
01.05.2023
2 хв
2552

У цій статті ви дізнаєтеся про передові методи та інструменти для забезпечення анонімності в інтернеті, включаючи детальний огляд анонімних мереж, таких як Tor та Hidden Lake, та їх роль у захисті вашої особистої інформації від небажаної уваги.

Хоча збереження конфіденційності даних, що передаються, є важливим і досить складним завданням за наявності глобальних спостерігачів і повсюдної централізованої інфраструктури, завдання збереження конфіденційності метаданих, таких як адреси абонентських мереж і інформація про частоту зв’язку, є ще більш проблематичним. Це завдання можна назвати завданням анонімності.
Анонімність означає, що зв’язок між відправником і одержувачем завжди прихований в будь-якій інформаційній системі. Під зв’язком слід розуміти як явний випадок надсилання інформації, так і неявний випадок її отримання. Спостерігачі трафіку аналогічно стають одержувачами факту появи інформації і починають формувати зв’язок з відправником.
Варто також уточнити, що відправник і одержувач можуть бути в однині або множині, а взаємна анонімність є необов’язковим параметром. Наприклад, цілком можливо, що два суб’єкти можуть бути взаємно ідентифіковані і спілкуватися один з одним через анонімну мережу. У такій моделі вони не є анонімними один для одного, але існування анонімної мережі обмежує можливості зовнішніх або внутрішніх сторонніх спостерігачів аналізувати їхню поведінку.
І навпаки, якщо відправник і одержувач анонімні один для одного, але їхні комунікації не приховані від спостерігача, таку систему можна вважати квазіанонімною. Прикладом такого явища є класична централізована соціальна мережа. Ця мережа не розкриває інформацію про своїх абонентів іншим абонентам, але в той же час повністю ідентифікує кожного абонента.
Деякі системи для створення анонімності потребують елементу відносної деанонімізації. Цей елемент відіграє роль довіри, коли вся комунікація або тільки її частина деанонімізується для обмеженої кількості людей. Різниця між відносною деанонімізацією та абсолютною деанонімізацією залежить від обсягу кола спілкування конкретної особи.
Наприклад, людина, яка скоїла злочин, стає анонімним джерелом інформації. З іншого боку, суспільство стає одержувачем цієї інформації. Сам факт отримання інформації може бути побічним ефектом дій правопорушника. У злочинця може бути спільник, який є одним із реципієнтів у суспільстві. Метою співучасника може бути передача фактичної мети (повідомлення) злочинця. У цій парадигмі злочинець не є анонімним для співучасника, але демонструє відносну неанонімність, запобігаючи абсолютній неанонімності в контексті наявності конкретного повідомлення.
Формування анонімності в мережевому просторі на початкових етапах мало чим відрізняється від описаних вище способів анонімізації в реальному матеріальному світі. Анонімність учасників також формується за рахунок часткової наявності вузлів відносного розміру, які деанонімізують відправників. На ранніх стадіях такі вузли є централізованими сервісами, на більш пізніх – це вже проксі-сервіси або VPN-сервіси.
Однак, порівняно з розглянутими раніше випадками, особливістю мережевої анонімізації є існування прихованих (анонімних) мереж, тобто потенціал для більш ефективного створення сприятливих умов середовища при ініціалізації та підтримці заданого рівня анонімності. Мережева анонімність в основному базується на криптографічних примітивах, і в багатьох випадках ризик перетворення відносної анонімності в абсолютну можна контролювати шляхом побудови N-го проміжного вузла в ланцюжку маршрутизації.
Мережева анонімність, будучи підмножиною анонімності, також призводить до появи більш конкретних моделей загроз та завдань:
Приховування мережної адреси одержувача часто є однією з форм анонімності для супутнього обходу блокувань з боку провайдера зв’язку,
Приховування адреси відправника часто є однією з форм анонімності для супутнього обходу блокувань з боку сервісу зв’язку,
Держави стають зовнішніми, і найчастіше глобальними спостерігачами (одержувачами) всього трафіку, що генерується,
З метою протидії глобальним спостерігачам створюються анонімні мережі з теоретично доведеною моделлю,
За відсутності глобальних спостерігачів застосовуються мережі із слабкою моделлю загроз з урахуванням принципу федеративності .
