
04.09.2023
48 min
1977

Domain names are an integral part of the Internet, defining its architecture and ease of use. These key components help us navigate the vast expanses of the web and find the web resources we need. Without them, the functioning of the Internet would become much less convenient and complex. The Main Role of Domain Attributes: Identification and Convenience: Domain Attributes provide textual and easy-to-remember identifiers for web resources, making Internet navigation convenient. They allow us to use common words and phrases instead of complex numeric IP addresses. Uniqueness: Each domain name is unique on the network, ensuring that no two different resources will have the same name.

This is important to avoid conflicts and ensure unambiguous identification. Structure of Domain Attributes: Domain Attributes consist of two parts: a secondary domain (for example, “example”) and a top-level domain (for example, “.com”). This structure divides domain names into logical categories and defines their organization in the network. Common Uses of Domain Primitives: Domain Primitives are used in all aspects of the Internet, from web browsers and e-mail to web development and online commerce. They have become an integral part of our digital lives, helping us find information, connect with others and grow our business online. Understanding the role and importance of domain names is important for anyone who wants to have a successful Internet presence, whether as a user or an IT professional.
Chapter 4 introduced you to powerful design principles such as immutability, fast completion, and testability. They help combat a variety of security issues, including incorrect input, invalid state, and data integrity violations. However, using them individually is not an efficient way to write secure code. In the table Figure 5.1 lists the problem areas that we will discuss in this chapter and the concepts that allow us to achieve a higher level of security.

This chapter is devoted to the creation of a higher-order concept, called a domain primitive, which combines security principles and objects of value, while being the smallest constituent element of a domain. Here, you’ll learn how to improve your code with design solutions that improve security on multiple levels at once, giving your system clarity and helping you navigate it better. You’ll also learn how to use domain primitives to simplify entities and orchestrate detection of inadvertent leaks of sensitive data. So, let’s talk about domain primitives and invariants.
Value objects in domain-oriented design are immutable and form a coherent concept – these are their key properties. As our experience shows, if a valuable object is slightly optimized with an emphasis on security, the so-called domain primitive will be obtained.
By starting to use domain primitives as the smallest building block of your domain model, you can write code that is far less likely to have security issues than usual. This is achieved solely by the way you design it. The code will be accurate and without any uncertainty. It will contain fewer defects and, as a result, fewer vulnerabilities. It will be easier for you to work with it, since domain primitives are less cognitive load on developers. Later in this section, we’ll try to explain what domain primitives are, how to define them, and how to build secure software with them.
The value object represents an important concept in your domain model. In the modeling process, you decide what the value object will look like and what it will be called. But if you go further and try to define what it is and what it is not, you can get a much deeper understanding of this concept. Based on this knowledge, you will be able to add invariants, compliance with which will allow you to consider the value of the object as valid. Then you can make compliance with these invariants mandatory and ensure it at the stage of creation. As a result, you will have such a strict definition of the value object that its very existence will confirm its validity. If it is invalid, it cannot be in principle. Value objects of this kind are called domain primitives.
Domain primitives are similar to value objects in a domain-specific design. Their key difference is that they require invariants that must be applied at the creation stage. They also preclude the use of simple primitives or standard types (including null) of the programming language to represent domain model concepts. It is also worth noting that, despite their name, they can be quite complex objects, containing non-trivial logic and other domain primitives.
NOTE. In a domain model, nothing should be represented by primitives or standard programming language types. Each concept must be modeled as a domain primitive so that it retains its meaning when transferred and can use its invariants.
Imagine that your domain model has the concept of quantity. Let it be the quantity of a certain product that the customer wants to buy in the online store that you are developing. This is a number by itself, but instead of using the standard integer type, we’ll create a domain primitive called Number. During its determination, you communicate with relevant experts and try to find out what, in their opinion, is the correct value. During the discussion, it turns out that the correct value is an integer between 1 and 200. It cannot be zero, since an order in which the customer wants to buy zero units of the product should not exist. Negative values are also inadmissible, as the product cannot be bought “back to front” and its return is processed separately. Orders containing more than 200 products are not accepted by the system. This is an extremely rare case, if it occurs, it should be treated with special attention: in such situations, customers contact the sales representative directly, bypassing the online store.
You encapsulate important aspects of domain primitive behavior, such as adding and subtracting units of a product. Because the primitive domain owns and controls the domain operations, there is less chance of software errors caused by misunderstanding the concepts involved in the operation. The more distant such operations are from the concept, the less detailed information about it can be expected, therefore it is logical to conduct all domain operations within the domain primitive itself. Let’s give an example. Let’s imagine that you need to add two units of the product. You create an addition method, but its implementation must respect the domain’s rules for quantity—remember, you’re not dealing with ordinary integers. If you place the add method in some other part of the codebase, such as the Functions utility class, it can easily introduce non-obvious defects. If you decide to slightly change the behavior of the Quantity domain primitive, you may forget to update the corresponding method in the utility class. Chances are high that this will happen, and if it does, you’ll end up with a hard-to-detect error that can cause serious problems. When you’re done with the Quantity domain primitive, your implementation should look like Listing 5.1.

It is an accurate and consistent implementation of the concept of quantity. In the anti-Hamlet study in Chapter 2, an example was given of how a small amount of uncertainty in the system can result in customers giving themselves discounts by specifying a negative quantity of a product before placing an order. A primitive domain similar to the previously introduced Quantity eliminates the possibility that an unscrupulous user will specify a negative value and cause the system to behave unintentionally. Using domain primitives eliminates the vulnerability without requiring explicit countermeasures. As this exercise shows, a quantity is not just an integer. It must be modeled and implemented as a primitive scope to preserve its value when passed and to observe its invariants.
