
04.09.2023
48 min
1977

Programming in today’s world is a key factor in ensuring information security. Concepts and methodologies built into the programming process can significantly improve the security of software products and applications. Security in programming is more than just avoiding vulnerabilities. It is also about proactively protecting information and data owners. Key Programming Concepts for Security: Protecting Against Vulnerabilities: Programmers must ensure that they use sound programming practices that prevent vulnerabilities, such as uncontrolled data injection and injection attacks. Attack Surface Minimization: Anticipating attack possibilities and reducing attack risk are key principles of secure programming. Authentication and Authorization: Built-in user authentication and resource access control ensure that only authorized individuals have access to data and functionality. Encryption and Data Protection: Application of cryptography to protect confidential information during storage and transmission.

Monitoring and Logging: Systems should be equipped with event monitoring and logging capabilities to help identify and respond to potential threats in a timely manner. Security Assurance: Correctly managing dependencies and using up-to-date versions of software libraries helps to avoid vulnerabilities associated with outdated components. Education and Security School: Increasing the awareness of programmers and their understanding of modern threats are critical aspects in improving security. The Principle of Least Allowed Access: Assigning minimal access rights to users and processes reduces the risk of unauthorized operations. The application of these concepts in programming helps to increase the level of information security. They help avoid threats and vulnerabilities, ensuring data protection and reliability of software products. In this section. How immutability solves security problems. How fast-failure contracts make architecture secure. Types of correctness checks and their procedure.
Developers are constantly reminded of priorities and deadlines. Various tricks and circumvention of the rules sometimes become part of the reality that one has to put up with. But can you do without it? Basically, only you decide which syntax to use, which algorithms to work with and how to organize the execution process. If you really understand why some programming concepts are better than others, applying them becomes second nature and takes no more time than writing bad code. The same applies to security. Intruders can be bothered by your deadlines and priorities – a weakly protected system can be hacked regardless of why and under what circumstances it was created.
We are all responsible for developing secure software. In this section, you’ll learn why it doesn’t take any extra time compared to developing weakly-secured, vulnerable software. In this regard, we have divided the material into three parts, which consider different strategies for solving security problems that you may encounter in your daily work (Table 4.1).

In this way, we will try to change the way you think, give you a new set of tools and give you recommendations that you can apply in your everyday work. You’ll also learn how to identify weaknesses in legacy code and fix them. Let’s start with the principle of immutability and give an example of how it helps to cope with updates.
When designing an object, you must decide whether it should be mutable or immutable. In the first case, its state can change, and in the second – not. This may seem insignificant, but from a security point of view, this aspect is very important. Immutable objects can be safely exchanged between threads of execution, and data can be made highly available, which is critical to protecting the system from denial-of-service (DoS) attacks). On the other hand, modifiable objects are meant to be updated, which can lead to unauthorized changes. Mutability support is often built into a system because frameworks require it, or because it makes the code simpler at first glance. But this is a dangerous approach that can be costly. To illustrate this, let’s look at an example of how using immutability in a web store architecture raises security issues that can easily be solved with immutability.
A regular web store
Imagine a regular web store where customers authenticate and add products to the cart. Each customer has a credit score based on their purchase history and membership points. A low credit rating allows you to pay only by credit card, and a high one also allows you to use an invoice. The calculation of the credit rating requires quite significant resources and is carried out continuously to make the overall load on the system more uniform.
In general, the system worked normally – until recently. During the last advertising campaign, a lot of people visited the store’s website. The system did not cope well with the load, and customers complained about order timeouts, long delays and illogical payment options. The last question seemed trivial, but then the finance department reported that many customers with poor credit ratings had unpaid invoices. A full-scale investigation has been launched – System security is at risk! The main suspect, of course, was the code for calculating the credit rating, but, to everyone’s surprise, the problem turned out to be much more serious – the internal structure of the Customer object.
Internal work of the Customer’s facility
The Client object shown in Listing 4.1 has two interesting features. The first is that all fields are initialized by setter methods. It follows that after an object is created, its internal state can be changed. This can be a source of problems because we cannot guarantee that the object is initialized correctly. Another observation is that each method is marked with the synchronized keyword, which should prevent simultaneous changes to fields, which in turn can lead to thread contention (this is when threads are forced to stop and wait for some other thread to release one or more blockages


It’s not entirely clear how these design decisions relate to security, but things will become clearer when we categorize web store issues as data integrity or availability violations.
Classification of problems as integrity or availability violations
Data integrity refers to the consistency of data throughout its life cycle, data availability is the guarantee that it can be retrieved at the expected level of performance in the system. Both concepts are key to understanding the cause of the problems encountered in the webshop. For example, the inability to get data is an availability problem, which often boils down to the fact that some code prevents parallel or concurrent access. Similarly, you should start your analysis of integrity problems with code that allows for changes. In the table 4.2 shows the problems of the web store classified as availability and integrity violations.

