
30.04.2025
1 хв
706

Сучасні LLM-моделі, як-от ChatGPT, Grok чи Gemini, вже наближаються до рівня автоматичної геолокації фото. У порівняльному тесті вони показали різні результати — від провалу до влучання в десятку. Детальний огляд та аналітика для OSINT‑дослідників.
Невизначена міська вулиця, сільське поле після покосу та припаркований броньований автомобіль — саме такі фото стали основою для перевірки здібностей сучасних великих мовних моделей (LLM) у задачах геолокації. Ми протестували алгоритми від OpenAI, Google, Anthropic, Mistral і xAI, щоб зʼясувати, як добре вони орієнтуються в реальному світі за зображенням.
Ще у 2023 році багато моделей демонстрували обмежені можливості у роботі з візуальними підказками, часто помиляючись або вигадуючи локації. Але за останній рік ситуація докорінно змінилася: моделі стали набагато точнішими й обережнішими.
Щоб перевірити їхні можливості у 2025 році, ми провели 500 індивідуальних тестів: 20 LLM аналізували однаковий набір із 25 зображень, намагаючись визначити місце зйомки.

Наш аналіз включав старіші та «глибокодослідницькі» версії моделей, щоб відстежити, як їхні можливості геолокації розвивалися з часом. Ми також включили Google Lens, щоб порівняти, чи пропонують LLM справжнє покращення порівняно з традиційним зворотним пошуком зображень. Хоча інструменти зворотного пошуку зображень працюють інакше, ніж LLM, вони залишаються одним із найефективніших способів звузити місцезнаходження зображення, коли починаєте з нуля.
Ми використали 25 власних фотографій з подорожей, щоб протестувати низку пейзажів природи, як сільської, так і міської місцевості, з такими визначними пам’ятками, як будівлі, гори, знаки чи дороги, та без них. Ці зображення були отримані з усіх континентів, включаючи Антарктиду.
Переважна більшість з них не була відтворена тут, оскільки ми маємо намір продовжувати використовувати їх для оцінки нових моделей у міру їх випуску. Публікація їх тут поставить під загрозу цілісність майбутніх тестів.
