
04.09.2023
48 min
1977

Object-oriented design (OBD) is a methodology that is increasingly important in the fields of software development, engineering, and business design. The basic idea is to create high-level, abstract models that represent key aspects of some subject environment in order to optimize and improve development and management processes. Basic Concepts of POP: Object Representation: POP sets itself the task of creating abstract models that accurately reflect the subject area with which users or systems interact. Deep Analysis: The central idea is a deep analysis of the subject area, which allows the creation of detailed models for a better understanding of processes and requirements. Abstraction: POP applies abstraction to create models that focus on essential aspects of a domain while ignoring non-critical details.
Flexibility: POP models should be flexible, easily modified and extensible to adapt to changing requirements and conditions. Fostering Shared Understanding: A BOP helps create a common understanding of the subject area among all project participants, including developers, analysts, and customers. Productivity Improvement: The main objective of the POP is to improve the efficiency of project development and management by simplifying and optimizing processes. Constant Evolution: POP supports the idea of constant development and change, which allows adapting models to new requirements and circumstances. Subject-oriented design is an approach aimed at improving the development and management of projects by creating abstract models of subject areas. This helps increase productivity, product quality, and overall understanding among project participants. In this section. The most important aspects of object-oriented design from a security perspective. Models as a strict simplification of the subject area. Value objects, entities and aggregates. Domain models as a single language. Limited contexts and semantic boundaries.
Over the years we’ve been developing software, we’ve found many sources of inspiration, including ones we all share. One of the most important was DomainDriven Design (DDD).
DDD sets a slightly higher bar for most system development. We have encountered many projects where the main guiding principle was “just make it work”. When a programming error was found, the solution was to add an if statement. Despite the fact that errors were rarely generated exclusively by local code fragments, no one delved into the problem and the system was based on an incomplete and contradictory model.
Domain-Specific Design is an approach to software development in which we:
Focus on the main subject area;
Explore patterns of creative collaboration between those with expertise in the field and those who develop software;
We speak the same language in a clearly limited context.
DDD states that we should strive not just to create a working system, but to really understand what we are actually creating. Let’s underline the word “what”. DDD emphasizes a deep understanding of the domain, not just the solution itself. From our perspective, the beauty of DDD principles is that they force us to translate this understanding into code – resulting in the code using the same language as the problem you’re solving. We believe that the focus on deep understanding helps us improve as developers. And the fact that such an approach has a serious impact on security became obvious much later.
This chapter focuses on only some aspects of DDD. This is a huge and multifaceted topic, the coverage of which goes from coding to system integration, from requirements analysis to testing. It is closely related to other agile methodologies and processes. Many books and a huge number of articles have been written about DDD, so a comprehensive discussion of this approach in one chapter would be impossible. Instead, we will focus on those aspects of DDD that our experience shows can improve security.
If you are not familiar with DDD, you can understand the approach here, which will be useful to you in the following chapters. This section can also serve as a reference. Later we will use various aspects of DDD to improve security, so you can refer to this material if you need to update objects, values, aggregations, context maps, or any other DDD concept.
We encourage you to take a closer look at this topic, as it covers much more than just security. A good start would be the DomainDriven Design Fast mini book. For beginners, patterns, principles and practices of domain design by Scott Millett (Wrox, 2015) are also suitable. If you want to study this topic in depth, read the seminal book Domain-Driven Design (DDD) by Eric Evans – You will find comprehensive material in it.
If you are already somewhat familiar with DDD, use this chapter to refresh your knowledge. And even if you are an experienced domain-oriented designer, read it anyway, as it touches on aspects that I would like to emphasize – they will be used in the future to improve security. Also keep in mind that some ideas will be presented in a somewhat condensed form and may seem a little distorted. We do not claim to be complete, but only aim to provide you with enough material to discuss security.
We’ll look at the domain models that underlie DDD-style system development. Domain models provide an unambiguous, rigorous basis for describing system functions. This is of some interest from a security point of view. By describing the responsibilities of the system, you also get a great opportunity to define what it should not do.
When modeling and implementing models in code, it’s helpful to have some building blocks handy. Domain models are typically based on objects, values, and entities. Larger structures are usually presented as aggregates. Using these elements will make your code more rigorous and less prone to vulnerabilities.
If we move away from a separate system and consider the level of integration, then DDD provides such tools as bounded contexts and context maps. With their help, it will be easier for you to ensure security and tight integration between several systems. Domain-specific design is based on strict domain models, so first we’ll show you how to build them so you can use them to get a good understanding of the problem your software can solve.
First, let’s explain what the models behind DDD are. In systems engineering, the word “model” can mean many different things: flowcharts in UML, a way to store information in database tables, and so on. In DDD, a model describes the main business aspects you deal with as a set of concepts. Why are such models needed and how should they look?
We all know that there is no such thing as a panacea, and DDD is no exception. In order not to mislead anyone, it is always necessary to note those cases in which a technique or technique does not provide significant advantages, and the circumstances for which it is ideal should be indicated. If you are designing a network router or a baggage management system, the external circumstances can be very different. In the first case, DDD will not help much, and in the second case, it can bring considerable benefit.
In the example of a network router, the most important problem is a technical one – achieving sufficiently high I/O throughput and sufficiently low latency, which is not an easy task at all. If you do not manage it, then as a result you will get a product that no one will want to buy. Network performance is the most important feature of a router. DDD can help you with modeling packet queues and routing tables, but not throughput or latency.
For comparison, consider the example of the baggage management system at the airport. Its technical implementation will use the same databases, message queues, and GUI frameworks as most other systems. Of course, all this introduces considerable complications, but, most likely, the main problem will be elsewhere. Your system must be able to describe the passage of baggage from the check-in point to the aircraft along conveyor belts and loading machines. If this description turns out to be incorrect, the baggage may be late for the desired flight or go in the wrong direction. This can annoy passengers and cause reputational and financial damage to the company. To make matters worse, important aspects of security are at stake. For obvious reasons, luggage is allowed on the plane only if its owner is already there. If the baggage has already been registered, and the passenger has not appeared, the system must take care of the unloading of the corresponding suitcases. If it is designed flawlessly, there is a risk that it may be forced to load a suitcase on a particular flight or leave it on board even though it should be unloaded – sometimes with serious security implications.
If you fail to gain a deep and clear understanding of how baggage is handled, you will create a broken system. But the worst thing is that it can be harmful to the company and potentially dangerous to the customers. It may come to the point that the system will turn out to be completely useless and the airport will be closed sooner than it will be put into operation. This is not a hypothetical example: the opening of the Denver airport, which was supposed to take place in 1990, was delayed for a year and a half due to deficiencies in the baggage handling system, which led to large financial losses. In such situations, understanding and modeling the baggage handling area should be your primary concern. And it would be a mistake to spend time optimizing the pool of connections in the database. In this example, the subject area is the critical complexity of the task.
DDD works best when the system deals with a subject area that is difficult to understand. In such situations, the most urgent tasks are understanding the complexity of the subject area and its modeling. If you can’t get into the nitty-gritty of the various technical aspects, your system won’t be as useful as you’d like it to be. But if you can’t understand the complexities of the domain, then you end up with a system that doesn’t do what it needs to do. In this sense, the subject area has critical complexity.
In our experience, most business applications fall into this category. Understanding the subject area and creating an appropriate model is the basis for solving business logic problems.
You may think that the subject area is something non-technical. But it is not so. Sometimes the critical complexity is related to the subject area, and the area itself is technical. Imagine that you are writing an optimizing compiler. It transforms source code into well-optimized machine code that can be executed, while it uses local optimizations, eliminates “dead” code, expands subexpressions at compile time, etc. The difficulty here is not to improve file read/write performance, and in applying all these optimizations so that the resulting program does what the source code says. The main effort should be directed to the strict presentation of the source code and the implementation of transformations so that the optimized program does not change its essence. Here, the critical complexity is domain specific, but the domain itself is technical!
Now let’s try to figure out what this has to do with security. It won’t be easy for you to acquire all the knowledge you need to make your system behave properly in every possible situation. Given all the oddities that can arise, this task will be quite difficult even if working with normal, secure data. But things get even more complicated if you need to be resilient against malicious data. Someone might try to attack your system by sending it fancy data to trick it into doing something nasty. And even in this case, the system must react correctly and safely. We have already seen this with the example of an online bookstore in Chapter 2. No normal business procedure can lead to the addition of -1 anti-book to the cart. However, an unscrupulous customer can do this in order to manipulate the system (in this case, reduce the total cost of the order).
As our experience shows, to ensure security, the main attention should be paid to the construction of domain models. A side effect of this approach would be to avoid many security issues, especially those related to business integrity. In addition, domain models protect your code to some extent from some technical attacks.