These categories give you a general idea of which parts of the Customer class deserve special attention. Let’s start with how a hidden lock can degrade accessibility.
Implicit blocking degrades availability
The question of whether parallel and parallel access should be disallowed is often a trade-off between performance and consistency. If you always want the state to be consistent, and updates alternate with reads, it makes sense to use locking mechanisms. However, if the data is primarily read, blocking can lead to unnecessary conflicts between threads of execution. Conflicts caused by concurrency are generally easier to understand than those caused by concurrency. Take, for example, the synchronized method in Listing 4.1: only one thread can execute it at a time, because accessing it requires acquiring the object’s built-in lock. All other threads trying to access this method at the same time must wait until this lock is released, which can lead to conflicts.
Using the synchronized keyword at the method level can also cause thread conflicts when two or more methods are called in parallel. It turns out that in order to access all methods, objects marked as synchronized must acquire the same built-in lock. This means that threads calling these methods in parallel implicitly block each other, and such conflicts are sometimes difficult to detect.
If you return to our online store and analyze the relationship between reading and writing operations, you will find that reading customer data occurs much more often than updating it. The fact is that the data is mainly changed by the algorithm for calculating the credit rating, and reading operations are performed within the framework of numerous customer requests, including from the reporting system belonging to the financial department. This shows that parallel and concurrent reading is safe. So why not get rid of the synchronized mechanism altogether?
Parallel and concurrent reads are most likely safe, but while minimizing conflicts, write operations cannot be ignored. Instead of abandoning the locking mechanism, you need to think about another solution. For example, you can use advanced locking tools like ReadWriteLock, which takes into account the predominance of read operations. However, locking mechanisms complicate the code and increase the cognitive load on developers. We prefer to avoid this.
A simpler and more successful strategy is to use design techniques designed for parallel and concurrent access, such as immutability. In Listing 4.2, you’ll see an immutable version of the Customer class that doesn’t allow for state updates. This means that Client objects can be securely exchanged between threads without using locks. The result is high availability with few conflicts. In other words, topics are no longer blocked.


But we still need the ability to edit customer data. How to achieve this if the Customer class is immutable? It turns out that you can do without modifiable data structures to support changes. All you need to do is decouple reads from writes and perform updates over separate channels. This may seem like a bit of a stretch, but if your system has a read/write imbalance, the result may be worth the effort. About Us How to put this into practice will be covered in Chapter 7, where we discuss the Entity Snapshot design pattern in detail.
You already know that immutability prevents accessibility issues at the design level, but what about breaking integrity in our web store? Will immutability help here? Maybe. Let’s look at how the changing architecture of Customer and CreditScore makes integrity issues likely.
Changing your credit rating: a matter of integrity
Before diving into the analysis, let’s remember what the problem is with a credit score. Each client is assigned a credit rating; If it is high enough, the customer can pay by invoice. During the last advertising campaign, the system crashed and the finance department reported that many low-rated customers had unpaid bills. The data integrity breach resulted in a credit score change, which opened access to an additional payment method. But how is this possible?
Looking at the credit rating management logic in the changing Customer object (Listing 4.3), we see the following:
The way creditScore is initialized inside Customer allows you to change the credit rating at any time;
A reference to creditScore was accidentally escaped from the getCreditScore method, allowing changes to be made outside of Customer;
The setCreditScore method does not create a copy of the argument, allowing you to inject a creditScore shared reference.

