
16.08.2024
3 min
1248

HTTP flood is a type of DDoS attack that aims to overload a web server with numerous HTTP requests, potentially rendering the site inaccessible to users. Most often, attackers use GET and POST requests, creating excessive load on the server.

At first glance, it seems that the easiest way to attack a server via DDoS is to overload its network channel to such an extent that new packets begin to be processed slowly or are rejected altogether. This is logical, since the establishment of each new connection and the SSL Handshake process require the exchange of several packets between the client and the server.
But there is an important nuance here.
Modern servers located in data centers have a bandwidth of 10 Gbps or even more. To fully load such a channel, a huge volume of requests is required every second.
A more effective approach is to overload the server’s outgoing bandwidth, since each response can be much larger than the received request. For example, a standard HTTP request GET / HTTP/1.1\r\n\r\n takes only 18 bytes, while the server’s response can reach several kilobytes, creating a significantly larger load.
Most web servers have a reverse proxy installed, such as Nginx, Apache HTTP Server (httpd), or other popular solutions. The main task of a reverse proxy is to accept incoming requests and redirect them to the backend for further processing.
However, the capabilities of a reverse proxy in terms of simultaneous request processing are not unlimited. Each connection is processed by a separate worker or thread, the number of which is determined by the server settings and available system resources.
If the number of connections exceeds the allowable limit, the server will not be able to allocate an additional worker, and new requests will simply remain unanswered. As a result, new users will not be able to access the resource, which will cause a denial of service.
When a request reaches the Reverse Proxy, it is forwarded to the backend server. It is worth understanding that the backend does not receive a connection directly from the client, but from a local address (for example, 10.0.0.2), which may belong to the internal Docker or Kubernetes network.
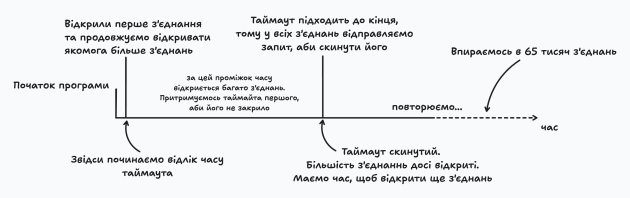
In this case, the problem of 65 thousand connections may arise. This limitation is due to the maximum number of simultaneous connections – 65,536 ports for one IP address. If all ports are busy, the server will not be able to establish new connections and will stop responding to requests.
This situation usually occurs in the following cases:
Long backend processing of requests – if the server “thinks” about the response for too long, connections remain open.
Excessive number of simultaneous requests – if there are too many requests, all available ports can be quickly exhausted.
The solution to this problem is to switch to UNIX sockets instead of TCP connections. Since UNIX sockets have no port limit, they help to avoid the 65,000 connection limit.
However, even when using UNIX sockets, the server still needs to make system calls to transmit each request, which can affect performance.

Imagine a situation: 100 connections sending 1 megabyte of data each. The server has to store this data somewhere, and it usually does so in RAM. At this point, it still looks acceptable.
But now imagine that the number of connections grows to 1000, and each of them transfers 5 megabytes of data. That’s ~4 gigabytes of memory! If RAM runs out, Linux experiences an Out of Memory (OOM) situation.
It simply kills the process that consumes the most memory to free up resources. In our case, it will be a web server or a backend process, which leads to a complete stop of service. However, the supervisor will restart the process.
Another serious problem is thread starvation. When an excessive number of requests are received by the backend at the same time, the server may face a lack of resources to process them.
In such a situation, each request takes a certain amount of time to execute, but due to the limited capabilities of the system, the operating system begins to intensively switch the context between threads. This switching is an extremely resource-intensive process.
As a result, most of the processor time is spent not on processing requests, but on switching the context between threads. This significantly reduces performance and can even cause the server to completely freeze.
If the server uses asynchronous processing instead of threads, the event loop must switch between tasks according to their priority. However, when there are too many such tasks, switching between asynchronous functions also begins to slow down, which negatively affects the performance of the entire system.
Let’s imagine the following situation: a client sends a request to the server to authenticate. Let’s calculate what the client needs to do:
Establish a connection.
Perform an SSL handshake.
Write the request to the socket.
Wait for a response from the server.
Now let’s consider what the server should do in response:
Accept the connection.
Perform an SSL handshake.
epoll to monitor the connection.
Open a connection to the backend and pass the request.
The backend should read the request and connect to the database.
The database performs a read or write, after which the backend generates a response.
As you can see, the number of system calls on the server far exceeds the number on the client side. Although modern processors can handle a huge number of such calls, this resource is not unlimited.
Under excessive load, even the most powerful processor can reach its limit, since the ability to process system calls per second is limited. In this case, the server can no longer cope with requests, which can lead to a serious decrease in performance or even a complete failure.
