
15.02.2024
2 min
1915

AI crawlers are scraping the web to learn for generative models and RAG systems, increasing the burden on sites, hammering them with requests, and ultimately increasing costs for owners. In this article, we look into why AI bots can take down a server, how zip bombs work, and ultimately if they’re worth using on your site.

Some webmasters expressed worry about the increasing number of bots that are using so much server space, including those crawlers that many Large Language Models (AI) use. Crawlers, scrapers and Fetchers were found to make as many as 39,000 requests to a single site per minute according to an analysis report from Fastly.
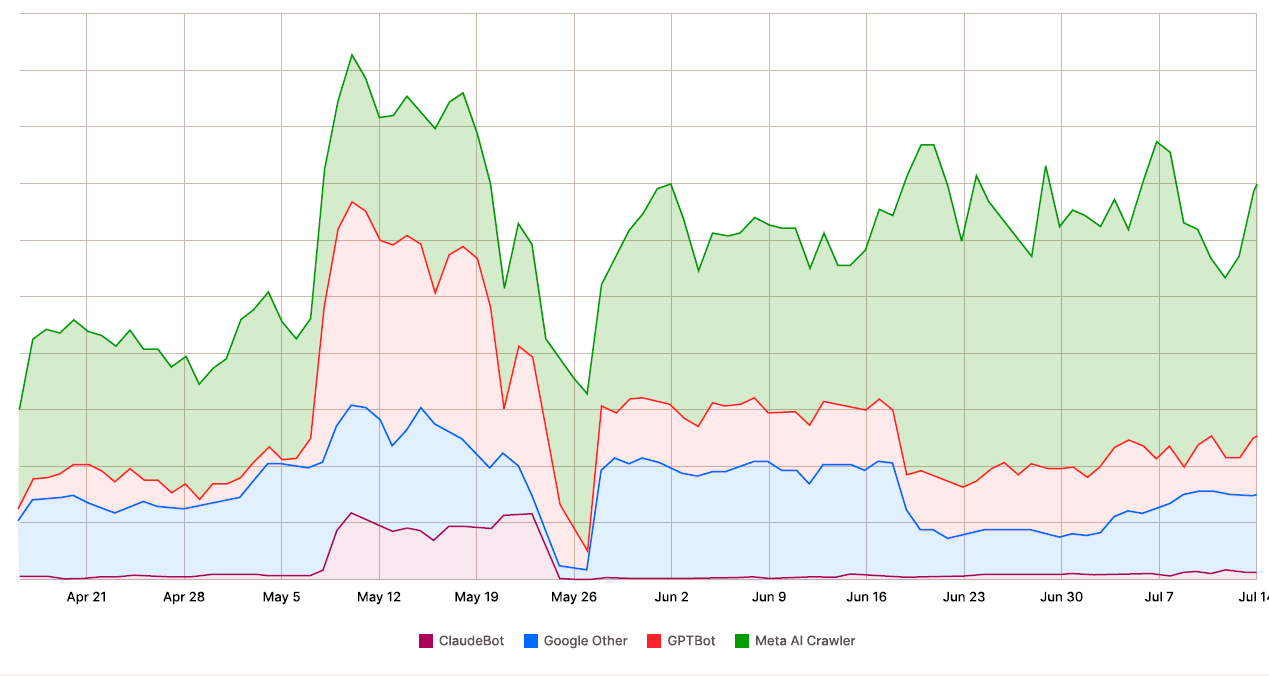
The amount of scraper-traffic to websites has been increasing by 87% in 2025 with almost all of this being caused by RAG scrapers versus bots that scrape information in order to train their first model.
Currently, Crawlers are making approximately 80% of the total AI-bot traffic across the entire Internet, while the remaining 20% is made by Fetchers, which, although less frequent, cause the most extreme traffic spikes. In addition, Anthropic’s ClaudeBot produced over one million requests to the tech document site iFixit.com in one day and generated over three and a half million requests in four hours to Freelancer.com.
