
01.06.2023
11 min
2595

You will dive into the fascinating world of computer technology and learn how computers are arranged. From the basic components that make up any computer to complex data processing operations, we’ll reveal all the secrets that make these machines indispensable in our daily lives.

When exploring the depths of computer technology, you can often encounter gaps in knowledge, especially when it comes to what exactly happens when you run a program on a computer. Curiosity about how programs are executed directly on the central processing unit (CPU), how system calls (syscalls) work and what they actually mean, and how multiple programs can be executed simultaneously are often unanswered.
The CPU is where all the calculations take place. It starts “puffing” as soon as you turn on the computer, following the instruction after the instruction.
The first mainstream CPU was the Intel 4004, designed in the late 60s by Italian physicist and engineer Federico Fargin. It was a 4-bit architecture, not the 64-bit used today. The 4-bit architecture was much less complex than today’s processors, but much remained largely unchanged.
The “instructions” executed by the CPU are just binary data: a byte or two representing the instruction to be executed (opcode), followed by the data needed to execute the instruction. What we call machine code is just a series of these binary instructions in string form. Assemble is a useful syntax that makes it easier for humans to read and write raw bits. It is always compiled into binary data understood by the CPU.

Note: instructions in machine code are not always represented 1:1, as in the example. For example, add eax, 512 becomes 05 00 02 00 00.
The first byte (05) is the opcode representing the addition of the EAX register to a 32-bit number. The other bytes are 512 (0x200) in little-endian byte order.
Defuse Security has developed a useful tool for converting assembly language to machine code.
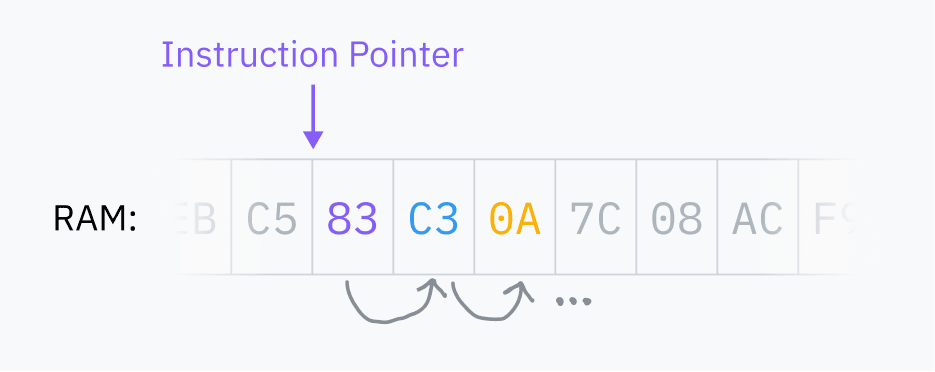
Random Access Memory (RAM) is a computer’s primary storage, a large, multipurpose place where all the data used by the programs running on the computer is stored. This includes program code as well as operating system kernel code. The CPU always reads the machine code directly from the VP. Code that is not loaded into the OP cannot be executed.
The CPU stores an instruction pointer, which indicates the place in the VP where the next instruction is. After all instructions are executed, the CPU returns the pointer to the beginning and the process repeats. This is called a fetch-execute cycle.
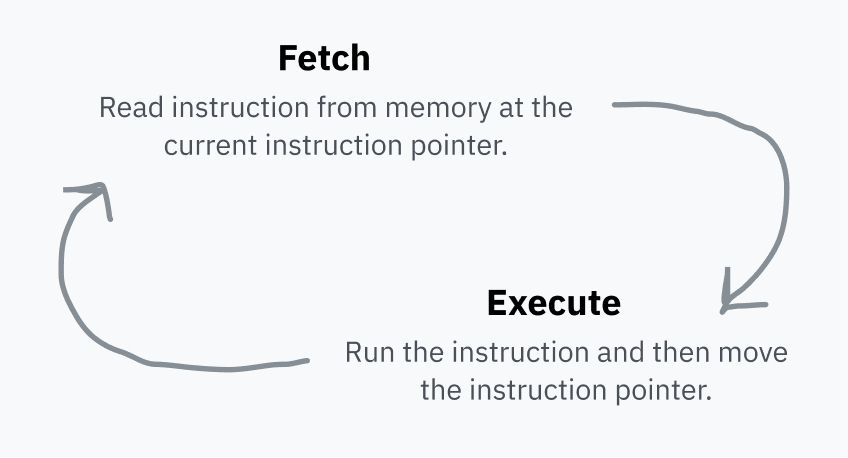
After the execution of the instruction, the pointer moves behind it in the OP and points to such an instruction. The instruction pointer moves forward and the machine code is executed in the order stored in memory. Some instructions can make the pointer move (jump) to another place (execute another instruction instead of the current one or execute one of the instructions depending on a certain condition). This enables repeated and conditional code execution.
The instruction pointer is stored in a register. Registers are small storages that are very efficient for CPU reads and writes. Each CPU architecture has a fixed set of registers that are used for everything from storing temporary values during calculations to configuring the processor.
Some registers are accessible from machine code directly, such as ebx in the diagram above.
Other registers are for internal CPU use only, but can be updated or read using special instructions. One example of such a register is an instruction pointer, which cannot be read directly, but can be updated, for example, to execute another instruction instead of the current one.
Let’s return to the question of what happens when the program is launched on the computer. First, some magic happens – we’ll talk about that later – and we end up with a machine code file that’s stored somewhere. The OS loads them into the OP and instructs the CPU to move the pointer to a certain position of the OP. The sample-execute cycle begins, and the program starts!
Your CPU receives sequential browser instructions from the OP and executes them, resulting in the rendering of this article.
CPUs have very limited horizons. They only see a pointer to the current instruction and some internal state. Processes are OS abstractions, not something the CPU understands or tracks.
This raises more questions than answers:
If the CPU does not know about multitasking (multiprocessing) and executes instructions sequentially, why does it not get stuck in a running program? How can you run multiple programs at the same time?
If the program is running in the CPU, and the CPU has direct access to the OP, why doesn’t code from other processes or, sorry, the kernel, have access to the memory?
What is the mechanism that prevents any instruction from being executed by any process? What is a system call?
In short, most memory accesses go through the misdirection layer, which reassigns the entire address space. For now, we’ll assume that programs have direct access to the entire OS, and computers can only run one process at a time. Later we will get rid of both of these assumptions.
It’s time to jump down our first rabbit hole – into a country full of systemic challenges and security rings.
What is a core?
Your computer’s OS, such as MacOS, Windows, or Linux, is a collection of software that does all the basic work. “Main work” is a general term and, depending on the OS, can include things like apps, fonts, icons that come with the computer by default.
Every OS has a kernel. When you turn on the computer, the instruction pointer starts some program. This program is the core. The kernel has almost full access to memory, peripherals and other resources and is responsible for running the software installed on the computer (user programs).
Linux is just a kernel, which needs a lot of programs, such as shells and display servers, to function properly. The macOS kernel is called XNU, and the modern Windows kernel is the NT Kernel.
The mode (sometimes called the privilege level or the ring) that the processor is in controls what can be done. In modern architectures, there are at least two options: kernel/supervisor mode and user mode. Although the architecture can support more than two modes, only kernel and user modes are usually used.
In kernel mode, anything is allowed: the CPU can execute any supported instruction and access any memory. In user mode, only a certain set of instructions is allowed, input/output (I/O) and memory access are limited, and many CPU parameters are locked. Typically, the kernel and drivers run in kernel mode, while programs run in user mode.
Processors start as cores. Before executing the program, the kernel initializes the switch to user mode.

An example of how processor modes are revealed in a real architecture: in x86-64, the current privilege level (current privilege level, CPL) can be read from the cs (code segment) register. Specifically, the CPL is contained in the 2 least significant bits of the cs register. These 2 bits can store 4 possible x86-64 rings: ring 0 is kernel mode and ring 3 is user mode. Rings 1 and 2 are for running drivers, but are only used by a few niche OSes. If, for example, the CPL bits are 11, the CPU starts in user mode.
Programs run in user mode because full access to the computer cannot be granted. User mode does its job by preventing access to most of the computer, but programs need input/output, memory, and the ability to interact with the OS! To do this, software running in user mode calls for help from the OS kernel. OSs then implement their own protection measures.
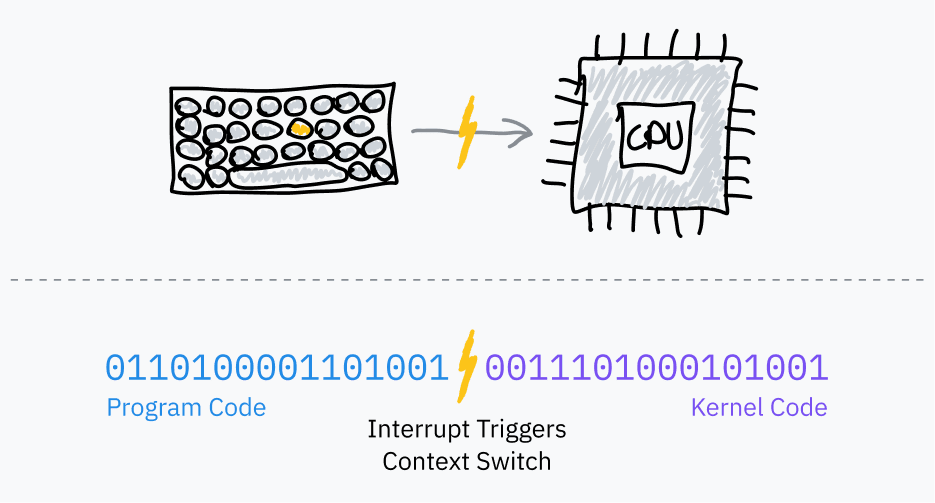
If you’ve written code that interacts with the OS, you should be familiar with the open, read, fork, and exit functions. Beneath several layers of abstraction, these functions use system calls to ask the OS for help. A system call is a special procedure that allows a program to initiate a transition from user space to kernel space, to jump from program code to OS code.