You need domain models that promote stable and secure development.
An effective model should:
Keep it simple so you can focus on the key points;
Be rigorous to serve as a basis for writing code;
Provide deep understanding to make the system truly useful;
To be the best choice from a pragmatic point of view;
Provide language that can be used when discussing the system.
DDD is not a panacea: the usefulness of such an approach depends on the context. There are situations in which you should not focus on domain modeling. For example, if you are writing software for a network router, the most important aspect for you will be I/O bandwidth. In this case, the critical complexity lies in the technical plane. But even here it is necessary to think about whether the incomplete domain model does not create security risks.
ADVICE. Critical complexity always exists. It needs to be determined whether it is technical or domain related.
In our opinion, the main advantage of subject modeling is that it stimulates a deeper study of the subject, which is indispensable. It is not so difficult to learn the jargon of business professionals, and with the help of the same language, you can make a list of requirements that at first glance looks decent. But if there is no deep understanding of the area, misunderstandings, inconsistencies and logical loopholes can creep into it. These shortcomings will prevent you from creating a reliable system that will behave correctly in non-standard situations, and in the worst case will become the cause of security vulnerabilities. You can learn a lot by working on a domain model with experts.
A model is a simplified version of reality, from which everything you do not need is removed. For example, when you check in your luggage at the airport, the system does not need to know your shoe size. But the information about the weight of the suitcase can come in handy. To make it easier for you to understand and implement the system, the model should contain only the information you are interested in, for example, the weight of the luggage, but not the size of the passenger’s shoes.
It should be understood that the model is not a diagram. Although in many other contexts a model can mean a diagram of a certain type, as in the case of relational models in database design or class diagrams in UML. These diagrams are representations of models, but the models themselves describe a simplified understanding of reality at a conceptual level.
NOTE. A model is not a diagram, but a certain set of abstractions.
In DDD, the term “model” is used in almost the same sense as in rail transport simulation. When making train models, some aspects of reality are given great attention, while others are completely ignored (Fig. 3.1). Understanding which details should be realistic and which can be distorted is key to creating both toy trains and domain models.
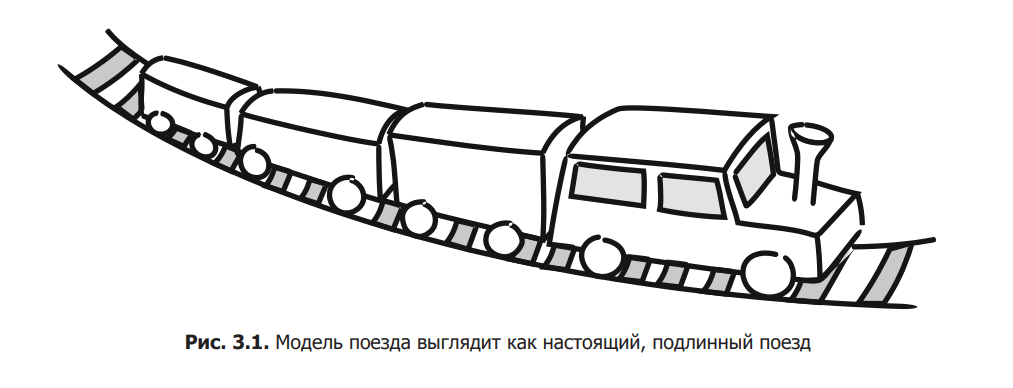
In fig. 3.1 The train model is shown. It looks like a train and moves on rails, but it cannot be called a real train. We consider it a model because it preserves some important attributes while ignoring others. Let’s list the parameters common to toy and real trains.
Color. We believe that the model of a certain train should have the same color as the original.
Relative dimensions. We expect that proportion will be respected. If in reality the height of the door is twice the width, the same ratio should be in the model.
Form. We expect the model train and its details to have the same shape as the real train.
Movement. We expect the model train to move along the rails just like a real train does.
We will also name some attributes of the model, the exact reproduction of which we consider optional.
Material. It’s okay if the model is made of plastic or tin, and the original is made of other materials.
Absolute size. If the real cars are 30 meters long, then in the model they can be much smaller, and this is normal.
Weight. The model is much lighter, which is quite expected.
Train mechanism. The model does not have a steam engine, it works on electricity.
Bending of rails. In the model, the rails can bend much more than in reality, and this is acceptable
Surprisingly, it is much easier to find the differences between a toy train and a real train than the similarities. However, we are convinced that this train model is correct. She clearly managed to absorb the main aspects of what we mean by a train.
Color, relative size and movement – this should be enough to understand that there is a train in front of us. These are the three necessary attributes: if they are not observed in the model, we will not pretend to call it a train. If the model does not meet some other requirements, we can ignore it.
NOTE. A model is a simplified version of reality that we can still perceive as a correct representation of the real thing.
This concludes our excursion into the world of toys. The main takeaway from this journey is that a model is a simplified representation of something real. This also applies to the models we use when developing systems. When simulating
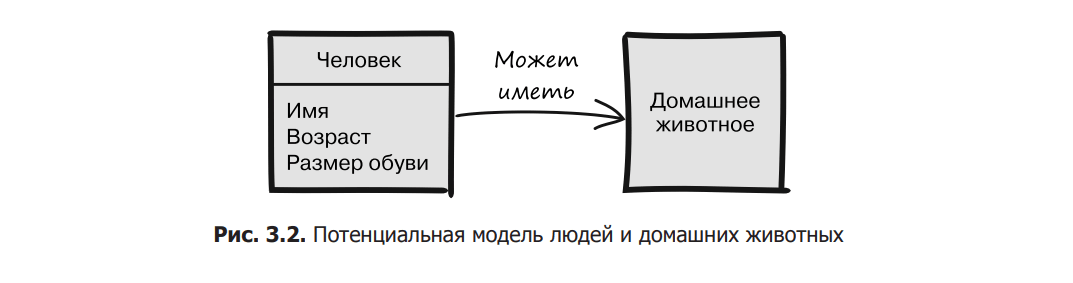
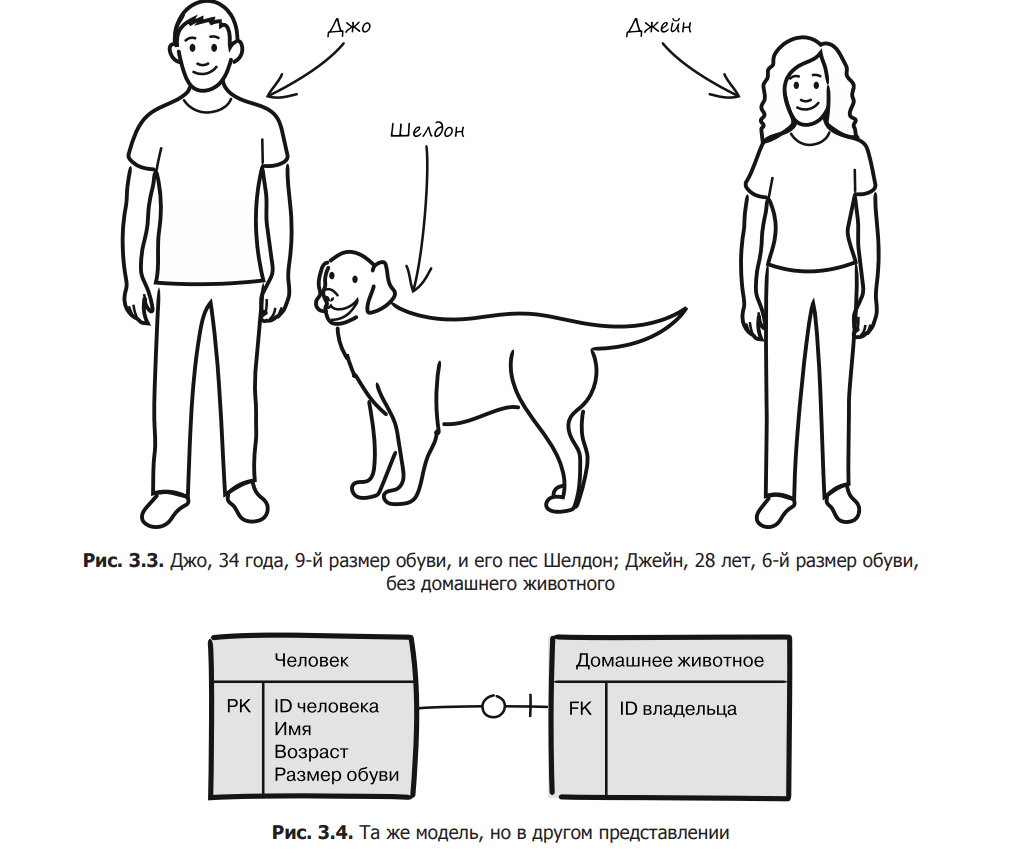
The model is a simplification, but it should still be general enough to cover the different variations you’re interested in. The example allows for different names, ages and shoe sizes, as well as the presence or absence of a pet. All this can appear in the model. We do not distinguish between people of different heights and do not pay attention to their hairstyle (Fig. 3.3).