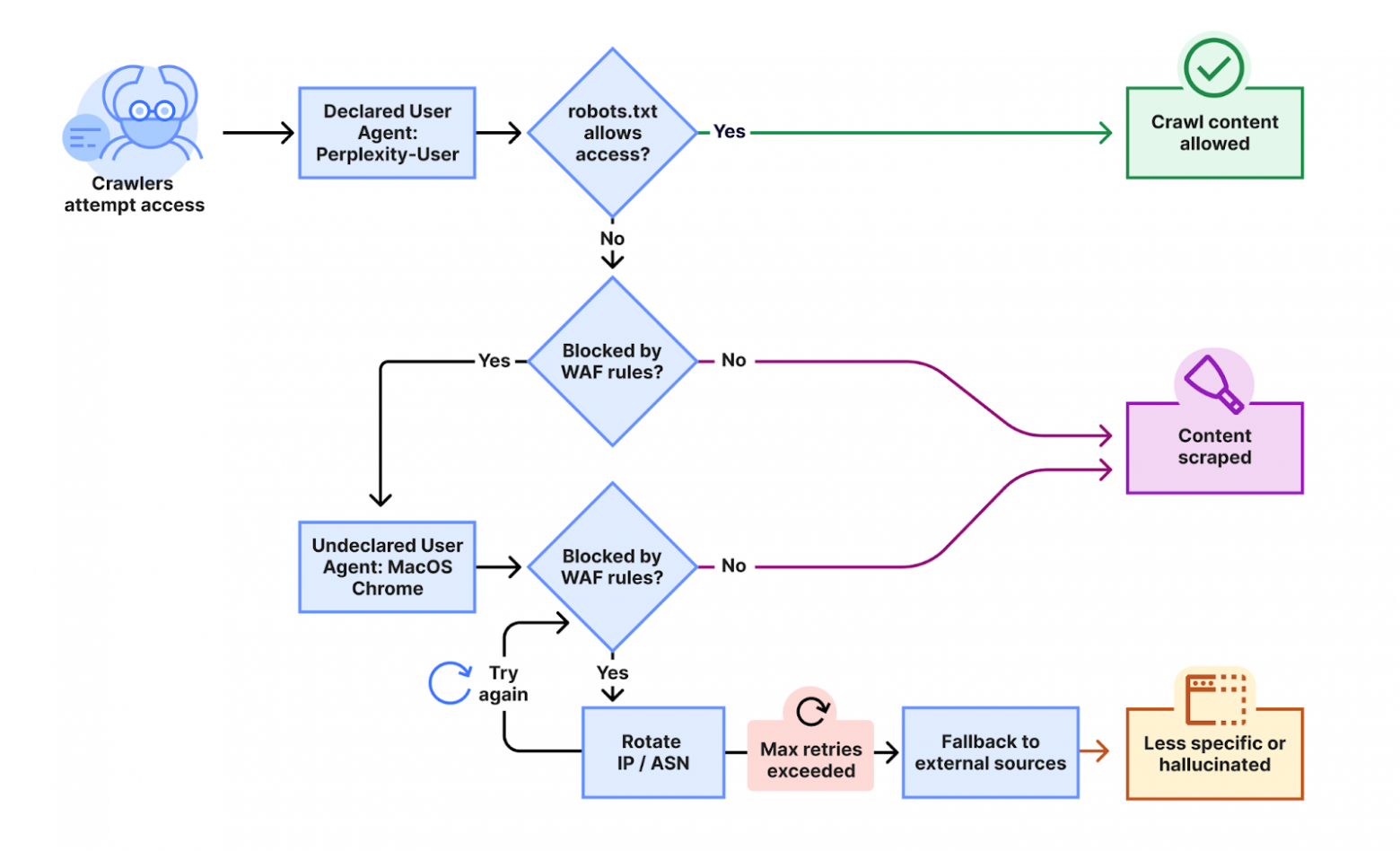
Among all bots, one of the most enduring is Facebook’s crawler. That crawler continually updates its User-Agent string when previous versions get blacklisted. Bots from Perplexity AI have been seen using non-listed IP addresses, and ignoring Robots.txt directives.
To defend against bots you typically use multiple forms of defense such as rate limits and CAPTCHA’s (tasks that are hard for machines to accomplish, however simple for humans) and filters based on user-agent strings and other parameters in the request.
However, there are more innovative solutions. The Anubis system looks at each and every incoming HTTP connection, and requests the client perform a specific SHA-256 computational test prior to allowing the connection to proceed.
calcString := fmt.Sprintf("%s%d", challenge, nonce)
calculated := internal.SHA256sum(calcString)
if subtle.ConstantTimeCompare([]byte(response), []byte(calculated)) != 1 {
// ...
}
// compare the leading zeroes
if !strings.HasPrefix(response, strings.Repeat("0", rule.Challenge.Difficulty)) {
// ...
}
This project was like those used for nefarious cryptocurrency mining. The developers were even inspired by Hashcash, a well known anti-spam program in the 90’s.
Anubis creates a substantial processing load for the AI crawlers to get through the data centers they come from; while Anubis may prevent them from accessing entirely, it certainly makes a cost (both time and money) for the operator to make it worth their while.
