
За умов сучасного розвитку ШІ-інструментів відбувається все більше їх залучення до пентесту. Зокрема, подекуди звертаються до Claude Code, Grok, ChatGPT та решти моделей, які розгортаються на VPS, серверах компаній чи локально самими користувачами на власному або віртуальному залізі. Робиться це кожним пентестером окремо задля своїх потреб та задач. Про один із таких інструментів і піде мова. PentestGPT – це інструмент, який дозволяє пришвидшити вирішення складних задач.

Дисклеймер: Автор не несе відповідальності за дії користувача. Даний інструмент використовувався у дослідницьких цілях та мав виключно освітній характер. При використанні даного інструменту використовуйте віртуальну машину та VPN задля вашої безпеки у мережі.
Для використання необхідно мати встановлений дистрибутив Linux, як це зробити, детальна інструкція є на на нашому сайті. В моєму випадку це Kali Linux.
Так, як Pentest GPT має можливість локальної роботи, окрім роботи через API вже згаданих Claude Code та ChatGPT, саме для локальної роботи ми і встановимо Ollama.
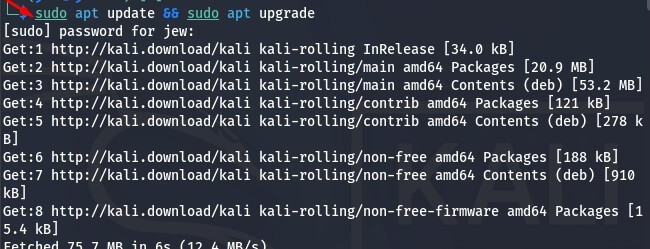
Відкриваємо термінал та встановлюємо Ollama, але спочатку необхідно оновити та встановити пакети командою:
sudo apt update && sudo apt upgrade
Цей процес може зайняти деякий час залежно від швидкості мережі та продуктивності заліза, ми просто чекаємо, доки завершиться цей процес.
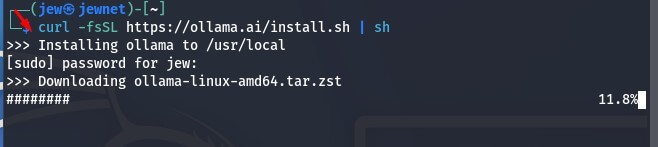
Тепер нам необхідно встановити Ollama, задля чого прописуємо у термінал команду. Вона є офіційною від розробників, адже класична sudo apt install ollama видасть помилку у терміналі.
Щоб не було помилок використовуємо офіційну команду:
curl -fsSL https://ollama.ai/install.sh | sh
Згодом, якщо встановлювати на віртуальну машину, як у статті, може з’явитися ось таке вікно з помилкою.
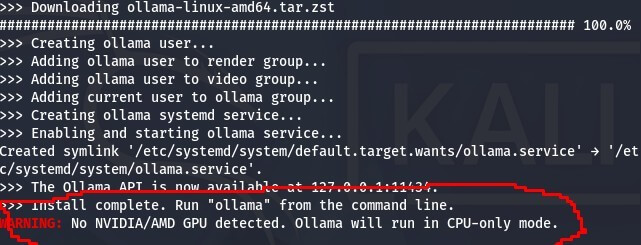
Але це не критично і все буде працювати, просто скрипт завантаження та встановлення не бачить підписів драйверів AMD або NVIDIA, адже ми на віртуальній машині, і це нормально. Усе буде коректно працювати, не хвилюємося та продовжуємо далі.
Тепер запускаємо локальний сервер Ollama у терміналі командою:
ollama serve
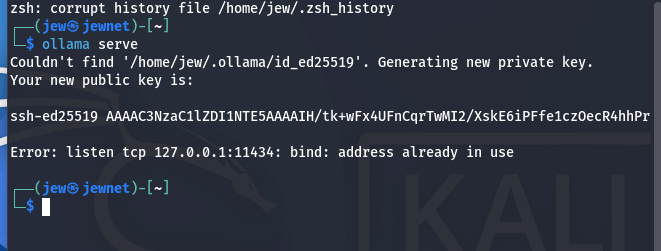
За замовчуванням він відкривається на 127.0.0.1:11434
Тепер встановлюємо модель, яка буде використовуватись у подальшому.
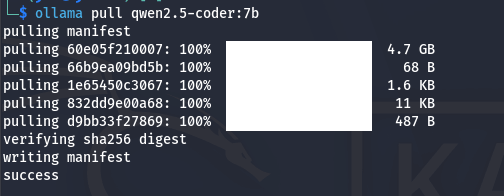
ollama pull qwen2.5-coder:7b
Розмір моделі 4.7 Гб. Враховуйте це при завантажені, за бажанням можно використовувати і іншу модель за вашим бажанням.

