
02.05.2023
4 min
2398

Mayoret is an advanced online service that helps you find the goals and purpose of users based on their username. This tool gives you access to advanced search and information analysis that helps uncover additional details about a user’s identity and purpose. Mayoret uses smart algorithms and powerful analytics to review various data sources, including social networks, profiles, forums and other public sources. This allows you to find valuable information about the user’s interests, activities and behavior, which is important for understanding their needs and motivations. Whether you’re a marketer, researcher, product developer, or just interested in analytics, Mayoret helps you enrich your data and take meaningful action. You will be able to use the information you receive to refine your strategies, personalize your content, establish better connections with your audience, and much more. Introduce a new level of analysis and understanding of your audience with Mayoret.

Find targets by username and connect more deeply with your audience, making informed decisions and achieving your business goals. Mayoret: Find targets by username with a powerful online tool. Unlock new opportunities to analyze and understand your audience by finding valuable information about users based on their username. Improve strategies, personalize content and connect more deeply with your audience with Mayoret.
You can specify multiple usernames separated by a space. Usernames are optional as there are other modes of operation (see below).

Megre will attempt to obtain information about the owner of the document/account (including username and other identifiers) and will search the extracted username and identifiers.
![]()
Settings can also be configured using settings files, see settings section.
--tags– Filter sites to search by tags: site categories and two-letter country codes (not language!). For example, photos, dating, sports; jp, us, global. Multiple tags can be associated with one site. Warning: Tagging is currently unstable.
-n,--max-connections– Allowed number of simultaneous connections (default: 100).
-a,--all-sites– Use all sites to crawl (default: top 500).
--top-sites– Number of Alexa Top (default: top 500) sites to crawl.
--timeout– The time (in seconds) to wait for a response from sites (default: 30). A longer timeout is more likely to get results from slow sites. On the other hand, this can lead to a long delay in collecting all the results. Choosing the right timeout should be done taking into account the bandwidth of the Internet connection.
--cookies-jar-file– File with special cookies in Netscape format (aka cookies.txt). You can install extensions to your browser to download your own cookies ( Chrome , Firefox ).
--no-recursion— Disable page parsing and recursive searches for other usernames.
--use-disabled-sites– Use disabled sites to search (can cause a lot of false positives).
--id-type– Specify the type of identifier(s) (default: username). Supported types: gaia_id, vk_id, yandex_public_id, ok_id, wikimapia_uid. Currently, you must add the -a flag to run a scan on sites with special ID types, sites will be automatically filtered.
--ignore-ids– Do not search by the specified username or other identifiers. Useful for rescans with known non-matching usernames found.
--db– Download the Magret database from a JSON file or an online valid JSON file.
--retries RETRIES– Number of attempts to restart temporarily failed requests.
-P,
-H,--html– Create an HTML report file (general report of all usernames).
-X,--xmind– Create an XMind 8 mind map (one report per username).
-C,--csv– Creating a CSV report (one report per user name).
-T,--txt– Creating a TXT report (one report per user name).
-J,--json– Generate a JSON report of a specific type: simple, ndjson (one report per username). e.g--json ndjson
-fo,--folderoutput– the results will be saved in this default results folder. Will be created if does not exist.
-v,--verbose– Display of additional information and indicators. (loglevel=WARNING)
-vv,--info– Display of service information. (loglevel=INFO)
-vvv,--debug,-d– Display debugging and site response information. (loglevel=DEBUG)
--print-not-found– Print sites where the username is not found.
--print-errors– Print error messages: connection, captcha, country ban, etc.
--version– Display version and dependency information.
--self-check– Run self-checks on sites and databases and disable dead ones for the current search session by default. This is useful for testing a new internet connection (it depends on the ISP/hosting which sites will have a censor stub or captcha display). After checking, Megre will ask if you want to save the update, a yes/yes answer will overwrite the local database.
--submit URL– Perform automatic analysis of a given account URL or site homepage URL to determine the site’s engine and account verification methods. After validation, Megre will ask if you want to add the site, yes/yes will overwrite the local database.
Maigret may parse URLs and web page content from URLs to obtain information about the account holder and other meta-information. You must specify a URL with the –parse option, which can be a link to an account or an online document. Once the parsing phase is complete, Magret will begin the search phase for the supported identifiers found (usernames, IDs, etc.).
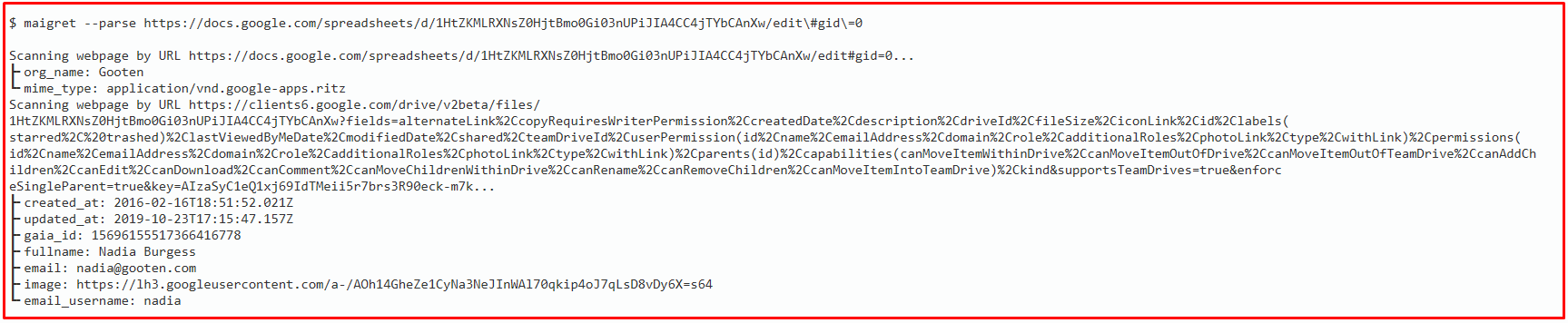

