
01.05.2023
14 min
2553

In this article, you’ll learn about best practices and tools for maintaining anonymity on the Internet, including an in-depth look at anonymous networks like Tor and Hidden Lake and their role in protecting your personal information from unwanted attention.

While preserving the confidentiality of transmitted data is an important and quite challenging task in the presence of global observers and ubiquitous centralized infrastructure, the task of preserving the confidentiality of metadata such as subscriber network addresses and frequency information is even more problematic. This task can be called the anonymity task.
Anonymity means that the communication between the sender and the recipient is always hidden in any information system. Communication should be understood as an explicit case of sending information, as well as an implicit case of receiving it. Traffic observers similarly become recipients of the fact of the appearance of information and begin to form a connection with the sender.
It is also worth clarifying that the sender and recipient can be singular or plural, and mutual anonymity is an optional parameter. For example, it is possible that two entities can be mutually identified and communicate with each other over an anonymous network. In such a model, they are not anonymous to each other, but the existence of an anonymous network limits the ability of external or internal third-party observers to analyze their behavior.
Conversely, if the sender and receiver are anonymous to each other, but their communications are not hidden from the observer, such a system can be considered quasi-anonymous. An example of such a phenomenon is a classic centralized social network. This network does not disclose information about its subscribers to other subscribers, but at the same time fully identifies each subscriber.
Some systems require an element of relative de-anonymization to create anonymity. This element plays the role of trust, when all or only part of the communication is de-anonymized for a limited number of people. The difference between relative de-anonymization and absolute de-anonymization depends on the scope of a particular person’s social circle.
For example, a person who has committed a crime becomes an anonymous source of information. On the other hand, society becomes the recipient of this information. The very fact of receiving information can be a side effect of the offender’s actions. A criminal may have an accomplice who is one of the recipients in society. The purpose of an accomplice may be to convey the actual purpose (message) of the criminal. In this paradigm, the perpetrator is not anonymous to the accomplice, but exhibits relative non-anonymity, preventing absolute non-anonymity in the context of having a specific message.
The formation of anonymity in the network space at the initial stages is not much different from the methods of anonymization in the real material world described above. Anonymity of participants is also formed due to the partial presence of nodes of relative size that deanonymize senders. In the early stages, such nodes are centralized services, in the later stages they are already proxy services or VPN services.
However, compared to the previously discussed cases, a feature of network anonymization is the existence of hidden (anonymous) networks, that is, the potential for more effective creation of favorable environmental conditions when initializing and maintaining a given level of anonymity. Network anonymity is mainly based on cryptographic primitives, and in many cases the risk of turning relative anonymity into absolute can be controlled by constructing an N-th intermediate node in the routing chain.
Network anonymity, being a subset of anonymity, also leads to more specific threat models and challenges:
Hiding the recipient’s network address is often a form of anonymity to simultaneously bypass blocking by the communications provider,
Hiding the sender’s address is often a form of anonymity to simultaneously bypass blocking by the communication service,
States become external, and often global, observers (recipients) of all traffic generated,
In order to counter global observers, anonymous networks are created with a theoretically proven model,
In the absence of global observers, networks with a weak threat model are applied, taking into account the principle of federacy.
Anonymous networks that protect against a global observer are always based on any theoretically proven problem and are an exotic pleasure due to the many limitations imposed: speed, size of transferred data, minimalism of functions, capabilities, etc.
Thus, if it is assumed that there is no global observer and some of the imposed restrictions are critical, then it is recommended to use the classic anonymous networks like Tor, I2P, Mixminion, Crowds, etc., which rely on the fact of existence many routing nodes in different states, countries, regions.
At the moment, only three tasks are known on the basis of which theoretically proven anonymous networks can be formed:
DC Networks: The Cryptographers Dining Out Problem (Anonymous Networks: Herbivore, Dissent)
QB Networks: Queue Based Tasks (Anonymous Networks: Hidden Lake, MA)
EI Networks: Entropy Maximization Task (Anonymous Networks: None)
As shown in the article “Is it possible to remain anonymous inside a country that has closed all the outside Internet?”, there is actually only one anonymous network alive at the moment – Hidden Lake. The Herbivore network is closed source and has not been publicly published anywhere. Although the Dissent network has the source code, the repository itself has been deprecated for over 10 years (archived). An MA network is a minimal prototype for using a queue-aware task.
