
20.03.2024
6 min
1919

The structure and components of the IT infrastructure are considered, comparing them with the infrastructure of a city with basic services for its residents. It tells the story of building a company’s infrastructure, detailing challenges such as single points of failure (SPOF) and solutions to increase resiliency, such as commanding network interfaces and using managed switches.

Who is a system administrator? A person who configures and is responsible for the regular operation of computer hardware, networks, and software, collectively known as IT infrastructure. It can be compared with the infrastructure of the city. There are systems of water supply, electricity supply, roads, garbage collection, etc., which are necessary for the safe life and work of people in the city; likewise in IT: without the proper infrastructure, users cannot work safely. Although all cities have infrastructure, it is specific to each city; the same applies to IT infrastructure – it is slightly different everywhere, but the fundamentals are the same. Therefore, the question “How is the infrastructure developed?” The answer to the question “What is infrastructure?” varies from company to company.
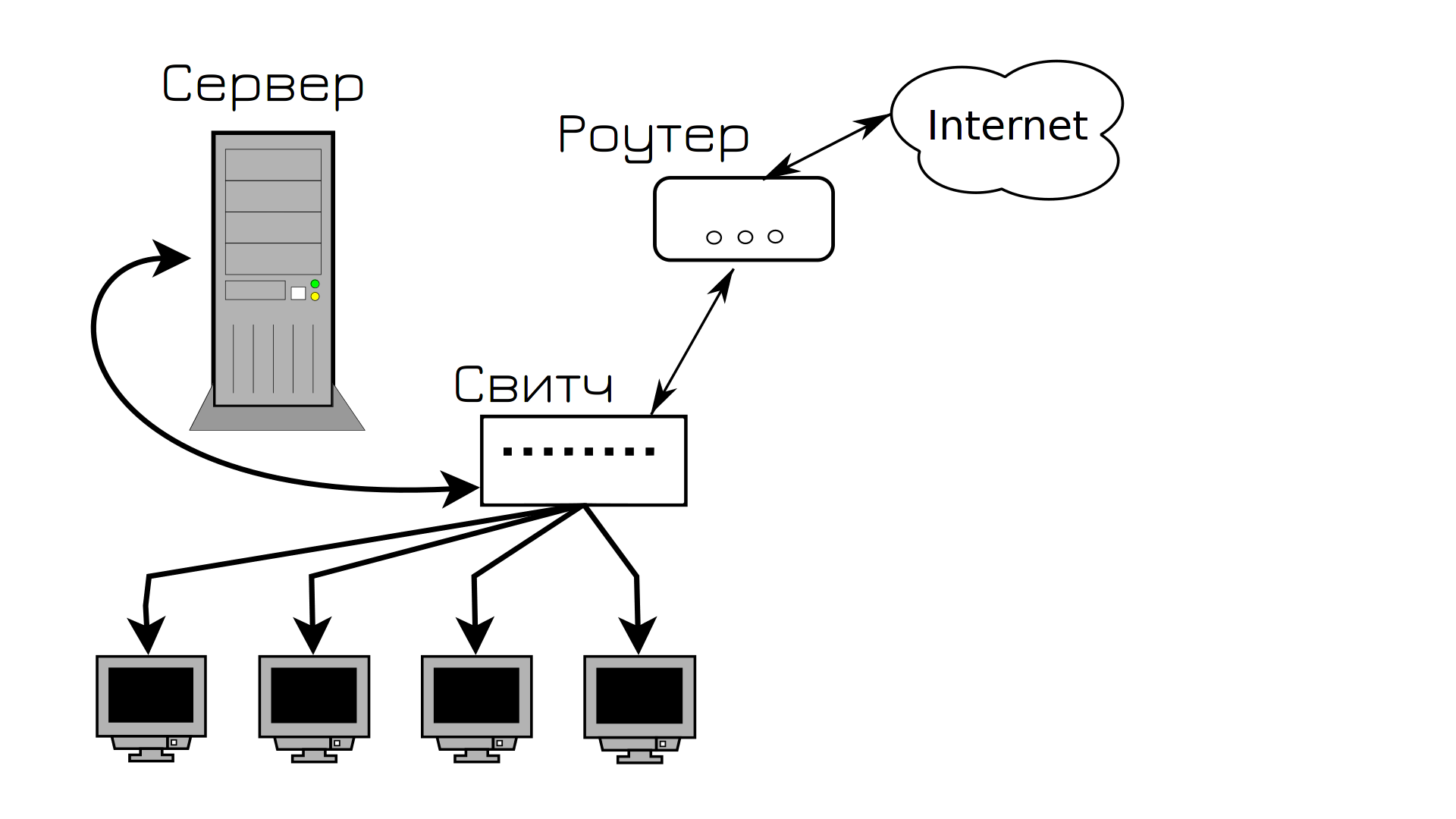
We are creating a company with our own infrastructure. We turn to the provider and ask to provide us with a router and the Internet. We call the system unit a server: we install Linux, configure the service and give it an IP address. To connect users, servers and routers, buy a simple switch and connect them with a copper patch cord. This is how infrastructure is created.
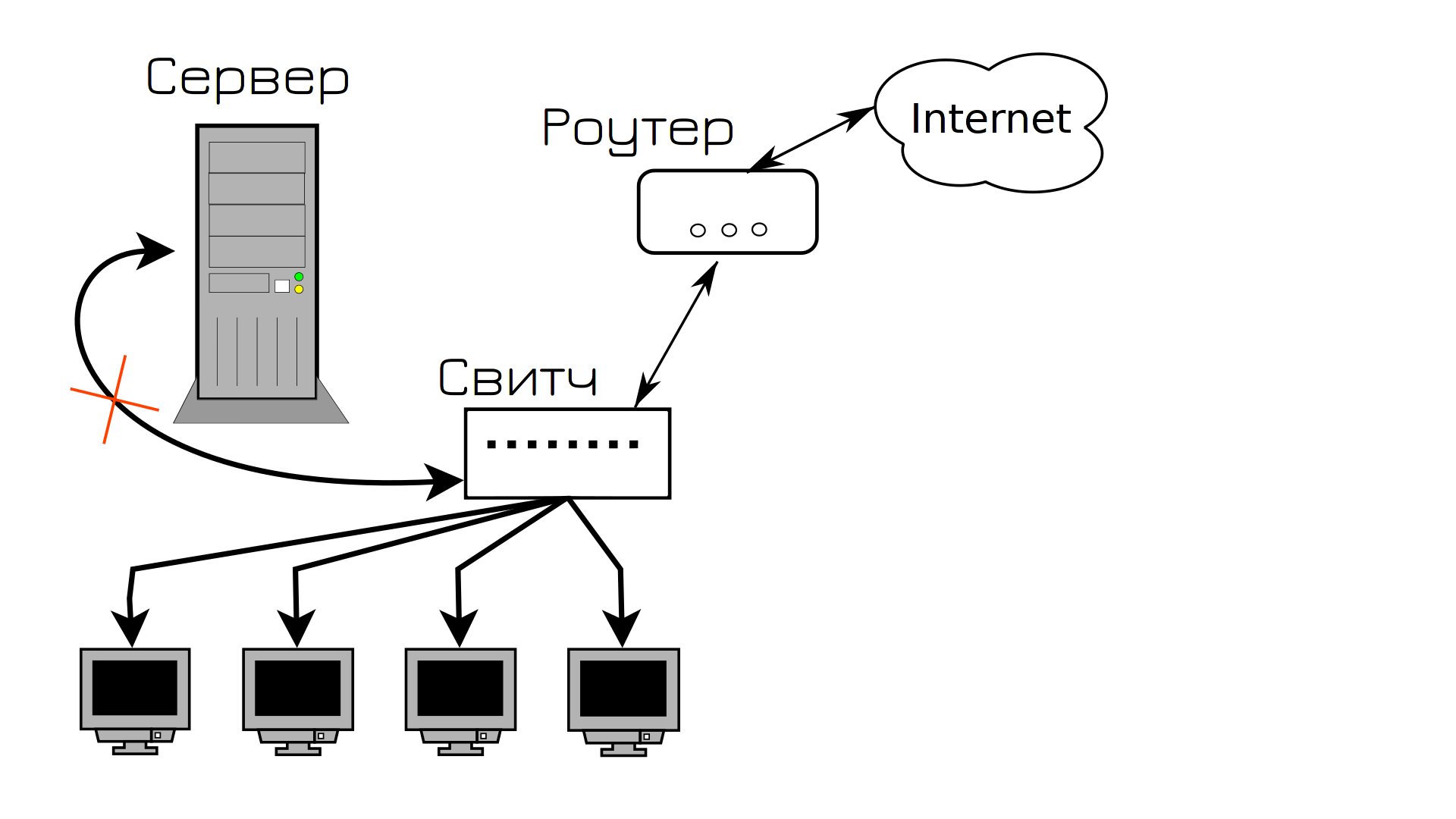
And everything works until one day someone accidentally puts something heavy on the cable going to the server. The cable breaks and the server becomes unavailable. And you took a day off today. Users cannot access the server, customers are not satisfied and you urgently need to go to the office and connect a new cable.
All this history introduces us to the term SPOF – single point of failure. This is such an element of the system, the failure of which leads to the stoppage of the service. The service is not in the plan of the program in the system, but in the plan of the service of the consumer. So, in our infrastructure, the cable connecting the server to the switch was the only point of failure – it failed and the service became unavailable. Even if the operating system is running, the program inside is running – it is not available to users.
SPOF is the driving force of IT, it is one of the main terms that answer most questions, including why the infrastructure is arranged this way and not otherwise. However, you will understand everything, let’s continue.
