
21.08.2025
1 хв
746

Auto Archiver — це відкритий інструмент, що допомагає журналістам, дослідникам та правозахисникам зберігати онлайн-докази ще до того, як вони зникнуть з мережі. Завдяки цьому сервісу вже збережено понад 150 000 матеріалів: від постів у соцмережах до відео та вебсторінок. Система дозволяє автоматизувати архівування, фіксувати метадані, створювати ланцюг збереження (chain of custody) та гарантувати достовірність цифрових свідчень. Інструмент зручний для командної роботи: можна інтегрувати джерела з Google Sheets, Telegram чи відеосервісів, а результати зберігати в хмарі або локально. Завдяки модульній архітектурі Auto Archiver підтримує проксі для обходу бот-захистів і дає можливість легко додавати нові компоненти. Це рішення ідеально підходить для журналістів-розслідувачів, OSINT-спільноти, НУО, а також усіх, хто працює з великими обсягами чутливої інформації.

Автоматичний архіватор – це інструмент, призначений для збереження цифрового онлайн-контенту до того, як його можна буде змінити, видалити або видалити. Публічно запущений у 2022 році, він зберіг понад 150 000 веб-сторінок та публікацій у соціальних мережах на сьогодні. Автоматичний архіватор використовувався журналістами для збереження інформації про десятки швидкоплинних подій, таких як заворушення 6 січня – коли ми вперше використовували цей інструмент внутрішньо, – а також для збору цифрових доказів для нашого проєкту «Правосуддя та відповідальність» та для моніторингу шкоди, завданої цивільному населенню в Україні.
Автоматичний архіватор також був прийнятий як великими редакціями, так і неурядовими організаціями. Його використовували також окремі дослідники, журналісти, активісти, архівісти, науковці та розробники. З огляду на великий інтерес до цього інструменту, ми наполегливо працювали над його доповненням та вдосконаленням з часом. Але ми використали останні кілька місяців, щоб зробити крок назад і побудувати нову та надійнішу екосистему, яка ще більше допоможе окремим організаціям і дослідникам використовувати його та отримувати від нього користь.
Нашою метою було зробити його надійнішим та ще простішим у використанні для більшої кількості людей. Сьогодні ми раді оголосити про оновлену версію Auto Archiver, яка включає багато нових функцій, таких як:
Детальна документація щодо всіх функцій та конфігурацій
Зручний інтерфейс , розроблений для команд, що використовують спільний екземпляр
Нова модульна структура, що покращує швидкість запуску та надійність інструменту
Нові функції, такі як ланцюг зберігання, перцептивне хешування для дедуплікації та методи уникнення антибот-заходів і капч на вебсайтах
Зручний інструмент для налаштування автоматичного архіватора без необхідності редагування текстових файлів конфігурації
Для детального ознайомлення зі змінами, внесеними до цієї стабільної версії Auto Archiver, див. розділ «Що змінилося, що залишилося» далі в цій статті.
Найновіша версія Auto Archiver має простий у використанні веб-інтерфейс та спрощений процес встановлення, що робить налаштування ще простішим, ніж раніше. Однак для цього початкового процесу все ще потрібні деякі технічні навички, а також доступні інші інструменти, які можуть задовольнити багато ваших потреб в архівуванні.
Якщо вам потрібно лише архівувати кілька неавтентифікованих URL-адрес, рекомендуємо використовувати Wayback Machine або Archive.today. Як варіант, розширення браузера ArchiveWebPage від WebRecorder може створити архів веб-сайту, який ви відвідуєте, для відтворення – навіть для контенту, який знаходиться поза системою входу. Для пакетної обробки Wayback Machine має сервіс масового завантаження, який приймає Google Таблиці. Якщо вам окремо потрібно записувати всі ваші взаємодії з браузером та зберігати контент по ходу процесу, існують платні опції, такі як Hunchly. Нарешті, якщо вас цікавлять лише відео, і ви впевнено користуєтеся командним рядком, yt-dlp, ймовірно, буде достатньо для їх завантаження, навіть масово.
