
22.01.2024
1 хв
1762

ETSI SAI — нові стандарти безпеки ШІ. Дізнайтесь, як Європейський інститут телекомунікацій впроваджує сучасні вимоги до захисту штучного інтелекту. У першій частині розглядаємо основні технічні документи: від тестування моделей до захисту supply chain і вимог explainability. Стаття корисна для розробників, аналітиків та ІТ-безпеки. Читайте гайд з впровадження на практиці.

Штучний інтелект стрімко розвивається, однак разом із можливостями зростають і загрози. Промпт-інʼєкції, зловживання агентами, уразливості в оркестрації — спектр ризиків для ІІ постійно розширюється. Поки США й Китай змагаються в потужності генеративних моделей, Європа зосередилась на розробці стандартів безпеки.
Для цього в межах Європейського інституту телекомунікаційних стандартів (ETSI) було створено Комітет захисту штучного інтелекту — SAI (Securing Artificial Intelligence). Основна мета — розробка практичних специфікацій, які покривають усі етапи життєвого циклу ІІ-систем: від навчання й постачання даних до впровадження та виведення з експлуатації. Наразі вже опубліковано 10 звітів — частина з них залишилась актуальною, інші морально застаріли за останні місяці.
Цей матеріал відкриває серію публікацій із детальним аналізом документів ETSI SAI. У першій частині — огляд базових звітів, що заклали фундамент у підходах до кібербезпеки ШІ в Європі.
ETSI — незалежна некомерційна організація, офіційно визнана Євросоюзом поряд із CEN та CENELEC. Вона розробляє стандарти для телекомунікацій, кібербезпеки й цифрових технологій, які безпосередньо впливають на вимоги до компаній, що працюють у ЄС. Саме ETSI стоїть за сертифікаціями типу CE, які часто можна побачити на електроніці, іграшках та телеком-обладнанні.
Комітет SAI працює в чотирьох напрямах:
захист ІІ-компонентів від атак;
зменшення ризиків у ІІ-системах;
застосування ІІ для посилення кіберзахисту;
врахування етичних і соціальних аспектів у сфері безпеки.
Далі — стислий огляд опублікованих документів ETSI SAI, що вже доступні для вивчення.
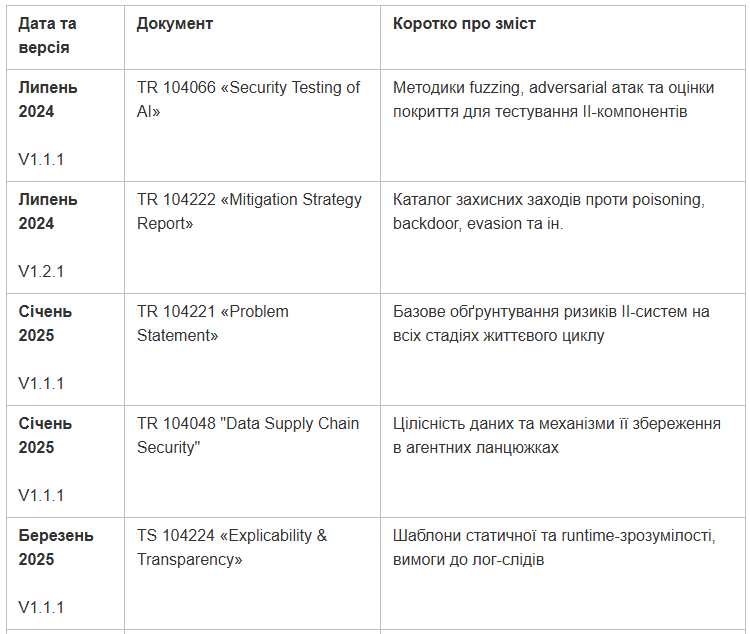

Виходячи з таблиці вище, ви можете звернути увагу на те, що документи виходили не разом, а з розривом у часі і це буде важливо, коли ми почнемо їх розбирати детальніше.
Перша хвиля (07-2024) – методологія: тестування та каталог контрзаходів.
Друга хвиля (01-2025) – фундамент: формулювання проблем та безпека ланцюжка даних.
Третя хвиля (03-2025) – тематичні специфікації для загроз, прозорості та контролів.
Четверта хвиля (04-2025) – єдиний базовий набір вимог для впровадження.
П’ята хвиля (05-2025) – ув’язування із законодавством (AI Act) і гайд з практичної реалізації.
Таким чином, історичність показує послідовний перехід від опису загроз і тестів → до процесних вимог → до регуляторного меппінгу та керівництва з впровадження в агентних AI-системах.