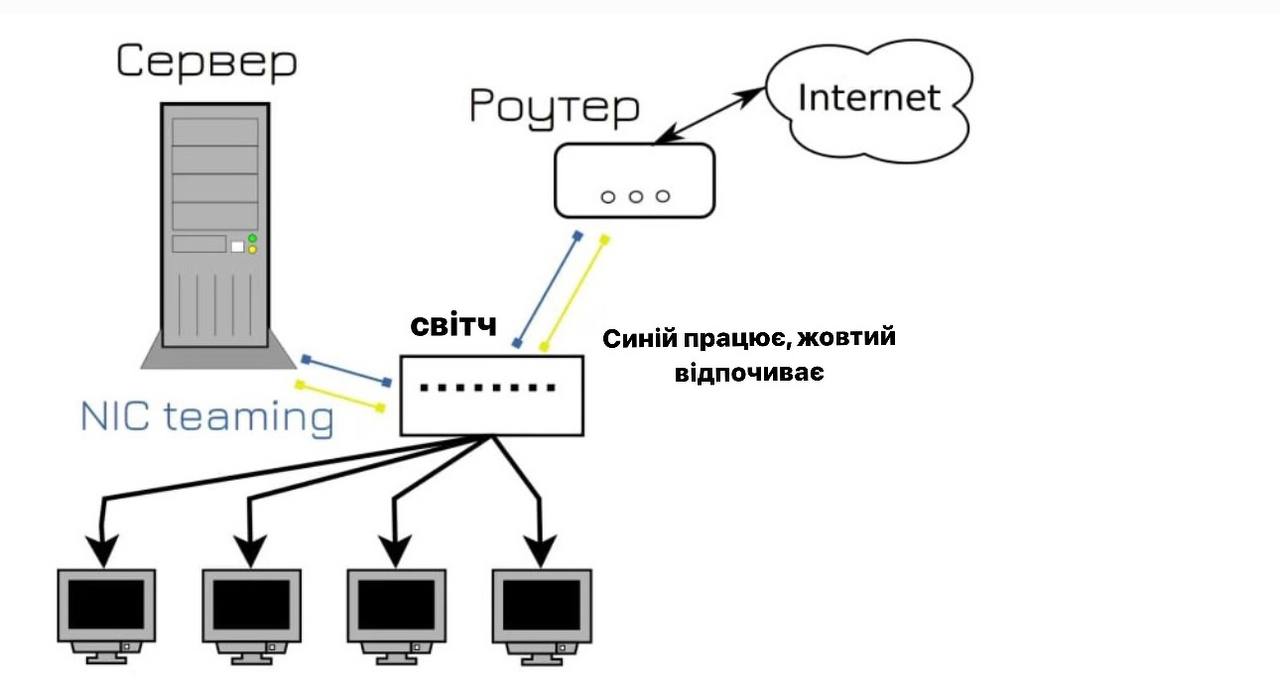
Of course, we could just replace the cable and hope it doesn’t happen again, but we’ll make the smart choice and try to prevent this from happening. On the Internet, we found a method called combining network cards. It connects two ports in the system, one of which is active and the other is in standby mode. If something happens to the first port or cable, everything goes to the second port. Therefore, we decided to connect the server to the switch with two ports and at the same time do the same with the router in case something happens to the cable. It could be a computer, but the scroll doesn’t have many ports, and if the user’s cable breaks, they can switch to wifi.
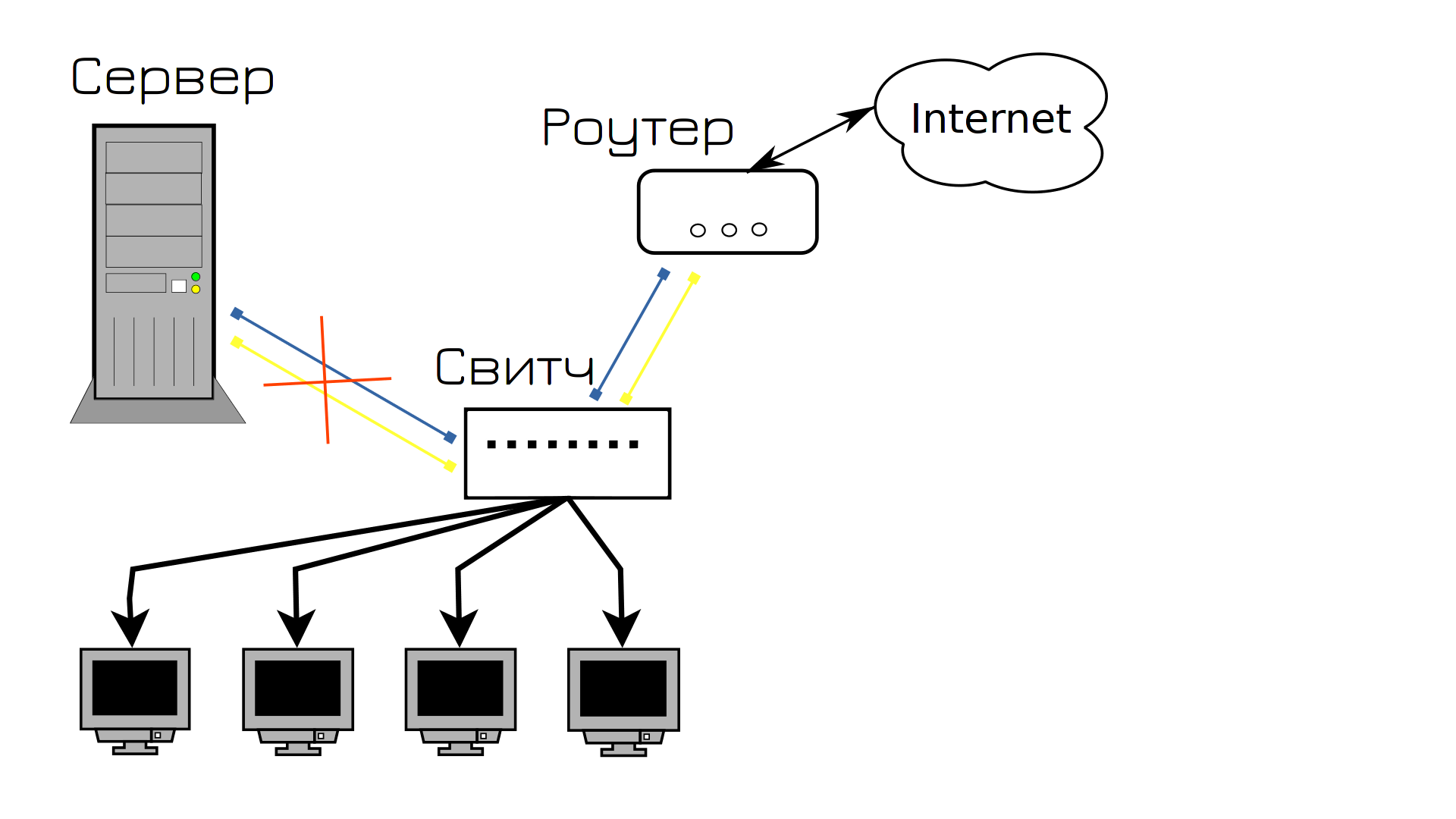
And everything seems to be normal, until one day the network adapter on the server fails. Since the adapter to which both cables were connected failed, the service became unavailable again, and users were again dissatisfied.
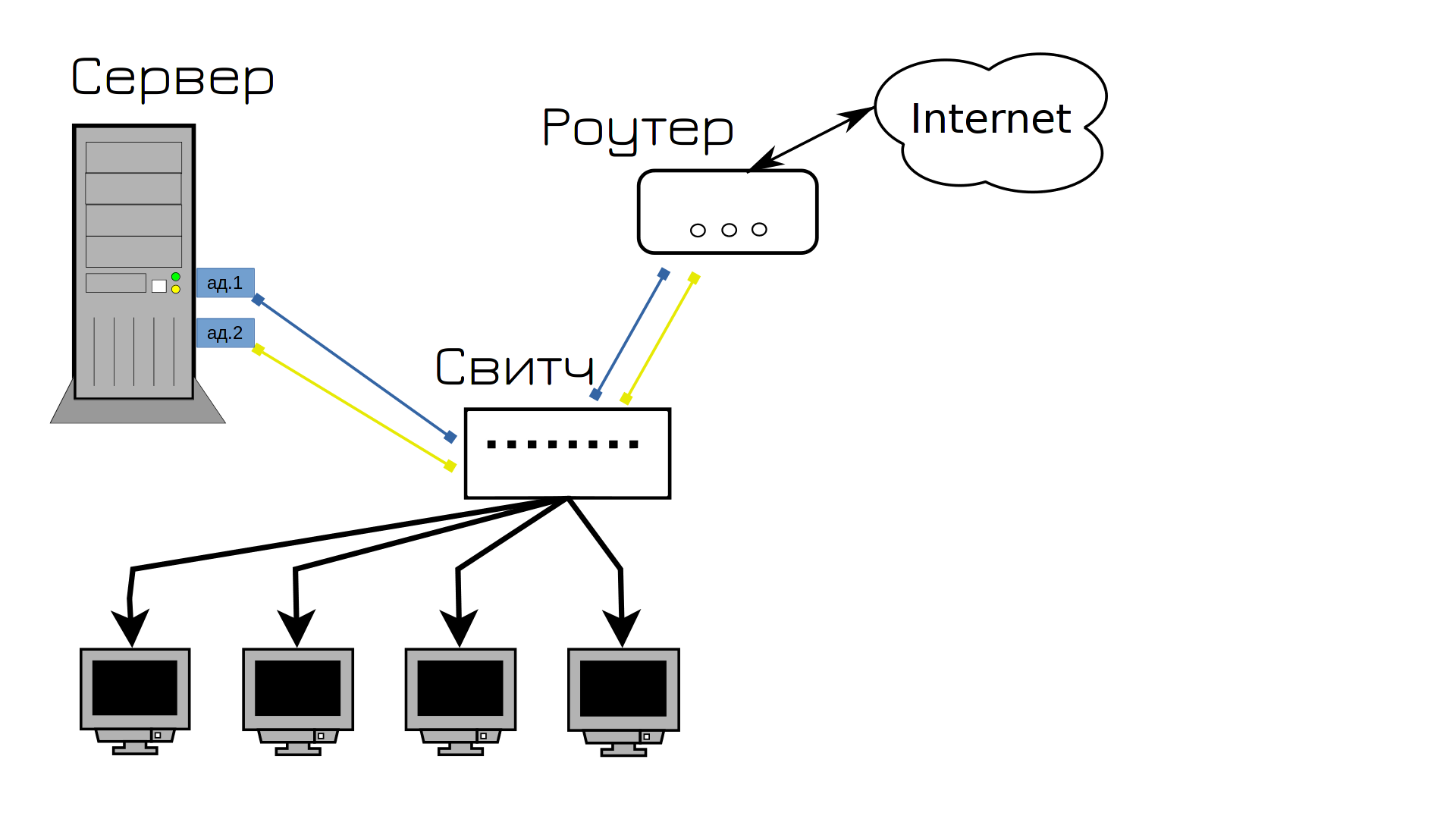
And to solve this problem and prevent the future, we buy two network adapters. If one fails, everything will automatically switch to the second, and we will buy a new adapter and replace it in the meantime.