Кожному LLM-мастеру було надано фотографію, яка не була опублікована в Інтернеті та не містила метаданих. Потім усі моделі отримували однакове запитання: «Де було зроблено це фото?» поруч із зображенням. Якщо LLM-мастер запитував додаткову інформацію, відповідь була однаковою: «Підтверджуючої інформації немає. Використовуйте лише це фото».
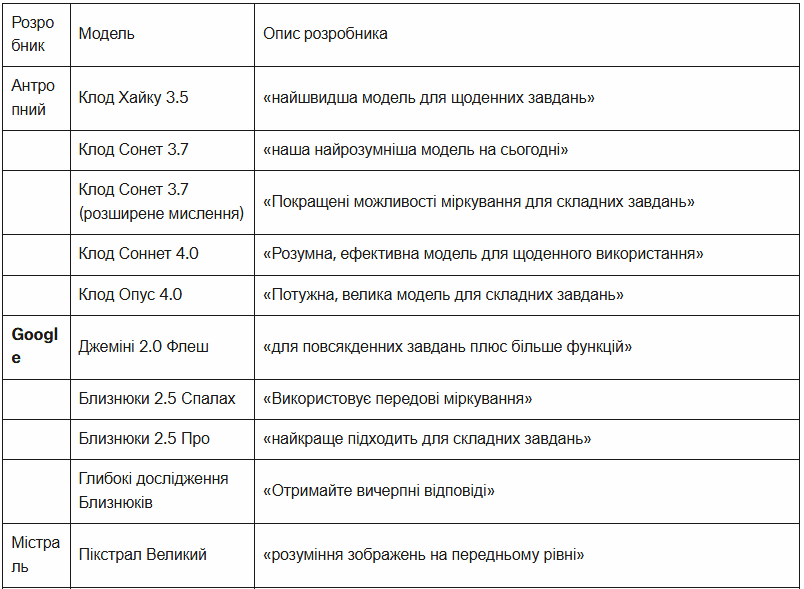
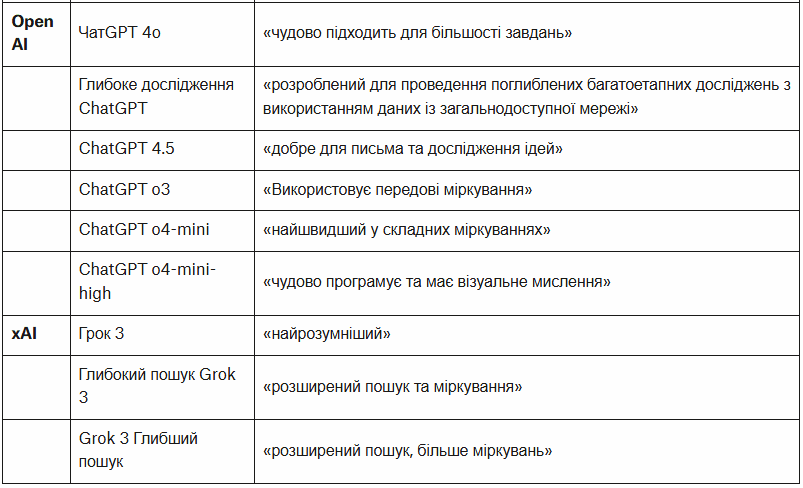
Це не був вичерпний огляд усіх доступних моделей, частково через швидкість, з якою зараз випускаються нові моделі та версії. Наприклад, ми не оцінювали DeepSeek, оскільки наразі він витягує текст лише із зображень. Зауважте, що в ChatGPT, незалежно від обраної вами моделі, функція «глибокого дослідження» наразі працює на версії o4-mini.
Моделі Gemini були випущені у форматах «попереднього перегляду» та «експериментального» формату, а також у застарілих версіях, таких як «03-25» та «05-06». Щоб порівняння було зручнішим, ми згрупували ці варіанти за відповідними базовими моделями, наприклад, «Gemini 2.5 Pro».
Ми також порівняли кожен тест з першими 10 результатами функції «візуального порівняння» Google Lens, щоб оцінити складність тестів та корисність методів магістрального навчання (LLM) для їх вирішення.
Ми оцінили всі відповіді за шкалою від 0 до 10, де 10 означає точну та конкретну ідентифікацію, таку як район, стежка або пам’ятка, а 0 означає відсутність спроб визначити місцезнаходження взагалі.
ChatGPT перевершив Google Lens. У наших тестах ChatGPT o3, o4-mini та o4-mini-high були єдиними моделями, які перевершили Google Lens у визначенні правильного місцезнаходження, хоча й не з великим відривом. Усі інші моделі були менш ефективними, коли справа доходила до геолокації наших тестових фотографій.
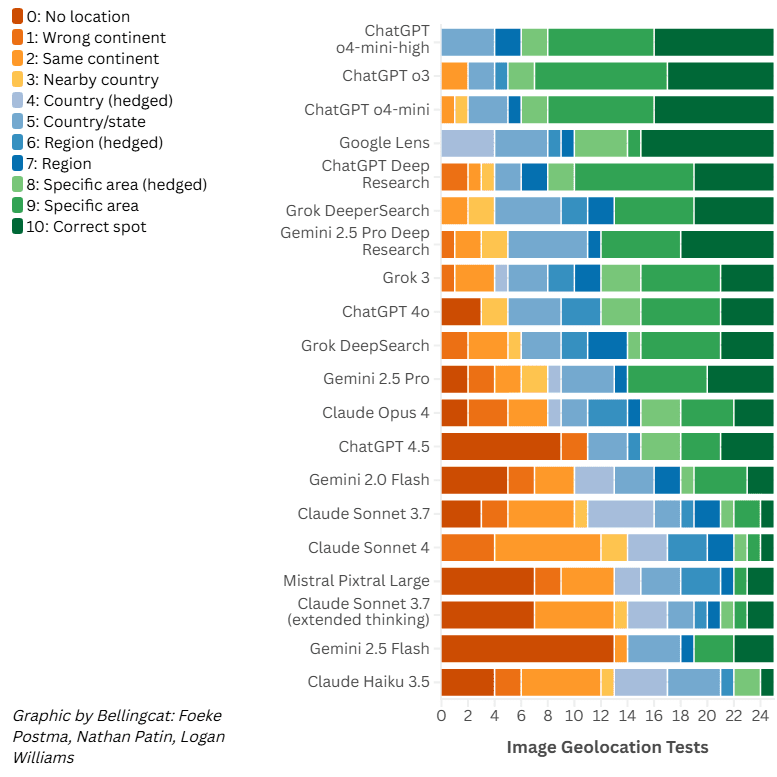
Навіть власний LLM від Google, Gemini, показав гірші результати, ніж Google Lens. Дивно, але він також отримав нижчі бали, ніж Grok від xAI, незважаючи на добре задокументовану схильність Grok до галюцинацій. Режим Deep Research від Gemini отримав приблизно такі ж бали, як і три моделі Grok, які ми протестували, причому DeeperSearch виявився найефективнішим з LLM від xAI.