This model can be presented in many different ways: using plain text or illustrating it with various types of diagrams (for example, compare Fig. 3.2 and 3.4). And also apply code (pseudocode or real programming language). Importantly, none of these views is a model. In particular, class diagrams are often mistaken for models, but models as such are not identical to their representations. A model is a conceptual understanding of what you think is important in the modeling process – in this case, name, age, shoe size, and pet.
The main advantage of using models as a very simplified version of reality is that simple models are easier to make rigorous. Later, when you build software from them, this will be important.
A domain model is not just a simplified version of reality: the lack of detail is compensated by additional rigor. The word “rigor” in this case is used in a mathematical sense and means “accuracy”: concepts, attributes, attitudes and behavior must be unambiguous.
Humans are very complex creatures with many attributes and relationships. By choosing to focus on name, age, shoe size, and pets, you’ve lost a lot of detail. But instead, you have a precise definition of what you mean by a person, and with that precision you can represent that entity in program code. It takes a lot of effort to determine what details can be sacrificed for accuracy. And if you want to do it right, you’ll have to reach out to people with a deep understanding of the subject area.
Writing software involves collaboration between professionals of two different profiles who must interact productively. We are talking about business professionals and developers. Each batch has special needs, the satisfaction of which is the key to creating a great product. Business professionals need to deal with terminology they are used to, not some technical abracadabra. If they don’t recognize their own subject area, you’ve failed them.
A few terms:
subject area (domain) – that part of the real world in which something happens (for example, the baggage management area);
A domain model is a filtered version of a domain in which each concept has a specific meaning.
Code is a coded version of a domain model written in a programming language.
Simply having familiar words in the user interface or in the titles of printed reports is not enough. The system should behave in such a way that business professionals consider it logical, consistent and understandable. For this, the domain model must be strict. If the model is weak and contains ambiguities, different parts of the system may behave differently.
For example, “number of suitcases” may appear on the screen at the check-in point, “number of baggage” at the boarding gate, and “baggage” on the loader’s tablets. The situation can get complicated if some of these concepts include carry-on baggage and others do not. When airport employees communicate with each other, each of them must remember which screen the interlocutor is looking at and whether to add/remove hand luggage. Sometimes there are misunderstandings and luggage gets lost. The system fails the company and looks illogical even for specialists in the subject area.
Confusion can also arise when a model is consistent in terms of terminology but has too loose constraints and relationships. In many cases, this is the result of using a standard system adapted to the subject area; So, for example, ERP (enterprise resource planning) products are usually used.
In the 1940s and 1950s, computers were used for commercial purposes for the first time: they were used to plan the use of devices and raw materials in production, which was a big step forward compared to paper and manual procedures. In the 1980s, material requirements planning (MRP) evolved into resource planning (manufacturing resource planning, sometimes abbreviated to MRP II) and began to include finance, personnel, marketing, and other so-called resources. However, in the original subject area, resources from the material invoice were still used to produce products. And because there are different businesses, these MRPs had a very flexible configuration.
In the 1990s, these processes evolved into ERP systems and began to be used to plan the work of entire enterprises, and so that they could work in any enterprise in any industry, their configuration was made even more flexible. They were often described and marketed as off-the-shelf systems that could be configured to work in any subject area. However, these were the same material management systems. This line of business has successfully sold such systems for handling customer complaints, police investigations and other completely different areas of activity. Unfortunately, the successful sale of the system did not mean that it brought any benefit. If you want to set up a material management system for police investigations, you need very non-obvious abstractions: a police officer can be represented as a device, and a robbery report as a pile of raw material that is processed by the device (the police) during the investigation.
To squeeze one subject area into another requires being less specific and precise. The result is often a generic object management system in which any entity is an object. The user interface allows you to update the attributes of objects, but such a generalized model does not carry much information about what these objects actually represent. Often any combination of attributes and relationships can be specified.
Such a weak system is naturally error-prone, and as you saw in the example of an online bookstore, a lack of rigor can lead to security holes.
NOTE. A good system takes care of the needs of both business professionals and developers. It should meet the professional needs of both of these groups.
It is obvious that it is worth paying attention to professionals in their field. They need to work in a familiar subject area, so it is necessary to select terminology that is familiar to them. Failure to achieve this will be a big mistake. As great as the inability to meet the needs of other development professionals.
Ultimately, our responsibilities as developers come down to writing code. And it’s mathematically rigorous code—it tells the computer what to do based on the data we have, according to the rules we’ve written. That is why rigor is needed. And you can get it either from conversations with specialized experts, or by filling in the gaps with educated guesses.
If we say that most people do not have more than one pet, it is not enough. Developers need to know if the number of pets is limited to just one. This is an aspect of our profession that requires a certain amount of courage. It is necessary to ask questions so that the model turns out to be strict and unambiguous. If you ask if there can be more than one pet, the answer might be, “Oh, well, that’s very rare.” As a result, you can either allow specifying a list of animals, or be content with the fact that there can be only one animal. In the first case, the system may become complicated and sooner or later will encounter some unusual combination of attributes. In the second case, you will not be allowed to list more than one pet, and after a few months you will feel the indignation of buyers (who may have gotten you when buying another company) who have two or more of them. Worse, business professionals can make you a scapegoat by slyly saying, “We told you it could happen,” even though you’ve made a reasonable guess so as not to overcomplicate the system. You need to be able to make decisions to move development forward.
In order not to fall into this trap, you should be actively interested in what the model should be: “Should we allow the addition of several pets or is it better to limit ourselves to one?” If your system does not support multiple pets, they will need to be handled using a separate manual procedure. But maintaining great diversity also comes at a price. It’s tempting to be able to work with more and more general models, but sooner or later all your entities will be related to each other in many-to-many relationships. In the long run, this will not lead to anything good. The consequences of using a general model are difficult to predict and understand.
Imagine you have a feature that allows customers to trade pets. If one person can have several quadrupeds at the same time, this possibility will have to be reconsidered. Does this mean that client A gets all of client B’s animals and vice versa? Or do the animals exchange one at a time? If you don’t represent the business domain in the model, you can let the business professionals down. If you don’t create a strict enough model, you can let the developers down.
NOTE. A good model should reflect the scope of the business and at the same time be rigorous. Having a strict model means that it can ultimately be used as a basis for writing code.
When you develop software, you make similar decisions – you create a simple representation of a complex phenomenon. Consider an example of object-oriented code, which is usually used in school textbooks.
This is a very superficial characterization of a person that ignores many attributes and relationships:

There are not a huge number of properties and operations characteristic of a person. The model boils down to four attributes that are important in a specific context. It has a purpose – the area of behavior you want to describe. At first glance, the rejection of details makes the system poorer, but in return we get something very important – the ability to be precise.
A person is a complex creature with complex relationships. But in our model, the Person class is something with a name, age, shoe size, pet, and the ability to age. And that’s all. This is what we mean by the term “human”. By losing detail, we gain precision.
Of course, the previous example of modeling a person turned out to be ridiculously simple. The real problems are much more complex, as in the case of baggage handling at the airport. A clear understanding of exactly what the domain model covers is not as easy as many might think. In fact, the knowledge you need to cover is even deeper than what experts use in their day-to-day work to solve individual problems. The reason for this is that the understanding should be enough for you not just to work in a specific subject area, but to create a computer system.
Let’s compare it to riding a bicycle.
Most of us are professional cyclists in the sense that we don’t think about every step we take. This is easy to see if you ride a bike in difficult conditions: on rough roads, in windy weather, and maybe even with a large package in one hand. Skill is required. Contrast this with the difficulties faced by a child who is just learning to skate on a smooth surface on a sunny summer day. The knowledge of specialists in the subject area can be compared with this skill – they understand their field of activity. For example, a shipping specialist knows how to build routes for cargo containers even in difficult conditions, for example, when a container has been mistakenly unloaded from a ship and no sea voyages in the same direction are expected in the near future. A specialist in the subject area is able to resolve even complex situations by considering them one by one.
Unfortunately, writing a software system requires an even deeper understanding. You cannot be “on the spot”, assessing emerging problems and improvising to solve them – all this is a luxury that is not available to you. You write a program that should do all this without your presence. A more apt analogy here is not teaching a child to ride a bicycle, but creating a robot cyclist.
