
Складовий файл (структуроване сховище) – файл містить у собі певну подобу файлової системи. Сам головний файл є звичайним файлом, має всі властивості файлу (тобто копіюється, видаляється, перейменовується тощо). Усередині є каталоги, які називаються сховищами, є файли звані потоками. До уваги файли .doc (MSWord), .xls (MSExcel) та ін є складовими файлами. Роботу з таким різновидом файлів забезпечує інтерфейси IStorage, IStream. У таких файлах можна і зручно зберігати будь-яку інформацію, систематизувати її за групами. Доступ до даних такого сховища здійснюється обрано, не завантажуючи весь файл на згадку. Поширена практика приховування вірусів – впровадження в складові файли: архіви, бази даних тощо. буд. Щоб виявити віруси, приховані таким чином, складовий файл необхідно розпакувати, що може призвести до значного зниження швидкості перевірки. Для кожного типу складеного файлу ви можете вибрати, чи слід перевіряти всі файли чи тільки нові.

Для вибору перейдіть за посиланням, розташованим поруч із назвою об’єкта. Вона змінює своє значення при натисканні на неї лівою кнопкою миші. Якщо встановлено режим перевірки лише нових та змінених файлів, посилання на вибір перевірки всіх або лише нових файлів будуть недоступні. Під час перевірки складених файлів великого розміру їх попереднє розпакування може тривати багато часу. Цей час можна скоротити, увімкнувши розпакування складених файлів, що перевищують заданий розмір, у фоновому режимі. Якщо під час роботи з таким файлом буде виявлено шкідливий об’єкт, Kaspersky Internet Security повідомить вас про це. Ви можете обмежити максимальний розмір складеного файлу. Складові файли, розмір яких перевищує задане значення, не перевірятимуться.
Натиснувши на кнопку, ви зможете ознайомитися з статтєю на цю тему про “Уразливості завантаження файлів”.

Багато файлів є об’єднання декількох файлів. Наприклад, файли офісних документів .docx та .odt. Ви можете замінити розширення таких файлів на .zip, відкрити будь-яким архіватором і переконатися, що насправді це просто контейнери, що містять безліч файлів. Наприклад, якщо ви вставили картинку в документ Word, то щоб витягти цю картинку, необов’язково відкривати файл в офісному редакторі – можна змінити розширення, розпакувати архів і з нього забрати свою картинку назад. Майже всі прошивки (для роутерів, IP камер, телефонів) це контейнери. ISO образи та образи файлових систем також контейнери. Архіви, як можна здогадатися, також містять відразу кілька файлів.
З практичної точки зору та з точки зору пошуку файлів можна виділити два способи об’єднати файли:
Приклад такого об’єднання файлів – це файлові системи без шифрування і без стиснення. Наприклад, EXT4, NTFS — у яких файли розміщені у своєму початковому вигляді. Відповідно, образи таких файлових систем також належать до цієї групи. Сюди можна віднести деякі прошивки, наприклад, для роутерів і IP камер. Зрозуміло, що в таких великих файлах (образах) можна знайти файли, що зберігаються. Більше того, файли, що зберігаються, можна витягти і зберегти у вигляді самостійного файлу, який буде ідентичний вихідному.
Приклади такого способу об’єднання файлів – це файлові системи з шифруванням або стисненням (наприклад, Squashfs), архіви зі стисненням. Для пошуку окремих файлів за їх сигнатурами необхідно виконати зворотну дію, тобто якщо файл був стиснутий, його необхідно розархівувати. Якщо це файлова система зі стисненням, необхідно її змонтувати. З практичної точки зору це означає, що марно шукати файли по сигнатурах в архівах, поки ці архіви не розпаковані (АЛЕ: деякі програми аналізу сирих даних підтримують роботу з архівами!). Марно шукати файли за сигнатурами у файловій системі Squashfs до її монтування. При цьому можна застосовувати пошук по сигнатурах EXT4 і NTFS і їх монтування не потрібно!
Монтування, наприклад, образу NTFS дасть нам таке: ми зможемо отримувати доступ до файлів цієї файлової системи тим способом, яким це передбачили розробники, тобто побачимо список файлів і зможемо отримати доступ до будь-якого з них без необхідності шукати файли по сигнатурах. Але при цьому ми не зможемо отримати або навіть дізнатися про вже видалені файли. Без монтування образу NTFS ми зможемо працювати з файлами, що зберігаються безпосередньо, тобто з одного боку нам доведеться шукати файли по сигнатурам, але з іншого боку ми отримаємо доступ навіть до віддалених файлів. Видалені файли доступні в результаті того, що зазвичай видалення на HDD полягає в тому, що інформація про файл просто видаляється з журналу файлової системи, але сам файл залишається там же, де і був (якщо його згодом випадково не перезаписали іншим файлом). Що стосується SSD, то там зазвичай дані все-таки видаляються. Нічого не заважає комбінувати ці способи, причому криміналістичні інструменти дозволяють зробити пошук віддалених даних ефективнішим, наприклад, пошук видалених файлів виконується тільки на тих частинах диска, які вважаються порожніми.
Розглянемо приклад розпакування прошивки камери Network Surveillance DVR r80x20-pq (цю камеру я використав у тестах, наприклад, у статті «Аудит безпеки IP камер».
Завантажуємо та розпаковуємо архів. Він називається General_IPC_XM530_R80X20 PQ_WIFIXM711.711.Nat.dss.OnvifS_V5.00.R02.20210818_all.bin, для стислості наступних команд я перейменую його в firmware.bin.
Перевіримо, що це за файл:
![]()
Висновок наступний:

Тобто це архів Zip. Перевіримо за допомогою Detect It Easy:
![]()
Також скористаємося утилітою Binwalk, яка спеціально призначена для аналізу прошивок:
![]()
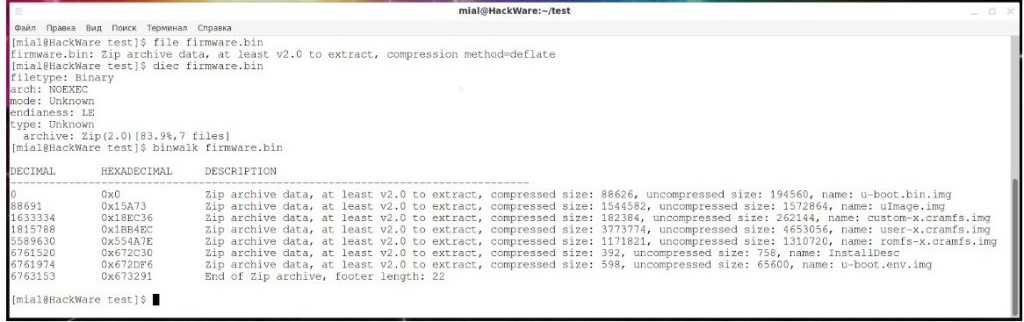
Оскільки це просто архів, розпакуємо його:
![]()
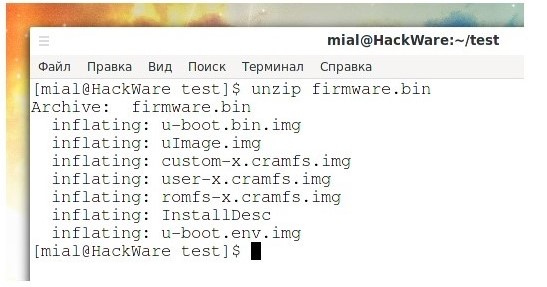
u-boot.bin.img
uImage.img
custom-x.cramfs.img
user-x.cramfs.img
romfs-x.cramfs.img
u-boot.env.img
Поцікавимося файлом user-x.cramfs.img:
![]()
Висновок:
![]()
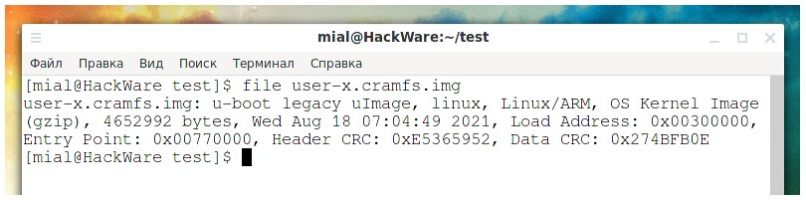
U-Boot – це завантажувач для вбудованих плат на базі PowerPC, ARM, MIPS та кількох інших процесорів, який можна встановити у завантажувальне ПЗП та використовувати для ініціалізації та тестування обладнання або для завантаження та запуску коду програми. У вашому Linux ви можете знайти пакети uboot-tools (Arch Linux та похідні) та u-boot-tools (Debian та похідні) – це інструменти та утиліти для складання прошивок та виконання з ними інших дій. Спробуємо змонтувати образ user-x.cramfs.img:

Отримуємо помилку:
![]()
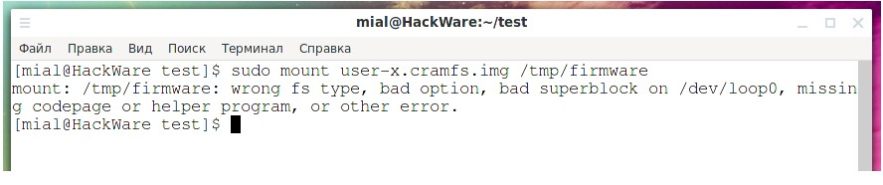
Звернемося за допомогою до утиліти Binwalk, яка вміє знаходити файли та файлові системи навіть якщо вони знаходяться не на початку:
![]()
Висновок:

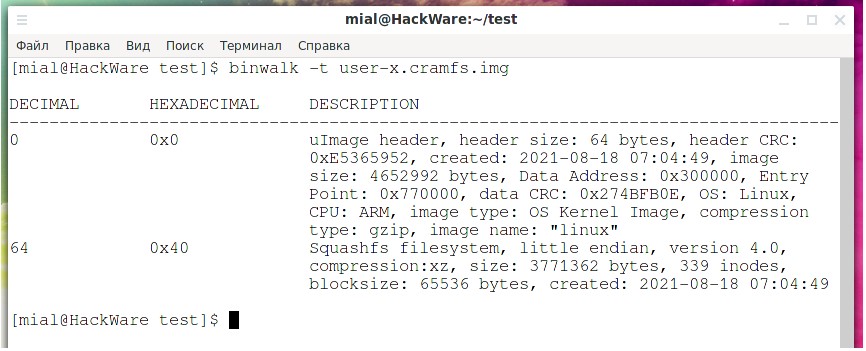
Тепер все стало зрозуміло – цей образ складається з двох розділів. Перші 64 байти займає заголовок uImage. А сама файлова система Squashfs йде починаючи з 64 байт. Ми можемо витягти файлову систему — як це зробити відразу декількома способами буде показано нижче, але також можемо її просто змонтувати, вказавши зміщення:
![]()
Подивимося на файли, які розміщені в образі user-x.cramfs.img:
![]()
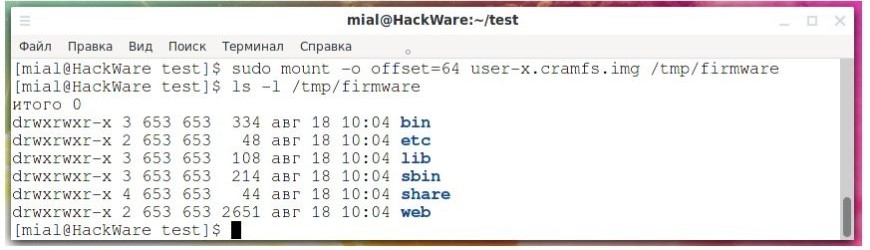
У цьому образі я не знайшов нічого цікавого, розмонтуємо його:
![]()
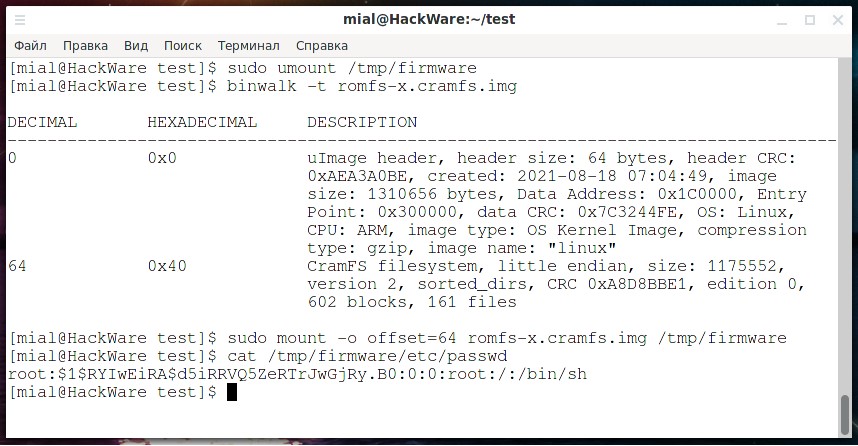
Подивимося, де починається файлова система в romfs-x.cramfs.img:
![]()
Змонтуємо:
![]()
Здесь можно найти хеш дефолтного пользователя root:
![]()
Аналогічно, скануючи за допомогою Binwalk і монтуючи розділи файлової системи, можна шукати цікаві файли.
Як було показано вище, за допомогою опції offset можна вказати зміщення та монтувати файлову систему яка є частиною образу і розташована не на самому його початку:
![]()
Якщо образ містить кілька файлових систем, вам може знадобитися вказати ще й опцію sizelimit розмір файлової системи:
![]()
Наприклад:
![]()
Наприклад візьмемо прошивку ZyXEL Keenetic Lite II: https://help.keenetic.com/hc/article_attachments/115009890565/Keenetic-II-V2.06(AAFG.0)C3.zip. Знайдемо розділи у прошивці:
![]()
Висновок:

