
08.01.2026
2 хв
657

Bash стає справді зручним тоді, коли ви починаєте працювати з даними усвідомлено. У цьому матеріалі зібрані дві теми, без яких важко рухатися далі. Як передавати значення у скрипти та як зберігати кілька даних одночасно.
Текст написаний для тих, хто вже знайомий з основами Bash і хоче краще розуміти, як скрипти приймають інформацію та що з нею роблять. Тут немає складних формулювань або перевантаження термінами. Лише логіка, приклади та відчуття, як усе це працює на практиці.
Матеріал буде корисний тим, хто використовує Bash для автоматизації, адміністрування або власних невеликих інструментів. Він допоможе писати скрипти, які легко читати, змінювати й доповнювати без хаосу.

У другій частині ми розглянемо, як передавати аргументи в Bash-скрипти. Також познайомимося зі спеціальними змінними Bash і зрозуміємо, як вони працюють у реальних сценаріях.

До цього моменту ви вже навчилися використовувати змінні, щоб робити Bash-скрипти гнучкими та універсальними. Завдяки цьому вони можуть працювати з різними даними й по-різному реагувати на введення користувача. У цьому уроці ви дізнаєтеся, як передавати змінні в Bash-скрипт безпосередньо з командного рядка.
Наступний скрипт count_lines.sh виводить загальну кількість рядків у файлі, який указує користувач.
#!/bin/bash echo -n "Please enter a filename: " read filename nlines=$(wc -l < $filename) echo "There are $nlines lines in $filename"
Наприклад, користувач може вказати файл /etc/passwd, і скрипт у відповідь виведе кількість рядків у цьому файлі:

Цей скрипт працює нормально, але є значно кращий варіант.
Замість того щоб запитувати в користувача назву файлу, можна зробити простіше. Користувач просто передає ім’я файлу як аргумент під час запуску скрипта, наприклад так:
./count_lines.sh /etc/passwd
Перший аргумент Bash, який ще називають позиційним параметром, доступний усередині скрипта через змінну $1.
Тому в скрипті count_lines.sh змінну з назвою файлу можна замінити на $1 ось таким чином:
#!/bin/bash nlines=$(wc -l < $1) echo "There are $nlines lines in $1"
Зверніть увагу, що команду read і перший echo було прибрано, оскільки вони більше не потрібні.
Тепер скрипт можна запустити й передати будь-який файл як аргумент:
./count_lines.sh /etc/group There are 73 lines in /etc/group
У Bash-скрипт можна передавати більше ніж один аргумент. Загалом синтаксис передачі кількох аргументів для будь-якого Bash-скрипта виглядає так:
script.sh arg1 arg2 arg3 …
Другий аргумент доступний через змінну $2, третій аргумент через $3 і так далі. Змінна $0 містить назву Bash-скрипта, якщо раптом було цікаво. Тепер можна змінити Bash-скрипт count_lines.sh так, щоб він рахував кількість рядків одразу в кількох файлах:
#!/bin/bash n1=$(wc -l < $1) n2=$(wc -l < $2) n3=$(wc -l < $3) echo "There are $n1 lines in $1" echo "There are $n2 lines in $2" echo "There are $n3 lines in $3"

Як видно, скрипт виводить кількість рядків для кожного з трьох файлів. І, звісно, порядок аргументів має значення.
У Linux існує дуже багато команд. Деякі з них досить складні, адже можуть мати довгий синтаксис або велику кількість параметрів. На щастя, за допомогою аргументів Bash можна перетворити складну команду на просте й зручне завдання. Для прикладу подивіться на наступний Bash-скрипт find.sh:
#!/bin/bash find / -iname $1 2> /dev/null
Це дуже простий скрипт, який водночас може бути справді корисним. Достатньо передати будь-яку назву файлу як аргумент, і він покаже, де саме знаходиться цей файл:

Бачите, наскільки це простіше, ніж вводити повну команду find. Це наочний приклад того, як за допомогою аргументів можна перетворити довгу й складну команду Linux на простий Bash-скрипт.
Якщо виникло питання щодо 2> /dev/null, це означає, що повідомлення про помилки (наприклад, коли файл недоступний) не виводитимуться на екран. Щоб краще розібратися в цій темі, варто почитати про перенаправлення stderr у Linux та про /dev/null.