Maigret analyzes account web pages and extracts personal information, links to other profiles, and more. The resulting information is displayed as additional output in the CLI output and as tables in HTML and PDF reports. Additionally, Maigret uses the found IDs and usernames from the links to start a recursive search.
СEnabled by default, can be disabled with
![]()
Megre can get some common IDs and usernames from the links on the account page (often people link to their other accounts) and immediately start a new search. All information collected will be displayed in CLI output and reports.
Enabled by default, can be disabled with
![]()
Maigret currently supports HTML, PDF, TXT, XMind 8 mindmap and JSON reports.
Profile photo
All personal information collected
Additional information about alleged personal data (name, gender, location), obtained from the statistics of all found accounts
Additionally, there is a short text report in the CLI output after the search phase is complete.
Warning: XMind 8 Mind Maps are not compatible with XMind 2022!
The database of Megre sites is very large (and will be even larger), and it may be overhead to search all sites. Also, it is often difficult to understand which sites are more interesting for us in the case of a certain person. Tagging allows you to select a subset of sites by interest (photos, messaging, finance, etc.) or by country. The tags of found accounts are grouped and displayed in reports.
Megre can detect common errors such as censorship stub pages, CloudFlare encoded pages, and more. If you receive more than 3% of errors of a certain type during a session, you will receive a warning message in the CLI output with recommendations for improving performance and avoiding problems.
Megre will retry requests with temporary errors (connection failures, proxy errors, etc.).
One attempt by default, can be changed with an option.
![]()
Megre’s database contains not only original websites, but also mirrors, archives and aggregators.
Reddit BigData Search
Picuki, a mirror of Instagram
Checking the Twitter shadow ban
Allows you to get additional information about an individual and verify the presence of an account, even if the main site is not available (bot protection, captcha, etc.)
Maigret can be easily integrated using the maigret Python package . Example: Official Telegram bot
TL;DR: Username => Dossier
Maigret is designed to collect all available information about a person by their login. What kind of information is this? First, links to personal accounts. Second, all pieces of information that can be retrieved by a machine, such as: other usernames, full name, URLs of people’s images, date of birth, location (country, city, etc.), gender.
All this information forms a certain dossier, but it is also useful for other tools and analytical purposes. Each piece of data collected has a label in a specific format (eg follower_count number of followers or created_at time of account creation) so that it can be analyzed by different systems and stored in databases.
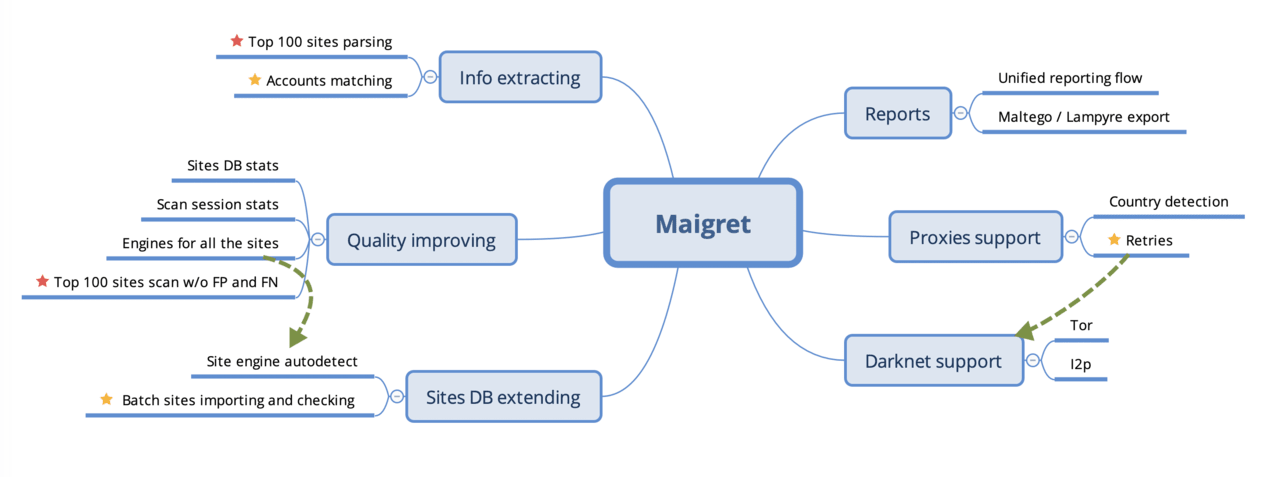
Database statistics of sites – good
Statistics of scanning sessions – good
Automatic detection of the site engine is good
Engines for all sites – WIP
A unified reporting flow is fine
Retries are good
Megre can search not only by common usernames, but also by certain common identifiers. There is a list of all currently supported identifiers.
gaia_id – Google’s internal numeric user ID, formerly located in the Google Plus account URL.
steam_id – Steam’s internal numeric user ID.
wikimapia_uid is Wikimapia.org’s internal numeric user ID.
uidme_uguid – internal numeric user ID of uID.me.
yandex_public_id – internal letter ID of the user of Yandex sites. See also: YaSeeker.
vk_id – VK.com’s internal numeric user ID.
ok_id – internal numerical ID of the OK.ru user.
yelp_userid – Yelp’s internal user ID.