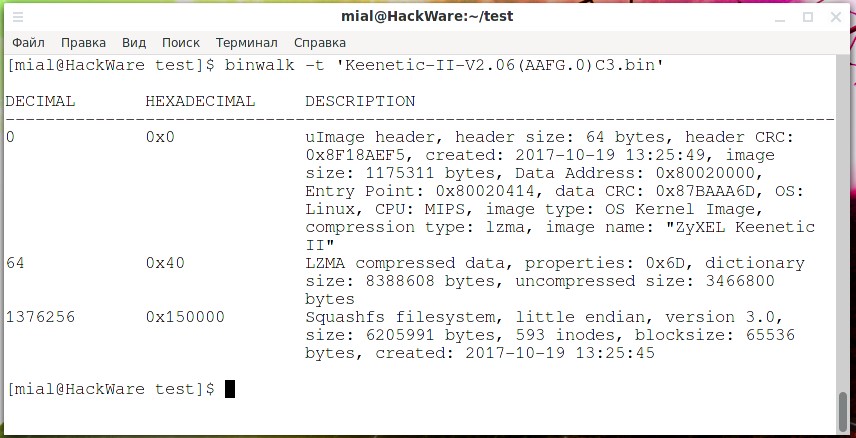
з 0 по 64 байти – заголовок uImage.
з 64 починаються стислі дані LZMA
З 1376256 починається файлова система Squashfs, її розмір 6205991 байт, це випливає із рядка «size: 6205991 bytes».
Для вилучення кожного з цих розділів можна використати команду виду:
![]()
Наприклад, з файлу Keenetic-II-V2.06(AAFG.0)C3.bin я хочу отримати перші 64 байт, тоді команда наступна:
![]()
Тепер я хочу отримати другий розділ, що починається з 64 байти. Цей розділ закінчується на байті 1376256, але опція count команди dd вказує скільки байт потрібно прочитати (а не межу отримання даних), тому значення count розраховується за формулою:
![]()
У нашому випадку це 1376256 – 64 = 1376192, отримуємо команду:
![]()
Файл LZMA можна розпакувати, наприклад, за допомогою 7z:
![]()
У принципі команда витягла дані, хоча й повідомила про помилку:
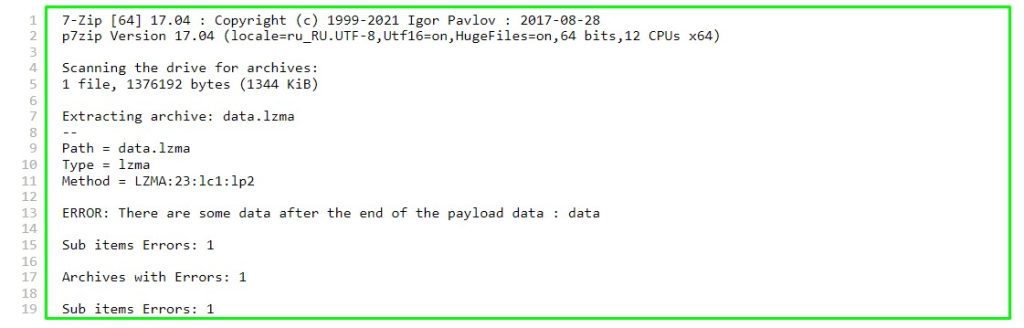
Суть помилки полягає в тому, що після кінця корисного навантаження були виявлені дані. Можна сказати, що це нормально (неминуче) в даному випадку, оскільки ми не знали точний розмір блоку і вказали як його кінець байт, де починається інший розділ. Інший розділ починається з байта (в шістнадцятковому вигляді) 0x150000, тому можна припустити, що для паддингу (padding, вирівнювання) між розділами просто “набиті” нулі. У цьому можна переконатися, відкривши файл data.lzma у шістнадцятковому редакторі, наприклад у Bless:
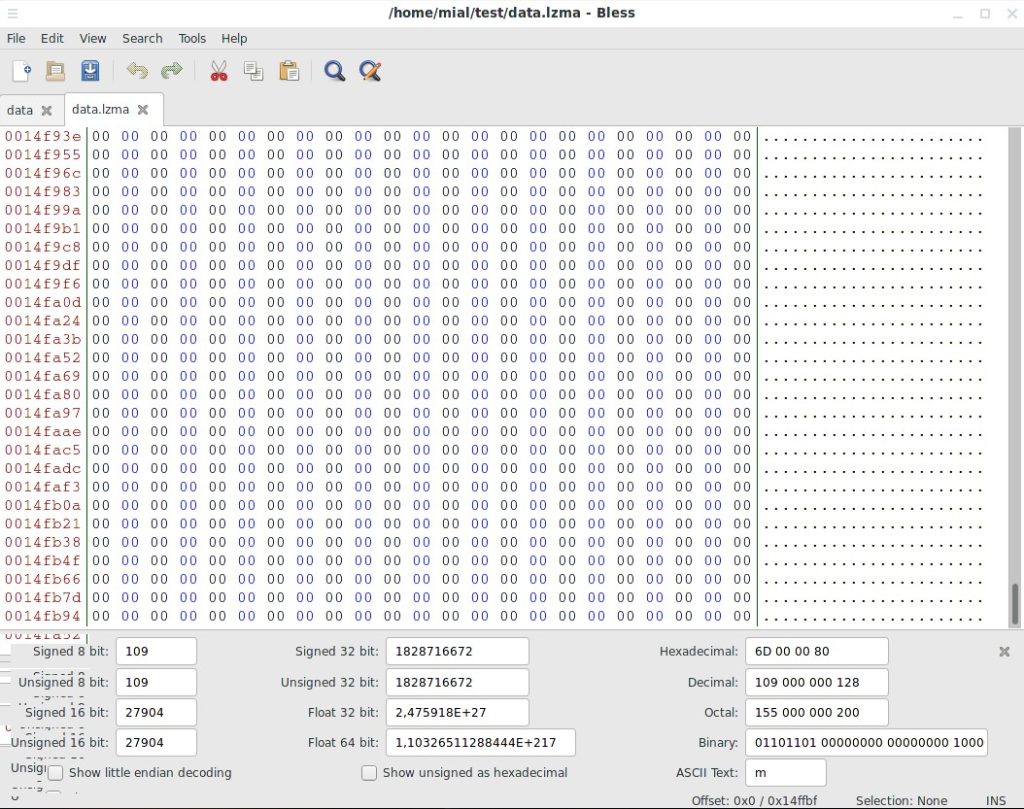
Так, наприкінці цього файлу нулі — якщо точний розмір невідомий, краще записати зайвого, ніж втратити дані. Третій блок починається з 1376256 байта і має розмір 6205991, про це нам говорить рядок «size: 6205991 bytes». Команда з його вилучення наступна:
![]()
Але виробники прошивки все одно мене перехитрили, використавши Squashfs version 3.0 з 2006 року і я не зміг її відкрити з технічних причин:

Програма Binwalk має такі опції для вилучення:

Більш докладний опис ви можете прочитати в картці програми https://kali.tools/?p=6771. Це здається зручним — витягувати дані автоматично, але на практиці результат буде не зовсім тим, на який ви очікуєте. Оскільки навіть у ручному режимі ми не завжди точно знаємо межі розділів, те саме стосується і вказаних опцій, які погано працюють з розділами, для яких не вказано конкретний розмір.
У програми dd є покращені версії dc3dd та dcfldd. За бажанням для вилучення розділів файлової системи з образу диска можна використовувати.
Програми file, Binwalk та Detect It Easy у пошуку даних використовують сигнатури. Ці сигнатури зумовлені їх базах даних (так звані магічні файли). Якщо вам потрібно виконати пошук за вашими власними сигнатурами, тобто по рядку бінарних даних, то ви можете використовувати Binwalk з наступними опціями:

Наприклад, пошук шістнадцяткових байтів 53EF у файлі /mnt/disk_d/fs.ext4:
![]()
Програма sigfind із пакета Sleuth також дозволяє шукати по сигнатурах, при цьому програма дозволяє вказати відступ від початку блоку (НЕ файлу). У програмі прописано кілька сигнатур для пошуку файлових систем, наприклад:
![]()
У наступному прикладі шукається послідовність байтів 53EF (зворотний порядок запису байтів) зі зміщенням 56 від будь-якого блоку (якщо не вказати зміщення, будуть виведені тільки блоки, де дана послідовність байтів має зміщення 0):
![]()