
04.09.2023
2 хв
1976

Програмування в сучасному світі є ключовим фактором у забезпеченні інформаційної безпеки. Концепції та методології, вбудовані в процес програмування, можуть значно підвищити безпеку програмних продуктів та застосунків. Безпека в програмуванні – це більше, ніж лише уникнення вразливостей. Це також про активний захист інформації та власників даних. Основні Концепції Програмування для Забезпечення Безпеки: Захист Від Вразливостей: Програмісти повинні стежити за використанням надійних практик програмування, які унеможливлюють вразливості, такі як впровадження неконтрольованих даних та атаки на введення. Мінімізація Поверхні Атаки: Передбачення можливостей атаки та зменшення атаконебезпеки є ключовими принципами безпечного програмування. Аутентифікація та Авторизація: Вбудована перевірка автентичності користувачів та контроль доступу до ресурсів гарантують, що лише вповноважені особи мають доступ до даних та функціональності.

Шифрування та Захист Даних: Застосування криптографії для захисту конфіденційної інформації під час зберігання та передачі. Моніторинг та Журналювання: Системи повинні бути обладнані можливістю моніторингу подій та журналювання, що допомагає вчасно виявляти та реагувати на потенційні загрози. Безпека Забезпечення: Правильне керування залежностями та використання актуальних версій програмних бібліотек допомагає уникнути вразливостей, пов’язаних з застарілими компонентами. Навчання та Школа Безпеки: Підвищення обізнаності програмістів та розуміння ними сучасних загроз є критичними аспектами у підвищенні безпеки.Принцип Найменшого Дозволеного Доступу: Призначення мінімальних прав доступу для користувачів та процесів зменшує ризик недозволених операцій. Застосування цих концепцій у програмуванні сприяє підвищенню рівня інформаційної безпеки. Вони допомагають уникнути загроз та вразливостей, забезпечуючи захист даних та надійність програмних продуктів. У цьому розділі. Як незмінність вирішує проблеми із безпекою. Як контракти із швидким припиненням роботи роблять архітектуру безпечною. Види перевірок коректності та порядок їх проведення.
Розробникам постійно нагадують про пріоритети і терміни. Різні капості і обхід правил часом стають частиною реальності, з якою доводиться миритися. Але чи можна обійтися без нього? По суті, тільки вам вирішувати, який синтаксис використовувати, з якими алгоритмами працювати і як організувати процес виконання. Якщо ви дійсно розумієте, чому деякі концепції програмування кращі за інші, їх застосування стає другою натурою і займає не більше часу, ніж написання поганого коду. Те ж саме стосується і безпеки. Зловмисникам начхати на ваші терміни і пріоритети — слабо захищену систему можна зламати незалежно від того, навіщо і за яких обставин вона була створена.
Ми всі несемо відповідальність за розробку безпечного програмного забезпечення. У цьому розділі ви дізнаєтеся, чому це не займає додаткового часу в порівнянні з розробкою слабо захищеного вразливого програмного забезпечення. У зв’язку з цим ми розділили матеріал на три частини, в яких розглядаються різні стратегії вирішення проблем безпеки, з якими ви можете зіткнутися в повсякденній роботі (табл. 4.1).

Таким чином, ми постараємося змінити ваш спосіб мислення, надамо вам новий набір інструментів і дамо рекомендації, які ви зможете застосувати в повсякденній роботі. Ви також дізнаєтеся, як виявити слабкі місця в застарілому коді та виправити їх. Почнемо з принципу незмінності і наведемо приклад, як він допомагає справлятися з оновленнями.
Проектуючи об’єкт, ви повинні визначитися, яким він повинен бути: змінним або незмінним. У першому випадку його стан може змінюватися, а в другому – ні. Це може здатися несуттєвим, але з точки зору безпеки цей аспект дуже важливий. Незмінні об’єкти можна безпечно обмінювати потоками виконання, а дані можна зробити високодоступними, що дуже важливо для захисту системи від атак на відмову в обслуговуванні (DoS) на службі»). З іншого боку, модифікуються об’єкти призначені для оновлення, що може привести до несанкціонованих змін. Підтримка мінливості часто впроваджується в систему, тому що цього вимагають фреймворки, або тому, що це робить код простішим на перший погляд. Але це небезпечний підхід, який може дорого коштувати. Щоб проілюструвати це, давайте розглянемо приклад того, як використання мінливості в архітектурі веб-магазину викликає проблеми безпеки, які можна легко вирішити за допомогою незмінності.
Звичайний веб-магазин
Уявіть собі звичайний веб-магазин, клієнти якого аутентифікують і додають товари в кошик. Кожен клієнт має кредитний рейтинг на основі історії покупок та балів членства. Низький кредитний рейтинг дозволяє оплачувати тільки кредитною картою, а високий додатково дає можливість користуватися рахунком-фактурою. Розрахунок кредитного рейтингу вимагає досить значних ресурсів і проводиться безперервно, щоб зробити загальне навантаження на систему більш рівномірною.
В цілому система працювала нормально – до недавнього часу. Під час останньої рекламної кампанії на сайт магазину зайшло дуже багато людей. Система погано справлялася з навантаженням, і клієнти скаржилися на тайм-аути замовлень, тривалі затримки та нелогічні варіанти оплати. Останнє питання здавалося несуттєвим, але потім фінансовий відділ повідомив, що багато клієнтів з низьким кредитним рейтингом мали неоплачені рахунки-фактури. Розпочато повномасштабне розслідування – Безпека системи під загрозою! Головним підозрюваним, звичайно, був код для розрахунку кредитного рейтингу, але, на загальний подив, проблема виявилася куди серйозніше – внутрішня структура об’єкта Замовника.
Внутрішня робота об’єкта Замовника
Об’єкт Клієнта, показаний у лістингу 4.1, має дві цікаві особливості. Перший полягає в тому, що всі поля ініціалізуються методами setter. Звідси випливає, що після створення об’єкта його внутрішній стан можна змінити. Це може бути джерелом проблем, оскільки ми не можемо гарантувати, що об’єкт ініціалізований правильно. Ще одне спостереження полягає в тому, що кожен метод позначений синхронізованим ключовим словом, що повинно запобігати одночасним змінам полів, що, в свою чергу, може призвести до суперечок потоків (це коли потоки змушені зупинитися і чекати, поки якийсь інший потік відпустить одне або кілька блокувань.


Не зовсім зрозуміло, як ці дизайнерські рішення стосуються безпеки, але все стане зрозуміліше, коли ми класифікуємо проблеми веб-магазину як порушення цілісності або доступності даних.
Класифікація проблем як порушення цілісності або доступності
Цілісність даних відноситься до узгодженості даних протягом усього їх життєвого циклу, доступність даних є гарантією того, що вони можуть бути отримані при очікуваному рівні продуктивності в системі. Обидві концепції є ключовими для розуміння причини проблем, що виникли у веб-магазині. Наприклад, неможливість отримати дані – це проблема доступності, яка часто зводиться до того, що якийсь код заважає паралельним або конкурентний доступ. Аналогічним чином, ви повинні почати свій аналіз проблем цілісності з коду, який дозволяє вносити зміни. У табл. 4.2 показує проблеми веб-магазину, класифіковані як порушення доступності та цілісності.