Як ми бачимо, ось воно вже встановилося.
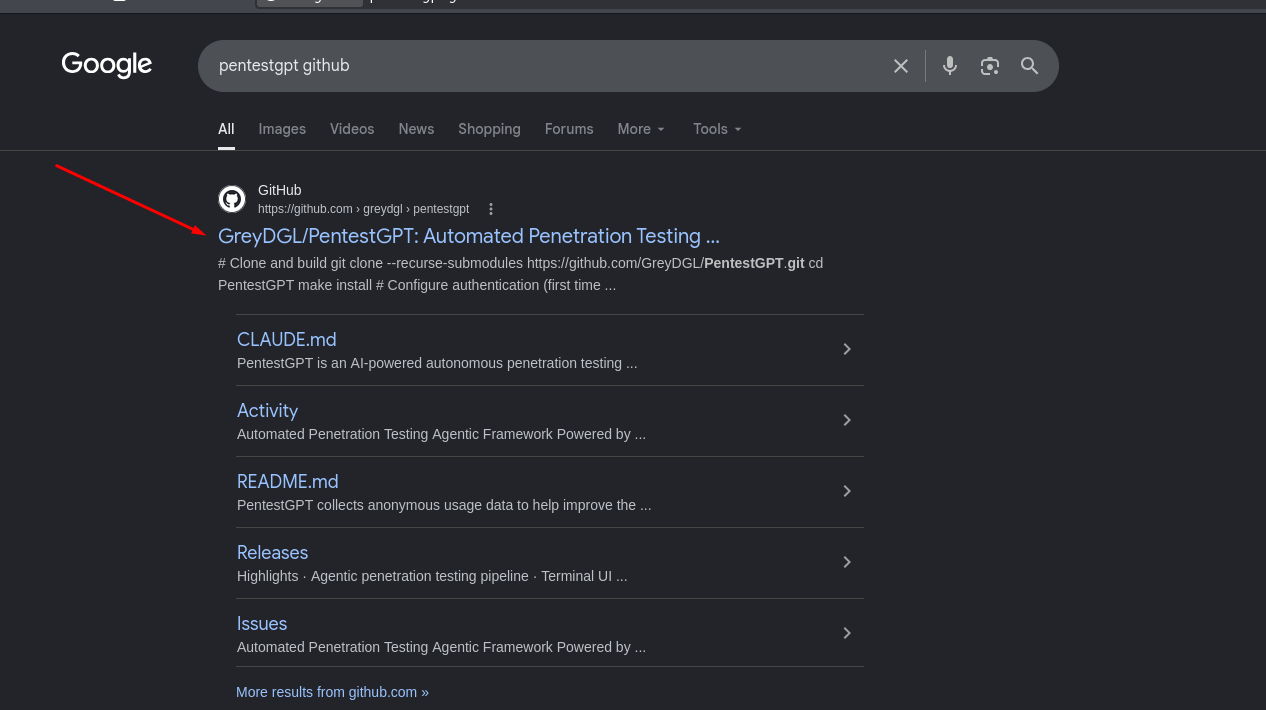
Тепер встановлюємо сам PentestGPT, у пошук вводимо Pentest GPT github, нам необхідно перше посилання:
Переходимо за посиланням та копіюємо позначене:
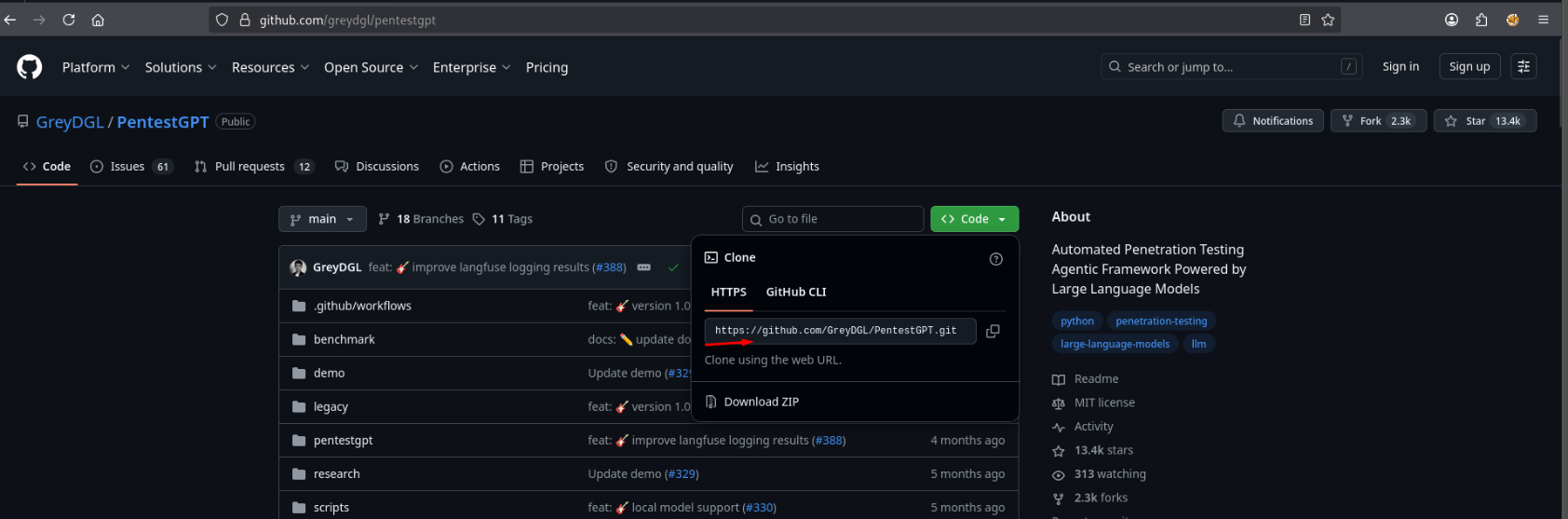
Тепер збираємо інструмент через Docker командою:
git clone --recurse-submodules https://github.com/GreyDGL/PentestGPT.git
Щоб це зробити, відкриваємо термінал, вводимо команду та чекаємо на такий результат:
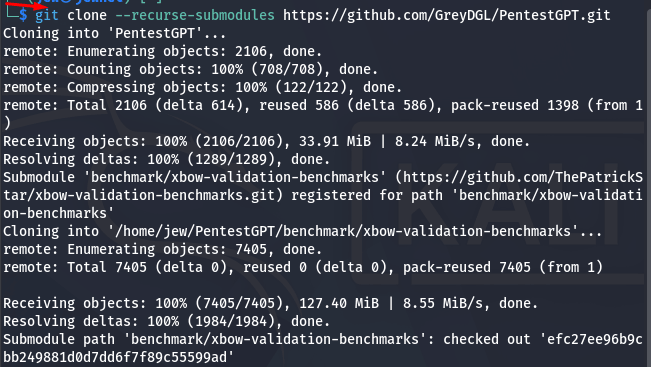
Тепер переходимо у папку PentestGPT, щоб зібрати Docker-контейнер та налаштувати конфігурацію. Робиться це командою:
cd PentestGPT
Спочатку збираємо контейнер командою:
make install
Подекуди можлива така помилка про відсутність менеджера пакетів uv для Python. Це виправляється однією командою:
curl -LsSf https://astral.sh/uv/install.sh | sh
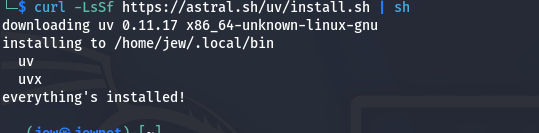
Тепер оновлюємо шляхи залежності у терміналі командою:
source ~/.zshrc
Тепер знову переходимо у папку cd PentestGPT та збираємо Docker контейнер командою:
make install
(Важливо: якщо помилок не виникло, дію, описану на скриншоті нижче, виконувати не потрібно. Якщо ж з’явилися помилки з кодами Error 1, Error 25 або Error 45, необхідно прибрати значення no-cache у файлі.)
