
04.09.2023
2 хв
1976

Доменні притиви є невід’ємною частиною Інтернету, що визначають його архітектуру та легкість використання. Ці ключові компоненти допомагають нам навігувати в безмежних просторах мережі та знаходити веб-ресурси, які нам потрібні. Без них функціонування Інтернету стало б значно менш зручним та складним. Основна Роль Доменних Притивів: Ідентифікація та Зручність: Доменні притиви надають текстові та легкі для запам’ятовування ідентифікатори веб-ресурсів, що робить навігацію в Інтернеті зручною.

Вони дозволяють нам використовувати звичайні слова та фрази, а не складні числові IP-адреси. Унікальність: Кожне доменне ім’я унікальне в мережі, що гарантує, що два різні ресурси не матимуть однакового імені. Це важливо для уникнення конфліктів та забезпечення однозначності ідентифікації. Структура Доменних Притивів: Доменні притиви складаються з двох частин: другорядного домена (наприклад, “example”) та верхнього рівня домена (наприклад, “.com”). Ця структура розділяє доменні імена на логічні категорії та визначає їхню організацію в мережі. Загальне Застосування Доменних Притивів: Доменні притиви використовуються в усіх аспектах Інтернету, від веб-переглядачів та електронної пошти до веб-розробки та онлайн-торгівлі. Вони стали невід’ємною частиною нашого цифрового життя, допомагаючи нам знаходити інформацію, з’єднуватися з іншими та розвивати бізнес в онлайн-середовищі. Зрозуміння ролі та значення доменних притивів є важливим для всіх, хто бажає мати успішний присутній в Інтернеті, будь то як користувач чи фахівець у сфері інформаційних технологій.
У розділі 4 вас познайомили з потужними принципами проектування, такими як незмінність, швидке завершення роботи та перевірка. Вони допомагають боротися з різними проблемами безпеки, включаючи неправильне введення, недійсний стан і порушення цілісності даних. Однак використання їх окремо не є ефективним способом написання захищеного коду. У табл. На рисунку 5.1 перераховані проблемні області, які ми обговоримо в цьому розділі, і концепції, що дозволяють досягти більш високого рівня безпеки.

Ця глава присвячена створенню концепції вищого порядку, званої примітивом домену, яка поєднує в собі принципи безпеки і об’єкти цінності, будучи при цьому найменшим складовим елементом предметної області. Тут ви дізнаєтеся, як поліпшити свій код за допомогою дизайнерських рішень, які покращують безпеку на декількох рівнях одночасно, надаючи системі ясність і допомагаючи вам краще орієнтуватися в ній. Ви також дізнаєтесь, Як використовувати примітиви домену для спрощення сутностей і організації виявлення ненавмисного витоку конфіденційних даних. Отже, поговоримо про примітиви і інваріанти домену.
Об’єкти-значення в доменно-орієнтованому проектуванні незмінні і утворюють цілісне поняття – це їх ключові властивості. Як показує наш досвід, якщо ціннісний об’єкт трохи оптимізувати з акцентом на безпеку, то вийде так званий примітив домену.
Почавши використовувати примітиви домену як найменший будівельний блок вашої моделі домену, ви зможете написати код, який набагато рідше матиме проблеми з безпекою, ніж зазвичай. Це досягається виключно завдяки тому, як ви його проектуєте. Код вийде точним і без будь-якої невизначеності. Він буде містити менше дефектів і, як наслідок, менше вразливостей. Вам буде простіше з ним працювати, так як примітиви домену – це менше когнітивне навантаження на розробників. Далі в цьому розділі ми спробуємо пояснити, що таке примітиви домену, як їх визначати і як з ними створювати безпечне програмне забезпечення.
Об’єкт value представляє важливу концепцію вашої моделі домену. У процесі моделювання ви вирішуєте, як буде виглядати об’єкт цінності і як він буде називатися. Але якщо піти далі і спробувати визначити, що це таке, а що ні, то можна отримати набагато глибше розуміння цього поняття. На основі цих знань ви зможете додавати інваріанти, дотримання яких дозволить вважати значення об’єкта допустимим. Потім можна зробити дотримання цих інваріантів обов’язковим і забезпечити його ще на етапі створення. В результаті у вас буде настільки суворе визначення об’єкта-значення, що саме його існування підтвердить його справедливість. Якщо він недійсний, то не може бути в принципі. Такого роду об’єкти значень називаються примітивами домену.
Примітиви домену схожі на об’єкти значень в дизайні для конкретної доменної області. Їх ключова відмінність полягає в тому, що вони вимагають наявності інваріантів, які необхідно застосовувати ще на етапі створення. Вони також виключають використання простих примітивів або стандартних типів (включаючи null) мови програмування для представлення понять моделі предметної області. Також варто відзначити, що, незважаючи на свою назву, вони можуть бути досить складними об’єктами, містять нетривіальну логіку та інші примітиви предметної області.
ПРИМІТКА. У моделі предметної області ніщо не повинно бути представлено примітивами або стандартними типами мови програмування. Кожне поняття повинно бути змодельовано як примітивний предметної області, щоб воно зберігало своє значення при передачі і могло застосовувати його інваріанти.
Уявіть, що у вашій моделі домену є поняття кількості. Нехай це буде кількість певного товару, яке клієнт хоче купити в інтернет-магазині, який ви розробляєте. Це число саме по собі, але замість використання стандартного цілочисельного типу ми створимо примітивний домен під назвою Кількість. Під час його визначення ви спілкуєтеся з профільними експертами і намагаєтеся з’ясувати, що, на їхню думку, є правильною величиною. В ході обговорення з’ясовується, що правильна величина є цілим числом в діапазоні від 1 до 200. Він не може бути нульовим, так як замовлення, при якому клієнт хоче купити нуль одиниць товару, існувати не повинно. Негативні значення також неприпустимі, так як товар не можна купити «задом наперед», а його повернення обробляється окремо. Замовлення, що містять більше 200 товарів, системою не приймаються. Це вкрай рідкісний випадок, якщо він виникає, до нього потрібно ставитися з особливою увагою: в таких ситуаціях клієнти звертаються безпосередньо до торгового представника, минаючи інтернет-магазин.
Ви інкапсулюєте важливі аспекти поведінки примітиву домену, такі як додавання та віднімання одиниць товару. Оскільки примітивний домен володіє і управляє операціями домену, існує менша ймовірність помилок програмного забезпечення, викликаних нерозумінням понять, що беруть участь в операції. Чим більш віддалені такі операції від поняття, тим менш детальної інформації про нього можна очікувати, тому логічно проводити всі операції домену всередині компанії сам примітив домену. Наведемо приклад. Уявімо, що потрібно скласти дві одиниці товару. Ви створюєте метод додавання, але його реалізація повинна враховувати правила домену щодо кількості — пам’ятайте, що ви не маєте справу зі звичайними цілими числами. Якщо розмістити метод додавання в якусь іншу частину кодової бази, наприклад клас утиліти Functions, в нього легко можуть закрастися неочевидні дефекти. Якщо ви вирішили трохи змінити поведінку примітиву домену Quantity , можливо, ви забудете оновити відповідний метод в класі утиліти. Шанси на те, що це станеться, високі, і якщо це станеться, ви отримаєте помилку, яку важко виявити, яка може спричинити серйозні проблеми. Коли ви закінчите роботу над примітивом домену Кількість, ваша реалізація повинна виглядати так, як показано в лістингу 5.1.

