
20.03.2024
1 хв
1920

Розглядається структура та компоненти ІТ-інфраструктури, порівнюючи їх із інфраструктурою міста з основними послугами для його мешканців. Розповідається про створення інфраструктури компанії, деталізуючи виклики, такі як єдині точки відмови (SPOF), та рішення для підвищення стійкості, наприклад, командування мережевих інтерфейсів та використання керованих комутаторів.

Хто такий системний адміністратор? Людина, яка налаштовує і відповідає за регулярну роботу комп’ютерного обладнання, мереж і програмного забезпечення, які разом називаються ІТ-інфраструктурою. Її можна порівняти з інфраструктурою міста. Існують системи водопостачання, електропостачання, доріг, збору сміття тощо, які необхідні для безпечного життя та роботи людей у місті; так само і в ІТ: без належної інфраструктури користувачі не можуть безпечно працювати. Хоча всі міста мають інфраструктуру, вона є специфічною для кожного міста; те ж саме стосується і ІТ-інфраструктури – скрізь вона дещо відрізняється, але фундаментальні основи однакові. Тому питання “Як розвинена інфраструктура?” Відповідь на питання “Що таке інфраструктура?” варіюється від компанії до компанії.
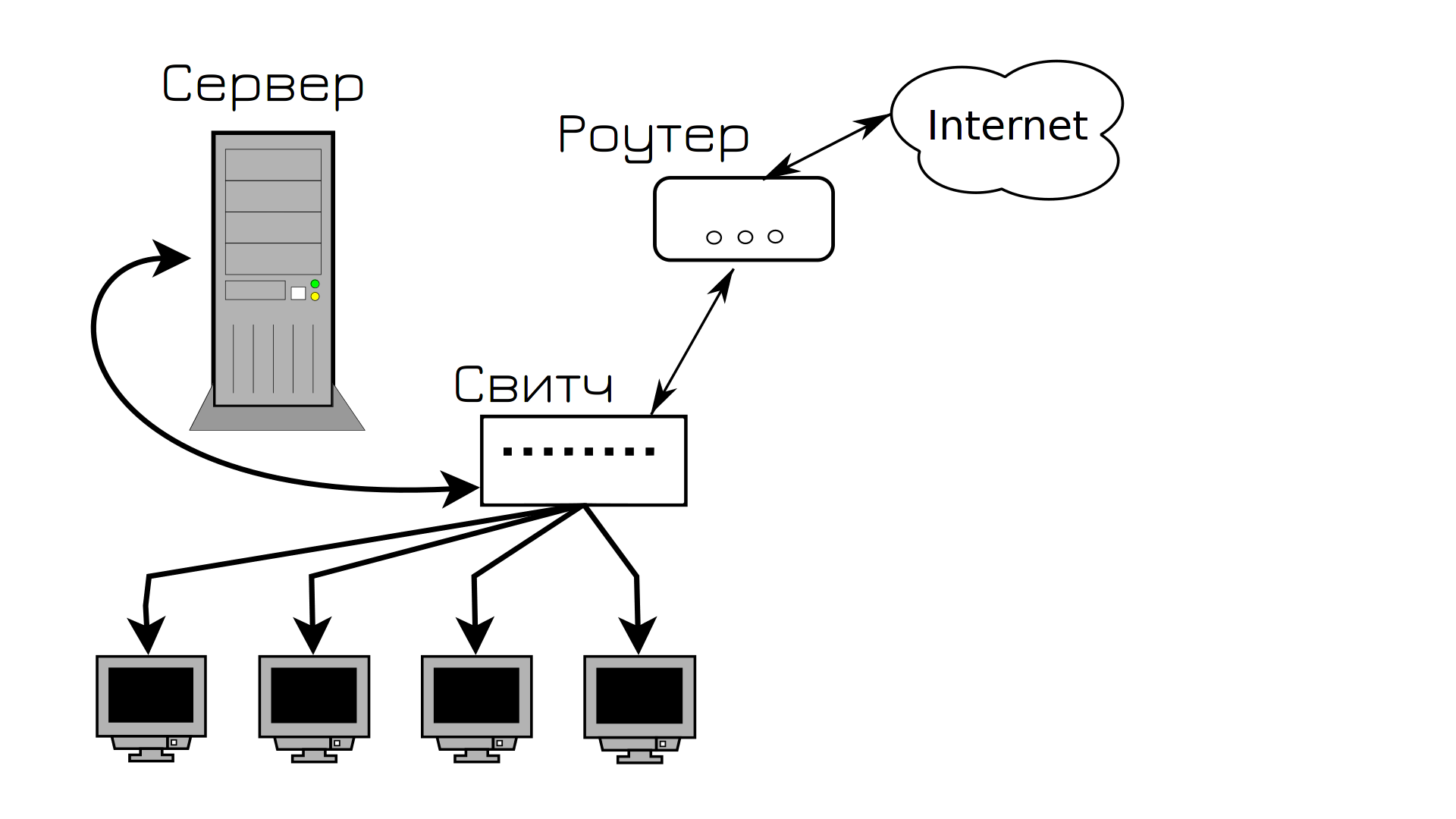
Ми створюємо компанію з власною інфраструктурою. Звертаємося до провайдера і просимо надати нам роутер та інтернет. Системний блок називаємо сервером: встановлюємо Linux, налаштовуємо сервіс і даємо йому IP-адресу. Для з’єднання користувачів, серверів і роутерів купують простий комутатор і з’єднують їх мідним патч-кордом. Так створюється інфраструктура.
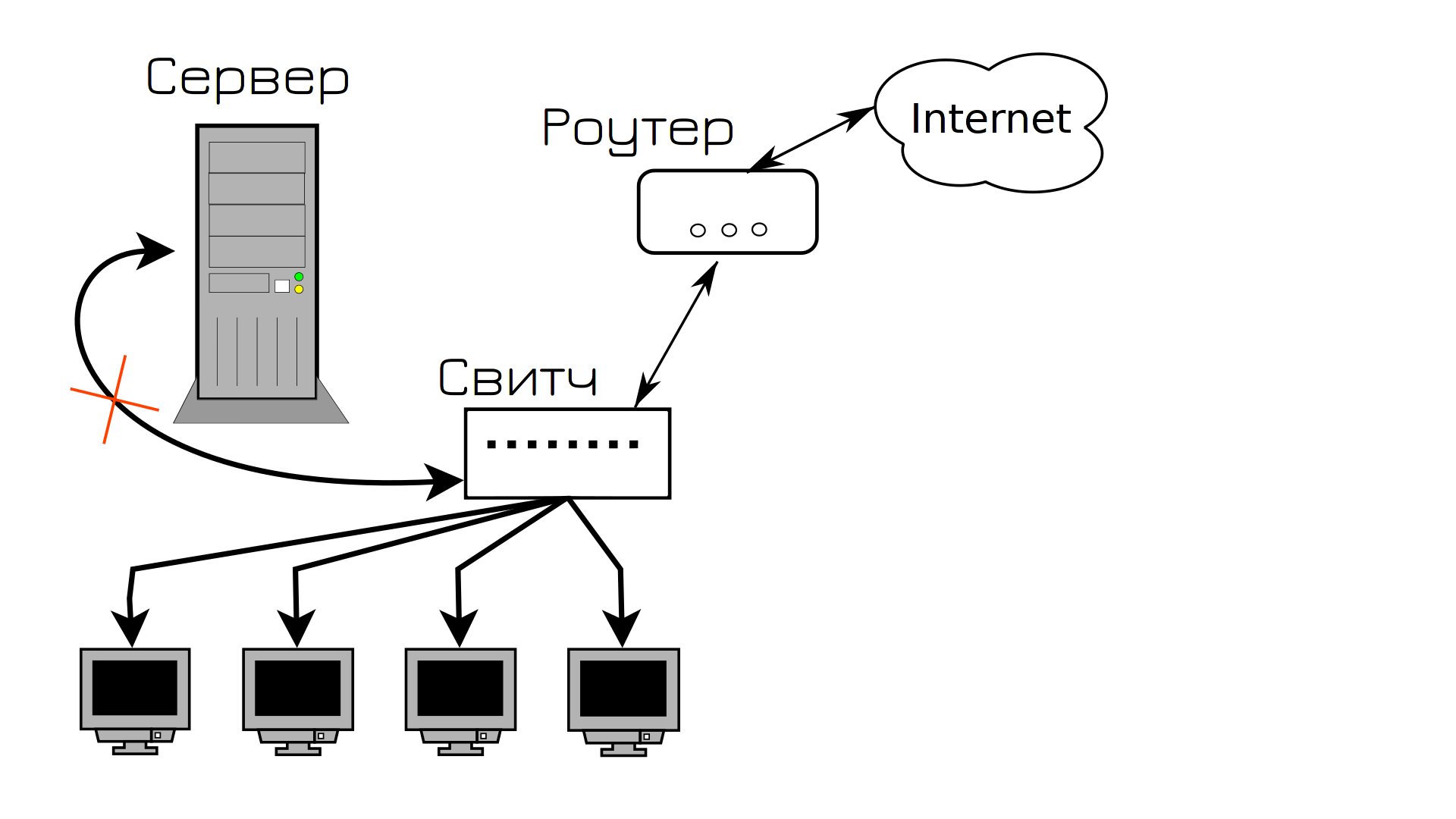
І все працює, поки одного дня хтось випадково не покладе щось важке на кабель, що йде до сервера. Кабель зіпсується і сервер стає недоступним. А ви цього дня взяли відгул. Користувачі не можуть зайти на сервер, клієнти не задоволені і вам терміново потрібно їхати в офіс і підключати новий кабель.
Вся ця історія знайомить нас з таким терміном, як SPOF – єдиний пункт відмови. Це такий елемент системи, вихід із ладу якого призводить до зупинення роботи сервісу. Сервіс не в плані програми в системі, а в плані послуги споживача. Так от, у нашій інфраструктурі кабель, що з’єднує сервер зі свитчем, був єдиною точкою відмови – він вийшов з ладу і сервіс став недоступним. Навіть якщо операційна система працює, програма всередині працює – для користувачів вона недоступна.
SPOF – це рушійна сила IT, це один із головних термінів, що відповідають на більшість питань, у тому числі чому інфраструктура влаштована так, а не інакше. Втім, ви зрозумієте все, давайте продовжимо.