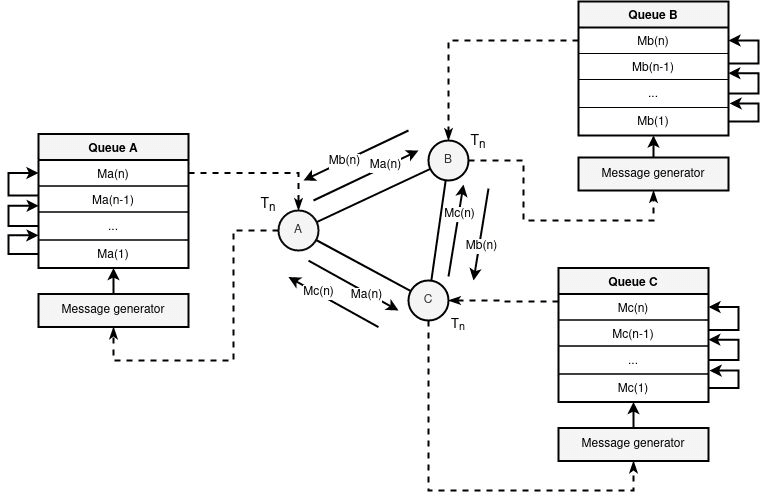
Suppose there are three members { A, B, C }. Each of them is connected to each other (not a mandatory criterion, but this case is given only for simplification). Each entity sets the period of information generation = T. Unlike DC networks, where synchronization of the period setting is required, queue-based tasks do not require this condition. In other words, each member of the network can start generating information with period = T at any time without prior cooperation/synchronization with other members. Each participant has its own internal storage, like a FIFO (first-in-first-out), you can say “queue” structure.
Suppose that participant A wants to send some information to one of the participants {B, C} without the other participant (or external observer) knowing that there is any fact of sending. Each participant in a certain period T generates a message. Such a message can be either false (which has no actual content and is not actually sent to anyone, being filled with random bits), or valid (a request or a response). No participant can send before or after the specified time T. If there are several requests to the same participant, then he puts them in his message queue and after a period T gets out of the queue and sends it to the network.
Thus, an external global observer will only see a picture when each participant in a given period T sends some message to all other nodes of the network, which does not give any information about the fact of sending or receiving. Internal passive participants are also unable to find out whether one of the participants is communicating with any other during the period, because it is assumed that the encrypted information does not reveal any data about the sender and receiver directly.
A subset of theoretically proven anonymous networks can also be abstract anonymous networks. Such networks are indifferent to the following criteria: 1) concentration of the network, 2) number of nodes in the network, 3) location of nodes in the network. The Hidden Lake network belongs entirely to this subspecies.
Therefore, if the main task is anonymous file sharing, the Hidden Lake network serves as a relatively well-prepared option. At the time of this writing, there was no file sharing software available for the Hidden Lake network. Messenger was the only app available. Therefore, today we will try to create an application for sharing files on the Hidden Lake network.
The Hidden Lake (HL) anonymous network is a microservice architecture where each individual service participates in a highly specialized task. The funny thing here is that the HLS anonymizing service itself can definitely also be removed and replaced by another technology, as a result of which anonymity can be removed, for example, due to unnecessaryness. However, in this case, the network ceases to be anonymous, which indicates the explicit dependence of the Hidden Lake network on the HLS service as its core.
In addition to the HLS anonymous service, the following services are also present in the Hidden Lake anonymous network:
HLT (traffic) is an auxiliary service that performs the role of storing and distributing/retransmitting anonymous traffic. Can be used to form secret communication channels within centralized services,
HLM (messenger) – application service, which is a messenger application,
HLL (loader) is an auxiliary small service that performs only the role of loading anonymous traffic from one HLT to another,
HLE (encryptor) is a small auxiliary service that performs only the role of encrypting and decrypting messages.
By default, the Hidden Lake network is a F2F (friends-to-friends) network, where each user personally sets up trusted members they can contact and message. If one subscriber is not on the other’s friends list and tries to send a message to the other, the recipient will simply ignore the message.
Thanks to this mechanism, HL eliminates the possibility of spam from untrusted nodes and vulnerabilities that may be hidden in the source code or included at the application level. In order to successfully write your own file sharing service based on the HIdden Lake network, it would be useful to learn how messages are formed, distributed and delivered to recipients.
1. Network. At this layer, the message is packaged as raw data with three features: 1) proof of work, 2) demarcating networks, 3) hiding the static message size.