Let’s discuss each of these observations and consider how they lead to data integrity violations.
The first thing that can cause an integrity problem is an apparent change in credit rating through initialization. The creditScore field in the Customer class is initialized by the setCreditScore method. This was done on purpose, but this way of initializing the field allows you to change the customer’s credit rating at any time, as it does not guarantee that it can only be called once. This may seem acceptable since the customer is expected to read only data, but the mutable nature of the Customer class does not prevent accidental use of this method. This means that you cannot guarantee the integrity of the Customer’s object.
The second problem is related to the change of credit rating outside the Client. If you look at the getCreditScore method inside the Client, you will notice an inadvertent leak of the internal creditScore field. As a result, it is possible to change the credit rating outside the Customer’s facility without purchasing a lock. This is extremely dangerous because the Client is a generic, mutable object, and updating it without synchronization is a ticking time bomb (more on this in Chapter 6). But this is not the worst thing.
The CreditScore class was designed to be mutable, so we can manually change the customer ID by calling the setCustomerId function, as shown in Listing 4.4. This means that the Customer and CreditScore objects can have different IDs, and this disconnect can cause the calculation method to use the wrong credit score value!
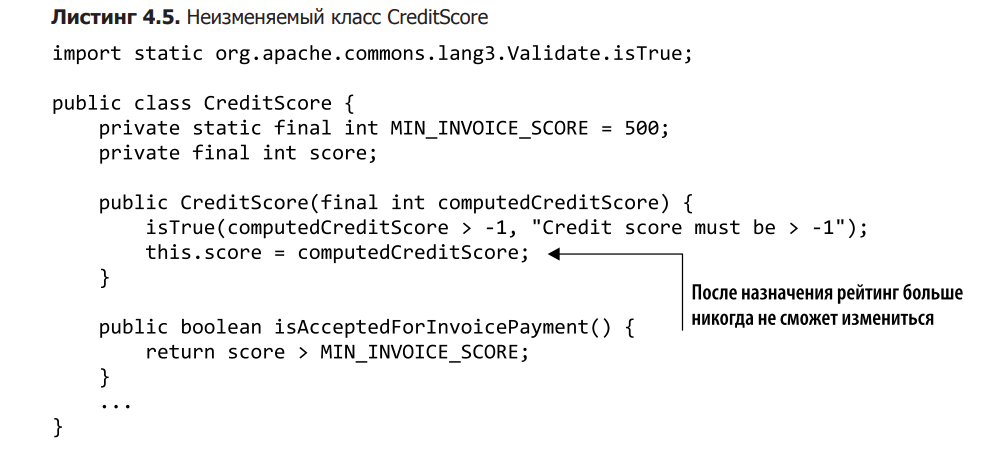
To fix the situation, we have to modify the CreditScore class. You can see an unchanged version of it in Listing 4.5. Please note that we have removed the sync keyword and client id dependency. The fact is that you no longer need to get blocked when checking your credit score, since now it cannot change after it is passed to the builder. This, in turn, means that client-specific dependency becomes redundant, so the architecture can be simplified by moving the credit score calculation outside the entity. This allows us to share the rating between threads, and we are not threatened by unauthorized updates, conflicts and blocking.
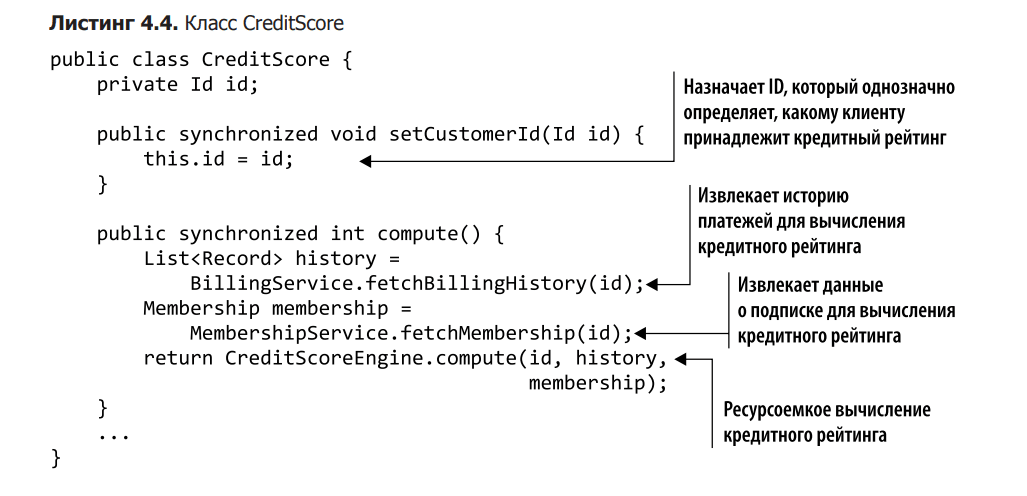
The third way to change the creditScore is not as obvious as the previous two – it is related to the modification of the general reference to the credit rating. If you look at the setCreditScore method on the version of the Customer object you’re modifying, you’ll notice that the internal field is assigned an external mutable reference to creditScore. It’s okay if the external link is not reused in another Client object. But if this happens, the calculated value of the credit score will be the same for all customers who share the link. This is a serious violation of integrity, which explains the illogical payment options in the online store.
All of the scenarios we’ve explored can explain data integrity issues in a web store, but which one is the real cause? It doesn’t really matter. The point here is that by choosing to use the mutable Customer and CreditScore classes, the system developers made their code less secure in several ways. But if you choose an approach focused on immutability, then the need to block and protect against accidental changes disappears. Such a design solution in itself increases the level of security.
Now you know how immutability avoids data integrity and availability issues. You may have noticed that in some cases bad data was aggressively blocked before it even got to the object. This is another effective security technique. Now let’s move on to quick termination using contracts.
Quick termination using contracts
As mentioned in Chapter 1, one of the principles that should guide security is depth. Even if one defense mechanism at the edge of the system fails, others can stop the intrusion. There are physical security measures such as access cards that visitors use when entering the building. This can be a photo badge that must be worn at all times. In our experience, measures such as prerequisites and contract design can also contribute to software security. In this section, we will show well-established pragmatic programming techniques and give numerous examples.
Prerequisites were part of theoretical research in computer science in the late 1960s. Anthony Hoare (also responsible for inventing the null pointer exception) was particularly active in these. The term “design by contract” was coined in the 1980s by Bertrand Meyer, who used it as a basis for object orientation. These ideas, in addition to theoretical interest, have a direct positive impact on security.
The use of prerequisites and contracts in architectural planning helps to clearly define the responsibilities of a particular component. Many security problems arise because different parts of the system expect each other to do something. In this section, we’ll show you how to use contracts, preconditions, and quick disconnects to avoid situations like this in practice.
How does contract design work and what do we mean? Let’s start with a non-software example. Imagine hiring a plumber to fix a faulty bathroom drain. The plumber may ask you to open the door and turn off the water. These are the prerequisites (or prerequisites)) of the contract. If they are not followed, problems may arise. At the same time, the master promises that the drain in the bathroom will work properly upon completion of the work. This is a post-contract agreement.
In design, object contracts work in a similar way. The contract defines the preconditions necessary for the method to work correctly, and the postconditions that describe how the object will change after the method completes. Listing 4.6 shows a class that is part of the cat breeding helper system. The specific CatNameList class helps keep track of nicknames that can be given to newborn kittens. When a breeder comes up with a new nickname, it queues it up using the queueCatName object. When it needs to name a kitten, it takes the next name in the queue with the nextCatName method and, if it matches, removes it from there with dequeueCatName. The size method allows you to find out how many nicknames are in the list.