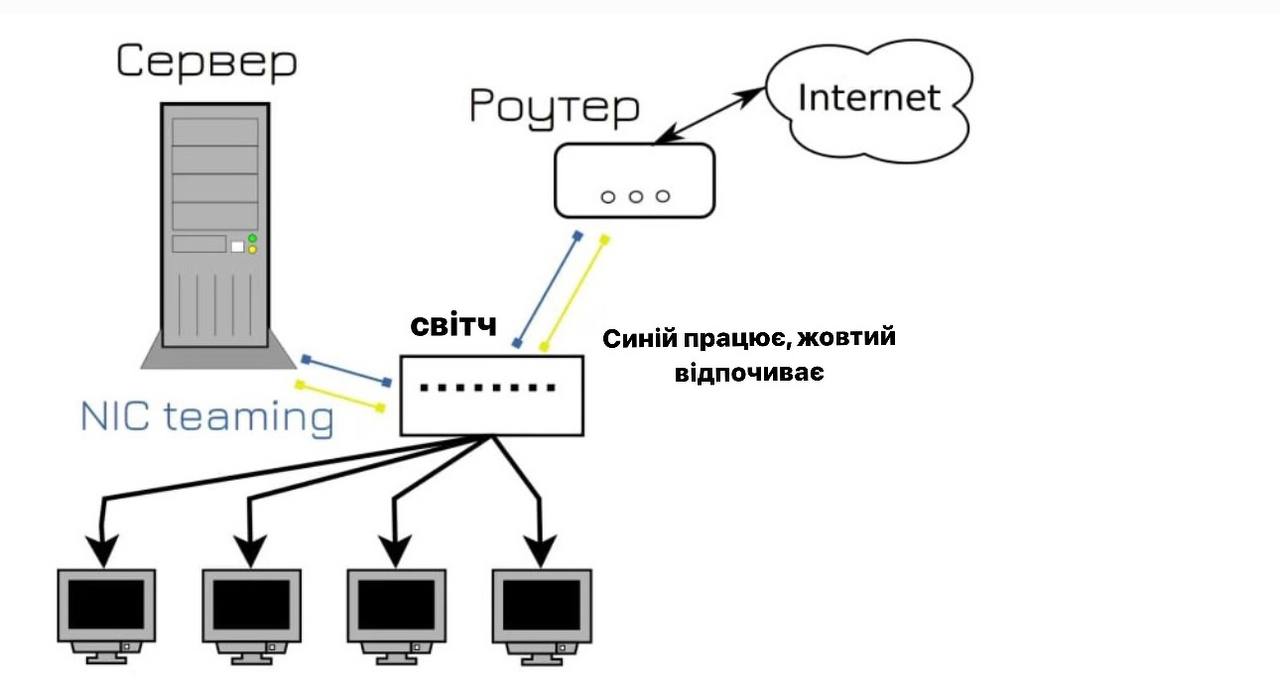
Звичайно, ми могли б просто замінити кабель і сподіватися, що це більше не повториться, але ми зробимо розумний вибір і спробуємо запобігти цій ситуації. В інтернеті ми знайшли метод, який називається об’єднання мережевих карт. Він об’єднує два порти в системі, один з яких працює, а інший знаходиться в режимі очікування. Якщо щось трапляється з першим портом або кабелем, все переходить на другий порт. Тому ми вирішили підключити сервер до свитчу двома портами і водночас зробити те саме з роутером на випадок, якщо щось станеться з кабелем. Це міг би бути комп’ютер, але у свитка не так багато портів, і якщо у користувача обірветься кабель, він зможе переключитися на wifi.
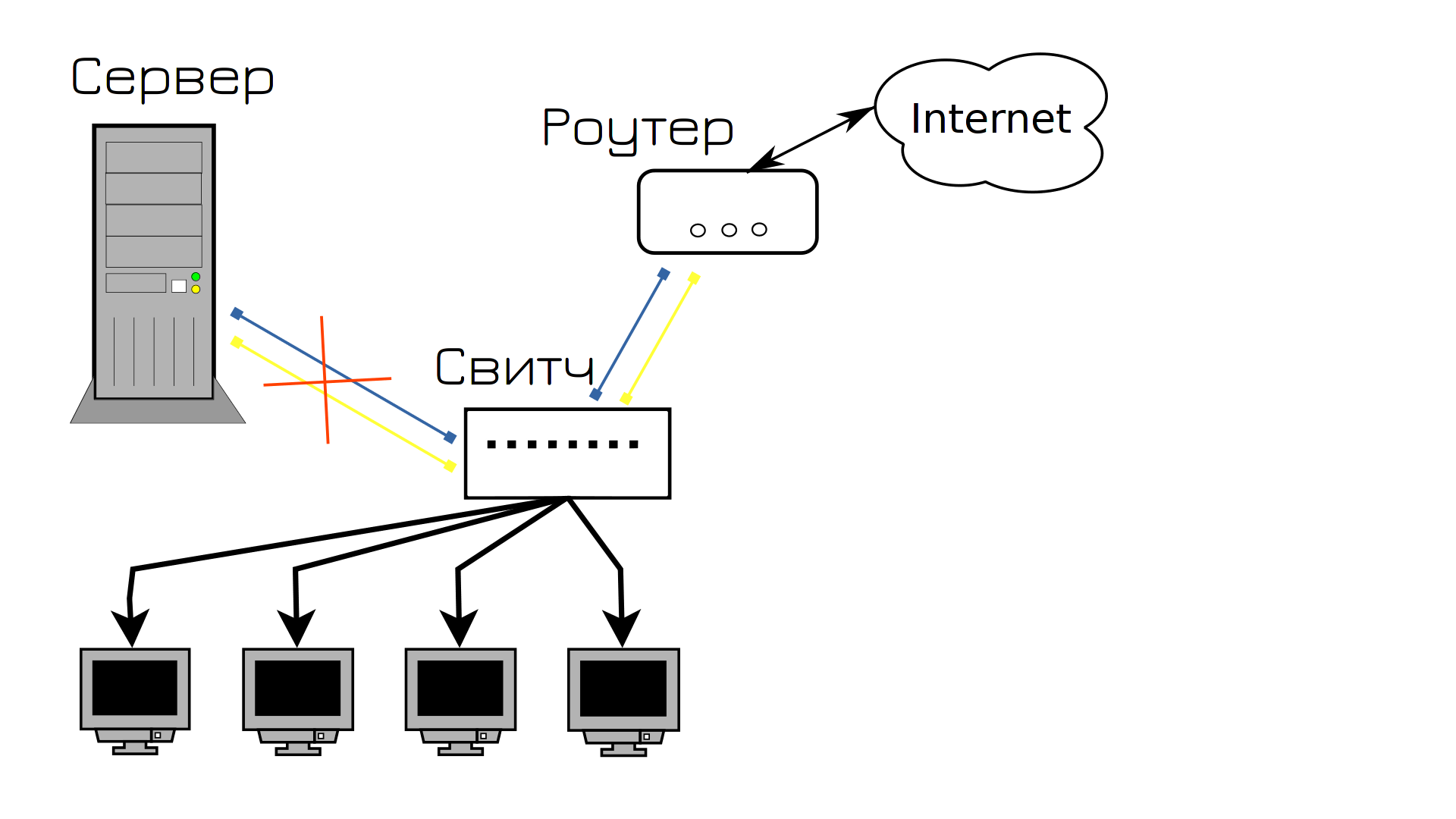
І все начебто нормально, поки в один із днів на сервері не виходить з ладу мережевий адаптер. Оскільки вийшов з ладу адаптер, до якого були підключені обидва кабелі, знову сервіс став недоступний, знову користувачі незадоволені.
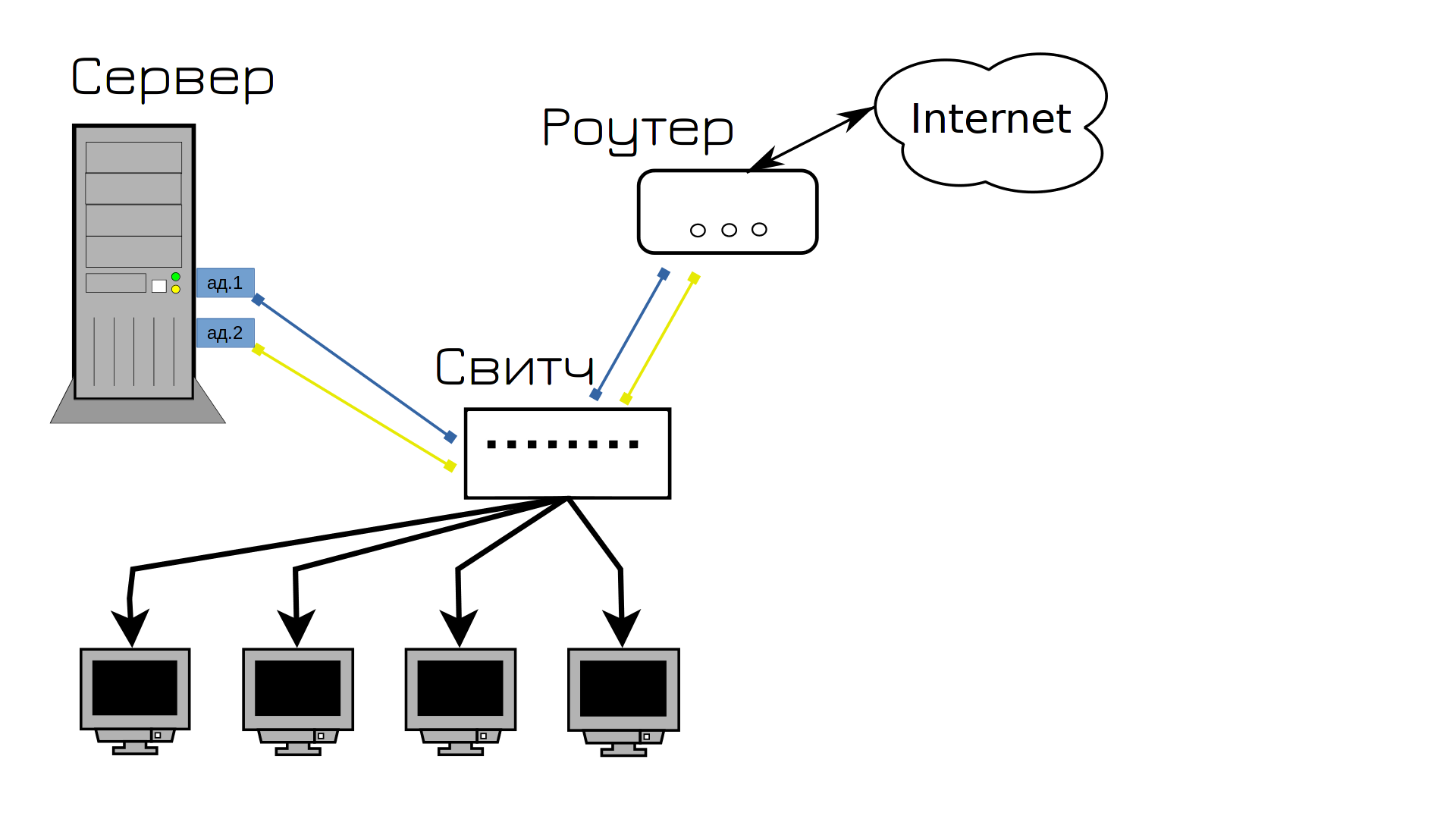
І щоб вирішити цю проблему і запобігти майбутньому, ми купуємо два мережеві адаптери. Вийде з ладу один – все автоматично перейде на другий, а ми тим часом купимо новий адаптер і замінимо.
