
28.09.2023
12 min
1913

Scraping (parsing) – automated extraction of data from web applications. There are many motivations for parsing, from hackers trying to harvest large numbers of phone numbers and email addresses for resale, to law enforcement obtaining photos and user data from social media to help solve missing persons cases. Parsing prevention is a set of measures aimed at limiting or controlling access to automated data extraction from websites or other sources on the Internet. This process can be important to ensure the security, privacy and normal operation of websites and online resources. The primary purpose of anti-parsing is to limit or control access to web content to prevent excessive, illegal or harmful information collection.

Anti-parsing is important for several reasons: Protecting privacy: Anti-parsing helps protect sensitive data and personal information that could be used for malicious purposes if it falls into the wrong hands. Protection against excessive traffic: Parsing can overload website servers. Preventing excessive parsing helps to ensure the site is accessible to other users and avoid service failures. Protection against illegal information collection: Some parsers can be used to illegally collect data such as website content, email addresses or other information. Preventing this helps prevent unauthorized use of data. Resource conservation: Preventing parsing saves server and network computing resources, as parsing can be a very resource-intensive process. Basic principles to prevent parsing include setting rules and restrictions for accessing website content, controlling the speed of requests, using security technologies such as CAPTCHA, and setting rules for the use of web resources. Controlling and restricting parsing can ensure the security, efficiency and stability of a website or online resource.
There are 5 main principles in the Anti-Scraping technique:
Authentication requirement;
setting a limit on the number of requests (Rate Limits);
Blocking the creation of accounts;
setting a data limit;
Return error messages.
The principles seem simple in theory, but in practice they become increasingly complex as the scale increases. Securing an application on a server with hundreds of users and 10 endpoints is a real challenge.
However, dealing with multiple applications distributed across global data centers with millions of concurrent users is a different matter. In addition, any incorrectly implemented rule can interfere with the user’s work.
If you set a limit on the number of requests, how many requests can a user send per minute? If the restriction is too strict, ordinary users will not be able to use the application, which is not acceptable for business. We hope that a deeper study of these topics will help to understand what solutions organizations may seek to implement and what obstacles may stand in the way.
A fake site with user posts will be used to demonstrate the interaction between defenders hardening their application and parsers bypassing these protections. All users and data were randomly generated. The program has typical login, account creation and forgotten password recovery workflows.
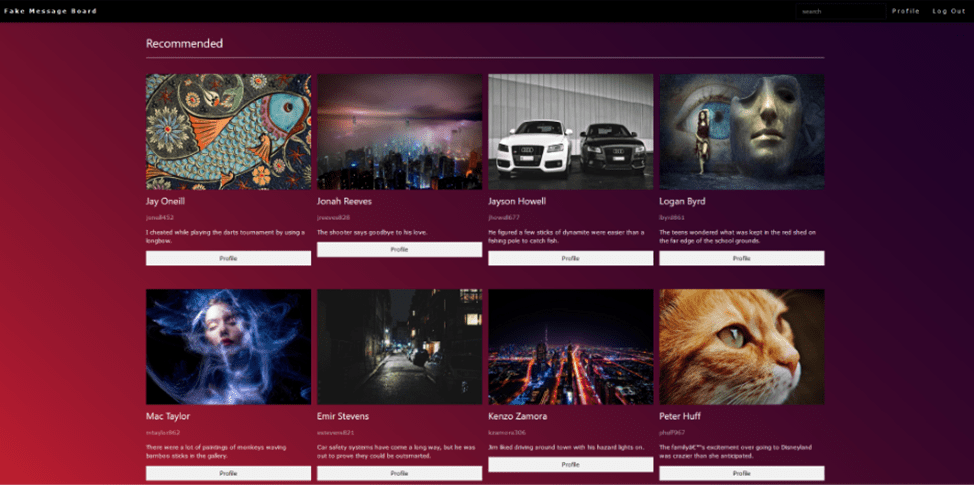
After entering the program, the user is shown 8 recommended posts. There is a search bar in the upper right corner that you can use to search for specific users.