The queueCatName method has a few specific prerequisites. The name of the cat cannot be null, and this is logical: it must have some meaning, otherwise this system will not work properly. According to Swedish folklore, a good cat name must contain s sounds (that’s how the cat will react to it) – this is also a prerequisite. And finally, breeders don’t want nicknames to be repeated, So this contract requires that the list be free of nicknames that we add.
The same contract could have been written differently. For example, the list itself could monitor the absence of duplicates. In this case, the pre- and post-conditions would be formulated differently (Table 4.4).

Note that this contract applies to the entire class, not to its individual methods. The contract requires that the nickname passed to the queueCatName method contains s sounds, while ensuring that it will be contained in the name returned by the nextCatName method. It also defines the responsibility of the class as a whole. Note that the contract describes the planned project solution. The anti-duplication task goes either to the CatNameList or to the caller. Having a contract clearly defines whose responsibility it is.
Many security problems arise in situations where the calling system component assumes that the caller is responsible for performing the task, and the caller, in turn, expects the caller to do so. Explicit contract design avoids many of these situations that lead to vulnerabilities.
But what to do if the preconditions are not met? Let’s go back to the example of a plumber who was hired to fix a broken drain and who made several demands (open door, blocked water). If the door is left closed, the plumber will not be able to enter, and if the water is not turned off, the work should not be started, otherwise serious problems may arise. In such situations, it is better to terminate quickly (fail quickly) – stop execution as soon as it becomes clear that the preconditions are not met. This has a very positive effect on security.
For treaties to be of any use, the rules described in the code must be followed. The Eiffel programming language, developed by Bertrand Meyer, has built-in support for this mechanism. The programmer specifies preconditions, postconditions, and invariants, and the runtime checks for them. But since you are most likely using other programming languages, you will have to perform these checks yourself in your code. Let’s take a look at some of these programming approaches and show you how to build more secure software.
The contract for the CatNameList class has some restrictions on nicknames queued by the queueCatName method: You cannot pass null and the nickname must contain s. If the subscriber does not fulfill the contract, there is a good chance that sooner or later something will break. If no mechanisms are in place to enforce the contract, nicknames without the s sound will fall into the queue and much later you will end up with kittens named Buddy, Charlie or Tuzik. For safety, we advise you to shut down the system quickly and in an organized manner, preventing further system failure in an unpredictable manner.
The prerequisites should be checked at the beginning of the method, before any actions are performed, and if they are not met, the work should be terminated abruptly. Failure to meet the prerequisites indicates that the program classes are not being used for their intended purpose. The program has lost control over what is happening, and the safest thing to do is to stop as soon as possible. There’s nothing complicated about this—you can implement it yourself with an if statement that throws an exception like the one shown in Listing 4.7.

This code might be a bit verbose, but it does the job. It stops if the cat’s name is missing (zero), does not match or is already listed. Aggressive shutdown is used for this.
In Java, when a null is found where something else should have been, a NullPointerException is thrown.
In our experience, it is useful to make this code more compact by using the Validate utility class from the Apache Commons Lang framework. It contains some useful helper methods that do exactly what we need: check the condition and, if it doesn’t pass, throw the appropriate exception. Listing 4.8 shows the code you can get by applying Validate.notNull, Validate.matchesPattern, and Validate.isTrue.

The Validate class contains many other useful methods, including exclusiveBetween and inclusiveBetween, which check whether a value is within a valid range. To learn more about other features of this framework, check out the documentation – it will make it much easier to check preconditions in your code. We use it in the following examples in this book to make them more concise.
NOTE. Invalid data does not need to be repeated in the exception. Such duplication can be fraught with vulnerabilities. We will talk about this in more detail in chapter 9.
There is nothing difficult in checking the prerequisites, but thinking through contracts requires more effort. In what cases is it justified? Our experience shows that the formulation of contracts and the verification of prerequisites by public methods will definitely pay off. This applies to simple checks – for null, for input into a range, etc. If we are talking about internal methods of packaging, then this question is subjective. For large packages and heavily used classes, such Checks probably make sense, but in the case of a helper class that is not used in many places, we would skip them. As for private methods, they should not be checked. If a class needs internal contracts, it will likely become too large and have many additional responsibilities, so it should be broken up.
ADVICE. Check the prerequisites for all public methods – at least make sure they don’t accept null as arguments.
So we figured out how to check the arguments passed to the methods. Now let’s move on to a similar topic – constructor arguments. Let’s talk about another concept that Meyer mentions in his theory along with preconditions and postconditions – invariants (these are aspects of an object that must always be true). First, invariants must be observed by the constructor when creating an object.
Compliance with invariants in constructors
Working with constructor arguments is a bit more complicated than with method arguments. The main task of the designer is not so much to process or change the state of the object as to create the object in its initial state. This state can be created in one part of the application and used in a completely different part of the application, so if it’s wrong, it can cause defects that are difficult to trace, and it can set the stage for security vulnerabilities.
The constructor contract may specify that one of the fields is mandatory, in which case it is enough to make sure that the corresponding value is not Null. The word “required” can be interpreted in the sense that this object contains an invariant, according to which the field must always be equal to some object and cannot be assigned null. By adding a null check, you ensure that the invariant is satisfied. Invariants can be much more complicated, but we’ll talk more about that in Chapter 6, where we talk about mutable state protection.
Listing 4.9 shows the constructor of the Cat class. The contract states that the name and gender fields should not be undefined, so you need to check if they are null. We also provided the already familiar check for the presence of the s sound in the name of the cat.