2. Anonymizing. At this level, the message is packaged as a static data size with the required headers (public key, encryption key, salt, message hash, hash signature) and then encrypted. The peculiarity of this layer is its belonging to a monolithic cryptographic protocol, in which all information is completely encrypted, and only the one who has the correct private key will be able to decrypt it.
3. Transport. At this level, the message is packaged in the form of a request, which indicates which service should receive information, in which way, with which parameters (headers).
4. Applied. At this level, the original message itself is processed directly.
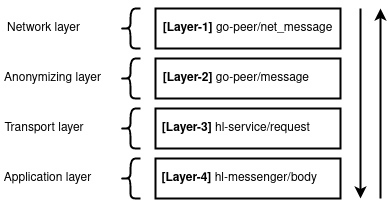
Each layer accumulates the next. For example, Layer-1 already contains Layer-2, Layer-2 contains Layer-3, and Layer-3 contains Layer-4. So, we get the entire HL/go-peer protocol stack of the form L1(L2(L3(L4(message)))))).
From a technical point of view, if anonymity is not required, the file sharing service can be implemented at the first two levels, i.e. L1 and L2, using two services: HLE (for encryption and decryption of messages) and HLT (for storage of encrypted messages).
But in any case, this is a less interesting task than creating a truly anonymous file sharer. The above may also raise questions about L2 level. This is the reason for using the “anonymization” layer, but at the same time it removes the actual anonymity.
The level of anonymization is called anonymization, but it only declares that all information about the sender and recipient is hidden in the packet. In fact, this layer begins to perform its role of anonymization only when it passes to the transport layer, that is, to the HLS service. For a more detailed explanation of the above, it is necessary to consider not the state of the packets/messages themselves, but the procedure for changing their state during communication between network nodes.
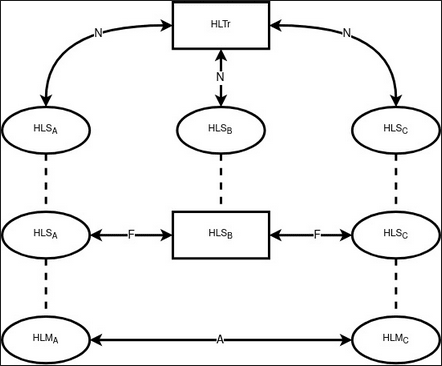
In such an example, three possible communications / connections emerge:
Network. At this stage, information is disseminated in the usual and open form for observers, which does not give an understanding of who sent what and to whom (or whether they sent it at all). Performed on layers L1, L2.
Friendly. At this stage, authentication information is directly obtained between friend-to-friend nodes. Executed at the L3 layer.
Logical. At this stage, there is direct communication with the recipient/recipients of open information. Executed at the L4 layer.
Services on the Hidden Lake network can be written in any programming language and with any technology you like best.
In the implementation, we will describe only the main method, the logic of communication of our HLF with HLS for the successful formation of anonymous traffic. So everything else, including the GUI, project structure, etc. can be found in the HLF repository itself.
Our service will have two possible actions:
Downloading a list of files. In this scenario, we may need to know file names, file sizes, and hashes,
Unloading file chunks. In this scenario, we need to download the file in chunks (chunks) because Hidden Lake limits the total size of messages to 8KiB, excluding header bytes.
The most problems are with the second point, so at this stage it will be better to first implement the download of the list of files, and then just get to the download of chunks.
The general appearance of the handler function will look like this.
func HandleIncomigListHTTP(pCfg config.IConfig, pPathTo string) http.HandlerFunc {
return func(pW http.ResponseWriter, pR *http.Request) {
// Устанавливаем заголовок для HLS указывающий, что мы генерируем ответ
pW.Header().Set(hls_settings.CHeaderResponseMode, hls_settings.CHeaderResponseModeON)
// Метод должен быть = GET
if pR.Method != http.MethodGet {
api.Response(pW, http.StatusMethodNotAllowed, "failed: incorrect method")
return
}
// Получаем номер страницы с файлами
page, err := strconv.Atoi(pR.URL.Query().Get("page"))
if err != nil {
api.Response(pW, http.StatusBadRequest, "failed: incorrect page")
return
}
// Получаем список файлов с дополнительной информацией (размер, хеш)
result, err := getListFileInfo(pCfg, pPathTo, uint64(page))
if err != nil {
api.Response(pW, http.StatusInternalServerError, "failed: open storage")
return
}
// Отправляем результат
api.Response(pW, http.StatusOK, result)
}
}
The main unknown function is just how to get the file list.
