
16.08.2024
1 хв
1250

HTTP-флуд – це різновид DDoS-атак, метою яких є перевантаження веб-сервера численними HTTP-запитами, що може зробити сайт недоступним для користувачів. Найчастіше зловмисники використовують GET і POST-запити, створюючи надмірне навантаження на сервер.

Ця стаття створена виключно з навчальною метою, щоб показати, як працюють навантаження на сервер і де можуть виникати слабкі місця в його архітектурі. Матеріал допомагає краще зрозуміти принципи роботи веб-систем і підвищити рівень безпеки, щоб вчасно знаходити та усувати вразливості. Автор не закликає до будь-яких незаконних дій і наголошує: отримані знання варто використовувати лише для тестування власних систем або в рамках легального пентесту.
На перший погляд здається, що найпростіший спосіб атакувати сервер через DDoS – це перевантажити його мережевий канал до такого рівня, що нові пакети почнуть оброблятися повільно або взагалі відхилятися. Це логічно, оскільки встановлення кожного нового з’єднання та процес SSL Handshake вимагають обміну кількома пакетами між клієнтом і сервером.
Але тут є важливий нюанс.
Сучасні сервери, розміщені у дата-центрах, мають пропускну здатність 10 Гбіт/с або навіть більше. Щоб повністю завантажити такий канал, потрібен величезний обсяг запитів щосекунди.
Більш ефективним підходом є перевантаження вихідної пропускної здатності сервера, оскільки кожна відповідь може бути значно більшою за отриманий запит. Наприклад, стандартний HTTP-запит GET / HTTP/1.1\r\n\r\n займає лише 18 байт, тоді як відповідь сервера може сягати кількох кілобайт, створюючи значно більше навантаження.
На більшості веб-серверів встановлено reverse proxy, наприклад, Nginx, Apache HTTP Server (httpd) чи інші популярні рішення. Головне завдання reverse proxy – приймати вхідні запити та переспрямовувати їх на бекенд для подальшої обробки.
Однак можливості reverse proxy у плані одночасної обробки запитів не є безмежними. Кожне з’єднання обробляється окремим воркером або потоком, кількість яких визначається налаштуваннями сервера та доступними ресурсами системи.
Якщо кількість з’єднань перевищує допустимий ліміт, сервер не зможе виділити додатковий воркер, і нові запити просто залишаться без відповіді. У результаті нові користувачі не зможуть отримати доступ до ресурсу, що спричинить відмову в обслуговуванні.
Коли запит доходить до Reverse Proxy, він спрямовується на бекенд-сервер. Варто розуміти, що бекенд отримує з’єднання не безпосередньо від клієнта, а від локальної адреси (наприклад, 10.0.0.2), яка може належати внутрішній мережі Docker або Kubernetes.
При цьому може виникнути проблема 65 тисяч з’єднань. Це обмеження пов’язане з максимальною кількістю одночасних з’єднань – 65 536 портів для однієї IP-адреси. Якщо всі порти будуть зайняті, сервер не зможе встановлювати нові з’єднання і припинить відповідати на запити.
Ця ситуація зазвичай виникає у таких випадках:
Тривала обробка запитів бекендом – якщо сервер “задумується” над відповіддю занадто довго, з’єднання залишаються відкритими.
Надмірна кількість одночасних запитів – якщо запитів занадто багато, всі доступні порти можуть бути швидко вичерпані.
Вирішити цю проблему можна досить просто – перейти на UNIX-сокети замість TCP-з’єднань. Оскільки UNIX-сокети не мають обмеження за кількістю портів, вони допомагають уникнути ліміту у 65 тисяч з’єднань.
Однак навіть при використанні UNIX-сокетів серверу все одно необхідні системні виклики для передачі кожного запиту, що може впливати на продуктивність.

Уявіть ситуацію: 100 з’єднань відправляють по 1 мегабайту даних. Сервер повинен десь зберігати ці дані, і зазвичай він робить це в оперативній пам’яті. На цьому етапі все ще виглядає прийнятно.
Але тепер уявіть, що кількість з’єднань зростає до 1000, і кожне з них передає по 5 мегабайт даних. Це вже ~4 гігабайти пам’яті! Якщо оперативна пам’ять закінчується, у Linux виникає Out of Memory (OOM) ситуація.
Він просто вбиває процес, який споживає найбільше пам’яті, щоб звільнити ресурси. У нашому випадку це буде веб-сервер або бекенд-процес, що призводить до повного припинення обслуговування. Однак, супервізор процес перезапустить.