By now you have a general idea of the primitive domain. Now let’s talk about why it is necessary to define the sphere in which it operates.
Domain primitives, like value objects, are defined by their content, not by their identifier. This means that two domain primitives of the same type and with the same value are interchangeable. They are ideal for representing a wide variety of domain concepts that cannot be classified as entities or aggregates. One important consideration when modeling a concept using a domain primitive is that the definition of the primitive must accurately reflect the meaning of the concept in the context of the current domain.
Imagine you are developing a system that allows users to choose and create their own email addresses. The user can select the local part of the address (the one to the left of the @) and use the created address to send and receive emails. If you enter jane.doe, [email protected] will be generated (provided your domain name is example.com). As you model, you realize that an email address is a perfect example of a domain primitive. It is determined by its value, and it is possible to predict certain restrictions that make it possible to be sure of its validity.
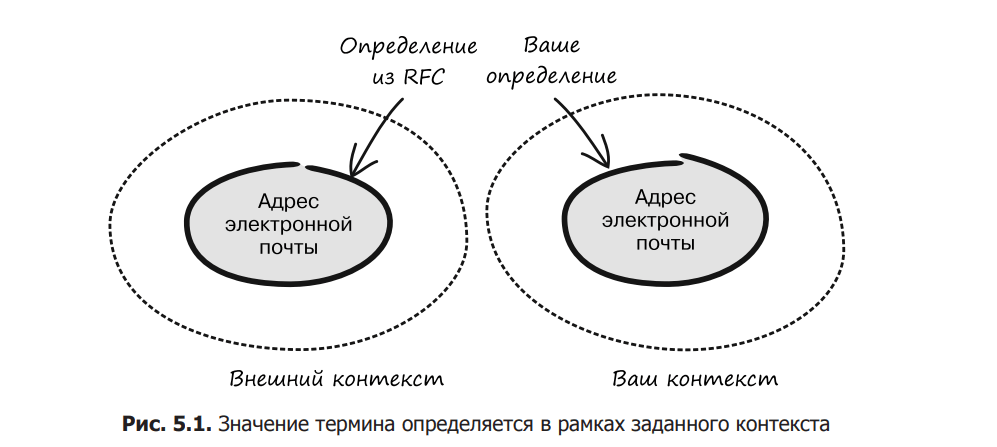
In the beginning, to define what constitutes a valid email address, you may be inclined to use the official definition. Formally, this would be the correct decision from the point of view of compliance with RFK requirements, but in the context of the existing subject area, this definition may be incorrect (Fig. 5.1). This may come as a surprise to you as an engineer. But remember that we are interested in the meaning of the concept in a certain subject area, and not what meaning it may have in another context, for example, a global standard. For example, in your case, email addresses can contain uppercase and lowercase letters, so everything the user types will be lowercase. You can go even further and say that only alphabetic characters, numbers, and ASCII dots ([a-z0-9.].) are allowed. This would be a deviation from the technical specification, but in the context of this subject area, such a decision can be considered correct.
Sometimes the name of the concept you’re trying to model is used outside of the current context, and that external definition is so common that replacing it in your domain model will cause confusion. Such a concept might be an email address, but as we just learned, sometimes it makes sense to redefine it in its current context.
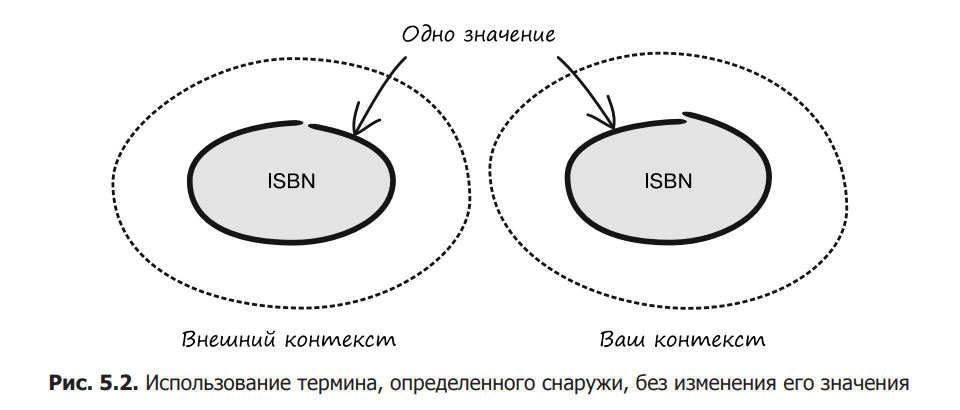
Another example of a well-defined concept is the ISBN number. This format is defined by the International Organization for Standardization (ISO), and overriding it can lead to confusion, misinterpretation, and software errors. These kinds of minor differences often cause security problems and should be avoided, especially when interacting with other systems or domain contexts (see Figure 5.2).
In most cases, the need to redefine well-known concepts is due to the fact that several things in the current context are described using the same concept. In such situations, try to either split the concept into two parts, or come up with an entirely new term unique to the current context. This will avoid misinterpretations, and will also make it obvious the reason for using certain invariants instead of those related to the externally defined term. Another advantage of introducing a new concept is that the original concept retains its clear definition and remains a primitive of the subject area. You have fully retained the ability to model important concepts in your subject area, and the model has not lost accuracy.