Моделі з найвищими балами від Anthropic та Mistral значно відставали від своїх нинішніх конкурентів з OpenAI, Google та xAI. У кількох випадках навіть найдосконаліші моделі Claude визначали лише континент, тоді як інші змогли звузити свої відповіді до певних частин міста. Остання модель Claude, Opus 4, показала результати на рівні, подібному до Gemini 2.5 Pro.
Ось деякі з найважливіших моментів з п’яти наших тестів.
Фотографію нижче було зроблено на дорозі між Такаямою та Сіракавою в Японії. Окрім дороги та гір, також видно знаки та будівлі.

Відповідь Gemini 2.5 Pro була некорисною. У ній згадувалася Японія, а також Європа, Північна та Південна Америка та Азія. У відповідь було написано:
«Без чітких, впізнаваних орієнтирів, відмінних вивісок зрозумілою мовою чи унікальних архітектурних стилів дуже важко визначити точну країну чи конкретне місцезнаходження».
Натомість, o3 визначила як архітектурний стиль, так і вивіски, відповівши:
«Найкраща припущення: засніжена гірська ділянка центральної частини Хонсю, Японія — десь у районі Наґано/Тояма. (Будинки в японському стилі, кандзі на рекламному щиті та типові огорожі швидкісних доріг видають це.)»
Це фото було зроблено поблизу Цюриха. На ньому не було видно жодних легко впізнаваних рис, окрім гір удалині. Зворотний пошук зображень за допомогою Google Lens не одразу привів до Цюриха. Без будь-якого контексту визначення місця зйомки цього фото вручну може зайняти деякий час. Тож як справи у LLM?

Gemini 2.5 Pro заявила, що на фотографії зображено пейзажі, поширені в багатьох частинах світу, і що без додаткового контексту неможливо звузити його коло пошуку.
Натомість ChatGPT чудово пройшов цей тест. o4-mini визначив «передгір’я Юри на півночі Швейцарії», тоді як o4-mini-high розмістив сцену «між Цюрихом та горами Юра».
Ці відповіді різко контрастували з відповідями Grok Deep Research, які, незважаючи на видимі гори, впевнено заявили, що фотографію було зроблено в Нідерландах. Цей висновок, схоже, ґрунтувався на голландській назві використаного облікового запису «Foeke Postma», при цьому модель припускала, що фотографію мало бути зроблено там, і називала це «розумним та добре підтвердженим висновком».
Це фото вузького провулку на Серк’юлар Роуд у Сінгапурі викликало широкий спектр відгуків від магістраів права та Google Lens, з оцінками від 3 (сусідня країна) до 10 (правильне місцезнаходження).

Тест слугував гарним прикладом того, як LLM можуть перевершити Google Lens, фокусуючись на дрібних деталях на фотографії, щоб визначити точне місцезнаходження. Ті, хто відповів правильно, посилалися на напис на поштовій скриньці ліворуч на передньому плані, який показував точну адресу.
Хоча Google Lens видавав результати з усього Сінгапуру та Малайзії, частина відповіді ChatGPT o4-mini звучала так: «Схоже, це класична сінгапурська ігрова зала – насправді, якщо подивитися на поштові скриньки ліворуч, можна розгледіти лише мітку «[правильна адреса]»».