The transfer of control from user space to kernel space is performed using processor functions called software interrupts:
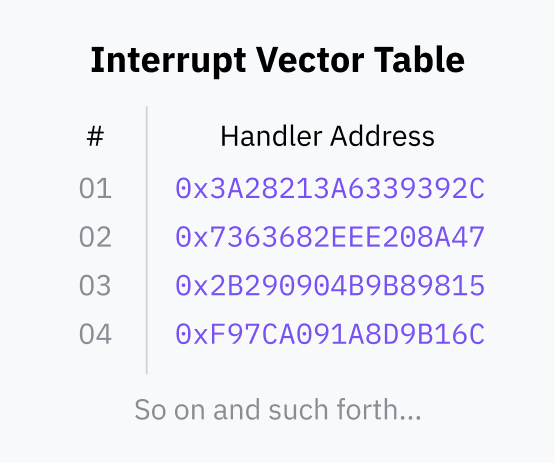
At startup, the OS stores an “interrupt vector table” (IVT) (x86-64 it is called an “interrupt descriptor table”) in the OS and registers it with the CPU. The IVT is a mapping table between the interrupt number and the handler code pointer.
User programs can then use instructions such as INT that tell the processor to find the specified interrupt number in the IVT, switch to kernel mode, and move the instruction pointer to the memory address specified in the IVT.
After this code completes, the kernel instructs the CPU to switch back to user mode and return the instruction pointer to the location where the interrupt occurred. This is done using instructions such as IRET.
In case you’re wondering, the interrupt ID for system calls on Linux is 0x80. A list of Linux system calls can be found here.
Here’s what we learned about system calls:
programs running in user mode do not have access to I/O or memory. They have to turn to the OS for help in interacting with the outside world;
programs can transfer control to the OS using special instructions containing machine code, such as INT and IRET;
applications cannot switch privilege levels directly. Software interrupts are safe because the processor is preconfigured by the OS as to which OS code to call. The interrupt vector table can only be configured in kernel mode.
Applications must pass data to the OS during a system call. The OS must know not only which system call to execute, but also have the data necessary to execute it, such as the file name (filename). The transfer mechanism depends on the OS and architecture, but usually it is done by placing data into certain registers or the stack before triggering the interrupt.
The differences in how system calls are invoked on different devices means that implementing each application’s system calls by developers is, to say the least, impractical. It would also mean that the OS could not change its interrupt handling to avoid breaking programs designed to use older systems. Finally, we write more programs in assembly language – programmers cannot be expected to switch to assembly every time a file is read or memory is allocated.
Therefore, OSes provide an abstraction layer on top of these interrupts. High-level “reusable” functions that wrap the necessary assembly language instructions are provided by libc on Unix-like systems and by part of a library called ntdll on Windows. Simply calling these functions does not entail switching to kernel mode. Inside libraries, assembly code transfers control to the kernel. This code is much more platform dependent than the library wrapper.
When we call exit(1) from C running on Unix, this function executes the machine code to trigger the interrupt after placing the system call opcode and arguments into the correct register/stack/whatever. Computers are so cool!
Many CISC architectures, such as x86-64, contain instructions intended for system calls, created by the dominance of the system call paradigm.
Intel and AMD did not coordinate very well when working on x86-64. So we have 2 sets of optimized system call instructions. SYSCALL and SYSENTER are optimized alternatives to instructions such as INT 0x80. Their return instructions, SYSRET and SYSEXIT, are designed to quickly return to user space and continue executing program code.
AMD and Intel processors have slightly different compatibility with these instructions. SYSCALL is generally better suited to 64-bit applications, while SYSENTER is better supported by 32-bit applications.
RISC architectures have no such special instructions. AArch64, the RISC architecture used in Apple Silicon, uses only one interrupt instruction for system calls and program interrupts.
Here’s what we learned in this chapter:
processors execute instructions in an endless fetch-execute loop and have no idea about the OS or programs. The processor mode, usually stored in a register, determines which instructions can be executed. Operating system code runs in kernel mode and switches to user mode to run programs;
to run the executable, the OS switches to user mode and tells the processor the entry point of the code in the OP. Because applications have low privileges, they are forced to rely on OS code to interact with the outside world. System calls are a standardized way of switching programs from user mode to kernel mode and OS code;
programs usually use these system calls by calling functions of special libraries. These functions are wrappers over machine code for software interrupts or architecture-specific system call instructions that pass control to the OS kernel and switch security rings. The kernel does its thing, switches back to user mode, and returns to the application code.
Back to the question, if the CPU doesn’t track more than one process and just executes one instruction after another, why doesn’t it get stuck in a running program. How can multiple programs run simultaneously? It’s all about timers.
Let’s say we’re developing an OS and want users to be able to run multiple programs at the same time. We don’t have a fancy multi-core processor, our CPU can only execute one instruction at a time.
Fortunately, we are very smart OS developers. We found that competitiveness can be simulated by executing processes in turn. If we cycle through the processes and execute several instructions from each, all processes will be responsive and none of them will load the CPU completely.
How to return control from the program code? After a little research, it turns out that most computers contain timer chips. We can program the timer chip to switch to the OS interrupt handler after a certain amount of time.
Earlier we looked at how software interrupts are used to transfer control from the user program to the OS. They are called “program” because they are arbitrarily started by a program – the machine code executed by the processor in a normal fetch-execute cycle instructs it to transfer control to the core.
OS schedulers use timer chips such as PIT to trigger program interrupts for multitasking purposes:
Before program code execution begins, the OS sets a timer chip to trigger an interrupt after a certain amount of time has elapsed.
The OS switches to user mode and moves to the next program instruction.
When the timer fires, the OS triggers a software interrupt to switch to kernel mode, and jumps to the OS code.
The OS remembers where the program execution stopped, loads another program and repeats the process.
This is called “preemptive multitasking”; interrupting a process is called preemptive. If, for example, you are reading this article in a browser and listening to music on the same machine, your computer is probably doing this cycle thousands of times per second.
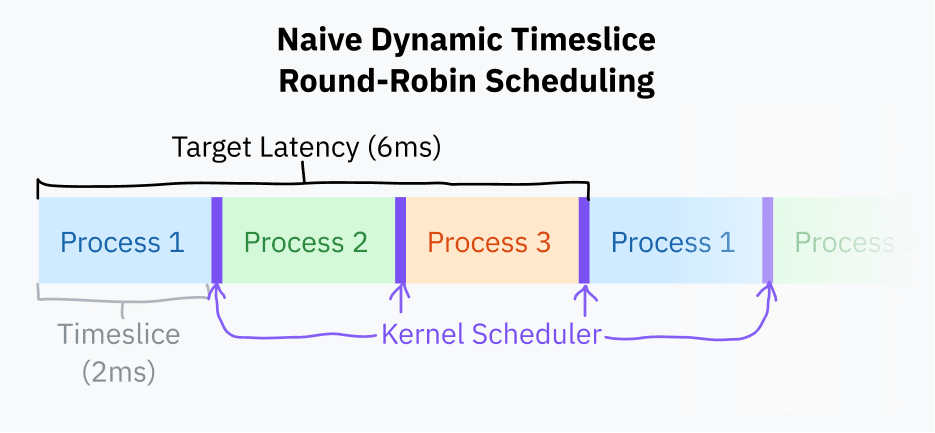
A timeslice is a period during which the OS scheduler allows a process to run before it is displaced. The easiest way to determine the time intervals is to assign each process the same interval, for example, within 10 ms, and iterate through the tasks in order. This is called “fixed timeslice round-robin scheduling”.
Note: fun slang facts.
Time intervals are often called “quantums”.
Linux kernel developers use the jiffy unit to count timer ticks at a fixed frequency. Among other things, this unit is used to measure the length of a time interval. The jiffy frequency is usually 1000 Hz, but can be configured when compiling the kernel.
A small improvement of scheduling with fixed time intervals is the choice of target latency (target latency) – the optimal maximum period of time required for the processor to respond. The target latency is the time it takes for the processor to resume code execution after being pushed out given a reasonable number of processes.
Time intervals are calculated by dividing the target delay by the number of tasks. This approach is better than fixed intervals because it eliminates unnecessary switching with fewer processes. With a target latency of 15ms and 10 processes, each process gets 15/10 or 1.5ms to execute. With 3 processes, each process gets 5ms and the target latency will remain the same.
Switching between processes is computationally expensive because it requires saving the entire state of the current program and restoring another state. At some point, time intervals that are too small can lead to performance issues with very fast switching between processes. A common practice is to set a lower threshold (minimum granularity). This means that the target latency is exceeded if there are enough processes for the minimum granularity to take effect.
At the time of writing, the Linux scheduler uses a target latency of 6ms and a minimum granularity of 0.75ms.
Cyclic scheduling with this basic time quantum calculation is close to what most computers do today. Most OSes, as a rule, have more complex schedulers that take into account process priorities and deadlines. Since 2007, Linux has a scheduler called Completely Fair Scheduler. CFS does a lot of very fancy computer science stuff to prioritize and divide CPU time.
Each time a process is pushed, the OS must load the saved execution context of the new program, including the memory environment. This is achieved due to the CPU using another page table (page table) – a connection (mapping) between “virtual” and physical addresses. It also prevents one program from accessing the memory of another.
So far, we have only talked about offloading and scheduling user processes. Kernel code can cause programs to hang if system call processing or driver code execution takes too long.
Modern kernels, including Linux, are. This means that they are programmed so that the kernel code can be interrupted and scheduled by analogy with user processes.
It’s not really important unless you’re going to write kernel or something, but knowledge is never superfluous.
Ancient OSes, including classic macOS and versions of Windows long before NT, used a precursor to crowding out multitasking. Then it was not the OS that unloaded the programs, but the programs “yielded” (yield) to the OS. They would trigger a program interrupt, as if to say, “Hey, you can run another program.” These explicit concessions were the only way for the OS to regain control and switch to the next process.
This is called “cooperative multitasking”. The main disadvantage of this approach is that malicious or poorly designed programs can easily freeze the entire OS and it is almost impossible to ensure the consistency of real-time tasks.
We looked at how processors execute machine code, what is loaded from files, what is executed, what ring-based security is, and how system calls work. In this chapter, we’ll dive deep into the Linux kernel to find out how programs are loaded and executed.
We will look at Linux x86-64. Why?
Linux is a full-featured production OS for desktop, mobile and server environments. In Linux, the source code is open, which makes it possible to study it in all details;
x86-64 is the architecture used in most modern computers.
However, most of what we’ll talk about applies to other OSes and architectures.