Imagine that you are developing software to manage a bookstore that uses ISBN numbers for identification. After a while, you realize that you need to somehow work with books that have not yet been assigned an ISBN number. One solution would be to redefine the term ISBN so that it not only represents real numbers, but also includes internal identifiers, which can, for example, have a “magic prefix” to distinguish them from real ISBNs. But to avoid the confusion that arises when re-defining the ISO standard, a new concept of BookId could be introduced, which would contain either an ISBN or an UnpublishedBookNumber (Figure 5.3). BookId is the global identifier of the book, and UnpublishedBookNumber is the identifier assigned internally by the book.
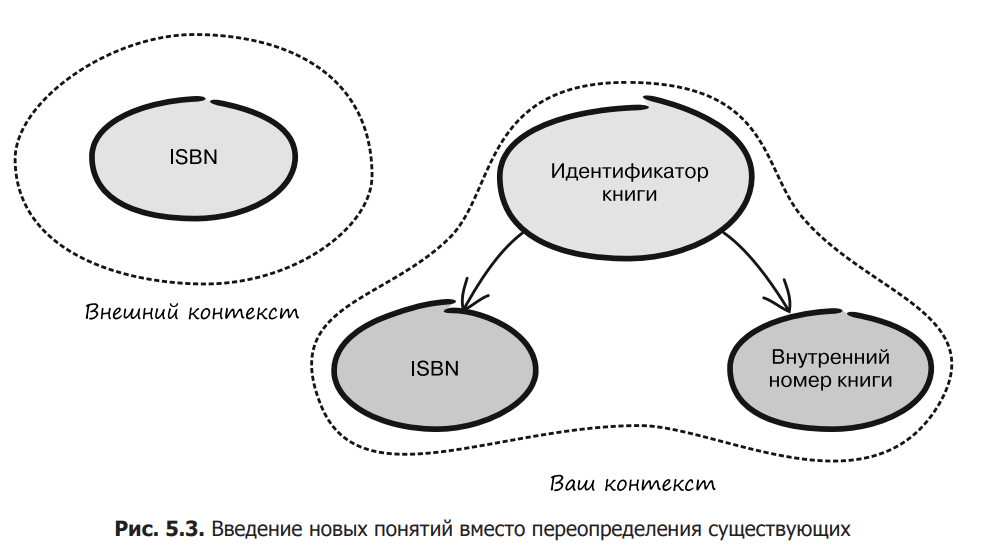
With the introduction of two new terms, BookId and UnpublishedBookNumber, you can use the exact known ISBN definition and still meet the business requirements of your subject area.
So, you have expanded the range of concepts available to you due to the versatility of domain primitives. Try to use them as much as possible in your code. These are the smallest standard blocks that form the basis of the domain model. Because of this, almost any concept you model will be based on one or more domain primitives. During simulation, you have a collection of domain primitives at your disposal, which can be thought of as a library. It is not just a set of generic utility classes and methods, but rather a well-defined, unified set of domain concepts. And since they are domain primitives, they can be safely passed as arguments in your code as normal value objects.
Domain primitives reduce the cognitive load on developers because they don’t need to understand how they work. You can work with them safely and be sure that they always have the right values and clear concepts. An invalid primitive domain simply cannot exist. This eliminates the need to constantly check the data to make sure it is safe to use. If they are defined in your domain, you can trust them and use them freely.
You should always try to use domain primitives in your APIs. If all arguments and return values are correct by definition, you get input and output validation in every method of your code base without any extra effort. This approach to domain design will allow writing extremely stable and reliable code. As a positive side effect, we note that the number of security vulnerabilities caused by incorrect input is significantly reduced.
Let’s talk about this in more detail on the example of a specific code. Imagine you are tasked with moving a system’s audit log to a central repository. Audit logs contain sensitive information, so they should be stored in a special place where they will be properly protected. If the data is sent to the wrong place, the company can have serious problems. Your API might have a method like the following: that takes the current audit log and sends it to the repository at the specified address: void sendAuditLogsToServerAt(java.net.InetAddress serverAddress);
The problem here is that the signature of this method allows you to specify any IP address as the log destination. If you cannot authenticate the address before sending the log, you can expose sensitive data by sending it to an unsecured location. Instead, you can create a primitive domain called InternalAddress that clearly defines what an internal IP address is. You can use it as an input type parameter in your method. By applying this To approach the sendAuditLogsToServerAt method, you get the following code, as shown in Listing 5.2.

So far, you’ve designed the method in such a way that it’s impossible to pass it incorrect input. To verify that the IP address is internal, all that remains is to check if it is null.
To improve the reliability of an API that serves as a window to another domain, you should not expose your domain models through it. Otherwise, the domain model will automatically become part of the public API. And as soon as other subject areas begin to use it, it becomes difficult to independently change and develop the model.
An example of a public API that works across domains is the REST API, which is available for use on the Internet by client software. If you expose your domain via a REST API, your software clients will need to support any changes you make in order for your domain model to continue to evolve. If the company depends on these customers, ignoring them will not work: there will be no choice but to synchronize the development process with consumers so that they have time to adapt their client software. What is even worse, if there are several such consumers, you will not only have to synchronize with each of them, but also synchronize them among themselves. This situation is far from ideal, and it can be avoided if you do not open public access to your subject area.
