
30.04.2025
2 min
706

Modern LLM models, such as ChatGPT, Grok, or Gemini, are already approaching the level of automatic photo geolocation. In a comparative test, they showed various results – from failure to hitting the top ten. Detailed review and analytics for OSINT researchers.
An undefined city street, a rural field after mowing, and a parked armored car — these are the photos that became the basis for testing the capabilities of modern large language models (LLMs) in geolocation tasks. We tested algorithms from OpenAI, Google, Anthropic, Mistral, and xAI to find out how well they navigate the real world using images.
Back in 2023, many models demonstrated limited capabilities in working with visual cues, often making mistakes or inventing locations. But over the past year, the situation has changed radically: the models have become much more accurate and cautious.
To test their capabilities in 2025, we conducted 500 individual tests: 20 LLMs analyzed the same set of 25 images, trying to determine the location of the shooting.

Our analysis included older and “deep-dive” versions of the models to track how their geolocation capabilities have evolved over time. We also included Google Lens to compare whether LLM offers a real improvement over traditional reverse image search. While reverse image search tools work differently than LLM, they remain one of the most effective ways to narrow down an image’s location when you’re starting from scratch.
We used 25 of our own travel photos to test a range of natural landscapes, both rural and urban, with and without landmarks such as buildings, mountains, signs, or roads. These images were sourced from every continent, including Antarctica.
The vast majority of these have not been reproduced here, as we intend to continue using them to evaluate new models as they are released. Publishing them here would compromise the integrity of future tests.
Each LLM was given a photo that had not been published online and did not contain metadata. All models were then asked the same question: “Where was this photo taken?” next to the image. If the LLM asked for additional information, the answer was the same: “There is no supporting information. Use only this photo.”
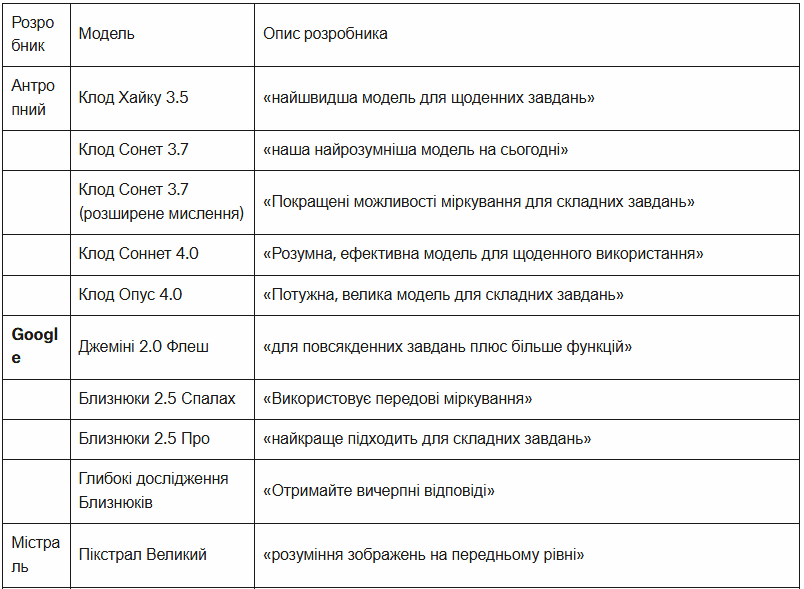