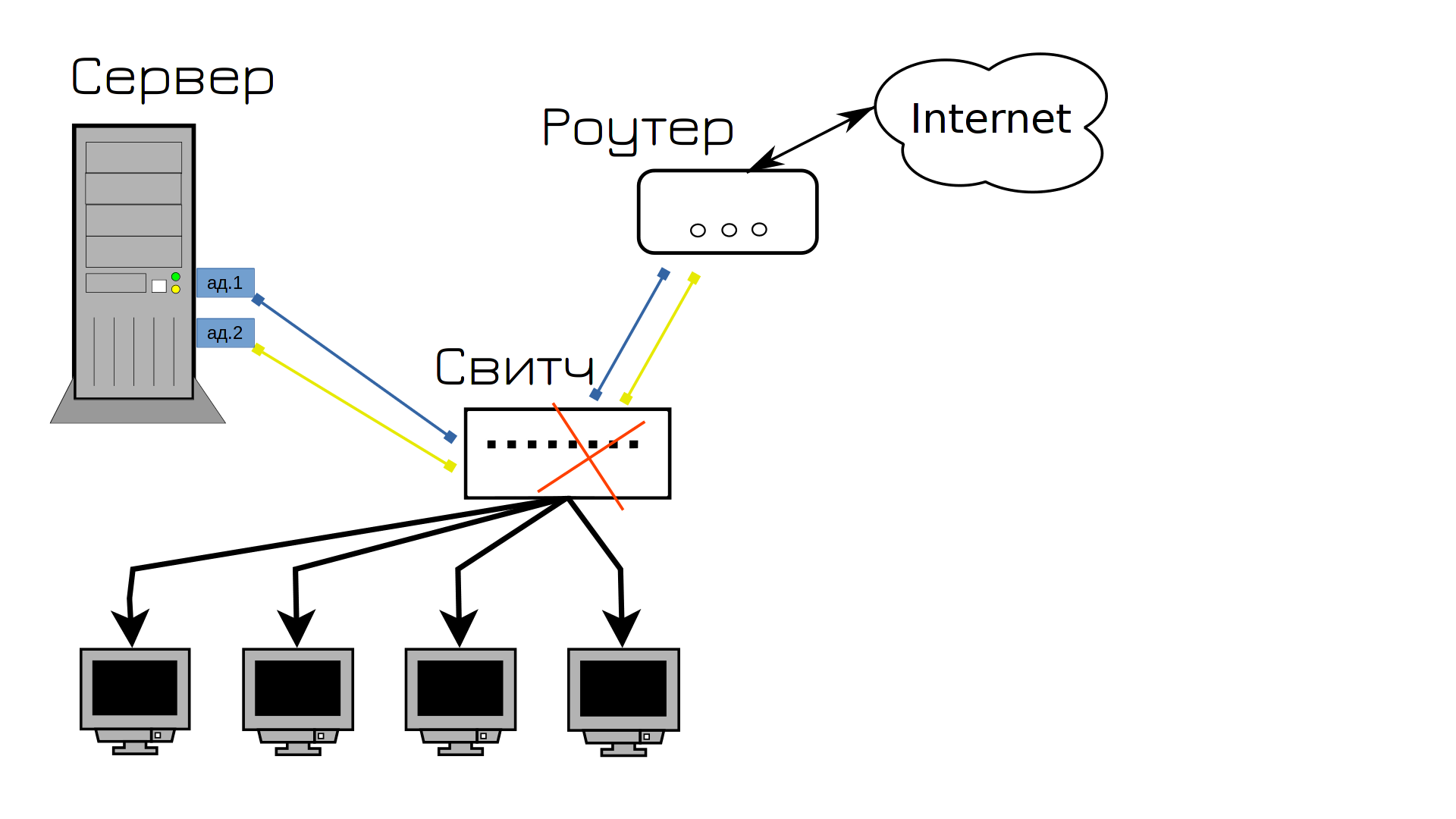
You know what went wrong next? Switch And how do we solve it and prevent it?
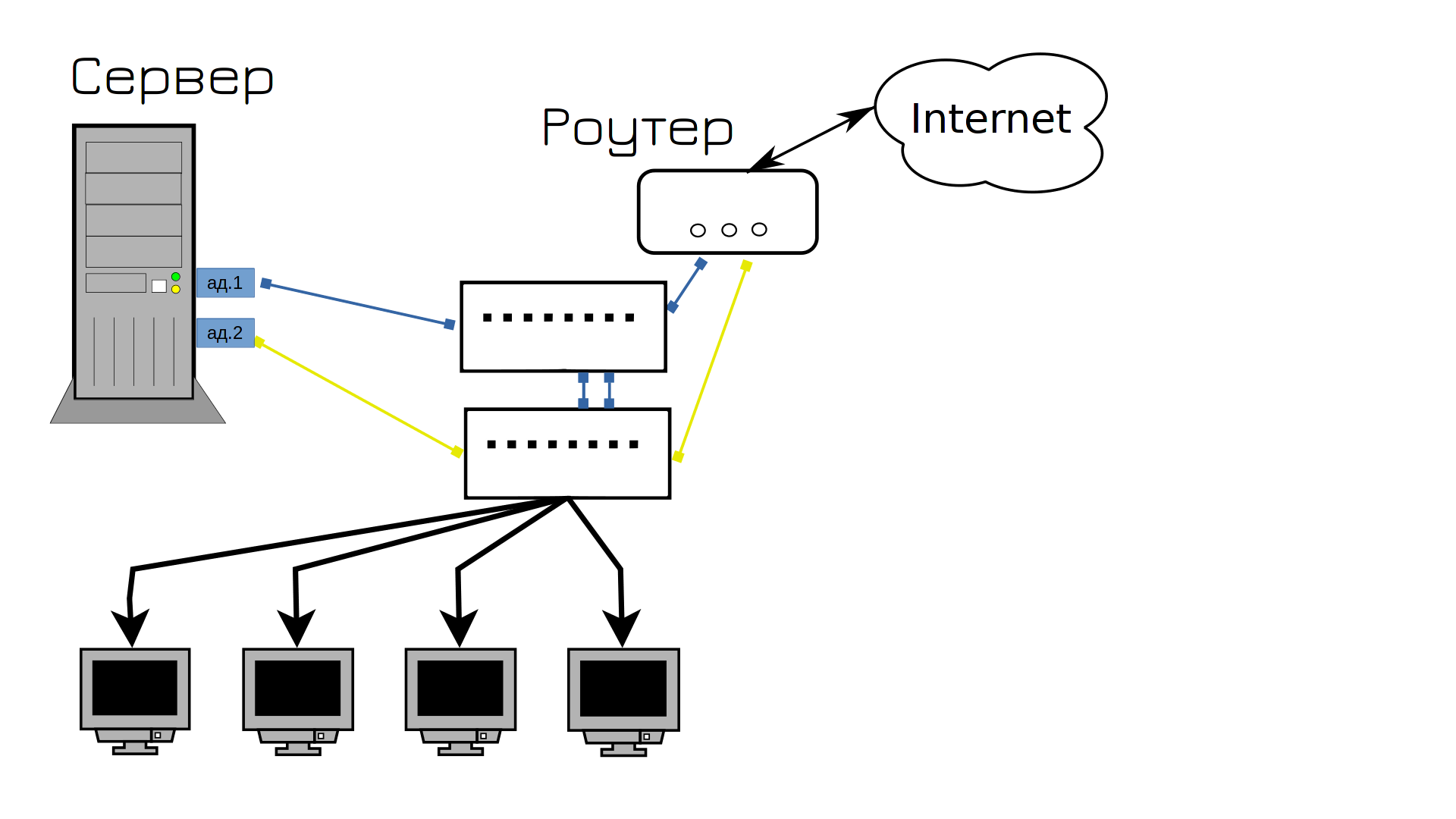
That’s right, let’s buy a second switch, plug one cable into the first switch, the other into the second, and connect the switches together. Now, no matter which of the cables fails, the network will continue to work. So? Well, almost, our network will go down in the first minute.