You can make this constructor more concise using one of the features of the Validate class. The notNull method not only performs the check, but also returns the checked object. This makes the Cat constructor even shorter, as shown in Listing 4.10.

Most of the validation methods return a validated value, but some do not. This includes the regular expression check method matchesPattern, so it cannot be used in abbreviated form and must be on a separate line. But at the same time, we get the desired behavior: null gives a NullPointerException, and an incorrect cat name leads to an exception.
You may have already noticed that there are two sections in the code that check the name field. This is a flagrant violation of the DRY (Don’t repeat yourself) principle, according to which the same idea should be implemented only once. In Chapter 5, we’ll show our preferred way of solving this kind of problem is to use a domain primitive, which in this case takes the form of the CatName class.
Now you know how to make sure that methods accept the appropriate arguments, and you know that objects are created using constructors that apply the appropriate invariants. It’s time to move on to the last type of checks that we recommend applying to contracts, which is a prerequisite that the object must be in the correct condition.
So, you need to take care of fulfilling the prerequisites that require the object to be in a certain state. For example, if the list of cat names is empty, it is illogical to search for the next nickname in the queue. This is an operation that does not match the state of CatNameList. As you remember from the table. 4.3, in order to use nextCatName and dequeueCatName, the contract requires the CatNameList to contain something.
The obvious solution here is to use Check to ensure that the list in catNames is not empty. However, the Validate.isTrue helper method does a poor job of this. If the validation fails, it throws an IllegalArgumentException, the nextCatName method has no arguments, so this exception will look strange to the caller. Fortunately, there is a Validate.validState method for these situations, which was used by the nextCatName method in Listing 4.11.

Listing 4.12 shows the final version of the CatNameList class with prerequisites to protect against misuse. If data is accepted that intentionally or accidentally violates the contract, the work will be terminated immediately.

As you can see, the class has increased by five lines of code, but at the same time it has become much safer. Invalid arguments are rejected at an early stage, and the object can never be in an invalid state. The main efforts were directed to the design and formulation of the adopted decisions in the form of a contract. But it’s work that still needs to be done.
The concept of quick completion increases security and does not require a lot of code. This can be useful in a larger mechanism for checking the correctness and security of data. In the next section, we will take a closer look at the different levels of verification.
To maintain the security of the system, it is very important to verify the correctness of the data. The OWASP project focuses on input validation (validation of data as it enters the system). It sounds quite obvious and logical, but unfortunately, not everything is so simple. Code should be structured so that input is checked everywhere. Another difficulty is determining what can be considered correct data, as it depends on the situation.
Asking if one value is correct is pointless. Is 42 a valid input? A –1 or <script>install(keylogger)</script>? It depends. When ordering books, 42 is likely to be an acceptable number, and -1 is not. But when measuring the temperature -1 certainly makes sense. In most situations, a line with a script is not acceptable, but it is definitely suitable for a site with messages about security holes.
Validation can mean many different things. Some may say that AV56734T is the correct order number because it matches the format used in the system. And someone else can deny that there is no order with such a number in the system. But even if there was such a number, it could turn out to be incorrect, for example, due to the fact that at some point it was not possible to organize the shipment of this order. Obviously, there are many different types of validation checks.
You’re probably already familiar with security advice like “check your input.” But with all this confusion about what is correct, this advice is akin to “avoid accidents while driving”. The message is clearly correct, but not very constructive.
To avoid confusion, let’s use a framework that tries to separate the different types of checks. The list shown below corresponds to the recommended order of checks. Quick operations, such as checking the size of input data, are at the top of the list, while more resource-intensive operations that require database access are near the bottom. Thus, input data can be rejected even before resource-intensive and complex checks are carried out.
We recommend performing the following types of checks, preferably in this order.
Origin. Was the data transmitted by a trusted sender?
Size. Aren’t they too big?
Lexical content. Do they contain the appropriate characters in the correct encodings?
Syntax. Is the format followed?
Semantics. Is the data meaningful?
As already mentioned, the origin and size can be checked quickly and without spending a lot of resources. Checking the lexical content requires data analysis, which takes more time and creates more load on the system. Syntax checking can be expressed in parsing, which is very time-consuming for the execution thread and takes a lot of CPU time. And checking the significance of the input involves accessing the database – this is a difficult operation. Thus, we can avoid unnecessary resource-intensive checks. Let’s take a look at each of these types of checks and see what role they play in developing secure software. Let’s start with the origin of the data.
Before processing the data, it is only logical to check where it came from. The point is that many attacks are asymmetric in favor of the attacker. This means that the effort required to send malicious data is much less than the system needs to process it. This principle is at the heart of a DoS attack: the system receives so much meaningless input that it ceases to perform its immediate duties, as all its resources are spent processing the input.
A very popular distributed denial-of-service (DDoS) attack, in which many malicious clients in different locations send many messages to the system at the same time. Clients are often botnets consisting of computers that someone has infected with a virus with remote control functionality. This virus is dormant until it receives a message from the host. Such botnets can be bought or rented in the hot corners of the Internet.
Unfortunately, verifying the origin of the data does not always save, but it is the first simple measure aimed at shifting the asymmetry of the asymmetry of the attack in its favor. If the data came from a reliable source, you can continue, if not – we will reject it. There are two main mechanisms for doing this: you can check the IP address the input came from, or you can request an API access key. Let’s start with checking the IP address – this is the easiest option.
The most obvious way to verify the correct origin of the data is to check the IP address from which it was sent. This approach is not as common as it used to be because things are becoming more interconnected on the Internet, but it still makes a certain amount of sense.
If you have a microservices architecture, some services will be at the edge of the microservices architecture, accepting external traffic, while others will be internal and only accept calls from other services. Internal services may only be allowed to communicate with traffic within a specific range of IP addresses owned by other services. For edge services, this probably won’t work because they can be available to any clients.
In practice, this kind of checking is not performed inside the program. Instead, access is restricted at the network configuration level. In a physical room, this is done with the help of routers. In cloud services such as Amazon Web Services (AWS), you can create a security group that allows incoming traffic only from IP addresses in a specific range or list. If your system is in-house (for example, at a point of sale), you can verify the origin of a message by determining whether it came from an address in a specific IP range. For example, if access to the servers should be carried out only through PoS-terminals or office computers located in the corporate network, you can limit access to these ranges. Unfortunately, in our world, in which everything is becoming interconnected, such situations occur less and less.
Also, keep in mind that IP address filters, MAC address filters, and similar tools do not provide any guarantees. The MAC address can be changed in the operating system and IP addresses can be spoofed or borrowed from a compromised device. However, they do provide some entry-level protection.
Using an API access key
If the system has to accept requests from many different locations, you won’t be able to check their IP addresses. For example, if your customers can be located anywhere on the Internet, then all sender IP addresses should be considered valid. This applies to almost any public service that interacts with users. Fortunately, access to the system can be restricted in another way – by requesting an access key. Such a key can be issued to all verified customers. If the client is another system, the key may be issued during its deployment. If we are talking about applications, then the key can be embedded in their code. A key may also be issued to customers who sign a user agreement. The point here is that the owner of the access key confirms that he is allowed to transmit data to your system.
Take AWS for example. It has a REST API that allows you to manage resources such as S3 cloud storage. When sending an HTTP request to this interface, you must specify your access key in the Authorization HTTP header, as shown in Listing 4.13. If there is no such header, the request is rejected. But one access key is not enough. An attacker could theoretically intercept it and impersonate you. To prevent this from happening, the authorization header must also contain a signature based on a private key known only to you and AWS, with which the message content was signed. AWS can determine which private key to use for signature verification by analyzing the access key.

