
08.01.2026
2 хв
657

Bash часто сприймають як щось просте – набір команд для терміналу. Але щойно з’являються функції та логіка автоматизації, він перетворюється на повноцінний інструмент, який реально економить час. У цій статті мова піде про те, як крок за кроком перейти від розрізнених команд до зрозумілих і керованих Bash-скриптів, які можна використовувати щодня.
Матеріал підійде тим, хто вже знайомий з базами Bash і хоче рухатися далі – навчитися структурувати код, уникати повторів і автоматизувати типові завдання. Без перевантаження термінами, без «магії», тільки логіка, приклади й практичне мислення. Це хороший старт для тих, хто хоче, щоб Bash працював на нього, а не навпаки.

Ніколи не переписуйте код, використовуйте функції.

Коли Bash-скрипти стають усе більшими, в них дуже легко навести безлад. У якийсь момент ви можете помітити, що знову і знову переписуєте одні й ті самі фрагменти коду в різних частинах скрипта. На щастя, цього можна уникнути, використовуючи функції в Bash.
Вони допомагають упорядкувати код і зробити скрипти більш читабельними. У цьому посібнику ви навчитеся створювати функції, повертати значення з функцій і передавати їм аргументи в Bash-скриптах. Також ви розберетеся, як працює область видимості змінних і як оголошувати рекурсивні функції.
У Bash існує два різні синтаксиси для оголошення функцій. Нижче наведено найпоширеніший спосіб створення функцій у Bash:
function_name () {
commands
}
Другий, менш поширений спосіб створення функцій у Bash починається із зарезервованого слова function, після якого вказується назва функції, наприклад:
function function_name {
commands
}
Тепер є кілька важливих моментів, про які варто пам’ятати під час роботи з функціями:
Функція ніколи не буде виконана, якщо ви її явно не викличете.
Оголошення функції має знаходитися вище за будь-який її виклик.
Щоразу, коли вам потрібно виконати функцію, достатньо просто її викликати. Виклик функції здійснюється шляхом звернення до її імені.
Подивіться на наступний Bash-скрипт fun.sh:
#!/bin/bash
hello () {
echo "Hello World"
}
hello
hello
hello
Оголошено функцію з назвою hello, яка просто виводить у термінал рядок «Hello World». Зверніть увагу, що функцію hello викликають тричі, тому під час запуску скрипта рядок «Hello World» з’являється на екрані три рази.
kabary@handbook:~$ ./fun.sh Hello World Hello World Hello World
У багатьох мовах програмування функції повертають значення під час виклику. У Bash усе інакше, оскільки функції Bash не повертають значення напряму.
Коли функція Bash завершує виконання, вона повертає код завершення останньої виконаної команди, який зберігається у змінній $?.
Значення 0 означає успішне виконання, а будь-яке ненульове додатне число від 1 до 255 вказує на помилку.
Для зміни коду завершення функції можна використовувати оператор return. Наприклад, розгляньте наступний скрипт error.sh:
#! /bin/bash
error () {
blabla
return 0
}
error
echo "The return status of the error function is: $?"
Якщо запустити Bash-скрипт error.sh, результат може вас здивувати:
kabary@handbook:~$ ./error.sh ./error.sh: line 4: blabla: command not found The return status of the error function is: 0
Без оператора return 0 функція error ніколи б не повернула ненульовий код завершення, оскільки blabla призводить до помилки command not found.
Як видно, попри те що функції Bash не повертають значення напряму, цю поведінку можна обійти, змінюючи код завершення функції.
Також варто пам’ятати, що оператор return одразу завершує виконання функції.
Аргументи у функцію можна передавати так само, як і в Bash-скрипт. Для цього достатньо вказати аргументи під час виклику функції.
Для прикладу розгляньмо наступний Bash-скрипт iseven.sh:
#!/bin/bash
iseven () {
if [ $(($1 % 2)) -eq 0 ]; then
echo "$1 is even."
else
echo "$1 is odd."
fi
}
iseven 3
iseven 4
iseven 20
iseven 111
Функція iseven() перевіряє, чи є число парним або непарним. Функцію iseven() викликають чотири рази. Під час кожного виклику передається одне число, яке є першим аргументом функції та доступне всередині її оголошення через змінну $1.
Запустімо Bash-скрипт iseven.sh, щоб переконатися, що він працює правильно:
kabary@handbook:~$ ./iseven.sh 3 is odd. 4 is even. 20 is even. 111 is odd.