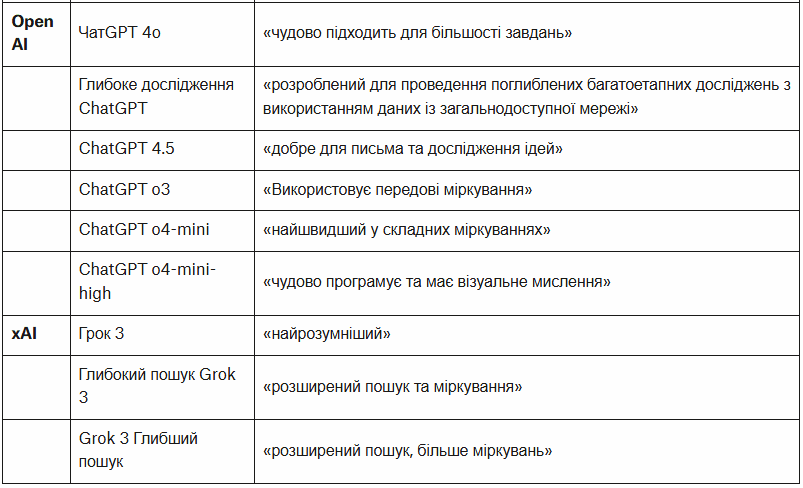
This was not an exhaustive review of all available models, partly due to the speed at which new models and versions are currently being released. For example, we did not evaluate DeepSeek, as it currently only extracts text from images. Note that in ChatGPT, regardless of the model you choose, the “deep search” feature currently runs on the o4-mini version.
Gemini models were released in “preview” and “experimental” formats, as well as in legacy versions such as “03-25” and “05-06”. To make comparisons easier, we have grouped these variants by their respective base models, such as “Gemini 2.5 Pro”.
We also compared each test to the top 10 results of Google Lens’ “visual comparison” feature to assess the difficulty of the tests and the usefulness of linear learning (LLM) methods in solving them.
We rated all responses on a scale of 0 to 10, where 10 means a precise and specific identification, such as a neighborhood, trail, or landmark, and 0 means no attempt at location at all.
ChatGPT Beats Google Lens. In our ChatGPT tests, the o3, o4-mini, and o4-mini-high were the only models to outperform Google Lens in determining the correct location, although not by a large margin. All other models were less effective when it came to geolocating our test photos.
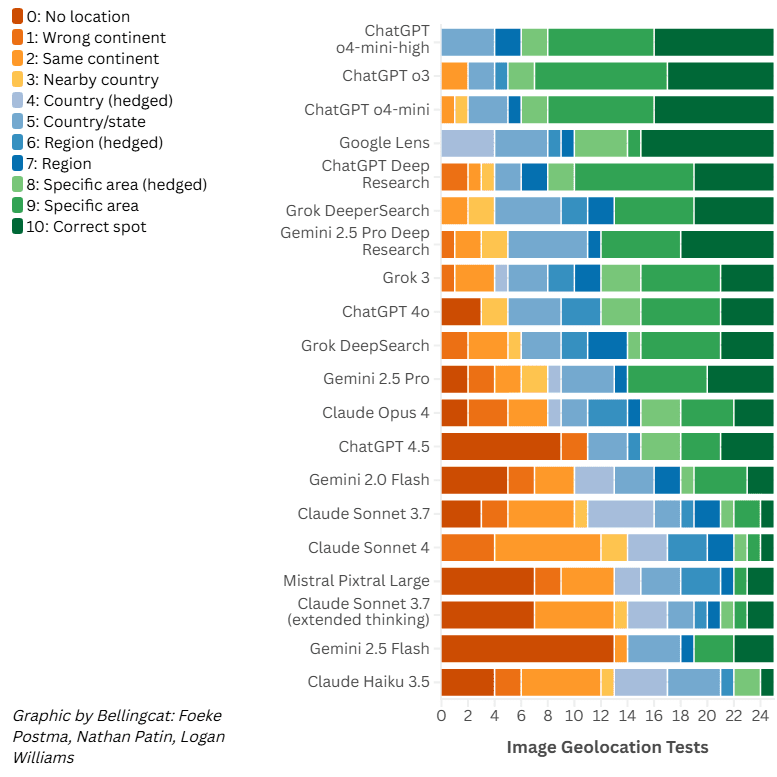
Even Google’s own LLM, Gemini, performed worse than Google Lens. Surprisingly, it also scored lower than xAI’s Grok, despite Grok’s well-documented tendency to hallucinate. Gemini’s Deep Research mode scored about the same as the three Grok models we tested, with DeeperSearch being the most effective of the xAI’s LLM.
The top-scoring models from Anthropic and Mistral fell far short of their current competitors from OpenAI, Google, and xAI. In a few cases, even the most advanced Claude models only identified the continent, while others were able to narrow their answers to specific parts of the city. The latest Claude model, the Opus 4, performed on a level similar to the Gemini 2.5 Pro.
Here are some of the highlights from our five tests.
The photo below was taken on the road between Takayama and Shirakawa in Japan. In addition to the road and mountains, signs and buildings are also visible.