Анонімні мережі, що захищають від глобального спостерігача, завжди базуються на будь-якій теоретично доведеній задачі і є екзотичним задоволенням за рахунок безлічі обмежень, що накладаються: швидкості, розміру переданих даних, мінімалізму функцій, можливостей і т.д.
Таким чином, якщо передбачається, що глобальний спостерігач відсутній і якесь із обмежень, що накладаються, є критичним, то в такому випадку рекомендується скористатися класичними анонімними мережами на кшталт Tor , I2P , Mixminion , Crowds і т.д., що спираються на факт існування безлічі маршрутизуючих вузлів у різних державах, країнах, регіонах.
На даний момент відомо лише три завдання на базі яких можуть формуватися теоретично доведені анонімні мережі:
DC-мережі : Проблема криптографів, що обідають (анонімні мережі: Herbivore , Dissent )
QB-мережі : Завдання на базі черг (анонімні мережі: Hidden Lake , MA )
EI-мережі : Завдання на базі збільшення ентропії (анонімні мережі: відсутні)
Як було показано у статті ” Чи можна залишатися анонімним всередині держави, яка закрила весь зовнішній Інтернет? “, на даний момент жива фактично лише одна анонімна мережа – Hidden Lake . Мережа Herbivore має закритий вихідний код, і ніде відкрито не публікувалася. Мережа Dissent хоч має вихідний код, але сам репозиторій не підтримується вже більше 10 років (заархівований). Мережа MA є мінімальним прототипом використання завдання з урахуванням черг.
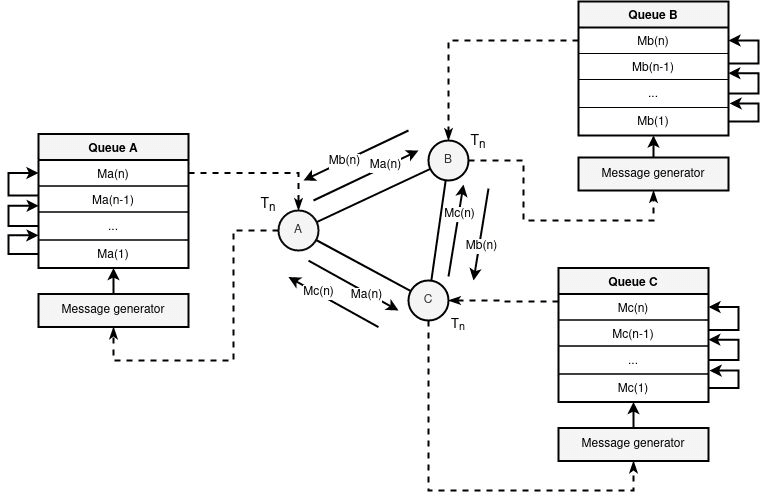
Припустимо, що є три учасника { A, B, C }. Кожен із них з’єднаний один з одним (не є обов’язковим критерієм, але цей випадок наведено виключно для спрощення). Кожен суб’єкт встановлює період генерації інформації = T. На відміну від DC-мереж, де потрібна синхронізація установки періоду за часом, завдання на основі черг така умова не є обов’язковою. Іншими словами, кожен учасник мережі може почати генерувати інформацію з періодом = T у будь-який час без попередньої кооперації/синхронізації з іншими учасниками. У кожного учасника є своє внутрішнє сховище на кшталт FIFO (перший прийшов – перший пішов), можна сказати структура ” черга ” .