Ще одна серйозна проблема – потокове голодування. Коли на бекенд надходить надмірна кількість запитів одночасно, сервер може зіштовхнутися з нестачею ресурсів для їхньої обробки.
У такій ситуації кожен запит потребує певного часу на виконання, але через обмежені можливості системи операційна система починає інтенсивно перемикати контекст між потоками. Це перемикання є надзвичайно ресурсозатратним процесом.
Як наслідок, більша частина процесорного часу витрачається не на обробку запитів, а на перемикання контексту між потоками. Це суттєво знижує продуктивність і може навіть спричинити повне зависання сервера.
Якщо ж сервер замість потоків використовує асинхронну обробку, то цикл подій має перемикатися між завданнями відповідно до їхнього пріоритету. Проте коли таких завдань занадто багато, перемикання між асинхронними функціями також починає сповільнюватися, що негативно впливає на продуктивність всієї системи.
Уявімо таку ситуацію: клієнт надсилає запит на сервер, щоб авторизуватися. Давайте порахуємо, що потрібно зробити клієнту:
Встановити з’єднання.
Виконати SSL handshake.
Записати запит у socket.
Дочекатися відповіді від сервера.
А тепер розглянемо, що повинен зробити сервер у відповідь:
Прийняти з’єднання.
Виконати SSL handshake.
epoll для моніторингу з’єднання.
Відкрити з’єднання з бекендом і передати запит.
Бекенд має прочитати запит і з’єднатися з базою даних.
База даних виконує читання або запис, після чого бекенд формує відповідь.
Як видно, кількість системних викликів на сервері значно перевищує їхню кількість на стороні клієнта. Хоча сучасні процесори можуть обробляти величезну кількість таких викликів, цей ресурс не є безмежним.
При надмірному навантаженні навіть найпотужніший процесор може досягти своєї межі, оскільки можливості обробки системних викликів у секунду обмежені. У такому випадку сервер перестає справлятися із запитами, що може призвести до серйозного зниження продуктивності або навіть повного виходу з ладу.
Хостинг-провайдери, такі як Google Cloud, AWS, DigitalOcean та інші, мають квоти на вихідний трафік. Наприклад, у DigitalOcean додаткова плата за перевищення квоти становить $0.01 за 1 гігабайт.
Як це можна використати? Достатньо знайти великий файл на сервері та завантажувати його багато разів. Таким чином, ми швидко вичерпаємо квоту на вихідний трафік.
Досвід та експерименти показують, що перевищити цю квоту можна дуже швидко, завдавши фінансових збитків власнику сервера.

Важливо правильно налаштувати ключові параметри сервера, такі як connection timeout, client max body та кількість запитів у межах одного з’єднання (завдяки Connection: keep-alive). Вони визначають, наскільки ефективно сервер оброблятиме вхідні запити та наскільки стійким буде до навантажень.
Значення connection timeout дозволяє контролювати час очікування перед закриттям з’єднання. Наприклад, якщо тайм-аут становить 1 хвилину, можна відправити запит за секунду до його закриття, паралельно відкриваючи сотні або навіть тисячі нових з’єднань. Однак слід враховувати обмеження: одна IP-адреса має лише 65 536 доступних портів, і цей ліміт накладає певні обмеження на масштабування таких дій.
Інший важливий параметр – client max body, який визначає максимальний розмір тіла запиту. Використовуючи його значення, можна змусити сервер витрачати більше ресурсів, відправляючи найбільші можливі файли або об’ємні дані. Якщо розмір перевищує ліміт, сервер може відхилити запит або закрити з’єднання. Щоб максимально використати доступний час, варто комбінувати client max body із connection timeout.
Ще один спосіб оцінити продуктивність сервера – тестування навантаження на процесор. Один із методів – відправлення великого JSON-об’єкта, що потребує значних обчислювальних ресурсів для парсингу.
Як це працює?
Спочатку надсилається JSON-запит, який сервер обробляє, наприклад, 2 секунди.
Потім відправляється цей самий JSON у паралельних з’єднаннях, щоб перевірити, чи збільшиться час його обробки.
Якщо час обробки починає зростати, це означає, що серверу не вистачає ядер процесора для одночасної обробки запитів, і він може досягти свого ліміту.
Знаючи, як налаштований сервер та які ресурси надає хостинг-провайдер, можна розробити ефективний план як для тестування стійкості, так і для виявлення слабких місць у конфігурації. Це дозволяє оцінити вразливість сервера та передбачити його поведінку під час високих навантажень.

Аби щось довести чи спростувати, потрібно спробувати. Для цього було розроблено невелике веб API з кількома ендпоїнтами:
/hit1— запити до цього ендпоїнта записуються в Redis. Кожні 10 секунд Celery масово переносить ці записи в базу даних.