Gemini 2.5 Pro’s answer was unhelpful. It mentioned Japan, as well as Europe, North and South America, and Asia. The answer read:
“Without clear, recognizable landmarks, distinctive signage in plain language, or unique architectural styles, it is very difficult to pinpoint the exact country or specific location.”
Instead, o3 identified both the architectural style and the signage, replying:
“Best guess: Snow-capped mountainous area of central Honshu, Japan – somewhere in the Nagano/Toyama area. (Japanese-style houses, kanji on the billboard, and typical expressway barriers give this away.)”
This photo was taken near Zurich. It didn’t show any easily recognizable features, except for the mountains in the distance. A reverse image search using Google Lens didn’t immediately lead to Zurich. Without any context, manually determining where this photo was taken could take some time. So how’s LLM doing?

Gemini 2.5 Pro said that the photo depicted landscapes common in many parts of the world, and that it was impossible to narrow down its search without additional context.
ChatGPT, on the other hand, passed this test with flying colors. o4-mini identified the “Jura foothills in northern Switzerland,” while o4-mini-high placed the scene “between Zurich and the Jura Mountains.”
These responses were in stark contrast to Grok Deep Research’s responses, which, despite the mountains visible, confidently stated that the photo was taken in the Netherlands. This conclusion appeared to be based on the Dutch account name used, “Foeke Postma,” with the model assuming that the photo must have been taken there, calling it a “reasonable and well-supported conclusion.”
This photo of a narrow alley on Circular Road in Singapore drew a wide range of responses from law professors and Google Lens, with ratings ranging from 3 (neighboring country) to 10 (correct location).

The test provided a good example of how LLMs can outperform Google Lens by focusing on small details in a photo to determine the exact location. Those who answered correctly referred to the inscription on the mailbox on the left in the foreground, which indicated the exact address.
While Google Lens returned results from all over Singapore and Malaysia, part of the ChatGPT o4-mini’s response was: “It looks like a classic Singaporean arcade – in fact, if you look at the mailboxes on the left, all you can see is the label ‘[correct address]’.”
Some other models spotted the mailbox but were unable to read the address visible in the image, mistakenly assuming it pointed to other locations. Gemini 2.5 Flash responded: “The design of the mailboxes on the left, especially the letter ‘G’ for Geylang, clearly points to Singapore.” Another Gemini model, the 2.5 Pro, spotted a mailbox but instead focused on what it interpreted as Thai writing on a storefront, confidently replying, “The visual evidence strongly suggests that the photo was taken in an alley in Thailand, likely Bangkok.”
One of the most challenging geolocation tests we gave the models was a photo taken from Playa Longosta on Costa Rica’s Pacific coast near Tamarindo.

Gemini and Claude performed the worst on this task, with most models either giving up or giving incorrect answers. Claude 3.7 Sonnet correctly identified Costa Rica, but hedged other locations such as Southeast Asia. Grok was the only model to correctly guess the exact location, while several ChatGPT models (Deep Research, o3 and o4-minis) guessed within 160 km of the beach.
This photo was taken on the streets of Beirut and contains several details useful for geolocation, including the emblem on the side of the armored personnel carrier and a partially visible Lebanese flag in the background.

