
07.05.2025
11 min
837

Learn how basic data types work in Python, including numbers, strings, and lists. These elements form the foundation for working with information in any program. In this chapter, you’ll learn how to create, modify, and effectively use the most common data structures that every Python developer needs. The training is accompanied by examples that make it easy to understand and quickly apply the knowledge.

Python has several standard data types:
Numbers
Strings
Lists
Dictionaries
Tuples
Sets
Boolean
These types of data can, in turn, be classified according to several characteristics:
mutable (lists, dictionaries, and sets)
immutable (numbers, strings, and tuples)
ordered (lists, tuples, strings, and dictionaries)
unordered (sets)
You can perform various mathematical operations with numbers.
In [1]: 1 + 2 Out[1]: 3 In [2]: 1.0 + 2 Out[2]: 3.0 In [3]: 10 - 4 Out[3]: 6 In [4]: 2**3 Out[4]: 8
Dividing int and float:
In [5]: 10/3 Out[5]: 3.3333333333333335 In [6]: 10/3.0 Out[6]: 3.3333333333333335
You can use the round function to round numbers to the desired number of characters:
In [9]: round(10/3.0, 2) Out[9]: 3.33 In [10]: round(10/3.0, 4) Out[10]: 3.3333
Remainder of distribution:
In [11]: 10 % 3 Out[11]: 1
Comparison operators
In [12]: 10 > 3.0 Out[12]: True In [13]: 10 < 3 Out[13]: False In [14]: 10 == 3 Out[14]: False In [15]: 10 == 10 Out[15]: True In [16]: 10 <= 10 Out[16]: True In [17]: 10.0 == 10 Out[17]: True
The int() function allows you to convert to the int type.
In [18]: a = '11' In [19]: int(a) Out[19]: 11
If we specify that the string a should be treated as a binary number, the result will be:
In [20]: int(a, 2) Out[20]: 3
Conversion to int of type float:
In [21]: int(3.333) Out[21]: 3 In [22]: int(3.9) Out[22]: 3
The bin function allows you to get the binary representation of a number (note that the result is a string):
In [23]: bin(8) Out[23]: '0b1000' In [24]: bin(255) Out[24]: '0b11111111'
Similarly, the hex() function allows you to get a hexadecimal value:
In [25]: hex(10) Out[25]: '0xa'
And, of course, you can do several transformations at the same time:
In [26]: int('ff', 16)
Out[26]: 255
In [27]: bin(int('ff', 16))
Out[27]: '0b11111111'
For more complex mathematical functions, Python has a math module:
In [28]: import math In [29]: math.sqrt(9) Out[29]: 3.0 In [30]: math.sqrt(10) Out[30]: 3.1622776601683795 In [31]: math.factorial(3) Out[31]: 6 In [32]: math.pi Out[32]: 3.141592653589793
A string in Python is:
a sequence of characters enclosed in quotes
an immutable ordered data type
Example lines:
In [9]: 'Hello' Out[9]: 'Hello' In [10]: "Hello" Out[10]: 'Hello' In [11]: tunnel = """ ....: interface Tunnel0 ....: ip address 10.10.10.1 255.255.255.0 ....: ip mtu 1416 ....: ip ospf hello-interval 5 ....: tunnel source FastEthernet1/0 ....: tunnel protection ipsec profile DMVPN ....: """ In [12]: tunnel Out[12]: '\ninterface Tunnel0\n ip address 10.10.10.1 255.255.255.0\n ip mtu 1416\n ip ospf hello-interval 5\n tunnel source FastEthernet1/0\n tunnel protection ipsec profile DMVPN\n' In [13]: print(tunnel) interface Tunnel0 ip address 10.10.10.1 255.255.255.0 ip mtu 1416 ip ospf hello-interval 5 tunnel source FastEthernet1/0 tunnel protection ipsec profile DMVPN
Rows can be summed. Then they are combined into one row:
In [14]: intf = 'interface' In [15]: tun = 'Tunnel0' In [16]: intf + tun Out[16]: 'interfaceTunnel0' In [17]: intf + ' ' + tun Out[17]: 'interface Tunnel0'
A string can be multiplied by a number. In this case, the string is repeated the specified number of times:
In [18]: intf * 5 Out[18]: 'interfaceinterfaceinterfaceinterfaceinterface' In [19]: '#' * 40 Out[19]: '########################################'
The fact that strings are an ordered data type allows you to access characters in a string by number, starting from zero:
In [20]: string1 = 'interface FastEthernet1/0' In [21]: string1[0] Out[21]: 'i'
All characters in a string are numbered from zero. However, if you need to refer to a specific character starting from the end, you can specify negative values (this time starting from one).