Вона являє собою точну і неухильну реалізацію концепції кількості. При дослідженні анти-«Гамлета» в главі 2 був приведений приклад того, як невелика невизначеність в системі може закінчитися тим, що клієнти дають собі знижки, вказуючи на негативну кількість товару перед оформленням замовлення. Примітивний домен, подібний до раніше введеного Кількість, виключає ймовірність того, що недобросовісний користувач вкаже негативне значення і змусить систему вести себе ненавмисно. Використання примітивів домену усуває уразливість, не вимагаючи явних контрзаходів. Як показує ця вправа, кількість – це не просто ціле число. Він повинен бути змодельований і реалізований як примітивна область, щоб зберегти своє значення при передачі і спостерігати його інваріанти.
Поки що ви маєте загальне уявлення про примітивний домен. Тепер поговоримо про те, навіщо необхідно визначати сферу, в рамках якої вона діє.
Примітиви домену, як і ціннісні об’єкти, визначаються їх змістом, а не ідентифікатором. Це означає, що два примітиви домену одного типу і з однаковим значенням взаємозамінні. Вони ідеально підходять для представлення найрізноманітніших концепцій предметної області, які не можуть бути класифіковані як сутності або агрегати. Одним з важливих аспектів, який слід враховувати при моделюванні поняття з використанням примітиву предметної області, є те, що визначення примітиву повинно точно відображати значення цього поняття в контексті поточної предметної області.
Уявіть, що ви розробляєте систему, яка дає користувачам можливість вибирати і створювати власні адреси електронної пошти. Користувач може вибрати локальну частину адреси (та, що ліворуч від @) і використовувати створену адресу для відправки і отримання електронних листів. Якщо ви введете jane.doe, буде згенеровано адресу [email protected] (за умови, що ваше доменне ім’я example.com). Моделюючи, ви розумієте, що адреса електронної пошти є прекрасним прикладом примітиву домену. Вона визначається її величиною, і можна передбачити певні обмеження, які дають можливість бути впевненими в її дійсності.
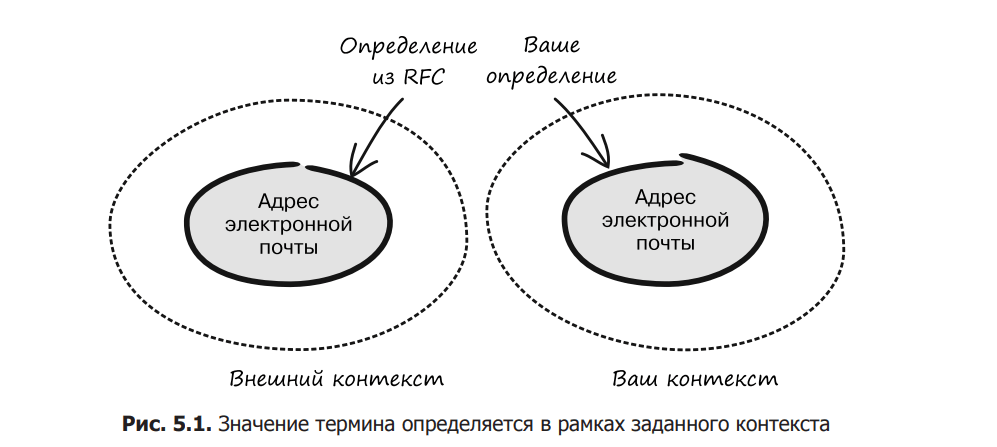
На початку, щоб визначити, що являє собою дійсна адреса електронної пошти, ви можете схилитися до використання офіційного визначення. Формально це було б правильним рішенням з точки зору відповідності вимогам РФК, але в контексті існуючої предметної області дане визначення може бути некоректним (рис. 5.1). Для вас, як для інженера, це може стати несподіванкою. Але пам’ятайте, що нас цікавить значення поняття в певній предметній області, а не те, яке значення воно може мати в іншому контексті, наприклад, глобальному стандарті. Наприклад, у вашому випадку адреси електронної пошти можуть містити великі та малі літери, тому все, що вводить користувач, буде малим. Ви можете піти ще далі і сказати, що дозволені лише алфавітні символи, цифри та крапки ASCII ([a-z0-9.].). Це було б відхиленням від технічної специфікації, але в контексті даної предметної області таке рішення можна вважати правильним.
Буває, що назва концепції, яку ви намагаєтеся змоделювати, використовується поза поточним контекстом, і це зовнішнє визначення настільки поширене, що заміна його у вашій моделі предметної області призведе до плутанини. Таким поняттям може бути адреса електронної пошти, але, як ми тільки що дізналися, іноді має сенс перевизначити його в його поточному контексті.
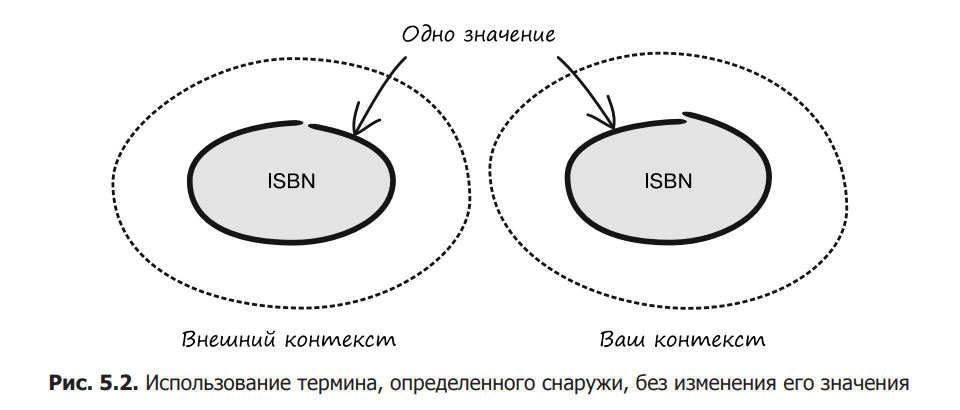
Іншим прикладом чітко визначеної концепції є номер ISBN. Цей формат описується Міжнародною організацією зі стандартизації (ISO), і його перевизначення може призвести до плутанини, неправильного тлумачення та помилок програмного забезпечення. Такого роду незначні відмінності часто викликають проблеми з безпекою, і їх слід уникати, особливо при взаємодії з іншими системами або контекстами домену (див. Рисунок 5.2).
У більшості випадків необхідність перевизначення загальновідомих понять обумовлена тим, що кілька речей в нинішньому контексті описуються за допомогою одного і того ж поняття. У таких ситуаціях спробуйте або розділити поняття на дві частини, або придумати абсолютно новий термін, унікальний для нинішнього контексту. Це дозволить уникнути неправильних тлумачень, а також зробить очевидною причину застосування тих чи інших інваріантів замість тих, які відносяться до терміна, визначеного зовні. Ще одна перевага введення нового поняття полягає в тому, що вихідне поняття зберігає своє чітке визначення і залишається примітивом предметної області. Ви повністю зберегли здатність моделювати важливі поняття в своїй предметній області, і при цьому модель не втратила точності.