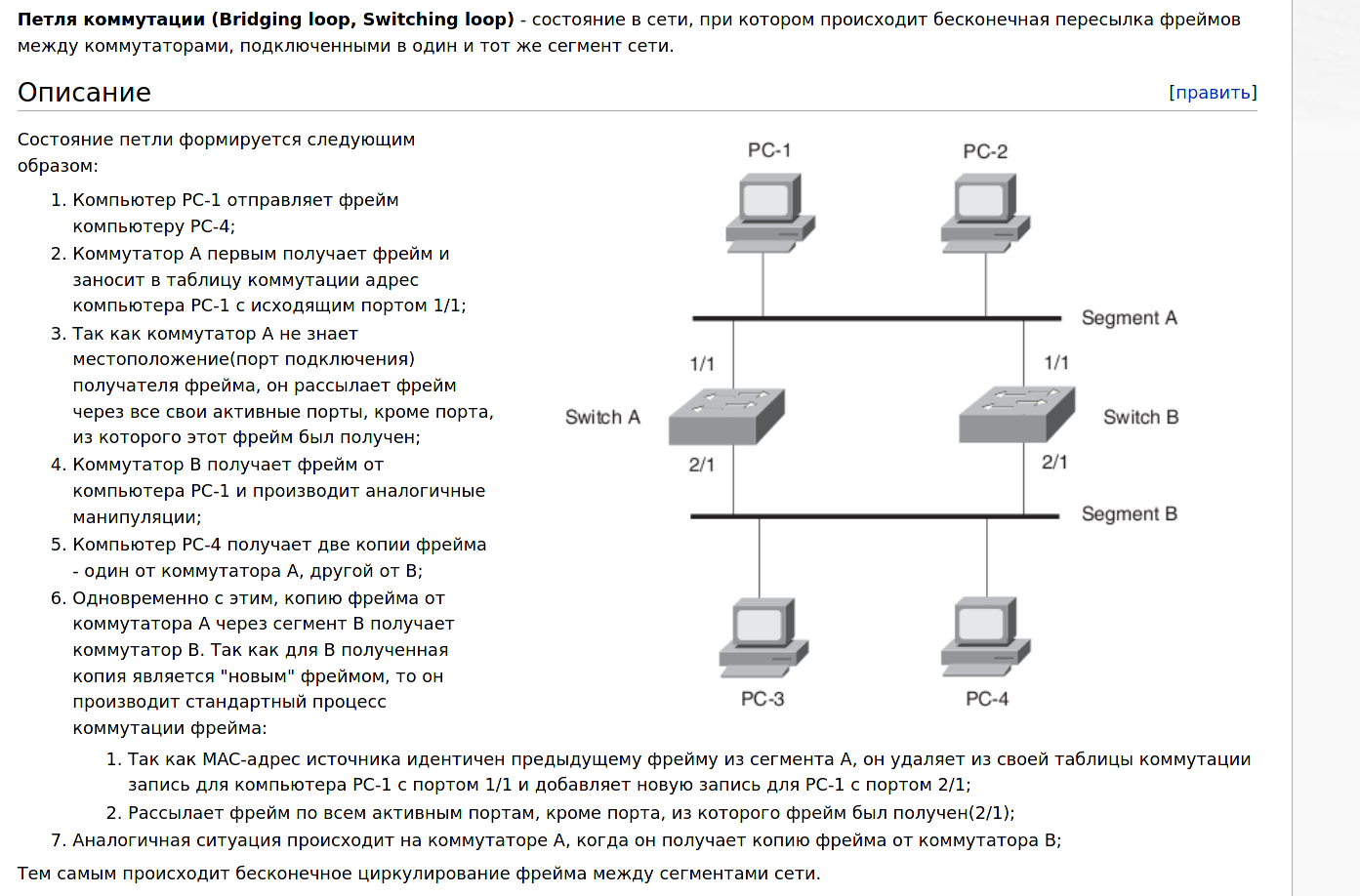
Two switches are connected to each other by two cables, creating a loop. Essentially, the switches start sending identical packets to each other, which multiply like an avalanche and eventually clog the entire network, making it unreachable.
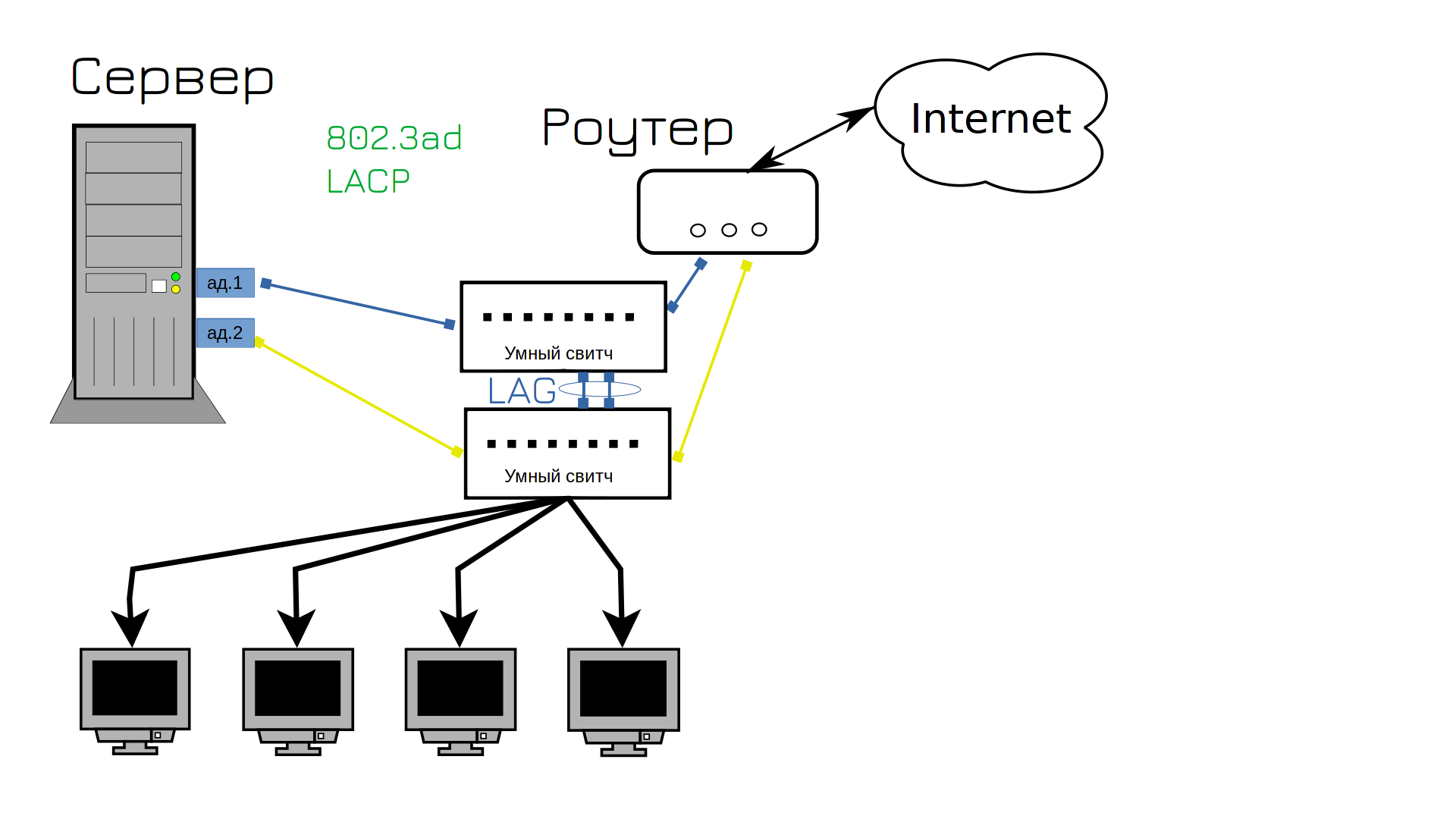
And we are finding a solution to this problem – we need smarter switches. They are called managed switches. These switches have many useful functions for us. For example, port aggregation, link aggregation, and LAG. This is the same combination of network cards, but from the outside. But if before we had to keep one cable on standby with a dull hiss, now we can use both cables.
Not only is there no malfunction, but both cables are used at the same time. Previously, there was an “active and standby” port aggregation type, that is, one port was in standby mode, but now both ports are active. This type of NIC synchronization is called LACP, often referred to as 802.3ad. However, with LACP, only two devices can be connected to multiple ports.
This means that LACP can be used to connect two scrolls. But how can you use LACP between a server and two scrollers so that both ports are active, even if it is three devices – two scrollers and one server?
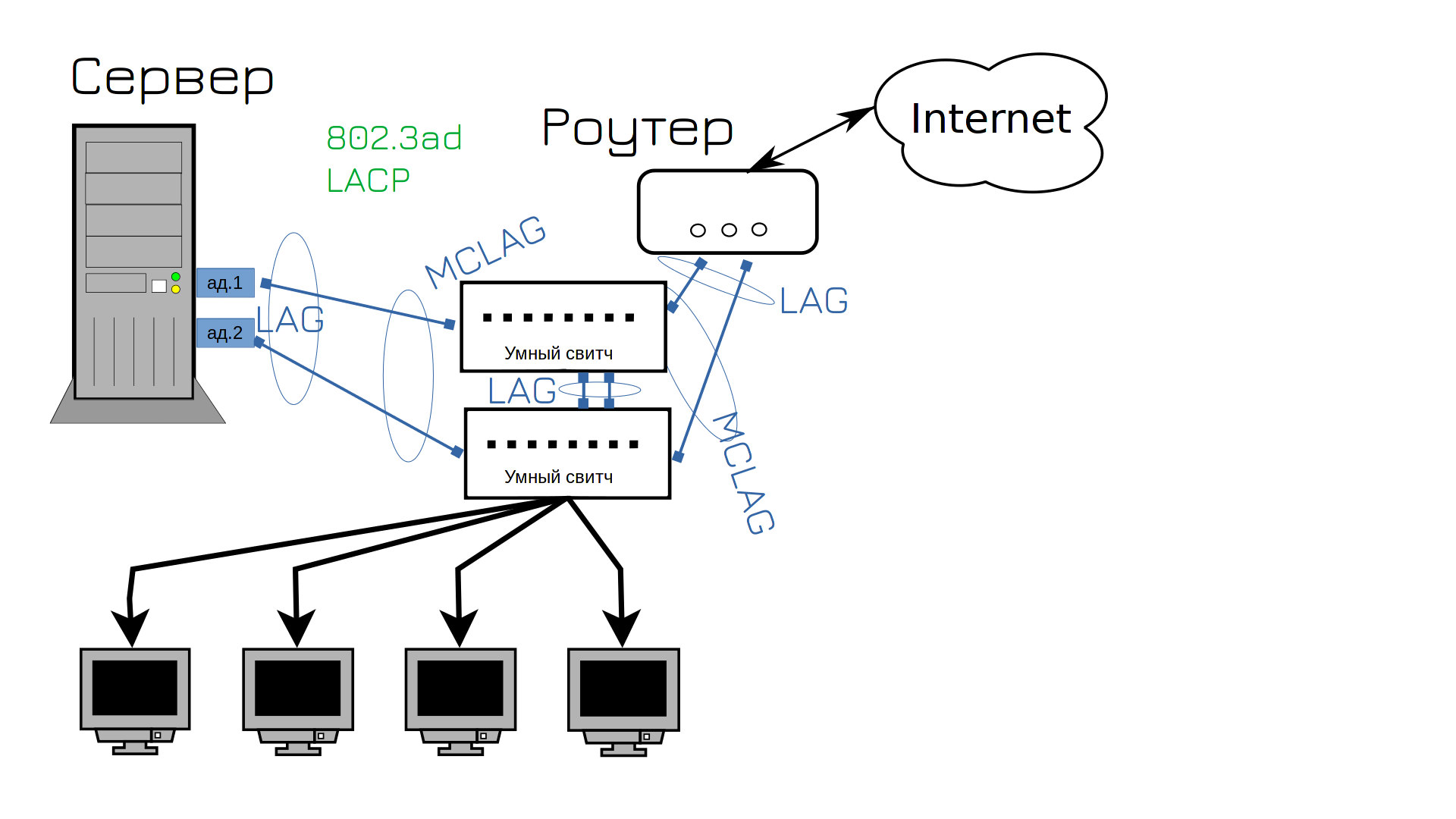
For this, modern switches support port aggregation between several devices, the so-called MCLAG (multi-chassis lag). This allows you to combine the ports of the first and second switch into one group. Since the server thinks that there is one device and one switch on the other side, LACP can be used to configure NIC aggregation. This increases the speed and fault tolerance of the network. Now the network won’t go down, will it?