In [22]: string1[1] Out[22]: 'n' In [23]: string1[-1] Out[23]: '0'
In addition to addressing a specific character, you can slice strings by specifying a range of numbers (the slice is performed based on the second number, not including it):
In [24]: string1[0:9] Out[24]: 'interface' In [25]: string1[10:22] Out[25]: 'FastEthernet'
If the second number is not specified, the cut will be to the end of the line:
In [26]: string1[10:] Out[26]: 'FastEthernet1/0'
Cut off the last three characters of a string:
In [27]: string1[-3:] Out[27]: '1/0'
You can also specify a step in the slice. This way you can get odd numbers:
In [28]: a = '0123456789' In [29]: a[1::2] Out[29]: '13579'
And this way you can get all the even numbers in the string a:
In [31]: a[::2] Out[31]: '02468'
Slices can also be used to get a string in reverse order:
In [28]: a = '0123456789' In [29]: a[::] Out[29]: '0123456789' In [30]: a[::-1] Out[30]: '9876543210'
The entries a[::] and a give the same result, but the double colon allows you to specify that not every element should be taken, but, for example, every second one.
The function len allows you to get the number of characters in a string:
In [1]: line = 'interface Gi0/1' In [2]: len(line) Out[2]: 15
The difference between a function and a method is that a method is bound to an object of a specific type, while a function is usually more general and can be applied to objects of different types. For example, the len function can be applied to strings, lists, dictionaries, etc., while the startswith method only applies to strings.
In automation, you will often need to work with strings, as the configuration file, command output, and commands being sent are all strings. Knowing the different methods (actions) that can be applied to strings helps you work with them effectively. Strings are an immutable data type. Therefore, all methods that convert a string return a new string, and the original string remains unchanged.
The join method combines a list of strings into a single string with the separator specified before join:
In [16]: vlans = ['10', '20', '30'] In [17]: ','.join(vlans) Out[17]: '10,20,30'
The methods upper(), lower(), swapcase(), and capitalize() perform string case conversion:
In [25]: string1 = 'FastEthernet' In [26]: string1.upper() Out[26]: 'FASTETHERNET' In [27]: string1.lower() Out[27]: 'fastethernet' In [28]: string1.swapcase() Out[28]: 'fASTeTHERNET' In [29]: string2 = 'tunnel 0' In [30]: string2.capitalize() Out[30]: 'Tunnel 0'
It is very important to pay attention to the fact that methods often return a converted string. And, therefore, you must not forget to assign it to some variable (it is possible to use the same one).
In [31]: string1 = string1.upper() In [32]: print(string1) FASTETHERNET
The count() method is used to count how many times a character or substring occurs in a string:
In [33]: string1 = 'Hello, hello, hello, hello'
In [34]: string1.count('hello')
Out[34]: 3
In [35]: string1.count('ello')
Out[35]: 4
In [36]: string1.count('l')
Out[36]: 8
The find() method can be passed a substring or a character, and it will show the position of the first character of the substring (for the first match):
In [37]: string1 = 'interface FastEthernet0/1'
In [38]: string1.find('Fast')
Out[38]: 10
In [39]: string1[string1.find('Fast')::]
Out[39]: 'FastEthernet0/1'
If no match is found, the find method returns -1.