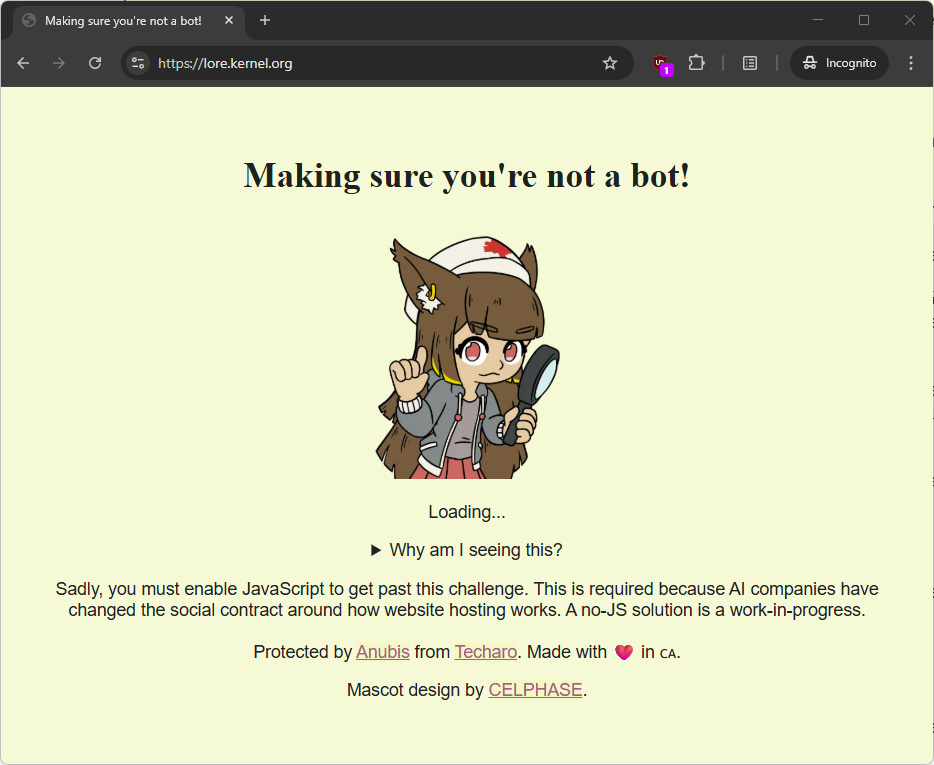
Critics say that it will be easy to get around the protection, and the extra computational effort involved in doing so will be small.
Some other ways to defend are based upon fingerprints made from differentiating characteristics of crawlers such as an old web browser’s User-Agent string (the part that identifies the browser) or refusing to download compressed files (to protect against Zip Bombs).
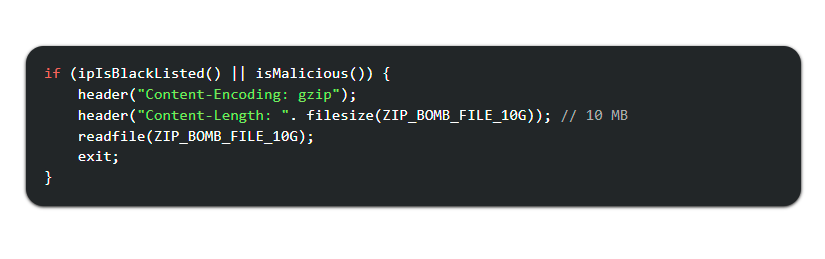
In addition, there has also been increasing use of “zip bombs” as a way to fight back against aggressive crawlers by making the crawler run out of memory at the data center. For example, the above described zip bomb which was only 10 megabytes in size would expand to approximately 10 gigabytes when unzipped.
$ dd if=/dev/zero bs=1M count=10240 | gzip -9 > 10G.gzip
Or even valid HTML:
#!/bin/fish # Base HTML echo -n '<!DOCTYPE html><html lang=en><head><meta charset=utf-8><title>Projet: Valid HTML bomb</title><meta name=fediverse:creator content=@[email protected]><link rel=canonical href=https://ache.one/bomb.html><!--' # Create a file filled with H echo -n (string repeat --count 258 'H') >/tmp/H_258 # Lots of H for i in (seq 507) # Concat H_258 with itself times cat (yes /tmp/H_258 | head --lines=81925) end cat (yes /tmp/H_258 | head --lines=81924) # End of HTML comment and body tag echo -n "--><body><p>This is a HTML valid bomb, cf. https://ache.one/articles/html_zip_bomb</p></body>"
…with a 1:1030 compression ratio:
$ fish zip_bomb.fish | gzip -9 > bomb.html.gz $ du -sb bomb.html.gz 10180 bomb.html.gz
Regular crawlers are protected from such attacks, since the page that contains the payload is blocked from being crawled using robots.txt.