Давайте розбиратися з документами.
Документ зосереджений на передиктивних ML-моделях та описує методики fuzzing, differential testing і низку adversarial‑алгоритмів. Утім, специфічні загрози для генеративного ШІ — такі як prompt‑injection, jailbreak або атаки на LLM — у ньому не згадуються. Хоча градієнтні атаки теоретично можуть застосовуватись і до genAI-систем, на практиці вони вже не є основною тактикою атак.
Матеріал не містить готових практичних прикладів чи коду — лише математичні формули, псевдокод і порівняльні таблиці ефективності. Це радше довідник із базових технік тестування стійкості нейромереж, ніж прикладне керівництво.
Для тих, хто шукає реальні кейси або рецепти для red teaming генеративних моделей, доцільніше звернутися до OWASP Red Team Guide.
Тут є таксономія атак на ML моделі (CV, NLP, аудіо), явної згадки LLM немає, хоча документ вийшов у 2024 році, це пояснюється тим, що перша версія була підготовлена в далекому 2021 і, мабуть, автори хотіли просто довести до релізу розпочате і не чіпати тему мовних моделей.
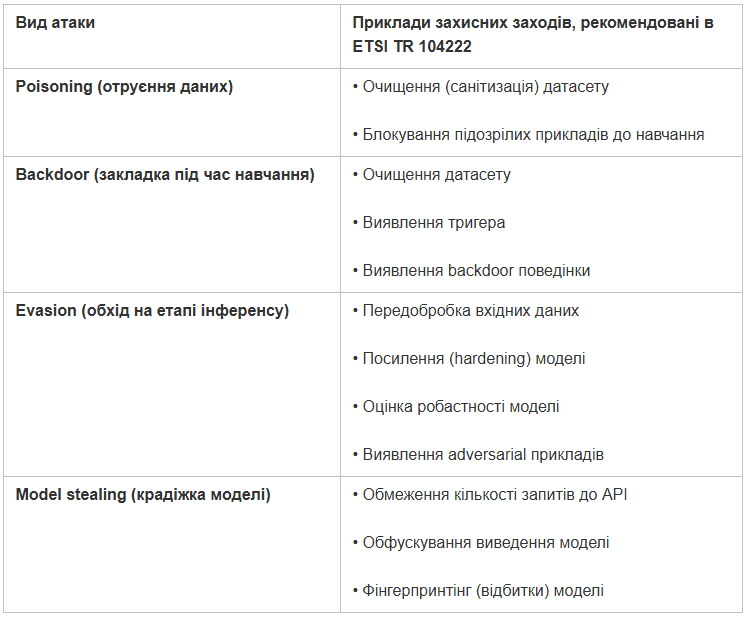
Нижче наведено приклад таксономії атак, поданий у скороченому вигляді для зручності сприйняття. Незважаючи на стислий формат, структура зберігає основну ідею та логіку класифікації.
Підсумок документа, автори визнають, що матеріал знову ж таки академічний, конкретних рекомендацій чи заклик до дії ви тут не знайдете, а шкода, назва обнадіювала.
Перший описує загрози для систем машинного навчання по двох осях – етап життєвого циклу та тип атаки/зловживання. До проблем з таблиці вище, додають два нових класи:
Некоректне використання штучного інтелекту:
обхід ad-blocker
обфускація шкідливого коду
deepfake-контент
підробка почерку чи голосу
фейкові листування та ін.
І Системні / процесні ризики:
упередженість,
етичні огріхи,
відсутність зрозумілості,
вразливості ПЗ/заліза
На повноцінну модель загроз не тягне документ невеликий, більше схожий на мемо для розсилки по корпоративній пошті.