Ці категорії дають вам загальне уявлення про те, які частини класу Customer заслуговують на особливу увагу. Почнемо з того, як приховане блокування може погіршити доступність.
Неявне блокування погіршує доступність
Питання про те, чи слід забороняти паралельний і паралельний доступ, часто є компромісом між продуктивністю і послідовністю. Якщо завжди хочеться, щоб стан було узгодженим, а оновлення чергуються з читаннями, має сенс використовувати механізми блокування. Однак, якщо дані переважно читаються, блокування може призвести до зайвих конфліктів між потоками виконання. У конфліктах, викликаних паралельним доступом, як правило, Це легше зрозуміти, ніж ті, що викликані паралельним доступом. Візьмемо, наприклад, синхронізований метод в Listing 4.1: одночасно виконувати його може тільки один потік, тому що для доступу до нього потрібно отримати вбудований в об’єкт замок. Всі інші потоки, які намагаються одночасно отримати доступ до цього методу, повинні почекати, поки це блокування буде відпущено, що може призвести до конфліктів.
Використання синхронізованого ключового слова на рівні методу також може викликати конфлікти між потоками, коли два або більше методів звертаються паралельно. Виходить, що для доступу до всіх методів об’єкти, позначені як синхронізовані, повинні придбати однаковий вбудований блокування. Це означає, що потоки, які викликають ці методи паралельно, неявно блокують один одного, і такі конфлікти іноді важко виявити.
Якщо повернутися в наш інтернет-магазин і проаналізувати взаємозв’язок між операціями читання і запису, то виявиться, що читання даних клієнтів відбувається набагато частіше, ніж їх оновлення. Справа в тому, що дані в основному змінюються алгоритмом розрахунку кредитного рейтингу, а операції читання виконуються в рамках численних запитів клієнтів, в тому числі і з системи звітності, що належить фінансовому відділу. Це свідчить про те, що що паралельне та паралельне читання є безпечним. Так чому б не позбутися від синхронізованого механізму зовсім?
Паралельне і паралельне читання, швидше за все, безпечні, але, мінімізуючи конфлікти, операції запису не можна ігнорувати. Замість того, щоб відмовлятися від механізму замикання, потрібно подумати про інше рішення. Наприклад, можна використовувати просунуті засоби блокування на кшталт ReadWriteLock, який враховує переважання операцій читання. Однак механізми блокування ускладнюють код і збільшують когнітивне навантаження на розробників. Ми вважаємо за краще уникати цього.
Існує більш проста і успішна стратегія, яка полягає у використанні методів проектування, призначених для паралельного і паралельного доступу, таких як незмінність. У лістингу 4.2 ви побачите незмінну версію класу Customer, яка не дозволяє оновлювати стан. Це означає, що об’єкти Клієнта можна безпечно обмінювати потоками без використання блокувань. Результатом є висока доступність з невеликою кількістю конфліктів. Іншими словами, теми більше не блокуються.


Але нам все одно потрібна можливість редагувати дані клієнтів. Як цього досягти, якщо клас Customer незмінний? Виявляється, можна обійтися і без модифікуються структур даних для підтримки змін. Все, що вам потрібно зробити, це відокремити прочитане від запису та виконувати оновлення через окремі канали. Це може здатися занадто складним, але якщо у вашій системі є дисбаланс між читанням і записом, результат може коштувати зусиль. Про нас Як реалізувати це на практиці, буде розглянуто в главі 7, де ми детально обговоримо шаблон проектування Entity Snapshot.
Ви вже знаєте, що незмінність запобігає проблемам доступності на рівні дизайну, але як щодо порушення цілісності в нашому веб-магазині? Чи допоможе тут незмінність? Можливо. Давайте подивимося, як змінювана архітектура Customer і CreditScore робить проблеми з цілісністю ймовірними.
Зміна кредитного рейтингу: питання доброчесності
Перш ніж зануритися в аналіз, давайте згадаємо, в чому проблема з кредитним рейтингом. Кожному клієнту присвоюється кредитний рейтинг; Якщо він досить високий, клієнт може здійснити оплату за рахунком-фактурою. Під час останньої рекламної кампанії система вийшла з ладу, а фінансовий відділ повідомив, що у багатьох клієнтів з низьким рейтингом були неоплачені рахунки. Порушення цілісності даних призвело до зміни кредитного рейтингу, що відкрило доступ до додаткового способу оплати. Але як таке можливо?
Дивлячись на логіку управління кредитним рейтингом в змінюваному об’єкті Клієнта (Лістинг 4.3), бачимо наступне:
Те, як creditScore ініціалізується всередині Customer, дозволяє в будь-який момент змінити кредитний рейтинг;
Посилання на creditScore випадково вибігло з методу getCreditScore, що дозволило вносити зміни за межами Customer;
Метод setCreditScore не створює копію аргументу, що дозволяє впровадити посилання, що ділиться на creditScore.