Instead, it is better to use different views for each of the domain objects. It can be thought of as a kind of data transfer object (DTO) that is used to interact with other subject areas. Such DTOs may contain invariants, but they will be different from the constraints in your domain model. For example, they can restrict the communication protocol defined in the API. The first thing to do in such an API method is to convert the DTO to the appropriate domain primitive (or primitives) to ensure that the data is correct. This abstraction layer helps separate the concepts of your public API and domain, allowing them to be developed independently of each other.
This section discusses many important features of domain primitives.
Before moving on, let’s list the key points.
Invariants in domain primitives are checked during creation.
Only valid domain primitives can exist.
Domain primitives should always be used instead of primitives and standard programming language types.
The meaning of domain primitives is defined within the current domain, even if the term has a different meaning outside of it.
To write secure code, you should use your own library of domain primitives.
At this point, we already know what immutability, fast failover, validation, and domain primitives are, and how each of these concepts contributes to security at the design level. In programming, there is another concept that plays an important role from the point of view of security – one-time readable objects. We will talk about them later.
One common source of software security problems is the leakage of sensitive data. It can be both unintentional, caused by the developer, and deliberately provoked. Regardless of the cause of this problem, several design techniques can be used to combat it. Let’s see how the Single Reader design template can reduce the likelihood of sensitive information being leaked.
Here is a list of key features inherent in these objects.
Their primary purpose is to help detect unintended data use.
They represent confidential meanings or concepts.
Most often, they are domain primitives.
Their meaning can be read once and only once.
They prevent serialization of sensitive data.
They prevent inheritance and extension.
A one-time read object, as the name implies, is designed to be read exactly once. It usually represents a value or concept in your domain that is considered confidential, such as passport and credit card numbers or passwords. The primary purpose of a read-only object is to help detect unintended use of the data it encapsulates. It often takes the form of a domain primitive, It can also be applied to entities and aggregates. The main point here is that once an object is created, the data encapsulated by it can only be retrieved once. Attempting to retrieve will result in an error. This object also takes some precautions against the extraction of sensitive data during the serialization process.
Listing 5.3 shows an example of a one-time read object. As you can see, it is called SensitiveValue and is modeled as a domain primitive, all of whose invariants are checked during creation. The class is defined as final to prevent inheritance and the value is wrapped in an AtomicReference. When the value accessor is called, the private value is returned and then set to null If the value method has already been called, its previous value is null, resulting in an exception.
This object also implements the java.io.Externalizable interface and always throws an exception to prevent accidental serialization. The declaration of a value field defines the transit keyword if you use a library that accesses the field directly instead of the standard Java serialization tools, but still respects the transitive keyword . As a last resort, the toString method is implemented in such a way that it cannot be used to retrieve an actual value.


To better understand the benefits of this design pattern, consider a situation in which a one-time read of an object can prevent the accidental disclosure of sensitive data.
Imagine that you are developing a simple login mechanism where a username and password are entered for authentication. Another mechanism responsible for verifying the provided credentials is then called, the authentication system. Once in the system, the password should be used exclusively for authentication and in no other way (Fig. 5.4). This means that the password only needs to be retrieved once when it is passed to the authentication system. After that, there is no point in storing it anywhere.
Passwords are a typical example of sensitive data. A user’s password should never end up in some plain text log file where anyone can read it, or in an error message in the user’s browser, or in a dashboard where operations engineers will see it. If you model the password as a domain primitive and implement it as a one-time read object, you’ll have a security mechanism that lets you know if the password starts leaking in some way. This is illustrated in Listing 5.4.
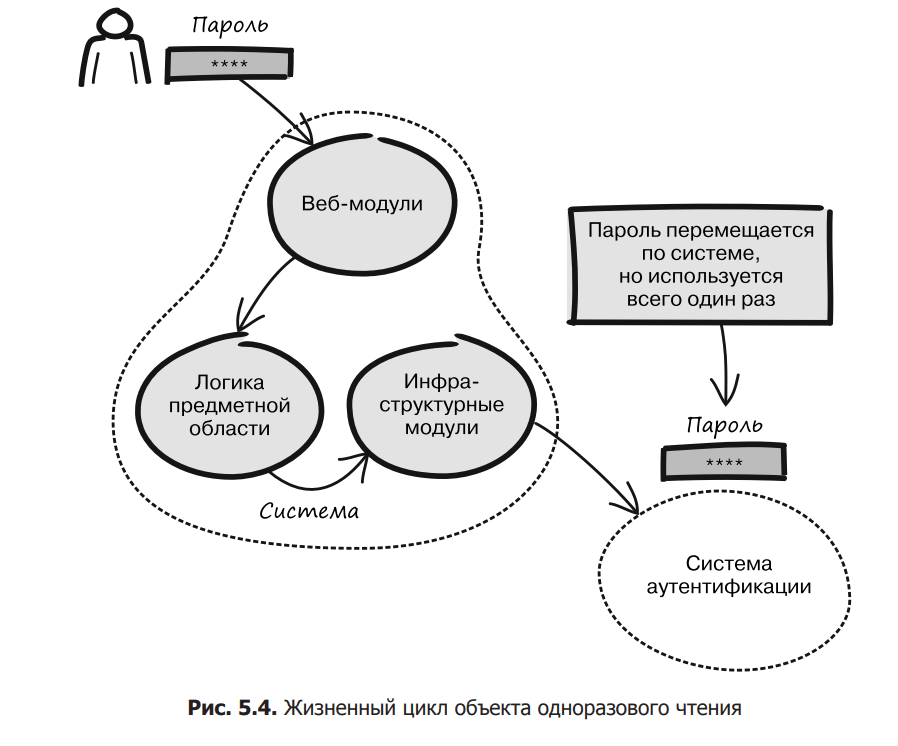

In this implementation, if a password is used unintentionally, an attempt to verify the credentials using the authentication system results in an error message similar to the following: Password value already expired. For example, an unintended use could occur in a log entry or result in an exception that accidentally contains a password. This kind of programming error will most likely be caught early by a failed test in your delivery pipeline. If this doesn’t happen, the authorization failure will be quickly detected in a production environment, and it should be fairly easy to figure out what’s going on from the error message.