Припустимо, що учасник A хоче надіслати якусь інформацію одному з учасників { B, C } так, щоб інший учасник (або зовнішній спостерігач) не знав, що існує якийсь факт відправлення. Кожен учасник у певний період T генерує повідомлення. Таке повідомлення може бути або хибним (що не має жодного фактичного змісту і нікому за фактом не відправляється, заповнюючись випадковими бітами), або дійсним (запит чи відповідь). Надіслати раніше або пізніше за визначений час T ніякий учасник не може. Якщо зібралося кілька запитів одному й тому учаснику, тоді він їх кладе у свою чергу повідомлень і після періоду T дістає з черги і відсилає до мережі.
Таким чином, зовнішній глобальний спостерігач бачитиме лише картину, коли кожен учасник у певно заданий період T відправляє деяке повідомлення всім іншим вузлам мережі, що дає жодної інформації факт відправлення, чи отримання. Внутрішні пасивні учасники також нездатні дізнатися чи комунікує один із учасників у період з будь-яким іншим, т.к. передбачається, що шифрована інформація не видає жодних даних про відправника та одержувача безпосередньо.
Підмножиною теоретично доведених анонімних мереж можуть бути також абстрактні анонімні мережі. Таким мережам байдужі наступні критерії: 1) концентрація мережі, 2) кількість вузлів у мережі, 3) розташування вузлів у мережі. Мережа Hidden Lake повністю належить до цього підвиду.
Тому, якщо основним завданням є анонімний обмін файлами, мережа Hidden Lake слугує відносно добре підготовленим варіантом. На момент написання цієї статті для мережі Hidden Lake не було доступного програмного забезпечення для обміну файлами. Єдиною доступною програмою був Messenger. Тому сьогодні ми спробуємо створити програму для обміну файлами в мережі Hidden Lake.
Анонімна мережа Hidden Lake (HL) є мікросервісною архітектурою, де кожен окремий сервіс бере участь у виконанні свого вузькоспеціалізованого завдання. Кумедним моментом тут є і те, що сам анонімізуючий сервіс HLS ( service ) точно також може бути видалений і замінений іншою технологією, внаслідок чого анонімність може бути видалена, наприклад, через непотрібність. Тим не менш, у такому випадку мережа перестає бути анонімною, що говорить про явну залежність мережі Hidden Lake до сервісу HLS як до її ядра .
Крім анонімного сервісу HLS, в анонімній мережі Hidden Lake також присутні такі сервіси:
HLT ( traffic ) – допоміжний сервіс, що виконує роль збереження та поширення/ретранслювання анонімного трафіку. Може бути використаний на формування таємних каналів зв’язку всередині централізованих сервісів,
HLM ( messenger ) – прикладний сервіс, що представляє собою додаток месенджер,
HLL ( loader ) – допоміжний малий сервіс, що виконує лише роль завантаження анонімного трафіку з одного HLT на інший,
HLE ( encryptor ) – допоміжний малий сервіс, що виконує лише роль шифрування та розшифрування повідомлень.
Мережа Hidden Lake за замовчуванням є мережею F2F (friends-to-friends), де кожен користувач особисто встановлює довірених учасників, з якими він може зв’язуватися і надсилати їм повідомлення. Якщо один абонент не входить до списку друзів іншого і намагається надіслати повідомлення іншому, одержувач просто проігнорує повідомлення.
Завдяки такому механізму HL виключає можливість спаму від ненадійних вузлів і вразливостей, які можуть бути приховані у вихідному коді або включені на рівні додатків. Для того, щоб успішно написати власний файлообмінний сервіс на базі мережі HIdden Lake, було б корисно дізнатися, як формуються, поширюються і доставляються повідомлення одержувачам.
1. Мережевий . На цьому рівні повідомлення упаковується у вигляді сирих даних із трьома особливостями: 1) підтвердження роботи, 2) розмежування мереж, 3) приховування статичного розміру повідомлень.
Підтвердження роботи необхідне для запобігання спаму. На даний момент кожне повідомлення, що генерується в мережі HL в інтервалі T=5s має складність в 22 біти.
Розмежування мереж здійснюється за допомогою ключа мережі ( network_key ) для того, щоб кілька мереж не могли зливатися в одну. Таке обмеження пов’язане зі способом маршрутизації, який є заливальним (сліпа маршрутизація). Через це кожен користувач відправляє згенероване повідомлення кожному вузлу, так і рівносильно приймає від кожного вузла повідомлення.