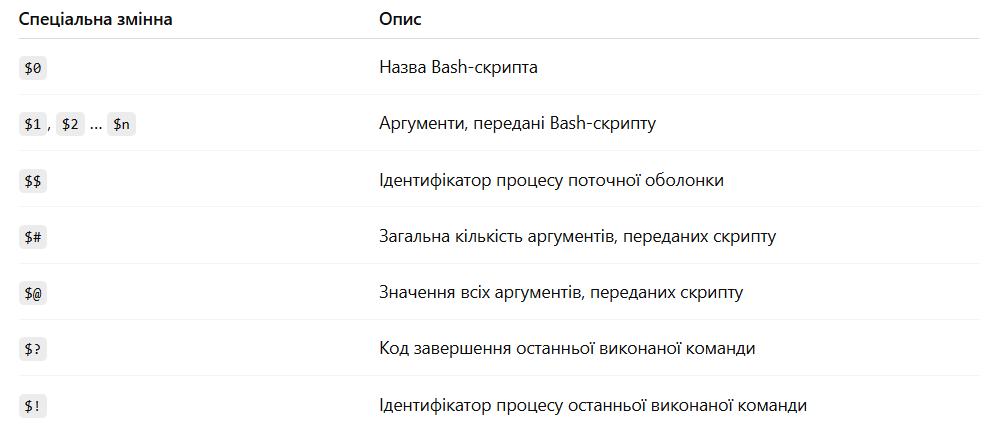
Bash має багато вбудованих спеціальних змінних, які можуть бути дуже корисними й доступні для використання одразу.
У таблиці нижче наведені найпоширеніші вбудовані спеціальні змінні Bash:
Щоб побачити ці спеціальні змінні в роботі, подивіться на наступний Bash-скрипт variables.sh:
#!/bin/bash echo "Name of the script: $0" echo "Total number of arguments: $#" echo "Values of all the arguments: $@"
Тепер можна передати будь-які аргументи й запустити скрипт:

Якщо хочеться трохи практики, завантажте цей PDF і потренуйтеся передавати аргументи в Bash-скрипти на простих завданнях. Рішення до них також додаються.
Забагато змінних і вже складно з ними працювати? Скористайтеся масивом у своєму Bash-скрипті.

Поки що у своїх Bash-скриптах ви використовували обмежену кількість змінних. Зазвичай це були кілька змінних для зберігання одного чи двох імен файлів або користувачів.
Але що робити, якщо змінних потрібно значно більше? Наприклад, ви хочете написати Bash-скрипт, який зчитує сотню різних значень від користувача. Невже доведеться створювати 100 окремих змінних?
На щастя, ні. Масиви пропонують набагато зручніше рішення.
Уявімо, що потрібно створити Bash-скрипт timestamp.sh, який оновлює часову мітку для п’яти різних файлів.
Для початку розглянемо наївний підхід і використаємо п’ять окремих змінних:
#!/bin/bash file1="f1.txt" file2="f2.txt" file3="f3.txt" file4="f4.txt" file5="f5.txt" touch $file1 touch $file2 touch $file3 touch $file4 touch $file5
Тепер замість того, щоб використовувати п’ять змінних для зберігання назв п’яти файлів, можна створити один масив, у якому будуть зберігатися всі ці імена. Ось загальний синтаксис масиву в Bash:
array_name=(value1 value2 value3 … )
Тепер можна створити масив з назвою files, у якому зберігатимуться всі п’ять назв файлів, що використовуються в скрипті timestamp.sh, ось так:
files=("f1.txt" "f2.txt" "f3.txt" "f4.txt" "f5.txt")
Як бачите, це набагато охайніше й ефективніше, адже п’ять змінних замінено всього одним масивом.