If you’re retrieving a value using a value accessor, reading the object once won’t prevent data leakage, but it will make it easier to detect if it does occur. By applying recommended development approaches and having a comprehensive test suite, you can likely avoid leaks in your production environment.
Learn more about the Password class
The Password object shown in Listing 5.4 is similar to the SensitiveValue object you saw earlier. But it has several features that are worth paying attention to. These features are related to how the JVM manages memory. Let’s list them so you can focus on them, but let’s not go into details.
The value field is now a char array instead of a string. This is because it needs to be cleaned after use. For the same reason, the input array is cloned, which ensures that you can’t break the cleanup logic performed by the code called by the Password constructor, and vice versa. Since we no longer use AtomicReference, a boolean flag is used in conjunction with a synchronized accessor to keep track of the consumed value in a safe way.
When a value is consumed using the value accessor, a copy of the internal char array is returned, which is then cleared. Again, a copy of the passed array is created so that the Password class can handle sensitive data without affecting the rest of the code. Subscribers and recipients outside of this class must also remove any reference to the password.
All this is done to limit access to sensitive values in JVM memory. If desired, these concepts can be developed, but it seems to us that these examples give quite a good result with relatively little effort, and this approach should be considered recommended for Java development.
Another situation where you can easily prevent accidental data leakage is code refactoring and remodeling. We ourselves face this from time to time, and by using disposable reading items, we manage to detect the leak and prevent it from entering the industrial environment. Let’s look at a case that we encountered in our work, but change some details so as not to compromise anyone.
Imagine that you are developing a web application in which the code frequently needs to access information about the current authenticated user. The necessary information is located in the User’s domain object. At some point, developers decide to put this object in a web session to make it easier to access and use as a cache. This solution works as intended and provides the benefits we need. Later, as new business requirements emerged, the User Domain Object Model was modified to add the Social Security Number (SSN) (Figure 5.5). This number is implemented as a one-time SSN object because it should only be used once.
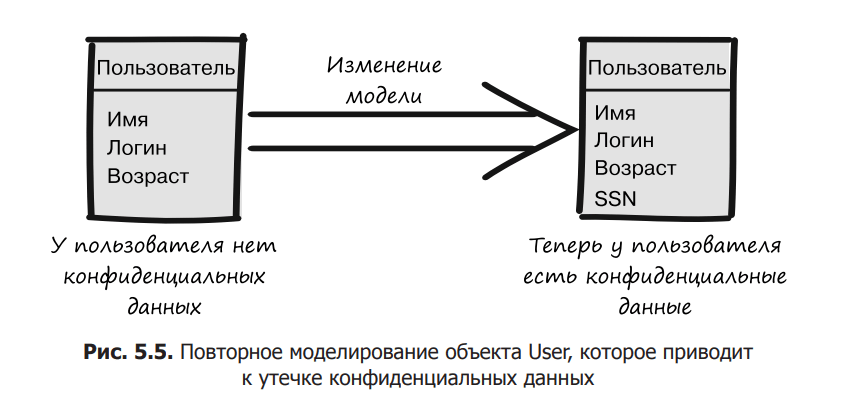
The new domain model takes into account the new requirements, and all tests in the suite pass successfully. However, during acceptance testing in the staging environment, you happen to notice that when the application shuts down, it always outputs some sort of stack trace, including an error message like “Invalid sensitive value operation”. When you look at this output, you can see that this exception is caused by an attempt to serialize the SSN. Something is trying to serialize sensitive data. You, confused, begin to look for the reason for such behavior. After a while it turns out that the serialization is initiated by the Tomcat web server you are using. This is because by default, when Tomcat is shut down or restarted, it saves all active sessions to disk. If you put any sensitive data in a session without shutting it down, it could end up in a file and be readable by anyone with disk access. This is a perfect example of disclosure of confidential information without express permission.
Such data leaks in software systems are not uncommon and almost always occur due to an inadvertent error: the developer either did not think about the consequences, or was completely unaware of them (perhaps because the code he was working on was far from the place where the confidential data). By using single-readable features in the design, you can focus on your immediate tasks without worrying about security.
So far, you have learned what domain primitives are and how to implement them. Now let’s see what role they play in the rest of the code. For example, how to help improve the security of other components, particularly entities.
If you don’t use domain primitives, the rest of the code has to handle validation, formatting, comparisons, and many other things. Organizations represent long-term objects with known identifiers, such as news feed articles, hotel rooms, or e-commerce shopping carts. The functionality of the system is often focused around changing the state of these objects: booking rooms, paying for the contents of the shopping cart, etc. Sooner or later, the thread of execution will reach the code that represents these entities. And if all data is passed as standard types, such as int or String, the responsibility for validating, comparing, formatting, etc. falls on the entity itself. Its code will have many responsibilities, and it will not be able to fully focus on the changes in the state it is simulating. The use of domain primitives allows you to combat this tendency and prevent excessive complexity of entities.
