26.09.2024
4 min
1127

The Domain Name System (DNS) is the foundation of the Internet, providing the ability to translate human-readable website names into IP addresses. However, this system has a critical vulnerability – DNS cache poisoning. The attack allows attackers to replace records, forcing users to go to fake sites or lose data. The article explains how the mechanics of DNS queries work, what roles resolvers, authoritative servers, and cache play, why predictable TXIDs and fixed ports make the system vulnerable. It also describes the Kaminski attack, which allows you to capture entire domains, and provides practical protection methods: random identifiers, port randomization, recursion restrictions, and the implementation of DNSSEC. The material is useful for administrators and cybersecurity professionals who seek to ensure the reliability of network infrastructure.

The Domain Name System (DNS) is an invisible but critically important layer of the Internet that translates human-friendly domain names into numeric IP addresses that network hardware can understand. Everything from the correct display of web pages to the delivery of email and the operation of mobile applications depends on its performance. The protocol itself is designed as a distributed database with a hierarchical structure of delegation of responsibility, which ensures scalability – but this same hierarchy creates points that can be used for attacks. This article examines in detail how a query occurs in the DNS chain, which fields of the packet are critical for security, how caching works, what mechanisms attackers use to poison the cache (including the Kaminsky attack), and what practical protection measures can significantly reduce the risks. The material is presented as a step-by-step instruction with explanations and recommendations for administrators and technical specialists, but is written clearly for those who want to delve into the topic.
DNS is a network service that is divided into several interconnected roles; each performs its own function, and it is the interaction of these roles that determines the correctness of name resolution. A zone describes a set of records for a specific domain and is a unit of administrative management: it stores A/AAAA, NS, MX, SOA and other records that determine the operation of domain services; authoritative zone servers (master/primary and secondary) are the source of “truth” for these records and answer queries as final; resolvers are client libraries or system agents that form queries and send them to recursive servers; recursive servers are intermediate executors that perform the full path from the root to the authoritative server on behalf of the client, caching intermediate results to improve performance and reduce network load.
Before providing a brief list of roles, it is important to understand that each role does not simply perform a technical function, it carries associated administrative responsibilities and policies (zone modification rights, TTL policies, replication mechanisms) that determine how reliable or vulnerable a particular infrastructure will be. Here is a condensed list of key components with additional remarks about their function:
zone (a set of records and policies) — a logical unit of management where records and rules for their update are defined; important for the separation of responsibility and delegation;
authoritative server (data source) — stores the “official” copy of the zone file; its availability and integrity are critical;
resolver (client logic) — a component transparent to the end application that generates DNS queries; depends on the system settings of the OS;
recursive server (search and caching) — does the heavy lifting of delegations and manages the cache; speed and security for a large number of clients depend on its behavior.
These roles interact in a certain order: the client contacts the resolver → the resolver contacts the recursive server → the recursive server, in case of no cache, sequentially contacts the root, then the TLD servers, and then the authoritative ones; the result is returned and cached for the TTL time. It is in this sequence that the field for manipulation arises: if the recursive server believes a false answer, all its clients will suffer due to the spread of the poisoned cache.