Because other types of browser-based applications (Chrome, Firefox) may also crash while attempting to render this type of HTML, many site owners do not create links to this page on their public websites to prevent unintended access by real users.
Some activist groups believe that the success of zip bombs has caused crawler developers to try to protect themselves from these types of payloads by blocking crawlers from accessing the content within ZIP files. These directives can be used to identify malicious crawler activity and therefore could be used to fingerprint crawlers.
In addition to this method of increasing the amount of processing power required of the client to download the page, some webmasters have suggested the following approach:
(echo '<html><head></head><body>' && yes "<div>") | dd bs=1M count=10240 iflag=fullblock | gzip > bomb.html.gz
Some webmasters continue to use this form of defense even though it may be detrimental to the overall health of the web ecosystem; as many bots consume over 50 percent of the server load for these sites. In general, older search crawler bots will follow the directives for crawling websites on the Internet, but newer crawlers (such as AI-based) are beginning to crawl more aggressively and therefore may bypass such directives.
A good example is a webmaster who has posted an analysis of how much traffic the GPTBot from OpenAI used during a 30-day time frame which was 30 Terabytes. Therefore, since he had a total of 600 Megabyte website, his site was downloaded about 50,000 times in one month.
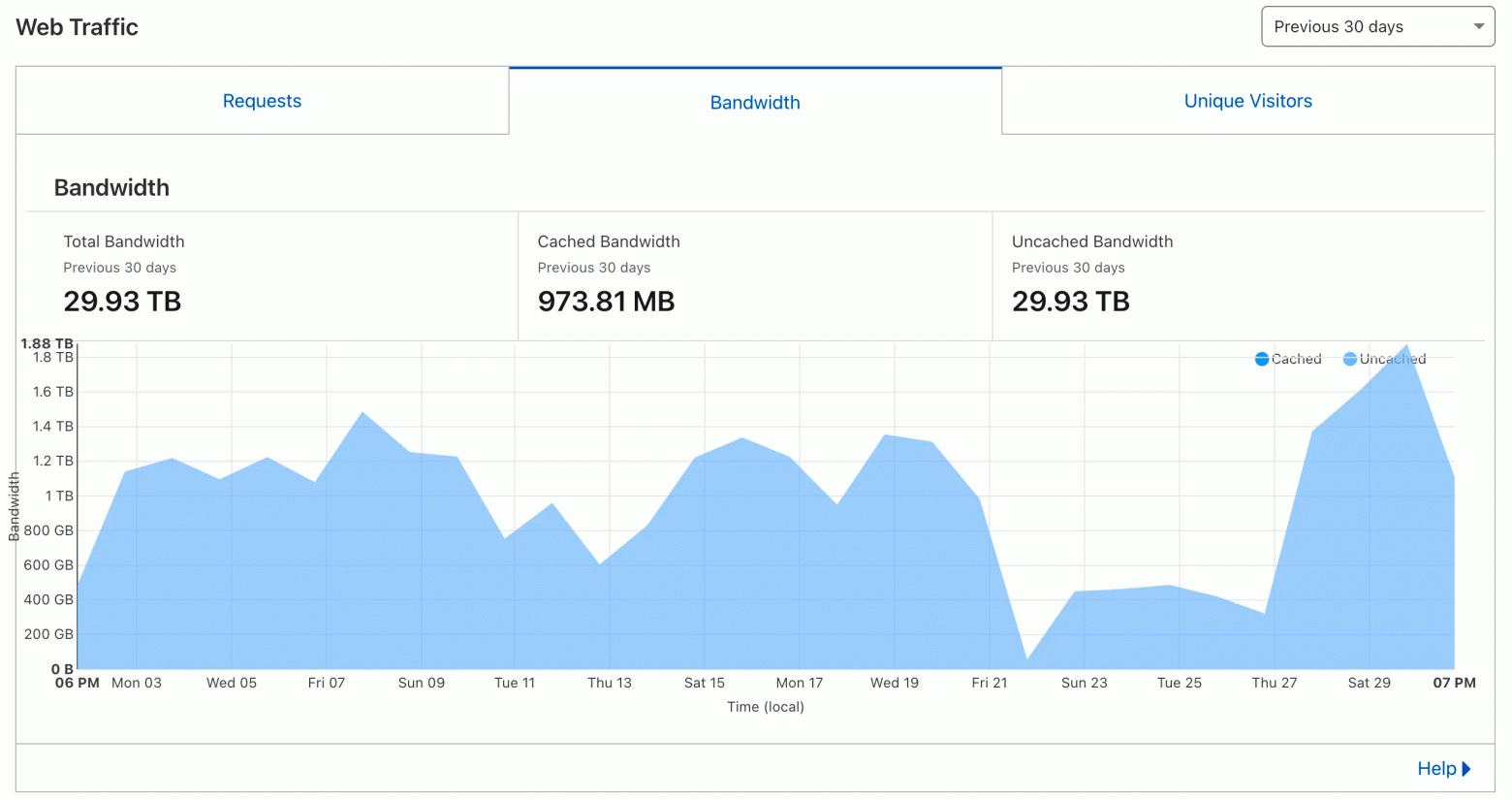
During crawler visits, server CPU load can spike several times over.