Також варто пам’ятати, що аргументи функцій у Bash і аргументи самого Bash-скрипта це не одне й те саме. Щоб краще побачити різницю, подивіться на наступний Bash-скрипт funarg.sh:
#!/bin/bash
fun () {
echo "$1 is the first argument to fun()"
echo "$2 is the second argument to fun()"
}
echo "$1 is the first argument to the script."
echo "$2 is the second argument to the script."
fun Yes 7
Запустіть цей скрипт із кількома аргументами та подивіться на результат:
kabary@handbook:~$ ./funarg.sh Cool Stuff Cool is the first argument to the script. Stuff is the second argument to the script. Yes is the first argument to fun()7 is the second argument to fun()
Як видно, навіть попри те, що для аргументів скрипта й аргументів функції використовуються ті самі змінні $1 і $2, усередині функції вони працюють інакше та дають інший результат.
У Bash змінні можуть бути глобальними або локальними. До глобальної змінної можна звертатися з будь-якого місця скрипта, незалежно від того, де вона використовується. Натомість локальна змінна доступна лише всередині тієї функції, у якій її було оголошено.
Щоб побачити, як це виглядає на практиці, подивіться на наступний Bash-скрипт scope.sh:
#!/bin/bash
v1='A'
v2='B'
myfun() {
local v1='C'
v2='D'
echo "Inside myfun(): v1: $v1, v2: $v2"
}
echo "Before calling myfun(): v1: $v1, v2: $v2"
myfun
echo "After calling myfun(): v1: $v1, v2: $v2"
За допомогою ключового слова local створюється власна локальна змінна v1, а значення глобальної змінної v2 при цьому змінюється. Важливий момент у тому, що одну й ту саму назву змінної можна спокійно використовувати для локальних змінних у різних функціях і це не призводить до жодних проблем.
Тепер можна запустити скрипт і подивитися, як це працює на практиці:
kabary@handbook:~$ ./scope.sh Before calling myfun(): v1: A, v2: B Inside myfun(): v1: C, v2: D After calling myfun(): v1: A, v2: D
Локальна змінна з тією самою назвою, що й глобальна, усередині функції має вищий пріоритет. При цьому глобальну змінну можна без проблем змінювати прямо з функції.
Рекурсивна функція це функція, яка викликає саму себе. Такий підхід зручний тоді, коли задачу можна поступово розбити на простіші кроки. Класичний приклад рекурсії це обчислення факторіала.
Подивіться на наступний Bash-скрипт factorial.sh.
Також важливо пам’ятати, що локальна змінна з такою самою назвою, як у глобальної, усередині функції має пріоритет. Водночас глобальну змінну можна змінювати безпосередньо з функції.
#!/bin/bash
factorial () {
if [ $1 -le 1 ]; then
echo 1
else
last=$(factorial $(( $1 -1)))
echo $(( $1 * last ))
fi
}
echo -n "4! is: "
factorial 4
echo -n "5! is: "
factorial 5
echo -n "6! is: "
factorial 6
Будь-яка рекурсивна функція має починатися з базового випадку. Саме він потрібен для того, щоб зупинити ланцюжок рекурсивних викликів. У функції factorial() базовий випадок виглядає так:
if [ $1 -le 1 ]; then echo 1
Тепер перейдемо до рекурсивного випадку для функції обчислення факторіала. Щоб знайти факторіал числа n, де n є додатним числом і більшим за одиницю, потрібно помножити n на факторіал числа n-1:
factorial(n) = n * factorial(n-1)
Скористаймося наведеним вище рівнянням, щоб записати цей рекурсивний випадок:
last=$(factorial $(( $1 -1))) echo $(( $1 * last ))
kabary@handbook:~$ ./factorial.sh 4! is: 24 5! is: 120 6! is: 720
Як додаткову вправу спробуйте написати рекурсивну функцію для обчислення n-го числа Фібоначчі. Спочатку визначте базовий випадок, а потім рекурсивний. У вас все вийде.
Або ви створюєте автоматизацію, або автоматизують вас.

Тепер можна використати всі навички роботи з Bash, отримані в цій серії для початківців, щоб створювати справді корисні скрипти. Такі скрипти допомагають автоматизувати нудні та повторювані адміністративні завдання.
Автоматизація має бути кінцевою метою щоразу, коли пишеться Bash-скрипт.
У цьому уроці показано кілька прикладів скриптів для автоматизації, які згодом легко розширити під будь-які власні задачі. У цих прикладах використовуються масиви Bash, умовні конструкції if-else, цикли та інші концепції, розглянуті в цій серії.
Створення користувача на кількох серверах це задача, з якою системні адміністратори стикаються досить часто. Виконувати її вручну незручно й виснажливо, тому логічно автоматизувати цей процес за допомогою Bash-скрипта.