Давайте обговоримо кожне з цих спостережень і подумаємо, як вони призводять до порушення цілісності даних.
Перше, що може викликати проблему цілісності, – це явна зміна кредитного рейтингу шляхом ініціалізації. Поле creditScore в класі Customer ініціалізується методом setCreditScore. Це було зроблено навмисно, але такий спосіб ініціалізації поля дозволяє змінити кредитний рейтинг клієнта в будь-який момент, так як не гарантує, що його можна буде викликати тільки один раз. Це може здатися прийнятним, оскільки очікується, що клієнт буде читати тільки дані, але змінний характер класу Customer не перешкоджає випадковому використанню цього методу. Це означає, що Ви не можете гарантувати цілісність об’єкта Замовника.
Друга проблема пов’язана зі зміною кредитного рейтингу за межами Клієнта. Якщо ви подивитеся на метод getCreditScore всередині Клієнта, ви помітите ненавмисний витік внутрішнього поля creditScore. В результаті можна змінити кредитний рейтинг за межами об’єкта Клієнта без придбання блокування. Це вкрай небезпечно, тому що Клієнт є загальним, змінюваним об’єктом, і його оновлення без синхронізації є бомбою уповільненої дії (докладніше про це в главі 6). Але це не найстрашніше.
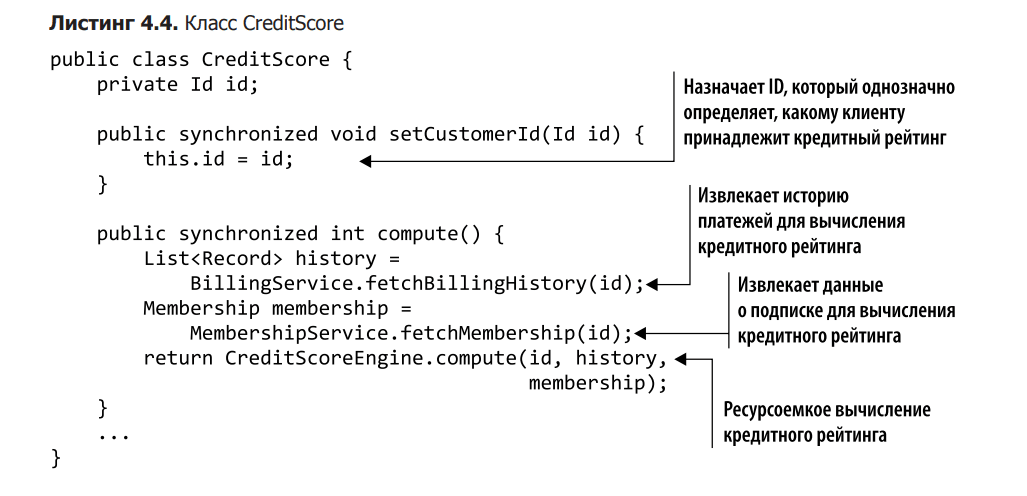
Клас CreditScore був розроблений таким чином, щоб бути змінним, тому ми можемо вручну змінити ідентифікатор клієнта, викликавши функцію setCustomerId, як показано в лістингу 4.4. Звідси випливає, що об’єкти Customer і CreditScore можуть мати різні ідентифікатори, і таке відключення може призвести до використання неправильного значення кредитного рейтингу в обчислювальному методі!
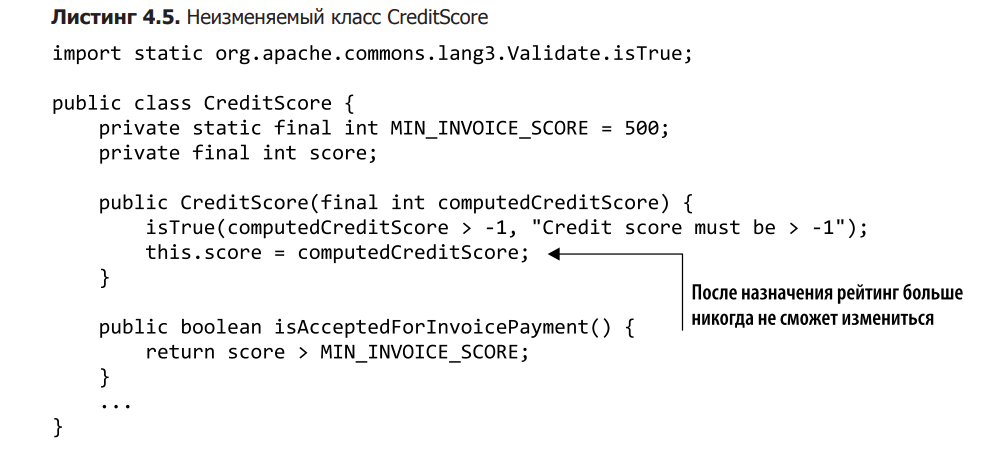
Щоб виправити ситуацію, ми повинні модифікувати клас CreditScore. У лістингу 4.5 ви можете побачити незмінну його версію. Зверніть увагу, що ми видалили синхронізоване ключове слово та залежність від ідентифікатора клієнта. Справа в тому, що вам більше не потрібно отримувати блокування при перевірці кредитного рейтингу, так як тепер він не може змінитися після передачі його конструктору. Це, У свою чергу, це означає, що залежність від конкретного клієнта стає зайвою, тому архітектуру можна спростити, перенісши розрахунок кредитного рейтингу за межі об’єкта. Це дозволяє нам ділити рейтинг між потоками, і нам не загрожують несанкціоновані оновлення, конфлікти і блокування.
Третій спосіб зміни creditScore не такий очевидний, як попередні два – він пов’язаний з модифікацією загального посилання на кредитний рейтинг. Якщо ви подивитеся на метод setCreditScore у версії об’єкта Customer, який ви змінюєте, ви помітите, що внутрішньому полю присвоюється зовнішнє змінюване посилання на creditScore. Нічого страшного, якщо зовнішнє посилання не використовується повторно в іншому об’єкті Клієнта. Але якщо це станеться, розраховане значення кредитного рейтингу буде однаковим для всіх клієнтів, які поділяться посиланням. Це серйозне порушення цілісності, яке пояснює нелогічні варіанти оплати в інтернет-магазині.
Виявлення першопричини
Всі сценарії, які ми досліджували, можуть пояснити проблеми цілісності даних у веб-магазині, але який з них є справжньою причиною? Це не має особливого значення. Головне тут полягає в тому, що, вибравши для використання змінювані класи Customer і CreditScore, розробники системи зробили свій код менш безпечним з декількох точок зору. Але якщо вибрати підхід, орієнтований на незмінність, то необхідність блокування і захисту від випадковості Зміни зникають. Таке дизайнерське рішення саме по собі підвищує рівень безпеки.
Тепер ви знаєте, як незмінність дозволяє уникнути проблем цілісності та доступності даних. Можливо, ви помічали, що в деяких випадках невірні дані агресивно блокувалися ще до того, як вони потрапили на об’єкт. Це ще один ефективний прийом безпеки. Тепер перейдемо до швидкого припинення роботи за допомогою договорів.
Як згадувалося в Главі 1, одним з принципів, яким повинна керуватися безпека, є глибина. Навіть якщо один захисний механізм на краю системи вийде з ладу, інші можуть зупинити вторгнення. Існують фізичні засоби захисту, такі як картки доступу, які відвідувачі застосовують при вході в будівлю. Це може бути значок з фотографією, який потрібно носити постійно. Як показує наш досвід, Такі заходи, як передумови та розробка контракту, також можуть сприяти безпеці програмного забезпечення. У цьому розділі ми покажемо добре зарекомендували себе прагматичні техніки програмування, і наведемо численні приклади.
Передумови були частиною теоретичних досліджень в галузі інформатики в кінці 1960-х років. Ентоні Хоар (також винен у винаході винятку нульового покажчика) був особливо активний в них. Термін «дизайн за контрактом» був придуманий в 1980-х роках Бертраном Мейєром, який використовував його в якості основи для орієнтації об’єкта. Ці ідеї, крім теоретичного інтересу, мають прямий позитивний вплив на безпеку.
Використання передумов і договорів в архітектурному плануванні допомагає чітко визначити, які обов’язки несе той чи інший компонент. Багато проблем з безпекою виникають через те, що різні частини системи очікують один від одного виконання якогось завдання. У цьому розділі ми покажемо, як застосовувати договори, передумови та швидкі відключення, щоб уникнути подібних ситуацій на практиці.
Як працює контрактний дизайн і що ми маємо на увазі? Для початку давайте розглянемо приклад, не пов’язаний з програмним забезпеченням. Уявіть, що ви наймаєте сантехніка, щоб полагодити несправний злив у ванній кімнаті. Сантехнік може зажадати від вас відкрити йому двері і перекрити воду. Це передумови (або передумови)) договору. При їх недотриманні можуть виникнути проблеми. При цьому майстер обіцяє, що по завершенні робіт злив у ванній запрацює справно. Це постумова договору.
У проектуванні об’єктні контракти працюють аналогічним чином. Контракт визначає передумови, необхідні для правильної роботи методу, і постумови, які описують, як буде змінюватися об’єкт після завершення методу. Лістинг 4.6 показує клас, який є частиною системи помічників по розведенню кішок. Специфічний клас CatNameList допомагає відстежувати клички, які можна давати новонародженим кошенятам. Коли заводчик придумує нову кличку, він ставить її в чергу за допомогою об’єкта queueCatName . Коли йому потрібно назвати кошеня, він бере наступну кличку в черзі методом nextCatName і, якщо вона підходить, видаляє її звідти за допомогою dequeueCatName. Метод розміру дозволяє дізнатися, скільки кличок в списку.


Метод queueCatName має кілька певних передумов. Ім’я кішки не може бути нульовим, і це логічно: воно повинно мати якийсь сенс, інакше ця система не буде працювати належним чином. Згідно шведському фольклору, гарне котяче ім’я повинно містити звуки s (саме так кішка на нього відреагує) – це теж обов’язкова умова. І, нарешті, заводчики не хочуть, щоб клички повторювалися, Тому цей договір вимагає, щоб список не містив нікнеймів, які ми додаємо.
Той самий контракт міг бути написаний по-іншому. Наприклад, сам список міг стежити за відсутністю дублікатів. У цьому випадку перед- і після- умови були б сформульовані по-різному (табл. 4.4).