Hosting providers such as Google Cloud, AWS, DigitalOcean, and others have quotas for outgoing traffic. For example, DigitalOcean charges an additional fee of $0.01 per gigabyte for exceeding the quota.
How can this be used? It is enough to find a large file on the server and download it many times. Thus, we quickly exhaust the quota for outgoing traffic.
Experience and experiments show that this quota can be exceeded very quickly, causing financial losses to the server owner.

It is important to properly configure key server parameters such as connection timeout, client max body, and the number of requests per connection (thanks to Connection: keep-alive). They determine how efficiently the server will handle incoming requests and how resilient it will be to load.
The connection timeout value allows you to control the time to wait before closing the connection. For example, if the timeout is 1 minute, you can send a request a second before closing it, opening hundreds or even thousands of new connections in parallel. However, you should take into account the limitations: one IP address has only 65,536 available ports, and this limit imposes certain limitations on the scaling of such actions.
Another important parameter is client max body, which determines the maximum size of the request body. Using its value, you can force the server to spend more resources by sending the largest possible files or voluminous data. If the size exceeds the limit, the server may reject the request or close the connection. To make the most of the available time, it is worth combining client max body with connection timeout.
Another way to evaluate server performance is to test the CPU load. One method is to send a large JSON object, which requires significant computing resources for parsing.
How does it work?
First, a JSON request is sent, which the server processes for, for example, 2 seconds.