Перший елемент масиву має індекс 0, тому для доступу до n-го елемента використовується індекс n - 1. Наприклад, щоб вивести значення другого елемента масиву files, можна скористатися такою командою echo:
echo ${files[1]}
А щоб вивести значення третього елемента масиву files, можна використати:
echo ${files[2]}
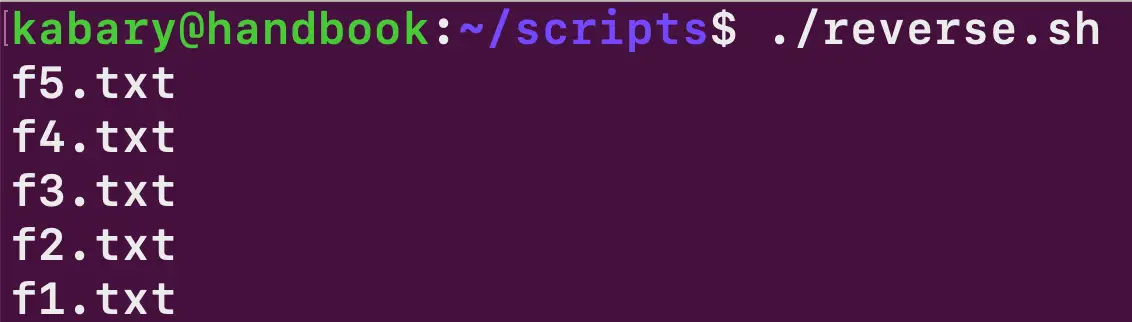
І так далі. Наступний Bash-скрипт reverse.sh виводить усі п’ять значень з масиву files у зворотному порядку, починаючи з останнього елемента масиву:
#!/bin/bash
files=("f1.txt" "f2.txt" "f3.txt" "f4.txt" "f5.txt")
echo ${files[4]}
echo ${files[3]}
echo ${files[2]}
echo ${files[1]}
echo ${files[0]}
Можливо, виникає питання, чому тут так багато команд echo і чому не використовується цикл. Причина в тому, що знайомство з циклами в Bash планується пізніше в цій серії.
Також можна вивести всі елементи масиву одразу:
echo ${files[*]}
f1.txt f2.txt f3.txt f4.txt f5.txt
Також можна вивести загальну кількість елементів у масиві files, тобто розмір масиву:
echo ${#files[@]}
5
Також можна змінювати значення будь-якого елемента масиву. Наприклад, значення першого елемента масиву files можна змінити на a.txt за допомогою такого присвоєння:
files[0]="a.txt"
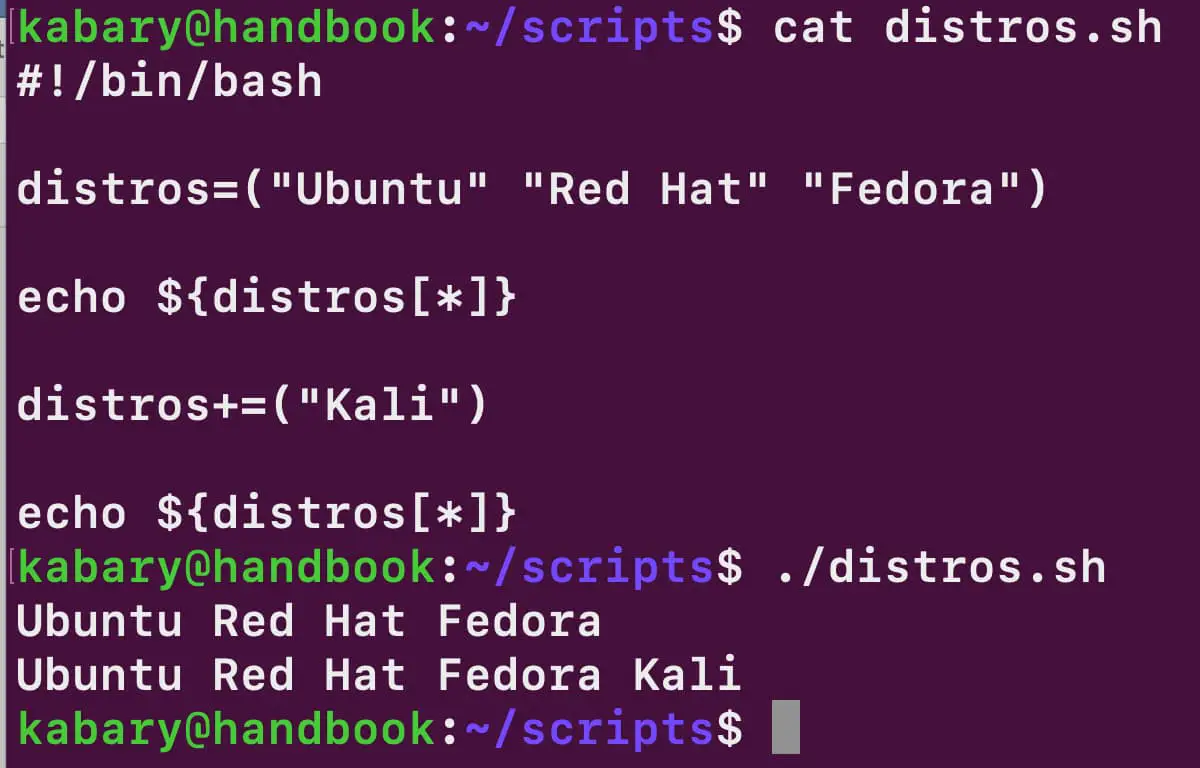
Створімо масив, у якому зберігатимуться назви популярних дистрибутивів Linux:
distros=("Ubuntu" "Red Hat" "Fedora")
Наразі масив distros містить три елементи. Для додавання нового елемента в кінець масиву можна використати оператор +=.