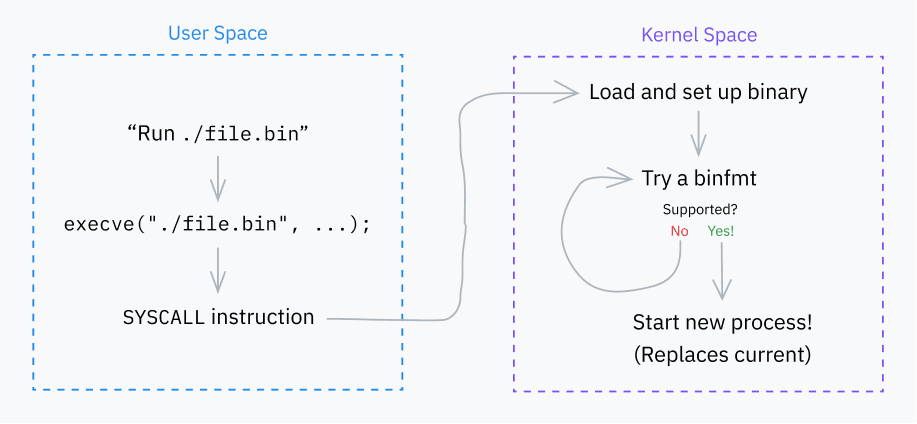
Let’s start with the very important execve system call. It downloads the program and if the download is successful, replaces the current process with this program. There are several other system calls (execlp, execvpet, etc.), but they are all based on execve in one way or another.
Note: execveat.
execve is actually built on top of execveat, a more general system call that runs a program with some tweaks. For simplicity, we will mainly talk about execve, which is a call to execveat with default settings.
Wondering what ve means? vmeans that one parameter is a vector (list) of arguments (argv), and emeans that the other parameter is a vector of environment variables (envp). Other system calls have different suffixes to indicate different call signals. atv execveat is simply “at”, which specifies the location to run execve.
The execve call signature looks like this:
int execve(const char *filename, char *const argv[], char *const envp[]);
the filename argument specifies the path to the program to be run;
argv is a null-terminated (the last element is a null pointer) list of program arguments. The argc argument, which is often passed to basic C functions, is actually evaluated later by the null-terminated system call;
The envp argument contains another null-terminated list of environment variables used as context for the application. They are… conventionally (by agreement) KEY=VALUE pairs. Conditionally. I adore computers.
Funny fact! Did you know that the rule that the first argument must be the program name is just a convention? execve doesn’t do any checks on this! The first argument will be what is passed to execve as the first element in the argv list, even if that element has nothing to do with the program name.
Interestingly, execve contains some code that assumes that argv[0] is the name of the program. We will talk more about this later.
We know how system calls work, but we haven’t looked at real code examples! Let’s see how execve is defined in the Linux kernel source code:
// fs/exec.c
// https://github.com/torvalds/linux/blob/22b8cc3e78f5448b4c5df00303817a9137cd663f/fs/exec.c#L2105-L2111
SYSCALL_DEFINE3(execve,
const char __user *, filename,
const char __user *const __user *, argv,
const char __user *const __user *, envp)
{
return do_execve(getname(filename), argv, envp);
}
SYSCALL_DEFINE3 is a system call code definition macro with three arguments.
The filename argument is passed to the getname() function, which copies a string from user space to kernel space and does some usage tracking. It returns the struct filename defined in include/linux/fs.h. This structure stores a pointer to the original string in user space, as well as a new pointer to the value copied into kernel space:
// include/linux/fs.h
// https://github.com/torvalds/linux/blob/22b8cc3e78f5448b4c5df00303817a9137cd663f/include/linux/fs.h#L2294-L2300
struct filename {
const char *name; /* указатель на скопированную строку в пространстве ядра */
const __user char *uptr; /* указатель на оригинальную строку в пространстве пользователя */
int refcnt;
struct audit_names *aname;
const char iname[];
};
execve then calls the do_execve() function. This in turn causes the do_execve_common() function to be called with the default settings. The execveat system call mentioned earlier also calls do_execve_common(), but passes it more user settings.
Below are the definitions of do_execve() and do_execveat():
// fs/exec.c
// https://github.com/torvalds/linux/blob/22b8cc3e78f5448b4c5df00303817a9137cd663f/fs/exec.c#L2028-L2046
static int do_execve(struct filename *filename,
const char __user *const __user *__argv,
const char __user *const __user *__envp)
{
struct user_arg_ptr argv = { .ptr.native = __argv };
struct user_arg_ptr envp = { .ptr.native = __envp };
return do_execveat_common(AT_FDCWD, filename, argv, envp, 0);
}
static int do_execveat(int fd, struct filename *filename,
const char __user *const __user *__argv,
const char __user *const __user *__envp,
int flags)
{
struct user_arg_ptr argv = { .ptr.native = __argv };
struct user_arg_ptr envp = { .ptr.native = __envp };
return do_execveat_common(fd, filename, argv, envp, flags);
}
In execveat, a file handle (a type of identifier that points to some resource) is passed first to the system call and then to do_execveat_common(). This specifies the directory against which the program is executed.
A special value of AT_FDCWD is used for the execve argument of the file descriptor. This is a shared Linux kernel constant that tells functions to interpret pathnames relative to the current working directory. Functions that accept file descriptors usually contain explicit checks like if (fd == AT_FDCWD) { /* … */ }.
We have reached do_execveat_common() – the main function for handling the execution of the program.
The first important task of do_execveat_common() is to set up a structure called linux_binprm. We won’t give a full definition of this structure, but here are some important points:
data structures such as mm_struct and vm_area_struct are defined to prepare virtual memory management for a new application;
argc and env are calculated and stored for passing to the program;
filename and interp store the filename of the program and its interpreter, respectively. They are initially equal to each other, but can change in some cases: one case where the executable binary differs from the program name is when running interpreted programs, such as Python scripts, with a shebang. In this case, filename will contain the name of the file, and interp will contain the path to the Python interpreter;
buf- This is an array filled with the first 256 bytes of the executable file. It is used to define the file format and load shebang scripts.
“binprm” stands for “binary program”.
Let’s take a closer look at the buf buffer:
// include/linux/binfmts.h // https://github.com/torvalds/linux/blob/22b8cc3e78f5448b4c5df00303817a9137cd663f/include/linux/binfmts.h#L64 char buf[BINPRM_BUF_SIZE];
As you can see, its length is determined by the BINPRM_BUF_SIZE constant. The definition of this constant is in include/uapi/linux/binfmts.h
// include/uapi/linux/binfmts.h // https://github.com/torvalds/linux/blob/22b8cc3e78f5448b4c5df00303817a9137cd663f/include/uapi/linux/binfmts.h#L18-L19 /* sizeof(linux_binprm->buf) */ #define BINPRM_BUF_SIZE 256
Thus, the kernel loads 256 bytes of the executable into the memory buffer.
What is UAPI?
You may have noticed that the code path above contains /uapi/. Why isn’t the buffer size defined in the same include/linux/binfmts.h file where the linux_binprm structure is defined?
UAPI stands for “userspace API” (user space interface). In this case, it means that someone decided that the length of the buffer should be part of the kernel’s public interface. In theory, all UAPIs are public, but no UAPIs are private to kernel code.
Kernel and userspace code originally co-existed in the same place. In 2012, the UAPI code was moved to a separate directory in an attempt to improve the maintainability of the code.
The next important task of the kernel is the sorting of “binfmt” (binary format) handlers. These handlers are defined in files such as fs/binfmt_elf.c and fs/binfmt_flat.c. Kernel modules can also add their binfmt handlers to the pool.
Each handler provides a load_binary() function that “takes” a linux_binprm structure and checks that the handler understands the program format.
This often involves looking for magic numbers in the buffer, trying to decode the program launch (also from the buffer), and/or checking the file extension. If the handler supports the format, it prepares the program to run and returns a success code. Otherwise, an early exit occurs and an error code is returned.
The kernel loops through the load_binary() functions of each binfmt until it succeeds. Sometimes this happens recursively. For example, if a script has a specific interpreter, and the interpreter itself is a script, the hierarchy might be: binfmt_script> binfmt_script> binfmt_elf (where ELF is the format executed at the end of the chain).
Let’s stop at binfmt_script.
Have you ever read or written a shebang? That line at the beginning of the script that defines the path to the interpreter?
#!/bin/bash
I always thought it was shellacked, but nope! In fact, shebangs are a “feature” of the kernel, and scripts are executed using the same system calls as other programs. Computers are so cool!
Let’s take a look at how fs/binfmt_script.c checks to see if a file starts with a shebang:
// fs/binfmt_script.c
// https://github.com/torvalds/linux/blob/22b8cc3e78f5448b4c5df00303817a9137cd663f/fs/binfmt_script.c#L40-L42
/* Файл не выполняется, если не начинается с "#!". */
if ((bprm->buf[0] != '#') || (bprm->buf[1] != '!'))
return -ENOEXEC;
If the file starts with shebang, the binfmt handler reads the interpreter path and any space-separated arguments after the path. It stops when a new line or the end of the buffer is reached.
Two interesting things happen here.
First, remember the buffer in linux_binprm that is filled with the first 256 bytes of the file? Not only is it used to determine the file format, but it also reads the shebangs in binfmt_script.