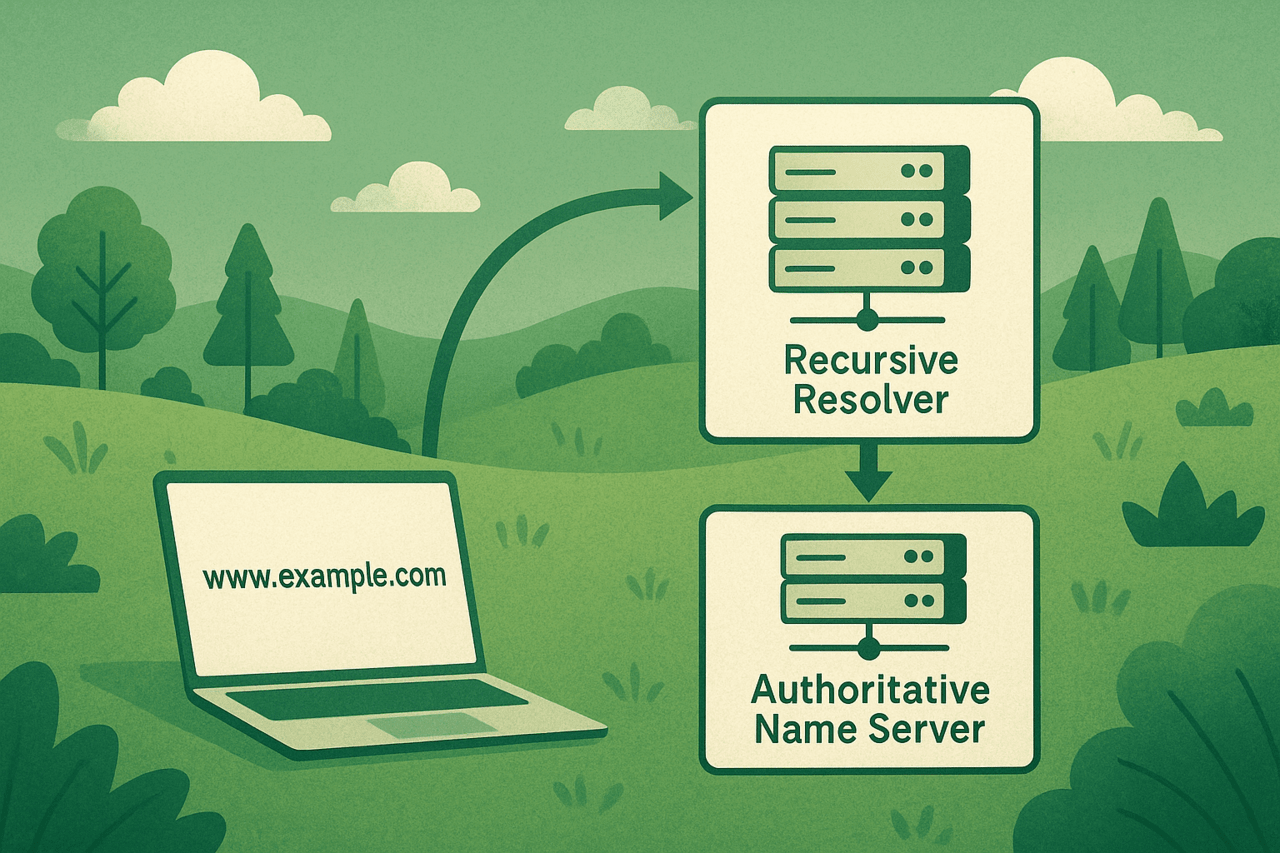
The resolution starts with a simple question: what is the IP address for a given name? If the recursive server does not have an answer in its cache, it uses its built-in list of “root hints”, sends a query to one of the root servers, gets a delegation to the top-level domain (TLD) servers, then goes to the TLD and gets a delegation to the authoritative servers of the target zone. At each step, not only the names of the servers returned in the Authority section are important, but also the so-called “glue” records in Additional, which contain the IP addresses of these servers and allow you to establish network connections immediately. It is the response fields — Question, Answer, Authority, Additional — that must pass “bailiwick” checks and match the expected domain, otherwise the response is considered invalid.
Before listing the key nodes of the chain, it is useful to note: the importance of each step is not only in the technical direction, but also in the security direction — each delegation is responsible and builds trust, so its compromise has a cascading effect. A short list of stages with explanatory notes:
root servers (root hints) — provide initial delegations, their list is built into resolvers; they do not perform recursion;
TLD servers (top-level domain delegation) — are responsible for zones like .com/.net and return NS for a specific domain;
authoritative zone servers (final answer) — return real zone records; their integrity is critical;
Additional / “glue” (IP addresses for quick connection) — additional records that allow you to avoid additional DNS queries and immediately connect by IP; their correctness is necessary for safe navigation.
Proper handling of these sections ensures that the recursive server does not succumb to incorrect delegations; weak implementation of checks or no checks allows an attacker to replace both the records themselves and the delegation, which immediately dramatically increases his capabilities for manipulation.