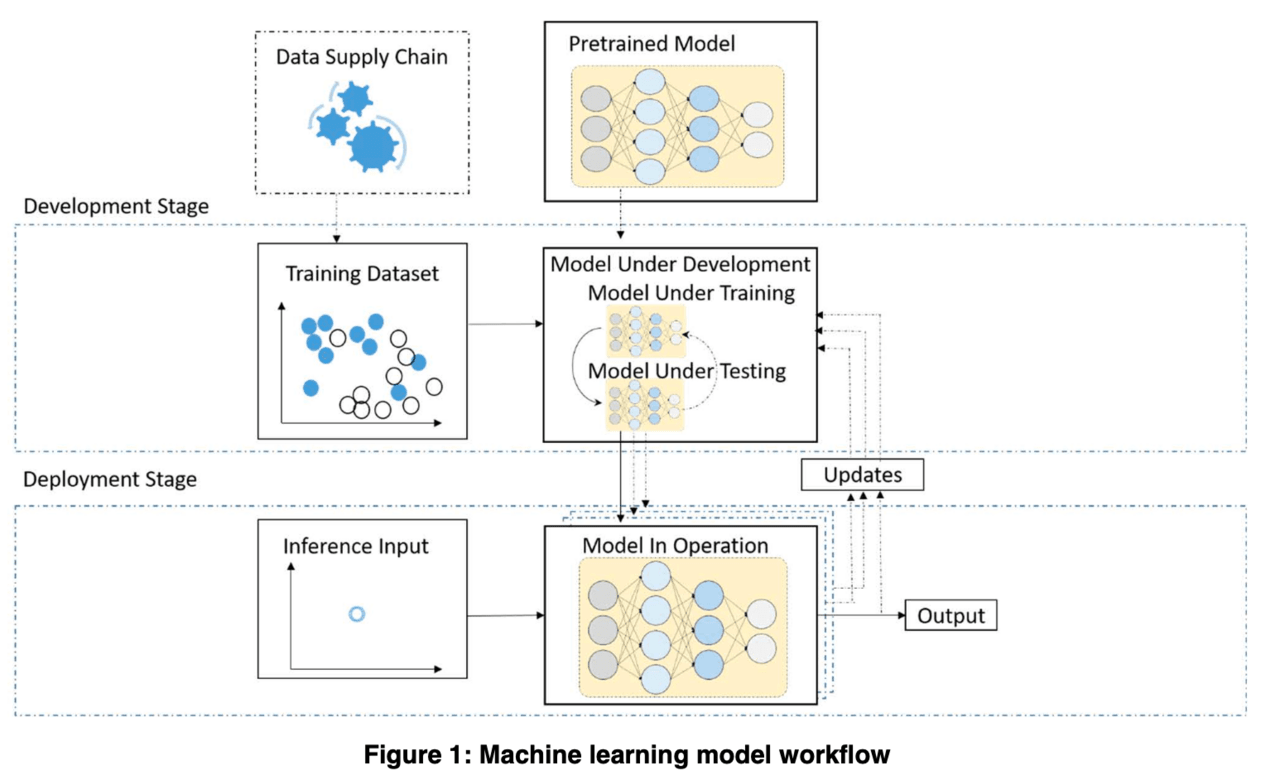
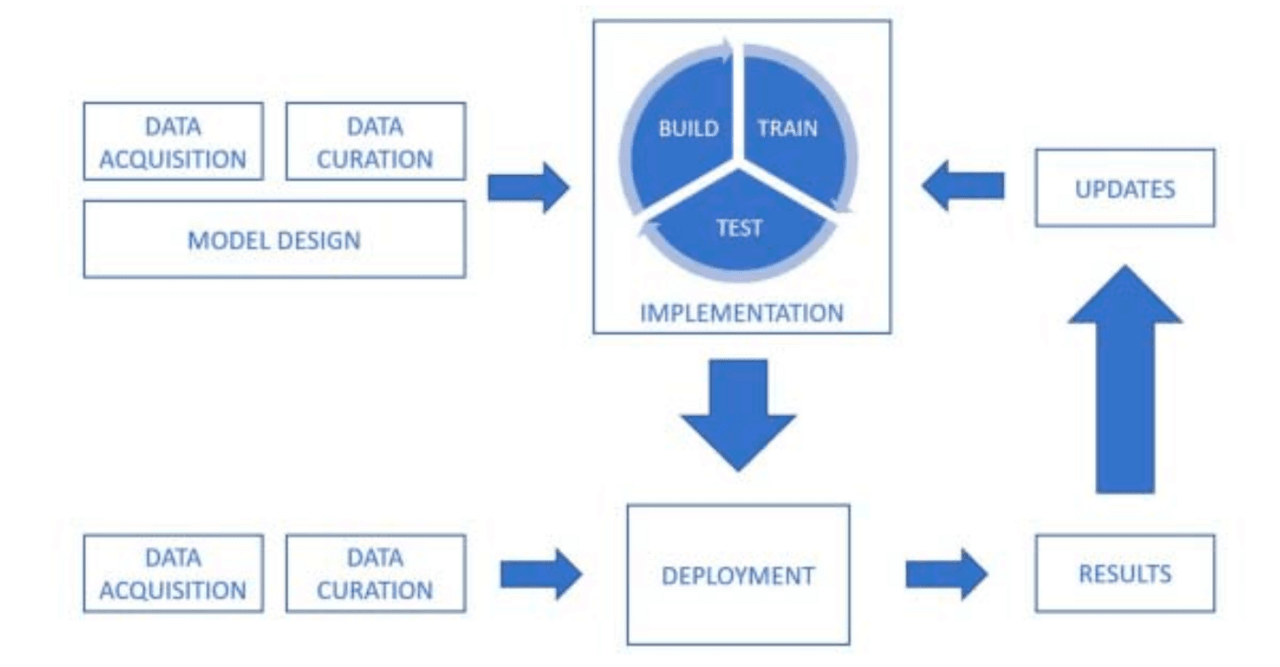
Другий документ знову стосується теми датасетів та захисту від різноманітних отруєнь даних та компрометації системи навчання. Нижче наведено ілюстрацію пайплайна навчання, навколо якого документ побудовано.