In the process of development, entity classes are repeatedly implemented, extended and modified. They can easily involve additional functionality, as a result of which their methods turn into piles of code of several hundred lines, filled with nested for and if blocks. We have repeatedly found security vulnerabilities caused by local changes that did not take all conditions into account. Imagine that somewhere in the bowels of such a method you add another statement to the if statement. What is the probability that you will forget to check this or that condition? As the code becomes more complex, important details can be overlooked, in particular, developers tend to forget validation, which has disastrous security consequences. To make entities more secure, it is better to move some of their code into the domain primitives library.
Let’s see how, relying on domain primitives, you can remove the responsibility of performing various validation checks from subjects, and at the same time make these checks more consistent, and the codebase as a whole more secure.
Let’s look at an example of an excessively cluttered entity and try to improve it with the help of domain primitives. Listing 5.5 shows the Order class from an online bookstore. We have already seen this kind of store in chapter 2. The state of the program changes when adding books to the order, as well as when paying and shipping orders. The Order class is responsible for tracking these changes.
An example of a state change can be seen in the addItem method, which is responsible for adding a book to the order. It consists of only ten lines of code, but manages to enforce many business rules. However, it has a non-obvious defect. Try to find it (it won’t be easy).

In these ten lines of code for the addItem method, it is possible to check the arguments, order status and availability of the books, as well as change the list of ordered items. Looks solid, doesn’t it? Sections responsible for ISBN verification are repeated in various places of the online store code, so they can be considered a kind of idiomatic element of the code base.
And what about the defect? It actually consists of two parts. First, the code does not validate the ISBN checksum. This is a minor and most likely harmless flaw. Second, there is no negative quantification here – this is the same mistake that led to huge financial losses in the example from Chapter 2. If you noticed this, kudos for your attention. If not, don’t worry. Such errors are difficult to detect in such a code base (in reality, the code also ensured that the number of books did not exceed 240 – this was caused by limitations in the warehouse accounting and logistics systems, which are not provided for in our list).
In a real codebase, finding defects is even more difficult, as there are more aspects to consider. For example, it should handle errors that we neglected in the example. In fact, the addItem method optionally throws ItemCannotBeAddException and InvalidISBNException. It will also contain a for loop to check that the ISBN is in order so that multiple instances of OrderLine are not created with the same ISBN. But that’s not all. The actual code will be full of legacy functionality that might be left over from last year’s ad campaign (“Buy three home furnishings books and get one free cookbook!”), for example. The code written at that time is no longer used, but is still present. The same applies to the Christmas promotion. In this mess, scripts may also be lost for particularly important customers who were eligible for discounted express shipping or free shipping in some cases. The list can be continued. With such a large and extremely complex method, it is easy to forget about checking for inclusion in the assortment.
The reason why details can be easily missed in even a simple example is due to fundamental psychology. We humans are good at recognizing similarities and subconsciously try to find them. That is why the verification of the identity card requires special training. Without it, we’ll just look at the person in front of us and think, “Yeah, two eyes, a nose in the middle, and a chin down—it all fits together.” This is just one of many such situations. Police training courses include: special measures to help avoid this. The human trait that makes us look for similarities is called confirmation bias by psychologists, and its systematic study began as early as the 1960s.
But how does this relate to our perception of the code? Most of the source texts we read are correct. Our lazy brain thinks, “Everything I’ve seen so far looks decent,” and subconsciously concludes, “The rest of the code is probably fine, too.” After that, thanks to confirmation bias, you’ll accept any code that looks OK as correct. As a result, you will practically lose the ability to find incomplete or defective code fragments.
You probably felt the opposite. When a software bug is discovered, the spell loses its power and you suddenly start seeing problems everywhere. It’s a bit like looking for mushrooms in the forest – at first you don’t notice anything, but after the first success, mushrooms start to appear at every step. When looking at large amounts of code, people tend to miss subtle details like validation, and its absence can cause serious security problems. We clearly need to put our essences in order.
You already know the dangers of cluttered entities. Let’s see how these problems can be avoided by using domain primitives. A primitive domain by its nature contains many important checks. And an organization that no longer needs to perform these checks can focus on what it does best.
Recall the different levels of verification we explored in Chapter 4.
Origin. Was the data transmitted by a trusted sender?
Size. Aren’t they too big?
Lexical content. Do they contain the appropriate characters in the correct encoding?
Syntax. Is the format followed?
Semantics. Is the data meaningful?
The last step, semantic validation, must be performed on the entities themselves. An entity knows the state and history of data changes, allowing it to judge whether the data makes sense at that particular moment. All the preceding steps are checks that must be performed before the data reaches the entity.
Now let’s apply domain primitives in practice. Earlier, you created a Quantity primitive (see Listing 5.1) that you can use to successfully replace the int parameter in addItem. We will also need a domain primitive to replace the ISBN string. Listing 5.6 shows how to create one.

We create this class only once, so there is no risk that the sum will sometimes be validated and sometimes not. This code contains all size, lexical content, and syntax checks, so they don’t need to clutter up the code of the entity that uses the ISBN.