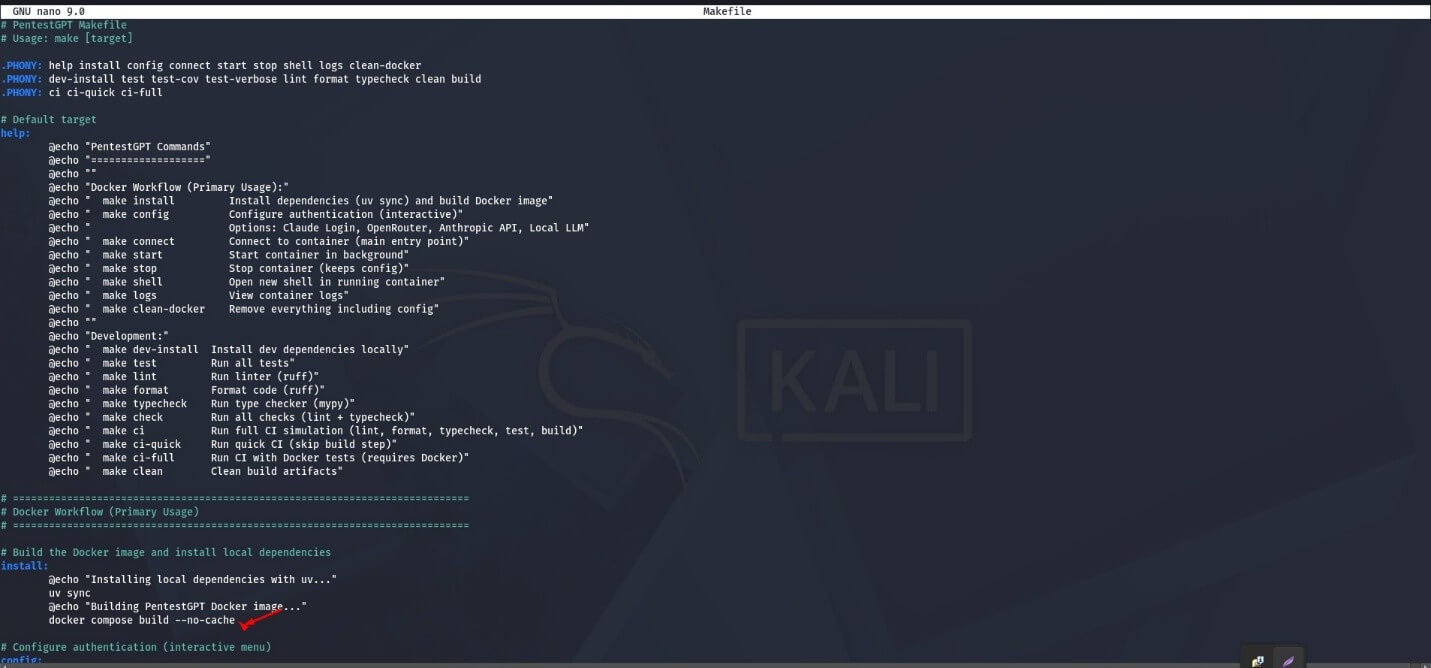
У файлі Makefile та повторити дії в такому порядку:
cd PentestGPT
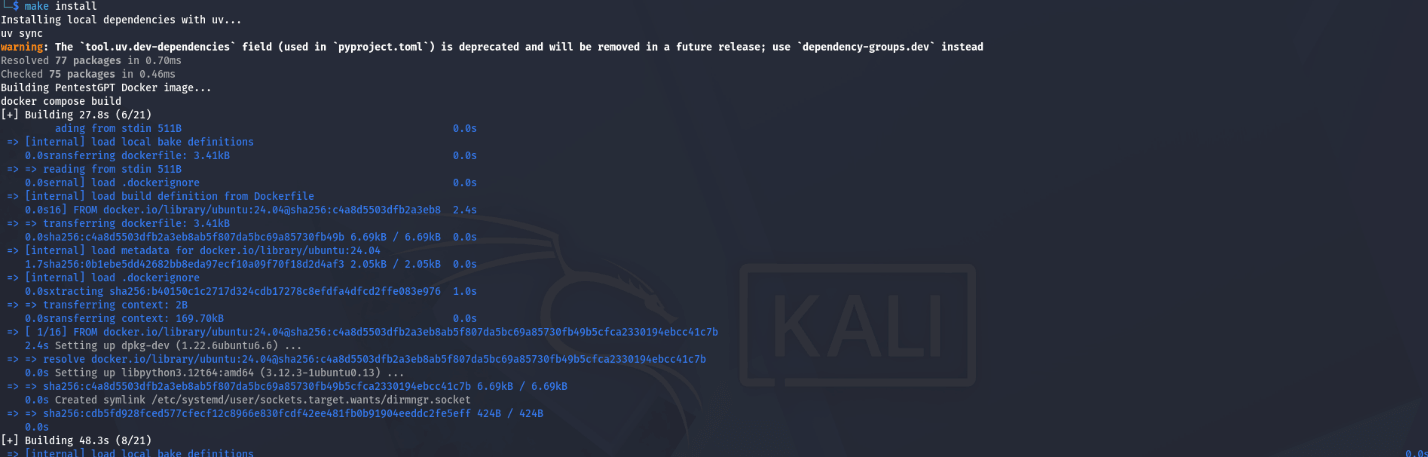
make install
І ось, нарешті, як бачимо, усе спрацювало. Тепер необхідно зачекати, поки завершиться процес встановлення та налаштування всіх компонентів.