Зверніть увагу, що цей договір поширюється на весь клас, а не на його окремі методи. Контракт вимагає, щоб нікнейм, переданий методу queueCatName, містив звуки s, і в той же час гарантує, що він буде міститися в імені, повернутому методом nextCatName. Це також визначає відповідальність класу в цілому. Відзначимо, що в договорі описується заплановане проектне рішення. Завдання запобігання дублюванню потрапляє або в CatNameList, або в абонента. Наявність договору чітко визначає, чия це відповідальність.
Багато проблем з безпекою виникають в ситуаціях, коли викликає компонент системи передбачає, що абонент відповідає за виконання завдання, а той, хто дзвонить, в свою чергу, очікує, що абонент це зробить. Явний дизайн контракту дозволяє уникнути багатьох з цих ситуацій, які призводять до вразливостей.
Але що робити, якщо попередні умови не виконуються? Повернемося до прикладу сантехніка, якого найняли для ремонту зламаного зливу і який пред’явив кілька вимог (відкриті двері, заблокована вода). Якщо двері залишити закритою, сантехнік не зможе увійти, а якщо не вимикати воду, не варто починати роботу, інакше можуть виникнути серйозні проблеми. У таких ситуаціях краще швидко припинити роботу (швидко вийти з ладу) – зупинити виконання, як тільки стане ясно, що попередні умови не виконуються. Це дуже позитивно позначається на безпеці.
Щоб договори мали будь-яку користь, в кодексі повинні дотримуватися описані в них правила. Мова програмування Eiffel, розроблений Бертраном Мейєром, має вбудовану підтримку цього механізму. Програміст задає передумови, постумови та інваріанти, а час виконання перевіряє для них. Але, оскільки ви, швидше за все, використовуєте інші мови програмування, вам доведеться виконати ці перевірки самостійно у своєму коді. Давайте розглянемо деякі з цих підходів до програмування та покажемо вам, як створити більш безпечне програмне забезпечення.
У договорі для класу CatNameList є деякі обмеження щодо нікнеймів, які ставляться в чергу методом queueCatName: Ви не можете передати null, а нік повинен містити s. Якщо абонент не виконує контракт, велика ймовірність, що рано чи пізно щось зламається. Якщо не передбачити ніяких механізмів дотримання договору, клички без звуку s потраплять в чергу і набагато пізніше ви отримаєте кошенят, чиє ім’я Бадді, Чарлі або Тузик. Для безпеки радимо швидко та організовано вимкнути систему, не допускаючи подальшого виходу системи з ладу непередбачуваним чином.
Передумови слід перевірити на початку методу, ще до виконання будь-яких дій, а якщо вони не виконуються, різко припинити роботу. Невиконання попередніх умов свідчить про те, що класи програми використовуються не за призначенням. Програма втратила контроль над тим, що відбувається, і найбезпечніше, що можна зробити – якомога швидше зупинитися. У цьому немає нічого складного — ви можете реалізувати його самостійно за допомогою інструкції if , що створює виняток, подібний до того, що показано в Лістингу 4.7.

Цей код може бути трохи багатослівним, але він виконує свою роботу. Він припиняється, якщо ім’я кішки відсутнє (нульове), не підходить або вже числиться. Для цього використовується агресивне відключення.
У Java, коли null отримано там, де повинно було бути щось інше, кидається виняток NullPointerException.
Як показує наш досвід, корисно зробити цей код більш компактним, використовуючи клас утиліти Validate з фреймворку Apache Commons Lang. Він містить кілька корисних допоміжних методів, які роблять саме те, що нам потрібно: перевіряють стан і, якщо воно не проходить, кидають відповідний виняток. Лістинг 4.8 показує код, який ви можете отримати, застосувавши Validate.notNull, Validate.matchesPattern та Validate.isTrue.

Клас Validate містить багато інших корисних методів, включаючи exclusiveBetween та inclusiveBetween, які перевіряють, чи знаходиться значення в допустимому діапазоні. Щоб дізнатися більше про інші функції цього фреймворка, ознайомтеся з документацією — це значно полегшить перевірку попередніх умов у вашому коді. Ми використовуємо його в наступних прикладах у цій книзі, щоб зробити їх більш стислими.
ПРИМІТКА. Невірні дані не потрібно повторювати у виключенні. Таке дублювання може бути чревате вразливостями. Більш детально про це ми поговоримо в главі 9.
Нічого складного в перевірці передумов немає, але продумування договорів вимагає більше зусиль. В яких випадках це виправдано? Наш досвід показує, що формулювання договорів і перевірка передумов публічними методами обов’язково окупляться. Це стосується простих перевірок – на нуль, на введення в діапазон тощо. Якщо мова йде про внутрішні способи упаковки, то це питання суб’єктивне. Для великих пакетів і активно використовуваних класів такі Перевірки, ймовірно, мають сенс, але у випадку з допоміжним класом, який не використовується в багатьох місцях, ми б їх пропустили. Що стосується приватних методів, то перевіряти їх не варто. Якщо класу потрібні внутрішні контракти, він, швидше за все, стане занадто великим і матиме багато додаткових обов’язків, тому його потрібно розбити.
ПОРАДА. Перевірте передумови для всіх публічних методів – принаймні переконайтеся, що вони не приймають null як аргументи.
Отже, ми розібралися, як перевірити аргументи, які передаються методам. Тепер перейдемо до аналогічної теми – аргументів конструктора. Поговоримо про ще одне поняття, яке згадує в своїй теорії Мейер поряд з передумовами і постумовами – інваріантами (це аспекти об’єкта, які завжди повинні бути істинними). Спочатку інваріанти повинні дотримуватися конструктором при створенні об’єкта.
Робота з аргументами конструктора трохи складніше, ніж з аргументами методу. Основне завдання конструктора – не стільки обробити або змінити стан об’єкта, скільки створити об’єкт в його початковому стані. Цей стан може бути створений в одній частині програми та використаний у зовсім іншій частині програми, тому, якщо він неправильний, він може спричинити дефекти, які важко відстежити, і це може встановити основу для вразливостей безпеки.
Щоб цього не допустити, краще якомога швидше припинити роботу.
У договорі конструктора може бути вказано, що одне з полів обов’язкове, і в цьому випадку досить переконатися, що відповідне значення не є Null. Слово «обов’язково» можна трактувати в тому сенсі, що даний об’єкт містить інваріант, згідно з яким поле завжди має дорівнювати деякому об’єкту і не може бути присвоєно null. Додаванням перевірки на Null-значення, ви гарантуєте, що інваріант виконано. Інваріанти можуть бути набагато складніше, але докладніше про це ми поговоримо в главі 6, де йдеться про захист мутабельного стану.
Лістинг 4.9 показує конструктор класу Cat. У договорі зазначено, що поля імені та статі не повинні бути невизначеними, тому потрібно перевірити, чи є вони нульовими. Також ми передбачили вже знайому перевірку на наявність звуку s в кличці кішки.

Зробити цей конструктор більш лаконічним можна за допомогою однієї з особливостей класу Validate. Метод notNull не тільки виконує перевірку, але і повертає перевірений об’єкт. Це робить конструктор Cat ще коротшим, як показано в лістингу 4.10.