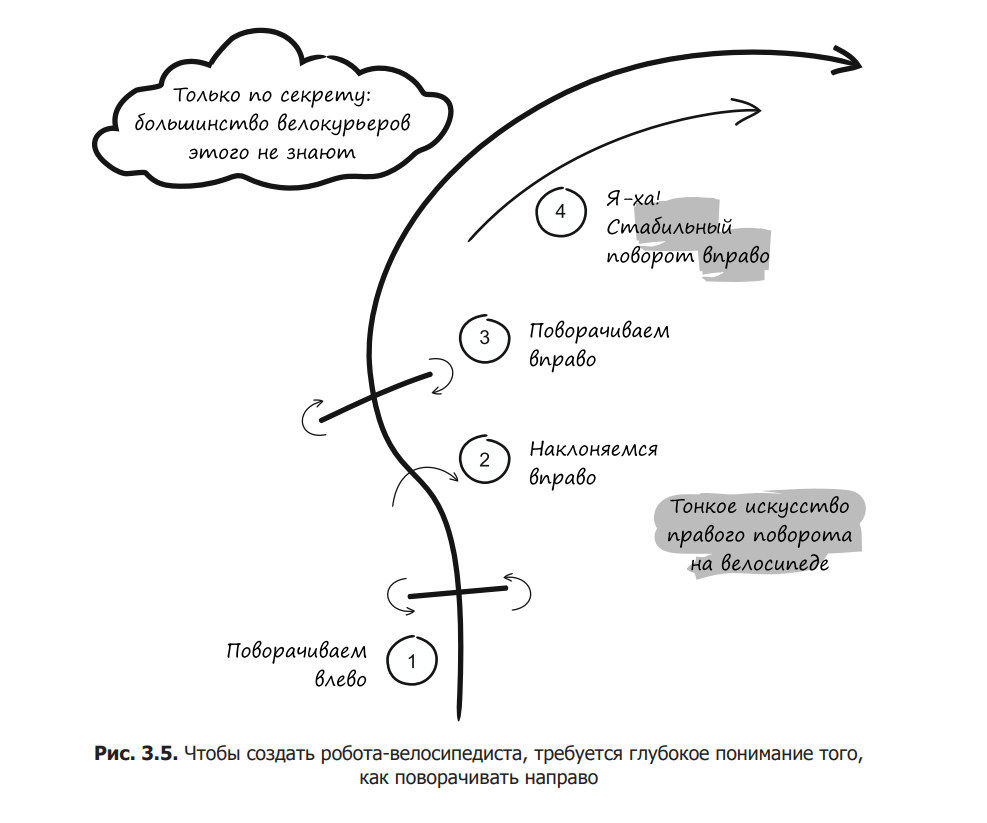
When developing such a robot, the understanding of cycling must be much deeper than that of most professionals, including professional bike couriers or those involved in cyclocross. For example, how do you turn right when you are riding a bicycle? Think about it for a few seconds – you’ve probably done it a thousand times. Most people will answer without hesitation: “I will pull the right wheel.” Unfortunately, due to centrifugal force, you will lean to the left and fall on the asphalt.
In fact, you subconsciously turn the steering wheel to the left, which causes you to veer to the right momentarily. After a few milliseconds, the slope will reach the appropriate angle, after which you will turn the steering wheel to the right and make the maneuver. The inclination to the right should be exactly such as to compensate for the centrifugal force, this will allow you to make a safe and stable turn (Fig. 3.5). You do it without thinking and without understanding all the intricacies of kinematics. If you want to build a bike robot, this is the level at which you should master this topic.
Robot history brings both bad and good news. The bad news is that there is no ready-made, real model in the head of a subject matter expert. You won’t be able to get answers to all your questions from him.
But the good news is that collaborating on a model with subject matter experts can be fun and rewarding. This is a process of gradually researching different models with the selection of the one that is suitable for solving existing problems.
One of the common myths about modeling, held by many, is that there is an ideal model in the mind of a subject matter expert. That’s not the point. Creating a model involves a conscious choice from many options: the model must meet your needs, which determine its purpose.
NOTE. There is no one real model, only options. Choose the one that suits your goals.
DDD practitioners sometimes use the term “distillation model”. Let’s compare ourselves to whiskey producers for a moment. To oversimplify a bit, whiskey production starts with a large amount of wort that is not suitable for drinking. The wort is heated and steam is collected. The starting product containing acetone is poured out. The middle part mainly contains alcohol and some water with natural flavoring. She is abandoned. In the last part, there is a little alcohol and a lot of water, its taste is not the most pleasant. He is also thrown away. All that remains is what we call whiskey. Your attitude to this drink and preferences may differ, but the main idea should be clear. In the process of distillation, we consciously keep some parts and discard those that we do not need. In the same way, by distilling a model, you get rid of some aspects of reality and leave others.
The important thing here is that distillation can be done in different ways. We have a choice. We deliberately leave the middle part, as our task is to get a strong drink with a specific taste. We try to surpass what is pleasant to consume. The purpose determines the method of distillation.
However, the manufacturer could make different decisions if he had a different task. If he wanted to get acetone, the process would look different. The first part would be kept and all the rest would be discarded. Likewise, you can distill different models from the same reality depending on what you intend to use them for.
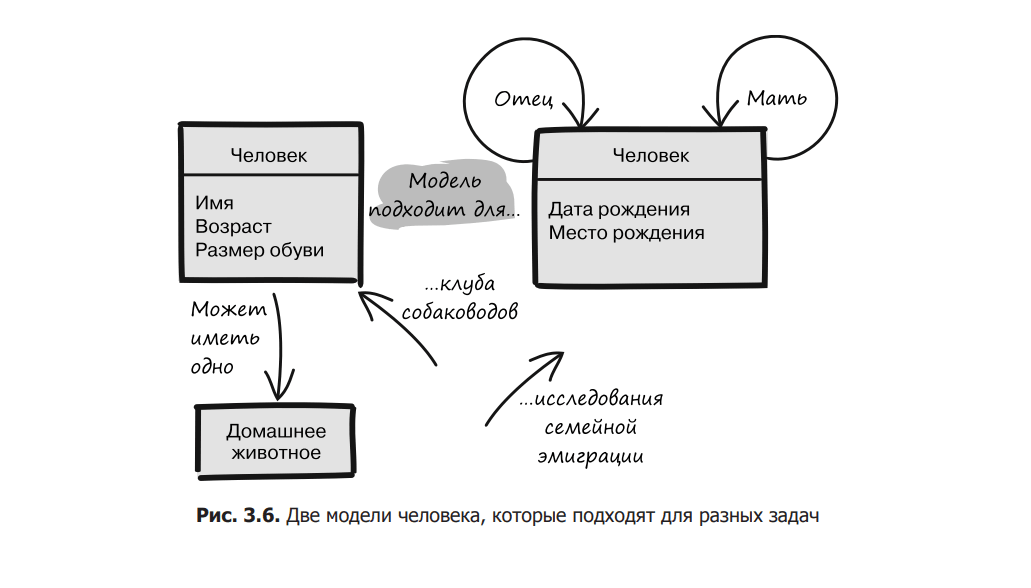
Our model, which describes a person with a name, age, shoe size and pet, is just one option. Another model can describe a person by his date and place of birth, the names of his mother and father. It cannot be said that one of these approaches is more correct than the other (Fig. 3.6). They are different and suitable for different purposes. If you keep a register of members of the kennel club, the first model will be clearly better. But if you are researching where different family members emigrated, the second option will work perfectly, and the first will turn out to be useless.
In the modeling process, try to choose different models that express your subject area. Try to find three models and compare how well they fit your tasks. Finding the best option is important, as it allows you to effectively and unambiguously think about the subject area. A good model makes a speech.
An interesting aspect of modeling is that it forms the language in which we reason about the system. To begin with, it should be noted that when domain experts communicate with each other, they speak their own language. It is a domain language (or domain language). In an English-speaking country, it may sound like English. But it has barely noticeable features. There are quite a few words that will never be used in it (for example, you are unlikely to hear the word “chervil” when discussing accounting). Conversely, experts use specific terms and idioms that do not exist in spoken language (for example, “sights”). Specialists communicate in a language that allows effective interaction.
Think for a moment about what language language system developers speak. When communicating with each other, we can easily throw around terms that sound logical to us, but will be completely incomprehensible to people working in other fields: for example, we can create a “pool of connections” or make something a “strategy”. Specialists in finance, logistics or healthcare also have their own jargon.