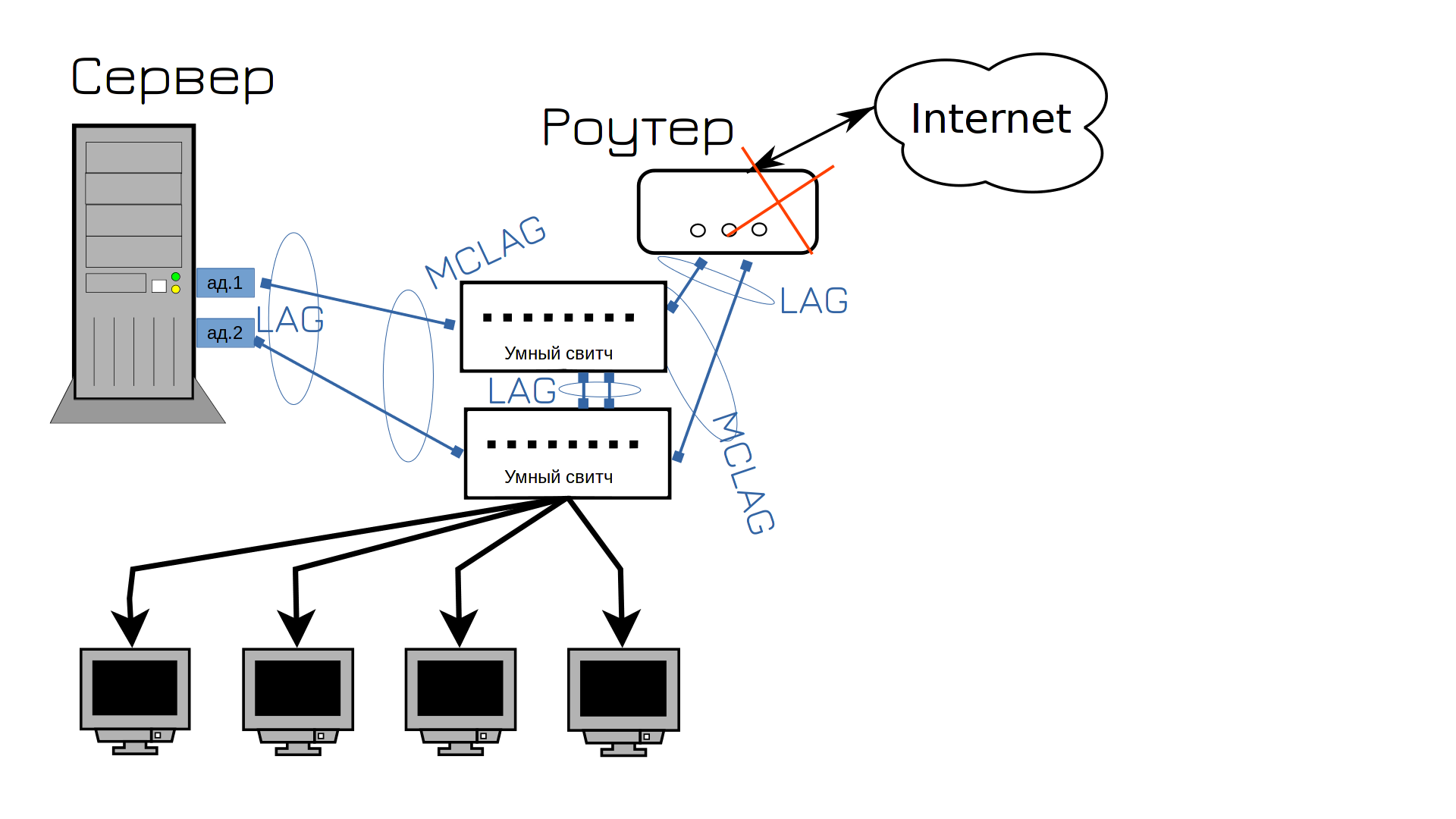
Rejoice early. Now the router has failed. Well, we are not lucky. What to do next? That’s right, buy a second router.
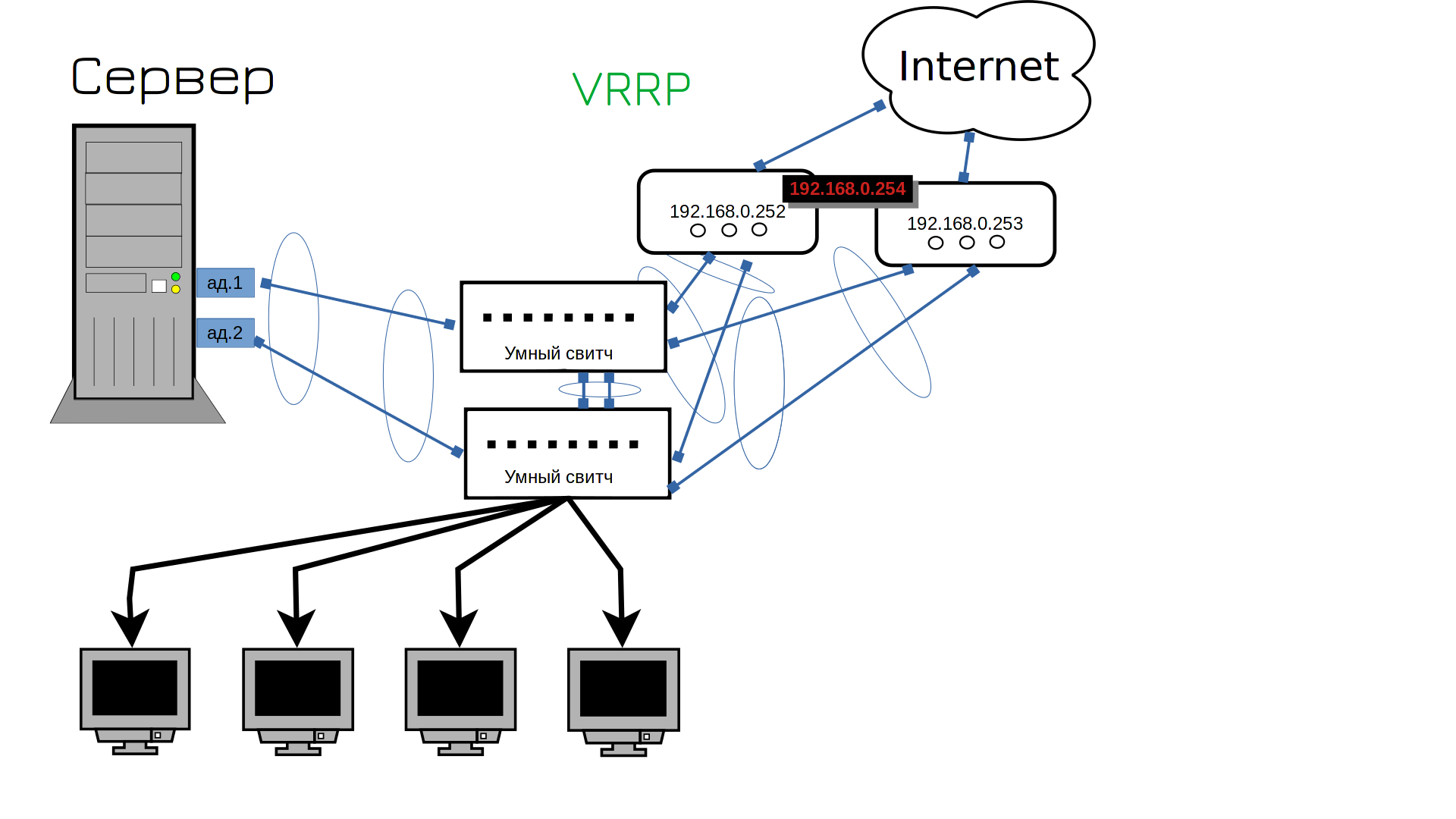
I connected the second router, but it has a different address. Our users use only one address as a gateway to access the Internet. Do you need to run and change gateways? No. We have to change the gateway on both routers. So how can we set the same address on both routers? It is technically impossible. Each device must have its own IP address. However, there is a VRRP protocol that allows you to share an IP address between two devices. Initially, one device will use this address, but when it fails, the IP address will start functioning on the other one. For example, if all goes well, address 254 will be the first router. And if the first router fails, this address will be used by the second router. Is it all true?