Приховування статичного розміру повідомлень можливе за умов, коли ключ мережі є секретним. В такому випадку буде проблемно визначити розмір повідомлень, що передаються, за рахунок додавання випадкових байт .
2. Анонімізуючий . На цьому рівні повідомлення упаковується у вигляді статичного розміру даних із зазначенням необхідних заголовків (публічний ключ, ключ шифрування, сіль, хеш повідомлення, підпис хешу), а далі шифрується. Особливістю даного шару є його приналежність до монолітного криптографічного протоколу , в якому вся інформація повністю зашифрована, а розшифрувати зможе лише той, хто має правильний приватний ключ.
3. Транспортний . На цьому рівні повідомлення упаковується у вигляді запиту, в якому вказується який сервіс повинен отримати інформацію, яким шляхом, з якими параметрами (заголовками).
4. Прикладний . На цьому рівні обробляється безпосередньо саме оригінальне повідомлення.
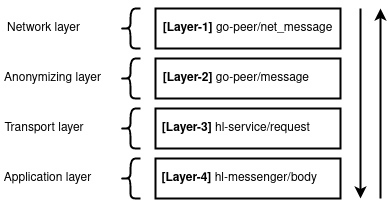
Кожен шар накопичує в собі наступний. Так наприклад, Layer-1 вже містить Layer-2, Layer-2 містить Layer-3, а Layer-3 містить Layer-4. Отже, отримуємо весь стек протоколу HL/go-peer виду L1(L2(L3(L4(message))))) .
З технічної точки зору, якщо анонімність не потрібна, то сервіс обміну файлами можна реалізувати на перших двох рівнях, тобто L1 і L2, використовуючи два сервіси: HLE (для шифрування і дешифрування повідомлень) і HLT (для зберігання зашифрованих повідомлень).
Але в будь-якому випадку, це менш цікаве завдання, ніж створення дійсно анонімного файлообмінника. Вищесказане також може викликати питання щодо рівня L2. Це є причиною використання шару “анонімізації”, але в той же час він усуває фактичну анонімність.
Рівень анонімізації називається анонімізацією, але він лише заявляє, що вся інформація про відправника і одержувача прихована в пакеті. Насправді ж цей рівень починає виконувати свою роль анонімізації лише тоді, коли він переходить на транспортний рівень, тобто до служби HLS. Для більш детального пояснення вищесказаного необхідно розглянути не стан самих пакетів/повідомлень, а процедуру зміни їх стану при комунікації між вузлами мережі.
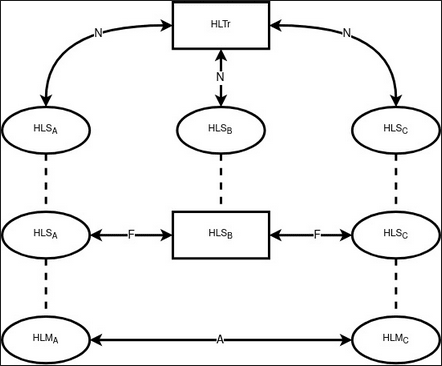
У такому прикладі вимальовується три можливі комунікації / зв’язки:
Мережева . На даному етапі відбувається поширення інформації у звичному та відкритому вигляді для спостерігачів, яка не дає при цьому розуміння, хто кому і що відправив (і чи відправив взагалі). Виконується на шарах L1, L2.
Дружня . На цьому етапі відбувається безпосереднє отримання автентифікуючої інформації між friend-to-friend вузлами. Виконується на шарі L3.
Логічна . На цьому етапі відбувається безпосередній зв’язок з одержувачем/одержувачами відкритої інформації. Виконується на шарі L4.
Сервіси в мережі Hidden Lake можна писати будь-якою мовою програмування та з будь-якою технологією, яка найбільше подобається.