If you are developing a logistics system, it seems logical to take terminology from logistics and codify it into a software system. It’s a great idea, but unfortunately a bad idea. The language used by experts in this field is not logically consistent. And not at all because they are deliberately careless with their terminology. We, developers, also often sin with this. Listen to a conversation between any two experienced programmers, and you’ll notice that they use the words “object,” “instance,” and “class” interchangeably, even though they’re not. You know this because when you learn object-oriented programming, there is always a clear separation between objects and classes. But experts talking to each other can be careless, because they understand each other and the discussion is actually on a higher level.
It would be great if, during the development of the logistics system, you could create a language in which you could discuss your work with complete mutual understanding. That’s what a model is for. If you and the logistics experts decide that “shoulder” means transportation from one place to another using the same vehicle, and “pack shoulder” means unloading cargo at the destination, then you can explain yourself using these terms . The phrase “If two transports complete a leg in one dock, they can perform joint transport on the next leg” will be understood unambiguously so that the corresponding functionality can be implemented (Fig. 3.7).
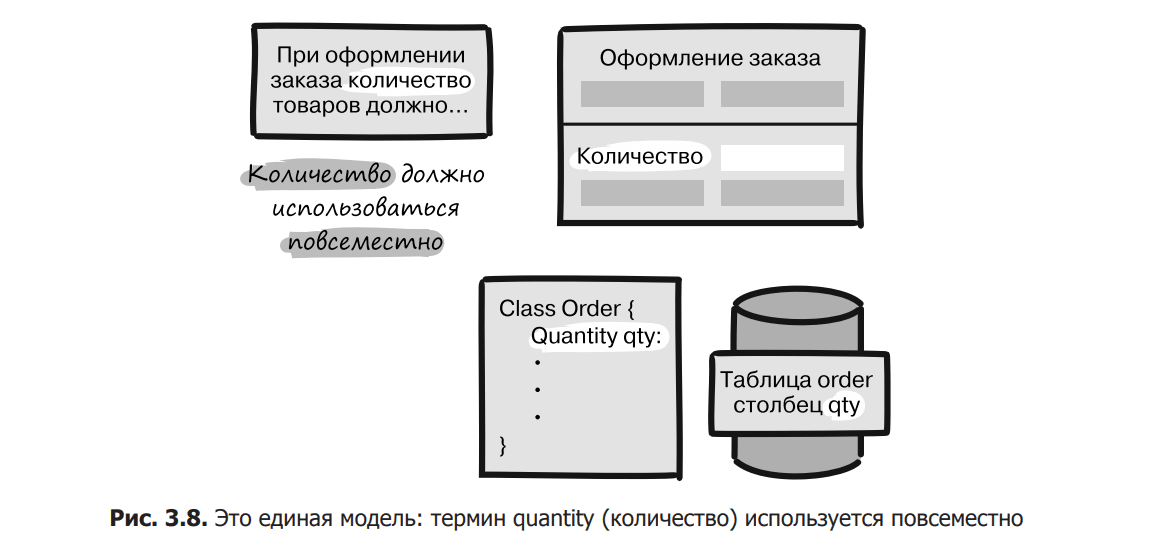
To use DDD terminology, when discussing a system, we want to translate the model into a single language. “Unique” in this case means that this terminology should be used wherever there is a conversation about the system (Fig. 3.8). The same terms should be used in user interface, instruction manuals, requirements (or user stories), code, and database tables
Let’s imagine that the same value is called quantity in the user interface, amount is called in the manual, and the database column is called Volume, which is simply illogical. The purposeful use of a common language in different areas helps to find ambiguities that may later manifest as software defects or security holes.
Of course, it should be noted that the model intended for permanent storage may differ slightly from the conceptual model. For example, it may be necessary to separate concepts into different tables, or to combine tables or synthetic keys that are not part of the conceptual model. Similarly, at the implementation stage, the classes in the code may differ slightly from the terms used in the conceptual model. However, you are describing the same information, so you should use the same language as much as possible when naming your constructs (database classes or tables).
This does not mean that now it is necessary to zealously monitor the purity of the language. The domain model is the only language for discussing the system. Domain scientists can still use ambiguous concepts when communicating with each other, just as developers can be careless when it comes to objects and classes.
The accuracy of one language is important when you are talking about a system. This is especially important when communicating between business professionals and developers, when the risk of misunderstanding is as high as possible. In such situations, the use of a single language should be insisted upon.
The context of language has certain limits. In DDD, this is called bounded model context. Within it, each term used in the model has a clearly defined meaning, but outside it, these meanings can be completely different. We will discuss bounded contexts in detail later in this section. With a deep understanding of the model and its purpose, you can take on the more down-to-earth aspects. The model needs to be implemented somehow, and standard components will help us with this.
To represent a model in code, you need a set of standard blocks. They must be clearly defined, as they are needed for the organization and structuring of complex models. This is a framework that allows you to clearly separate the domain logic from the rest of the code and helps to understand the technical aspects of the process.
In DDD, the building blocks of particular interest to us are entities, objects of value, and aggregates (Figure 3.9). We are interested in them because, using them in a certain way, you can lay the foundation for software security.
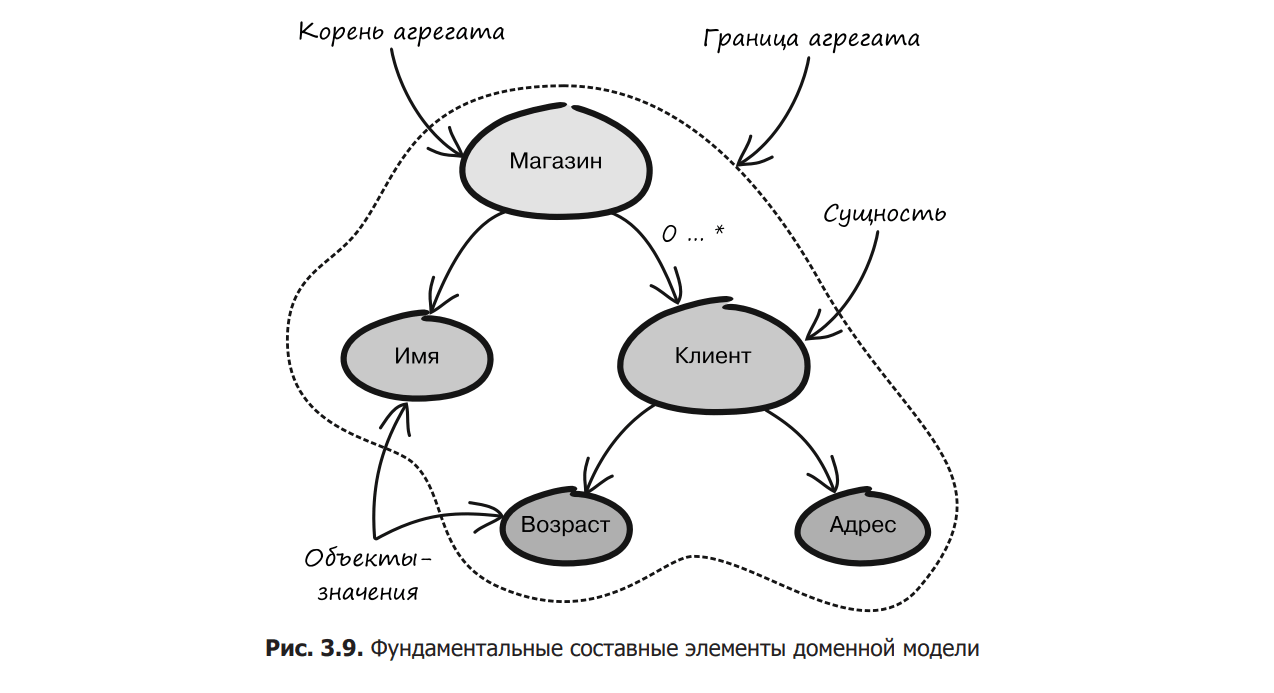
Once you understand these building blocks, you will have an easier time understanding the concepts discussed later in the book. In this section, you will learn the meaning of each of these terms, their characteristics, and how to use them.
Each part of the domain model has certain characteristics and values. Entities are model elements that have different properties. This is what makes them special.
In essence, there is an identifier that defines and distinguishes it from other entities.
This identifier does not change throughout the entity’s lifecycle.
An entity contains other objects, including other entities or value objects.
An entity is responsible for coordinating operations with objects belonging to it.
This means that in order to find out whether two entities are the same, you need to check their identifiers, not their attributes. This is an identifier that identifies an entity, regardless of its attributes. The ID never changes. Throughout its life cycle, an entity can change and take on many different attributes and behaviors, but its identifier always remains the same.