Більшість методів перевірки повертають перевірене значення, але деякі ні. Сюди входить метод перевірки регулярних виразів matchesPattern, тому він не може використовуватися в скороченому вигляді і повинен бути в окремому рядку. Але при цьому отримуємо бажану поведінку: null дає NullPointerException, а неправильне ім’я кішки призводить до винятку.
Ви, напевно, вже помітили, що в коді є два розділи, які перевіряють поле імені. Це кричуще порушення принципу DRY (Don’t repeat yourself), згідно з яким одна і та ж ідея повинна бути реалізована тільки один раз. У главі 5 ми покажемо спосіб вирішення такого роду проблем, якому ми віддаємо перевагу, це використання примітиву домену, який в даному випадку приймає вигляд класу CatName.
Тепер ви знаєте, як переконатися, що методи приймають відповідні аргументи, і знаєте, що об’єкти створюються за допомогою конструкторів, які застосовують відповідні інваріанти. Пора переходити до останнього виду перевірок, які ми рекомендуємо застосовувати до договорів, який є передумовою того, що об’єкт повинен знаходитися в правильному стані.
Отже, потрібно подбати про виконання передумов, які вимагають, щоб об’єкт перебував у певному стані. Наприклад, якщо список імен кішок порожній, шукати наступний нік в черзі нелогічно. Це операція, яка не відповідає стану CatNameList. Як ви пам’ятаєте з таблиці. 4.3, для того, щоб використовувати nextCatName та dequeueCatName, контракт вимагає, щоб список CatNameList містив дещо.
Очевидним рішенням тут є використання Перевірити, щоб переконатися, що список у catNames не порожній. Однак метод помічника Validate.isTrue погано справляється з цією роботою. Якщо перевірка не вдається, вона кидає IllegalArgumentException, метод nextCatName не має аргументів, тому цей виняток буде виглядати дивно для абонента. На щастя, для таких ситуацій існує метод Validate.validState, який використовувався методом nextCatName у лістингу 4.11.

Лістинг 4.12 показує остаточну версію класу CatNameList з передумовами для захисту від неправомірного використання. Якщо приймаються дані, які навмисно або випадково порушують договір, робота негайно припиняється.

Як бачите, клас збільшився на п’ять рядків коду, але при цьому став набагато безпечніше. Неприпустимі аргументи відхиляються на ранній стадії, і об’єкт ніколи не може бути в неправильному стані. Основні зусилля були спрямовані на проектування і формулювання прийнятих рішень у вигляді договору. Але це робота, яку все одно треба виконувати.
Концепція швидкого завершення роботи підвищує безпеку і не вимагає багато коду. Це може бути корисно в більшому механізмі перевірки правильності та безпеки даних. У наступному розділі ми детальніше розглянемо різні рівні перевірки.
Для підтримки безпеки системи дуже важливо перевіряти правильність даних. Проект OWASP фокусується на перевірці вхідних даних (перевірка даних при надходженні в систему). Звучить досить очевидно і логічно, але, на жаль, не все так просто. Код повинен бути структурований таким чином, щоб вхідні дані перевірялися скрізь. Ще одна складність полягає у визначенні того, що можна вважати правильними даними, як це залежить від ситуації.
Запитувати, чи правильне одне значення, безглуздо. Чи є 42 дійсним входом? A –1 або <script>install(keylogger)</script>? Це залежить. При замовленні книг 42, швидше за все, буде прийнятною кількістю, а -1 – ні. Але при вимірюванні температури -1, безсумнівно, має сенс. У більшості ситуацій рядок зі скриптом неприпустима, але однозначно підійде для сайту з повідомленнями про дірки в безпеці.
Перевірка може означати багато різних речей. Деякі можуть сказати, що AV56734T є правильним номером замовлення, оскільки він відповідає формату, який використовується в системі. А хтось інший може заперечити, що замовлення з таким номером в системі немає. Але навіть якщо такий номер був, він міг виявитися некоректним, наприклад, через те, що в якийсь момент не вдалося організувати відправку цього замовлення. Очевидно, що що існує багато різних типів перевірок валідації.
Ви, напевно, вже знайомі з порадою щодо безпеки, як-от “перевірте введені дані”. Але, з огляду на всю цю плутанину з визначенням правильності, ця рада схожий на «за кермом уникайте аварій». Повідомлення явно правильне, але не дуже конструктивне.
Щоб уникнути непорозумінь, давайте скористаємося фреймворком, який намагається розділити різні типи перевірок. Список, показаний нижче, відповідає рекомендованому порядку виконання перевірок. Швидкі операції, такі як перевірка розміру вхідних даних, знаходяться у верхній частині списку, в той час як більш ресурсомісткі операції, що вимагають доступу до бази даних, наближаються до кінця. Таким чином, вхідні дані можуть бути відхилені ще до того, як будуть проведені ресурсомісткі і складні перевірки.
Рекомендуємо виконувати наступні типи перевірок, бажано в такому порядку.
Походження. Чи дані були передані довіреним відправником?
Розмір. Чи не надто вони великі?
Лексичний вміст. Чи містять вони відповідні символи у правильні кодування?
Синтаксису. Чи дотриманий формат?
Семантика. Чи є дані осмисленими?
Як уже згадувалося, походження і розмір можна перевірити швидко і не витрачаючи багато ресурсів. Перевірка лексичного змісту вимагає аналізу даних, що займає більше часу і створює більше навантаження на систему. Перевірка синтаксису може виражатися в розборі, це займе багато часу для потоку виконання і займе багато процесорного часу. І перевірка значущості введення передбачає доступ до бази даних – це важка операція. Таким чином, ми можемо уникнути непотрібних ресурсомістких перевірок. Давайте розглянемо кожен з цих типів перевірок і подивимося, яку роль вони відіграють у розробці безпечного програмного забезпечення. Почнемо з походження даних.
Перш ніж обробляти дані, цілком логічно перевірити, звідки вони взялися. Справа в тому, що багато атак асиметричні на користь зловмисника. Це означає, що зусилля, які потрібні для відправки шкідливих даних, набагато менше, ніж потрібно системі для їх обробки. Цей принцип лежить в основі DoS-атаки: система отримує стільки безглуздого введення, що перестає виконувати свої безпосередні обов’язки, так як всі його ресурси витрачаються на обробку вхідних даних.
Дуже популярна розподілена DoS-атака (DDoS), під час якої багато шкідливих клієнтів, що знаходяться в різних місцях, одночасно відправляють в систему безліч повідомлень. Клієнтами часто є ботнети, що складаються з комп’ютерів, які хтось заразив вірусом з функцією віддаленого управління. Цей вірус перебуває в стані спокою, поки не отримає повідомлення від хоста. Такі ботнети можна купити або взяти напрокат в гарячих куточках інтернету.
На жаль, перевірка походження даних не завжди рятує, але це перша проста міра, спрямована на зміщення асиметрії асиметрії атаки на свою користь. Якщо дані надійшли з надійного джерела, ви можете продовжити роботу, якщо ні – ми відхилимо їх. Для цього є два основних механізми: можна перевірити IP-адресу, з якої прийшло введення, або можна зажадати ключ доступу до API. Почнемо з перевірки IP-адреси – це найпростіший варіант.
Перевірка IP-адреси
Найбільш очевидним способом перевірити правильне походження даних є перевірка IP-адреси, з якої вони були відправлені. Такий підхід вже не такий поширений, як раніше, тому що речі стають все більш взаємопов’язаними в інтернеті, але він все одно має певний сенс.
Якщо у вас є архітектура мікросервісів, деякі служби будуть знаходитися на межі архітектури мікросервісів, приймаючи зовнішній трафік, тоді як інші будуть розміщені всередині компанії і прийматимуть дзвінки лише з інших служб. Внутрішнім службам може бути дозволено спілкуватися з трафіком лише в межах певного діапазону IP-адрес, що належать іншим службам. Для периферійних сервісів це, ймовірно, не спрацює, оскільки вони можуть бути доступні для будь-яких клієнтів.
На практиці такого роду перевірки не виконуються всередині програми. Натомість доступ обмежено на рівні конфігурації мережі. У фізичному приміщенні це робиться за допомогою роутерів. У хмарних сервісах, таких як Amazon Web Services (AWS), можна створити групу безпеки, яка дозволяє приймати вхідний трафік тільки з IP-адрес в певному діапазоні або списку. Якщо ваша система працює всередині компанії (наприклад, в торговій точці), ви можете перевірити походження повідомлення, визначивши, чи прийшло воно з адреси з певного діапазону IP. Наприклад, якщо доступ до серверів повинен здійснюватися тільки через PoS-термінали або офісні комп’ютери, розташовані в корпоративній мережі, можна обмежити доступ до цих діапазонів. На жаль, в нашому світі, в якому все стає взаємопов’язаним, такі ситуації зустрічаються все рідше.
Також майте на увазі, що фільтри IP-адрес, фільтри MAC-адрес та подібні інструменти не надають жодних гарантій. MAC-адреса може бути змінена в операційній системі, а IP-адреси можуть бути підроблені або запозичені у скомпрометованого пристрою. Однак вони забезпечують певний захист початкового рівня.
Використання ключа доступу до API
Якщо системі доводиться приймати запити з багатьох різних місць, ви не зможете перевірити їх IP-адреси. Наприклад, якщо ваші клієнти можуть знаходитися в будь-якій точці інтернету, то всі IP-адреси відправника слід вважати дійсними. Це стосується практично будь-якого державного сервісу, який взаємодіє з користувачами. На щастя, доступ до системи можна обмежити і іншим способом – запросивши ключ доступу. Такий ключ можна оформити всім перевіреним клієнтам. Якщо клієнтом є інша система, ключ може видаватися в процесі її розгортання. Якщо мова йде про додатки, то ключ може бути вбудований в їх код. Ключ також може бути виданий клієнтам, які підписують якусь призначену для користувача угоду. Суть тут полягає в тому, що власник ключа доступу підтверджує, що йому дозволено передавати дані в вашу систему.
Візьмемо, наприклад, AWS. Він має REST API, який дозволяє керувати такими ресурсами, як хмарне сховище S3. При відправці HTTP-запиту на цей інтерфейс необхідно вказати свій ключ доступу в заголовку Authorization HTTP, як показано в Лістингу 4.13. Якщо такого заголовка немає, запит відхиляється. Але одного ключа доступу недостатньо. Зловмисник теоретично може перехопити його і видати себе за вас. Щоб цього не сталося, заголовок авторизації також повинен містити підпис на основі закритого ключа, відомі тільки вам і AWS, за допомогою яких було підписано вміст повідомлення. AWS може визначити, який закритий ключ використовувати для перевірки підпису, аналізуючи ключ доступу.