Then the same JSON is sent in parallel connections to see if its processing time increases.
If the processing time starts to increase, this means that the server does not have enough processor cores to process requests simultaneously and may have reached its limit.
Knowing how your server is configured and what resources your hosting provider provides can help you develop an effective plan for both stress testing and configuration vulnerability detection. This allows you to assess your server’s vulnerability and predict its behavior under high load.

To prove or disprove something, you have to try it. For this purpose, a small web API with several endpoints was developed:
/hit1 – Requests to this endpoint are written to Redis. Every 10 seconds, Celery bulk-transfers these records to the database.
/hit2 – Requests are immediately written directly to the database.
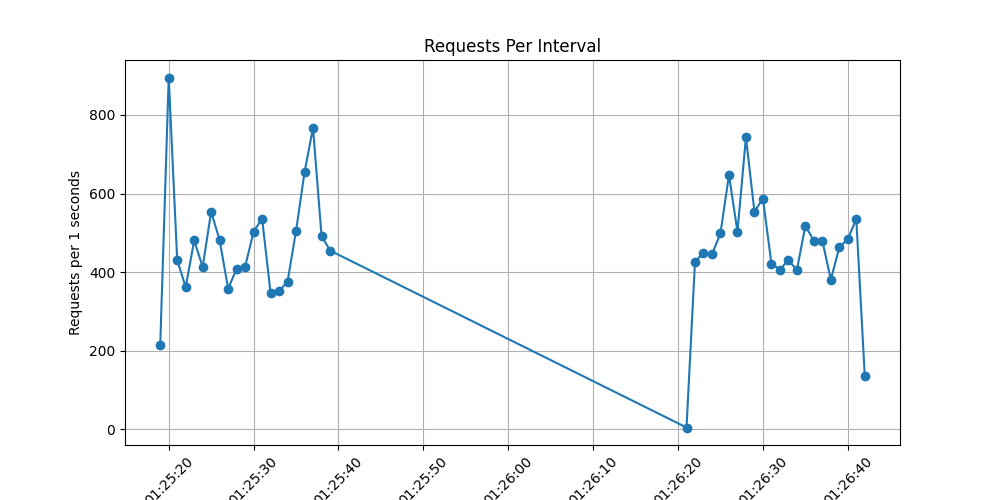
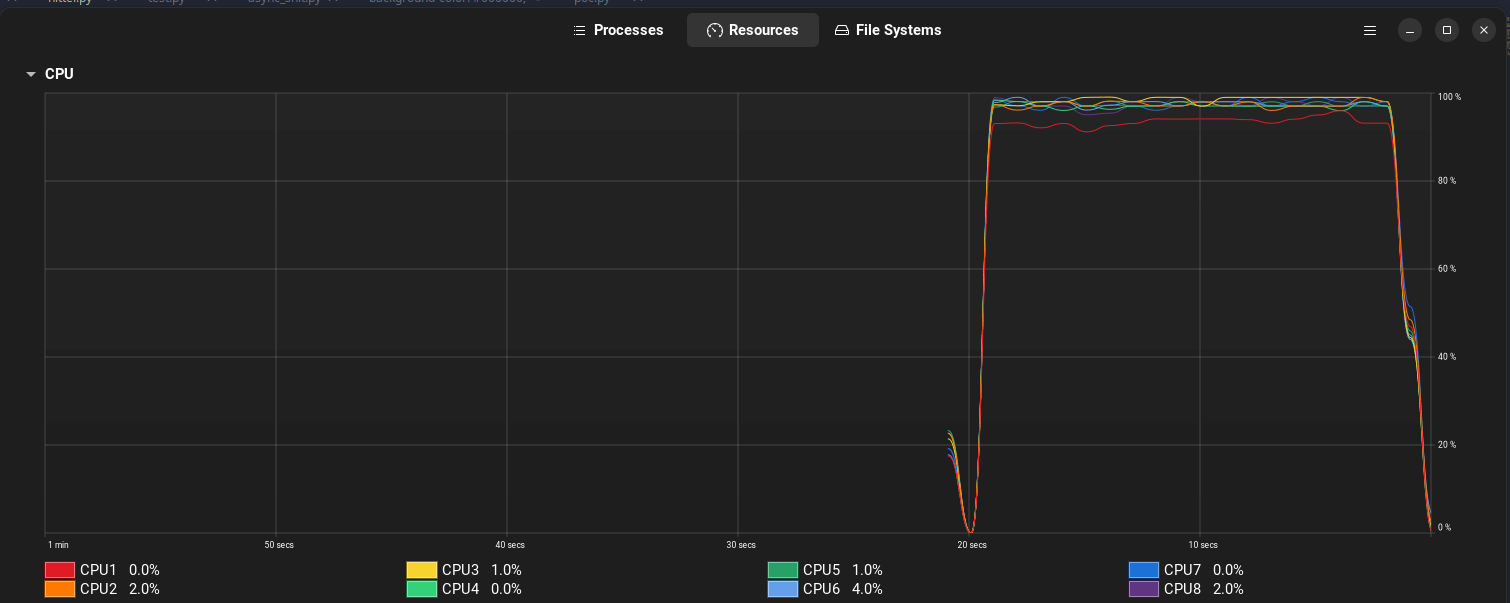
The next stage was testing requests to the /hit1 endpoint, where a database write is performed every 10 seconds using Celery, an asynchronous task manager for Python.
Less server load: Our server’s CPU was not as heavily loaded as in the case of /hit2.
Higher performance: The graph clearly shows that the server processed 3250 requests in one second.
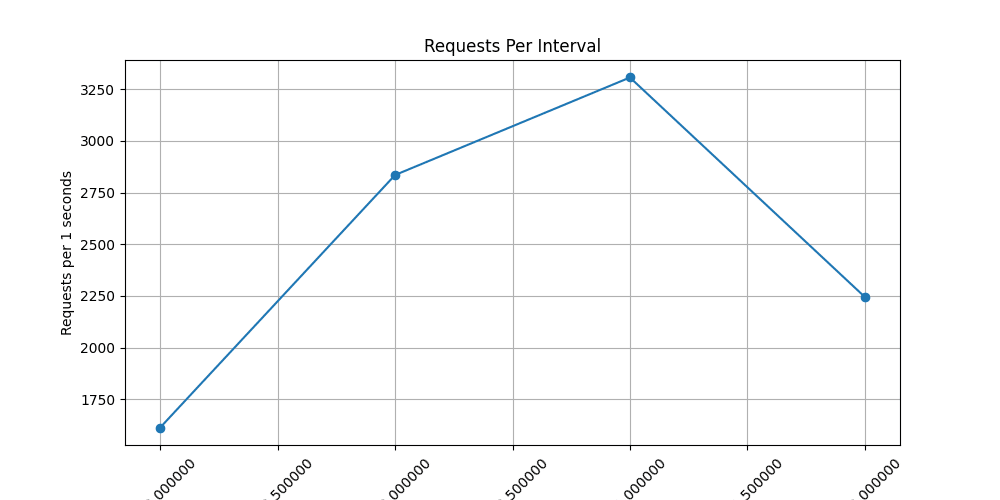
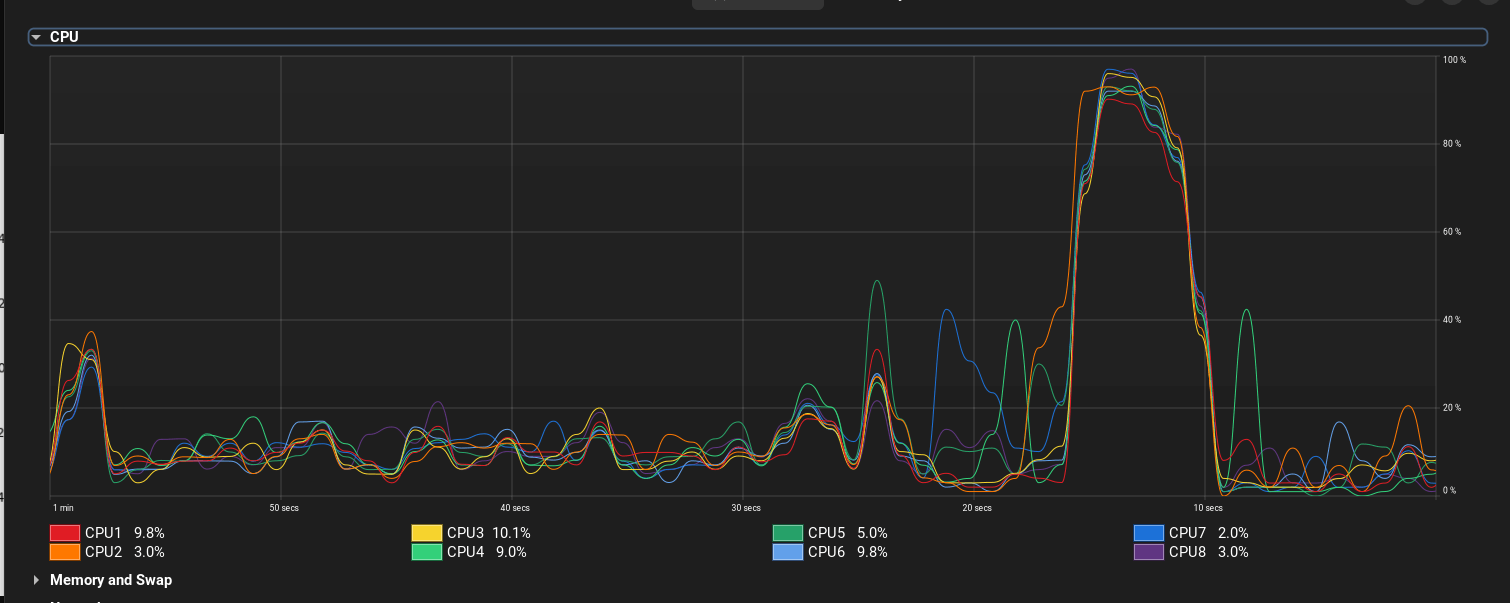
Randomly sending a large number of requests to a random location does not guarantee a significant load on the server. Even with a high frequency of requests, flooding can be inefficient.
A more effective approach is to identify weak points in the architecture. In this case, /hit2 writes data directly to the database, which makes it a bottleneck. Instead, /hit1 uses Celery, which allows it to withstand the load better and ensures more efficient server operation.