In the course of our research, we read an article that describes this 128-byte buffer. At some point after this article was published, the buffer size was increased to 256 bytes! Why? Checked the logs for editing the line of code where BINPRM_BUF_SIZE is defined in the Linux source code:
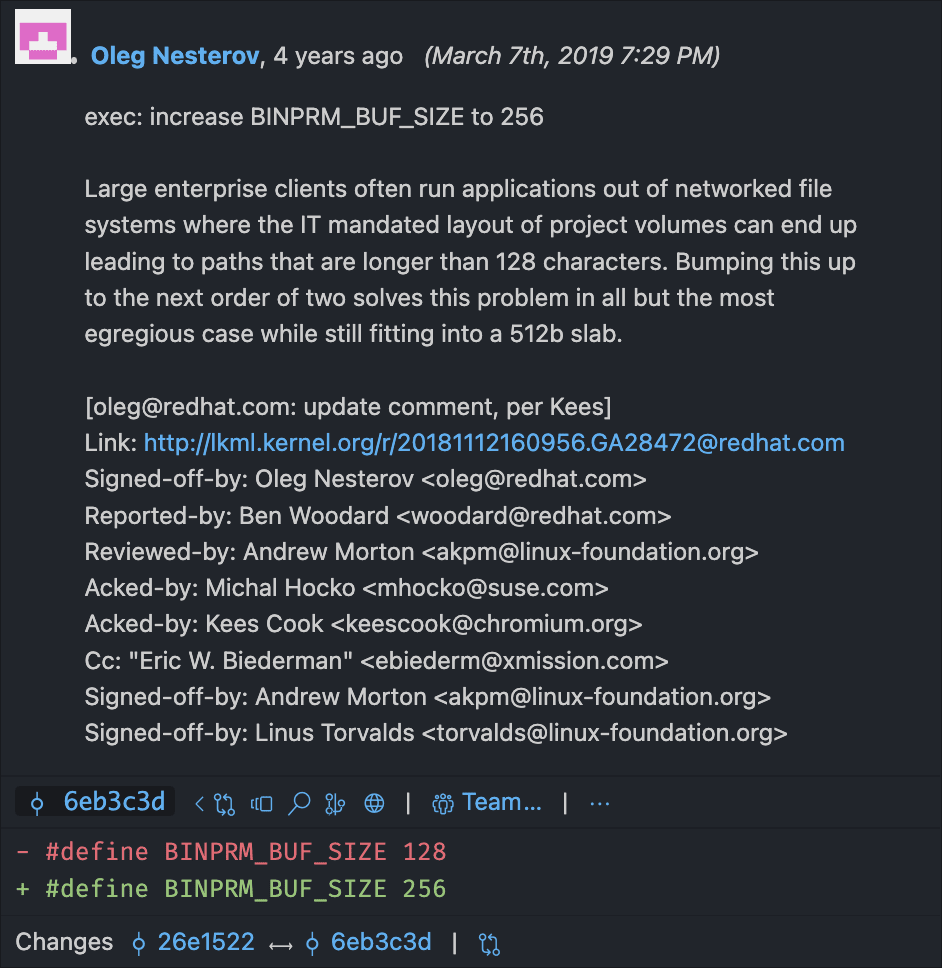
Since the shebangs are handled by the kernel, and the read happens instead of bufloading the entire file, they are always truncated to the buf length. Probably 4 years ago someone was really annoyed that their paths were being truncated to 128 bytes and decided to double the length. Today, on Linux, if you have a shebang longer than 256 characters, anything that follows them will be completely lost.

Imagine that because of this you got a bug. Imagine you’re trying to figure out the cause of a broken code. Imagine how you will feel when you discover that the reason lies deep in the Linux kernel. Woe to the next major developer who discovers that part of the road has mysteriously disappeared.
Second, remember that the argv[0] for the program name is just a convention, so the caller can pass any argv to the system call and they will pass without moderation?
It just so happens that binfmt_script is one of those places where it assumes that argv[0] is the name of the program. argv[0] is always removed and instead (at the beginning of argv) the following is added:
the path of the interpreter;
arguments to him;
the name of the script file.
Let’s look at an example of calling execve:
// аргументы: filename, argv, envp
execve("./script", [ "A", "B", "C" ], []);
A hypothetical script file contains this shebang on the first line:
#!/usr/bin/node --experimental-module
The modified argv passed to the Node.js interpreter would look like this:
[ "/usr/bin/node", "--experimental-module", "./script", "B", "C" ]
After updating argv, the handler completes preparing the file for execution by setting the linux_binprm.interpinterpreter path value. Finally, it returns 0 as an indicator that the program was successfully prepared for execution.
Another interesting handler is binfmt_misc. It allows some limited formats to be added via userspace settings by mounting a custom filesystem in /proc/sys/fs/binfmt_misc/. Applications can make specially formatted writes to files in this directory to add their own handlers. Each configuration contains information about:
How to determine the file format. A magic number can be defined for a certain offset or file extension for searching;
the path to the executable file of the interpreter. There is no way to specify the arguments of the interpreter, which requires a wrapper script;
some configuration flags, including one that defines how binfmt_misconfigures argv.
This binfmt_misc system is often used by Java installations configured to detect class files by their magic 0xCAFEBABE bytes and JAR files by their extension. On my system, the handler is configured to detect Python bytecode from the .pyc extension and pass it to the appropriate handler.
This allows application installers to add support for their formats without writing high-privileged kernel code.
A system call always ends up doing one of two things:
eventually an executable binary format is reached that it understands and the code executes. And here the replacement of the old code takes place;
or an error code is returned to the calling program after all possibilities have been exhausted.
If you’ve used a Unix system, you may have noticed that shell scripts run even without the shebang line or the .sh extension.
$ echo "echo hello" > ./file $ chmod +x ./file $ ./file hello
chmod +x tells the OS that the file is being executed. Otherwise, the file cannot be executed.
So why does a shell script run as a shell script? Kernel handlers should not define shell scripts without explicit labels!
In fact, this behavior is not part of the core. This is a typical shell error handling method.
When we execute a file with a shell and the system call fails, most shells re-execute the file as a shell script by calling the shell with the filename as the first argument. Bash usually uses itself as an interpreter, while ZSH usually uses the Bourne shell.
This behavior is standard because it is defined in POSIX, an old standard designed to make code portable between different Unix systems. Although POSIX is not fully adhered to by most tools and OSes, many of its conventions are generally accepted.
If the [system call] fails with an error similar to the [ENOEXEC] error, the shell must execute a similar command with the command name as the first operand and other arguments passed to the new shell. If the file being executed is not a text file, the shell may skip this command. In this case, the shell should write an error message and return an exit status of 126.
Now we have a good understanding of execve. In most cases, the kernel reaches the program containing the machine code to run. As a rule, running the code is preceded by some configuration process, for example, different parts of the program must be loaded into the correct places in memory. Each program needs different amounts of memory for different things, so we have standard file formats to define the program’s settings for execution. Although Linux supports many formats, the most common is ELF (executable and linkable format).
When we run a program or a command line program on Linux, it is likely that an ELF binary is run. However, on macOS, the actual format is Mach-O. Mach-O does the same thing as ELF but has a different structure. On Windows, .exe files are in the Portable Executable format, which follows the same concept.
In the Linux kernel, ELF “binaries” are handled by the binfmt_elf handler, which is more complex than most handlers and contains thousands of lines of code. It is responsible for parsing certain details from the ELF file and using them to load the process into memory and execute it.
$ wc -l binfmt_* | sort -nr | sed 1d
2181 binfmt_elf.c
1658 binfmt_elf_fdpic.c
944 binfmt_flat.c
836 binfmt_misc.c
158 binfmt_script.c
64 binfmt_elf_test.c
Before looking at how binfmt_elf handles ELF files, let’s take a look at the file format itself. ELF files usually consist of 4 parts:

Each ELF file has a header. It has a very important role – the transfer of such basic information about the binary as:
for which processor it is intended. ELF files can contain machine code for different processor types, such as ARM and x86;
whether the binary is intended to be run as an executable file or to be loaded by another program as a “dynamically linked library”. We’ll talk about dynamic binding later;
executable entry point. Determines where in memory to load data from the ELF file. An entry point is a memory address that indicates where in memory the first instruction of the machine code is located after the entire process is loaded.
The ELF header is always at the beginning of the file. It defines the locations of the program header table and section header table, which can be anywhere within the file. These tables, in turn, point to data stored somewhere in the file.
The program’s header table is a series of entries that contain details on how to load and run the binary at runtime. Each record has a type field that tells what details it defines: for example, PT_LOAD means that the record contains data that should be loaded into memory, and PT_NOTE means a segment containing informational text that may not be loaded anywhere.

Each entry contains information about where the data is in the file and sometimes how to load the data into memory:
it points to the data position in the ELF file;
it can specify the memory address where the data should be loaded. If no data is to be loaded into memory, this segment is left empty;
2 fields define the length of the data: one for the length of the data in memory, the other for the length of the memory area to create. If the memory length exceeds the file length, the extra memory is filled with zeros. This allows programs to reserve static memory for use at runtime. These empty memory segments are commonly called BSS segments;
finally, the flags field determines what operations are allowed when loaded into memory: PF_Rmakes the data read-only PF_W- for writing PF_X- for CPU execution.
A section header table is a series of records that contain information about sections. Section information is like a card that displays the data inside an ELF file. This makes it easier to understand the intended use of data elements by programs such as debuggers.
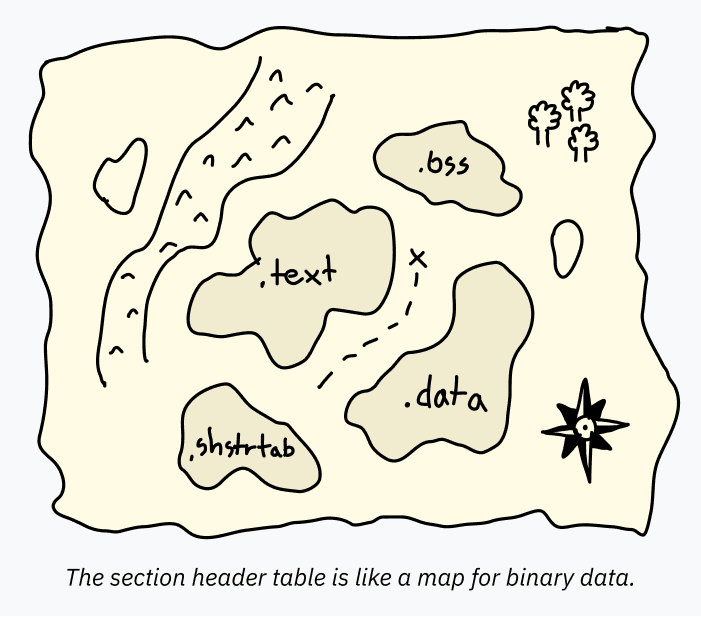
For example, an application’s header table may define a large set of data to load memory entirely. A single PT_LOAD block can contain both code and global variables! Their separate definition is not required to run the program. The CPU starts at the entry point and moves forward, retrieving data about the program’s requests. However, a debugger-type software to analyze the program must know exactly where each piece of data begins and ends, otherwise it might try to decode the string “hello” as code (and since the string is not valid code, “explode”). Such information is stored in the section header table.