Але якщо ви сподіваєтеся автоматизувати архівування або архівувати велику кількість URL-адрес у середовищі спільної роботи, то саме тут Auto Archiver справді сяє. Його модульна структура дозволяє вам або вашій команді налаштовувати архівування відповідно до ваших потреб і надає спосіб генерувати метадані, що гарантує, що інші можуть бути впевнені, що ваш архівований контент не був підроблений.
Дізнайтеся більше про те, які сайти може архівувати автоархіватор, тут.
Архівування веб-сторінок – складна справа, особливо коли використовуються логіни, капчі та інші системи запобігання ботам. Ми докладемо всіх зусиль, щоб продовжувати вдосконалювати наш автоматичний архіватор, але зазначаємо, що він має бути лише одним із багатьох інструментів у вашому дослідницькому наборі.
Однак, якщо ви хочете підтримати нас у цій подорожі архівування важливої інформації, ви можете:
Завантажте та використовуйте цей інструмент
Тестуйте, залишайте відгуки та розробляйте нові функції на нашому GitHub
Тепер, коли ми надали загальний огляд інструменту та його змін, далі глибше розглянемо, як працюють та взаємодіють різні його частини. Це, ймовірно, буде кориснішим для більш технічно підкованих користувачів, і ми ще раз наголошуємо, що успішним користувачам інструменту, ймовірно, знадобляться певні технічні знання для його першого налаштування.
Але допомога доступна з нашою документацією Auto Archiver у реальному часі . Тут ви завжди знайдете найновішу інформацію про те, як встановити, налаштувати або налагодити інструмент. Навіть якщо деякі аспекти, згадані в цій статті, зміняться в найближчі роки, документація буде вашим місцем для отримання актуальних інструкцій.
Якщо у вас є запитання чи проблеми, будь ласка, відкрийте проблему на GitHub. Саме туди інші також звертатимуться за допомогою, і це створює наш спільний простір знань.
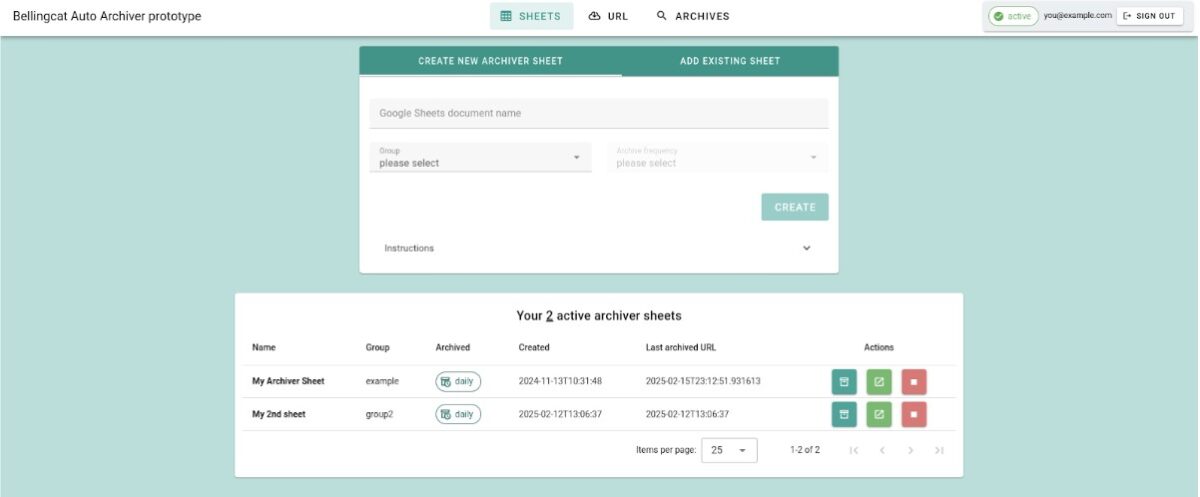
Багато дослідників відкритого коду надають перевагу використанню Auto Archiver з інтеграцією з Google Таблицями, що дозволяє користувачам працювати разом, додаючи посилання до електронної таблиці та дозволяючи Auto Archiver працювати у фоновому режимі. Однак тепер ми спростили інтеграцію Auto Archiver в інші системи. Одним із таких прикладів є ATLOS, платформа для спільних розслідувань, яка інтегрувала Auto Archiver і яка використовувалася Bellingcat та Центром інформаційної стійкості.