Checking whether a string begins or ends with certain characters (startswith(), endswith() methods):
In [40]: string1 = 'FastEthernet0/1'
In [41]: string1.startswith('Fast')
Out[41]: True
In [42]: string1.startswith('fast')
Out[42]: False
In [43]: string1.endswith('0/1')
Out[43]: True
In [44]: string1.endswith('0/2')
Out[44]: False
Multiple values can be passed to methods (requires a startswith() as well as an endswith() tuple):
In [1]: "test".startswith(("r", "t"))
Out[1]: True
In [2]: "test".startswith(("r", "a"))
Out[2]: False
In [3]: "rtest".startswith(("r", "a"))
Out[3]: True
In [4]: "rtest".endswith(("r", "a"))
Out[4]: False
In [5]: "rtest".endswith(("r", "t"))
Out[5]: True
Replacing a sequence of characters in a string with another sequence (replace() method):
In [45]: string1 = 'FastEthernet0/1'
In [46]: string1.replace('Fast', 'Gigabit')
Out[46]: 'GigabitEthernet0/1'
Often when processing a file, the file is opened line by line. But at the end of each line, as a rule, there are some special characters (and they can be at the beginning). For example, a line break.
In order to get rid of them, it is very convenient to use the strip() method:
In [47]: string1 = '\n\tinterface FastEthernet0/1\n'
In [48]: print(string1)
interface FastEthernet0/1
In [49]: string1
Out[49]: '\n\tinterface FastEthernet0/1\n'
In [50]: string1.strip()
Out[50]: 'interface FastEthernet0/1'
By default, the strip() method strips whitespace characters. This set of characters includes:\t\n\r\f\v
You can pass any characters as an argument to the strip method.
In [51]: ad_metric = '[110/1045]'
In [52]: ad_metric.strip('[]')
Out[52]: '110/1045'
The strip() method removes special characters from both the beginning and end of a string. If you want to remove characters only from the left or right, you can use the lstrip() and rstrip() methods, respectively.
The split() method splits a string into parts, using a character (or characters) as a separator, and returns a list of strings:
In [53]: string1 = 'switchport trunk allowed vlan 10,20,30,100-200' In [54]: commands = string1.split() In [55]: print(commands) ['switchport', 'trunk', 'allowed', 'vlan', '10,20,30,100-200']
In the example above, string1.split() splits a string of spaces and returns a list of strings. The list is stored in the command variable.
By default, whitespace characters (spaces, tabs, linefeeds) are used as delimiters, but you can specify any delimiter in parentheses:
In [56]: vlans = commands[-1].split(',')
In [57]: print(vlans)
['10', '20', '30', '100-200']
In the commands list, the last element is a string with vlans, so the index is -1. The string is then split into parts using split commands[-1].split(‘,’). Since a comma is specified as the separator, the following list is obtained.[’10’, ’20’, ’30’, ‘100-200’]
Example of dividing an address into octets:
In [10]: ip = "192.168.100.1"
In [11]: ip.split(".")
Out[11]: ['192', '168', '100', '1']
A useful feature of the split method with a default separator is that not only is the string split into a list of strings based on whitespace characters, but whitespace characters are also removed at the beginning and end of the string:
In [58]: string1 = ' switchport trunk allowed vlan 10,20,30,100-200\n\n' In [59]: string1.split() Out[59]: ['switchport', 'trunk', 'allowed', 'vlan', '10,20,30,100-200']
The split() method has another nice feature: by default, the method splits a string not on a single space character, but on any number of them. This will be very useful, for example, when processing show commands:
In [60]: sh_ip_int_br = "FastEthernet0/0 15.0.15.1 YES manual up up" In [61]: sh_ip_int_br.split() Out[61]: ['FastEthernet0/0', '15.0.15.1', 'YES', 'manual', 'up', 'up']
And this is what splitting the same line looks like when a single space is used as a separator:
In [62]: sh_ip_int_br.split(' ')
Out[62]:
['FastEthernet0/0', '', '', '', '', '', '', '', '', '', '', '', '15.0.15.1', '', '', '', '', '', '', 'YES', 'manual', 'up', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', 'up']
When working with strings, there are often situations where you need to substitute different data for a string pattern. This can be done by combining parts of the string and the data, but Python has a more convenient way – string formatting.
String formatting can help, for example, in the following situations:
need to substitute values into a string according to a specific pattern
need to format the output in columns
need to convert numbers to binary format
There are several options for formatting lines:
with the % operator – an older option
the format() method – a relatively new option
f-strings – a new option that appeared in Python 3.6.
Although it is recommended to use the format method, you can often find string formatting using the % operator.
Since a full explanation of f-strings requires examples with loops and working with objects that have not yet been considered, this topic is discussed in the section String Formatting Using f-strings with additional examples and explanations.