func getListFileInfo(pCfg config.IConfig, pPathTo string, pPage uint64) ([]hlf_settings.SFileInfo, error) {
// Количество файлов на одной странице
pageOffset := pCfg.GetSettings().GetPageOffset()
// Читаем содержимое директории-хранилища
entries, err := os.ReadDir(hlf_settings.CPathSTG)
if err != nil {
return nil, err
}
lenEntries := uint64(len(entries))
result := make([]hlf_settings.SFileInfo, 0, lenEntries)
for i := (pPage * pageOffset); i < lenEntries; i++ {
e := entries[i]
if e.IsDir() {
continue
}
// Если мы прочитали всю страницу, тогда прерываем чтение
if i != (pPage*pageOffset) && i%pageOffset == 0 {
break
}
fullPath := filepath.Join(pPathTo, hlf_settings.CPathSTG, e.Name())
result = append(result, hlf_settings.SFileInfo{
FName: e.Name(),
FHash: getFileHash(fullPath),
FSize: getFileSize(fullPath),
})
}
return result, nil
}
func getFileSize(filename string) uint64 {
stat, _ := os.Stat(filename)
return uint64(stat.Size())
}
func getFileHash(filename string) string {
f, err := os.Open(filename)
if err != nil {
return ""
}
defer f.Close()
h := sha256.New()
if _, err := io.Copy(h, f); err != nil {
return ""
}
// Аналог функции hex.EncodeToString()
return encoding.HexEncode(h.Sum(nil))
}
This is the entire handler, including the file list. Where is the anonymity, where is the anonymization of traffic? The bottom line is that HLS only uses the service we write as a printed black box: HLS receives requests from the Hidden Lake network and forwards them to our service.
Our service creates a response and sends it to HLS, which packages the response into a common Hidden Lake network format and sends it to the sender’s address. Thus, since the service itself does not disclose any personal information, we do not need to worry too much about the correctness of the anonymization logic
Now we need to write a handler for unloading chunks. Here, too, the logging lines have been removed to simplify the code.
func HandleIncomigLoadHTTP(pCfg config.IConfig, pPathTo string) http.HandlerFunc {
return func(pW http.ResponseWriter, pR *http.Request) {
// Устанавливаем заголовок для HLS указывающий, что мы генерируем ответ
pW.Header().Set(hls_settings.CHeaderResponseMode, hls_settings.CHeaderResponseModeON)
// Также метод должен быть только GET
// Узел должен нам указать имя файла, который он хочет скачивать...<br />name := filepath.Base(query.Get("name"))<br />if name != query.Get("name") {<br />api.Response(pW, http.StatusConflict, "failed: got another name")<br />return<br />}
// ... и также номер чанка<br />chunk, err := strconv.Atoi(query.Get("chunk"))<br />if err != nil || chunk < 0 {<br />api.Response(pW, http.StatusBadRequest, "failed: incorrect chunk")<br />return<br />}
// Пытаемся найти этот файл в нашей директории-хранилище<br />fullPath := filepath.Join(pPathTo, hlf_settings.CPathSTG, name)<br />stat, err := os.Stat(fullPath)<br />if os.IsNotExist(err) || stat.IsDir() {<br />api.Response(pW, http.StatusNotAcceptable, "failed: file not found")<br />return<br />}
// Вычисляем размер чанка, который мы можем отправить<br />// по анонимной сети Hidden Lake<br />chunkSize, err := getMessageLimit(getClient(pCfg))<br />if err != nil {<br />api.Response(pW, http.StatusNotAcceptable, "failed: get chunk size")<br />return<br />}
// Вычисляем общее количество чанков для нашего файла<br />// и если полученный номер чанка больше общего количество, то выдать ошибку<br />chunks := utils.GetChunksCount(uint64(stat.Size()), chunkSize)<br />if uint64(chunk) >= chunks {<br />api.Response(pW, http.StatusNotAcceptable, "failed: chunk number")<br />return<br />}
// Открываем полученный файл<br />file, err := os.Open(fullPath)<br />if err != nil {<br />api.Response(pW, http.StatusNotAcceptable, "failed: open file")<br />return<br />}<br />defer file.Close()
// Создаём буфер размером с чанк и вычисляем позицию нужного чанка<br />buf := make([]byte, chunkSize)<br />chunkOffset := int64(chunk) * int64(chunkSize)
// Сдвигаем чтение файла на позицию номера чанка<br />nS, err := file.Seek(chunkOffset, io.SeekStart)<br />if err != nil || nS != chunkOffset {<br />api.Response(pW, http.StatusNotAcceptable, "failed: seek file")<br />return<br />}
// Читаем только один чанк<br />nR, err := file.Read(buf)<br />if err != nil || (uint64(chunk) != chunks-1 && uint64(nR) != chunkSize) {<br />api.Response(pW, http.StatusNotAcceptable, "failed: chunk number")<br />return<br />}
// Отправляем прочтённый чанк<br />api.Response(pW, http.StatusOK, buf
There is only one previously unknown getMessageSize function in this code.