Although a table of section headings is usually included, it is actually optional. ELF files can run fine if this table is completely removed. Developers who want to hide their code sometimes intentionally remove or obfuscate it in ELF binaries to make it more difficult to decode.
Each section contains a name, a type, and some flags that define how the data should be used and decoded. Standard names usually start with a dot after agreement. The most common sections are:
.text – machine code for loading into memory and execution in the CPU. The SHT_PROGBITS type with the SHF_EXECINSTR flag marks it as executable. The SHF_ALLOC flag indicates loading into memory for execution;
.data – initialized data hard-coded in a file for loading into memory. This section can contain, for example, a global variable containing some text. If you’re writing low-level code, this is the section where the static “lives”. The SHT_PROGBITS type simply means that the partition contains information for the application. The SHF_ALLOC and SHF_WRITE flags mark it as writable memory;
.bss- Usually part of the allocated memory starts from zero. It’s not smart to put a bunch of empty bytes in an ELF file, that’s what the BSS section is for. BSS segments are useful to know during debugging. There is an entry in the section header table that defines the length of the allocation memory. The type here is SHT_NOBITS, and the flags are SHF_ALLOC and SHF_WRITE;
.rodata- This is the same as .data, but read-only. In the simplest C program that runs printf(“Hello, world!”), the line “Hello, world!” will be in the .rodata section, and the display code itself (printing code) – in the .text section;
.shstrtab is a funny implementation fact! Section titles themselves (such as .text and .shtrtab) are not included in the section header table. Each entry contains an offset to the location in the ELF file containing its name. This makes parsing table entries easier due to their fixed size (indentation is a fixed-size number, and names are a variable-size string to include in the table). All of this name data is stored in a separate .shstrtab section of type SHT_STRTAB.
The program and header section table entries indicate which blocks of data within the ELF file should be loaded into memory, where code should be located, or simply called sections. All these different pieces of data are contained in the “Data” section of the ELF file.
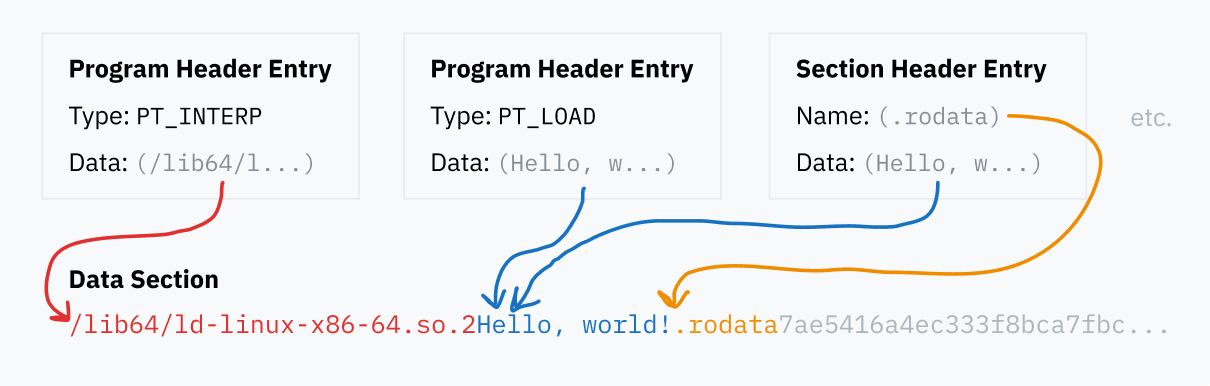
Back to the binfmt_elf code, the kernel takes care of two types of entries from the application header table.
The PT_LOAD segments define where all these programs should be loaded, such as the .text and .data sections. The kernel reads these entities from the ELF file to load the data into memory so that the program can be executed by the CPU.
Another type of application header table entry that the kernel cares about is PT_INTERP, which defines the “dynamic linking runtime”.
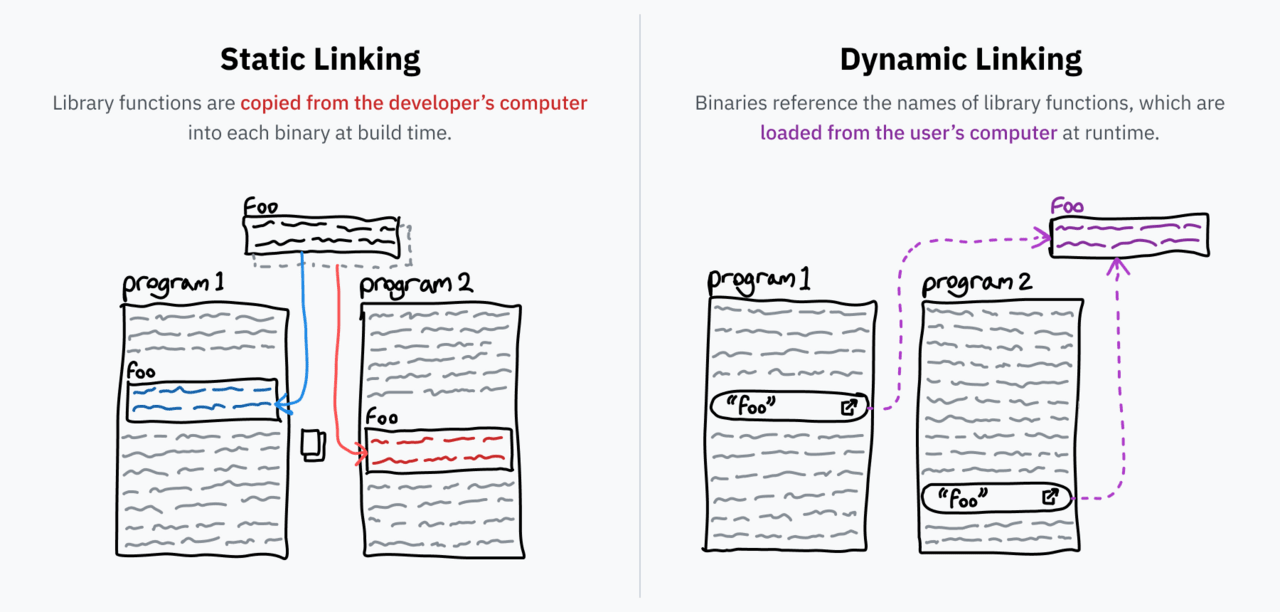
Let’s start with what is “linking” or “composition” (linking). Programmers tend to write programs on top of reusable code libraries, such as libc mentioned earlier. When converting the source code into an executable binary, the program calls the linker, which allows all links by identifying the library code and copying it into the binary. This process is called “static linking” (static linking) – the external code is included directly in the distributed file.
Some libraries are very popular. The same libc is used by almost all programs because it is the canonical interface for interacting with the OS through system calls. What shall I do? Include a separate copy of libc for each program on the machine? What if libc has a bug? Will I have to update all apps? These problems are solved by dynamic layout.
If a statically linked program needs the foo() function from the bar library, a copy of that function is included in the program. However, with dynamic linking, only a reference is included in the program, which seems to say it needs foo() with bar”. When the program starts (provided that bar is installed on the computer), the machine code for the function foo() is loaded into memory at requirement (on-demand) When updating the installation, the barcode is loaded into the application the next time it is launched without the need to change the application itself.
On Linux, dynamically linked bar libraries are usually packaged in files with the .so (shared object) extension. These .so files are the same ELF files as programs. The ELF header contains a field that specifies whether the file is an executable or a library. In addition, common objects contain a .dynsym section of the section header table that contains information about which symbols are exported from the file and can be dynamically linked.
In Windows, libraries are packaged in files with the extension .dll (dynamic link library). macOS uses the .dylib (dynamically linked library) extension. Also like macOS and .exeWindows files, these formats are slightly different from ELF files, but follow the same concept and technique.
An interesting difference between the two types of linking is that with static linking, the executable file is included (loaded into memory), only part of the library is used. In the case of dynamic linking, the entire library is loaded into memory. At first glance, this seems less efficient, but it actually allows modern OSes to save more space by loading the library into memory once and distributing the code between processes. Only the code can be shared because the library needs different state for different applications, but the savings can still be around tens to hundreds of MB of RAM.
Let’s go back to the kernel executing ELF files: if the executable binary is dynamically linked, the OS cannot immediately jump to its code, because not all the code is available – dynamically linked programs only contain references to the functions they need libraries!
To run the OS binary, you need to define the necessary libraries, load them, replace all named pointers with real jump instructions, and then run the complete program code. This is very complex code that interacts deeply with the ELF format, so it’s usually a separate program rather than part of the kernel. ELF files specify the path to the program they want to use (something like /lib64/ld-linux-x86-64.so.2) in the PT_INTERP entry of the program header table.
After reading the ELF header and scanning the program’s header table, the kernel configures the memory structure for the program. It all begins by loading all PT_LOAD segments, static data, BSS space, and program machine code into memory. If the program is dynamically linked, the kernel must execute the ELF interpreter (PT_INTERP), so it also loads the data, BSS, and interpreter code into memory.
The kernel now needs to set the instruction pointer to the CPU to recover when returning to user space. If the executable is dynamically linked, the kernel sets the instruction pointer to the beginning of the ELF interpreter code in memory. Otherwise, the kernel sets it to the beginning of the executable.
The kernel is almost ready to return from the system call (remember we’re still in execve). It pushes the argc and argv environment variables onto the stack to be read by the program at startup.
After that, the registers are cleared. Before processing a system call, the kernel stores the current value of the registers on the stack for later restoration when switching back to user space. Before returning to user space, the kernel fills this part of the stack with zeros.
Finally, the system call terminates and the kernel returns to user space. It restores the registers, which are now filled with zeros, and moves to the stored instruction pointer. This pointer is the starting point of a new program (or ELF interpreter) and the current process is replaced by the new one!
So far, all of our talk about reading and memorizing has been a bit vague. For example, ELF files define specific memory addresses to load data from, so why aren’t there problems with processes trying to use the same addresses? Why does each process seem to access different memory?
We understand that execve is a system call that replaces the current process with a new program, but that doesn’t explain how multiple processes can be running at the same time. It also does not explain how the first program is launched – the process that spawns other processes.