The DNS packet contains a number of fields that are responsible for the correct identification and processing of the request-response. The transaction identifier (TXID) — a 16-bit number — is used to match the response with the corresponding request; the source port in the UDP request specifies where the response should be sent; the QR, AA, RD, RA flags indicate the message type, authority, and recursion support; the Question/Answer/Authority/Additional sections carry the records themselves. For security, it is critical that the TXID and port be sufficiently unpredictable, and that the server checks the origin and correspondence of the sections. Incremental TXIDs or fixed ports make the attacker’s job much easier.
Before listing the most important fields, it should be noted that these fields are not just technical markers — they form a “window of trust” through which potentially malicious responses are passed or rejected. Now, a short list with an explanation of the role of each parameter:
TXID (transaction identifier) — a unique 16-bit number to link the response to the request; its predictability makes it easy to attack;
source port (outgoing UDP port) — the address where the response should return; the randomness of the port adds another layer of protection;
QR/AA/RD/RA (response context) flags — inform about whether this is a request or a response, whether the response is authoritative and whether recursion is supported;
Question/Authority/Additional sections (context and authority) — contain the data itself and additional “glue” records; the reliability of the delegation depends on them.
If one of these elements is predicted or handled incorrectly (for example, due to incorrect NAT/PDN settings that “align” ports), the possibilities for attack increase: the attacker can send a large number of fake responses and with a certain probability “fall” into the desired TXID+port combination and thereby inject fake entries into the cache.
The recursive server cache stores authoritative responses and related records for a time specified by the TTL (Time To Live). This allows many clients to receive the same information without repeated requests to the root or TLD, saves resources and speeds up work. However, the cache is also a place of risk concentration: once there, a false record automatically begins to propagate to all requesters for the duration of the record’s lifetime. Administrators often try to balance: longer TTLs reduce the load, but increase the recovery time after a compromise; shorter TTLs allow for faster “undoing” of erroneous or malicious changes, but increase the number of requests to authoritative servers.
Before listing exactly what items are cached and what this affects, it is worth emphasizing: understanding the relationship between TTL and the role of related records helps to form the right protection and response strategy. Here is what usually gets into the cache and why it is important:
authoritative response cache — directly A/AAAA records returned to clients; impact on service availability;
accompanying NS and “glue” — delegation data that helps to quickly find authorities; their substitution allows you to change the source of truth;
TTL (time to live record) — determines the duration of the impact of any response in the cache; determined by the zone administrator;
compromise between performance and updatability — strategic setting of TTL depends on the level of criticality of services and readiness for frequent updates.
So TTL policy and careful cache management are not just a performance issue, but also an essential part of defense: vulnerable zones with large TTLs become attractive targets for those seeking long-term control over traffic.

The idea is simple but effective: a recursive server waits for a response to a specific request; if the attacker can guess the TXID and source port combination and send the response before the real authoritative server, the recursive server will accept the response as genuine and cache it. The attacker typically initiates a series of requests, often to random subdomains of the main domain, to force the recursive server to make requests to the target authoritative servers, in response to which it starts sending a large number of forged packets in the hope of guessing the right combination. In older systems with sequential TXID generation, this was easier; modern systems greatly improve this process by adding entropy.
To better understand the key technical steps and what the attacker is trying to do, it is useful to list the main elements of a classic attack and briefly explain why each of them is important:
initiating requests for random names — creates a load and forces the recursive server to make requests to authoritative servers;
the “flooding” phase with fake responses — mass sending of fake packets with the hope of getting into the correct TXID+port pair;
the “first correct one wins” rule — the recursive server accepts the first correctly formatted response and can ignore the real one that comes later;
exhaustion of the real response and caching of the fake — after accepting the fake, subsequent clients will receive the fake result until the TTL expires.
This mechanism still works where the combined TXID+port entropy is insufficient or is destroyed by external factors (for example, NAT that monitors and changes ports), so protection against such attacks should include not only improving random value generation, but also architectural solutions: limiting recursion, monitoring client behavior, and quickly detecting anomalies in logs.
Dan Kaminsky showed a more sophisticated and destructive approach: instead of directly replacing a single A record, the attacker tries to replace the authority records (NS and the corresponding “glue”). If the recursive server accepts fake NS records with the attacker’s addresses, it will consider these servers authoritative for the target zone and will start contacting them. As a result, the attacker gets the opportunity to respond to any requests for this domain: create fake A or AAAA, change MX to intercept mail, give fake CNAMEs, and so on. It is this approach that allows you to capture not a single name, but the entire zone or even several of the lower zones at once.