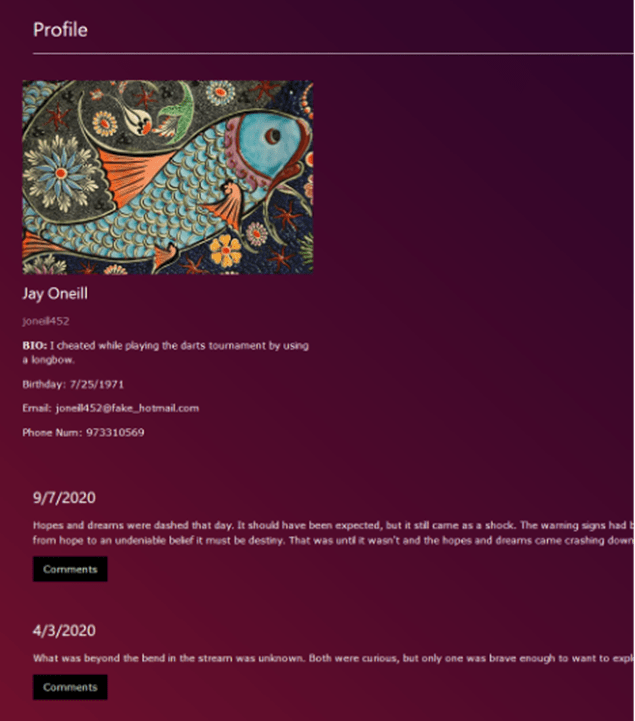
In addition, each user has a profile page with information about him (name, email address, biography, date of birth, phone number) and his position (date, content, comments).
There were no attempts to limit scraping. Let’s see how difficult it is to collect all 500,000 fake users on the platform.
One of the parser’s first steps will be to proxy the traffic for the web application using the Burp Suite tool. The goal is to find endpoints that return user data.
In this case, there are a few different areas of the program to look out for:
Functionality of recommended posts;
search bar;
User profile pages;
Creating an account;
Forgotten password recovery function.
The featured posts functionality returns 8 different posts each time the home page is refreshed. As shown below, user data is embedded in HTML.
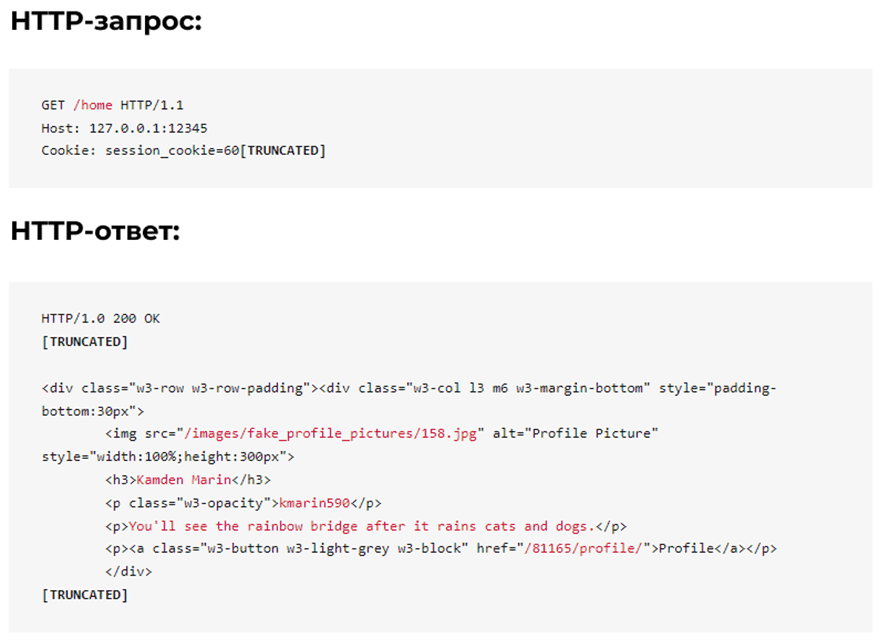
As a parser trying to figure out which endpoint to target, here are some key questions we can ask ourselves:
Whether authentication is required: Yes;
How much data is returned: 8 users/response;
What data is returned: user ID, name, nickname, bio;
Is it easy to parse the data: Easy, in HTML.