The Order entity can now be updated to work with ISBN and Quantity domain primitives. The new version of the Order class shown in Listing 5.7 shows the improvement. First of all, the code has become more compact, but this is mainly due to the fact that part of it has been moved to another place. It is important that the remaining code is focused on solving a specific task – performing actions, which is mandatory when adding a new product to an order.

The addItem method doesn’t need to be blamed for the early stages of the validation – it just does the final step of checking if the data makes semantic sense at that particular point in time. As you can see, the method contains less code, which reduces the risk of making a mistake when updating it. Also, the check is always done by the domain primitives, so we don’t have to worry about forgetting to check the ISBN checksum or making sure the count isn’t negative.
The client code in ShoppingFlow (see Listing 5.5) can no longer send ISBNs and quantities as plain String and int types. Any attempt to do so will fail with a compile error. To call Order.addItem, the code must create ISBN and Quantity objects, and since their constructors perform validation, there is no risk that the entity will receive invalid data. The calling code is responsible for checking for correctness.
Validation issues can occur when the calling client tries to instantiate an ISBN or Quantity. At the same time, the client code must return control to the graphical interface so that the user can correct the entered data. Note the separation of concerns: the client code ensures that the validation is done, but the ISBN and Quantity domain primitives.
So far we have discussed the argumentation of methods. But all of the above is true for the arguments of designers. Additionally, our experience shows that it’s useful to apply the same ideas to the return values and fields that the entity stores.
Below are some of the key benefits of using domain primitives in entity code:
Input is always checked. The type system makes sure you use domain primitives.
Agreed correctness check. It is always performed in the constructor of the domain primitive.
Entity code becomes less cluttered and focused. It should perform input checks, format control, etc.
Entity code becomes more readable. It corresponds to the language of the subject area.
These benefits can be gained not only with domain primitives. But in our experience, this approach gives the best result, especially in the case of method arguments, ensuring proper validation of entity inputs.
Performing substantive validation checks using domain primitives is a very effective approach. It is so effective that it is difficult for us to find an example where it should not be used. Maybe, only in the case when the login does not need to be checked and any data is allowed. Perhaps a time series with temperature readings would be simple enough? But even here, the temperature cannot be taken below absolute zero (0 °K, which corresponds to -273 °C or -460 °F). It is not so easy to find a problem in which something is a regular integer or an unbounded string.
Sometimes we hear that extra wrapping (such as an ISBN around a string) degrades runtime performance. In principle, this is true, but in practice it hardly matters. Don’t forget that ISBN validation still needs to be done (either in the ISBN builder or elsewhere) so it doesn’t slow down your code. Additional resources are spent only on allocating a new object and managing its memory.
With modern garbage collectors, such ephemeral objects have little impact on performance: it takes only about ten machine instructions to allocate memory, and the freeing cost is often zero. And all this has little effect on the background of calls to the database or network calls. The performance impact mentioned earlier is measured in nanoseconds or microseconds, whereas a database query takes milliseconds. You should only worry about object allocation in extreme situations like big data analysis, but if you need to crunch huge numbers in memory or write code for a resource-constrained device, you probably don’t need entities.
It’s worth noting that domain primitives can be applied not only inside entities that you create from scratch. Once you find an entity in the code you’re maintaining or developing, you can take the risk and change its signature using domain primitives. If you don’t have a suitable primitive, it’s probably time to create one (we had a code base that we were refactoring using this technique, making changes to the code incrementally as the opportunity presented itself). Over time, your library of domain primitives will grow and your entities will become more focused. In Chapter 12, we’ll take a closer look at this aspect and talk about what to do with legacy code.
Now you know that domain primitives form a solid foundation for further development, largely freeing the rest of the code from the need for validation. To conclude the chapter, let’s look at some research relevant to this topic. In computer science, the process of tracking potentially harmful input data and ensuring that it is correct (up to a point) before using it is called labeled data analysis.
Staining analysis is used in security research to determine how to prevent malicious data from being used by marking it. Malicious data can be embedded JavaScript that installs a keylogger, or contain embedded SQL commands that attempt to destroy a database or expose its contents. Any input is considered suspicious until proven otherwise, for which it is checked using some mechanism. If unconfirmed (still flagged) data is used in an unsafe way (eg, output to the user or written to a database), this is a sign of a potential vulnerability that should be aware of when analyzing the flagged data.