Take, for example, a car. During operation, many of its attributes can change. It can have a new owner, it can be repainted, new parts can be installed. But it’s still the same car. In this case, the vehicle identifier can be a unique vehicle identification number (VIN), which consists of 17 characters and is assigned to it during manufacture.
Sometimes the entity identifier is unique within the system, and sometimes its uniqueness is limited to a specific domain. In some cases, an entity identifier may be unique and relevant even outside the current system. It is also used to refer to entities from other parts of the model.
Another important feature of an entity is that it is responsible for coordinating the objects that belong to it, not only for ensuring consistency, but also for maintaining its internal invariants. The ability to accurately identify information and coordinate / control behavior is critical if you don’t want security flaws to creep into your code. In the following sections, you’ll see how this feature makes entities an important tool for writing secure code.
Sometimes a domain object is defined by its attributes, but sometimes they change over time without affecting the object’s identifier. For example, you can identify a customer’s perspective using the name, age, and address attributes. Most of them can change during the life of the client in the system, but it is still the same client with the same order history, so its identifier should remain unchanged (Fig. 3.10). If the system created a new customer every time the home address changed, it would quickly become confusing.
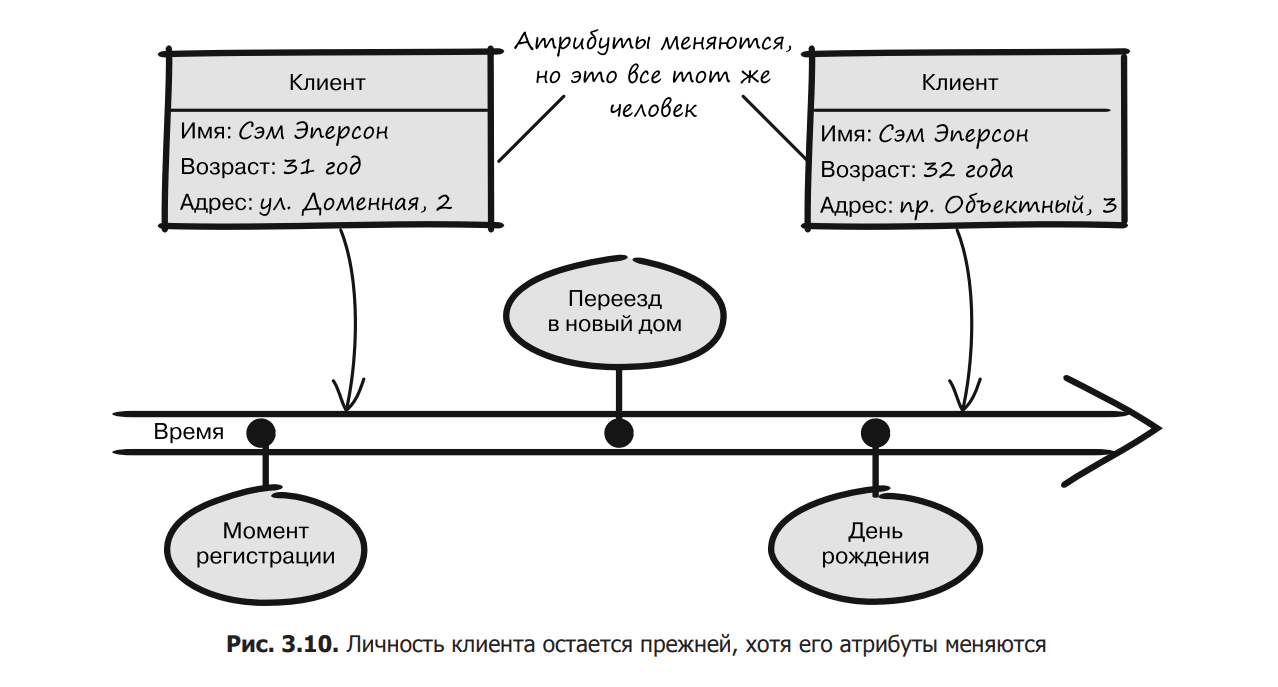
A client is not defined by its attributes, but rather by its identity (identifier), so it should be modeled as an entity. Thus, as long as the customer exists in the system, his identity remains consistent regardless of how many times his state has changed during that time.
Choosing the right approach to defining an entity identifier is very important and should be done carefully. The result is usually an ID. This means that the identifier identifies the identity and uniqueness of the entity. Sometimes a unique identifier can be generated, and sometimes it is obtained by applying a function to a specific set of entity attributes. In the second case, it is necessary to make sure that none of the specified attributes will change over time. This may prove to be a difficult task, as it is difficult to predict which attributes are likely to change in the future, even if they appear to be fixed at the moment. Therefore, in general, it is better to use generated unique identifiers as an identifier.
It should also be said that the concept of identifier in DDD is not the same as identity or equality, which is used in many programming languages. In Java, for example, standard object equality is no different from instance equality. Unless you explicitly define your own equals() method, two instances of an object representing the same client will not be equal. Furthermore, the identifier is independent of the specific representation of the entity. The same entity can be represented by an object instance, a JSON document, or binary data.
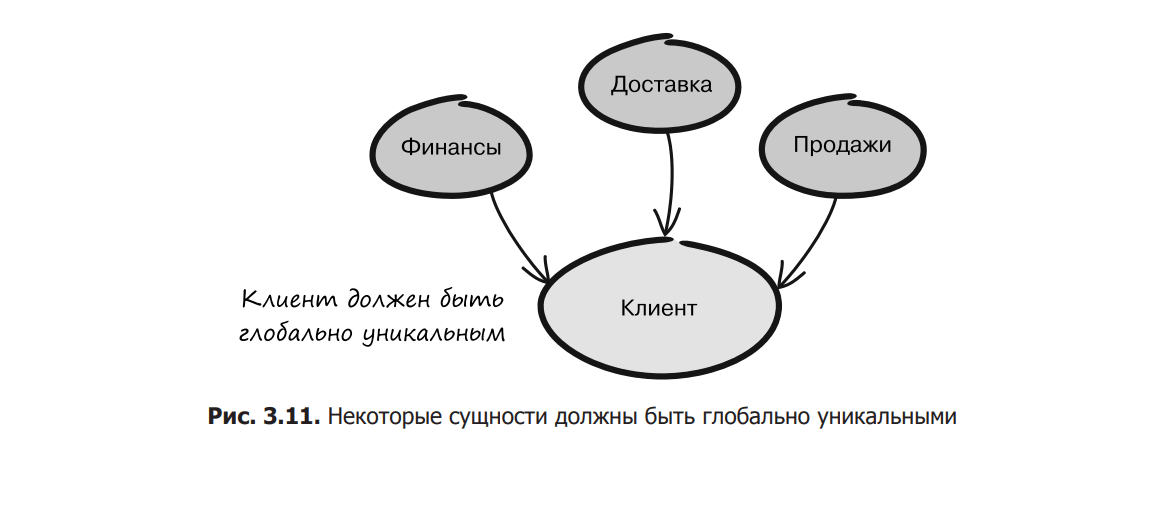
The object identifier is important, but it can be unique at different levels. Take, for example, the “client” entity. The system could use a unique identifier not only internally, but also externally. Such an identifier is called externally unique. Examples include ID cards or numbers used in many countries to identify citizens. In the United States, this is a social security number. However, using an identifier defined outside the system can have certain disadvantages, which, as you will see in the following sections, can pose a security risk.
Perhaps more common are identifiers whose uniqueness is limited by the framework of the system or the current model. They can be called globally unique. As an example, we can cite a unique ID that is generated by the system when creating a new client (Fig. 3.11). Interesting technical nuances may arise here, which are worth paying special attention to. If you are dealing with a distributed system and your identifiers need to be not only unique, but also consistent, from a technical point of view, their generation may require considerable effort.