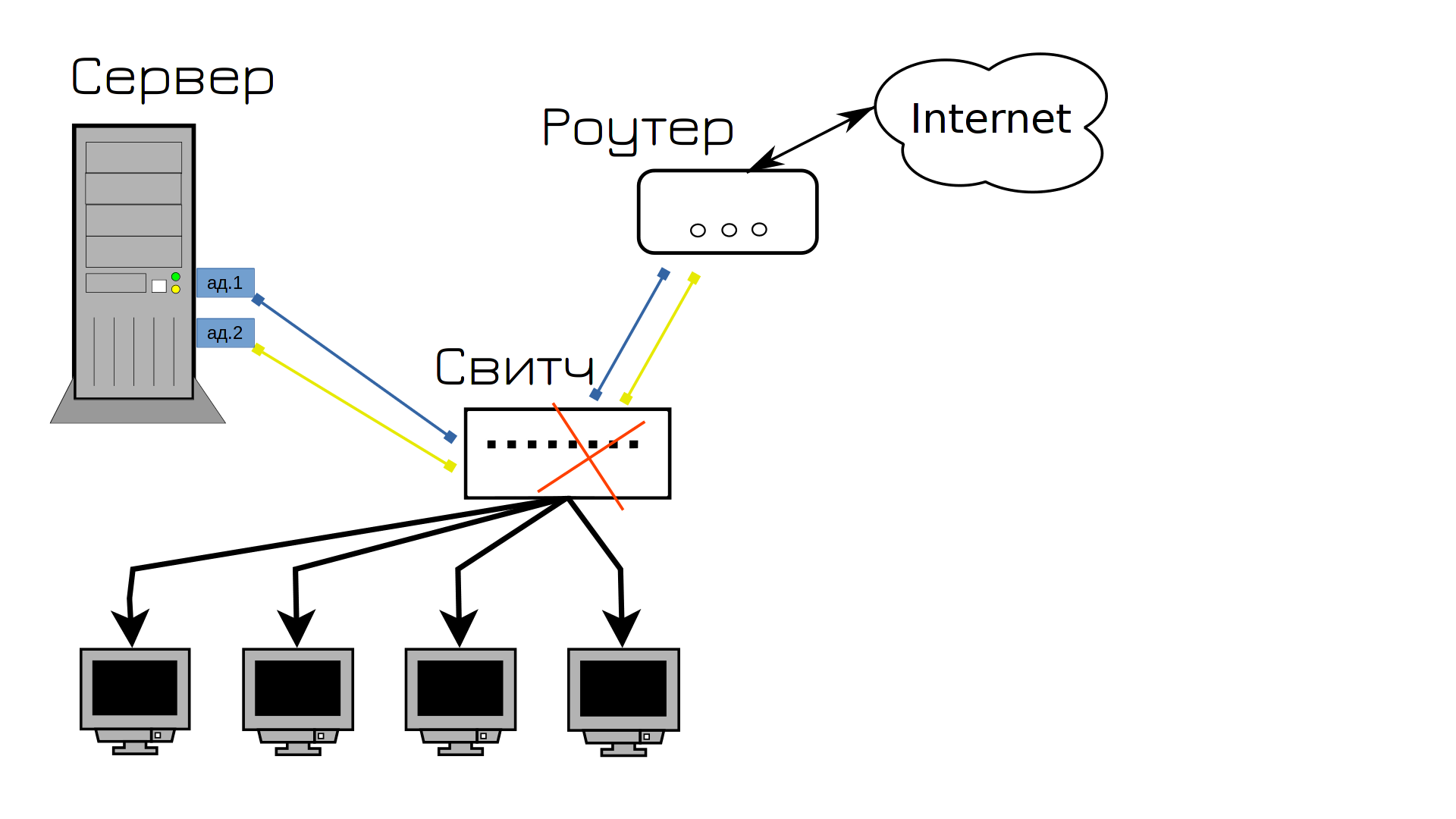
Знаєте, що потім вийшло з ладу? Світч. І як ми це вирішимо і запобігмо?
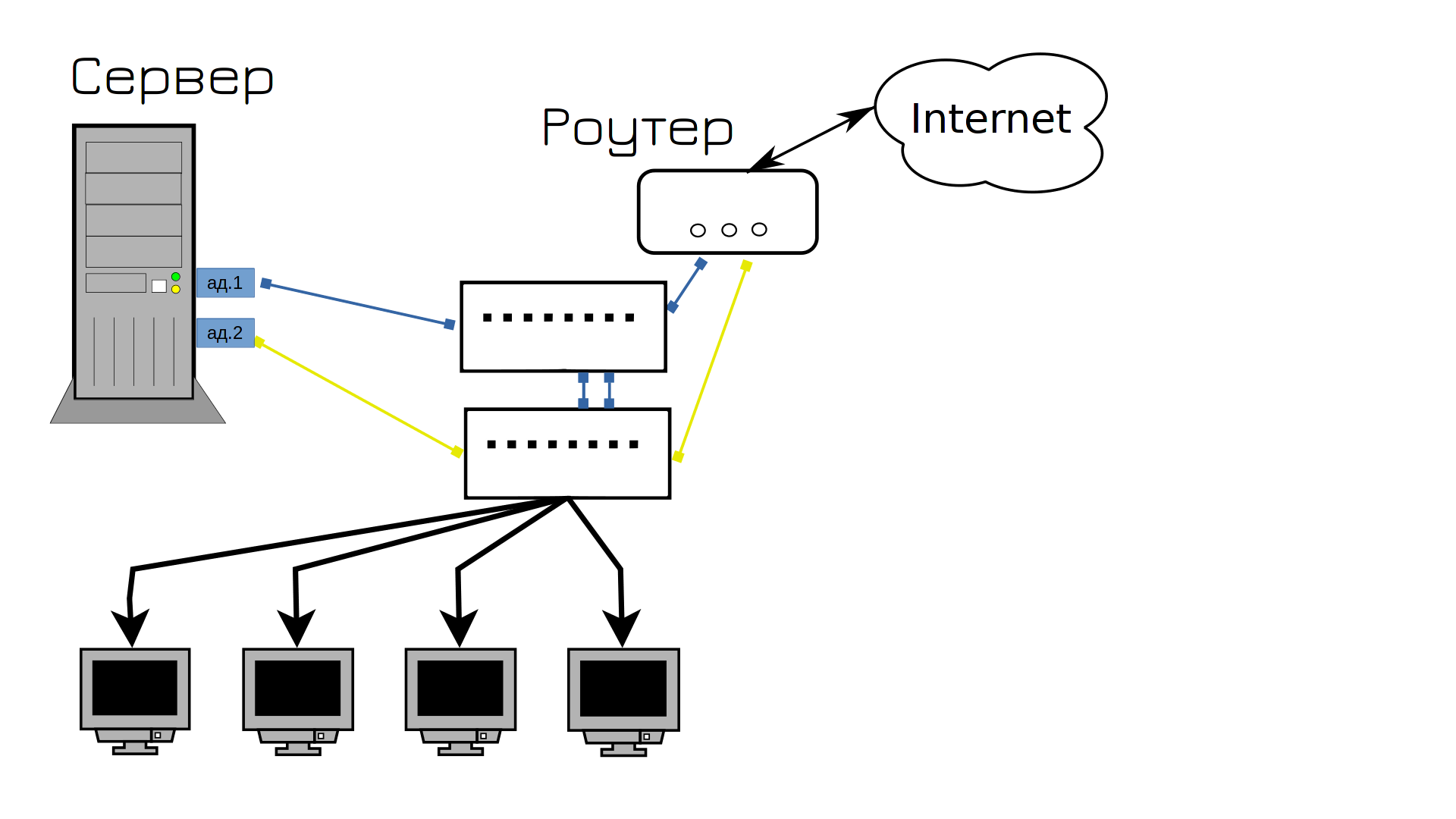
Правильно, купимо другий свитч, одні кабелі застромимо в перший свитч, другі в другий, та й зв’яжемо між собою свитчі. Тепер, який би з кабелів не вийшов з ладу, мережа продовжить працювати. Так? Ну майже, у нас мережа ляже в першу хвилину.