In this case, you need to provide some server-side computation because you need to make sure that the message has the correct signature. It doesn’t require a lot of resources, but there is a risk that someone will send you a large amount of data and force you to process it. The good thing here is that the attacker needs a real access key, which can always be blacklisted for a while. The disadvantage of this approach is that additional work has to be done. But fortunately, this mechanism usually only needs to be implemented once, and it can also be provided by an API Gateway or similar product. When you are going to write it yourself, do not forget to check the correctness of the access key (length, character set, format) so that it does not turn into an attack vector.
Access Tokens
An access key is a type of access token. Some protocols, such as OAuth, allow the authentication server to generate a token that can later be used to authenticate and access other resources. Common to these two mechanisms is that they require prior authentication, and their presence proves the authenticity of the sender.
Access control using authentication and authorization is a whole world in itself. You can start with OAuth (see: www.oauth.com).
After verifying the origin of the data, you can spend some time processing it without exposing yourself to much danger. First, you need to make sure that the data is of an acceptable size.
Does it make sense to accept 1GB orders? Probably not. If you already know that the origin of the data is correct, you need to check its size. Ideally, this should be done as early as possible.
What size can be considered reasonable? It totally depends on the situation. For example, the data uploaded to a video site can easily take up 100 MB to several gigabytes, and this is not unusual. However, a business application based on JSON or XML accepts messages that are likely to be kilobytes in size. What size is acceptable for your data?
If the data is received via the HTTP protocol, its size can be checked by the header
Content-length. If you are doing batch processing, you can check the file size.
When processing data, you can check not only its overall size, but also the dimensions of its individual parts. An attacker can hide the 1GB order number in the request. You may forget to check the requested size, or the size may be within the normal range, but in case the order number is too large, you will have a safety mechanism.
Hopefully, this approach seems reasonable. With its help, you will be able to provide fairly reliable protection without additional efforts. If you apply this technique to an order number, phone number, street name, zip code, etc., it will be much more difficult for an attacker to find a place to enter large data. Your protection ensures that none of the data items can be extremely large.
For example, if you run an online bookstore, you might receive a set of files or HTTP requests related to ordering some books. These books are most likely identified by a nine-digit ISBN (International Standard Book Number) with an additional check digit. Checking the entire file or HTTP request for an acceptable size makes sense, but if you’ve already highlighted the element that should represent the ISBN, you can check it separately. Listing 4.14 shows a class that represents an ISBN and checks its length to prevent DoS attacks.