/hit2— запити одразу записуються безпосередньо в базу даних.
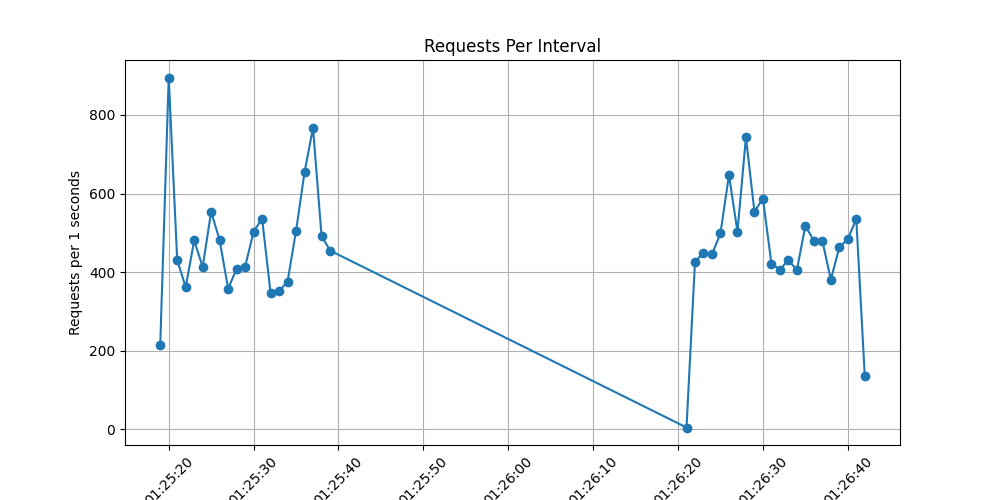
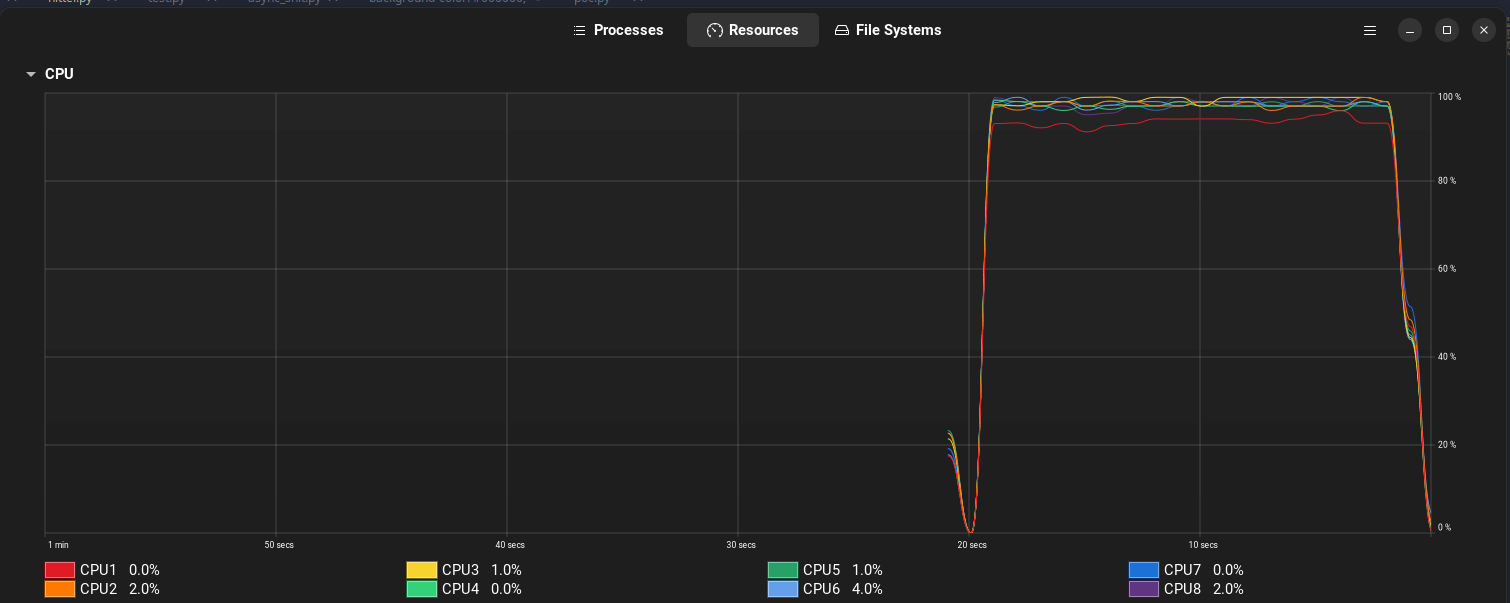
Наступним етапом було тестування запитів на ендпоінт /hit1, де запис у базу даних виконується раз на 10 секунд за допомогою Celery – асинхронного таск-менеджера для Python.