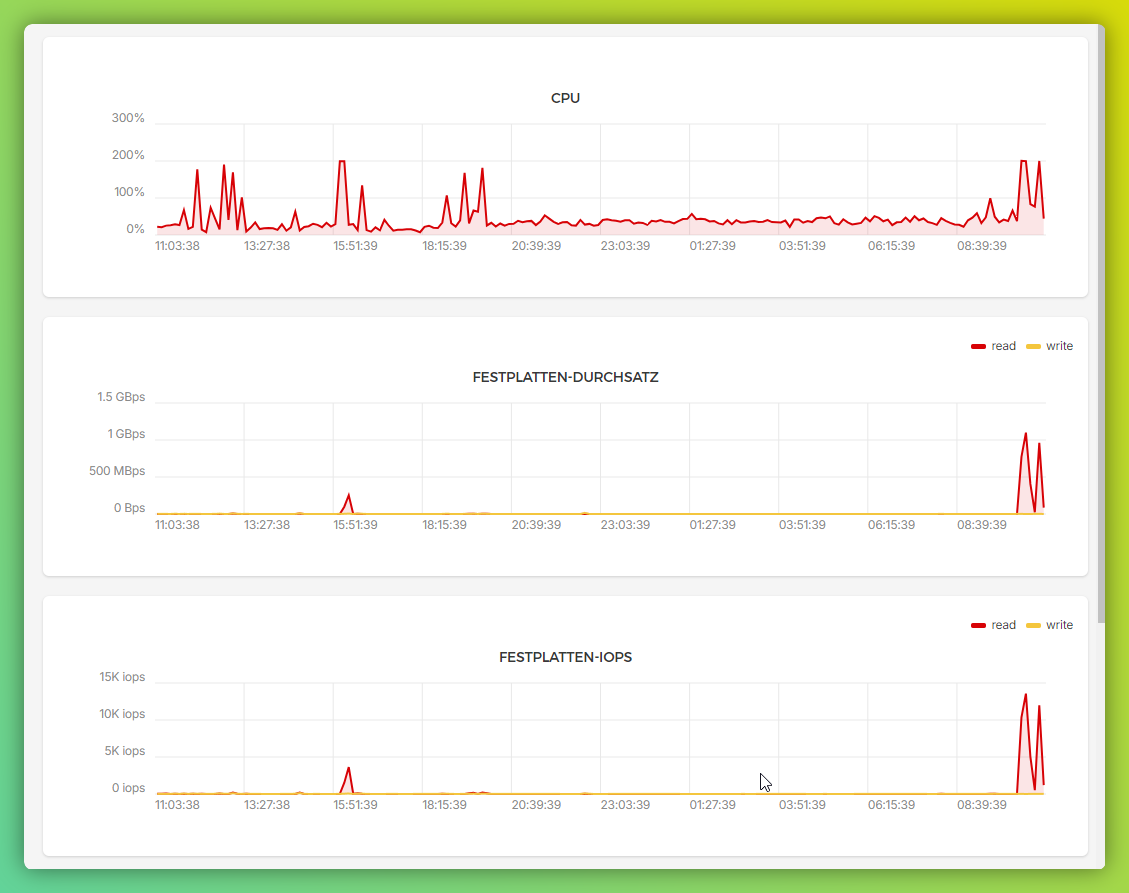
Because of this, many third-party website owners are left to pay for the operating cost of the AI model (as well as the training of that model) that was originally trained on their content.
For some webmasters, the unethical behavior of AI crawlers ignoring robots.txt has become an excuse to deploy additional defensive measures that are more extreme than simply blocking crawler traffic (i.e., “aggressive,” or even “destructive”).


Цікаво, треба якось глибше почитать