The use of tags allows you to select a subset of sites from the large Megre database for searching.
Warning: Tagging is currently unstable.
Country codes: us, jp, br… (ISO 3166-1 alpha-2). These tags reflect the language of the site and the regional origin of its users, and are then used to identify the location of the username owner. If the regional origin is difficult to establish or the site is positioned as global, the country code is not specified. There can be multiple country code tags for one site.
Site Engines. Most of them are now forum engines: uCoz, vBulletin, XenForota, etc. A complete list of engines stored in the Magret database.
Subject/type of sites and user interests. The full list of “standard” tags is present in the source code for just a moment.
--tags us,jp– search on US and Japanese sites (actually marked as such in the Maigret database)
--tags coding– search on sites related to software development.
--tags ucoz– search on uCoz sites only (mostly CIS countries)
Start searching for accounts with the username machine42 on the top 500 sites from the Magret database.
![]()
Start searching for accounts with the username machine42 on all sites from the Megre database.
![]()
Start searching […] and generate HTML and PDF reports.
![]()
Start searching for accounts with the username machine42 on Facebook only.
![]()
Get the information from the Steam page at the URL and start searching for accounts with the found username machine42.
![]()
Start looking for accounts with the username machine42 on US and Japanese sites only.
![]()
Start searching for accounts with the username machine42 only on sites related to software development.
![]()
Start searching for accounts with machine42 login only on uCoz sites (mainly CIS countries).
![]()
Settings can also be configured using settings files. See the JSON settings file for a list of supported options.
Once started, Megre attempts to load the configuration from the following sources in the same order:
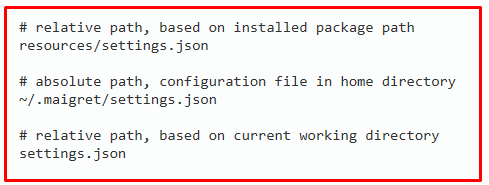
Missing any of these files is not an error. If the following settings file contains an already known parameter, this parameter will be overwritten. Thus, it is possible to create an individual configuration for different users and directories.
Recommended to use Python 3.7/3.8 for testing due to some conflicts in 3.9.
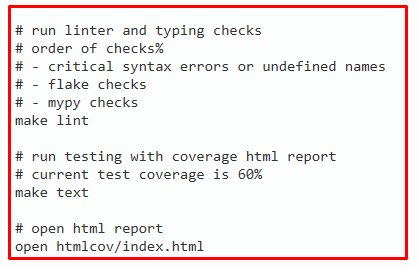
Installation test requirements:
![]()
To check Megre, use the following commands:
Collaborative rights required, email Soxoj to obtain them.
To publish a new version, you must create a new branch in the repository with the changed version number and the actual changelog. After that you have to create a release and the GitHub action will automatically create a new PyPi package.
An example of a new branch: https://github.com/soxoj/maigret/commit/e520418f6a25d7edacde2d73b41a8ae7c80ddf39
Example release: https://github.com/soxoj/maigret/releases/tag/v0.4.1
Check the current version number here: https://pypi.org/project/maigret/ . Only increase the patch version (the third number) if there are no critical changes.
![]()
setup.py
maigret/__version__.py
docs/source/conf.py

Open https://github.com/soxoj/maigret/releases/new
Click Select Tag, enter v0.4.0 (your version)
Click Create New Tag
Click + Automatically create release notes
Copy all the text from the description text box below
Paste it into an empty text section in CHANGELOG.txt
Remove the extra lines ## What’s Changed and ## New Members section if it exists
Close the new release page

Click Select Tag
Please enter the current version as v0.4.0
Also, enter the current version in the Release Name field
Click Create New Tag
Click + Automatically create release notes
Click the “Publish Release” button.
You can follow it on the action page: https://github.com/soxoj/maigret/actions/workflows/python-publish.yml