У реалізації опишемо лише основний спосіб, логіку комунікації нашого HLF із HLS для успішного формування анонімного трафіку. Таким чином, все інше, включаючи графічний інтерфейс, структуру проекту тощо можна знайти в самому репозиторії HLF.
У нашого сервісу буде дві можливі дії:
Вивантаження списку файлів . У цьому сценарії нам може знадобитися дізнатися імена файлів, їх розміри, а також хеші,
Вивантаження чанків файлу . У цьому сценарії нам потрібно завантажувати файл чанками (шматками) тому як Hidden Lake обмежує загальний обсяг повідомлень 8KiB без урахування заголовних байт.
Найбільше проблем саме з другим пунктом, тому на даному етапі краще буде спочатку реалізувати вивантаження списку файлів, а потім просто дійти до вивантаження чанків.
Загальний вигляд функції обробника буде виглядати так.
func HandleIncomigListHTTP(pCfg config.IConfig, pPathTo string) http.HandlerFunc {
return func(pW http.ResponseWriter, pR *http.Request) {
// Устанавливаем заголовок для HLS указывающий, что мы генерируем ответ
pW.Header().Set(hls_settings.CHeaderResponseMode, hls_settings.CHeaderResponseModeON)
// Метод должен быть = GET
if pR.Method != http.MethodGet {
api.Response(pW, http.StatusMethodNotAllowed, "failed: incorrect method")
return
}
// Получаем номер страницы с файлами
page, err := strconv.Atoi(pR.URL.Query().Get("page"))
if err != nil {
api.Response(pW, http.StatusBadRequest, "failed: incorrect page")
return
}
// Получаем список файлов с дополнительной информацией (размер, хеш)
result, err := getListFileInfo(pCfg, pPathTo, uint64(page))
if err != nil {
api.Response(pW, http.StatusInternalServerError, "failed: open storage")
return
}
// Отправляем результат
api.Response(pW, http.StatusOK, result)
}
}
Основною невідомою функцією є лише спосіб отримання списку файлів.
func getListFileInfo(pCfg config.IConfig, pPathTo string, pPage uint64) ([]hlf_settings.SFileInfo, error) {
// Количество файлов на одной странице
pageOffset := pCfg.GetSettings().GetPageOffset()
// Читаем содержимое директории-хранилища
entries, err := os.ReadDir(hlf_settings.CPathSTG)
if err != nil {
return nil, err
}
lenEntries := uint64(len(entries))
result := make([]hlf_settings.SFileInfo, 0, lenEntries)
for i := (pPage * pageOffset); i < lenEntries; i++ {
e := entries[i]
if e.IsDir() {
continue
}
// Если мы прочитали всю страницу, тогда прерываем чтение
if i != (pPage*pageOffset) && i%pageOffset == 0 {
break
}
fullPath := filepath.Join(pPathTo, hlf_settings.CPathSTG, e.Name())
result = append(result, hlf_settings.SFileInfo{
FName: e.Name(),
FHash: getFileHash(fullPath),
FSize: getFileSize(fullPath),
})
}
return result, nil
}
func getFileSize(filename string) uint64 {
stat, _ := os.Stat(filename)
return uint64(stat.Size())
}
func getFileHash(filename string) string {
f, err := os.Open(filename)
if err != nil {
return ""
}
defer f.Close()
h := sha256.New()
if _, err := io.Copy(h, f); err != nil {
return ""
}
// Аналог функции hex.EncodeToString()
return encoding.HexEncode(h.Sum(nil))
}
Це весь обробник, включаючи список файлів. Де анонімність, де анонімізація трафіку? Суть в тому, що HLS використовує лише сервіс, який ми пишемо, як друкований чорний ящик: HLS отримує запити від мережі Hidden Lake і перенаправляє їх на наш сервіс.