Наприклад, так можна додати Kali до масиву distros:
distros+=("Kali")
Тепер масив distros містить уже чотири елементи, і Kali є останнім елементом цього масиву.
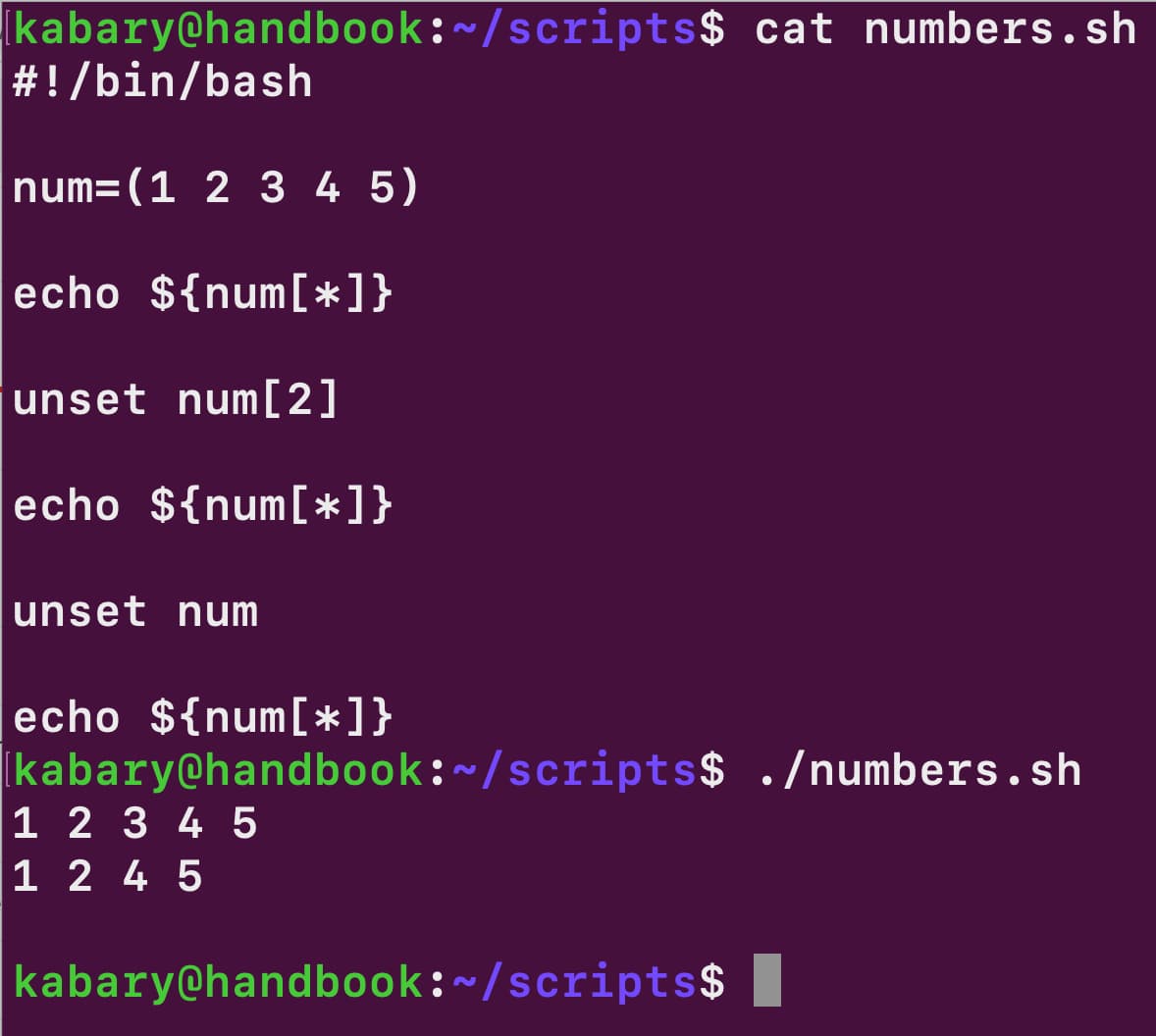
Для початку створімо масив num, у якому зберігатимуться числа від 1 до 5:
num=(1 2 3 4 5)
Можна вивести всі значення масиву num:
echo ${num[*]}
1 2 3 4 5
Третій елемент масиву num можна видалити за допомогою вбудованої команди оболонки unset:
unset num[2]
Тепер, якщо знову вивести всі значення масиву num, можна побачити результат:
echo ${num[*]}
1 2 4 5
Як видно, третій елемент масиву num було видалено.