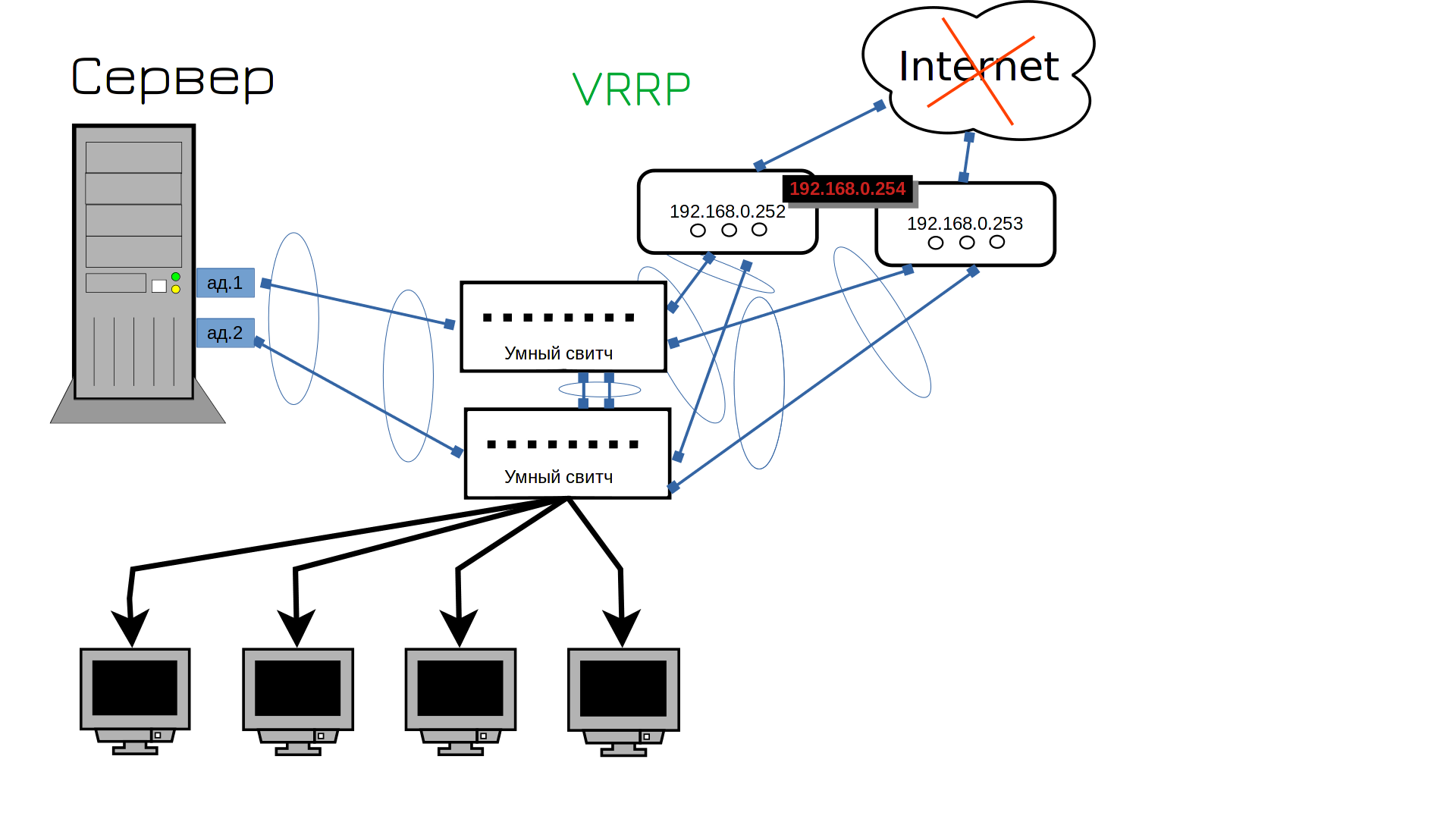
And here is a surprise from the provider – Internet League. Someone dug something and damaged the line, the Internet will be available in a few hours. Well, my dear, what should we buy now, two Internet providers?
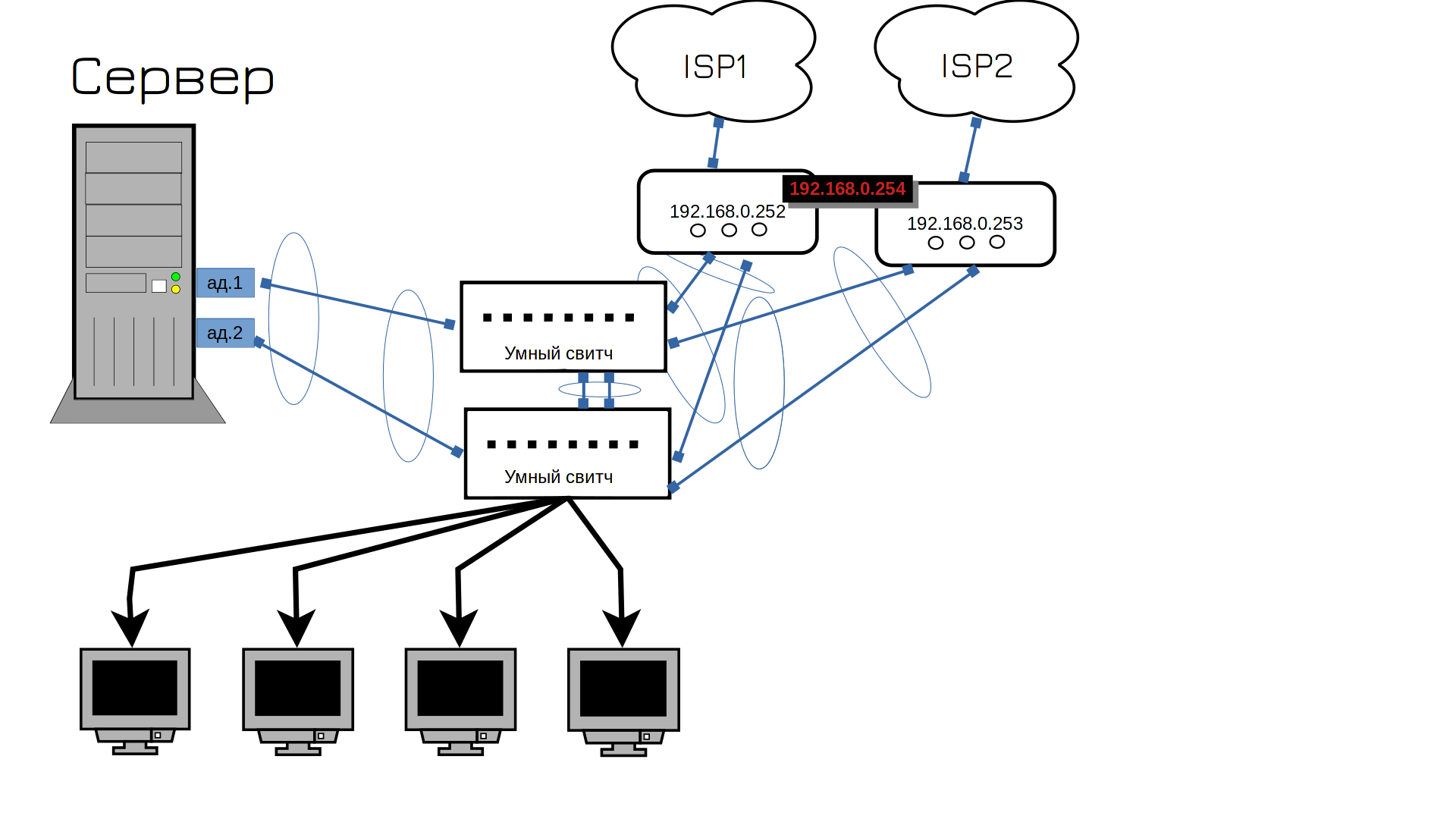
Did you think it was different? Yes, you need a second provider. ISP, by the way, is an Internet service provider. At this stage, dances with a tambourine begin. This is due to the fact that one provider often provides only a cable and cannot connect to two routers. Then one router must be connected to one provider or the provider to the switch. It is possible to connect one cable to one switch and another to another, but this will mean that when the switch fails, the Internet channel will also switch. This is usually not a fatal problem, but it is annoying: two different ISPs will give you two different public addresses, so one of your addresses will be unavailable. And anyone who used that address to connect to a web server, for example, will lose access. You can get around this by setting up an IP address check with your ISP, but we’ll get back to that jungle later.
Now the network has returned to normal operation. Now you can rely on the network. In a real infrastructure, there would be more switches, but these are just numbers – the essence remains the same. Routers can be combined in different ways, and we analyzed VRRP, a standard open protocol. Often, businesses use two routers in the same cluster, and IP address translation is implemented differently by the router’s internal software.