Уявіть, що ви розробляєте програмне забезпечення для управління книжковою торгівлею, яке використовує номери ISBN для ідентифікації. Через деякий час розумієш, що потрібно якось працювати з книгами, яким ще не присвоєно номер ISBN. Одним з рішень було б перевизначити термін ISBN таким чином, щоб він не тільки представляв дійсні числа, але і включав внутрішні ідентифікатори, які можуть, наприклад, мати «магічний префікс», щоб їх можна було відрізнити від справжніх ISBN. Але щоб уникнути плутанини, яка виникає при перевизначенні стандарту ISO, можна ввести нову концепцію BookId, яка містила б або ISBN, або UnpublishedBookNumber (рисунок 5.3). BookId – це загальний ідентифікатор книги, а UnpublishedBookNumber – це ідентифікатор, який призначається книгою внутрішньо.
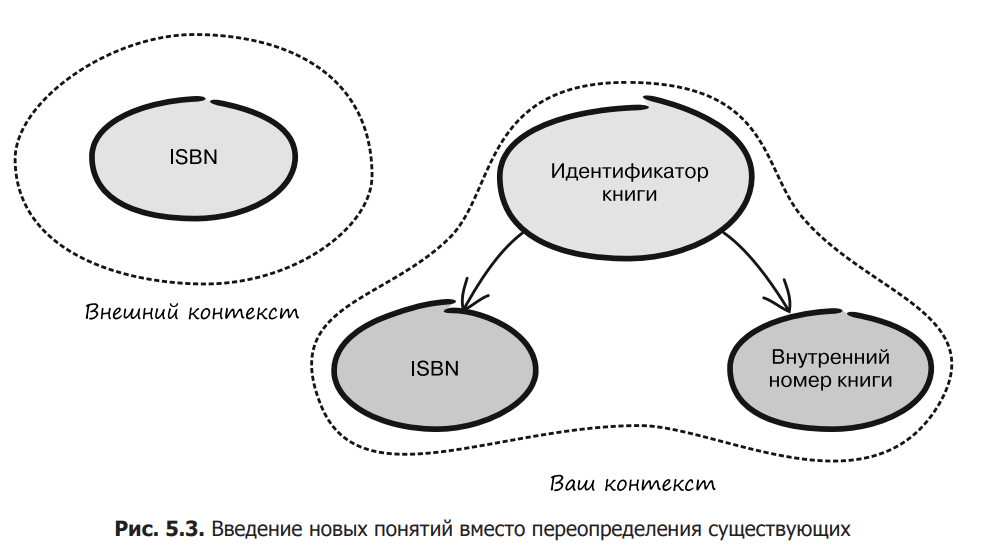
З введенням двох нових термінів, BookId і UnpublishedBookNumber, ви можете використовувати точне відоме визначення ISBN і в той же час відповідати бізнес-вимогам вашої предметної області.
Отже, ви розширили спектр доступних вам концепцій за рахунок універсальності примітивів домену. Постарайтеся використовувати їх якомога більше в своєму коді. Це найменші стандартні блоки, які складають основу моделі домену. Через це практично будь-яка концепція, яку ви моделюєте, буде заснована на одному або декількох примітивах домену. В ході моделювання у вашому розпорядженні колекція примітивів домену, яку можна розглядати як бібліотеку. Це не просто набір загальних класів і методів корисності, а скоріше чітко визначений, уніфікований набір понять предметної області. А оскільки вони є примітивами домену, їх можна сміливо передавати як аргументи у вашому коді як звичайні об’єкти значень.
Примітиви доменів знижують когнітивне навантаження на розробників, адже їм не потрібно розуміти, як вони працюють. З ними можна працювати безпечно і бути впевненим, що в них завжди присутні правильні цінності і чіткі поняття. Неприпустимий примітивний домен просто існувати не може. Це позбавляє від необхідності постійно перевіряти дані, щоб переконатися, що вони безпечні у використанні. Якщо вони визначені у вашій предметній області, ви можете довіряти їм і вільно ними користуватися.
Більш надійні API на основі бібліотеки Domain Primitive
Ви завжди повинні намагатися використовувати примітиви домену у своїх API. Якщо всі аргументи та значення, що повертаються, правильні за визначенням, ви отримуєте перевірку введення та виводу в кожному методі вашої кодової бази без додаткових зусиль. Такий підхід до дизайну доменів дозволить писати надзвичайно стійкий і надійний код. Як позитивний побічний ефект відзначимо, що кількість вразливостей безпеки, викликаних неправильним введенням, значно зменшується.
Поговоримо про це докладніше на прикладі конкретного коду. Уявіть, що вам доручено перемістити журнал аудиту системи до центрального сховища. Журнали аудиту містять конфіденційну інформацію, тому їх потрібно зберігати в спеціальному місці, де вони будуть належним чином захищені. Якщо відправити дані не туди, куди потрібно, у компанії можуть виникнути серйозні проблеми. Ваш API може мати метод, подібний до наступного: що приймає поточний журнал аудиту та надсилає його до репозиторію за вказаною адресою: void sendAuditLogsToServerAt(java.net.InetAddress serverAddress);
Проблема тут полягає в тому, що підпис цього методу дозволяє вказати будь-яку IP-адресу як місце призначення журналу. Якщо ви не можете автентифікувати адресу перед надсиланням журналу, ви можете розкрити конфіденційні дані, надіславши їх у незахищене місце. Замість цього можна створити примітивний домен під назвою InternalAddress, який чітко визначає, що таке внутрішній IP-адреса. Ви можете використовувати його як вхідний тип параметра у вашому методі. Застосувавши це Для підходу до методу sendAuditLogsToServerAt ви отримуєте наступний код, як показано в Listing 5.2.

Поки що ви розробили метод таким чином, що неможливо передати йому неправильне введення. Щоб переконатися, що IP-адреса внутрішня, залишається тільки перевірити, чи є вона нульовою.
Щоб підвищити надійність API, який служить вікном в інший домен, не слід виставляти свої моделі доменів через нього. Інакше модель домену автоматично стане частиною загальнодоступного API. І як тільки його починають використовувати інші предметні області, стає складно самостійно змінювати і розвивати свою модель.
Прикладом публічного API, який працює з різними доменами, є REST API, який доступний для використання в Інтернеті за допомогою клієнтського програмного забезпечення. Якщо ви відкриєте доступ до свого домену через REST API, то для подальшого розвитку вашої моделі домену клієнтам програмного забезпечення потрібно буде підтримувати всі внесені вами зміни. Якщо компанія залежить від цих клієнтів, ігнорувати їх не вийде: нічого не залишиться, як синхронізувати процес розробки зі споживачами, щоб вони встигли адаптувати своє клієнтське програмне забезпечення. Що ще гірше, якщо таких споживачів кілька, доведеться не тільки синхронізувати з кожним з них, але і синхронізувати їх між собою. Така ситуація далека від ідеальної, і уникнути її можна, якщо не відкрити публічний доступ до своєї предметної області.