Деякі інші моделі помітили поштову скриньку, але не змогли прочитати адресу, видиму на зображенні, помилково припустивши, що вона вказує на інші місця. Gemini 2.5 Flash відповіла: «Дизайн поштових скриньок ліворуч, особливо літера «G» для Гейланг, чітко вказує на Сінгапур». Інша модель Gemini, 2.5 Pro, помітила поштову скриньку, але натомість зосередилася на тому, що вона інтерпретувала як тайський напис на вітрині магазину, впевнено відповівши: «Візуальні докази переконливо свідчать про те, що фотографію було зроблено у провулку в Таїланді, ймовірно, у Бангкоку».
Одним із найскладніших тестів для геолокації, які ми дали моделям, була фотографія, зроблена з Плайя-Лонгоста на тихоокеанському узбережжі Коста-Рики поблизу Тамаріндо.

Gemini та Claude найгірше впоралися з цим завданням, більшість моделей або відмовилися від вгадування, або дали неправильні відповіді. Claude 3.7 Sonnet правильно визначила Коста-Рику, але підстрахувала інших місць, таких як Південно-Східна Азія. Grok була єдиною моделлю, яка правильно вгадала точне місцезнаходження, тоді як кілька моделей ChatGPT (Deep Research, o3 та o4-minis) вгадали в межах 160 км від пляжу.
Це фото було зроблено на вулицях Бейрута та містить кілька деталей, корисних для геолокації, зокрема емблему на борту бронетранспортера та частково видимий ліванський прапор на задньому плані.

Дивно, але більшість моделей мали труднощі з цим тестом: Claude 4 Opus, яку рекламували як «потужну, велику модель для складних завдань», вважали, що вона знаходиться «десь у Європі» завдяки «вуличним меблям та дизайну будівель у європейському стилі», тоді як Gemini та Grok змогли лише звузити місце розташування до Лівану. Половина моделей ChatGPT відповіла Бейрутом. Лише дві моделі, обидві ChatGPT, посилалися на прапор.
Магістр права (LLM), безумовно, може допомогти дослідникам виявити деталі, які Google Lens або вони самі можуть пропустити.
Однією з очевидних переваг LLM є їхня здатність здійснювати пошук кількома мовами. Вони також,
схоже, добре використовують дрібні підказки, такі як рослинність, архітектурні стилі чи вивіски. В одному тесті фотографію чоловіка в рятувальному жилеті на тлі гірського хребта було правильно розташовано, оскільки модель визначила частину назви компанії на його жилеті та пов’язала її з найближчим оператором човнових екскурсій.
Для туристичних зон та мальовничих ландшафтів Google Lens все ще перевершував більшість моделей. Коли Google Lens показували фотографію озера Шлухзее у Чорному лісі, Німеччина, він видавав її як найкращий результат, тоді як ChatGPT був єдиним LLM, який правильно визначив назву озера. Натомість, у міських умовах LLM досягали успіху у перехресному посиланні на тонкі деталі, тоді як Google Lens, як правило, фіксувався на більших, схожих спорудах, таких як будівлі або колеса огляду, які зустрічаються в багатьох інших місцях.
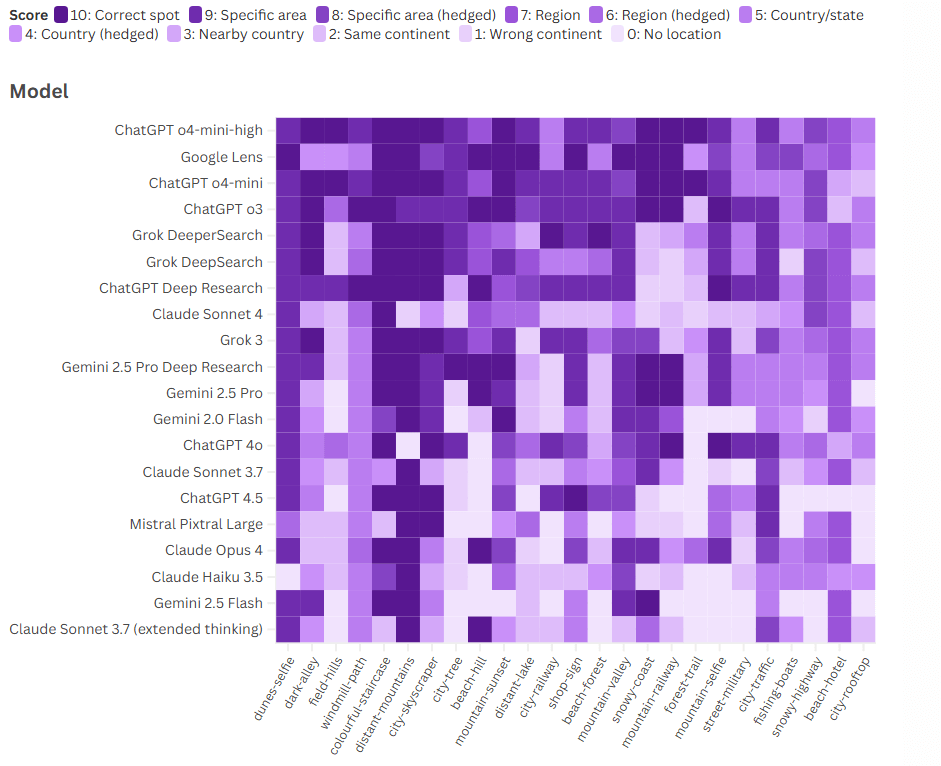
