
У другій частині посібника з впровадження Zero Trust розглядаємо, як побудувати єдиний проксі-шар для захисту адмінок, впровадити mTLS і авторизацію через OIDC, а також контролювати доступ залежно від стану пристрою. Пояснюємо, як працює система прийняття рішень (СПР), інтегрується osquery та EDR, реалізується кешування й логіка реального часу. Стаття допоможе DevOps, сисадмінам і безпековим командам налаштувати динамічний доступ, побудувати архітектуру з проксі та виявляти скомпрометовані пристрої ще до того, як вони відкриють адмінку. Це — фундаментальний крок у побудові надійної Zero Trust-інфраструктури.

Згадаймо основну ідею ZT щодо захисту адмінок – в адмінку можна потрапити лише надавши сертифікат, що лежить у захищеному сховищі на пристрої. Це означає, що поверхня атаки сильно знижується і становить а) кінцеві пристрої; б) міжмашинні взаємодії (коли один сервіс стукає в апі іншого сервісу).
Виходить, для того, щоб зловмиснику отримати доступ до даних адмінки, найпростіше зламати ноутбук співробітника.
На початковому етапі ми повинні дотриматися щонайменше:
Базові вимоги до налаштування ОС
Встановлення та працездатність агентів
Пишемо вимоги до налаштування ОС. Фіксуємо в них необхідність локскрину, шифрування диска, відключення непотрібних сервісів тощо. Статус виконання цих вимог перевіряємо за допомогою агента на пристрої. Найпростіший варіант – osquery. Osquery дозволить нам постійно відстежувати статус захищеності наших пристроїв. Також він легко інтегрується з SIEM для потенційного збагачення даними.
Крім osquery нам потрібний якийсь агент, який збирає логи з пристрою, в ідеалі EDR агент. Це дозволить детектувати атаки на пристрій і оперативно реагувати на них, у тому числі відключати скомпрометованому пристрою доступи до адмінок.
Поверх базового мінімуму можна докручувати будь-які свої контролі, головне – забезпечити доставку статусів за цими контролами в єдине місце, де ми бачитимемо загальний статус захищеності нашого парку пристроїв.
Розглянемо докладніше, як пов’язана захищеність пристроїв та доступ до даних. Ось ми розкотили osquery, встановили EDR, складаємо логи в SIEM. Нам залишається написати сервіс, назвати його “Системою Прийняття Рішень” (СПР), в якому відбуватиметься основна логіка. У ньому містяться вимоги щодо доступу до адмінок, які будуть зіставлятися з поточним статусом пристрою.
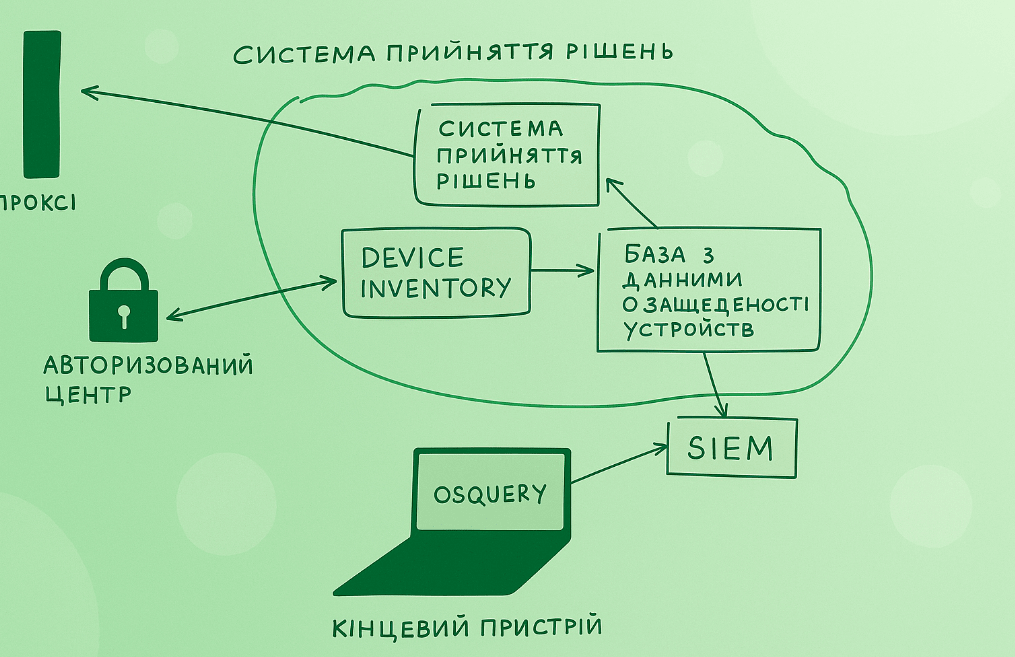