Замість цього краще використовувати різні подання для кожного з об’єктів домену. Це можна розглядати як свого роду об’єкт передачі даних (DTO), який використовується для взаємодії з іншими предметними областями. Такі DTO можуть містити інваріанти, але вони будуть відрізнятися від обмежень у вашій моделі домену. Наприклад, вони можуть обмежити протокол зв’язку, визначений в API. Перше, що потрібно зробити в такому методі API – перетворити DTO у відповідний примітив домену (або примітиви), щоб переконатися в правильності даних. Цей шар абстракції допомагає розділити поняття вашого публічного API та домену, дозволяючи розробляти їх незалежно один від одного.
У цьому розділі розглядається безліч важливих особливостей, властивих примітивам доменів.
Перш ніж рухатися далі, давайте перерахуємо ключові моменти.
Інваріанти у доменних примітивах перевіряються на етапі створення.
Існувати можуть лише дійсні доменні примітиви.
Замість примітивів і стандартних типів мови програмування завжди слід використовувати доменні примітиви.
Сенс доменних примітивів визначається в рамках поточної предметної галузі, навіть якщо за її межами термін має інше значення.
Для написання безпечного коду слід використовувати власну бібліотеку доменних примітивів.
На даний момент ми вже знаємо, що таке незмінність, швидке відключення, перевірка та примітиви домену, і як кожна з цих концепцій сприяє безпеці на рівні дизайну. У програмуванні існує ще одне поняття, яке відіграє важливу роль з точки зору безпеки – одноразово зчитувані об’єкти. Про них ми і поговоримо далі.
Одним із поширених джерел проблем із безпекою програмного забезпечення є витік конфіденційних даних. Воно може бути як ненавмисним, викликаним забудовником, так і навмисно спровокованим. Незалежно від причини виникнення цієї проблеми, з нею можна боротися декількома дизайнерськими прийомами. Давайте подивимося, як шаблон оформлення «Разовий читець» може знизити ймовірність витоку конфіденційної інформації.
Ось список ключових особливостей, властивих цим об’єктам.
Їхнє основне призначення полягає у сприянні виявленню ненавмисного використання даних.
Вони представляють конфіденційні значення чи концепції.
Найчастіше вони є доменними примітивами.
Їхнє значення можна прочитати один і лише один раз.
Вони запобігають серіалізації конфіденційних даних.
Вони запобігають успадкування та розширення.
Одноразовий об’єкт читання, як зрозуміло з назви, призначений для прочитання рівно один раз. Зазвичай він представляє значення або поняття вашої предметної області, яка вважається конфіденційною, наприклад, номери паспортів та кредитних карток або паролі. Основне призначення одноразового об’єкта читання полягає в тому, щоб допомогти виявити ненавмисне використання даних, які він інкапсулює. Часто він має вигляд доменного примітиву, Він також може бути застосований до сутностей і агрегатів. Основний момент тут полягає в тому, що після створення об’єкта дані, інкапсульовані ним, можуть бути отримані лише один раз. Спроба отримати призведе до помилки. Цей об’єкт також вживає певних заходів проти вилучення конфіденційних даних під час процесу серіалізації.
Лістинг 5.3 показує приклад одноразового об’єкта читання. Як бачите, називається він SensitiveValue і моделюється як примітив домену, всі інваріанти якого перевіряються на етапі створення. Клас визначається як кінцевий для запобігання успадкування, а значення обгортається в AtomicReference. Коли викликається аксесуар значень, повертається конфіденційне значення, а потім встановлюється значення nullЯкщо метод значень вже викликався, його попереднє значення дорівнює Null, що призводить до винятку.
Цей об’єкт також реалізує інтерфейс java.io.Externalizable і завжди кидає виняток, щоб запобігти ненавмисній серіалізації. Оголошення поля значення визначає перехідне ключове слово, якщо ви використовуєте бібліотеку, яка звертається безпосередньо до поля замість стандартних інструментів серіалізації Java, але все ще поважає перехідне ключове слово . Як останній захід, метод toString реалізований таким чином, що його не можна використовувати для отримання реального значення.


Щоб краще зрозуміти переваги цієї моделі проектування, розглянемо ситуацію, в якій одноразове читання об’єкта може запобігти ненавмисному розголошенню конфіденційних даних.
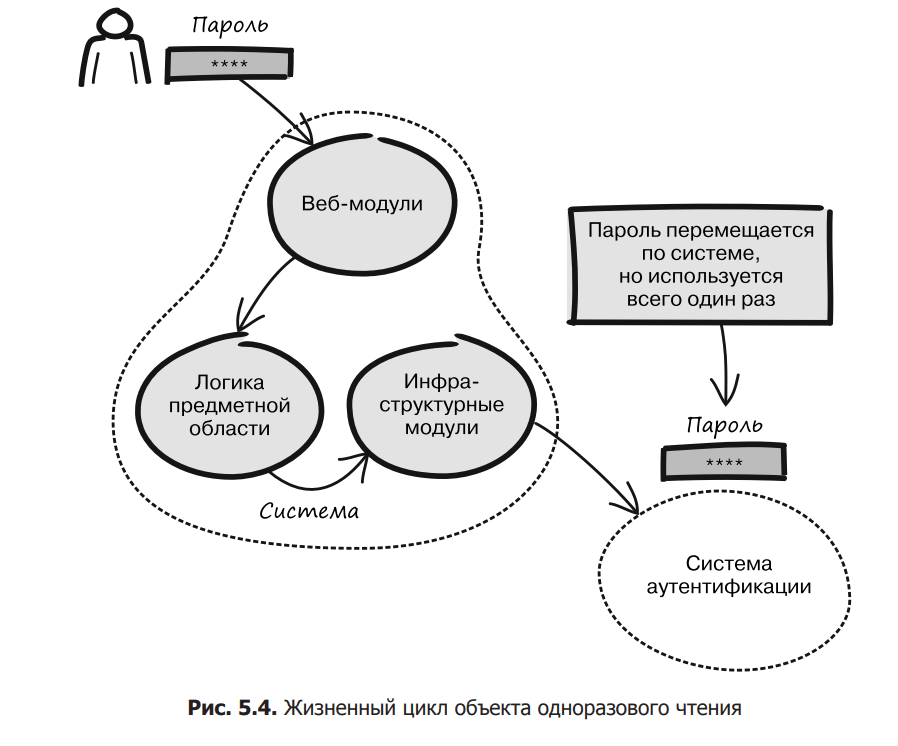
Уявіть, що ви розробляєте простий механізм входу, при якому для аутентифікації вводяться логін і пароль. Потім називається інший механізм, який відповідає за перевірку наданих облікових даних, система аутентифікації. Потрапивши в систему, пароль повинен використовуватися виключно для аутентифікації і ніяк інакше (рис. 5.4). Це означає, що пароль потрібно отримати лише один раз, коли він буде переданий до системи аутентифікації. Після цього зберігати його в будь-якому місці вже немає сенсу.
Паролі є типовим прикладом конфіденційних даних. Пароль користувача ніколи не повинен потрапляти в якийсь звичайний текстовий файл журналу, де будь-хто може його прочитати, або в повідомленні про помилку в браузері користувача, або на інформаційній панелі, де його буде видно інженерам з експлуатації. Якщо ви змоделюєте пароль як примітивний домен і реалізуєте його як одноразовий об’єкт читання, ви отримаєте механізм безпеки, який дозволить вам знати, якщо пароль почне якимось чином просочуватися. Це проілюстровано в Лістингу 5.4.