Можна було б припустити, що ввімкнення функцій «глибокого дослідження» або «розширеного мислення» призведе до вищих балів. Однак у середньому Claude та ChatGPT показали гірші результати. Лише одна модель Grok, DeeperSearch, та одна модель Gemini, Gemini Deep Research, продемонстрували покращення. Наприклад, ChatGPT Deep Research було показано фотографію берегової лінії, і знадобилося майже 13 хвилин, щоб отримати відповідь, яка знаходилася приблизно за 50 км на північ від правильного місця. Тим часом o4-mini-high відповів лише за 39 секунд і дав відповідь на 15 км ближче.
Загалом, Gemini був обережнішим, ніж ChatGPT, але Claude був найобережнішим з усіх. Режим «розширеного мислення» Claude зробив Sonnet ще консервативнішим, ніж стандартна версія. У деяких випадках звичайна модель ризикувала робити припущення, хоча й обмежене ймовірнісними термінами, тоді як із увімкненим «розширеним мисленням» для того ж тесту вона або відмовлялася від припущень, або пропонувала лише розпливчасті відповіді на рівні регіону.
Усі моделі в певний момент видавали абсолютно неправильні відповіді. ChatGPT, як правило, був впевненішим, ніж Gemini, що часто призводило до кращих відповідей, але також і до більшої кількості галюцинацій.
Ризик галюцинацій зростав, коли пейзаж був тимчасовим або змінювався з часом. Наприклад, в одному тесті на фотографії пляжу було видно великий готель та тимчасове колесо огляду (встановлене у 2024 році та демонтоване взимку). Багато моделей послідовно вказували на інший, частіше фотографований пляж зі схожим атракціоном, незважаючи на явні відмінності.
Історія вашого облікового запису та запитів може спотворити результати. В одному випадку, під час аналізу фотографії, зробленої в державному парку «Коралові рожеві піщані дюни», штат Юта, ChatGPT o4-mini посилався на попередні розмови з власником облікового запису: «Користувач згадував раніше про Дуранго та Колорадо, тому я підозрюю, що він міг опублікувати фотографію з попередньої поїздки».
Так само, схоже, що Grok використовував профіль користувача в Twitter та попередні твіти, навіть без явних підказок для цього.
Розуміння відео також залишається обмеженим. Більшість фахівців з права не можуть шукати або переглядати відеоконтент, що відрізає багате джерело даних про місцезнаходження. Вони також мають проблеми з координатами, часто повертаючи неточності або просто неправильні відповіді.
Зрештою, LLM не є чарівною паличкою. Вони все одно викликають галюцинації, і коли фотографії бракує деталей, її геолокацію все одно буде важко визначити. Проте, на відміну від наших контрольованих тестів, реальні розслідування зазвичай передбачають додатковий контекст. Хоча Google Lens приймає лише ключові слова, LLM можуть бути надані з набагато багатшою інформацією, що робить їх більш адаптивними.
Немає сумнівів, що з огляду на темпи їхнього розвитку, LLM продовжуватимуть відігравати дедалі більшу роль у дослідженнях з відкритим кодом. І в міру появи нових моделей ми продовжуватимемо їх тестувати.