Схема роботи буде виглядати так – кожен HTTP запит від кінцевого пристрою приходить на проксі, проксі своєю чергою запитує у СПР чи можна пускати цей пристрій. У будь-який момент часу статус пристрою може змінитись – наприклад, з’явилося нове RCE у браузері, а оновлення ще не встановлені. У цей момент СПР змінює статус пристрою на незахищений, і користувачеві замість даних в адмінці показується заглушка, що повідомляє про необхідність оновитись. Після оновлення дані через osquery досягнуть СПР, і статус пристрою знову зміниться на зелений. Для різних адмінок можна виставити різні вимоги – до некритичних, наприклад, пускати навіть неоновлені пристрої, особливо критичним – додати додаткові вимоги.
Як можна бачити зі схеми Device inventory та База з даними про захищеність пристроїв рознесені. Зроблено це тому, що найчастіше система інвентаризації пристроїв погано розширюється або повільно адаптується під динамічні вимоги щодо функціоналу. Тому для швидкості розробки можна розгорнути свою систему, в яку дані про інвентаризацію будуть синхронізуватися з єдиної Device inventory, а вже статус виконання вимог – з osquery та інших агентів.
Завдання щодо інвентаризації та агентів – складний та трудомісткий процес, який розумно виділити в окремий проект та передати окремим людям. Також у цьому завдання важливі комунікації – потрібно максимально широко сповіщати користувачів про впровадження нових технологій та необхідність дотримання вимог. Особливу увагу слід приділити домовленостям із керівниками, отриманню від них схвалення та підтримки. Ці заходи значно знижать тертя при переході на нову схему доступу і допоможуть підвищенню загальної захищеності парку пристроїв.
Вище ми обговорили завдання-мінімум щодо побудови захищеного парку пристроїв та інтеграції його до Zerotrust. Як факультатив хочу поділитися додатковими заходами, які виведуть захищеність ноутбуків і, частково, користувачів, на новий рівень.
Виділені люди повинні постійно моніторити нові вектори атак та перевіряти їх на практиці. Нові засоби доставки, закріплення, підходи до соціальної інженерії – все це повинно проводитися регулярно, і спільно з командою Security Operations Centre потрібно оцінювати які з векторів були помічені, а які ні. За всіма пропущеними векторами потрібно вибудовувати контролі, ці контролі повинні валідуватися.
Найчастіше Red Teaming знаходить вектори, які погано або взагалі не детектуються доступними засобами захисту. Для вирішення цієї проблеми необхідно або а) дописувати конкретні правила моніторингу, якщо це можливо; б) створювати власний софт, або брати опенсорсний.
Приклади завдань, які погано детектуються антивірусами, але регулярно використовуються в атаках:
Додавання ключа ssh в authorized keys
Запуск бінар з флешки.
Більшість методів закріплення на macOS
Для завдань вище є готові рішення, або не так складно написати своїх маленьких демонів.