У цій реалізації, якщо пароль використовується ненавмисно, спроба перевірити облікові дані за допомогою системи автентифікації призводить до повідомлення про помилку, подібного до такого: Значення пароля вже витрачено. Наприклад, ненавмисне використання може статися в записі журналу або призвести до винятку, який випадково містить пароль. Такого роду помилка програмування, Швидше за все, буде виявлено рано завдяки невдалому тесту у вашому конвеєрі доставки. Якщо цього не відбудеться, неможливість авторизації буде швидко виявлена у виробничому середовищі, і зрозуміти, що відбувається з повідомлення про помилку, має бути досить легко.
Якщо ви отримуєте значення за допомогою аксесуара значень, одноразове зчитування об’єкта не запобіжить витоку даних, але полегшить виявлення, якщо воно відбувається. Застосовуючи рекомендовані підходи до розробки та маючи повний набір тестів, ви, ймовірно, зможете уникнути витоків у вашому виробничому середовищі.
Дізнатися більше про клас Password
Об’єкт Password, показаний у списку 5.4, схожий на об’єкт SensitiveValue, який ви бачили раніше. Але у нього є кілька особливостей, на які варто звернути увагу. Ці особливості пов’язані з тим, як JVM управляє пам’яттю. Давайте перерахуємо їх, щоб ви могли зосередитися на них, але не будемо вдаватися в подробиці.
Поле значення тепер є масивом char, а не рядком. Це пояснюється тим, що його потрібно чистити після використання. З цієї ж причини вхідний масив клонується, що гарантує, що ви не зможете порушити логіку очищення, що виконується кодом, який викликається конструктором Password, і навпаки. Оскільки ми більше не використовуємо AtomicReference, логічний прапорець використовується в поєднанні із синхронізованим аксесуаром для відстеження споживаного значення безпечним способом.
Коли значення споживається за допомогою аксесуара значень, повертається копія внутрішнього масиву char, яка потім очищається. Знову ж таки, створюється копія пройденого масиву, щоб клас Password міг обробляти конфіденційні дані, не впливаючи на решту коду. Абоненти та одержувачі за межами цього класу також повинні видалити будь-які посилання на пароль.
Все це робиться для обмеження доступу до чутливих значень в пам’яті JVM. При бажанні ці поняття можна розвинути, але нам здається, що ці приклади дають досить непоганий результат при відносно невеликих зусиллях і в розробці на Java такий підхід слід вважати рекомендованим.
Інша ситуація, в якій ви можете легко запобігти ненавмисному витоку даних, – це переробка та ремоделювання коду. Ми самі час від часу стикаємося з цим, і завдяки використанню одноразових предметів для читання нам вдається виявити витік і запобігти її потраплянню в промислове середовище. Давайте розглянемо випадок, з яким ми зіткнулися в своїй роботі, але змінимо деякі деталі, щоб нікого не компрометувати.
Уявіть, що ви розробляєте веб-додаток, в якому код часто потребує доступу до інформації про поточного аутентифікованого користувача. Необхідна інформація розташовується в об’єкті домену Користувача. У якийсь момент розробники вирішують помістити цей об’єкт у веб-сесію, щоб полегшити доступ і використання в якості кешу. Це рішення працює за призначенням і приносить необхідні нам переваги. Пізніше, в результаті появи нових вимог до бізнесу Об’єктна модель домену користувача модифікована для додавання номера соціального страхування (SSN) (рисунок 5.5). Цей номер реалізований як одноразовий об’єкт SSN, оскільки його слід використовувати лише один раз.
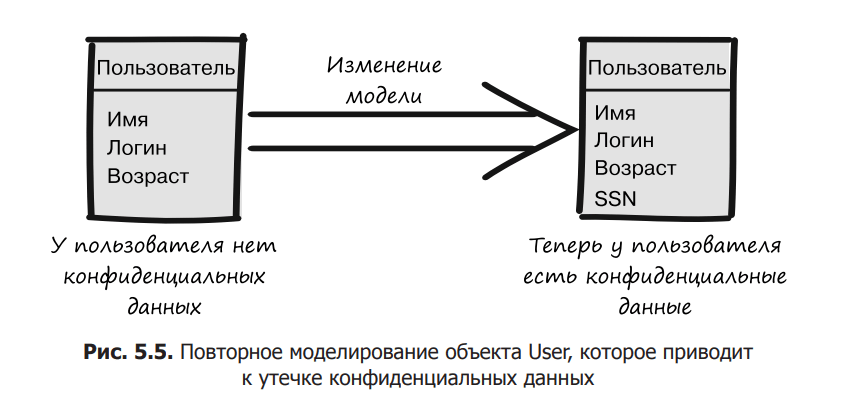
Нова модель домену враховує нові вимоги, і всі тести в наборі проходять успішно. Однак під час приймального тестування в проміжному середовищі ви випадково помічаєте, що коли програма вимикається, вона завжди виводить якісь результати трасування стека, включаючи повідомлення про помилку на кшталт “Операція недійсного чутливого значення”. Коли ви переглядаєте цей вихід, ви можете побачити, що цей виняток викликаний спробою серіалізації SSN. Щось намагається серіалізувати конфіденційні дані. Ви, розгубившись, починаєте шукати причину такої поведінки. Через деякий час з’ясовується, що серіалізація ініціюється веб-сервером Tomcat, який ви використовуєте. Це пов’язано з тим, що за замовчуванням, коли Tomcat вимикається або перезавантажується, він зберігає всі активні сеанси на диск. Якщо ви помістите будь-які конфіденційні дані в сеанс, не вимикаючи його, вони можуть опинитися у файлі та бути доступними для читання будь-ким, хто має доступ до диска. Це прекрасний приклад розкриття конфіденційної інформації без явного дозволу.
Такі витоки даних в програмних системах не рідкість і практично завжди відбуваються через ненавмисну помилку: розробник або не замислювався про наслідки, або зовсім не знав про них (можливо, тому, що код, над яким він працював, знаходився далеко від того місця, де створювалися конфіденційні дані). Використовуючи одноразові читабельні можливості в дизайні, ви можете зосередитися на своїх безпосередніх завданнях, не турбуючись про безпеку.
Поки що ви дізналися, що таке примітиви домену і як їх реалізувати. Тепер давайте подивимося, яку роль вони відіграють в іншій частині коду. Наприклад, як допомогти підвищити безпеку інших компонентів, зокрема сутностей.
Якщо ви не використовуєте примітиви домену, то інша частина коду повинна займатися валідацією, форматуванням, порівнянням і багатьма іншими речами. Організації представляють довгострокові об’єкти з відомими ідентифікаторами, такими як статті стрічки новин, номери в готелях або кошики для покупок електронної комерції. Функціональність системи часто концентрується навколо зміни стану цих об’єктів: бронюються номери, оплачується вміст кошика для покупок і т.д. Рано чи пізно нитка виконання прийде до коду, який представляє ці сутності. І якщо всі дані передаються у вигляді стандартних типів, такі як int або String, відповідальність за їх перевірку, порівняння, форматування тощо лягає на саму сутність. Його код матиме багато обов’язків, і він не зможе повністю зосередитися на змінах стану, який моделює. Використання примітивів доменів дозволяє боротися з цією тенденцією і запобігати надмірну складність сутностей.