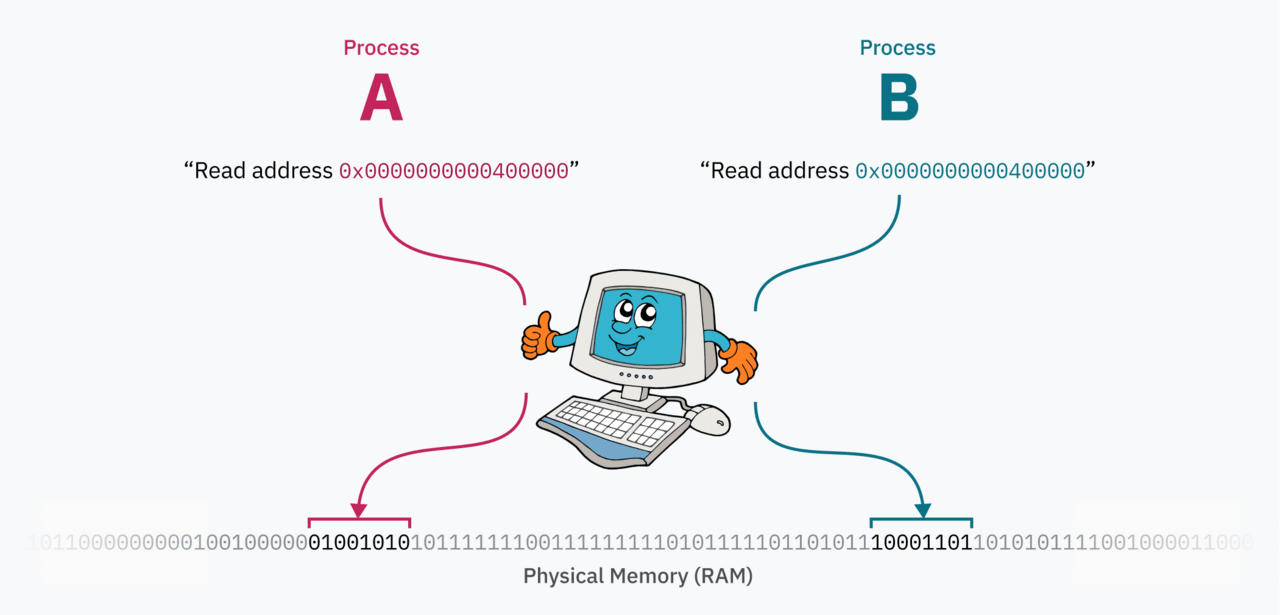
It turns out that when the CPU reads or writes to a memory address, it is not a location in physical memory (PRM). This is a place in virtual memory space.
The CPU “communicates” with a chip called a memory management unit (MMU). MMU uses a dictionary to translate locations in virtual memory into locations in the OP. When the CPU receives an instruction to read from memory address 0xAD4DA83F, it turns to the MMU for address translation. The MMU “looks” in the dictionary, finds a physical address that matches 0x70B7BD74, and returns that number to the CPU. After that, the CPU reads from this address in the OP.
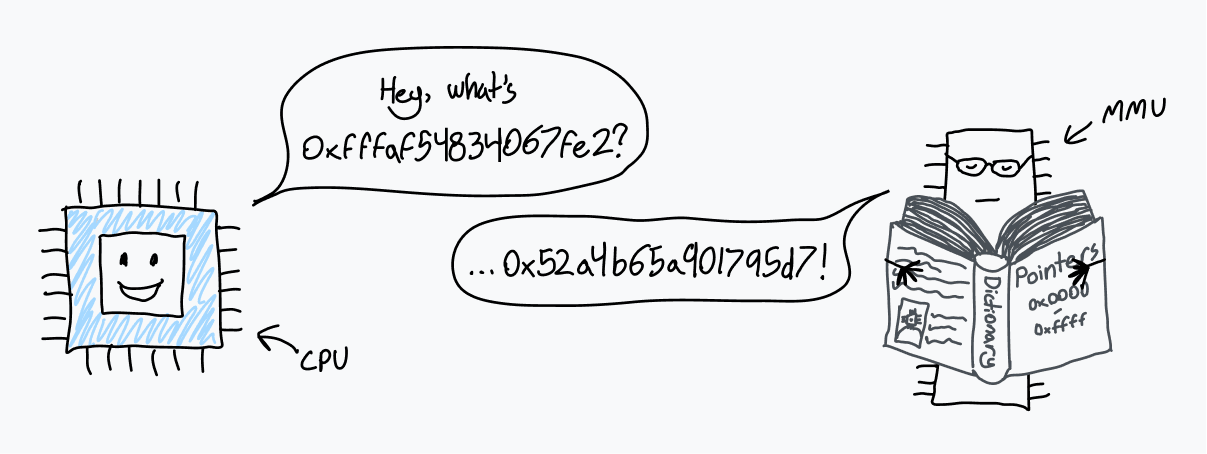
After switching on, the computer works with a physical virtual machine. Immediately after that, the OS creates a dictionary and tells the CPU to use the MMU.
This dictionary is called a “page table”, and the system for translating each memory address is called “paging”. Entries of the page table are called pages. A page is a connection of a certain part (chunk) of virtual memory with the OP. These parts always have a fixed size, each processor architecture has its own size. The x86-64 page size is 4KB ie. each page defines a link for a block of memory 4096 bytes long (x86-64 allows the OS to have large pages of 2 MB or 4 GB, which increases the speed of address translation, but increases fragmentation and memory loss).
The page table itself simply lies in the VP. Although it can contain millions of records, the size of each record is only a couple of bytes, so it does not take up much space.
In order to enable paging at boot time, the kernel first creates a page table in the OP. It then stores the physical address of the start of the page table in a register called the page table base register (PTBR). Finally, the kernel includes a swap conversion of all memory addresses using the MMU. In x86-64, the upper 20 bits of Control Register 3 (CR3) function as PTBR. Bit 31 of the CR0 (PG) register is set to 1 to enable paging.
The magic of the page table lies in the ability to edit it while the computer is running. This allows each process to have its own isolated memory space, when the OS switches context from one process to another, it is important to bind the virtual memory space to a different physical memory area. Let’s say we have two processes: Process A’s code and data (probably loaded from an ELF file) resides at 0x0000000000400000, and Process B accesses the code and data at the same address. These two processes can even be instances of the same program because there are no memory conflicts between them! In physical memory, the data of process A lies far from process B, binding to 0x0000000000400000 is performed by the kernel when switching processes.
Note: A negative fact about ELF.
In some situations, binfmt_elf must map the first memory page to zeros. Some programs written for UNIX System V Release 4.0 (SVr4), OS 1988, the first to support ELF, rely on reading null pointers. Miraculously, some programmers still rely on this behavior.
It seems the Linux kernel developer who implemented this was a little unhappy.
“You ask why??? Well, SVr4 renders the page as read-only and some applications “depend” on this behavior. Since we have no way to recompile them, we are forced to emulate SVr4 behavior. Sigh.”
Process isolation provided by memory pumping not only improves code ergonomics (processes do not need to worry about other processes using memory), but also creates a layer of security: one process cannot access other processes. This is half the answer to the question:
If the programs run directly in the CPU, and the CPU has direct access to the OP, why can’t the code access the memory of another process or, sorry, the kernel?
What about kernel memory? In fact, the kernel needs to store a lot of its own data to keep track of all running processes and the same page table. Every time a system call is interrupted or started when the CPU enters kernel mode, the kernel must somehow access the memory.
Linux’s solution is to always allocate the upper half of the kernel’s virtual memory, which is why Linux is called the higher half kernel. Windows practices a similar technique, but macOS is… a bit more complicated (ed: note that there are three different links here).

From a security perspective, it would be terrible if user processes had access to kernel memory, so swapping adds a second layer of security: each page must define permission flags. One flag specifies whether the memory area is read-only or also writable. Another flag tells the CPU that only the kernel has access to the region. This flag is used to protect all the space of the upper half of the kernel – in fact, user programs have all the memory space of the kernel in the virtual memory map, they just do not have the appropriate permissions.

The page table itself is actually contained in the kernel memory space! When the timer chip triggers a hardware interrupt to switch processes, the CPU switches the privilege level and goes to the Linux kernel code. Being in kernel mode (Intel ring 0) allows the CPU to access a protected area of kernel memory. The kernel can then write to the page table (which resides somewhere in this upper half of memory) to re-allocate the lower portion of virtual memory for the new process. When the kernel switches to a new process and the CPU enters user mode, its access to kernel memory is closed.
Almost all memory access is through the MMU. What about interrupt handler table pointers? They also access the kernel’s virtual memory space.
64-bit systems have memory addresses that are 64 bits long, so the 64-bit virtual memory space is a whopping 16 exibytes. This is an incredible amount, much more than any modern or near-future computer can boast. As far as is known, the Blue Waters supercomputer had the largest OP (more than 1.5 petabytes – less than 0.01% of 16 EB).
If a page table entry is required for each 4KB virtual memory partition, 4503599627370496 such entries are required. With 8-byte page table entries, 32 pebibytes of table storage alone are required. As you can see, this still exceeds the world record for the volume of VP in a computer.
Since it is impossible (or at least very impractical) to have consecutive page table entries for all possible memory space, CPU architectures implement hierarchical paging (hierarchical paging). In such systems, there are several levels of page tables with progressively finer granularity. The top-level records cover large blocks of memory and point to the page tables of smaller blocks, creating a tree-like structure. Individual entries for blocks of 4 KB or other size are leaves of the tree.
x86-64 has historically used four-level hierarchical paging. In this system, each entry in the page table is determined by shifting the beginning of the table containing it by a portion of the address. This part starts with the most significant bits, which work as a prefix, so the entry covers all addresses starting with those bits. The entry indicates the beginning of the next level of the table containing the subtrees of this block of memory, which are again indexed by the next set of bits.
The designers of four-level paging also decided to ignore the high-order 16 bits of all virtual pointers in order to save space in the page table. 48 bits gives us a virtual address space of 128 TB, which is considered quite large.
Since the first 16 bits are omitted, the “most significant bits” for indexing the first level of the page table actually start at the 47th bit, not the 63rd bit. This also means that the above diagram of the upper half of the kernel was technically inaccurate: the starting address space of the kernel should be represented as the middle of an address space smaller than 64 bits.
