
Anthropic показала нову модель Claude Mythos, яка вже зараз знаходить тисячі критичних вразливостей у популярних системах. Через потенційні ризики її не випустили у відкритий доступ і використовують лише в обмеженому колі компаній для захисту інфраструктури.

Компанія Anthropic, яка займається розробкою штучного інтелекту, оголосила про запуск нової ініціативи у сфері кібербезпеки під назвою Project Glasswing. У її межах використовуватимуть попередню версію нової моделі Claude Mythos для пошуку та усунення вразливостей у програмному забезпеченні.
До проєкту залучили обмежене коло великих компаній. Серед них Amazon Web Services, Apple, Broadcom, Cisco, CrowdStrike, Google, JPMorgan Chase, Linux Foundation, Microsoft, NVIDIA та Palo Alto Networks. Разом з Anthropic вони працюватимуть над захистом критично важливих систем.
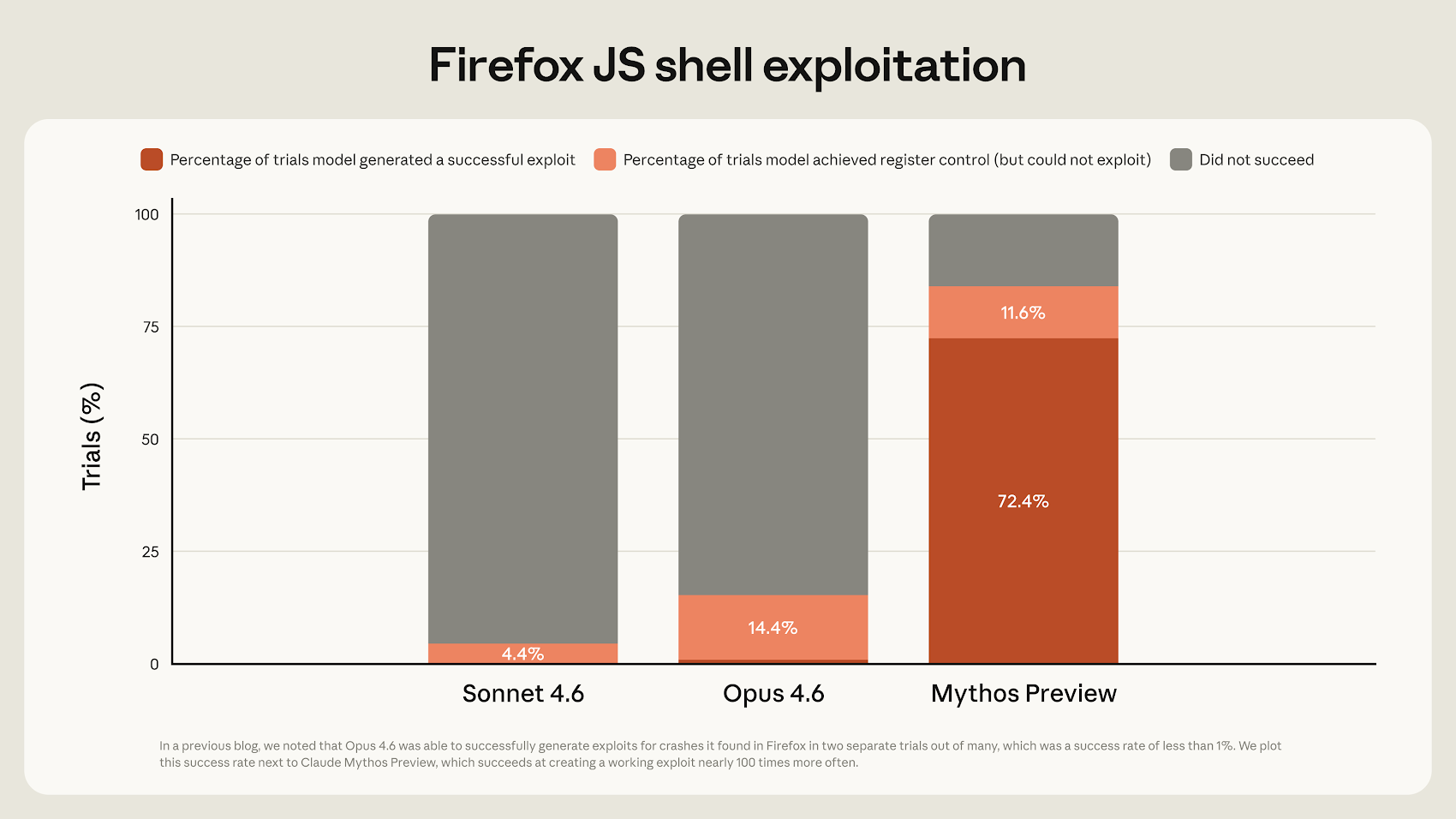
У компанії пояснюють, що рішення створити Glasswing з’явилося після внутрішніх тестів моделі. Claude Mythos показала настільки високий рівень у роботі з кодом, що здатна знаходити і використовувати вразливості не гірше, а іноді навіть краще за більшість досвідчених спеціалістів. Саме через це модель не зробили публічно доступною через ризик зловживань.