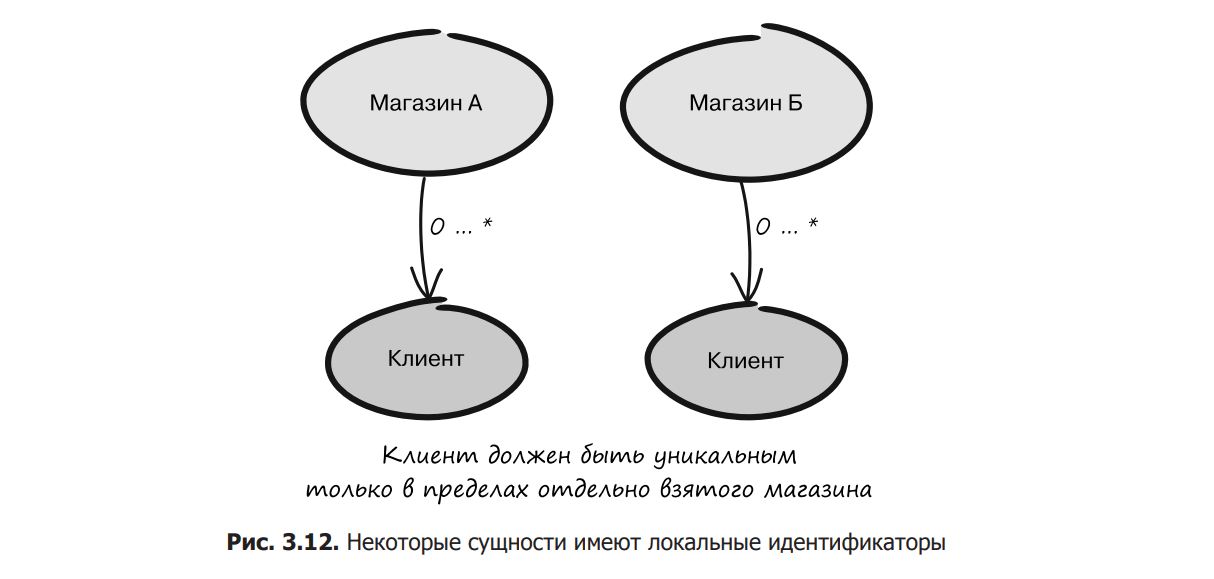
Sometimes some entities are inside others. Since such encapsulated entities are managed by their owner, their identifiers can only be unique within that entity, which is usually sufficient. Such identifiers are called local identifiers at the level of the business entity (Fig. 3.12). Let’s return to our example and imagine that the system manages customers in retail stores and each customer belongs to only one store. In this case, it is enough to make the identifier unique at the level of the store to which the customer belongs. Modeling local uniqueness can simplify the function of generating identifiers, and also allows you to explicitly transfer all responsibility for managing client data to the entity in which it is encapsulated.
When modeling an entity, try to add only those attributes and behaviors that are important to define it or help identify it. Everything else must be moved from the entity to other objects of the model, which can then be made part of it. These can be both other entities and objects, which we will talk about in the next section.
Business entities coordinate operations that may concern not only themselves, but also their objects (Fig. 3.13). This is important because we can have invariants associated with a particular operation. At the same time, an entity is responsible for managing its internal state and encapsulating its behavior, so it must also own operations to work with its content. Moving operations outside the entity would make it weak (anemic).
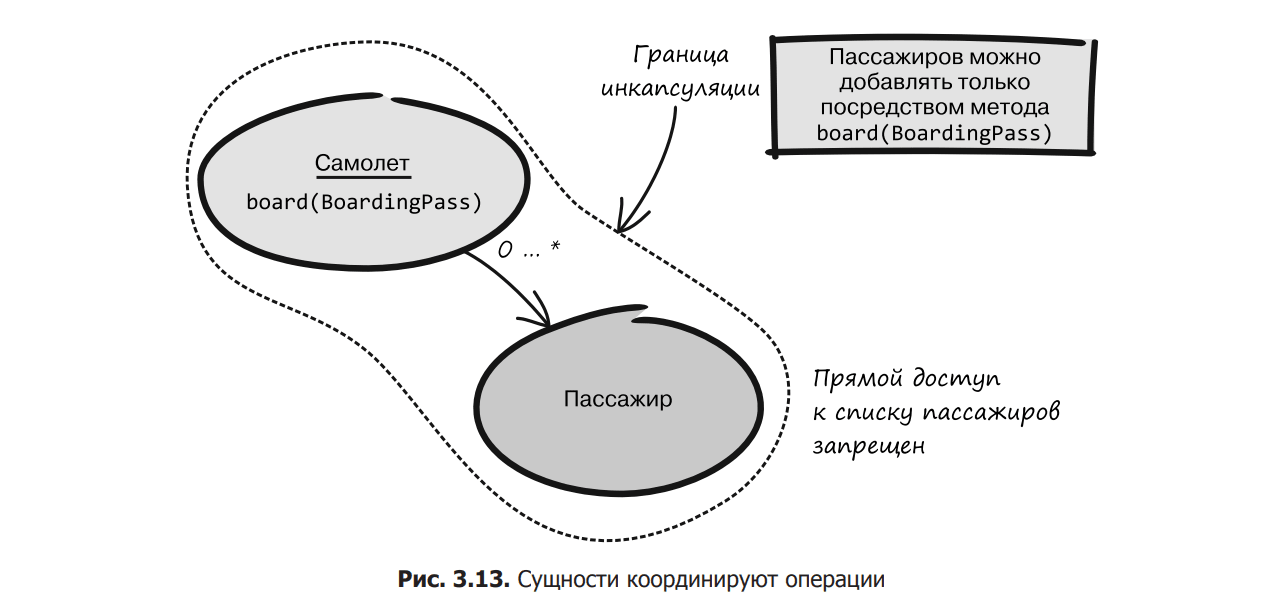
When boarding an aircraft, each passenger must present a boarding pass to confirm that they are boarding the correct aircraft. This makes it easier to track down missing passengers before departure. If passengers were allowed to walk freely from plane to plane, airport staff would have to check boarding passes after everyone had taken their seats. This will take much longer and can cause confusion if passengers get on the wrong plane. In view of this, the control and coordination of passengers during boarding looks quite logical. The same applies to the software model that describes this process.
If you model an airplane as an entity with a list of passengers on board, then other parts of the system should not freely add people to that list, otherwise it will be too easy to bypass invariants.
The passenger must be added using the board(BoardingPass) method from the “aircraft” business entity. Thus, the business entity will control the boarding of passengers and maintain the correct condition. This method allows boarding only if the boarding pass corresponds to the current flight.
Entities are the main mechanism for representing concepts in a domain model, but not all aspects of the model are defined by their identifiers. Their meanings are used to define some concepts. Value objects are used to model such concepts.
As you know from the previous section, the entity often consists of other model objects. Attributes and behavior can be extracted from the entity itself and placed in separate objects. It can be other entities, but in many cases value objects are used for this.
The key characteristics of such objects are listed below:
They are defined not by an identifier, but by their value;
Immutable;
Must form a coherent concept;
Can refer to entities;
Clearly define and enforce important restrictions;
Can be used as attributes in entities and other value objects;
May have a short life span.
As you will see in the following sections, it is largely because of these properties that value objects play an important role in writing safe code at the design level.
A value object is defined by its value, not its identifier, so two objects of the same type are considered equal if their values are the same. We are only interested in what they are, but not what they are. Objects of value do not have identifiers. This is the exact opposite of how we define entities.
Imagine that your domain model has the concept of money. You can model it as a valuable object, since you do not distinguish between different coins and bills. Any two five dollar bills have the same value. The denomination is important here, not its physical representation.
NOTE. How you describe a concept—as an object of value without an identifier or an entity with a unique identifier—depends on the context you’re dealing with.
If you’re modeling a domain like central banking, then money should probably be modeled as entities. The fact is that from the point of view of the central bank, each five-dollar bill is unique, because it not only prints them, but also monitors their turnover and ultimately destroys them. Each banknote has a unique serial number that identifies it and allows it to be distinguished from any other. It is used until it is withdrawn from circulation, for example, to replace it with a banknote of a new type with a new identifier. From a central bank’s perspective, money is unique and has a life cycle.
Indestructible
Since objects of this kind are defined by their values, care must be taken to ensure that the values do not change. Otherwise, it will be other objects. For this reason, value objects must be immutable. If they could be modified, it could break the invariants of other objects inside which they are located. Immutability also allows objects to be passed as arguments and allows for various technical optimizations, such as reusing objects in memory-constrained environments and making them easier to work with on multithreaded systems.
Holistic concept
A value object can consist of one or more attributes, or other similar objects. It can also refer to entities, but cannot contain them. The reason for this is that the value of the entity can change. If the value object did not refer to the entity, but contained it, then any change in it would change the object itself. And this would violate its immutability.