In some cases, the string length check may seem redundant. In later stages, we often check the content and structure of the data using a regular expression (regexp, or regexp). A regexp might look like this:
[a-z] – one character in the range between a and z;
[A-Z]{4} – four letters, each in the range between A and Z; [1-9]* – numbers from 1 to 9 in any number.
If the next step is to check the format against the regular expression [0-9]{20} (equal to 20 digits from 0 to 9), it would seem why check the length separately? A twenty-five-digit string will still be rejected, right? The point here is that the length check protects the regular expression engine. What if the string does not consist of 25 characters, but a billion characters? Most likely, the Regular Expression Engine will load this huge input and start processing it without realizing that it is too big. Pre-checking the length allows you to secure the following steps.
After making sure that the input data is the right size, you can finally look inside. First of all, we need to check if the content type matches what we expect. This applies, for example, to symbols and coding, which are related to lexical content.
After making sure that your data comes from a reliable source and is of sufficient size, you can decide to analyze its content. Chances are, sooner or later you’ll need to parse the data to extract the elements you’re interested in, such as if it came in JSON or XML format. But this process requires a lot of CPU time and memory, so more checks should be done first.
During the lexical analysis of data, we check its content, but not its structure. We make sure that they contain the appropriate characters and have the correct encoding. If we find something suspicious, we can reject the data without even starting the analysis, which can crash the servers.
For example, when we expect to receive data with only numbers, we check if there is anything else in the stream. If we manage to find something, then we conclude: the data is either damaged by accident or intentionally formed in such a way as to deceive the system. In any case, it is better to refuse them. Similarly, if we expect to receive plain text in HTML format, we check if it has the appropriate content. That being said, every < character should be encoded as < , so we shouldn’t encounter any angle brackets. The presence of a corner bracket should be alarming. Maybe someone is trying to sneak in a piece of JavaScript? In order not to risk, the data is rejected again.
Lexical content defines what the data should look like on closer inspection, when we pay attention to individual details rather than larger structures. In many simple cases, simple regular expressions are excellent for checking lexical content. For example, the ISBN-10 format for books can only contain numbers and the letter X. The ISBN can also contain hyphens and spaces to make it easier to understand, but we’ll ignore them for simplicity. Listing 4.15 shows an extended version of the familiar ISBN class, which now checks whether an ISBN contains matching characters.

If you are dealing with more complex input, such as XML, you may want to use a more powerful lexer. A lexical analyzer breaks a sequence of characters into parts called tokens or lexemes. They can be considered as elementary components with meaning or sequences of symbols that form a syntactic unit. In written English, tokens are considered individual words. In XML, markers are tags and what is between them. Listings 4.16 and 4.17 show the XML document and its tokens.


In some situations where you don’t need the full power of XML, you can limit this format. In Chapter 1, I gave an example of how dangerous it is to allow XML entities on input data. The relatively short XML file shown in Listing 4.18 is less than 1,000 characters long. However, it expands to a billion lines lol, which will probably break our poor parser.
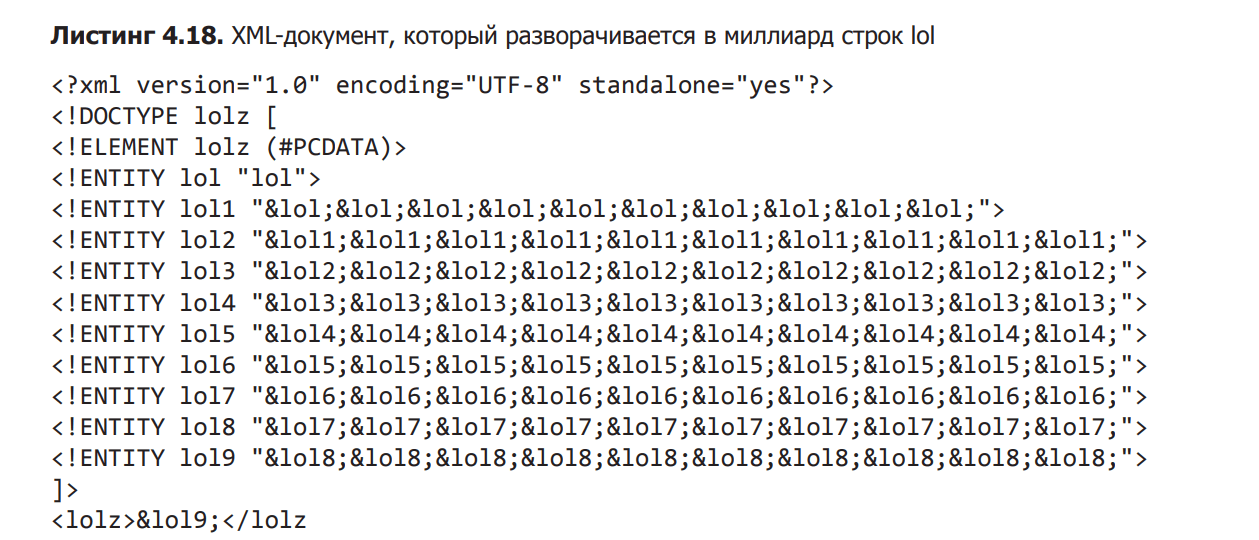
It goes without saying that a billion lines lol is an abuse of the parser that should not be allowed. To avoid this, you can prevent XML entity definitions from being used without recognizing the <! ENTITY as a valid token. If you are interested in the details, you can refer back to section 1.5.
In practice, working with XML documents most often consists in their analysis, aimed at extracting the elements that interest us. There is no need to analyze twice, first checking the lexical content and then analyzing the syntax of the structure. Instead, lexical checks can be performed as part of parsing. This is done by lexical parsing during streaming, which we did in Chapter 1. By making sure that your data comes from a trusted sender, is the right size, and contains the right types of tokens, you can allocate resources to further study it, such as parsing , to make sure they are properly formatted and structured.
It’s not uncommon for data to come in XML or JSON format and you need to parse it to make sense. In the previous section, we explained how to look at data closely—at the lexical level. By checking the syntax, we go up a level to see the big picture of what’s going on. In XML, we need to make sure that every opening tag has a closing tag and that the attributes inside the tags are well-formed.
Sometimes it is enough to use regular expressions for syntax checking. But to be honest, this approach is not always easy: we have seen many times how people create complex regular expressions that are sometimes impossible to understand. We advise you to choose this path only in simple cases. If looking at a regular expression gives you a headache, consider formatting that logic as code.
One example of a simple syntax checker is ISBN numbers. As already mentioned, the ISBN consists of nine valid digits and one check digit. The check digit can be 10, indicated by the letter X. ISBN syntax can be checked using a regular expression. This requires making sure that the data follows the format [0-9]{9}[0-9X]. If the test is successful, it means that the format is followed. If not, then the data should be rejected.
More complex data structures like XML require a parser. Analysis of large, complex structures requires significant computing resources. That is why the analyzer is often chosen as a target in a DoS attack on the system. Many of the previously described steps are implemented to protect it, including checks for provenance, data size, and lexical content.
We have already mentioned that as part of parsing, it is necessary to check whether the data arrived in a suitable form. To do this, we will use one of the most common mechanisms – the checksum. The ISBN is a good example because the last, tenth digit is the checklist. We will not go into the details of how the checksum is calculated, we will only note that this procedure is performed as part of the syntax check. Listing 4.19 shows another version of the ISBN class, this time with formatting and digit parsing.