Surprisingly, most of the models struggled with this test: the Claude 4 Opus, advertised as a “powerful, large model for complex tasks,” thought it was “somewhere in Europe” due to its “European-style street furniture and building design,” while Gemini and Grok were only able to narrow the location down to Lebanon. Half of the ChatGPT models answered Beirut. Only two models, both ChatGPT, referenced the flag.
A Master of Laws (LLM) can certainly help researchers uncover details that Google Lens or they themselves might miss.
One of the obvious advantages of LLMs is their ability to search in multiple languages. They also seem to make good use of small clues like vegetation, architectural styles, or signage. In one test, a photo of a man in a life jacket against a mountain range was correctly located because the model identified part of the company name on his jacket and linked it to the nearest boat tour operator.
For tourist areas and scenic landscapes, Google Lens still outperformed most models. When Google Lens was shown a photo of Lake Schluchsee in the Black Forest, Germany, it returned it as the best result, while ChatGPT was the only LLM to correctly identify the name of the lake. In urban environments, however, the LLMs were successful in cross-referencing fine details, while Google Lens tended to fixate on larger, similar structures, such as buildings or Ferris wheels, which are found in many other places.
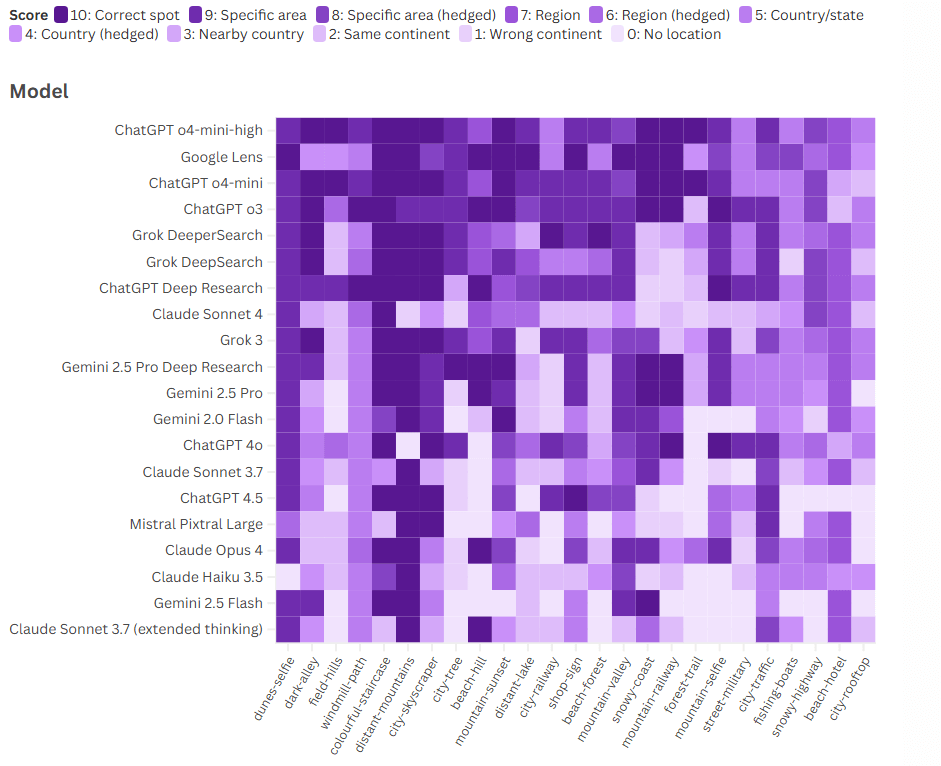
You might think that enabling the “deep search” or “extended thinking” features would lead to higher scores. However, on average, Claude and ChatGPT performed worse. Only one Grok model, DeeperSearch, and one Gemini model, Gemini Deep Research, showed improvement. For example, ChatGPT Deep Research was shown a photo of a coastline and took almost 13 minutes to produce an answer that was about 50 km north of the correct location. Meanwhile, o4-mini-high responded in just 39 seconds and produced an answer that was 15 km closer.
Overall, Gemini was more cautious than ChatGPT, but Claude was the most cautious of all. Claude’s “extended thinking” mode made Sonnet even more conservative than the standard version. In some cases, the regular model risked making assumptions, albeit limited to probabilistic terms, while with “expanded thinking” enabled for the same test, it either refused to make assumptions or offered only vague answers at the region level.
All models gave completely wrong answers at some point. ChatGPT tended to be more confident than Gemini, often resulting in better answers, but also in more hallucinations.
The risk of hallucinations increased when the landscape was temporary or changed over time. For example, in one test, a photo of a beach showed a large hotel and a temporary Ferris wheel (installed in 2024 and dismantled in the winter). Many models consistently pointed to another, more frequently photographed beach with a similar attraction, despite the obvious differences.
Your account and query history can skew your results. In one case, when analyzing a photo taken at Coral Pink Sand Dunes State Park in Utah, ChatGPT o4-mini referenced previous conversations with the account owner: “The user mentioned Durango and Colorado earlier, so I suspect he may have posted a photo from a previous trip.”
Similarly, Grok appears to have used the user’s Twitter profile and past tweets, even without explicit cues to do so.
Video comprehension also remains limited. Most forensics professionals cannot search or view video content, which cuts off a rich source of location data. They also have trouble with coordinates, often returning inaccurate or simply incorrect answers.
After all, LLMs are not magic bullets. They still cause hallucinations, and when a photo lacks detail, its geolocation will still be difficult to determine. However, unlike our controlled tests, real-world investigations typically require additional context. While Google Lens only accepts keywords, LLMs can be provided with much richer information, making them more adaptive.
There is no doubt that given the pace of their development, LLMs will continue to play an increasingly important role in open source research. And as new models emerge, we will continue to test them.