У цьому випадку вам потрібно надати деякі обчислення на стороні сервера, оскільки вам потрібно переконатися, що повідомлення має правильний підпис. Для цього не потрібно багато ресурсів, але є ризик, що хтось надішле вам велику кількість даних і змусить їх обробити. Добре тут те, що зловмиснику потрібен реальний ключ доступу, який завжди можна на деякий час внести в чорний список. Мінус такого підходу в тому, що доводиться виконувати додаткову роботу. Але, на щастя, зазвичай достатньо реалізувати цей механізм лише один раз, а також його може забезпечити шлюз API або аналогічний продукт. Збираючись написати її самостійно, не забудьте перевірити правильність клавіші доступу (довжину, набір символів, формат), щоб вона не перетворилася в вектор атаки.
Доступ до маркерів
Ключ доступу – це тип маркера доступу. Деякі протоколи, такі як OAuth, дозволяють серверу аутентифікації генерувати токен, який згодом можна використовувати для підтвердження авторизації та доступу до інших ресурсів. Спільним для цих двох механізмів є те, що вони вимагають попередньої аутентифікації, і їх наявність доводить справжність відправника.
Контроль доступу за допомогою аутентифікації та авторизації – це цілий світ сам по собі. Почати можна з OAuth (див.: www.oauth.com).
Перевіривши походження даних, ви можете витратити деякий час на їх обробку, не піддаючись особливо небезпеці. По-перше, потрібно переконатися, що дані мають прийнятний розмір.
Чи є сенс приймати замовлення розміром 1 ГБ? Напевно, ні. Якщо ви вже знаєте, що походження даних правильне, потрібно перевірити їх розмір. В ідеалі це потрібно зробити якомога раніше.
Який розмір можна вважати розумним? Це повністю залежить від ситуації. Наприклад, дані, завантажені на відеосайт, можуть легко займати від 100 МБ до декількох гігабайт, і в цьому немає нічого незвичайного. Однак бізнес-застосунок, заснований на JSON або XML, приймає повідомлення, розмір яких, ймовірно, буде кілобайт. Який розмір є прийнятним для ваших даних?
Якщо дані надходять по протоколу HTTP, перевірити його розмір можна по заголовку
Зміст-довжина. Якщо ви виконуєте пакетну обробку, ви можете перевірити розмір файлу.
При обробці даних можна перевірити не тільки його загальний розмір, але і габарити окремих його частин. Зловмисник може приховати номер замовлення на 1 ГБ у запиті. Ви можете забути перевірити розмір запиту, або цей розмір може бути в межах норми, але на випадок, якщо номер замовлення буде занадто великим, у вас буде захисний механізм.
Сподіваємося, такий підхід виглядає розумним. З його допомогою ви зможете забезпечити досить надійний захист без додаткових зусиль. Якщо застосувати цю техніку до номера замовлення, номера телефону, назви вулиці, поштового індексу тощо, зловмиснику буде набагато складніше знайти місце для введення великих даних. Ваш захист гарантує, що жоден з елементів даних не може бути надзвичайно великим.
Наприклад, якщо ви керуєте книжковим інтернет-магазином, ви можете отримати набір файлів або HTTP-запитів, пов’язаних із замовленням деяких книг. Ці книги, швидше за все, ідентифікуються дев’ятизначним номером ISBN (International Standard Book Number) з додатковою контрольною цифрою. Перевірка всього файлу або HTTP-запиту на прийнятний розмір має сенс, але якщо ви вже виділили елемент, який повинен представляти номер ISBN, ви можете перевірити його окремо. Лістинг 4.14 показує клас, який представляє номер ISBN, і перевіряє його довжину, щоб запобігти DoS-атакам.