Наш сервіс створює відповідь і відправляє її до HLS, який упаковує відповідь у звичайний формат мережі Hidden Lake і відправляє її на адресу відправника. Таким чином, оскільки сам сервіс не розголошує жодної особистої інформації, нам не потрібно надто турбуватися про правильність логіки анонімізаці
Тепер нам необхідно написати обробник із вивантаженням чанків. Тут також видалені рядки з логуванням для спрощення коду.
func HandleIncomigLoadHTTP(pCfg config.IConfig, pPathTo string) http.HandlerFunc {
return func(pW http.ResponseWriter, pR *http.Request) {
// Устанавливаем заголовок для HLS указывающий, что мы генерируем ответ
pW.Header().Set(hls_settings.CHeaderResponseMode, hls_settings.CHeaderResponseModeON)
// Также метод должен быть только GET
// Узел должен нам указать имя файла, который он хочет скачивать...<br />name := filepath.Base(query.Get("name"))<br />if name != query.Get("name") {<br />api.Response(pW, http.StatusConflict, "failed: got another name")<br />return<br />}
// ... и также номер чанка<br />chunk, err := strconv.Atoi(query.Get("chunk"))<br />if err != nil || chunk < 0 {<br />api.Response(pW, http.StatusBadRequest, "failed: incorrect chunk")<br />return<br />}
// Пытаемся найти этот файл в нашей директории-хранилище<br />fullPath := filepath.Join(pPathTo, hlf_settings.CPathSTG, name)<br />stat, err := os.Stat(fullPath)<br />if os.IsNotExist(err) || stat.IsDir() {<br />api.Response(pW, http.StatusNotAcceptable, "failed: file not found")<br />return<br />}
// Вычисляем размер чанка, который мы можем отправить<br />// по анонимной сети Hidden Lake<br />chunkSize, err := getMessageLimit(getClient(pCfg))<br />if err != nil {<br />api.Response(pW, http.StatusNotAcceptable, "failed: get chunk size")<br />return<br />}
// Вычисляем общее количество чанков для нашего файла<br />// и если полученный номер чанка больше общего количество, то выдать ошибку<br />chunks := utils.GetChunksCount(uint64(stat.Size()), chunkSize)<br />if uint64(chunk) >= chunks {<br />api.Response(pW, http.StatusNotAcceptable, "failed: chunk number")<br />return<br />}
// Открываем полученный файл<br />file, err := os.Open(fullPath)<br />if err != nil {<br />api.Response(pW, http.StatusNotAcceptable, "failed: open file")<br />return<br />}<br />defer file.Close()
// Создаём буфер размером с чанк и вычисляем позицию нужного чанка<br />buf := make([]byte, chunkSize)<br />chunkOffset := int64(chunk) * int64(chunkSize)
// Сдвигаем чтение файла на позицию номера чанка<br />nS, err := file.Seek(chunkOffset, io.SeekStart)<br />if err != nil || nS != chunkOffset {<br />api.Response(pW, http.StatusNotAcceptable, "failed: seek file")<br />return<br />}
// Читаем только один чанк<br />nR, err := file.Read(buf)<br />if err != nil || (uint64(chunk) != chunks-1 && uint64(nR) != chunkSize) {<br />api.Response(pW, http.StatusNotAcceptable, "failed: chunk number")<br />return<br />}
// Отправляем прочтённый чанк<br />api.Response(pW, http.StatusOK, buf
У цьому коді існує лише одна невідома раніше функція getMessageSize.
var (
// Вычисляем размер структуры сообщения без самих данных
// {"code":200,"head":{"Content-Type":"application/octet-stream","Hl-Service-Response-Mode":"on"},"body":""}
gRespSize = uint64(len(
hls_response.NewResponse(200).
WithHead(map[string]string{
"Content-Type": api.CApplicationOctetStream,
hls_settings.CHeaderResponseMode: hls_settings.CHeaderResponseModeON,
}).
WithBody([]byte{}).