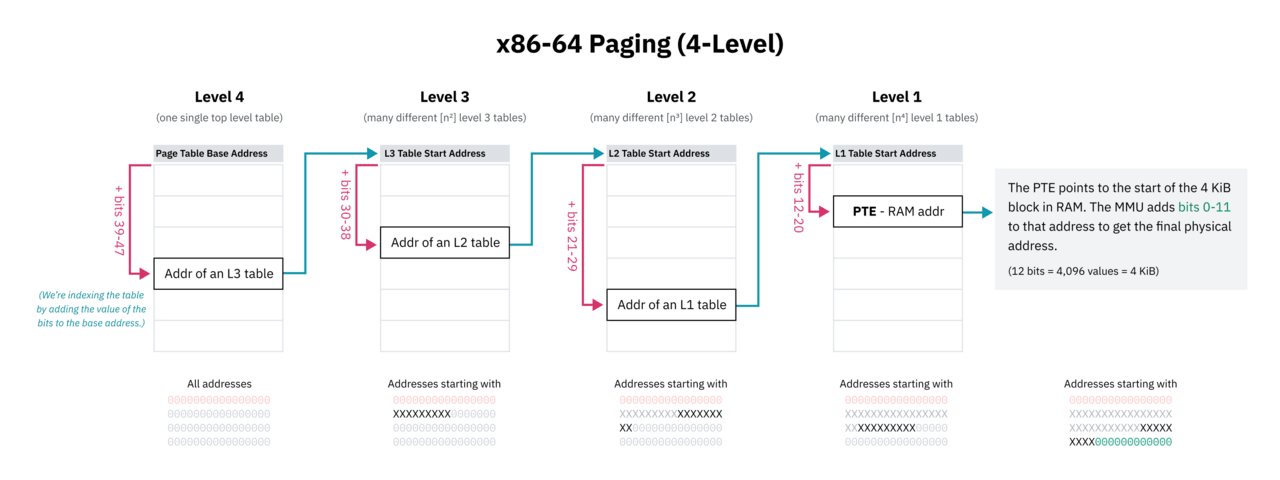
Hierarchical paging solves the space problem because at any level of the tree the pointer to the next entry can be null (0x0). This allows you to exclude entire subtrees of the page table – unmapped areas take up space in the OP. Searches for unbound memory addresses quickly fail because the CPU returns an error when it encounters an empty entry higher up the tree. Using the presence flag, page table entries can be marked as unusable, even if the address appears to be valid.
Another advantage of hierarchical swapping is the ability to effectively switch large sections of virtual memory. A large area of virtual memory can be mapped to one area of physical memory of one process and to another area of another process. The kernel can keep both mappings in memory and simply update the pointers at the top level of the tree when switching processes. If the entire memory space map were stored as a flat array of entries, the kernel would have to update many entries, which would be slow and require independent tracking of memory mappings for each process.
I said x86-64 “historically” uses four-level paging because recent processors implement five-level paging. Five-level paging adds another level of abstraction as well as 9 bits of addressing to expand the address space to 128 PB with 57-bit addresses. This swapping has been supported by Linux since 2017, as well as recent server versions of Windows 10 and 11.
Note: limitation of physical address space.
OSs do not use all 64 bits of virtual addresses, and CPUs do not use all 64 bits of physical addresses. When 4-level paging was the standard, x86-64 processors did not use more than 46 bits. This meant that the physical address space was limited to only 64 TB. Processors with 5-level paging use up to 52 bits, supporting a physical address space of up to 4 PB.
At the OS level, it is beneficial for the virtual space to be larger than the physical space. As Linus Torvalds said: “[virtual space should be larger than physical space], at least 2 times, preferably 10 or more. Anyone who doesn’t understand this is a fool. End of discussion.”
A memory access may fail for several reasons: the address may be outside the valid range, it may not appear in the page table, or it may contain an entry marked as missing. In all these cases, the MMU initiates a hardware interrupt called a “page fault” to transfer control to the kernel.
If the read was indeed invalid or forbidden, the kernel terminates the program with a segmentation fault (segmentation fault, segfault):
$ ./program Segmentation fault (core dumped)
Note: origin of segfault.
A “segmentation fault” means different things depending on the context. The MMU triggers a hardware interrupt called a “segmentation fault” when an unauthorized memory read occurs, but a “segmentation fault” is also the name of a signal that the OS sends to a running program to force it to terminate due to illegal access to memory
In other cases, a memory access may “intentionally” fail, allowing the OS to fill the memory and hand over control to the CPU to retry. For example, the OS can match a file on disk with virtual memory without downloading it to the OS, and make such a download only when an address is requested and a page fault occurs. This is called “demand paging”.

This allows system calls like mmap to lazily map entire files from disk to virtual memory. Justin Tunney recently significantly optimized LLaMa.cpp, Facebook’s language model runtime, by making all loading logic use mmap.
When the program and its libraries are executed, the kernel does not actually load anything into memory. Only the mmap file is created – when the CPU tries to execute the code, a page fault occurs immediately and the kernel replaces the page with a real block of memory.
On-demand swapping also allows for a method known as “swapping” or simply “swapping”. OSes can free physical memory by writing memory pages to disk and then removing them from physical memory but keeping them in virtual memory with the presence flag set to 0. When reading this virtual memory, the OS restores memory from disk to the OS and sets the flag back to 1. In this, the OS can swap RAM partitions to make room for memory loaded from disk. Disk read and write operations are slow, so OSes try to minimize paging by using efficient page replacement algorithms.
An interesting technique is the use of pointers to the physical memory of the page table for storing file locations in physical memory. Since the MMU returns a page fault as soon as it sees a negative presence flag, whether the address is valid or not is irrelevant.
Approx. trans.: the author plays with the words “fork” and “cow”.
Last question: where does the first process come from?
If execve runs a new program replacing the current process, how do I run the new program separately in the new process? This is important if we want to do several things on the computer at the same time: when we double-click on a program icon, it starts separately, while the program in which we worked before continues to work.
The answer is another system call: fork, which is at the heart of multitasking. fork is very simple: it clones (copies) the current process and its memory without touching the stored instruction pointer, and then allows both processes to continue. Programs continue to run independently of each other, and all calculations are duplicated.
The newly started process is called “child”, and the cloned one is called “parent”. Processes can fork multiple times, producing many children (descendants). Each descendant is numbered with a process identifier (process ID, PID) that starts with 1.
Mindlessly duplicating code is pretty useless, so fork returns different values for parent and child processes. For the ancestor, it returns the PID of the new child process, and for the descendant it returns 0. This allows you to do other work in the new process, so forking is really useful.
pid_t pid = fork();
// С этой точки код продолжается как обычно, но через
// два "одинаковых" процесса.
//
// Одинаковых... за исключением PID, возвращаемого из `fork()`!
//
// Это единственный индикатор того, что мы имеем дело
// с разными программами.
if (pid == 0) {
// Мы находимся в дочернем процессе.
// Производим некоторые вычисления и передаем результат предку!
} else {
// Мы в родительском процессе.
// Продолжаем делать то, что делали.
}
Process branching can be difficult to understand. We assume you know how it works. If not, check out this unattractive site with a good explanation.
Thus, Unix programs start new programs by calling fork and running execve in the new child process. This is called the “fork-exec pattern”. When starting the program, our computer executes the following code:
pid_t pid = fork();
if (pid == 0) {
// Заменяем дочерний процесс новой программой.
execve(...);
}
// Если мы попали сюда, значит, процесс не был заменен. Мы находимся в родительском процессе!
// PID дочернего процесса хранится в переменной `pid` на случай,
// если мы захотим его убить.
// Здесь продолжается код родительской программы...
You might have noticed that duplicating a process’s memory only to discard it when another program loads sounds a bit inefficient. Duplicating data in physical memory is a slow process, but not duplicating page tables, so we simply don’t duplicate the OP: we create a copy of the old process’s page table for the new process – the mapping points to the same lower physical memory.
But the child process must be independent and isolated from the parent! It is not good if a descendant writes in memory of an ancestor, and vice versa!
I present to you COW (copy on write – copying during recording, cow – a cow). COW allows both processes to read from the same physical addresses as long as they attempt to write to the memory. As soon as the process tries to do this, this page is copied to the OP. This allows both processes to have isolated memory without cloning the entire memory space. This determines the effectiveness of the fork-exec pattern. Since none of the old processes write to the memory before the new binary is loaded, the memory is not copied.
COW is implemented, like many other funny things, through page hacks and hardware interrupt handling. After cloning the pages with fork, it marks (sets the appropriate flags) the pages of both processes as read-only. This triggers a segfault (a type of hardware interrupt) that is handled by the kernel. The memory-duplicating kernel refreshes the page to allow the write and returns from the interrupt to retry the write.
Early
Every process on the computer is the result of a fork-executed parent program, except for one: the init process. The initialization process is set manually by the kernel. It is the first user program on startup and the last on shutdown.
Want to see an instant black screen bite? If you have macOS or Linux, save your work, open a terminal, and kill the initialization process (PID 1):
$ sudo kill 1
Note: Knowledge of the initialization process is unfortunately only applicable to Unix-like systems such as macOS or Linux. Most of what you’ll learn next doesn’t apply to Windows, which has a very different kernel architecture.
The initialization process is responsible for creating all the programs and services that make up the OS. Many of them, in turn, create their own services and programs.