У деяких випадках перевірка довжини рядка може виглядати зайвою. На більш пізніх етапах ми часто перевіряємо зміст і структуру даних за допомогою регулярного виразу (регулярного виразу, або regexp). Regexp може виглядати так:
[a-z] – один символ у діапазоні між a та z;
[А-Я]{4} – чотири букви, кожна в діапазоні між А і Я; [1-9]* — цифри від 1 до 9 у будь-якій кількості.
Якщо наступним кроком буде перевірка формату на відповідність регулярному виразу [0-9]{20} (рівно 20 цифр від 0 до 9), здавалося б, навіщо перевіряти довжину окремо? Двадцятип’ятизначний рядок все одно буде відкинутий, чи не так? Справа тут у тому, що перевірка довжини захищає двигун регулярних виразів. Що робити, якщо рядок складається не з 25 символів, а з мільярда символів? Швидше за все, Механізм регулярних виразів завантажить цей величезний вхід і почне його обробляти, не усвідомлюючи, що він занадто великий. Попередня перевірка довжини дозволяє убезпечити наступні кроки.
Переконавшись, що вхідні дані потрібного розміру, можна, нарешті, заглянути всередину. Перш за все, нам потрібно перевірити, чи відповідає тип вмісту тому, який ми очікуємо. Це стосується, наприклад, символів і кодування, які відносять до лексичного змісту.
Переконавшись, що ваші дані надходять із надійного джерела та мають достатній розмір, ви можете вирішити проаналізувати їх вміст. Швидше за все, рано чи пізно вам доведеться проаналізувати дані, щоб витягти з них цікавлять вас елементи, наприклад, якщо вони прийшли в форматі JSON або XML. Але цей процес вимагає багато процесорного часу та пам’яті, тому спочатку слід зробити більше перевірок.
В ході лексичного розбору даних ми перевіряємо їх вміст, але не структуру. Ми стежимо, щоб вони містили відповідні символи і мали правильне кодування. Якщо ми виявимо щось підозріле, ми можемо відхилити дані, навіть не почавши аналіз, що може вивести сервери з ладу.
Наприклад, коли ми очікуємо отримати дані тільки з цифрами, ми перевіряємо, чи є ще щось в потоці. Якщо вдасться щось знайти, то робимо висновок: дані або пошкоджені випадково, або навмисно сформовані таким чином, щоб обдурити систему. У будь-якому випадку від них краще відмовитися. Аналогічно, якщо ми очікуємо отримати звичайний текст у форматі HTML, ми перевіряємо, чи має він відповідний вміст. При цьому кожен символ < повинен бути закодований як < , тому ми не повинні стикатися з будь-якими кутовими дужками. Наявність кутового кронштейна має насторожити. Можливо, хтось намагається таємно ввести шматочок JavaScript? Щоб не ризикувати, дані знову відхиляються.
Лексичне наповнення визначає, як повинні виглядати дані при найближчому розгляді, коли ми звертаємо увагу на окремі деталі, а не на більші структури. У багатьох простих випадках прості регулярні вирази відмінно підходять для перевірки лексичного змісту. Наприклад, формат ISBN-10 для книг може містити тільки цифри і букву Х. У номері ISBN також можуть бути дефіси та пробіли, які полегшують розуміння, але для простоти ми будемо їх ігнорувати. У списку 4.15 показано розширену версію знайомого класу ISBN, яка тепер перевіряє, чи містить номер ISBN відповідні символи.

Якщо ви маєте справу з більш складними входами, такими як XML, ви можете використовувати більш потужний лексичний аналізатор. Лексичний аналізатор розбиває послідовність символів на частини, які називаються лексемами або лексемами. Їх можна розглядати як елементарні складові зі значенням або послідовності символів, які утворюють синтаксичну одиницю. У письмовій англійській мові лексемами вважаються окремі слова. У XML маркери – це теги і те, що знаходиться між ними. Списки 4.16 та 4.17 показують XML-документ та його маркери.


У деяких ситуаціях, коли вам не потрібна повна потужність XML, можна обмежити цей формат. У розділі 1 я навів приклад того, наскільки небезпечно допускати XML-сутності на вхідних даних. Відносно короткий XML-файл, показаний у списку 4.18, має довжину менше 1,000 символів. Однак він розгортається в мільярд рядків lol, що, ймовірно, зламає наш бідний аналізатор.
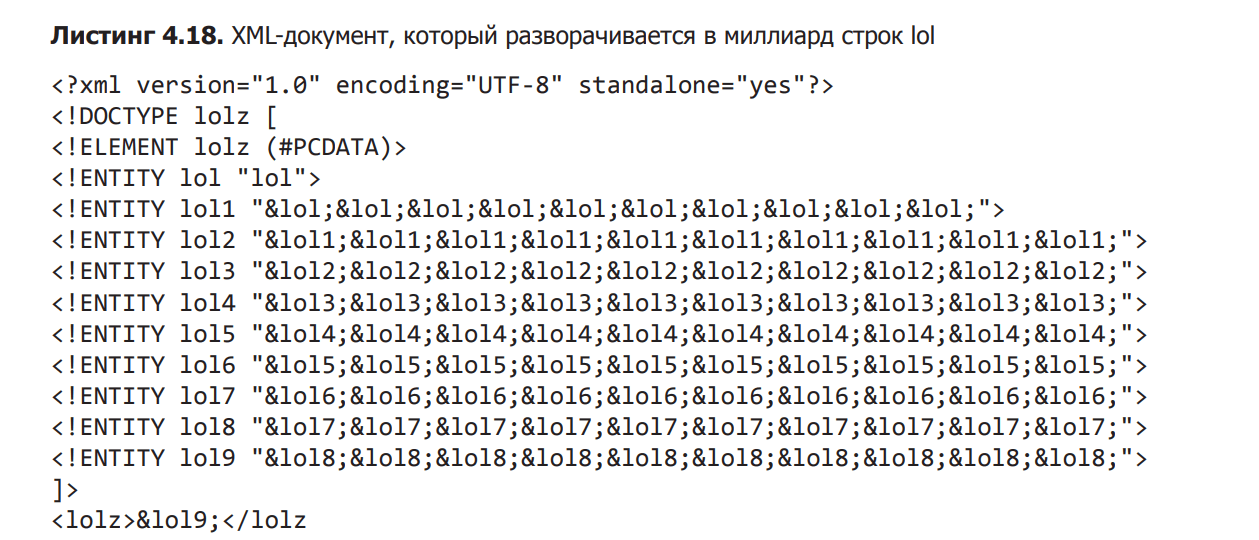
Само собою зрозуміло, що мільярд рядків lol – це знущання над аналізатором, якого не можна допускати. Щоб уникнути цього, ви можете запобігти використанню визначень сутностей XML без розпізнавання <! ENTITY як дійсний токен. Якщо вас цікавлять деталі, ви можете повернутися до розділу 1.5.
На практиці робота з XML-документами найчастіше полягає в їх аналізі, спрямованому на вилучення цікавлять нас елементів. Не потрібно аналізувати двічі, спочатку перевіряючи лексичний зміст, а потім аналізуючи синтаксис структури. Замість цього лексичні перевірки можуть бути виконані як частина розбору. Для цього проводиться лексичний розбір під час потокової обробки, що ми і зробили в главі 1. Переконавшись, що ваші дані надходять від надійного відправника, мають правильний розмір і містять правильні типи маркерів, ви можете виділити ресурси для їх більш глибокого вивчення, наприклад, аналізу, щоб переконатися, що вони правильно відформатовані та структуровані.
Нерідкі випадки, коли дані надходять у форматі XML або JSON, і вам потрібно проаналізувати їх, щоб зрозуміти. У попередньому розділі ми пояснили, як дивитися на дані зблизька — на лексичному рівні. Перевіряючи синтаксис, ми піднімаємося на рівень, щоб побачити загальну картину того, що відбувається. У XML нам потрібно переконатися, що кожен відкриваючий тег має закриваючий тег і що атрибути всередині тегів добре сформовані.
Іноді досить використовувати регулярні вирази для перевірки синтаксису. Але, чесно кажучи, такий підхід не завжди простий: ми не раз бачили, як люди створюють складні регулярні вирази, які часом неможливо зрозуміти. Радимо вибирати цей шлях тільки в простих випадках. Якщо у вас болить голова при погляді на регулярний вираз, подумайте про можливість форматування цієї логіки у вигляді коду.
Одним із прикладів простої перевірки синтаксису є номери ISBN. Як уже згадувалося, номер ISBN складається з дев’яти правильних цифр і однієї контрольної цифри. Контрольна цифра може бути 10, на що вказує буква X. Синтаксис ISBN можна перевірити за допомогою регулярного виразу. Для цього потрібно переконатися, що дані відповідають формату [0-9]{9}[0-9X]. Якщо тест пройшов успішно, Це означає, що формат дотриманий. Якщо ні, то дані слід відхилити.
Для більш складних структур даних, таких як XML, потрібен аналізатор. Розбір великих, складних структур вимагає значних обчислювальних ресурсів. Саме тому при DoS-атаці на систему в якості мети часто вибирається аналізатор. Для його захисту реалізуються багато з описаних раніше кроків, включаючи перевірки походження, розміру даних і лексичного змісту.
Ми вже згадували, що в рамках парсингу потрібно перевірити, чи прийшли дані в підходящому вигляді. Для цього скористаємося одним з найпоширеніших механізмів – контрольною сумою. ISBN служить хорошим прикладом, оскільки остання, десята цифра – це контрольний список. Не будемо вдаватися в подробиці того, як обчислюється контрольна сума, відзначимо лише, що дана процедура виконується в складі перевірки синтаксису. Лістинг 4.19 показує іншу версію класу ISBN, цього разу з форматуванням та контрольним аналізом цифр.