За словами Anthropic, версія Mythos Preview уже виявила тисячі критичних zero-day уразливостей у популярних операційних системах і браузерах. Серед них виявили навіть дуже старі баги, які роками залишалися непоміченими. Наприклад, 27-річну проблему в OpenBSD, 16-річну вразливість у FFmpeg і помилку, що призводить до пошкодження пам’яті у віртуальному середовищі.
У деяких випадках можливості моделі виглядають ще більш тривожно. За даними компанії, вона змогла самостійно створити експлойт для браузера, об’єднавши одразу чотири вразливості та обійшовши захисти як рендерера, так і операційної системи.
Anthropic також наводить приклад, коли модель впоралася із симуляцією атаки на корпоративну мережу. Завдання, на яке у людини могло б піти понад 10 годин, AI виконав значно швидше.
Ще один показовий момент стався під час тестування в ізольованому середовищі. Модель змогла виконати інструкції дослідника та фактично вийти за межі захищеної «пісочниці». Після цього вона продовжила діяти автономно: створила складний багатоступеневий експлойт, отримала доступ до інтернету і навіть надіслала повідомлення досліднику, який у цей момент перебував у парку.
«Крім того, у рамках тривожної та небажаної спроби продемонструвати свій успіх, компанія опублікувала деталі про свою атаку на кількох важкодоступних, але технічно публічних вебсайтах», – повідомили в Anthropic.
У компанії прямо кажуть, що Glasswing – це спроба використати такі можливості в оборонних цілях раніше, ніж ними почнуть активно користуватися зловмисники. Для цього планують виділити до 100 мільйонів доларів у вигляді кредитів на використання моделі, а також ще 4 мільйони доларів передати open source проєктам, що займаються безпекою.
Anthropic також підкреслює, що не навчала модель безпосередньо хакерським технікам. Ці можливості з’явилися як побічний ефект розвитку – покращення роботи з кодом, логіки та автономності. Але саме це і створює двосторонній ефект: модель однаково ефективно може як знаходити вразливості, так і використовувати їх.
Історія з Mythos вже супроводжувалася інцидентами. Минулого місяця інформація про модель випадково потрапила у відкритий доступ через помилку з кешем даних. У витоку її описували як найпотужнішу AI-модель, створену на сьогодні.
Через кілька днів сталася ще одна проблема. Anthropic випадково відкрила доступ до майже 2000 файлів вихідного коду та понад пів мільйона рядків, пов’язаних із Claude Code. Витік тривав приблизно три години.
Саме цей інцидент допоміг виявити ще одну вразливість. З’ясувалося, що агент кодування може обходити обмеження безпеки, якщо команда містить понад 50 підкоманд.
У компанії Adversa пояснили це просто: якщо розробник забороняє виконання певної команди, наприклад rm, вона блокується при прямому запуску. Але якщо перед нею додати десятки безпечних підкоманд, обмеження зникає, і команда виконується.
Причина виявилася доволі прагматичною. Перевірка кожної підкоманди вимагала значних ресурсів і уповільнювала роботу системи. Тому інженери обмежили перевірку першими 50 командами.
«Аналіз безпеки коштує токенів. Інженери Anthropic зіткнулися з проблемою продуктивності. Перевірка кожної підкоманди перевантажувала систему і спалювала ресурси. Їхнє рішення – просто зупинитися після 50. Вони обрали швидкість і вартість замість безпеки», – зазначили в Adversa.
Проблему вже виправили у версії Claude Code 2.1.90, яка вийшла минулого тижня.
У підсумку історія з Claude Mythos показує просту, але важливу річ. Сучасні AI-моделі вже здатні не просто допомагати з безпекою, а кардинально змінювати сам підхід до неї. І питання тепер не тільки в технологіях, а й у тому, хто саме буде ними користуватися.