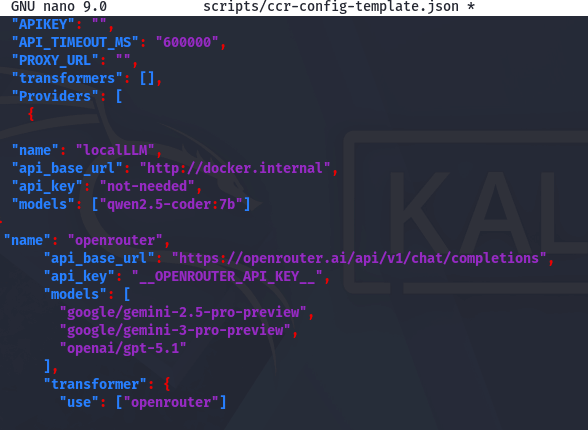
Тепер редагуємо файл config та встановлюємо такі значення:
nano scripts/ccr-config-template.json
{
"name": "localLLM",
"api_base_url": "http://docker.internal",
"api_key": "not-needed",
"models": ["qwen2.5-coder:7b"]
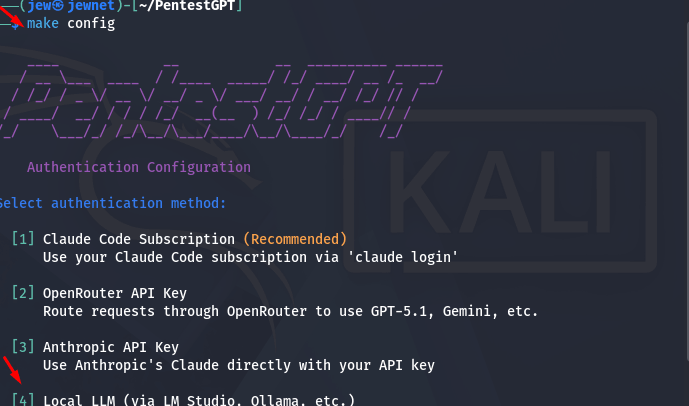
Необхідно обрати значення 4, як показано на скриншоті, щоб використовувалася саме локальна модель.
Обрали та запускаємо все що треба командою:
make connect
Або:
sudo make connect
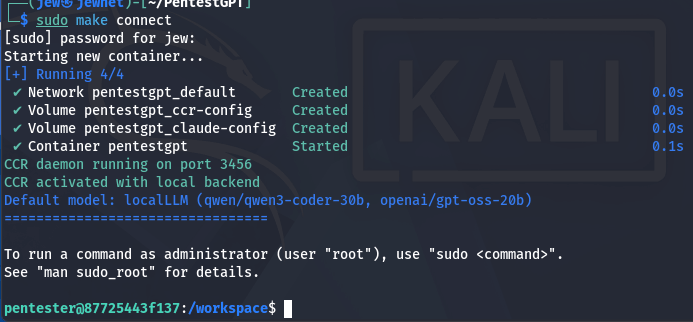
Наприкінці налаштування необхідно ввести команду, щоб використовувалася саме локальна модель.
pentestgpt --reasoning_model=localLLM --parsing_model=localLLM
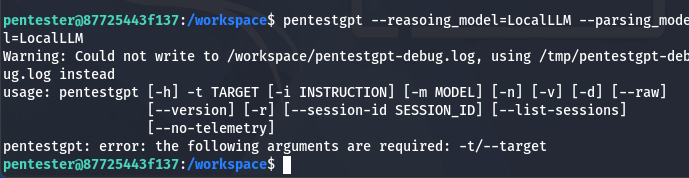
У підсумку цю команду необхідно вводити разом із ціллю. Для прикладу:
pentestgpt -t "http://127.0.0.1" -m "назва моделі ШІ яка використовується для пентесту"
Цей інструмент покращує процес пентесту для всіх, хто хоче навчитися або оптимізувати свою роботу. Це не панацея на всі можливі випадки, а лише один із багатьох інструментів, який може стати корисним у певних сценаріях.



Вау, клас!. Але от на Github’і проєкту інша інструкція встановлення. Чув, що ви навмисно так робите, щоб тупо не копіпастили команди. Респект.
Слава Україні. РуZZні 3.14зда!
замість qwen – глючного китайського лайна можете поритись на huggingface та підшукати собі якусь хоча б трохи менш цензуровану модельку, а так прікольно