var (
// Вычисляем размер структуры сообщения без самих данных
// {"code":200,"head":{"Content-Type":"application/octet-stream","Hl-Service-Response-Mode":"on"},"body":""}
gRespSize = uint64(len(
hls_response.NewResponse(200).
WithHead(map[string]string{
"Content-Type": api.CApplicationOctetStream,
hls_settings.CHeaderResponseMode: hls_settings.CHeaderResponseModeON,
}).
WithBody([]byte{}).
ToBytes(),
))
)
func getMessageLimit(pHlsClient hls_client.IClient) (uint64, error) {
// Получаем настройки от HLS
sett, err := pHlsClient.GetSettings()
if err != nil {
return 0, fmt.Errorf("get settings from HLS (message size): %w", err)
}
// Получаем количество возможных байт, сколько мы можем записать
// В этих байтах не учтён размер структуры сообщения
msgLimitOrig := sett.GetLimitMessageSizeBytes()
if gRespSize >= msgLimitOrig {
return 0, errors.New("response size >= limit message size")
}
// Поэтому вычитаем из количества полученных байт структуру сообщения
msgLimitBytes := msgLimitOrig - gRespSize
// HLS кодирует данные в base64, которые находятся в поле body
// Поэтому нам необходимо учесть сколько байт сожрёт ещё сама кодировка base64
return base64.GetSizeInBase64(msgLimitBytes)
}
// ... package base64 ...
func GetSizeInBase64(pBytesNum uint64) (uint64, error) {
if pBytesNum < 2 {
return 0, errors.New("pBytesNum < 2")
}
// base64 encoding bytes with add 1/4 bytes of original
// (-2) is a '=' characters in the suffix of encoding bytes
return pBytesNum - uint64(math.Ceil(float64(pBytesNum)/4)) - 2, nil
As soon as we have written the service itself, we will also need to write a client program that will communicate with our file sharing service. To do this, we would be better off writing API functions that will interact with HLF through HLS. And only after, on the basis of the written functions, write the main logic of downloading files.
type IClient interface {
GetListFiles(string, uint64) ([]hlf_settings.SFileInfo, error)
LoadFileChunk(string, string, uint64) ([]byte, error)
}
type IRequester interface {
GetListFiles(string, hls_request.IRequest) ([]hlf_settings.SFileInfo, error)
LoadFileChunk(string, hls_request.IRequest) ([]byte, error)
}
type IBuilder interface {
GetListFiles(uint64) hls_request.IRequest
LoadFileChunk(string, uint64) hls_request.IRequest
}
var (
_ IClient = &sClient{}
)
type sClient struct {
fBuilder IBuilder
fRequester IRequester
}
func NewClient(pBuilder IBuilder, pRequester IRequester) IClient {
return &sClient{
fBuilder: pBuilder,
fRequester: pRequester,
}
}
func (p *sClient) GetListFiles(pAliasName string, pPage uint64) ([]hlf_settings.SFileInfo, error) {
return p.fRequester.GetListFiles(pAliasName, p.fBuilder.GetListFiles(pPage))
}
func (p *sClient) LoadFileChunk(pAliasName, pName string, pChunk uint64) ([]byte, error) {
return p.fRequester.LoadFileChunk(pAliasName, p.fBuilder.LoadFileChunk(pName, pChunk))
}
var (
_ IBuilder = &sBuilder{}
)
type sBuilder struct {
}
func NewBuilder() IBuilder {
return &sBuilder{}
}
func (p *sBuilder) GetListFiles(pPage uint64) hls_request.IRequest {
return hls_request.NewRequest(
http.MethodGet,
hlf_settings.CTitlePattern,
fmt.Sprintf("%s?page=%d", hlf_settings.CListPath, pPage),
)
}
func (p *sBuilder) LoadFileChunk(pName string, pChunk uint64) hls_request.IRequest {
return hls_request.NewRequest(
http.MethodGet,
hlf_settings.CTitlePattern,
fmt.Sprintf("%s?name=%s&chunk=%d", hlf_settings.CLoadPath, pName, pChunk),
)
}
var (
_ IRequester = &sRequester{}
)
type sRequester struct {
fHLSClient hls_client.IClient
}
func NewRequester(pHLSClient hls_client.IClient) IRequester {
return &sRequester{
fHLSClient: pHLSClient,
}
}
func (p *sRequester) GetListFiles(pAliasName string, pRequest hls_request.IRequest) ([]hlf_settings.SFileInfo, error) {