Before listing the more detailed steps of the attack and its consequences, it is necessary to emphasize: the main threat here is not the temporary replacement of one resource, but the ability to establish long-term control over the domain infrastructure. Below are the key points of Kaminsky’s technique with brief explanations:
NS substitution in the Authority section — the recursive server learns “new authorities” that actually belong to the attacker;
“glue” IPs in Additional, pointing to the attacker’s servers — allow you to bypass additional address requests and immediately connect to controlled resources;
mass A/MX/CNAME management after compromise — the ability to simultaneously substitute web and mail services, which leads to widespread compromise of communications;
setting a high TTL for the duration of control — the attacker can intentionally set a long TTL so that fake records remain in caches for a long time and affect a larger number of users.
Because this technique allows an attacker to become the “source of truth” for a large number of requests, its consequences can be catastrophic: mass redirects of users, interception of correspondence, loss of trust in services, and complex consequences for PKI if the accompanying procedures for confirming control over the domain use DNS.

Cache poisoning protection is built on several levels and combines tactical and strategic measures. At the tactical level, it is necessary to ensure high entropy in all random parameters: the TXID should be cryptographically unpredictable, and the output UDP ports should be selected from a large pool of random numbers; in addition, it is important to avoid NAT or firewall configurations that “flatten” or rewrite ports, as this reduces the effective entropy and makes the attack easier. At the political-administrative level, one should prohibit or limit recursion for unknown external clients (closed resolvers), configure strict bailiwick-checking, carefully control access to transfer zones, and regularly update software. Strategically, implement DNSSEC, which cryptographically signs records and makes it impossible to accept incorrect data without the appropriate keys.
Before listing specific practical steps, it is important to understand that effective protection is a set of settings, policies, and procedures, each of which closes a specific vector of attack. Here is a list of the main measures with explanations of their purpose:
cryptographically random TXIDs — minimize the probability of guessing the identifier;
a large pool of random output ports — adds another independent entropy and makes it more difficult to attack;
recursion restrictions and bailiwick settings — reduce the risk of open resolvers and delegation substitution;
DNSSEC implementation and change monitoring — strategic protection that allows you to verify signatures and detect inconsistent changes.
The combined application of these measures significantly raises the barrier to attack: instead of being a “practically feasible” measure, cache poisoning becomes expensive, complex, and risky for the attacker, and in the case of DNSSEC, essentially theoretically impossible without full control over the zone’s cryptography.
DNS defense doesn’t end with configuration: it requires constant visibility and responsiveness. Keeping query and response logs, analyzing anomalies (sudden waves of queries to random subdomains, unusual NS changes, or a sharp increase in responses from new IPs) can help you catch attack attempts early. Back-up plans include proactively lowering the TTL for critical records before planned changes, emergency update procedures for authoritative records, and a well-established incident notification process. It’s also a good idea to regularly perform penetration testing for cache poisoning capabilities in your infrastructure.
Before we list practical steps for monitoring and responding, let’s emphasize that rapid diagnostics and coordinated actions can minimize the impact of even a large-scale compromise. Here’s a recommended set of measures for operational readiness:
logging and anomaly analysis — centralized log collection, event correlation, and indicators of compromise;
rapid TTL decrement and zone refresh scenarios — operational plans for flushing fake entries from the cache;
regular pentests and NAT/firewall configuration audits — checking whether external devices are destroying port entropy;
incident response and communication processes — roles, contacts, message templates, and procedures for rapid recovery.
These measures ensure not only prevention, but also rapid recovery in the event of a compromise: clear procedures and automated tools help minimize exposure time and reduce the impact on users and business services.
DNS is the backbone of network infrastructure, and the cache poisoning problem demonstrates how even fairly low-level flaws in the protocol and implementation can lead to large-scale risks. Practical defense requires a multi-layered approach: cryptographically strong random parameters, sound recursion and validation policies, implementation of DNSSEC, and ongoing monitoring and robust response processes. Only a combination of these measures can transform DNS from a potential vulnerability to a reliable and secure service that can be trusted.