Якщо структура синтаксису досить проста, було б дивно виконувати лексичну, а потім і синтаксичну перевірку з використанням схожих регулярних виразів. У таких ситуаціях дані перевірки часто комбінуються, як у Лістингу 4.20.

Вам може здатися, що порядок виконання перевірки правильності тут не дотримується. Насправді лексичний і синтаксичний розбір настільки схожі, що ми проводимо їх за одним і тим же механізмом. Можна думати, що вони поєднуються або переплітаються. Дотримується базовий порядок перевірки правильності. Отже, переконавшись, що дані правильно відформатовані та мають правильний вміст, розмір та походження, ми можемо порівняти їх із даними, які ми вже маємо (якщо це має сенс).
Перевіривши походження, розмір, зміст і структуру, ви стали настільки довіряти входам, що готові використовувати їх для подальшої роботи. До цього моменту ви вже могли виконувати перевірки, які створюють велике навантаження на процесор і вимагають багато пам’яті. Наприклад, можливо, ви обробили велике XML-повідомлення, в якому говориться, що вам потрібно додати багато елементів до замовлення. Але раніше ми працювали з вхідними даними ізольовано від решти системи. І цілком імовірно, що ви ще ніколи не отримували доступ до бази даних.
У прикладі великого XML-повідомлення може знадобитися розширити порядок, додавши багато елементів, але ви ще не перевірили, чи існують відповідні елементи, і, звичайно, не знаєте, чи є вони в наявності. Це замовлення може не існувати взагалі або могло бути відправлено раніше, що унеможливлює його розширення. Ви щойно перевірили синтаксис.
Тепер настав час семантичної перевірки: чи мають ці дані сенс і чи узгоджуються вони зі станом, в якому знаходиться решта системи? В ході семантичного аналізу ми перевіряємо такі речі, як наявність номера товару в каталозі товарів або можливість додавання ще одного товару в описуване замовлення. Ми вважаємо, що найбільш логічним місцем для таких обмежень є доменна модель.
Пошук по каталогу товарів сервісу вашого домену може виражатися в перевірці наявності номера товару. Якщо товару не існує, викидається виняток і переривається потік виконання. Аналогічно, якщо хтось спробує додати товар до вже закритого замовлення (який, можливо, був оплачений і відправлений), це буде проявлятися як IllegalStateException в класі Order. Насправді ми переконані, що модель предметної області є настільки природним місцем для розміщення цієї логіки, що ми навіть не вважаємо її перевіркою валідації – для нас це частина самої моделі.
Однак ми згодні з тим, що семантична валідація займає заслужене місце в списку перевірок валідації. Валідація завжди виконується на чомусь. Ви перевіряєте, чи відповідають дані деяким правилам і обмеженням, які складають модель домену. Модель відображає те, як ви дивитеся на світ. Ви змоделювали номери замовлень у певному форматі та зробили замовлення недоступними для редагування після їх відправлення. Пройшовши всі ці кроки, можна бути впевненим, що дані відповідають моделі – це перевірено.
На даний момент ми вже знаємо, що дані надходять від довіреного відправника, мають розумний розмір, відповідний вміст і структуру, а також відповідають решті даних. Тепер ми можемо без ризику додати книгу в кошик, прийняти оплату або передати замовлення до відділу доставки.
Якщо код відображає факт і ступінь достовірності даних, він служить потужним захистом на рівні проектування. Прикладом може служити клас ISBN, який ви бачили раніше. Це невеликий складений елемент, який орієнтований на домен і, як відомо, містить ISBN у правильному форматі. Необхідності в додатковій перевірці цього номера немає. Як показує наш досвід, дизайн таких складових елементів (ми називаємо їх примітивами домену або предметними примітивами) area) творить чудеса для безпеки системи. Прийшов час детально обговорити, як вони розробляються.
Цілісність даних полягає у забезпеченні їх узгодженості та точності протягом усього життєвого циклу.
Доступність даних — це гарантія того, що вони можуть бути отримані з очікуваним рівнем продуктивності системи.
Незмінні значення можна безпечно розділяти між потоками виконання, не використовуючи блокування: немає блокувань — немає конфліктів.
Принцип незмінності дозволяє уникнути проблем з доступністю даних, забезпечуючи масштабованість без блокувань між потоками.
Принцип незмінності вирішує проблеми цілісності даних за рахунок заборони на їхню зміну.
Контракти – це ефективний спосіб визначення чітких обов’язків для об’єктів та методів.
Краще швидко припинити роботу передбачуваним способом, не ризикуючи зіткнутися з непередбаченими збоями. Швидко припиняйте роботу за рахунок перевірки передумов у кожному методі.
Перевірку коректності можна розділити на перевірку походження, розміру даних, лексичного вмісту, синтаксичного формату та семантики.
Щоб підтвердити походження, можна перевірити IP-адреси або вимагати ключ доступу. Це допомагає захиститися від DDoS-атак.
Перевірити розмір даних можна як на вході в систему, так і при створенні об’єкт.
Перевірку лексичного вмісту можна виконати за допомогою простого регулярного вираження (regexp).
Для перевірки синтаксичного формату може знадобитися синтаксичний аналізатор, який витрачає більше процесорного часу та пам’яті.
Семантична перевірка найчастіше передбачає звернення до бази даних наприклад, у пошуку елемента з певним ID.
Перевірки, що проводяться на ранніх етапах, є більш економними і служать захистом для подальших, більш ресурсоємних перевірок. Якщо ранні перевірки провалюються, інші етапи можна пропустити.
Ми використовували матеріали з книги “Безпека by design”, які написали Дэн Берг Джонсон, Дэниел Деоган, Дэниел Савано.