Example of using the format method:
In [1]: "interface FastEthernet0/{}".format('1')
Out[1]: 'interface FastEthernet0/1'
The special symbol {} indicates that the value passed to the format method will be substituted here. Each pair of curly braces indicates a place for substitution.
The values substituted into curly braces can be of different types. For example, they can be a string, a number, or a list:
In [3]: print('{}'.format('10.1.1.1'))
10.1.1.1
In [4]: print('{}'.format(100))
100
In [5]: print('{}'.format([10, 1, 1,1]))
[10, 1, 1, 1]
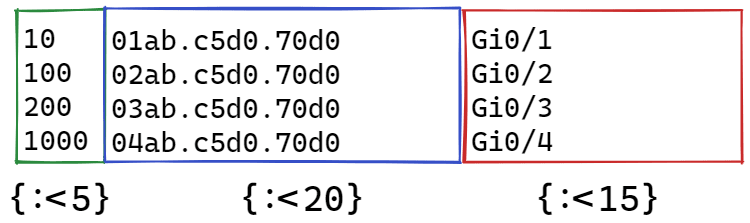
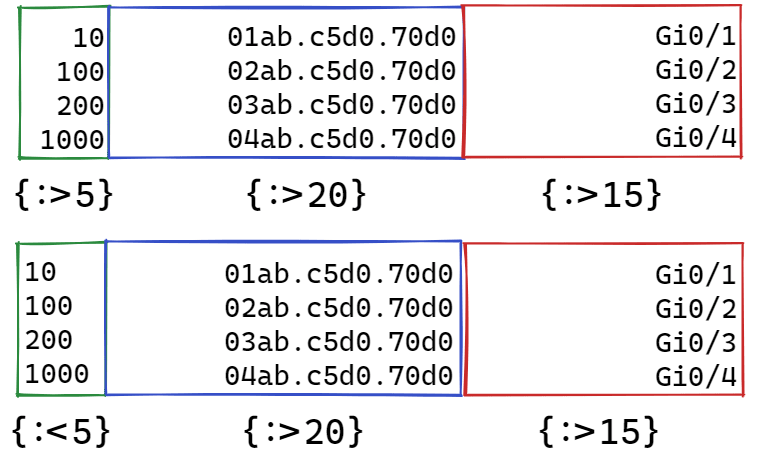
Using row formatting, you can display the result in columns. In row formatting, you can specify how many characters are allocated for the data.
For example, this way you can display the data in columns of equal width, 15 characters each, and right-aligned:
In [3]: vlan, mac, intf = ['100', 'aabb.cc80.7000', 'Gi0/1']
In [4]: print("{:>15} {:>15} {:>15}".format(vlan, mac, intf))
100 aabb.cc80.7000 Gi0/1
Left alignment:
In [5]: print("{:15} {:15} {:15}".format(vlan, mac, intf))
100 aabb.cc80.7000 Gi0/1
Examples of alignment:
The output template can also be multi-line:
ip_template = '''
IP address:
{}
'''
In [7]: print(ip_template.format('10.1.1.1'))
IP address:
10.1.1.1
You can also use string formatting to affect how numbers are displayed.
For example, you can specify how many digits after the decimal point to display:
In [9]: print("{:.3f}".format(10.0/3))
3.333
Using string formatting, you can convert numbers to binary format:
In [11]: '{:b} {:b} {:b} {:b}'.format(192, 100, 1, 1)
Out[11]: '11000000 1100100 1 1'
At the same time, as before, you can specify additional parameters, for example, column width:
In [12]: '{:8b} {:8b} {:8b} {:8b}'.format(192, 100, 1, 1)
Out[12]: '11000000 1100100 1 1'
You can also specify that numbers should be padded with zeros instead of spaces:
In [13]: '{:08b} {:08b} {:08b} {:08b}'.format(192, 100, 1, 1)
Out[13]: '11000000 01100100 00000001 00000001'
You can specify names in curly braces. This allows you to pass arguments in any order and also makes the template more understandable:
In [15]: '{ip}/{mask}'.format(mask=24, ip='10.1.1.1')
Out[15]: '10.1.1.1/24'
Another useful option for formatting strings is specifying the argument number:
In [16]: '{1}/{0}'.format(24, '10.1.1.1')
Out[16]: '10.1.1.1/24'
This, for example, can eliminate the need to repeatedly transmit the same values:
ip_template = '''
IP address:
{:<8} {:<8} {:<8} {:<8}
{:08b} {:08b} {:08b} {:08b}
'''
In [20]: print(ip_template.format(192, 100, 1, 1, 192, 100, 1, 1))
IP address:
192 100 1 1
11000000 01100100 00000001 00000001
In the example above, the address octets have to be passed twice – one for the decimal representation and the other for the binary representation.