A script was created using Python that opens a large number of connections and keeps them active for as long as possible. This technique is similar to the Slowloris attack, which aims to exhaust server resources by keeping a large number of connections open.
To effectively load the server, you should consider several important points:
✔ Set the server timeout – find out how long the server keeps a connection open before forcibly closing it.
✔ Create connection groups – open a large number of connections and manage them in groups for more control.
✔ Send data in parts – to keep the connection alive, send fragments of the request a few seconds before the timeout expires.
✔ Find a “cheap” request – choose the request that has the least load on the client side, but takes a long time to process on the server.
This approach allows you to effectively overload the server, forcing it to spend significant resources on maintaining open connections.
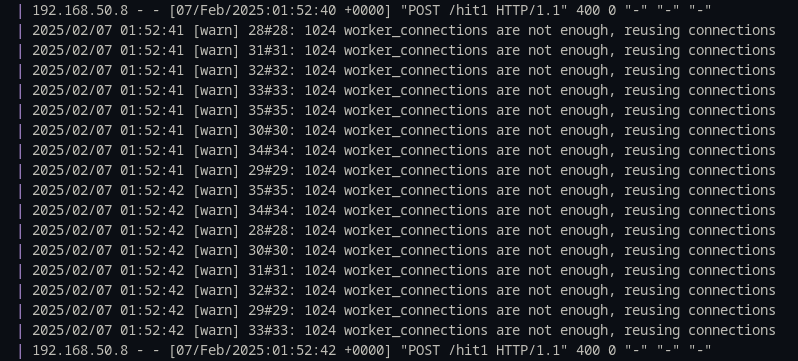
As a result, Nginx exhausted all available workers, which made it impossible to establish new connections.
Of course, Nginx could have been better configured, optimizing the configuration for greater resilience. However, a similar situation can occur on any server, especially if its settings were not adapted to protect against this type of attack or did not provide limits on the number of connections to be held.
HTTP flood DoS and DDoS attacks can be extremely effective, but it is important to not just randomly send requests, but first find a bottleneck in the server architecture. This could be an endpoint with frequent database writes or a resource-intensive operation that performs complex calculations.
This article was written to demonstrate methods for creating load on a server, including how to identify and exploit weaknesses in its architecture. By identifying which operations are consuming the most resources, you can more effectively conduct load attacks, using the fewest requests to achieve maximum impact.