ToBytes(),
))
)
func getMessageLimit(pHlsClient hls_client.IClient) (uint64, error) {
// Получаем настройки от HLS
sett, err := pHlsClient.GetSettings()
if err != nil {
return 0, fmt.Errorf("get settings from HLS (message size): %w", err)
}
// Получаем количество возможных байт, сколько мы можем записать
// В этих байтах не учтён размер структуры сообщения
msgLimitOrig := sett.GetLimitMessageSizeBytes()
if gRespSize >= msgLimitOrig {
return 0, errors.New("response size >= limit message size")
}
// Поэтому вычитаем из количества полученных байт структуру сообщения
msgLimitBytes := msgLimitOrig - gRespSize
// HLS кодирует данные в base64, которые находятся в поле body
// Поэтому нам необходимо учесть сколько байт сожрёт ещё сама кодировка base64
return base64.GetSizeInBase64(msgLimitBytes)
}
// ... package base64 ...
func GetSizeInBase64(pBytesNum uint64) (uint64, error) {
if pBytesNum < 2 {
return 0, errors.New("pBytesNum < 2")
}
// base64 encoding bytes with add 1/4 bytes of original
// (-2) is a '=' characters in the suffix of encoding bytes
return pBytesNum - uint64(math.Ceil(float64(pBytesNum)/4)) - 2, nil
Як тільки ми написали сам сервіс, нам необхідно буде також написати і клієнтську програму, яка буде зв’язуватися з нашим файлообмінним сервісом. Для цього нам краще буде написати функції API , які будуть взаємодіяти з HLF через HLS. І лише після, на основі написаних функцій, писати основну логіку завантаження файлів.
type IClient interface {
GetListFiles(string, uint64) ([]hlf_settings.SFileInfo, error)
LoadFileChunk(string, string, uint64) ([]byte, error)
}
type IRequester interface {
GetListFiles(string, hls_request.IRequest) ([]hlf_settings.SFileInfo, error)
LoadFileChunk(string, hls_request.IRequest) ([]byte, error)
}
type IBuilder interface {
GetListFiles(uint64) hls_request.IRequest
LoadFileChunk(string, uint64) hls_request.IRequest
}
var (
_ IClient = &sClient{}
)
type sClient struct {
fBuilder IBuilder
fRequester IRequester
}
func NewClient(pBuilder IBuilder, pRequester IRequester) IClient {
return &sClient{
fBuilder: pBuilder,
fRequester: pRequester,
}
}
func (p *sClient) GetListFiles(pAliasName string, pPage uint64) ([]hlf_settings.SFileInfo, error) {
return p.fRequester.GetListFiles(pAliasName, p.fBuilder.GetListFiles(pPage))
}
func (p *sClient) LoadFileChunk(pAliasName, pName string, pChunk uint64) ([]byte, error) {
return p.fRequester.LoadFileChunk(pAliasName, p.fBuilder.LoadFileChunk(pName, pChunk))
}
var (
_ IBuilder = &sBuilder{}
)
type sBuilder struct {
}
func NewBuilder() IBuilder {
return &sBuilder{}
}
func (p *sBuilder) GetListFiles(pPage uint64) hls_request.IRequest {
return hls_request.NewRequest(
http.MethodGet,
hlf_settings.CTitlePattern,
fmt.Sprintf("%s?page=%d", hlf_settings.CListPath, pPage),
)
}
func (p *sBuilder) LoadFileChunk(pName string, pChunk uint64) hls_request.IRequest {
return hls_request.NewRequest(
http.MethodGet,
hlf_settings.CTitlePattern,
fmt.Sprintf("%s?name=%s&chunk=%d", hlf_settings.CLoadPath, pName, pChunk),
)
}
var (
_ IRequester = &sRequester{}
)
type sRequester struct {
fHLSClient hls_client.IClient
}
func NewRequester(pHLSClient hls_client.IClient) IRequester {
return &sRequester{
fHLSClient: pHLSClient,
}
}
func (p *sRequester) GetListFiles(pAliasName string, pRequest hls_request.IRequest) ([]hlf_settings.SFileInfo, error) {
resp, err := p.fHLSClient.FetchRequest(pAliasName, pRequest)
if err != nil {
return nil, utils.MergeErrors(ErrRequest, err)
}
if resp.GetCode() != http.StatusOK {