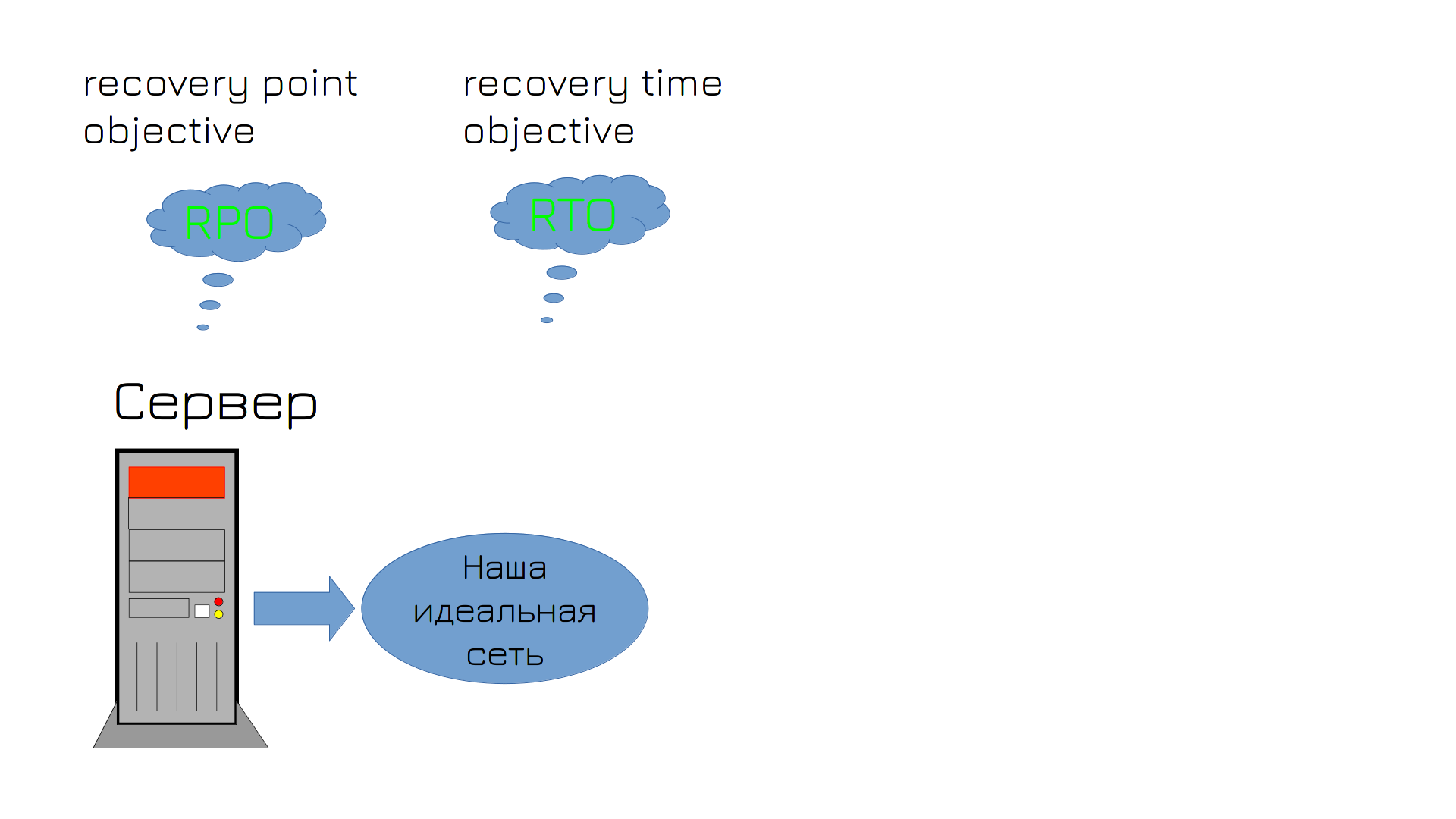
And after you have struggled to explain all the problems to your superiors and managed to beat the budget, your server crashes – the hard drive has failed. At this point, many thoughts are forming in your head, among which are the terms RPO and RTO.
RPO – recovery point objective – is the maximum period of time during which data can be lost. No one wants to lose data, but making backups every second and keeping a bunch of backups will be unrealistically expensive. Therefore, you and your superiors agree that if something goes wrong, you are ready to lose data, for example, for the last two hours. This is your RPO. Accordingly, backups should be made with approximately this frequency.
RTO – recovery time objective – a period of time during which the system can remain unavailable. That is, how long will it take you to get everything back the way it was? Let’s say that in this time you will have time to install a new disk, restore the backup to it and start everything.
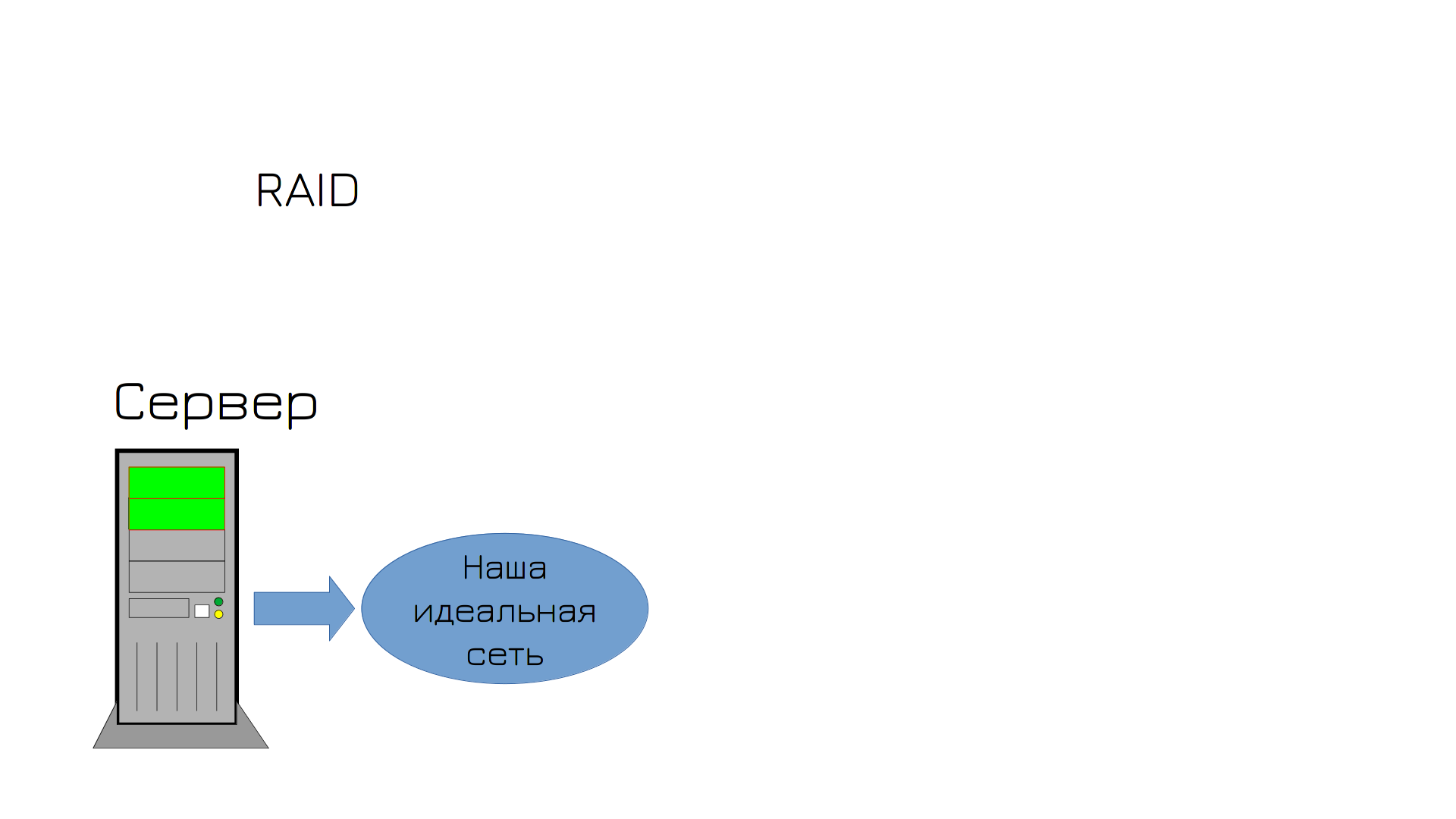
But to avoid a repeat of the situation, you decide to buy a second drive and configure RAID. You have two network adapters, two drives, what else could go wrong?

For example, the power supply may burn. But you cannot put a second power supply unit on the computer.

But you can finally get rid of this junk and buy a real server. It has a lot of useful things like a raid controller, processor and RAM designed for continuous operation, as well as tracking the status of all equipment. It also has two power supplies! What can go wrong?

Why not crash the operating system? Won’t the mother burn? How about a soul mate? But no way.

Well, you will have to be generous – buy a second server and create a cluster. Clusters can be created on the basis of a hypervisor, where everything can be virtualized and run on separate servers. However, creating a cluster with two servers is a very bad idea. This is because if the servers lose contact with each other, each server will think the other is down. Then each will try to start the virtual machine. This will wreak havoc and likely lead to data corruption.

Therefore, the cluster should consist of three servers: if one server fails, the other two will continue to work; if one server confirms that it has lost contact with the other two servers, it will assume that there is a problem with that server and stop loading the virtual machines.
Now suppose one of the servers goes down. The virtual machine files are on an inaccessible server. Do you need to constantly back up your virtualization from one server to another? If the server goes down, some data will be lost. Data must be centralized and available on all three servers at the same time.