Для початку потрібно створити текстовий файл зі списком серверів, на яких необхідно додати користувача. Це можуть бути імена хостів або IP-адреси.
Наприклад, створено файл servers.txt, який містить п’ять різних серверів:
kabary@handbook:~$ cat servers.txt server1 server2 server3 server4 server5
Майте на увазі, що тут використовуються імена серверів, оскільки IP-адреси вже додані до файлу /etc/hosts. За потреби замість цього також можна скористатися конфігураційним файлом SSH.
Тепер подивіться на наступний Bash-скрипт adduser.sh:
#!/bin/bash servers=$(cat servers.txt) echo -n "Enter the username: " read name echo -n "Enter the user id: " read uid for i in $servers; do echo $i ssh $i "sudo useradd -m -u $uid $name" if [ $? -eq 0 ]; then echo "User $name added on $i" else echo "Error on $i" fi done
Скрипт adduser.sh спочатку попросить ввести ім’я користувача та його user ID, якого потрібно додати. Після цього він по черзі пройде всі сервери зі списку в файлі servers.txt, підключиться до кожного з них через SSH і створить вказаного користувача.
Запустімо скрипт і подивімося, як він працює:
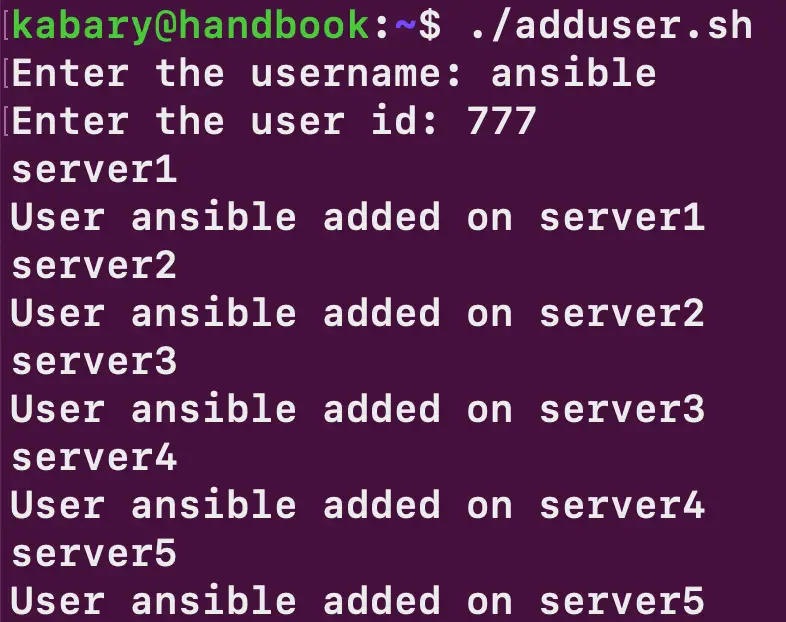
Скрипт успішно відпрацював, і користувача ansible було додано на всі п’ять серверів. Тут є кілька важливих моментів, які варто врахувати:
Можна використовувати SSH-ключі без парольної фрази або запускати
ssh-agent, щоб під час виконання скрипта не вводити ключ чи пароль.
Потрібно мати дійсний обліковий запис із правами суперкористувача на всіх серверах без вимоги введення пароля.
Уявіть, що потрібно додати користувача на понад 100 різних Linux-серверів. Скрипт adduser.sh легко заощадить години, а то й дні ручної роботи.
Резервне копіювання це те, що доводиться робити регулярно, тож цілком логічно автоматизувати цей процес. Подивіться на наступний Bash-скрипт backup.sh:
#!/bin/bash
backup_dirs=("/etc" "/home" "/boot")
dest_dir="/backup"
dest_server="server1"
backup_date=$(date +%b-%d-%y)
echo "Starting backup of: ${backup_dirs[@]}"
for i in "${backup_dirs[@]}"; do
sudo tar -Pczf /tmp/$i-$backup_date.tar.gz $i
if [ $? -eq 0 ]; then
echo "$i backup succeeded."
else
echo "$i backup failed."
fi
scp /tmp/$i-$backup_date.tar.gz $dest_server:$dest_dir
if [ $? -eq 0 ]; then
echo "$i transfer succeeded."
else
echo "$i transfer failed."
fi
done
sudo rm /tmp/*.gzecho "Backup is done."
Отже, спочатку створюється масив backup_dirs, у якому зберігаються всі каталоги, що потрібно включити до резервної копії. Далі задаються ще три змінні:
dest_dir:для вказання каталогу, куди зберігатимуться резервні копії.
dest_server:для вказання сервера, на який надсилатиметься бекап.
backup_time:для збереження дати створення резервної копії.