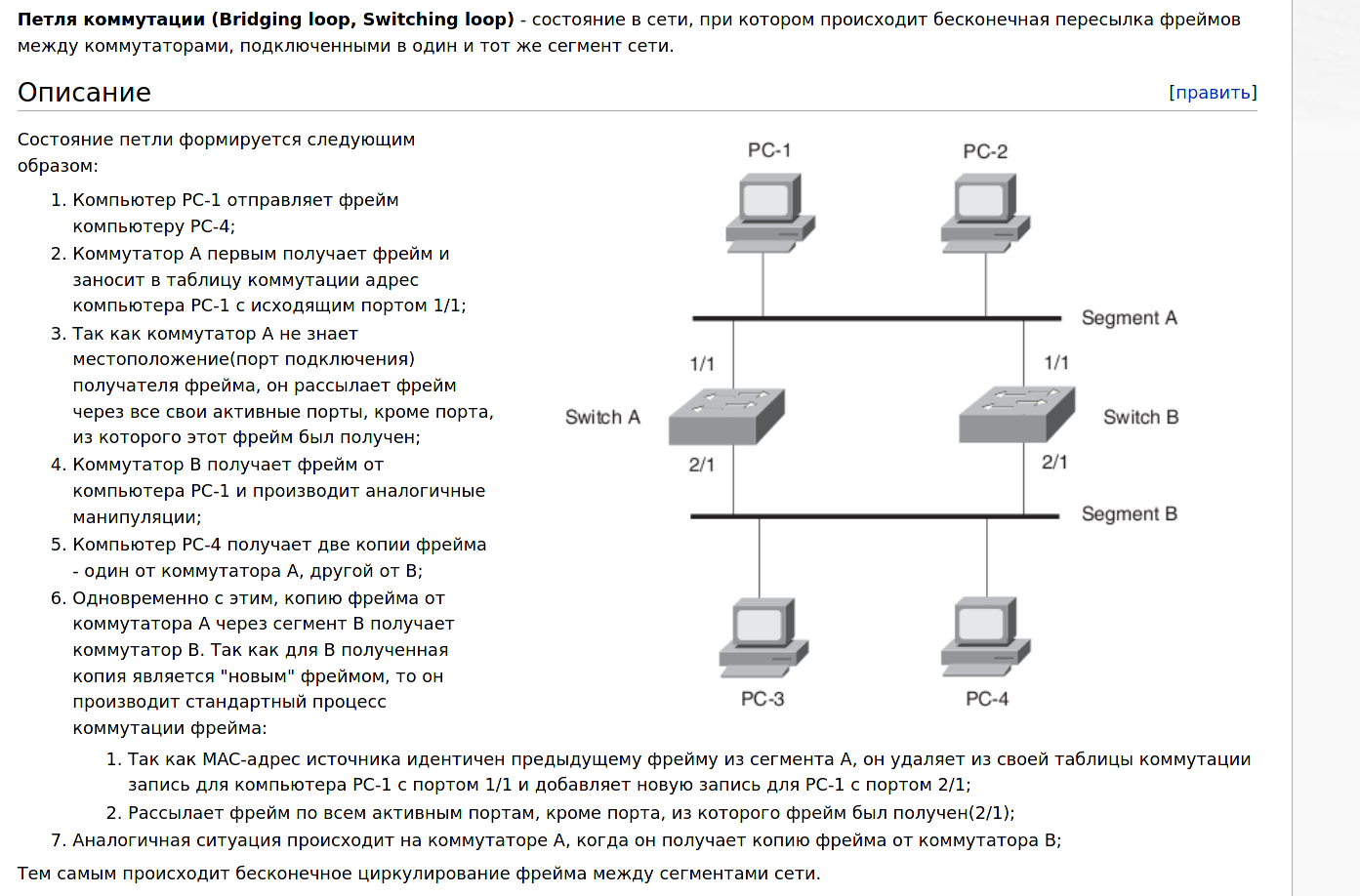
Два комутатори з’єднуються між собою двома кабелями, створюючи петлю. По суті, комутатори починають надсилати один одному однакові пакети, які розмножуються лавиноподібно і врешті-решт забивають всю мережу, роблячи її недоступною.
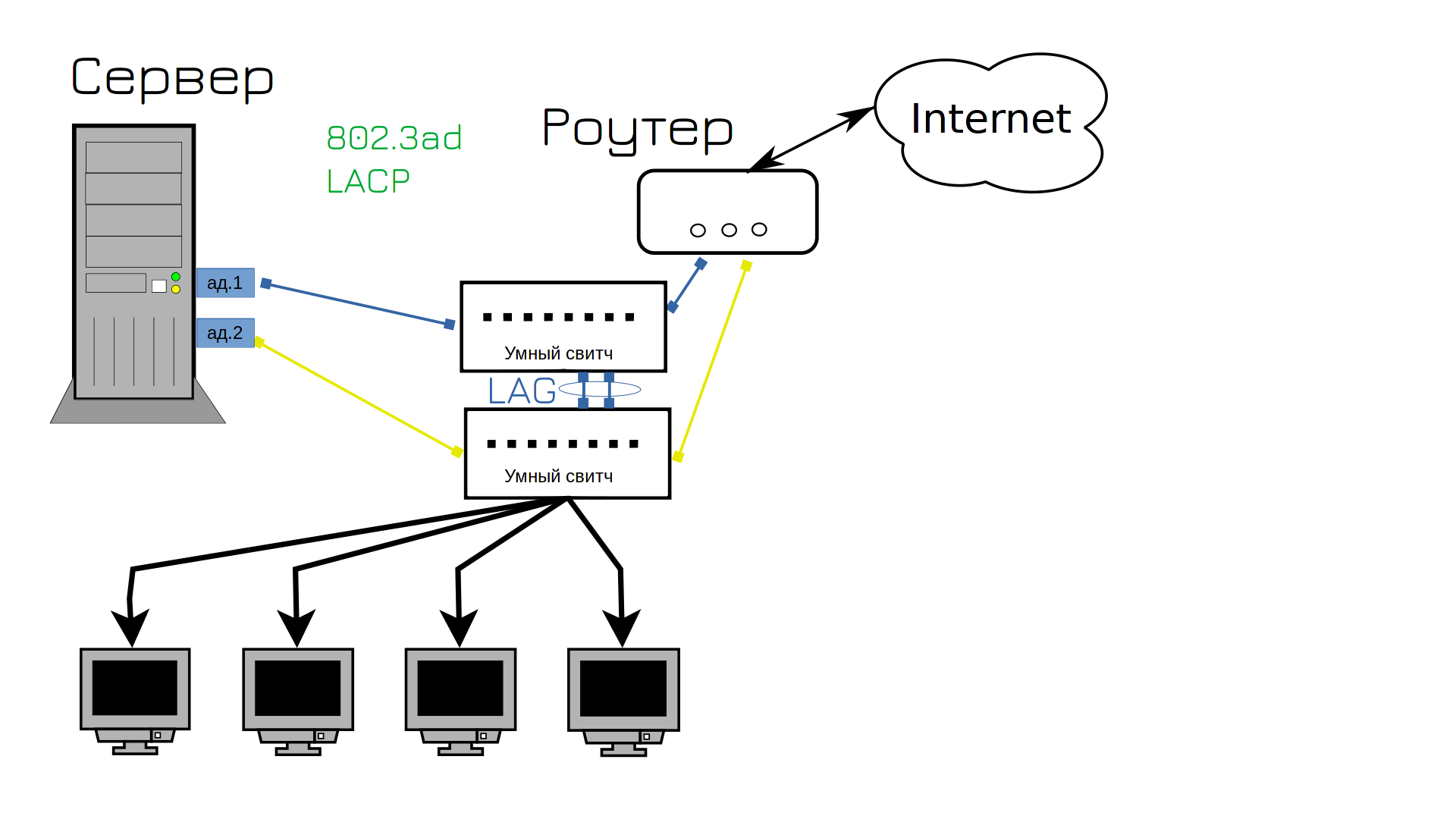
І ми знаходимо рішення цієї проблеми – нам потрібні розумніші комутатори. Вони називаються керованими комутаторами. Ці комутатори мають багато корисних для нас функцій. Наприклад, агрегація портів, агрегація каналів і LAG. Це те саме об’єднання мережевих карт, але ззовні. Але якщо раніше нам доводилося тримати один кабель в режимі очікування з глухим свистом, то тепер ми можемо використовувати обидва кабелі.
Мало того, що немає ніякої несправності, так ще й обидва кабелі використовуються одночасно. Раніше існував тип агрегації портів “активний і резервний”, тобто один порт знаходився в режимі очікування, але тепер обидва порти активні. Цей тип синхронізації мережевих карт називається LACP, часто його називають 802.3ad. Однак за допомогою LACP до декількох портів можна підключити лише два пристрої.
Це означає, що LACP можна використовувати для підключення двох скролів. Але як можна використовувати LACP між сервером і двома скролерами, щоб обидва порти були активними, навіть якщо це три пристрої – два скролери і один сервер?
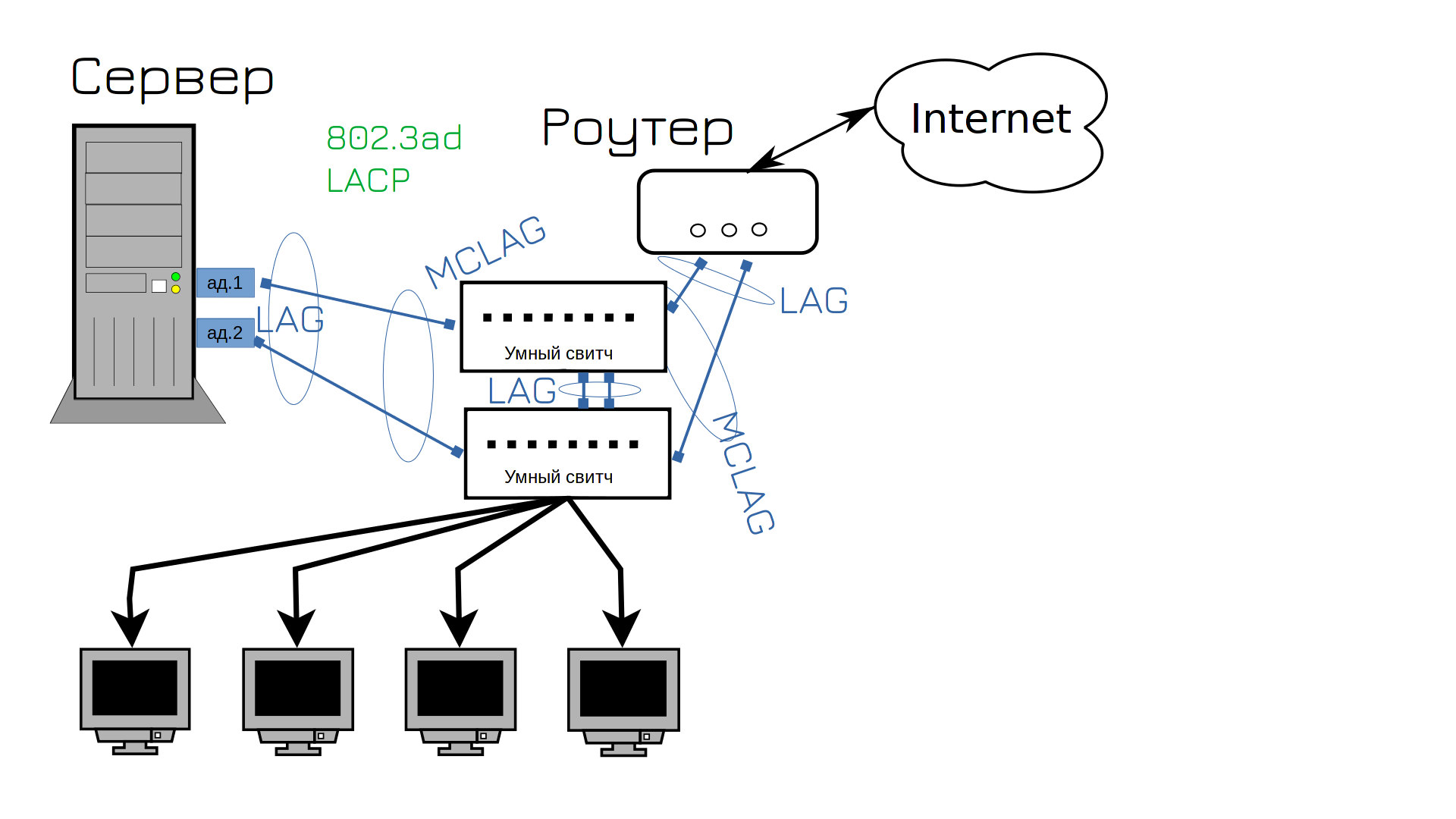
Для цього сучасні комутатори підтримують агрегацію портів між кількома пристроями, так званий MCLAG (multi-chassis lag). Це дозволяє об’єднати порти першого і другого комутатора в одну групу. Оскільки сервер вважає, що з іншого боку є один пристрій і один комутатор, можна використовувати LACP для налаштування об’єднання мережевих карт. Це підвищує швидкість і відмовостійкість мережі. Тепер мережа не впаде, чи не так?