return nil, utils.MergeErrors(
ErrDecodeResponse,
fmt.Errorf("got %d code", resp.GetCode()),
)
}
list := make([]hlf_settings.SFileInfo, 0, hlf_settings.CDefaultPageOffset)
if err := encoding.DeserializeJSON(resp.GetBody(), &list); err != nil {
return nil, utils.MergeErrors(ErrInvalidResponse, err)
}
for _, info := range list {
if len(encoding.HexDecode(info.FHash)) != hashing.CSHA256Size {
return nil, utils.MergeErrors(
ErrInvalidResponse,
errors.New("got invalid hash value"),
)
}
}
return list, nil
}
func (p *sRequester) LoadFileChunk(pAliasName string, pRequest hls_request.IRequest) ([]byte, error) {
resp, err := p.fHLSClient.FetchRequest(pAliasName, pRequest)
if err != nil {
return nil, utils.MergeErrors(ErrRequest, err)
}
if resp.GetCode() != http.StatusOK {
return nil, utils.MergeErrors(
ErrDecodeResponse,
fmt.Errorf("got %d code", resp.GetCode()),
)
}
return resp.GetBody(), nil
Таким чином, щоб отримати список файлів, потрібно лише виконати наступний код:
filesList, err := hlfClient.GetListFiles(aliasName, page)
if err != nil {
return err
}
...
А щоб одержати всі чанки файлу, наступний. У цьому коді лише пропущено моменти необхідного порівняння розміру отриманого файлу та його хеша, щоб переконатися, що ми завантажили саме потрібний нам файл.
chunksCount := utils.GetChunksCount(uint64(fileSize), chunkSize)
for i := uint64(startChunk); i < chunksCount; i++ {
chunk, err := hlfClient.LoadFileChunk(aliasName, fileName, i)
if err != nil {
return err
}
...
}
Також у цій реалізації рекомендується додати повторні спроби скачування, за умови, якщо пакет загубиться в мережі, а також запам’ятовування раніше скачаних чанків, щоб мати можливість відновлювати скачування при розірваному з’єднанні.
Для того щоб підключити сервіс HLF до сервісу HLS, достатньо в конфігураційному файлі останнього додати адресу на яку потрібно буде перенаправляти запит.
services:
hidden-lake-filesharer:
host: localhost:8081
Результат роботи, показаний на GIF-зображенні, було прискорено вдвічі, і навіть з урахуванням цього нюансу записане відео триває більше хвилини. У той же час завантажене зображення, показане в прикладі, має розмір лише 17,8 Кб! Це і є основний недолік HLF. Також, з певної точки зору, навіть виглядає смішно, що зображення завантажуються по частинах зверху вниз, як у старі добрі часи. З чим це може бути пов’язано? Це пов’язано з самою архітектурою Hidden Lake, яка обмежує розмір одного вихідного повідомлення періодом його генерації. У Hidden Lake кожне повідомлення має розмір 8 кілобайт, а період – 5 секунд.
Тоді може виникнути ще одне логічне запитання – чому зображення не завантажилося за ~15 секунд, адже для цього зображення цього цілком достатньо? Справа в двох моментах: 1) з 8 Кб реальна частка даних, що передаються, становить ~3,5 Кб, і 2) для кожного надісланого шматка потрібен повний запит-відповідь, коли клієнт робить запит із зазначенням номера шматка, а сам шматок надсилається надсилається у відповідь від файлообмінника; успішна передача 3,5 кілобайт займає щонайменше 10 секунд, що відповідає швидкості ~358Б/сек. Те ж саме стосується і отримання списку файлів: щоб отримати файли розміром зі сторінку, потрібно почекати близько 10 секунд.
В результаті на базі мережі Hidden Lake було реалізовано анонімний файлообмінник з теоретично доведеною анонімністю. До плюсів можна віднести те, що він працює дуже стабільно. Недоліком, звичайно, є швидкість передачі даних. Таким чином, теоретично доведена анонімність не є безкоштовною і іноді за неї доводиться платити.