У процесі розробки класи сутностей багаторазово реалізуються, розширюються і модифікуються. Вони легко можуть залучити додатковий функціонал, в результаті чого їх методи перетворюються в купи коду з декількох сотень рядків, заповнені вкладеними блоками for і if. Ми неодноразово знаходили вразливості безпеки, викликані локальними змінами, які не враховували всіх умов. Уявіть, що десь в надрах такого методу ви додасте До оператора if, інше твердження. Яка ймовірність того, що ви забудете перевірити ту чи іншу умову? Коли код стає складнішим, важливі деталі можна не помітити, зокрема, розробники, як правило, забувають про перевірку, яка має катастрофічні наслідки для безпеки. Щоб зробити сутності більш безпечними, краще перемістити частину їх коду в бібліотеку примітивів домену.
Давайте подивимося, як, спираючись на примітиви домену, можна зняти з суб’єктів відповідальність за виконання різних перевірок валідації і при цьому зробити ці перевірки більш послідовними, а кодову базу в цілому більш безпечною.
Ризик захаращення методів сутності
Давайте розглянемо приклад надмірно захаращеною сутності і спробуємо поліпшити його за допомогою примітивів доменів. Лістинг 5.5 показує клас Order з книжкового інтернет-магазину. Такого роду магазин ми вже бачили в главі 2. Стан програми змінюється при додаванні книг в замовлення, а також при оплаті і відвантаженні замовлень. Клас Order відповідає за відстеження цих змін.
Приклад зміни стану можна побачити в методі addItem, який займається додаванням книги в замовлення. Він складається всього з десяти рядків коду, але йому вдається забезпечити дотримання багатьох бізнес-правил. Однак у нього є неочевидний дефект. Спробуйте знайти його (зробити це буде непросто).

У цих десяти рядках коду методу addItem вдається перевірити аргументи, статус замовлення і доступність книг, а також змінити список замовлених елементів. Виглядає надійно, чи не так? Розділи, що відповідають за перевірку ISBN, повторюються в різних місцях коду інтернет-магазину, тому їх можна вважати своєрідним ідіоматичним елементом кодової бази.
А як же дефект? Він фактично складається з двох частин. По-перше, код не підтверджує контрольну суму ISBN. Це незначний і, швидше за все, нешкідливий недолік. По-друге, тут немає негативної кількісної перевірки – це та сама помилка, яка призвела до величезних фінансових втрат в прикладі з глави 2. Якщо ви це помітили, браво за вашу уважність. Якщо ні, не хвилюйтеся. Такі помилки складно виявити в такій кодовій базі (в реальності код також стежив за тим, щоб кількість книг не перевищувала 240 – це було викликано обмеженнями в системах складського обліку і логістики, які не передбачені в нашому переліку).
У реальній кодовій базі шукати дефекти ще складніше, так як доводиться враховувати більше аспектів. Наприклад, він повинен обробляти помилки, якими ми знехтували в прикладі. Насправді, метод addItem за бажанням кидає винятки ItemCannotBeAddException та InvalidISBNException. Він також міститиме for цикл для перевірки наявності номера ISBN у порядку, щоб кілька екземплярів OrderLine не створювалися з тим самим номером ISBN. Але і це ще не все. Фактичний код буде сповнений застарілого функціоналу, який, наприклад, може залишитися від минулорічної рекламної кампанії («Купи три книги про меблі для дому та отримай одну кулінарну книгу в подарунок!»). Код, написаний в той час, вже не використовується, але присутній досі. Те ж саме стосується і різдвяної акції. У цьому безладді сценарії також можуть бути втрачені для особливо важливих клієнтів, які мали право на знижку на експрес-доставку або безкоштовну доставку в деяких випадках. Список можна продовжувати. При такому великому і надскладному способі можна легко забути про перевірку на входження в асортимент.
Причина, чому деталі можуть бути легко упущені навіть у простому прикладі, полягає в фундаментальній психології. Ми, люди, добре розпізнаємо подібності і підсвідомо намагаємося їх знайти. Саме тому перевірка посвідчення особи вимагає спеціальної підготовки. Без нього ми просто подивимося на людину перед собою і подумаємо: «Так, два ока, ніс посередині, а підборіддя внизу — все підходить разом». Це лише одна з багатьох подібних ситуацій. Навчальні курси поліції включають: спеціальні заходи, які допоможуть цього уникнути. Людська риса, яка змушує нас шукати подібності, психологи називають схильністю до підтвердження, а її систематичне вивчення почалося ще в 1960-х роках.
Але як це пов’язано з нашим сприйняттям коду? Більшість вихідних текстів, які ми читаємо, правильні. Наш ледачий мозок думає: «Все, що я бачив досі, виглядає пристойно», і підсвідомо робить висновок: «Решта коду, ймовірно, теж в порядку». Після цього, завдяки схильності до підтвердження, ви будете вважати правильним будь-який код, який виглядає нормально. В результаті ви практично втратите можливість знаходити неповні або дефектні фрагменти коду.
Ви, напевно, відчували протилежне. Коли виявляється програмна помилка, заклинання втрачає свою силу і ви раптом починаєте бачити проблеми всюди. Це трохи схоже на пошук грибів в лісі – спочатку нічого не помічаєш, але після першого успіху гриби починають з’являтися на кожному кроці. Переглядаючи великі обсяги коду, люди, як правило, пропускають такі тонкі деталі, як перевірка, і її відсутність може викликати серйозні проблеми з безпекою. Нам явно потрібно навести порядок у наших сутностях.
Ви вже знаєте про небезпеку захаращених сутностей. Давайте подивимося, як можна уникнути цих проблем, використовуючи примітиви домену. Домен примітивний за своєю природою містить безліч важливих перевірок. І організація, якій більше не потрібно виконувати ці перевірки, може зосередитися на тому, для чого вона найкраще підходить.
Згадаймо різні рівні перевірки, які ми досліджували в розділі 4.
Походження. Чи дані були передані довіреним відправником?
Розмір. Чи не надто вони великі?
Лексичний вміст. Чи містять вони відповідні символи у правильному кодуванні?
Синтаксису. Чи дотриманий формат?
Семантика. Чи є дані осмисленими?
Останній крок, семантична валідація, обов’язково повинен бути виконаний на самих сутностях. Сутність знає стан та історію змін даних, що дозволяє їй судити про те, чи мають дані сенс у цей конкретний момент. Усі попередні кроки є перевірками, які слід виконати, перш ніж дані потраплять до сутності.
Тепер застосуємо примітиви домену на практиці. Раніше ви створили примітив Quantity (див. Лістинг 5.1), який можна використовувати для успішної заміни параметра int в addItem. Нам також знадобиться примітивний домен для заміни рядка ISBN. Лістинг 5.6 показує, як його створити.

Ми створюємо цей клас тільки один раз, тому немає ризику, що сума іноді буде перевірена, а іноді ні. Цей код містить усі перевірки розміру, лексичного вмісту та синтаксису, тому їм не потрібно захаращувати код сутності, яка використовує ISBN.