Таким самим способом можна видалити й увесь масив num:
unset num
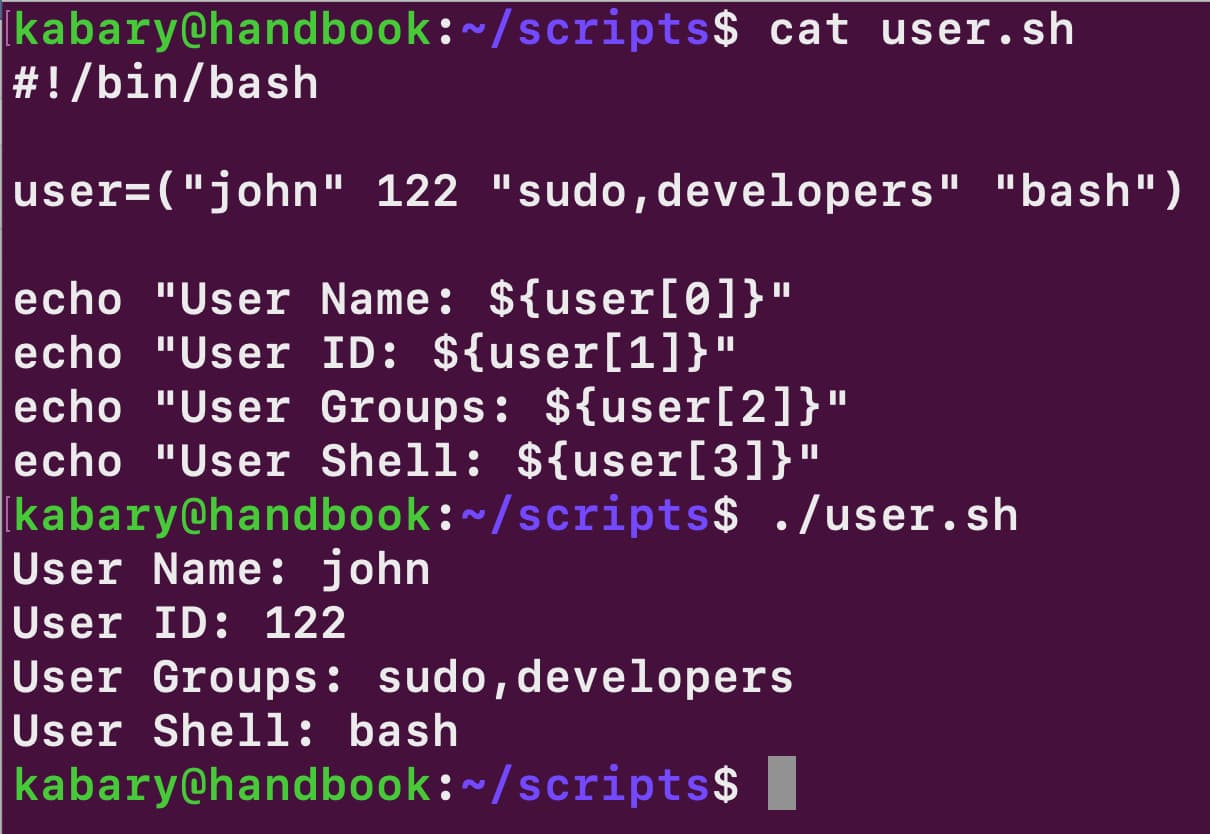
У Bash, на відміну від багатьох інших мов програмування, можна створювати масиви, які містять різні типи даних одночасно. Подивіться на наступний Bash-скрипт user.sh:
#!/bin/bash
user=("john" 122 "sudo,developers" "bash")
echo "User Name: ${user[0]}"
echo "User ID: ${user[1]}"
echo "User Groups: ${user[2]}"
echo "User Shell: ${user[3]}"
Якщо хочеться чогось складнішого та ближчого до реальних задач, зверніть увагу на приклад із розділенням рядків у Bash за допомогою масивів.
І, звісно, можна закріпити вивчене на практиці, розв’язуючи завдання та підглядаючи в рішення, якщо щось не виходить або потрібна підказка.