Зрозуміло, що тема захисту пристроїв значно ширша, але оскільки вектор атаки через компрометацію ноутбука для нас є дуже важливим, необхідність уваги до цієї теми важко переоцінити.
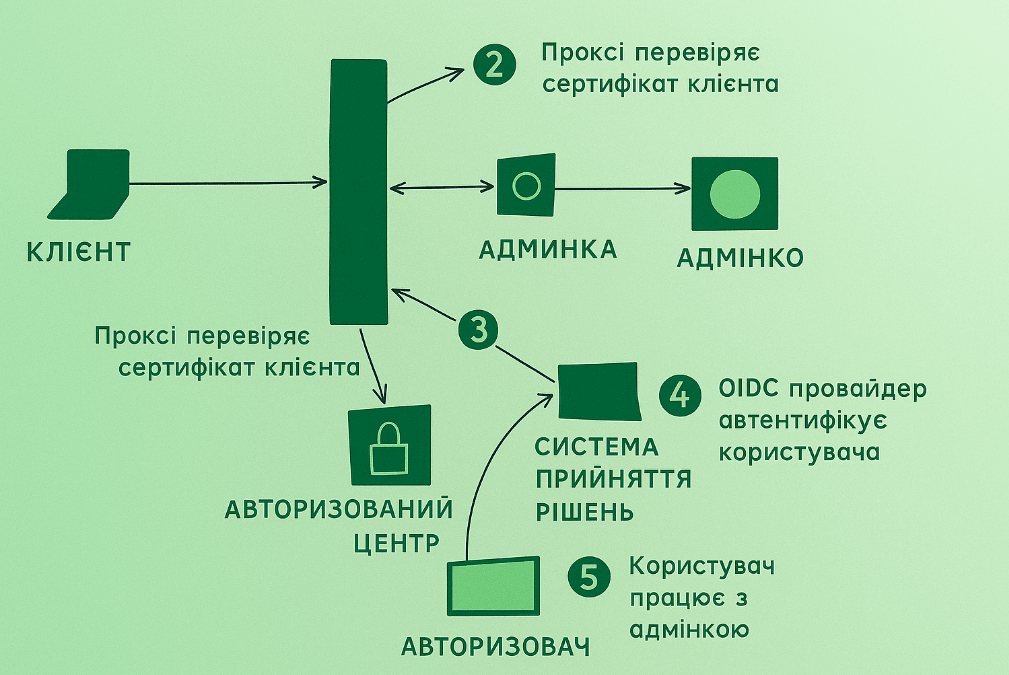
Ключовою ланкою zt є проксі. Саме з нею взаємодіють усі клієнти, від неї вони отримують вердикт – пустять їх до адмінки чи ні.
Що має вміти проксі насамперед:
Встановлювати mTLS з’єднання з клієнтом
Коректно проксувати запити від клієнта в сервіс, що захищається, і назад
Працювати з іншими сервісами – Certification Authority та його middleware, OIDС, системою прийняття рішень (яка приймає рішення пускати/не пускати)
Схема роботи виходить така:
Що має вміти проксі в другу чергу:
Працювати не лише з HTTP протоколом
У режимі реального часу розривати з’єднання
Підтримувати гранулярне налаштування доступу per route для HTTP. Наприклад на /admin пускати лише певних користувачів.
Забезпечувати підтримку machine-2-machine взаємодії
Мати breaking glass механізм
Подивимося, чи є готові рішення для цих завдань, що потрібно допилювати самим, і подумаємо, що нам потрібно зробити в період MVP період.
Першим критерієм для вибору є відкриті джерела. Готові вендорські рішення не підходять – у них дуже специфічні вимоги, продукти сирі, вендор завжди біжить повільніше, ніж ти. При виборі опенсорс орієнтуємося на стек, оскільки рішення плануємо підтримувати, дописувати та переписувати.
Другий критерій – відповідність нашим вимогам до функціоналу.