resp, err := p.fHLSClient.FetchRequest(pAliasName, pRequest)
if err != nil {
return nil, utils.MergeErrors(ErrRequest, err)
}
if resp.GetCode() != http.StatusOK {
return nil, utils.MergeErrors(
ErrDecodeResponse,
fmt.Errorf("got %d code", resp.GetCode()),
)
}
list := make([]hlf_settings.SFileInfo, 0, hlf_settings.CDefaultPageOffset)
if err := encoding.DeserializeJSON(resp.GetBody(), &list); err != nil {
return nil, utils.MergeErrors(ErrInvalidResponse, err)
}
for _, info := range list {
if len(encoding.HexDecode(info.FHash)) != hashing.CSHA256Size {
return nil, utils.MergeErrors(
ErrInvalidResponse,
errors.New("got invalid hash value"),
)
}
}
return list, nil
}
func (p *sRequester) LoadFileChunk(pAliasName string, pRequest hls_request.IRequest) ([]byte, error) {
resp, err := p.fHLSClient.FetchRequest(pAliasName, pRequest)
if err != nil {
return nil, utils.MergeErrors(ErrRequest, err)
}
if resp.GetCode() != http.StatusOK {
return nil, utils.MergeErrors(
ErrDecodeResponse,
fmt.Errorf("got %d code", resp.GetCode()),
)
}
return resp.GetBody(), nil
So to get a list of files, you just need to execute the following code:
filesList, err := hlfClient.GetListFiles(aliasName, page)
if err != nil {
return err
}
...
And to get all chunks of the file, the following. This code just skips the necessary comparison of the size of the received file and its hash to make sure we’ve downloaded exactly the file we need.
chunksCount := utils.GetChunksCount(uint64(fileSize), chunkSize)
for i := uint64(startChunk); i < chunksCount; i++ {
chunk, err := hlfClient.LoadFileChunk(aliasName, fileName, i)
if err != nil {
return err
}
...
}
Also in this implementation it is recommended to add download retries, provided that the package is lost in the network, as well as the memory of previously downloaded chunks to be able to resume the download in case of a broken connection.
In order to connect the HLF service to the HLS service, it is enough to add the address to which the request will be redirected in the configuration file of the latter.
services:
hidden-lake-filesharer:
host: localhost:8081
The result of the work shown in the GIF image was accelerated twice, and even taking into account this nuance, the recorded video lasts more than a minute. At the same time, the downloaded image shown in the example is only 17.8 KB in size! This is the main drawback of HLF. Also, from a certain point of view, it even looks funny that the images are loaded in parts from top to bottom, like in the good old days. What can this be related to? This is due to the Hidden Lake architecture itself, which limits the size of one output message to the period of its generation. In Hidden Lake, each message has a size of 8 kilobytes and a period of 5 seconds.
Then another logical question may arise – why didn’t the image load in ~15 seconds, because for this image it is quite enough? It’s two points: 1) out of 8Kb, the actual data portion being transferred is ~3.5Kb, and 2) each chunk sent requires a full request-response, where the client makes a request with the chunk number and the chunk itself is sent sent in response from the file exchange; a successful transfer of 3.5 kilobytes takes at least 10 seconds, which corresponds to a speed of ~358B/s. The same applies to retrieving the file list: it takes about 10 seconds to retrieve page-sized files.
As a result, an anonymous file exchange with theoretically proven anonymity was implemented on the basis of the Hidden Lake network. The pluses include the fact that it works very stably. The disadvantage, of course, is the speed of data transfer. Thus, theoretically proven anonymity is not free and sometimes you have to pay for it.