Тепер можна оновити сутність Order для роботи з примітивами доменів ISBN і Кількість. Нова версія класу Order, показана в Лістингу 5.7, показує поліпшення. Перш за все, код став більш компактним, але це пов’язано в основному з тим, що частина його була перенесена в інше місце. Важливим є те, що код, що залишився орієнтований на вирішення конкретної задачі – виконання дій, обов’язковий при додаванні нового товару в замовлення.

Метод addItem не потрібно звинувачувати на ранніх стадіях перевірки — він виконує лише останній крок, перевіряючи, чи мають дані семантичний сенс у конкретний момент. Як бачите, метод містить менше коду, що знижує ризик зробити помилку при його оновленні. Крім того, перевірка завжди виконується примітивами домену, тому турбуватися про неї не потрібно що ми забудемо перевірити контрольну суму ISBN або переконатися, що кількість не є від’ємним числом.
Код клієнта в ShoppingFlow (див. Список 5.5) більше не може надсилати номери ISBN та кількості як звичайні типи String та int. Будь-яка спроба зробити це зазнає невдачі з помилкою компіляції. Щоб викликати Order.addItem, код повинен створити об’єкти ISBN і Quantity , а оскільки їх конструктори виконують перевірку, немає ризику, що суб’єкт господарювання отримає неприпустимі дані. Код виклику несе відповідальність за перевірку правильності.
Проблеми з перевіркою можуть виникнути, коли клієнт, що викликає, намагається створити екземпляр ISBN або Quantity. При цьому код клієнта повинен повернути управління графічному інтерфейсу, щоб користувач міг виправити введені дані. Зверніть увагу на поділ проблем: код клієнта гарантує, що перевірка виконана, але примітиви домену ISBN і Кількість.
Поки що ми обговорювали аргументацію методів. Але все вищесказане справедливо для аргументів конструкторів. Крім того, наш досвід показує, що корисно застосовувати ті самі ідеї до повернутих значень і полів, які зберігає сутність.
Нижче наведено деякі з ключових переваг використання примітивів домену в коді сутності:
Введення завжди перевіряється. Система типів слідкує за тим, щоб ви задіяли доменні примітиви.
Узгоджена перевірка коректності. Вона завжди виконується у конструкторі доменного примітиву.
Код сутності стає менш захаращеним і сфокусованим. Він повинен виконувати перевірки на входження, контролювати формат тощо.
Код сутності стає більш легкочитаним. Він відповідає мові предметної області.
Ці переваги можна отримати не тільки за допомогою примітивів доменів. Але, з нашого досвіду, такий підхід дає найкращий результат, особливо у випадку аргументів методу, забезпечуючи належну валідацію вхідних даних сутностей.
Проведення перевірок валідації по суті з використанням примітивів домену є дуже ефективним підходом. Настільки ефективний, що нам навіть складно знайти приклад того, де його застосовувати не варто. Може бути, тільки в тому випадку, коли вхід не потрібно перевіряти і допускаються будь-які дані. Можливо, часовий ряд з температурними показниками був би досить простим? Але і тут не можна приймати температуру нижче абсолютного нуля (0 °K, що відповідає –273 °C або –460 °F). Не так-то просто знайти задачу, в якій щось є звичайним цілим числом або необмеженою рядком.
Іноді ми чуємо, що додаткова обгортка (наприклад, номер ISBN навколо рядка) погіршує продуктивність середовища виконання. В принципі, це дійсно так, але на практиці це навряд чи має значення. Не забувайте, що перевірку ISBN все одно потрібно виконати (або в конструкторі ISBN, або в іншому місці), щоб це не сповільнювало ваш код. Додаткові ресурси витрачаються тільки на виділення нового об’єкта і управління його пам’яттю.
З сучасними збирачами сміття такі недовговічні об’єкти мало впливають на продуктивність: на розподіл пам’яті йде всього близько десяти машинних інструкцій, а вартість звільнення часто дорівнює нулю. І все це надає незначний ефект на тлі дзвінків в базу даних або мережевих дзвінків. Вплив продуктивності, згаданий раніше, вимірюється в нано або мікросекундах, тоді як запит до бази даних займає мілісекунди. Ви повинні турбуватися про розподіл об’єктів тільки в екстремальних ситуаціях, таких як аналіз великих даних, але якщо вам потрібно перемолоти величезну кількість чисел в пам’яті або написати код для пристрою з обмеженими ресурсами, вам, ймовірно, не потрібні сутності.
Варто відзначити, що примітиви домену можуть застосовуватися не тільки всередині сутностей, які ви створюєте з нуля. Як тільки ви знайдете сутність в коді, яку ви підтримуєте або розробляєте, ви можете ризикнути і змінити її підпис за допомогою примітивів домену. Якщо відповідного примітива у вас немає, то, ймовірно, пора його створити (у нас була кодова база, яку ми переробляли за допомогою цієї методики, вносячи зміни в код поступово, коли з’являлася можливість). З часом ваша бібліотека примітивів домену буде рости, а ваші сутності стануть більш цілеспрямованими. У розділі 12 ми детальніше розглянемо цей аспект і поговоримо про те, що робити з застарілим кодом.
Тепер ви знаєте, що примітиви домену формують міцну основу для подальшого розвитку, багато в чому звільняючи решту коду від необхідності перевірки на коректність. Щоб завершити главу, давайте розглянемо деякі дослідження, що мають відношення до цієї теми. В інформатиці процес відстеження потенційно шкідливих вхідних даних і забезпечення його правильності (до певної міри) перед його використанням називається міченим аналізом даних.
Аналіз плям використовується в області досліджень безпеки, щоб визначити, як запобігти використанню шкідливих даних, позначаючи їх. Шкідливі дані можуть бути вбудованим кодом JavaScript, який встановлює кейлоггер, або містити вбудовані команди SQL, які намагаються знищити базу даних або розкрити її вміст. Будь-який вхід вважається підозрілим до тих пір, поки не підтвердиться зворотне, для цього його перевіряють за допомогою якогось механізму. Якщо непідтверджені (все ще позначені) дані використовуються небезпечним способом (наприклад, виводяться користувачеві або записуються в базу даних), це ознака потенційної уразливості, про яку слід знати під час аналізу позначених даних.