By specifying the indices of the values passed to the format method, we can eliminate the duplication:
ip_template = '''
IP address:
{0:<8} {1:<8} {2:<8} {3:<8}
{0:08b} {1:08b} {2:08b} {3:08b}
'''
In [22]: print(ip_template.format(192, 100, 1, 1))
IP address:
192 100 1 1
11000000 01100100 00000001 00000001
Python has a very handy feature called string literal concatenation. It allows you to split strings into parts when writing code and even move those parts to different lines of code. This is necessary both to break up long text into parts due to Python’s maximum string length guidelines and for readability.
In [1]: s = ('Test' 'String')
In [2]: s
Out[2]: 'TestString'
In [3]: s = 'Test' 'String'
In [4]: s
Out[4]: 'TestString'
You can move compound lines to different lines, but if they are in parentheses:
In [5]: s = ('Test'
...: 'String')
In [6]: s
Out[6]: 'TestString'
This is very convenient to use in regular expressions:
regex = ('(\S+) +(\S+) +'
'\w+ +\w+ +'
'(up|down|administratively down) +'
'(\w+)')
This way, the regular expression can be broken down into parts and made easier to understand. Plus, you can add explanatory comments to the lines.
regex = ('(\S+) +(\S+) +' # interface and IP
'\w+ +\w+ +'
'(up|down|administratively down) +' # Status
'(\w+)') # Protocol
This technique is also convenient to use when you need to write a long message:
In [7]: message = ('За виконання команди "{}" '
...: 'виникла така помилка "{}".\n'
...: 'Виключити цю команду зі списку? [y/n]')
In [8]: message
Out[8]: 'Під час виконання команди "{}" виникла така помилка "{}".\nИсключить эту команду из списка? [y/n]'
A list in Python is:
a sequence of elements separated by commas and enclosed in square brackets
a mutable ordered data type
Examples of lists:
In [1]: list1 = [10,20,30,77] In [2]: list2 = ['one', 'dog', 'seven'] In [3]: list3 = [1, 20, 4.0, 'word']
Creating a list using a literal:
In [1]: vlans = [10, 20, 30, 50]
A literal is an expression that creates an object.
Creating a list using the list() function:
In [2]: list1 = list('router')
In [3]: print(list1)
['r', 'o', 'u', 't', 'e', 'r']
Since a list is an ordered data type, just like in strings, in lists you can access an element by number and make slices:
In [4]: list3 = [1, 20, 4.0, 'word'] In [5]: list3[1] Out[5]: 20 In [6]: list3[1::] Out[6]: [20, 4.0, 'word'] In [7]: list3[-1] Out[7]: 'word' In [8]: list3[::-1] Out[8]: ['word', 4.0, 20, 1]
You can reverse the list using the reverse() method:
In [10]: vlans = ['10', '15', '20', '30', '100-200'] In [11]: vlans.reverse() In [12]: vlans Out[12]: ['100-200', '30', '20', '15', '10']
As changes are made, list items can be modified:
In [13]: list3 Out[13]: [1, 20, 4.0, 'word'] In [14]: list3[0] = 'test' In [15]: list3 Out[15]: ['test', 20, 4.0, 'word']
You can also create a list of lists. And, just like in a regular list, you can access items in nested lists:
In [16]: interfaces = [['FastEthernet0/0', '15.0.15.1', 'YES', 'manual', 'up', 'up'], ....: ['FastEthernet0/1', '10.0.1.1', 'YES', 'manual', 'up', 'up'], ....: ['FastEthernet0/2', '10.0.2.1', 'YES', 'manual', 'up', 'down']] In [17]: interfaces[0][0] Out[17]: 'FastEthernet0/0' In [18]: interfaces[2][0] Out[18]: 'FastEthernet0/2' In [19]: interfaces[2][1] Out[19]: '10.0.2.1'
The len function returns the number of elements in a list:
In [1]: items = [1, 2, 3] In [2]: len(items) Out[2]: 3
And the sorted function sorts the elements of the list in ascending order and returns a new list with the sorted elements:
In [1]: names = ['John', 'Michael', 'Antony'] In [2]: sorted(names) Out[2]: ['Antony', 'John', 'Michael']
A list is a mutable data type, so it is very important to pay attention to the fact that most methods for working with lists modify the list in place, without returning anything.