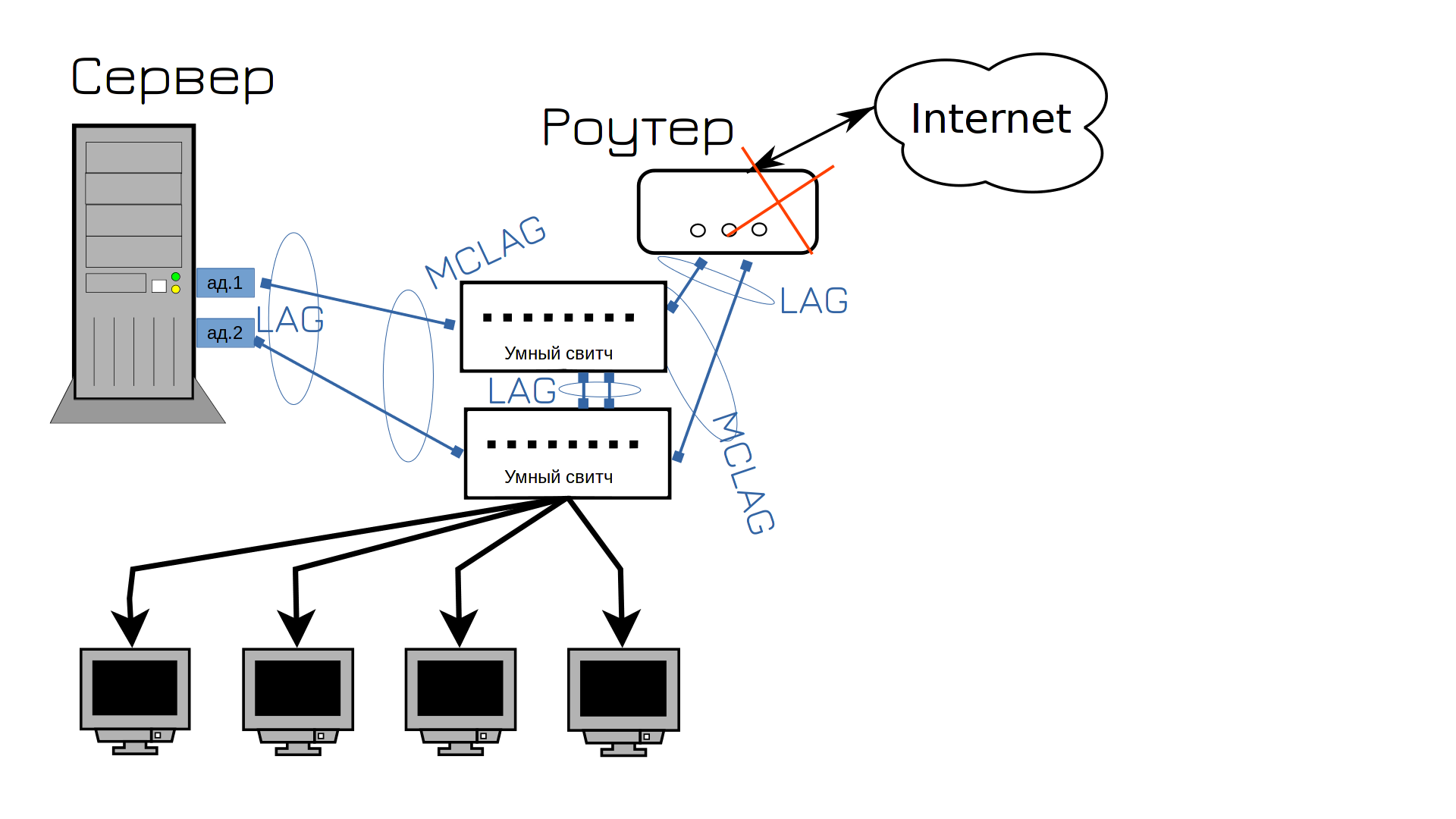
Рано радієте. Тепер вийшов з ладу роутер. Ну от не щастить нам. Що робити далі? Правильно, купувати другий роутер.
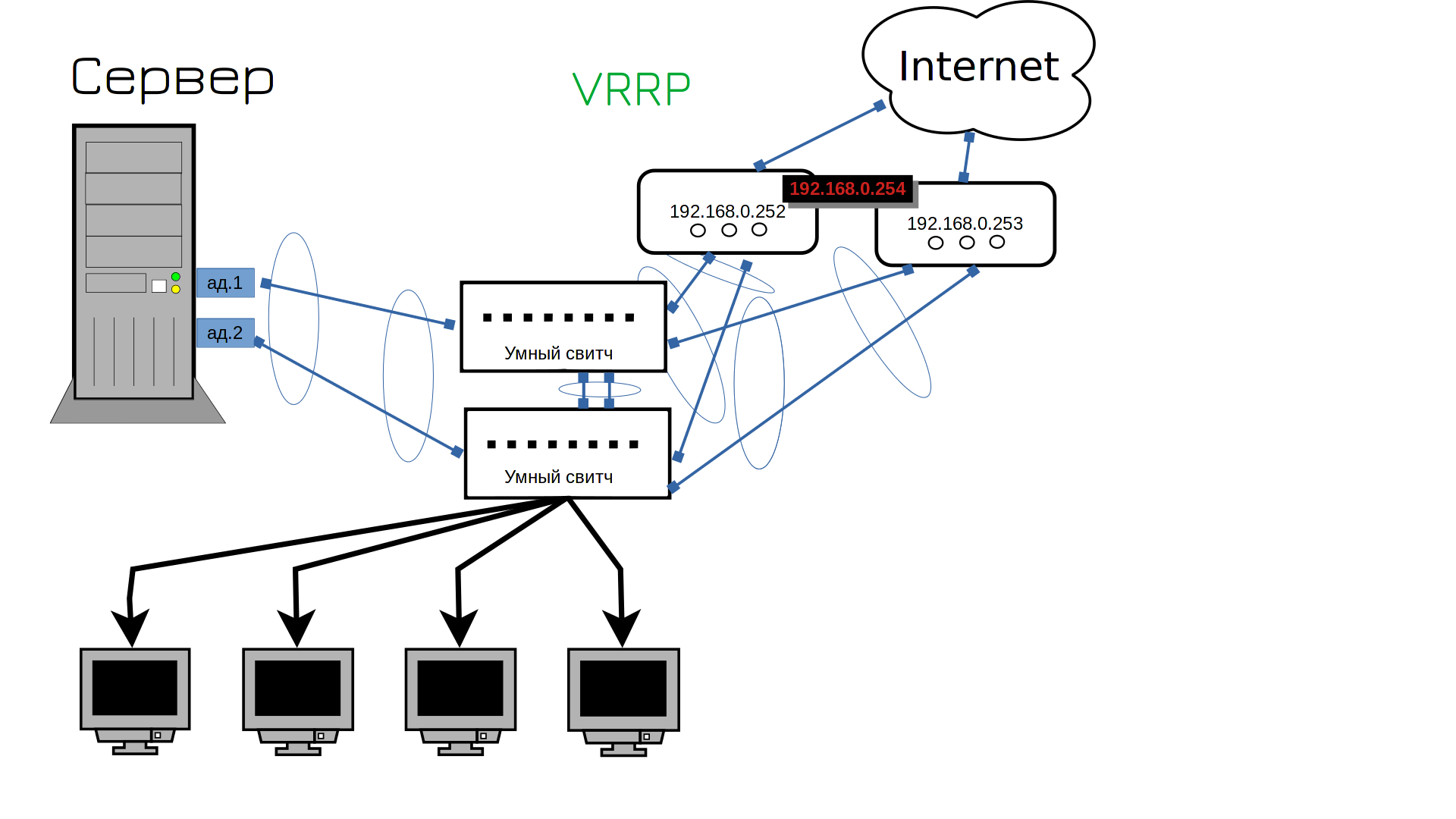
Я підключив другий роутер, але він має іншу адресу. Наші користувачі використовують лише одну адресу як шлюз для доступу до інтернету. Чи потрібно бігати і змінювати шлюзи? Ні. Ми повинні змінити шлюз на обох маршрутизаторах. Тож як ми можемо встановити однакову адресу на обох роутерах? Технічно це неможливо. Кожен пристрій повинен мати власну IP-адресу. Однак існує протокол VRRP, який дозволяє розділити IP-адресу між двома пристроями. Спочатку один пристрій буде використовувати цю адресу, але коли він вийде з ладу, IP-адреса почне функціонувати на іншому. Наприклад, якщо все буде добре, адреса 254 буде першим маршрутизатором. А якщо перший роутер вийде з ладу, цю адресу буде використовувати другий роутер. Чи все це достовірно?