If the syntax structure is fairly simple, it would be strange to perform a lexical and then a syntax check using similar regular expressions. In such situations, the validation data are often combined, as in Listing 4.20.

It may seem to you that the procedure for performing the correctness check is not followed here. In fact, lexical and syntactic parsing are so similar that we perform them using the same mechanism. You can think that they are combined or intertwined. The basic correctness check procedure is followed. So, after making sure the data is properly formatted and has the right content, size, and origin, we can compare it to the data we already have (if that makes sense).
After verifying the origin, size, content, and structure, you’ve come to trust the inputs so much that you’re ready to use them for further work. Up to this point, you could already perform checks that create a heavy load on the processor and require a lot of memory. For example, you might have processed a large XML message that says you need to add many items to an order. But before, we worked with input data in isolation from the rest of the system. And it’s likely that you’ve never accessed a database before.
In the example of a large XML message, you might want to extend the order by adding many elements, but you haven’t yet checked whether the corresponding elements exist, and you certainly don’t know if they do. This order may not exist at all or may have been shipped before, making it impossible to expand it. You just checked the syntax.
Now it’s time for a semantic check: Does this data make sense and is it consistent with the state of the rest of the system? During the semantic analysis, we check such things as the presence of a product number in the product catalog or the possibility of adding another product to the described order. We believe that the most logical place for such constraints is the domain model.
Searching the product catalog of your domain service can be expressed by checking the availability of the product number. If the product does not exist, an exception is thrown and the execution flow is interrupted. Similarly, if someone tries to add an item to an already closed order (which may have been paid for and shipped), it will be thrown as an IllegalStateException in the Order class. In fact, we believe that the domain model is such a natural place to put this logic that we don’t even consider it a validation check – to us, it’s part of the model itself.
However, we agree that semantic validation has a well-deserved place on the list of validation checks. Validation is always performed on something. You check whether the data conforms to some of the rules and constraints that make up the domain model. The model reflects the way you look at the world. You have modeled the order numbers in a certain format and made the orders uneditable after they have been shipped. After going through all these steps, you can be sure that the data corresponds to the model – it is verified.
At this point, we already know that the data comes from a trusted sender, is a reasonable size, has appropriate content and structure, and is consistent with the rest of the data. Now we can add the book to the cart, accept payment or transfer the order to the shipping department without risk.
If the code reflects the fact and degree of reliability of the data, it serves as a powerful protection at the design level. An example would be the ISBN class you saw earlier. This is a small composite element that is domain oriented and known to contain the ISBN in the correct format. There is no need for additional verification of this number. Our experience shows that the design of such constituent elements (we call them domain primitives or subject primitives area) does wonders for system security. It is time to discuss in detail how they are developed.
Data integrity is about ensuring its consistency and accuracy throughout its lifecycle.
Data availability is a guarantee that it can be retrieved with the expected level of system performance.
Immutable values can be safely shared between threads of execution without using locks: no locks – no conflicts.
The principle of immutability avoids problems with data availability, ensuring scalability without deadlocks between threads.
The principle of immutability solves the problems of data integrity by prohibiting their change.
Contracts are an efficient way to define clear responsibilities for objects and methods.
Better to shut down quickly in a predictable way without risking unexpected failures. Stop work quickly by checking prerequisites in each method.
Validity checking can be divided into provenance, data size, lexical content, syntactic format, and semantics.
To confirm the origin, you can check IP addresses or request an access key. This helps protect against DDoS attacks.
You can check the size of the data both when logging in to the system and when creating an object.
Lexical content validation can be performed using a simple regular expression (regexp).
A parser may be required to check the syntax format, which consumes more CPU time and memory.
Semantic verification most often involves accessing the database, for example, in searching for an element with a certain ID.
Inspections carried out in the early stages are more economical and serve as protection for later, more resource-intensive inspections. If early checks fail, other steps can be skipped.
We used materials from the book “Security by design”, which was written by Dan Berg Johnson, Daniel Deoghan, Daniel Savano.