Після цього для кожного каталогу з масиву backup_dirs у каталозі /tmp створюється стиснений архів tar із використанням gzip. Далі за допомогою команди scp резервні копії передаються на сервер призначення. Наприкінці всі gzip-архіви з каталогу /tmp видаляються.
Нижче наведено приклад запуску скрипта backup.sh:
kabary@handbook:~$ ./backup.sh Starting backup of: /etc /home /boot /etc backup succeeded. etc-Aug-30-20.tar.gz 100% 1288KB 460.1KB/s 00:02 /etc transfer succeeded. /home backup succeeded. home-Aug-30-20.tar.gz 100% 2543KB 547.0KB/s 00:04 /home transfer succeeded. /boot backup succeeded. boot-Aug-30-20.tar.gz 100% 105MB 520.2KB/s 03:26 /boot transfer succeeded. Backup is done.
Можливо, вам потрібно запускати резервне копіювання щодня опівночі. У такому разі скрипт можна запланувати для виконання як завдання cron:
kabary@handbook:~$ crontab -e 0 0 * * * /home/kabary/scripts/backup.sh
Файлові системи рано чи пізно заповнюються, і єдине, що можна зробити, це встигнути відреагувати до того, як система почне працювати з помилками або взагалі впаде. Щоб перевірити, скільки вільного місця залишилося на будь-якій файловій системі, можна скористатися командою df:
kabary@handbook:~$ df -h / /apps /database Filesystem Size Used Avail Use% Mounted on /dev/sda5 20G 7.9G 11G 44% / /dev/mapper/vg1-applv 4.9G 2.4G 2.3G 52% /apps /dev/mapper/vg1-dblv 4.9G 4.5G 180M 97% /database
Файлова система /database майже заповнена, зараз використано 97% простору. Щоб вивести лише відсоток використання, можна скористатися командою awk і показати тільки п’яте поле.
Тепер подивіться на наступний Bash-скрипт disk_space.sh:
#!/bin/bash
filesystems=("/" "/apps" "/database")
for i in ${filesystems[@]}; do
usage=$(df -h $i | tail -n 1 | awk '{print $5}' | cut -d % -f1)
if [ $usage -ge 90 ]; then
alert="Running out of space on $i, Usage is: $usage%"
echo "Sending out a disk space alert email."
echo $alert | mail -s "$i is $usage% full" your_email
fi
done
Спочатку створюється масив filesystems, у якому перелічені всі файлові системи, за якими потрібно стежити. Далі для кожної з них береться відсоток використання диска і перевіряється, чи він більший або дорівнює 90. Якщо використання перевищує 90%, скрипт надсилає лист із попередженням про те, що на файловій системі майже не залишилося вільного місця.
Зверніть увагу, що в скрипті потрібно замінити your_email на свою реальну електронну адресу.
Скрипт було запущено:
kabary@handbook:~$ ./disk_space.sh Sending out a disk space alert email.
У результаті на електронну пошту надійшов такий лист:
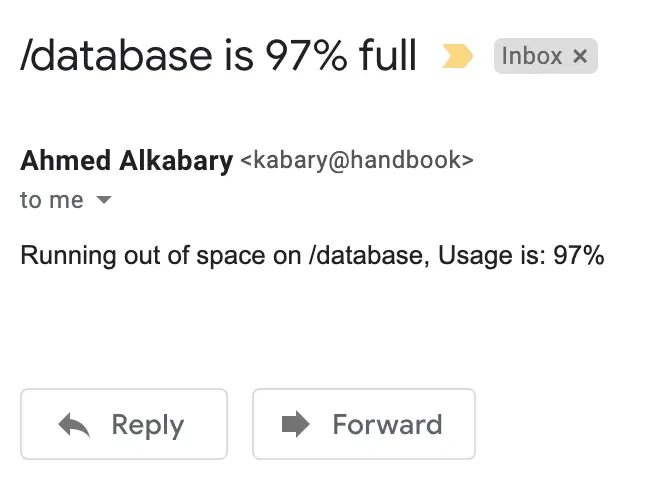
Можливо, цей скрипт disk_space.sh варто запускати приблизно кожні шість годин. У такому разі його також можна запланувати для виконання як завдання cron:
kabary@handbook:~$ crontab -e 0 */6 * * * /home/kabary/scripts/disk_space.sh
На цьому ми добігаємо кінця нашої серії навчальних посібників з bash для початківців. Сподіваюся, вам сподобалося вивчати bash-скрипти. Маючи bash-скрипти у своєму арсеналі, ви можете автоматизувати будь-яке нудне та виснажливе завдання в Linux!