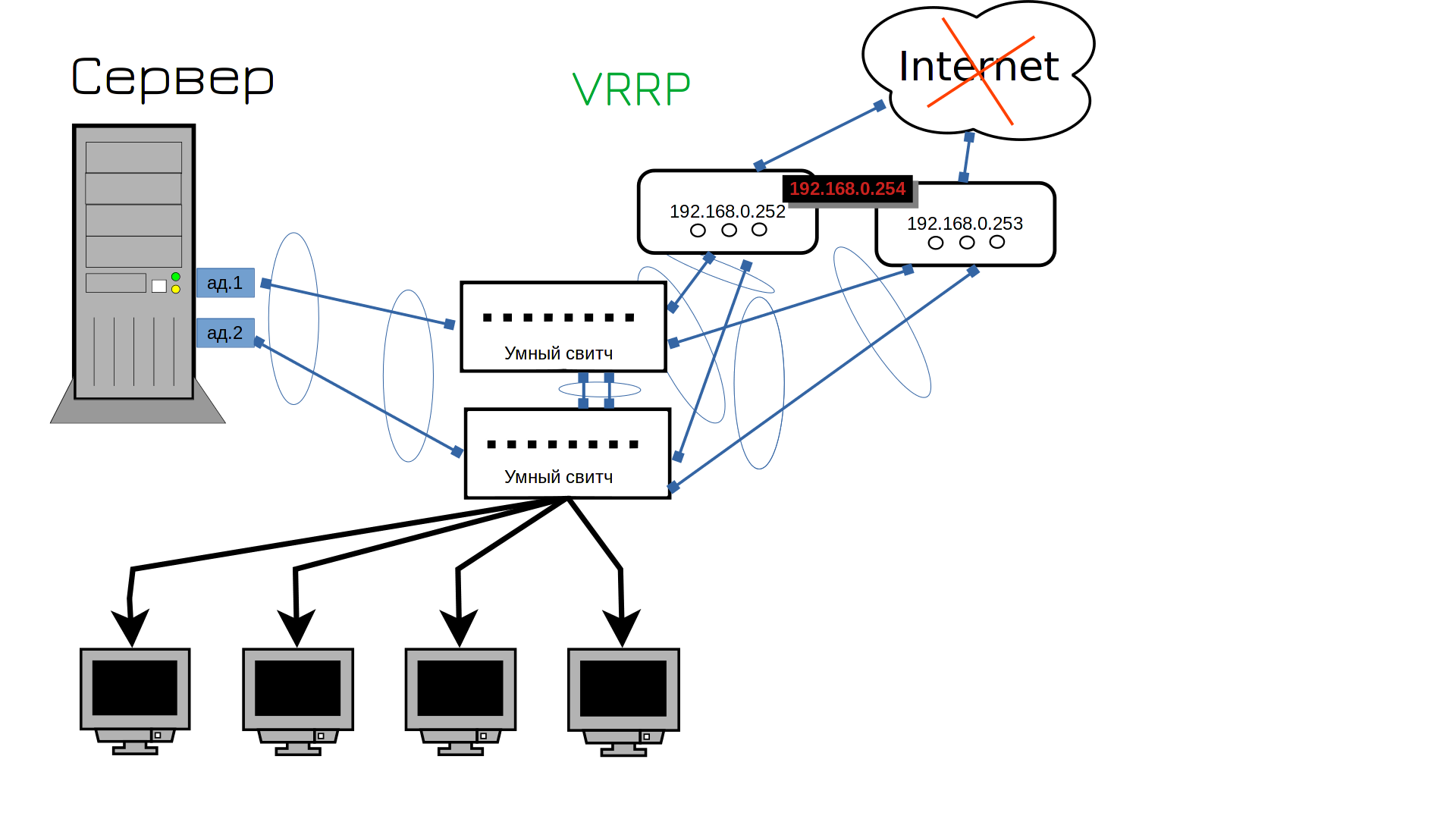
А тут сюрприз від провайдера – інтернет ліг. Хтось щось копав і пошкодив лінію, інтернет буде за кілька годин. Ну е-моє, що нам тепер, два інтернет-провайдери купувати?
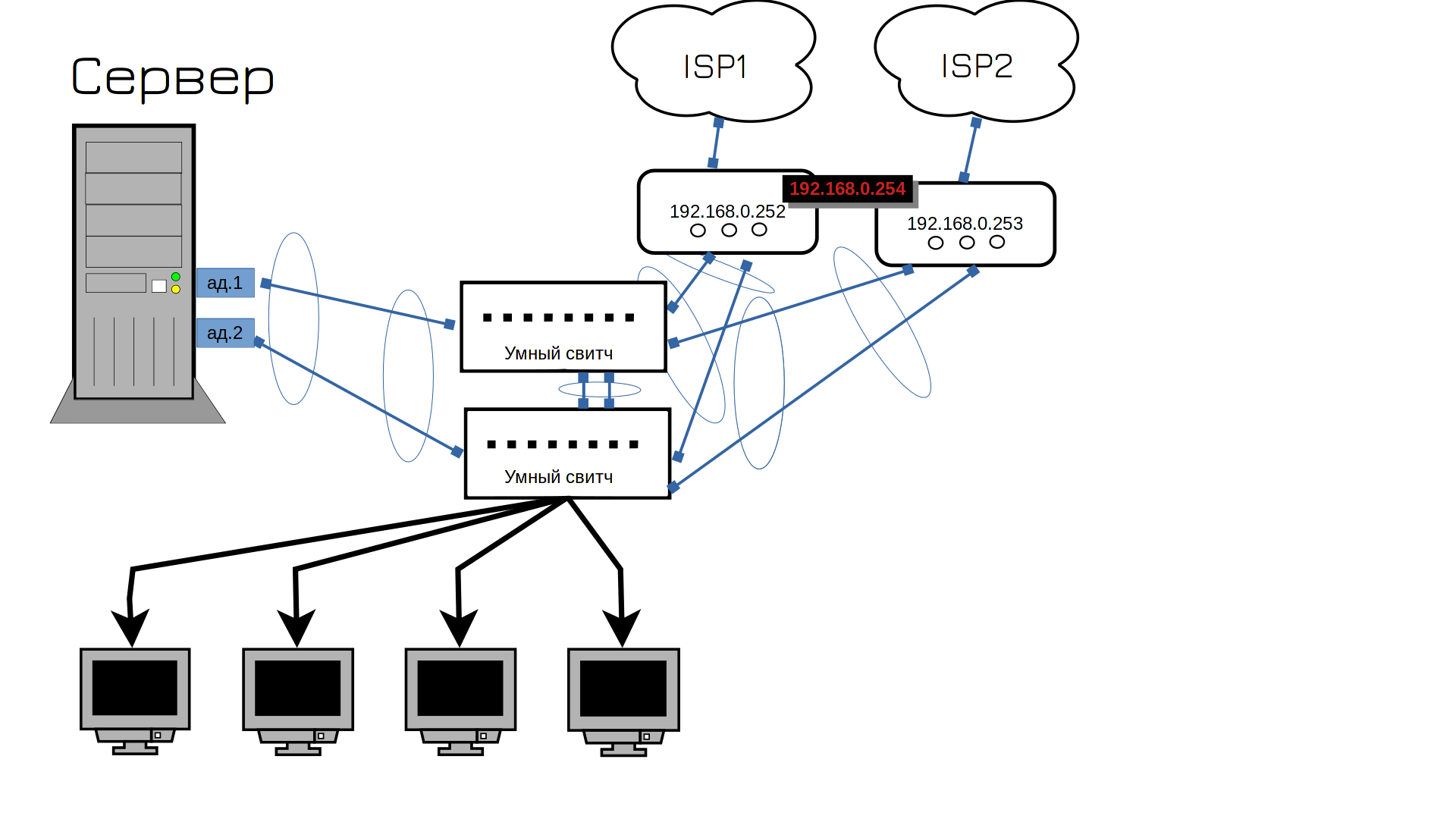
Ви думали, що це було інакше? Так, вам потрібен другий провайдер. ISP, до речі, це провайдер інтернет-послуг. На цьому етапі починаються танці з бубном. Це пов’язано з тим, що один провайдер часто надає лише кабель і не може підключити до двох роутерів. Тоді один роутер повинен бути підключений до одного провайдера або провайдер до комутатора. Можна підключити один кабель до одного комутатора, а інший – до іншого, але це означатиме, що коли комутатор вийде з ладу, інтернет-канал також переключиться. Зазвичай це не смертельна проблема, але неприємна: два різних провайдери нададуть вам дві різні публічні адреси, тому одна з ваших адрес буде недоступна. І будь-хто, хто використовував цю адресу для підключення до веб-сервера, наприклад, втратить доступ. Ви можете обійти це, налаштувавши перевірку доступності IP-адреси у вашого провайдера, але до таких джунглів ми повернемося пізніше.
Зараз мережа повернулася до нормальної роботи. Тепер ви можете покластися на мережу. У реальній інфраструктурі комутаторів було б більше, але це лише цифри – суть залишається незмінною. Маршрутизатори можна комбінувати по-різному, і ми проаналізували VRRP, стандартний відкритий протокол. Часто підприємства використовують два маршрутизатори в одному кластері, і трансляція IP-адрес реалізується по-різному внутрішнім програмним забезпеченням маршрутизатора.