Інтеграція можлива завдяки новій модульній архітектурі Auto Archiver, що можна побачити у двох нових проектах, які ми нещодавно опублікували за ліцензіями з відкритим вихідним кодом: Auto Archiver API та Auto Archiver Web Interface.
Модулі є будівельними блоками конвеєра архівування та вказують інструменту, як працювати. Вони детально описують, де знаходити URL-адреси, які методи архівування використовувати, яку додаткову обробку виконувати над архівованим контентом, а також де і як його зберігати. Кожен модуль належить до певного класу:
Модулі Feeder вказують, звідки зчитувати URL-адреси.Наприклад, один із них є для Google Таблиць .
Модулі екстрактора завантажують медіафайли та інші метадані з URL-адреси: нашим найуніверсальнішим є Generic Extractor, який використовує yt-dlp для завантаження відео. Однак екстрактори можна налаштувати для певних платформ, таких як Telethon Extractor, для якого потрібен обліковий запис Telegram для завантаження всіх медіафайлів та метаданих із повідомлень у публічних або приватних чатах, до яких приєднався обліковий запис.
Модулі збагачення збільшують цінність архівованого контенту за допомогою додаткової інформації або перевірок, таких як хешування або додавання позначок часу до контенту для майбутньої узгодженості або перевірки ланцюга зберігання.
Модулі форматування збирають та відображають результат процесу в одному відформатованому виводі. Ми використовуємо HTML Formatter, як показано в цьому прикладі публікації Bluesky.
Модулі сховища повідомляють інструменту, куди розміщувати завантажені або згенеровані файли. Найпростіше зберігати їх локально . Але для кращого збереження найкращою практикою є використання хмарних сховищ, таких як S3 або Google Drive.
Модулі бази даних просто вказують, де зберігати запис цього архіву, наприклад, чи було архівування успішним і які методи були використані.Наприклад, можна використовувати файл CSV та Google Таблиці .
Документацію модулів можна знайти тут, і вона допоможе вам зрозуміти, як працює та налаштовується кожен модуль. Налаштування модулів для використання здійснюється за допомогою YAML- файлу. Якщо вам це незручно, ми пропонуємо вам новий інтерфейс під назвою редактор конфігурації, де ви можете візуально створювати або редагувати конфігурацію модулів. Фактично, під час першого запуску Auto Archiver генерується мінімальний робочий YAML-файл конфігурації, який ви можете одразу використовувати для зчитування URL-адрес з командного рядка та зберігання архівованого вмісту локально.
Деякі платформи обмежують швидкість доступу або повністю блокують IP-адреси на основі неавтентичної поведінки. Одна зі стратегій, яку ми використовуємо для обходу цього, – це надсилання трафіку через проксі-сервер, який можна налаштувати в спеціальних модулях, таких як Generic Extractor. Ми успішно використовуємо житлові проксі-сервери Oxylab як частину їхнього Project 4beta вже понад рік, але знаємо, що є кілька хороших провайдерів.
Якщо ви розробник, ви можете створювати нові модулі за потреби, використовуючи код Python, і ми будемо раді, якщо ви захочете додати їх до нашого коду. Уявіть собі Feeder , який постійно збирає URL-адреси з облікового запису Bluesky, або Enricher, який використовує модель штучного інтелекту для виявлення та розмиття графічного контенту. Все це можливо та легко створити в цій новій архітектурі.
Сподіваємося, що вам сподобається оновлений інструмент.