Менше навантаження на сервер: процесор нашого сервера не завантажився так сильно, як у випадку з
/hit2.
Вища продуктивність: на графіку чітко видно, що в одну секунду сервер обробив 3250 запитів.
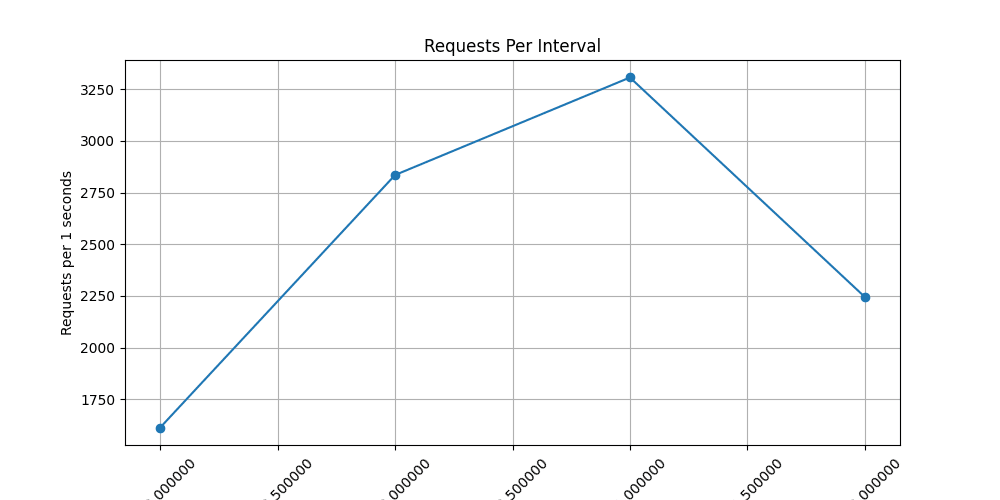
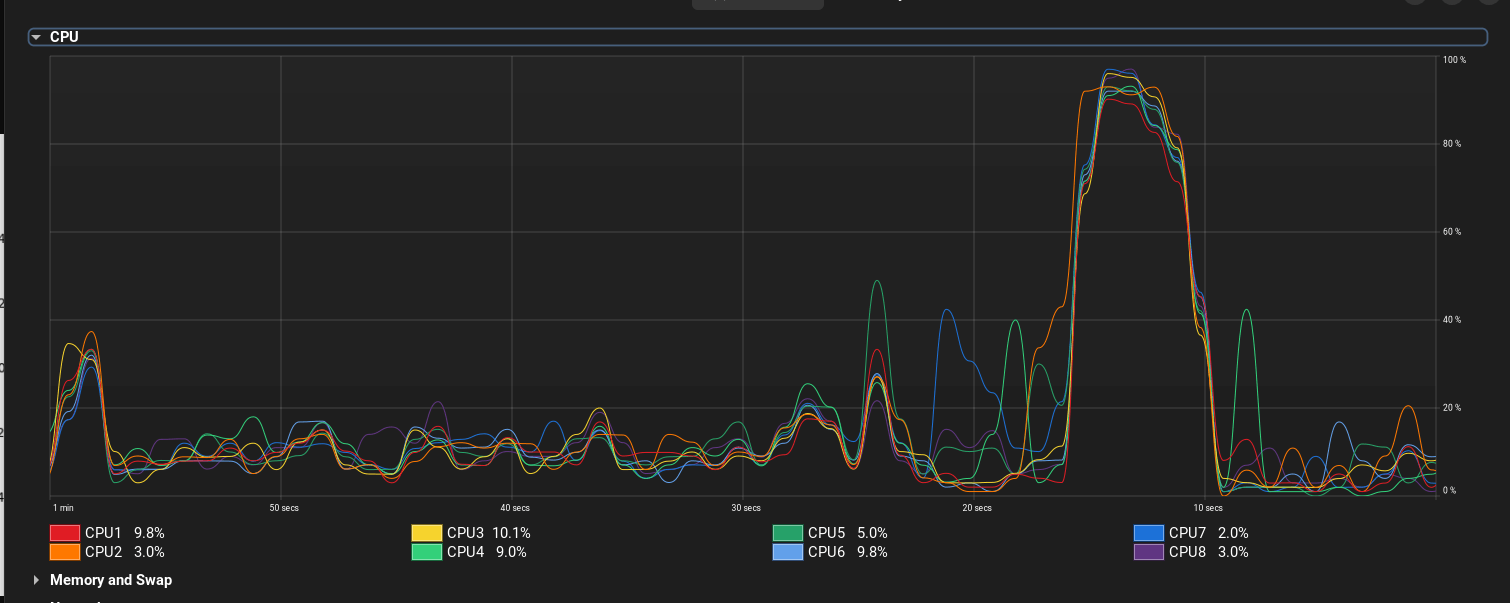
Безсистемне надсилання великої кількості запитів у випадкове місце не гарантує значного навантаження на сервер. Навіть при високій частоті запитів флуд може бути малоефективним.