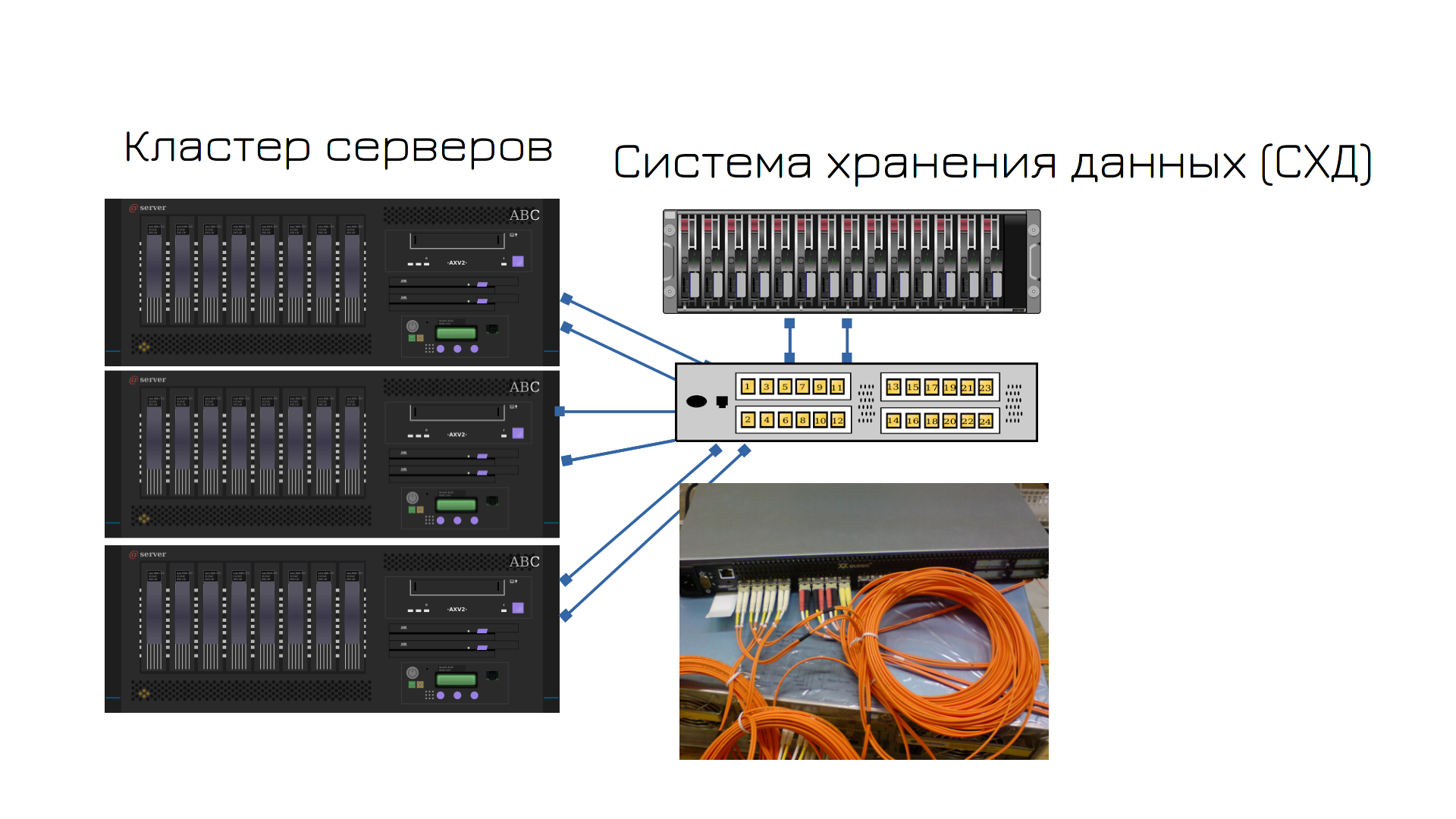
It is a data storage system called gatekeeper. This is a type of server with a bunch of disks that are needed to reserve space on the server. The server is connected to a special switch called a SAN switch that is connected to the custodian. Virtual disks are created on it, and the server sees these disks over the network. However, this is not the usual network we studied. In other words, there’s a regular network that works with network packets going back and forth, and a couple of special optical adapters that access the drives over the network. Such a network is called a data storage network (Storage Area Network, SAN).
The storage unit itself has two controllers – like two motherboards – so there is no need to buy a second storage unit for failover. Inside Guardian are RAID, deduplication, snapshots, and many other useful storage technologies.
All three servers refer to the same virtual disk, so virtual disks can be moved between servers without problems.
Such an infrastructure is called classic if there are servers and data storage systems. There are others, but this is a separate topic.

This is how servers, data storage systems, and tapes accumulated. All this equipment gets very hot, emits a lot of heat and is very sensitive to the environment. The standard temperature at which such equipment feels comfortable is about 20 degrees Celsius. At 30-35°C, for example, problems can occur or something can break. Humidity should also be around 40%. In a normal environment, it is difficult to create such conditions, and the noise from the servers prevents quiet work. Therefore, all these devices should be kept in a special room with appropriate conditions, that is, in a server room.

And so that these devices do not stand on the floor, there are special metal cabinets called racks. They are standardized and have the same height and width for many cabinets. In the racks there is a place called a unit, in Ukrainian it is “U”, which means “mounting block”. And the height is about 4.5 cm. Servers, scrolls and other equipment usually have a height corresponding to this unit. For example, a scroll usually occupies 1U, a server – 1U, 2U or sometimes 4U.
Server rooms have certain requirements, for example, where the air comes from and how it circulates, a special air conditioning system to regulate the temperature and humidity in the server room, special environmental monitoring systems to control temperature, humidity and other parameters, as well as special fire extinguishing systems. In general, a huge number of requirements are placed on server rooms.

What, do you think after spending so much money and collecting such a server, you got rid of a single point of failure? Ha, no matter what. One day your electricity just goes out. It’s not your fault, what can be done about it? Something I did not hear about Google being cut off, so it became unavailable.

So we buy a UPS with the money we have. But not household. Do you know how much energy this equipment consumes? We need a more powerful UPS. If you have one or two cabinets with equipment, then a river UPS will suffice. But you can’t count on one UPS, so you need at least two. And sometimes you have a lot of equipment and you don’t want to lose power to the entire building. Therefore, a separate room can be allocated for UPS. But it is not about IT, but about servers working and services being available.
What if the outage lasts longer? We break the last piggy bank and pull the second wire of electricity, with the UPS power supply unit on one side and the UPS on the other. If one side loses power, the other will still work.

What do you think about it all? And if the server is flooded? What if the electricity goes out in the whole city? If a meteorite falls on the city? What, because of this the business has to stop working? No matter what.
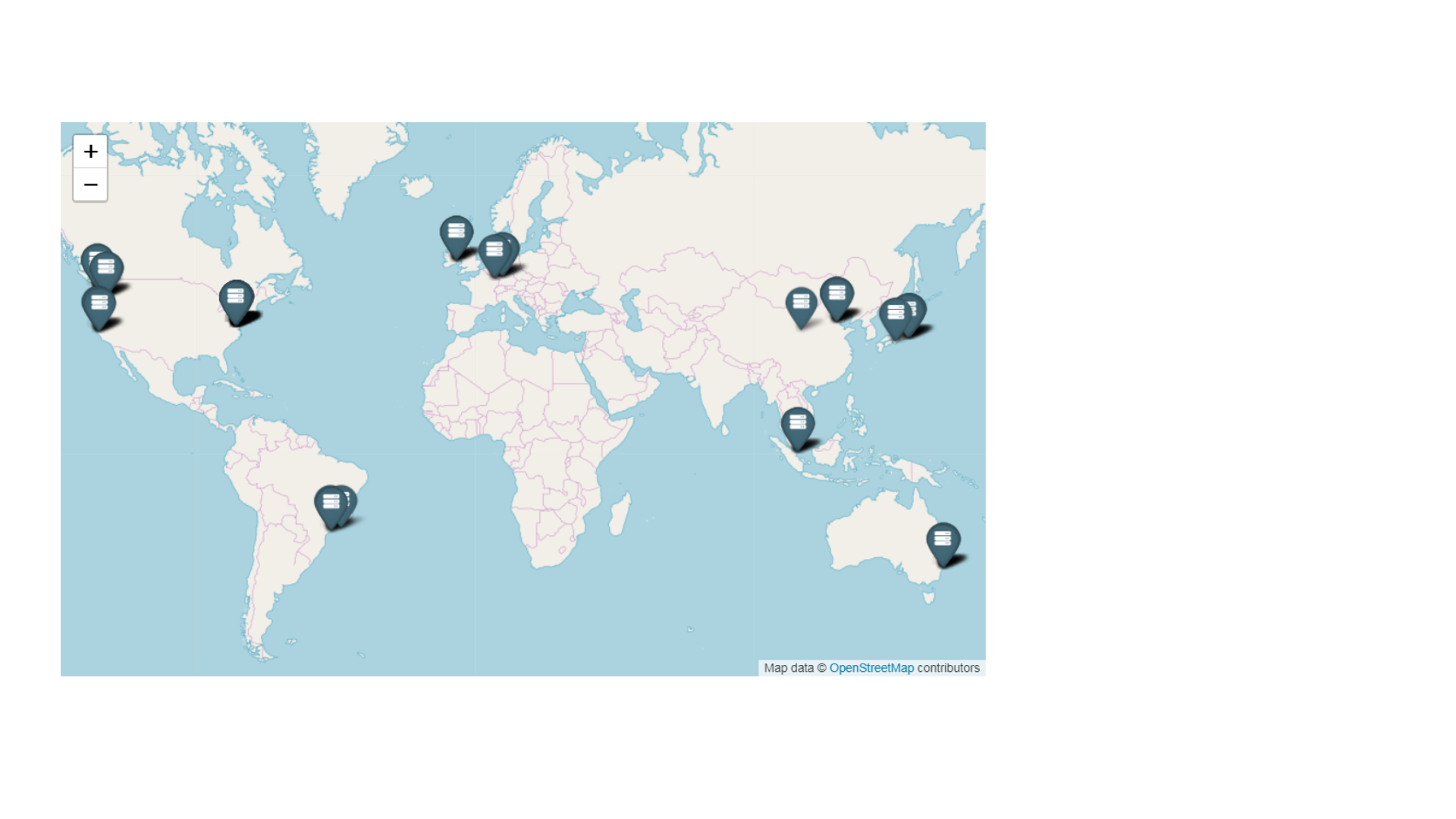
Build a copy of the data center in another building, in another city, in another country, on another continent, on another planet. No matter what happens, our infrastructure must work. Do you think Elon Musk is exploring Mars for humanity? Believe me, the first thing that will appear there are data centers.
Now you understand why SPOF is the keyword in IT and why IT is so expensive? There are many other nuances that I have not mentioned, but you will learn a lot over time. Not every company will build a backup data center, but you can grow as a professional by connecting two cables instead of one.