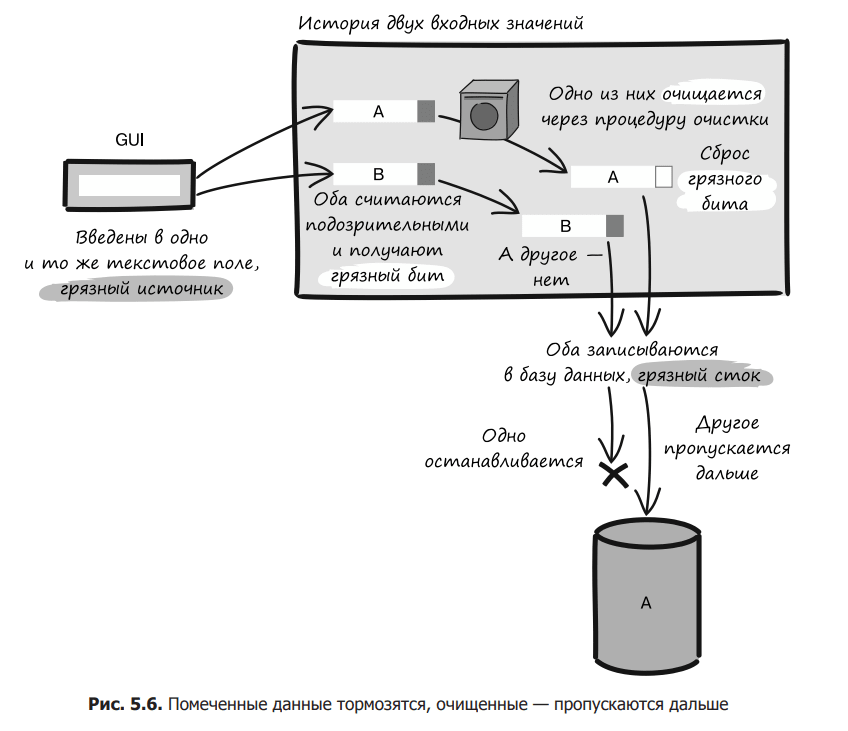
Цікаво, що такого роду аналіз можна проводити під час виконання, відстежуючи будь-який вхід, що надходить в систему, присвоюючи йому біт плями. Якщо спробувати записати зазначений вхід в базу даних або використовувати його якимось іншим потенційно небезпечним способом, система аналізу зазначених даних перехопить його і зупинить подальший розподіл (рис. 5.6).
Кожен аналізатор даних з тегами має свої правила щодо того, що перевіряти, коли відбувається перехоплення та як відбувається дезінфекція введення. Але більшість з них використовують однакову термінологію.
Вона включає в себе чотири поняття.
Брудні джерела. Те, звідки в систему може надходити підозріле введення. Це можуть бути інтерфейси користувача, функції імпорту даних або механізми інтеграції із зовнішніми системами.
Очищення. Перевірка, після якої дані перестають вважатися підозрілими.
Політика розповсюдження. Визначає, чи потрібно помічати результат обробки чи об’єднання даних.
Брудний стік. Місця, в яких дані використовуються небезпечним способом: при виведенні користувачеві, записи в БД і т.д.
Позначені інструменти аналізу даних, які реалізують ці концепції, повинні взаємодіяти з середовищем виконання. Наприклад, реалізація для систем, написаних на Java, буде взаємодіяти з JVM під час виконання байт-коду. Він доповнює представлення кожного об’єкта на купі брудним байтом і поміщається між байт-кодом і JVM для безперервного аналізу позначених даних.
На Java можна вказати певні методи зі стандартної бібліотеки для виявлення брудних джерел. Наприклад, було б корисно стежити за всім, що надходить в систему через InputStream.read, але не Random.nextBytes. Аналізатор також може розрізняти різні вхідні потоки. Наприклад, ми можемо позначити InputStream.read, якщо об’єкт InputStream є результатом виконання Socket.getInputStream або ігнорувати його, якщо його створено за допомогою нового FileInputStream(…).
Очищення відбувається, коли дані вважаються перевіреними. Однак аналізатор нічого про це не знає, оскільки не знає правил прикладної області і не може читати думки програміста. Замість цього він спирається на евристичні методи. Наприклад, якщо ви перевіряєте рядок за регулярним виразом за допомогою String.matches, інструмент аналізу може вважати, що програміст виконав якусь розумну перевірку. Але, строго кажучи, впевненості в цьому немає. Регулярні вирази зазвичай використовуються для очищення рядків, операцій порівняння (<, =, >) і так далі для очищення чисел. Іншим прикладом є те, що дані передаються як аргумент конструктора. Якщо конструктор не відповідає, фреймворк сприймає це як знак того, що програміст вважає рядок нормальною, і вона більше не позначена.
Політика поширення тегованих даних визначає обставини, за яких брудний біт потрібно змінити. Наприклад, якщо об’єднано два рядки, один з яких позначений, результат також буде позначений. Його можна вважати чистим тільки в тому випадку, якщо обидві струни чисті. При отриманні підрядка результат буде чистим, якщо вихідний рядок був чистим, інакше він буде позначений.
Нарешті, брудний злив – потенційно небезпечний метод. Очевидним прикладом є метод java.sql.Statement.execute. Запис до локального файлу за допомогою FileWriter.write може бути безпечним або вимагати перевірки. Якщо перевірка не вдається, аналізатор даних з мітками перехоплює виконання та кидає виняток безпеки.
Для порівняння давайте подивимося, яку роль аналіз маркованих даних відводить дизайнеру. Очевидно, що це центральне місце для перевірки валідації — рядок, переданий конструктору, повинен бути перевірений. Звідси випливає, що написання конструктора, який не перевіряє параметри рядка, робить аналіз позначених даних марним.
Багато сучасних систем, ймовірно, не встигли б запустити навіть кілька секунд, перш ніж інструмент аналізу створив виняток у брудному зливі. Ми часто стикаємося з системами, в яких рядок може потрапити в базу даних різними способами без будь-якої перевірки за допомогою конструктора або регулярних виразів. Коли це відбувається, система аналізу маркованих даних дає про себе знати. У той же час додатки, розроблені за допомогою примітивів домену, ймовірно, працювали б без проблем.
Аналіз маркованих даних не має нічого спільного з поняттям примітивів домену, але приємно, що ці дві ідеї так добре сумісні один з одним. Аналіз, виконаний одночасно з виконанням, звучить заманливо, але, на жаль, практичного застосування на даний момент не має. У той же час проектування систем з використанням примітивів домену пропонує безліч переваг з точки зору безпеки.
Цей розділ був присвячений формуванню міцної основи для викладу предметної області. Примітиви домену – це надійні і надійні будівельні блоки, поверх яких можна створювати більші структури. Ви бачили безпосередні переваги, які примітиви домену можуть принести сутностям. У наступному розділі ми зупинимося на інших труднощах створення сутностей, покажемо, як вони можуть стати небезпечними, і як з цим боротися.
Доменні примітиви – це найменші складові елементи, що формують основу доменної моделі.
Концепції в доменній моделі не слід подавати у вигляді примітивів або стандартні типи мови.
Якщо термін, який використовується в доменній моделі, вже існує за її межами і має трохи інше значення, ви повинні ввести новий термін замість перевизначення існуючого.
Доменний примітив незмінний і може існувати, тільки якщо діє льон у поточній предметній області.
При використанні доменних примітивів решта коду суттєво спрощується і стає безпечнішою.
Ви повинні робити API більш надійними за рахунок застосування власної бібліотеки доменних примітивів.
Об’єкти одноразового читання — це зручний механізм для подання конфіденційних даних у вашому коді.
Значення об’єкта одноразового читання може бути вилучено лише один раз.
Шаблон проектування «об’єкти одноразового читання» може допомогти у боротьбі з витоком конфіденційних даних.
Доменні примітиви забезпечують безпеку того ж роду, яку можна було б отримати за рахунок аналізу помічених даних під час виконання програми.
Ми використовували матеріали з книги “Безпека by design”, які написали Дэн Берг Джонсон, Дэниел Деоган, Дэниел Савано.