З більш-менш готових рішень можна виділити: ORY, Pomerium, Teleport. Кожен може оцінити, що йому ближче. Потрібно просто відразу прийняти, що на другий рік експлуатації все доведеться поміняти та переписати.
Загалом досить нескладне завдання, деякі рішення вміють із коробки, деякі доведеться дописати.
Оскільки наша проксі стоїть урозріз, до неї висуваються високі вимоги до стабільності. Також велику увагу потрібно приділити процесу перевезення адмінок за нашу проксі. Розбремо на прикладі:
Існуюча адмінка використовує самописну систему авторизації та аутентифікації користувачів. Користувач йде в самописну систему, авторизується в ній, вона ставить йому HTTP заголовки та куки, після чого адмінка користувача пропускає. При перевезенні на єдину OIDC це створює проблему – адмінка чекає на певні заголовки від користувача, інакше його просто не пустить.
Тому нам необхідно реалізувати доробки на нашому єдиному OIDC і на нашому проксі, щоб вони прокидали ті заголовки, на які адмінка чекає. Можливо, з боку адмінки також знадобляться доопрацювання, але нам потрібно звести їх до мінімуму. Це дуже важливий момент – чим легше ресурсу переїхати на zt, тим швидше та простіше пройде переїзд інших ресурсів, а згодом і всієї компанії. В ідеалі ми маємо зробити схему зручнішою, ніж вона була. Користувачі отримають зручність у доступі та роботі, а ми отримаємо більш безпечну та технічно зрілу інфраструктуру.

Взаємодія з CA реалізується в рамках задачі по mTLS з’єднанню, з нею складнощів виникнути не повинно.
З OIDC також – після перевірки пристрою ми повинні редагувати користувача на сторінку введення його логіна та пароля/другого фактора, після чого коректно це обробляти та зберігати його сесію.
Взаємодія із Системою прийняття рішень. У СПР ми закладемо функціонал аналізу ступеня захищеності пристрою, установки до них вимогам і управління цими сутностями. На ній зупинимося докладніше в наступних матеріалах, головне що відзначимо для себе тут – СПР має мати API, за яким проксі його опитуватиме, а сама проксі повинна підтримувати механізм кешування, щоб на кожен запит користувача не смикати СПР. Зазначу, що в рамках MVP ми тільки проектуємо цю частину, саме рішення “пускати/не пускати” поки що прийматиметься на рівні наявності та довіри сертифікату.
Навіть у процесі MVP після підключення кількох адмінок у нас вже буде зростати і множитися список функцій, які нам знадобляться. Перерахую та прокоментую деякі з них:
Підтримка не-HTTP протоколів. Було б круто, якби ми ходили адмінити наші сервери по ssh з zt функціоналом – перевірка пристрою, єдина зручна авторизація тощо.
Розрив з’єднання в реальному часі При інциденті або виході нового 0day у Chrome ми хочемо знижувати рівень довіри пристроїв та розривати їхнє з’єднання з адмінками.
Гранулярне налаштування маршрутів усередині програми дозволить нам швидко та зручно підключати legacy адмінки та на рівні zt контролювати доступ до чутливого функціоналу всередині них.
Machine-2-machine. Це очевидна і дуже важлива річ – майже в будь-яку адмінку ходять не тільки люди, а й інші сервіси, і їх також треба якось перевіряти та авторизувати. Тема сильно перетинається із проблемою міжсервісної аутентифікації, інтегрувати ці дві технології в одну – складне та цікаве завдання.
Breaking glass. У деяких випадках ми все-таки пускати non-compliant клієнтів до наших ресурсів. А в деяких ситуаціях наша zt інфраструктура може дати збій, і нам потрібно дати можливість користувачам продовжити роботу під час збою.
Проксі – сервіс, що постійно зростає і змінюється. Важливо визначити собі, що хочемо насамперед, реалізувати це, забезпечити надійність, та був продовжити розвиток.
У вас скільки класного, усілякого добра, що потрібно ще одне життя ))