Більш результативним підходом є виявлення слабких місць в архітектурі. У цьому випадку /hit2 безпосередньо записує дані в базу, що робить його вузьким місцем. Натомість /hit1 використовує Celery, що дозволяє краще витримувати навантаження і забезпечує більш ефективну роботу сервера.
За допомогою Python було створено скрипт, який відкриває велику кількість з’єднань і утримує їх активними якомога довше. Ця техніка схожа на Slowloris-атаку, метою якої є вичерпання ресурсів сервера шляхом утримання великої кількості відкритих підключень.
Щоб ефективно навантажити сервер, слід враховувати кілька важливих моментів:
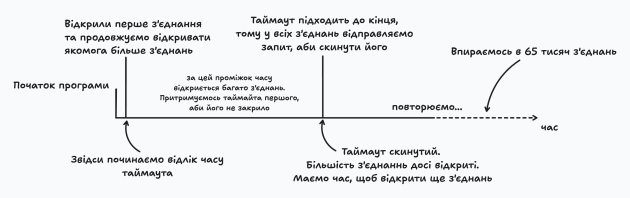
✔ Визначте таймаут сервера – дізнайтесь, скільки часу сервер утримує з’єднання відкритим перед його примусовим закриттям.
✔ Створюйте групи з’єднань – відкривайте велику кількість підключень та керуйте ними у групах для більшого контролю.
✔ Надсилайте дані частинами – щоб з’єднання залишалося активним, відправляйте фрагменти запиту за кілька секунд до завершення таймауту.
✔ Знайдіть “дешевий” запит – оберіть той запит, який найменше навантажує клієнтську сторону, але довго обробляється сервером.
Такий підхід дозволяє ефективно перевантажити сервер, змушуючи його витрачати значні ресурси на підтримку відкритих з’єднань.
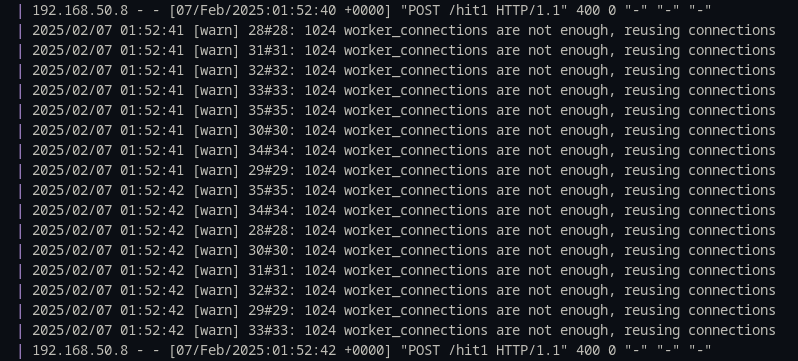
У результаті Nginx вичерпав усі доступні воркери, що спричинило неможливість встановлення нових з’єднань.
Звісно, можна було краще налаштувати Nginx, оптимізувавши конфігурацію для більшої стійкості. Проте подібна ситуація може виникнути на будь-якому сервері, особливо якщо його налаштування не були адаптовані до захисту від такого типу атак або не передбачали обмежень для утримання з’єднань.
DoS- та DDoS-атаки методом HTTP-флуду можуть бути надзвичайно ефективними, але важливо не просто хаотично відправляти запити, а спершу знайти вузьке місце в архітектурі сервера. Це може бути, наприклад, ендпоїнт із частими записами в базу даних або ресурсомістка операція, що виконує складні обчислення.
Ця стаття була написана, щоб продемонструвати методи створення навантаження на сервер, зокрема як виявляти слабкі місця в його архітектурі та експлуатувати їх. Якщо визначити, які операції споживають найбільше ресурсів, можна значно ефективніше проводити навантажувальні атаки, використовуючи мінімум запитів для досягнення максимального впливу.