Наприкінці документа наведено рекомендації щодо захисту supply chain для моделей:
Хеш-суми можуть використовуватись для ефективного захисту цілісності даних. Під час перевірки цілісності даних.
Донавчання моделей з використанням перевірених чи довірених даних
Дотримання стандартних рекомендацій щодо кібербезпеки, таких як принцип мінімальних привілеїв при доступі до даних та ланцюжка поставок.
Логування на всіх етапах обробки та розгортання, включаючи збір телеметрії моделі.
Документ, який занурює читача у такі поняття:
Transparency – система “відкрита для перевірки”, у неї “немає прихованих частин”; будь-яку операцію можна піддати зовнішньому аудиту
Explicability — здатність показати, як саме система дійшла результату («показати розв’язання задачі крок за кроком»)

Для забезпечення прозорості ІІ систем автори пропонують такі дії:
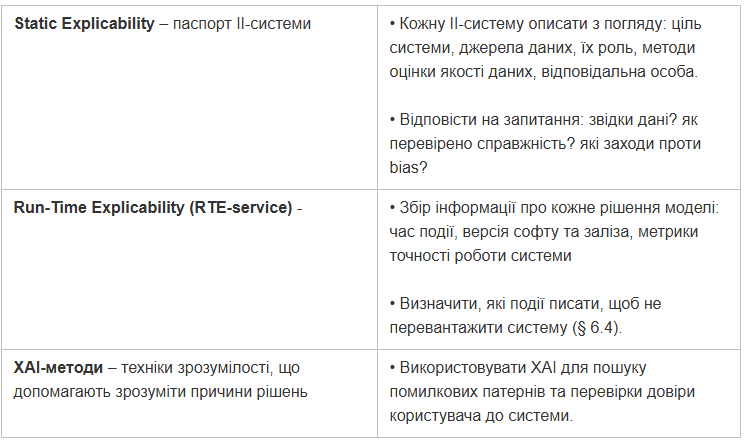
Побіжно розглянемо TR 104030 «Critical Security Controls for AI Sector». По суті, документ відповідає на єдине запитання: чи потрібно міняти перелічені в старішому чеклісті ETSI TR 103305 методи тестування для AI-систем. Деякі засоби контролю за безпекою з першоджерела нижче:
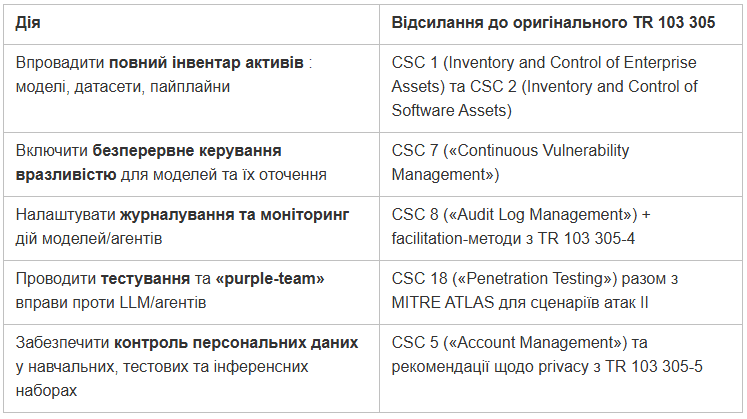
Звіт підтверджує застосування існуючої методики Critical Security Controls і не вводить нових методик.
На цьому етапі розбір документів робочої групи Securing Artificial Intelligence ETSI тимчасово зупиняється. Значна частина звітів зосереджена на класичних ML-моделях і не охоплює специфіку LLM або агентних систем. У наступній частині буде розглянуто найновіші травневі документи, пов’язані з EU AI Act, який уже набув чинності й частково охоплює актуальні виклики генеративного ШІ та агентних архітектур.

