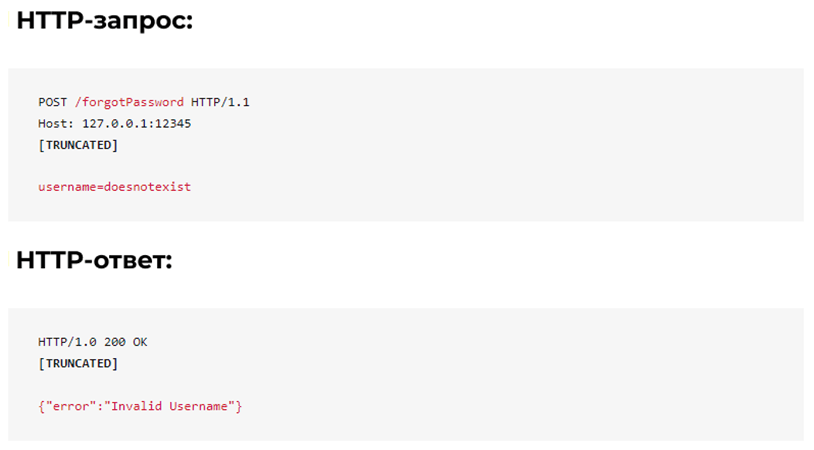
Якщо вказано неправильне ім’я користувача, сервер повертає повідомлення про помилку, як показано нижче:
Давайте подивимося, як підроблений додаток працює з 5 основними принципами захисту від парсингу.
Вимога аутентифікації: Пошук доступний після виходу із системи;
Встановлення обмеження кількості запитів ( Rate Limits): Обмеження запитів відсутнє у всьому додатку;
Блокування створення облікового запису: Блокування немає;
Встановлення обмеження на дані: Пошук приймає параметр «limit» без максимального примусового значення;
Повернення повідомлень про помилки: Функції створення облікового запису та відновлення пароля забезпечують витік інформації через повідомлення про помилки. За відсутності захисту парсинг всіх 500 000 підроблених користувачів програми можна легко виконати за лічені хвилини за допомогою кількох запитів.