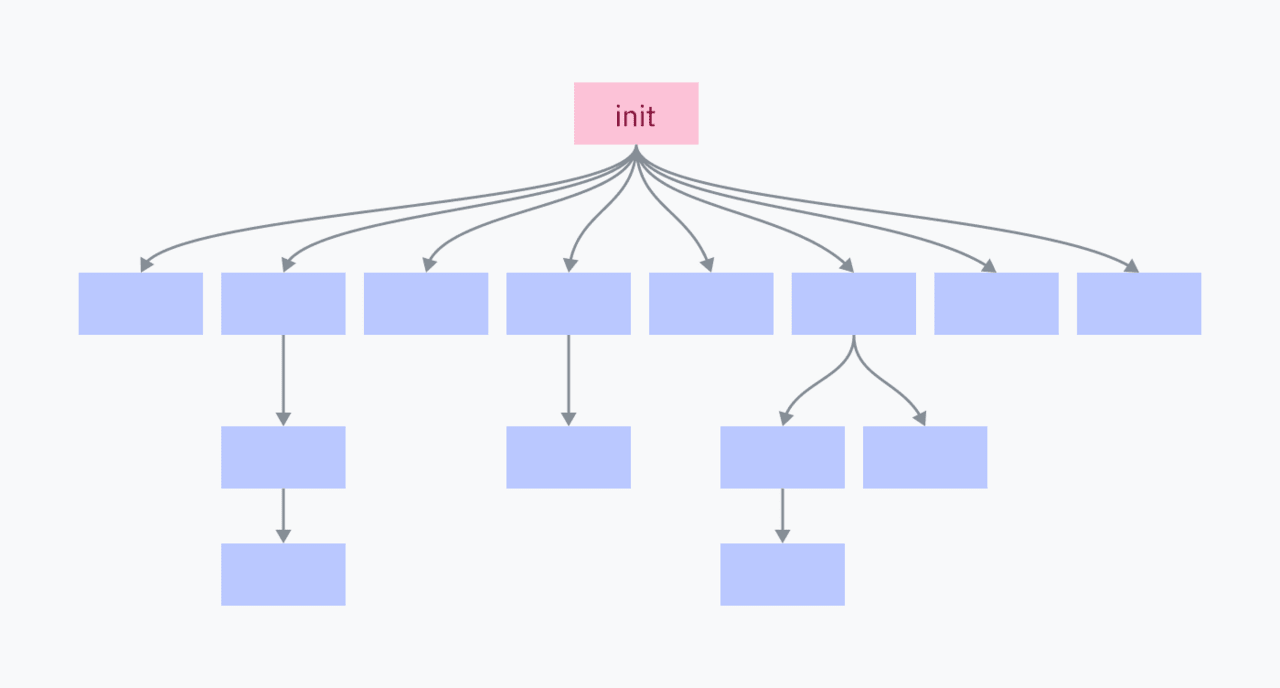
Completing the initialization process terminates all of its children and their children, resulting in the OS shutting down.
Consider how the kernel starts the initialization process.
The computer does the following sequence of things:
The motherboard comes with a small piece of software that searches for a program called a “bootloader” on connected drives. It selects a loader, loads its machine code into a VP, and executes that code. Remember that the OS is not yet running. There is no multitasking or system calls before the initialization process starts. In the pre-initialization context, “executing” a program means going directly to the machine code in the OP without waiting for a return.
The loader is responsible for detecting the kernel, loading it into the VP, and executing it. Some boot loaders, such as GRUB, can be configured and/or selected between multiple OSes. The built-in bootloaders for macOS and Windows are BootX and Windows Boot Manager, respectively.
The kernel starts up and proceeds to perform a large number of initialization tasks, including setting up interrupt handlers, loading drivers, and creating an initial memory map. Finally, the kernel enters user mode and runs the initialization program.
Now we are in the user space of the OS! The initialization program executes initialization scripts, starts services, and executes applications such as the shell/UI (user interface).
On Linux, kernel initialization (step 3) occurs in the start_kernelinit/main.c function. This function calls more than 200 other initialization functions, so we won’t include the entire code in the article, but we recommend that you familiarize yourself with it. At the end of start_kernel, the arch_call_rest_init function is called:
// init/main.c
// https://github.com/torvalds/linux/blob/22b8cc3e78f5448b4c5df00303817a9137cd663f/init/main.c#L1087-L1088
/* Делаем остальное без "__init", теперь мы живы */
arch_call_rest_init();
Note: What does no __init mean?
The start_kernel function is defined as asmlinkage __visible void __init __no_sanitize_address start_kernel(void). The strange words __visible and __init are __no_sanitize_address macros of the C preprocessor and are used by the Linux kernel to add various code and behavior to a function.
In this case, __init is a macro that tells the kernel to unload the function and its data from memory after the startup process is complete to save space.
How does it work? Without diving too deeply into the details, the Linux kernel itself is packaged as ELF. The __init macro is converted to a __section(“.init.text”) compiler directive to place code in the .init.text section instead of the normal .text section. Other macros also allow data and constants to be placed in special sections, for example __initdata becomes __section(“.init.data”).
arch_call_rest_init is just a function-
// init/main.c
// https://github.com/torvalds/linux/blob/22b8cc3e78f5448b4c5df00303817a9137cd663f/init/main.c#L832-L835
void __init __weak arch_call_rest_init(void)
{
rest_init();
}
The comment says “doing else without __init” because rest_init is not defined by the __init macro. This means that it is not unloaded to clear memory:
// init/main.c
// https://github.com/torvalds/linux/blob/22b8cc3e78f5448b4c5df00303817a9137cd663f/init/main.c#L689-L690
noinline void __ref rest_init(void)
{
Next, rest_init creates a thread for the initialization process:
/* * Сначала нам нужно создать процесс, чтобы он получил pid 1, однако * задача инициализации, в конечном итоге, захочет создать kthreads, которые, * если мы запланируем их до kthreadd, будут OOPS. */ pid = user_mode_thread(kernel_init, NULL, CLONE_FS);
The kernel_init parameter passed to user_mode_thread is a function that completes some initialization tasks and then looks for a valid init program to run. This procedure begins with some basic setup tasks. Let’s skip most of the code where this happens, except for the free_initmem call. This is where the kernel frees the .init sections!
free_initmem();
Now the kernel can find the appropriate program to run:
/*
* Мы пробуем каждую, пока не достигнем успеха.
*
* Вместо init можно использовать оболочку Борна, если мы
* пытаемся восстановить по-настоящему сломанную машину.
*/
if (execute_command) {
ret = run_init_process(execute_command);
if (!ret)
return 0;
panic("Requested init %s failed (error %d).",
execute_command, ret);
}
if (CONFIG_DEFAULT_INIT[0] != '\0') {
ret = run_init_process(CONFIG_DEFAULT_INIT);
if (ret)
pr_err("Default init %s failed (error %d)\n",
CONFIG_DEFAULT_INIT, ret);
else
return 0;
}
if (!try_to_run_init_process("/sbin/init") ||
!try_to_run_init_process("/etc/init") ||
!try_to_run_init_process("/bin/init") ||
!try_to_run_init_process("/bin/sh"))
return 0;
panic("No working init found. Try passing init= option to kernel. "
"See Linux Documentation/admin-guide/init.rst for guidance.");
On Linux, the init program is almost always located or symlinked to /sbin/init. Common initialization programs are systemd, OpenRC, and runit. kernel_init() defaults to /bin/sh if it finds nothing else. If it doesn’t find /bin/sh, then something is terribly wrong.
MacOS also has an initializer! It is called launchd and is located in /sbin/launchd. Try running it in the terminal and get a message that you are not a kernel.
Here we go to step 4 of the computer startup process: the initialization process runs in user space and starts running various programs using the fork-exec pattern.
How the Linux kernel remaps the bottom of memory when cloning processes. Most of the process cloning code appears to be in kernel/fork.c . The beginning of this file told us the right place to look:
// kernel/fork.c // https://github.com/torvalds/linux/blob/22b8cc3e78f5448b4c5df00303817a9137cd663f/kernel/fork.c#L8-L13 /* * 'fork.c' содержит подпрограммы помощи (help-routines) для системного вызова 'fork' * (см. также entry.S и др.). * Клонирование является простым, когда вы его освоите, но * управление памятью может быть стервой. См. 'mm/memory.c': 'copy_page_range()' */
It looks like the copy_page_range() function takes some memory mapping information and copies the page tables. A cursory look at the functions it calls makes it clear that pages become read-only to become COW pages. Determining whether this is necessary is done using the is_cow_mapping() function.
is_cow_mapping() is defined in include/linux/mm.h and returns true if the memory mapping has flags indicating that the memory is writable and not shared (that is, not used by multiple processes at the same time). Shared memory should not be COW because it is shared. Pardon the slightly obscure bitmasking:
// include/linux/mm.h
// https://github.com/torvalds/linux/blob/22b8cc3e78f5448b4c5df00303817a9137cd663f/include/linux/mm.h#L1541-L1544
static inline bool is_cow_mapping(vm_flags_t flags)
{
return (flags & (VM_SHARED | VM_MAYWRITE)) == VM_MAYWRITE;
}
Back in kernel/fork.c, doing a simple copy command to copy_page_range() results in a single call from dup_mmap()… which is in turn called by dum_mm()… which is called by copy_mm().. .which is finally called by the massive copy_process() function! copy_process() is the core of the clone function and, in a sense, the essence of how Unix systems run programs – copying and editing the template created for the first process at startup.
How are the programs executed?
At low level: CPUs are dumb. They keep a pointer as a reference and execute the instructions in sequence until they reach an instruction that tells them to go somewhere.
In addition to jump instructions, the sequence of instructions can be disrupted by hardware and software interrupts. CPU cores cannot run multiple programs at the same time, but multitasking can be simulated by using timers to trigger interrupts and have kernel code switch between different code pointers.
Programs appear to run as complete, isolated units. Direct access to system resources in user mode is closed, memory space is isolated by swapping, system calls are designed to provide generic I/O without knowledge of the actual execution context. System calls are instructions that ask the CPU to run specific kernel code, the location of which is set by the kernel at startup.
But… how do programs run?
After starting the computer, the kernel starts the initialization process. It’s the first program to run at the highest level of abstraction, where machine code doesn’t have to worry about many system-specific details. The initialization program starts the programs that render the computer’s graphical environment and are responsible for starting other software.
To run, the program is cloned using the fork system call. This cloning is efficient because all memory pages are COW and the memory is not copied to the physical OP. In Linux, the copy_process() function is responsible for this.
Both processes are checked for cloning. If they are cloned, they use the execve system call to contact the kernel to replace the current process with a new program.
Most likely, the new program is an ELF file that floats around the kernel to get information about how to load the program and where to put its code and data in the new virtual memory mapping. The kernel can also perform ELF interpreter preparation in case the program is dynamically linked.
The kernel then loads the program’s virtual memory mapping and returns to user space with the program running, which means setting the CPU instruction pointer to the start of the new program’s code in virtual memory.
Congratulations! Now you know better how the computer works. I hope you had fun.
Let me guide you by emphasizing that the knowledge you have gained is real and relevant. The next time you think about how a computer runs multiple applications, hopefully you’ll think of timer chips and hardware interrupts. When you’re writing a program in some fancy programming language and you get a linker error, hopefully you’ll remember what a linker is and what it’s responsible for.