appendThe append method adds the specified element to the end of the list:
In [18]: vlans = ['10', '20', '30', '100-200']
In [19]: vlans.append('300')
In [20]: vlans
Out[20]: ['10', '20', '30', '100-200', '300']
The append method modifies the list in place and returns nothing. If your script needs to append an item to a list and then print the list, you need to do this on different lines of code.
extendIf you want to combine two lists, there are two ways to do it: the extend method and the addition operation. There is an important difference between these methods – extend modifies the list to which the method is applied, while addition returns a new list consisting of two.
The extend method:
In [21]: vlans = ['10', '20', '30', '100-200'] In [22]: vlans2 = ['300', '400', '500'] In [23]: vlans.extend(vlans2) In [24]: vlans Out[24]: ['10', '20', '30', '100-200', '300', '400', '500']
Summarizing the lists:
In [27]: vlans = ['10', '20', '30', '100-200'] In [28]: vlans2 = ['300', '400', '500'] In [29]: vlans + vlans2 Out[29]: ['10', '20', '30', '100-200', '300', '400', '500']
Notice that when summing lists in ipython, the Out line appeared. This means that the result of the summing can be assigned to a variable:
In [30]: result = vlans + vlans2 In [31]: result Out[31]: ['10', '20', '30', '100-200', '300', '400', '500']
popThe pop method removes the element that matches the specified number. But importantly, the method returns that element:
In [28]: vlans = ['10', '20', '30', '100-200'] In [29]: vlans.pop(-1) Out[29]: '100-200' In [30]: vlans Out[30]: ['10', '20', '30']
Without specifying a number, the last item in the list is deleted.
removeThe remove method removes the specified element.
remove() does not return the removed element:
In [31]: vlans = ['10', '20', '30', '100-200']
In [32]: vlans.remove('20')
In [33]: vlans
Out[33]: ['10', '30', '100-200']
In the remove method, you must specify the element to be removed, not its number in the list. If you specify the element number, an error will occur:
In [34]: vlans.remove(-1) ------------------------------------------------- ValueError Traceback (most recent call last) <ipython-input-32-f4ee38810cb7> in <module>() ----> 1 vlans.remove(-1) ValueError: list.remove(x): x not in list
indexThe index method is used to check the number under which an element is stored in the list:
In [35]: vlans = ['10', '20', '30', '100-200']
In [36]: vlans.index('30')
Out[36]: 2
insertThe insert method allows you to insert an element at a specific location in a list:
In [37]: vlans = ['10', '20', '30', '100-200'] In [38]: vlans.insert(1, '15') In [39]: vlans Out[39]: ['10', '15', '20', '30', '100-200']
sortThe sort method sorts the list in place:
In [40]: vlans = [1, 50, 10, 15] In [41]: vlans.sort() In [42]: vlans Out[42]: [1, 10, 15, 50]
Python data types are the foundation for efficient coding, data processing, and automation of routine tasks. In this article, we’ve covered the key categories of built-in types: numbers, strings, lists, dictionaries, tuples, sets, and booleans. For each data type, we’ve provided examples of operations, methods, conversions, and formatting features.
Understanding which types are mutable or immutable, ordered or unordered, helps you write reliable, readable, and scalable code. With hands-on examples from IPython and hands-on tasks, each chapter is not just theoretical, but directly useful in everyday development and automation of network or system scenarios.
Knowing the basics of data types opens the door to more advanced Python topics: functions, classes, file processing, working with APIs, and libraries like Pandas or NumPy. Use this foundation as a launching pad for your further growth in Python.