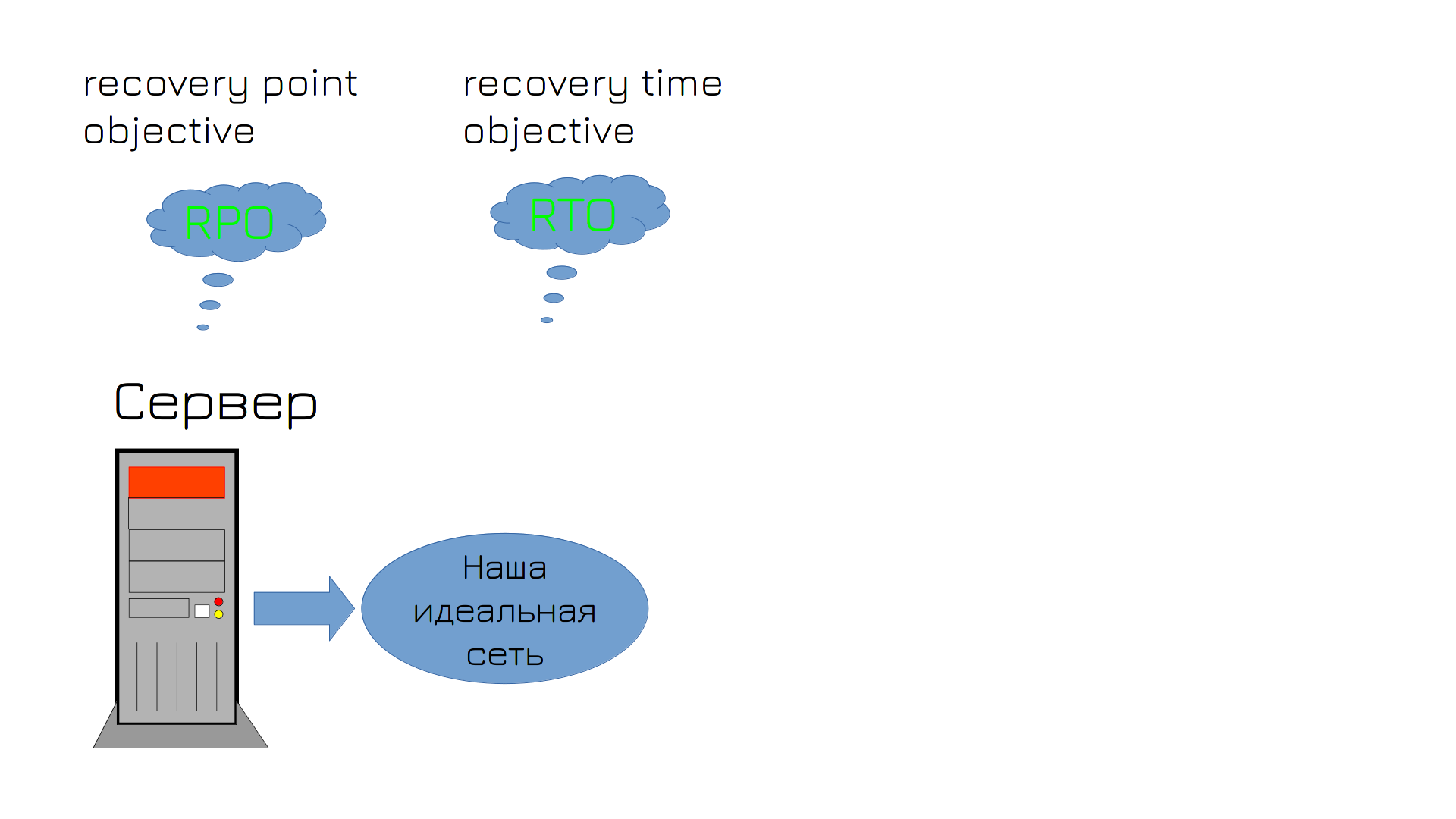
І після того, як ви насилу пояснили начальству всі проблеми і насилу вибили бюджет, у вас лягає сервер – вийшов з ладу жорсткий диск. У цей момент у вас у голові зароджується багато думок, серед яких є терміни RPO та RTO.
RPO – recovery point objective – це максимальний період часу, за який можуть бути втрачені дані. Ніхто не хоче втрачати дані, але й робити бекап щомиті і зберігати купу бекапів вийде нереально дорого. Тому ви з начальством погоджуєтесь, що якщо щось піде не так, ви готові втратити дані, наприклад, за дві останні години. Це ваше RPO. Відповідно, бекапи повинні робитися приблизно з такою періодичністю.
RTO – recovery time objective – проміжок часу, протягом якого система може залишатися недоступною. Тобто. скільки часу вам потрібно буде, щоб повернути все, як було? Припустимо, годину ви за цей час встигнете поставити новий диск, відновити на нього бекап і все запустити.
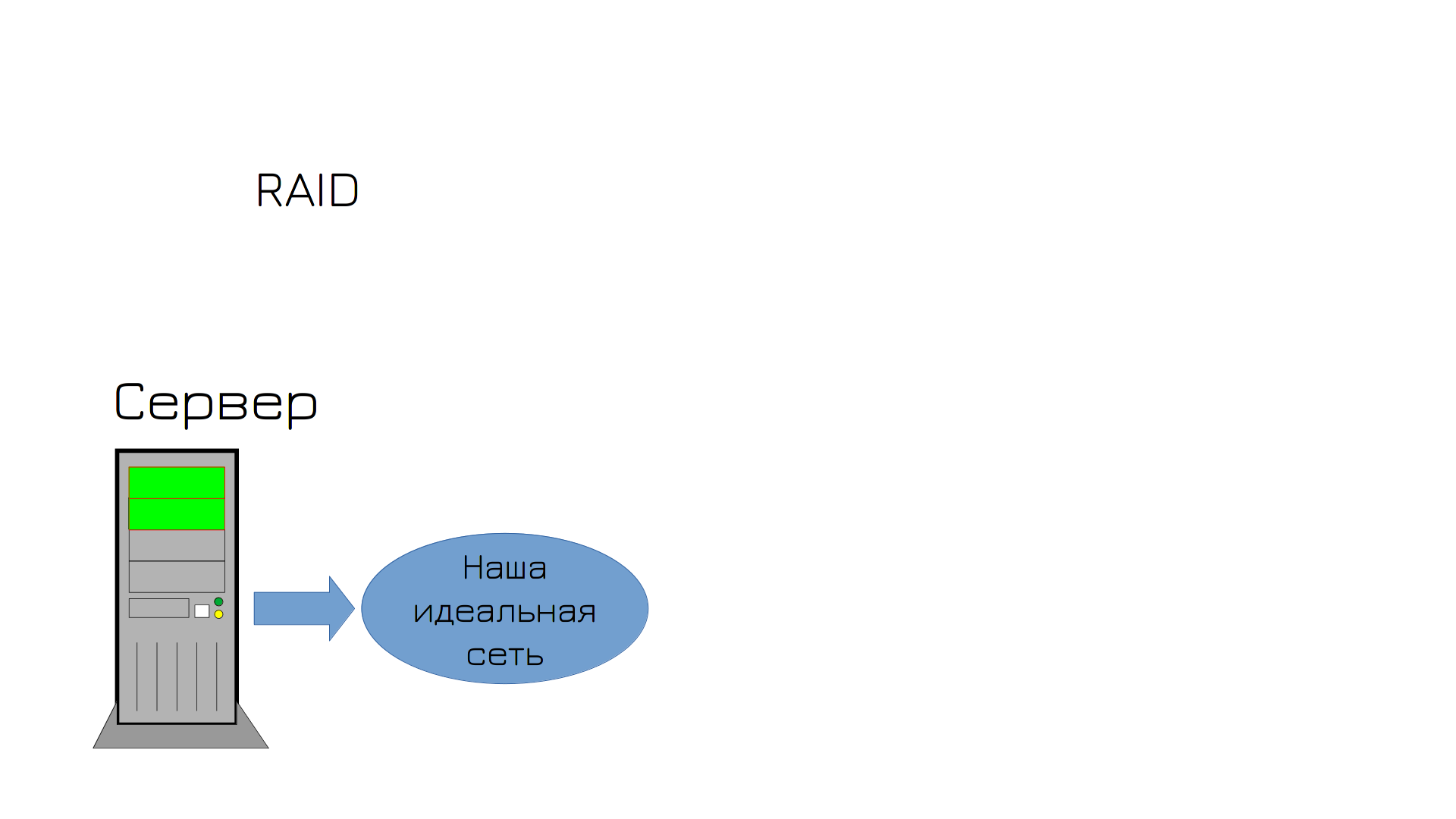
Але щоб уникнути повторення ситуації, ви вирішуєте придбати другий диск та налаштувати RAID. У вас два мережеві адаптери, два диски, що ще може піти не так?

Наприклад, може згоріти блок живлення. Але другий блок живлення на комп’ютер не поставиш.

Але ви можете нарешті позбутися цього мотлоху і купити справжній сервер. У ньому є багато корисних речей, як-от рейд-контролер, процесор і оперативна пам’ять, розраховані на безперервну роботу, а також відстеження стану всього обладнання. У нього також є два блоки живлення! Що може піти не так?

Чому б не вийти з ладу операційної системи? Чи не згоріти материнці? Як щодо другої душі? А ось ніяк.

Що ж, доведеться розщедритися – купити другий сервер і створити кластер. Кластери можна створювати на основі гіпервізора, де все можна віртуалізувати і запускати на окремих серверах. Однак створення кластера з двома серверами – дуже погана ідея. Це тому, що якщо сервери втрачають зв’язок один з одним, кожен сервер буде думати, що інший вийшов з ладу. Тоді кожен спробує запустити віртуальну машину. Це спричинить хаос і, ймовірно, призведе до пошкодження даних.

Тому кластер повинен складатися з трьох серверів: якщо один сервер вийде з ладу, два інших продовжать працювати; якщо один сервер підтвердить, що втратив зв’язок з двома іншими серверами, він вважатиме, що з цим сервером виникла проблема, і припинить завантаження віртуальних машин.
Тепер припустимо, що один із серверів виходить з ладу. Файли віртуальної машини знаходяться на недоступному сервері. Чи потрібно постійно робити резервне копіювання віртуалізації з одного сервера на інший? Якщо сервер вийде з ладу, частина даних буде втрачена. Дані повинні бути централізованими і доступними на всіх трьох серверах одночасно.