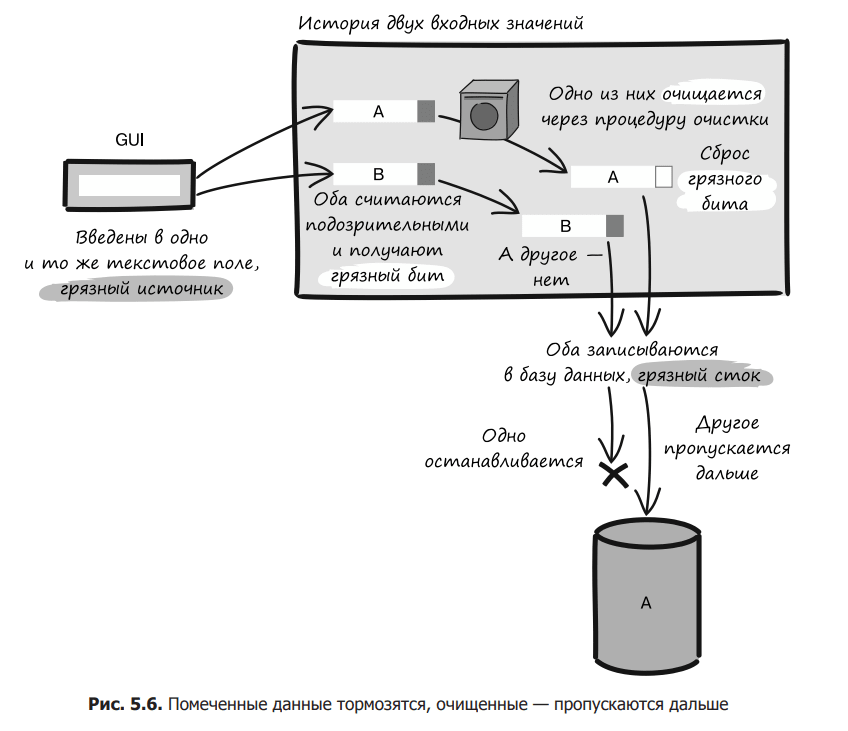
Interestingly, this kind of analysis can be done at runtime by tracking any input that comes into the system, assigning it a spot bit. If you try to write the specified entry into the database or use it in some other potentially dangerous way, the system for analyzing the specified data will intercept it and stop further distribution (Fig. 5.6).
Each tagged data analyzer has its own rules about what to check, when to intercept, and how to sanitize input. But most of them use the same terminology.
It includes four concepts.
Dirty sources. Where suspicious input may be coming into the system. These can be user interfaces, data import functions, or mechanisms for integration with external systems.
Cleaning. Verification after which the data is no longer considered suspicious.
Distribution Policy. Determines whether to notice the result of data processing or merging.
Dirty drain. Places in which data is used in a dangerous way: when outputting to the user, entries in the database, etc.
Marked data analysis tools that implement these concepts must interact with the runtime environment. For example, an implementation for systems written in Java will interact with the JVM when executing bytecode. It supplements the representation of each object on the heap with a dirty byte and is placed between the bytecode and the JVM for continuous parsing of the marked data.
In Java, you can specify certain methods from the standard library to detect dirty sources. For example, it would be useful to monitor everything coming into the system via InputStream.read, but not Random.nextBytes. The analyzer can also distinguish between different input streams. For example, we can flag InputStream.read if the InputStream object is the result of a Socket.getInputStream execution, or ignore it if it is created using new FileInputStream(…).
Cleanup occurs when the data is considered validated. However, the analyzer does not know anything about this, because it does not know the rules of the application domain and cannot read the thoughts of the programmer. Instead, it relies on heuristic methods. For example, if you check a string against a regular expression using String.matches, the parsing tool might assume that the programmer has done some reasonable validation. But, strictly speaking, there is no certainty in this. Regular expressions are commonly used to clean strings, comparison operations (<, =, >) and so on to clean numbers. Another example is when data is passed as a constructor argument. If the constructor doesn’t respond, the framework takes this as a sign that the programmer thinks the string is normal, and it’s no longer marked.
The Tagged Data Distribution Policy defines the circumstances under which the dirty bit must be changed. For example, if two strings are concatenated, one of which is marked, the result will also be marked. It can be considered clean only if both strings are clean. When retrieving a substring, the result will be pure if the original string was pure, otherwise it will be marked.
Finally, dirty draining is a potentially dangerous method. An obvious example is the java.sql.Statement.execute method. Writing to a local file using FileWriter.write may be safe or require validation. If the validation fails, the labeled data parser intercepts execution and throws a security exception.
For comparison, let’s see what role the analysis of labeled data assigns to the designer. Obviously, this is central to the validation check—the string passed to the constructor must be validated. It follows that writing a constructor that doesn’t check for string parameters makes parsing the marked data useless.
Many modern systems probably wouldn’t even run for a few seconds before the analysis tool threw a dirty dump exception. We often encounter systems where a string can enter the database in a variety of ways without any validation using a constructor or regular expressions. When this happens, the labeled data analysis system makes itself known. At the same time, applications developed using domain primitives would probably work without problems.
Labeled data analysis has nothing to do with the concept of domain primitives, but it’s nice that these two ideas go so well together. The analysis performed simultaneously with the execution sounds tempting, but, unfortunately, it has no practical application at the moment. At the same time, designing systems using domain primitives offers many security advantages.
This chapter was devoted to forming a solid foundation for the presentation of the subject area. Domain primitives are reliable and robust building blocks on top of which you can build larger structures. You’ve seen the immediate benefits that domain primitives can bring to entities. In the next chapter, we’ll look at other entity creation difficulties, how they can become dangerous, and how to deal with them.
Domain primitives are the smallest components that form the basis of a domain model.
Concepts in a domain model should not be represented as primitives or standard language types.
If a term used in the domain model already exists outside of the domain model and has a slightly different meaning, you must enter the new term instead of overriding the existing one.
A domain primitive is immutable and can only exist if flax is active in the current domain.
When using domain primitives, the rest of the code is significantly simplified and becomes safer.
You should make the API more robust by using your own library of domain primitives.
Read-once objects are a convenient mechanism for presenting sensitive data in your code.
The value of a read-only object can only be fetched once.
The design pattern “read-once objects” can help in the fight against leakage of sensitive data.
Domain primitives provide the same kind of security that would be obtained by analyzing observed data at runtime.
We used materials from the book “Security by design”, which was written by Dan Berg Johnson, Daniel Deoghan, Daniel Savano.