By default, the search bar returns 8 users associated with the specified search query. As shown below, the search has several interesting aspects.

One of the first features to check is the need for authentication. In this case, the server still returns data even after deleting the user’s session cookie. Additionally, each parameter tells the server how much data to return as a potential target for the parser.
What happens if we increase the ‘limit’ parameter from 8 to a higher value? Is there a maximum limit? As shown below, if you change the ‘limit’ parameter to 500,000 and search for ‘t’, 121,069 users will be returned in one response.
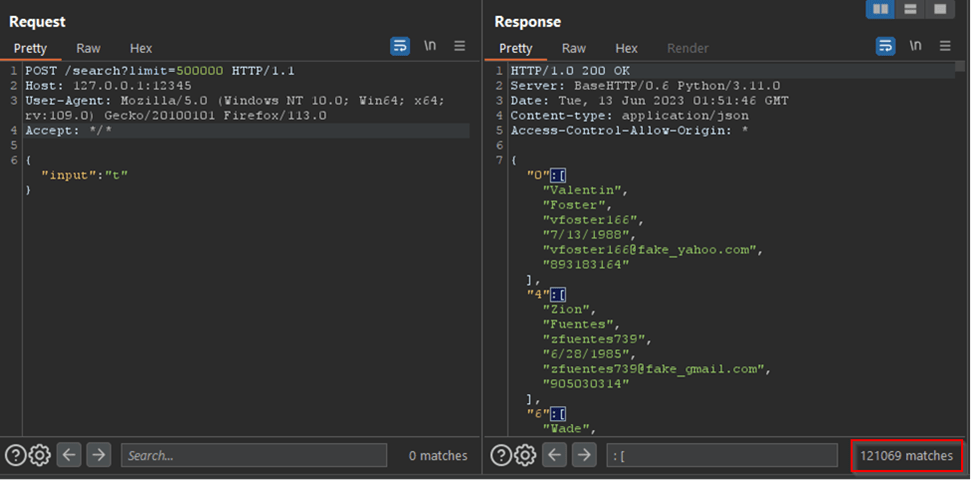
Whether authentication is required: No;
How much data is returned: No maximum limit;
What data is returned: User ID, name, nickname, birthday, email address, phone number;
Is the data easy to parse: Yes, it’s just JSON;
Visiting a user’s profile page returns information about the user, their posted posts, and their comments.

Since user IDs are generated sequentially, we can start with ID 1 and increase it to 500,000.
Whether authentication is required: Yes;
How much data is returned: 1 target user and 3 commenters per post;
What data is returned: user ID, name, nickname, bio, date of birth, email, phone number;
Is it easy to parse the data: Yes, in HTML.
To create an account, you need a username, email address, password and phone number.

The server responds with a “success” message when it receives a new username/email/phone number. What if the username/email address/phone number is already in use by a user?
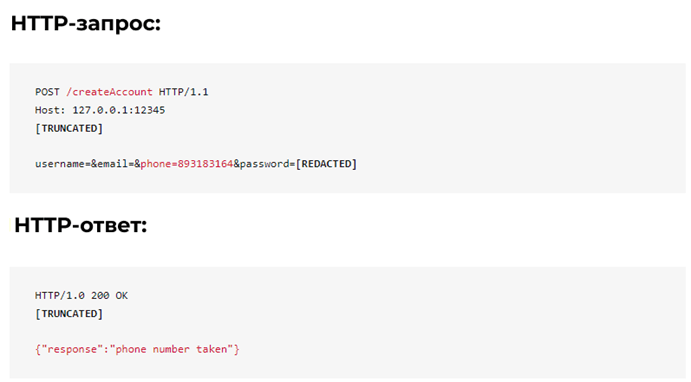
In this case, the account used the phone number “893183164” and the server ignored this information. Even if the endpoint does not return user data, the data is still leaked.