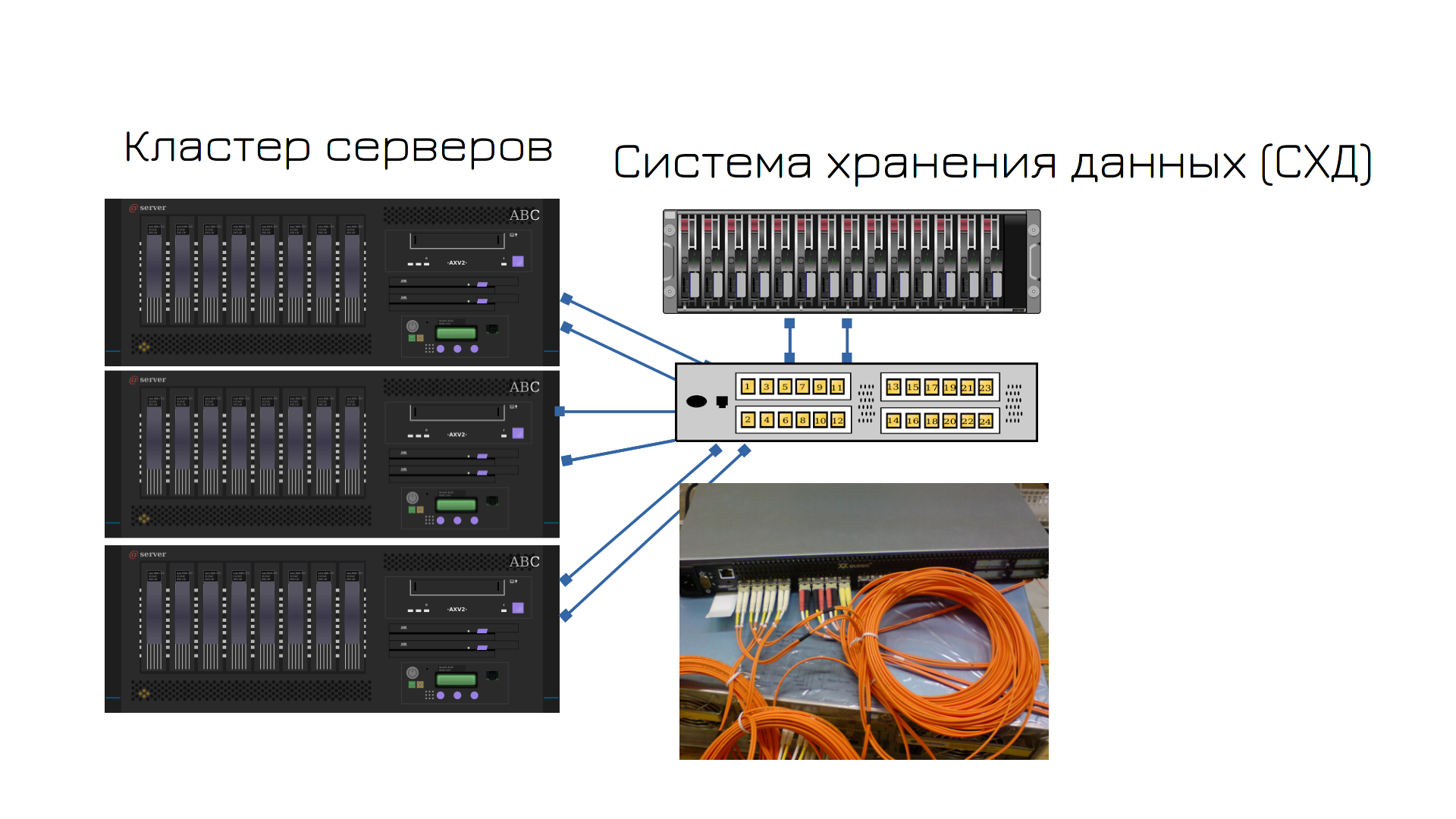
Це система зберігання даних, яка називається gatekeeper. Це тип сервера з купою дисків, які потрібні для резервування місця на сервері. Сервер підключений до спеціального комутатора, який називається SAN-комутатор, який підключений до охоронця. На ньому створюються віртуальні диски, і сервер бачить ці диски через мережу. Однак це не звичайна мережа, яку ми вивчали. Іншими словами, є звичайна мережа, яка працює з мережевими пакетами, що ходять туди-сюди, а також пара спеціальних оптичних адаптерів, які отримують доступ до дисків через мережу. Така мережа називається мережею зберігання даних (Storage Area Network, SAN).
Сам блок зберігання даних має два контролери – як дві материнські плати – тому немає необхідності купувати другий блок зберігання даних для відмовостійкості. Усередині Guardian є рейд, дедуплікація, моментальні знімки та багато інших корисних технологій для зберігання даних.
Всі три сервери посилаються на один і той самий віртуальний диск, тому віртуальні диски можна без проблем переміщувати між серверами.
Така інфраструктура називається класичною, якщо є сервери і системи зберігання даних. Бувають і інші, але це окрема тема.

Так накопичувалися сервери, системи зберігання даних і стрічки. Все це обладнання дуже сильно нагрівається, виділяє багато тепла і дуже чутливо реагує на навколишнє середовище. Стандартна температура, за якої таке обладнання почувається комфортно, становить близько 20 градусів за Цельсієм. При 30-35°C, наприклад, можуть виникнути проблеми або щось може зламатися. Вологість також має бути близько 40%. У звичайному середовищі важко створити такі умови, а шум від роботи серверів заважає спокійно працювати. Тому всі ці пристрої слід тримати в спеціальному приміщенні з відповідними умовами, тобто в серверній кімнаті.

А щоб ці пристрої не стояли на підлозі, існують спеціальні металеві шафи, які називаються стелажами. Вони стандартизовані і мають однакову висоту та ширину для багатьох шаф. У стійках є місце, яке називається юнітом, українською мовою це “У”, що означає “монтажний блок”. А висота становить приблизно 4,5 см. Сервери, скроли та інше обладнання, як правило, мають висоту, що відповідає цій одиниці. Наприклад, скролл зазвичай займає 1U, сервер – 1U, 2U або іноді 4U.
До серверних приміщень висуваються певні вимоги, наприклад, звідки надходить повітря і як воно циркулює, спеціальна система кондиціонування для регулювання температури і вологості в серверній кімнаті, спеціальні системи моніторингу навколишнього середовища для контролю температури, вологості та інших параметрів, а також спеціальні системи пожежогасіння. Загалом, до серверних приміщень висувається величезна кількість вимог.

Що, думаєте витративши стільки грошей і зібравши таку серверну, ви позбавилися єдиної точки відмови? Ха, як би не так. Одного дня у вас просто вирубує електрику. Це ж не ваша вина, що можна з цим поробити?

Тож ми купуємо ДБЖ на ті гроші, що маємо. Але не побутовий. Ви знаєте, скільки енергії споживає ця техніка? Нам потрібен більш потужний ДБЖ. Якщо у вас одна-дві шафи з обладнанням, то вистачить річкового ДБЖ. Але на один ДБЖ розраховувати не можна, тому потрібно як мінімум два. А іноді у вас багато обладнання і ви не хочете втратити живлення для всієї будівлі. Тому для ДБЖ можна виділити окрему кімнату. Але мова йде не про ІТ, а про те, щоб сервери працювали, а сервіси були доступними.
Що, якщо відключення триватиме довше? Ми розбиваємо останню скарбничку і тягнемо другу нитку електрики, з блоком живлення ДБЖ з одного боку і ДБЖ з іншого. Якщо одна сторона втратить живлення, інша все одно працюватиме.

Що думаєте на цьому все? А якщо серверну затопить? Якщо по всьому місту зникне електрика? Якщо на місто впаде метеорит? Що, через це бізнес має перестати працювати? Як би не так.
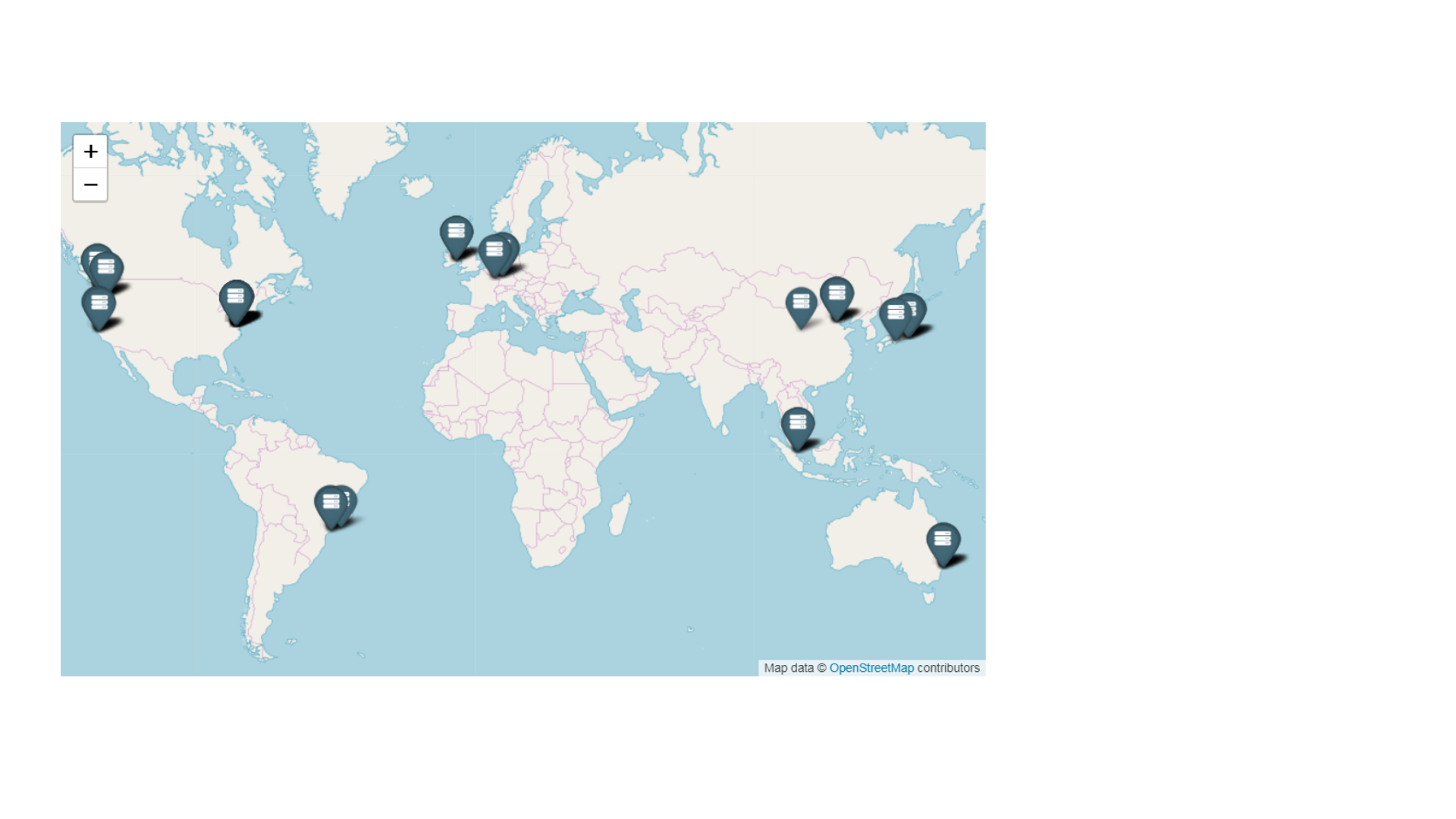
Побудувати копію дата-центру в іншій будівлі, в іншому місті, в іншій країні, на іншому континенті, на іншій планеті. Що б не сталося, наша інфраструктура повинна працювати Як ви думаєте, Ілон Маск освоює Марс для людства? Повірте, перше, що там з’явиться – це дата-центри.
Тепер ви розумієте, чому SPOF є ключовим словом в ІТ і чому ІТ так дорого коштує? Не кожна компанія побудує резервний дата-центр, але ви можете зростати як фахівець, підключаючи два кабелі замість одного.