This vulnerability can be used by an analyzer, for example, to scan all possible phone numbers and collect a list of all numbers used by users of the platform. In this way, there is no protection during account creation, so we can create a large number of fake accounts that can be used for further analysis.
The Forgotten Password Recovery feature requires a username and sends a recovery email/SMS if the account exists.
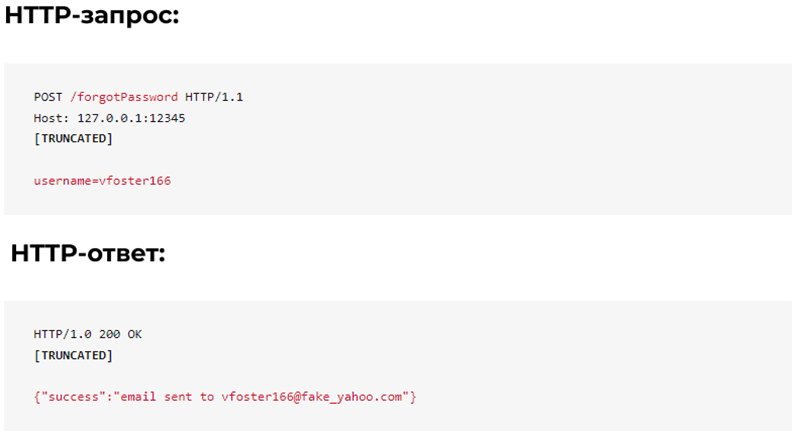
Note that if a valid username is provided, the server returns the email address of the account. This action can be used by the parser to collect email addresses by traversing usernames or collecting usernames from elsewhere in the application.
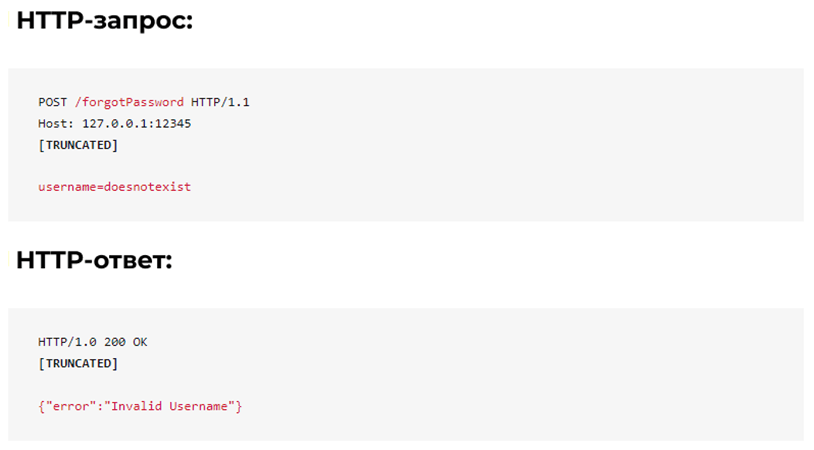
If an invalid username is specified, the server returns an error message as shown below:
Let’s see how a fake app works with 5 basic principles of parsing protection.
Authentication requirement: Search is available after logging out;
Setting a limit on the number of requests ( Rate Limits): There is no request limit in the entire application;
Account creation blocking: No blocking;
Setting a data limit: Search accepts a “limit” parameter with no maximum forced value;
Return error messages: The account creation and password recovery functions ensure information leakage through error messages. In the absence of protection, parsing all 500,000 fake users of the app can easily be done in minutes with a few queries.