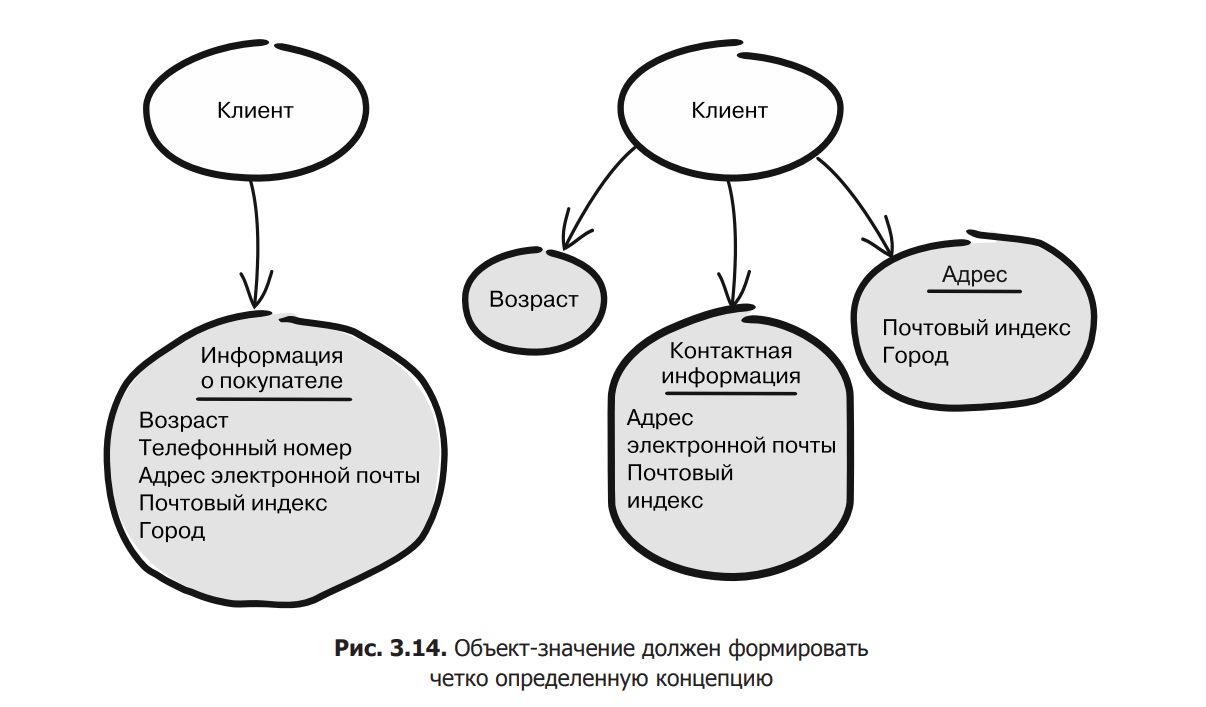
When modeling a value object and determining what it should contain, it is important to make sure that it represents a coherent concept. In other words, it should be the only meaning. That is, the value object should not only be a convenient container for attributes, relationships and other objects, but also form a clearly defined concept in the domain model (Fig. 3.14). This applies even to one attribute. When your value object is modeled as a whole concept, its meaning is transferred along with it, while still being able to retain its constraints.
3.14 you can see two different approaches to modeling the client and its attributes. On the left, all attributes are grouped together in a model object called CustomerInfo. On the right, attributes are modeled to form well-defined concepts: street, zip code, and city are grouped into a value object named Address. The phone number and email address are placed in the ContactInfo value object. And age has become a separate object.
It is important to understand that a value object is not just a data structure that stores a value. It can also encapsulate the logic (sometimes non-trivial) associated with the concept it represents. For example, a value object representing a GPS coordinate point might have a method that calculates the distance between itself and another point using complex calculations.
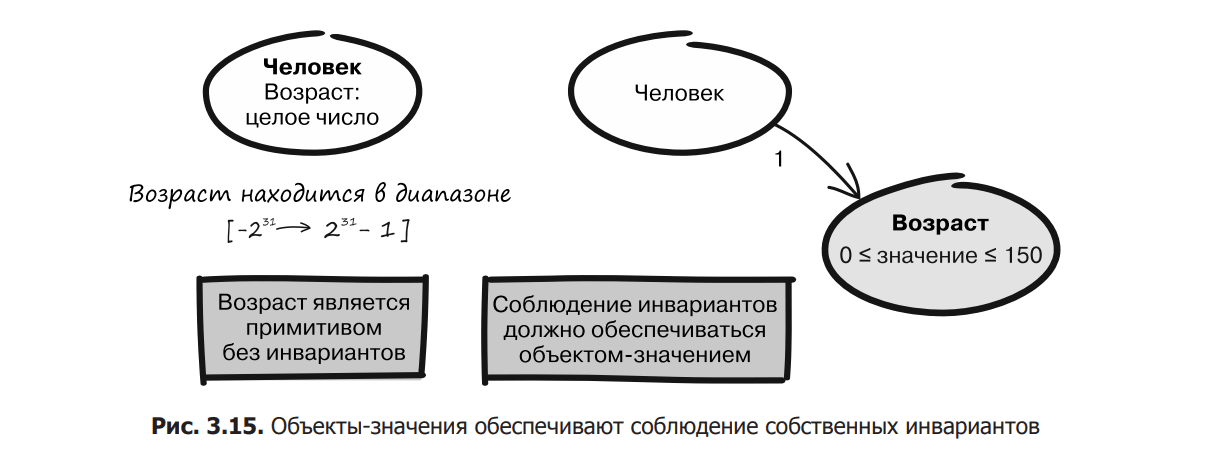
Let’s imagine that you have an Age object with a single integer inside (Figure 3.15). In Java, for example, the default integer is in the range from -231 to 231 – 1. Such a range can hardly be called typical for a human age. Therefore, to refine the definition of age, it should be modeled as a value object with appropriate constraints or invariants, as shown in the figure.
In the course of modeling, it is possible to come to the conclusion that the age of a person should be from 0 to 150 years. Your subject area may not allow children, so the minimum age may be 18. Whatever range you choose will be much stricter than the one Java uses for integers.
It’s also worth noting that the types of invariants we’re discussing here are different from so-called validation checks. They are usually conducted when a statement is made that a domain object is suitable for a certain operation and a certain action can be performed on it. An example can be checking the readiness of the order to be transferred to the delivery system. To do this, you may need to ensure that the order is paid for and contains the required address. Such checks often span multiple domain objects and are typically performed as late as possible.
Rubble
When you’re dealing with a model object with a lifecycle like an entity, you need to make sure that its state remains correct throughout its lifetime. To do this, you may have to implement quite a bit of logic and use code to work with locking mechanisms to support parallel operations and write changes to persistent storage. Regardless of Whether the entity is persisted or not, the change of state can be said to occur within a transaction.
Transaction management is usually possible when working with one entity. But in reality, your domain model is probably not that simple, and there are many relationships between its various entities and value objects. This means that the consistency to be maintained spans multiple domain objects. In such a situation, the question quickly arises: how to manage transactions involving several model elements? That’s what units are for.
An aggregate is a conceptual boundary that can be used to group individual parts of a model. This is done so that when the state changes, the aggregate can be considered as a whole, this is the limit within which transactions must be carried out. The boundary defined by the population is not chosen arbitrarily or technically. It is carefully formed based on a deep understanding of the model.
When modeling the unit, it is necessary to follow strict rules so that it works properly and fulfills the task assigned to it.
Below are the rules suggested by Eric Evans.
Each aggregate has a limit and a root.
The role of the root is played by one specific entity placed inside the aggregate.
The root is the only member of the aggregate that can be referenced by objects outside the boundary.
Ago:
root has a global identifier;
root controls access to objects within the boundary;
all entities except the root have local identifiers that may be unknown outside the aggregate;
the root can pass internal entity references to other objects, but these references can only be used temporarily and cannot be held;
the root can pass references to value objects to other objects.
Invariants between aggregate members are always respected within each transaction.
Invariants spanning multiple aggregates are not guaranteed to be consistent at all times, but may eventually become consistent.
Objects inside an aggregate can contain references to other aggregates.
It’s a pretty broad set of rules, and you should probably go through it again and think about their meaning and the implications each one will have not only for your model architecture, but for your code as well. However, there are a few points we would like to clarify.
A set is a conceptual boundary, and it contains the entity that is its root. In the general case, at the implementation stage, the root entity and the aggregate itself are one and the same object. You may find it easier to talk about them if you think of them as identical.
The root of an aggregate is the only part of an aggregate that is visible outside its boundaries. Root controls access to everything inside the unit. This makes it an ideal place to put all the invariants spanning different objects within a scope. It cannot be bypassed, provided that the rules of aggregate modeling are followed. This also means that root is the only thing that can be accessed through the repository (see sidebar). This is another way of controlling access to an aggregate, which ensures that the entities inside it cannot be directly modified by external objects.
REFUGE
We won’t go into details about repositories, but you can think of them as technology-independent repositories for aggregate roots. Roots can be stored in storage and logged out later. Repositories also allow you to delete previously saved roots if your model supports it.
Aggregations, along with their boundaries and consistent state support, can play an important role in keeping your code secure. Let’s look at an example of how to model a simple unit.
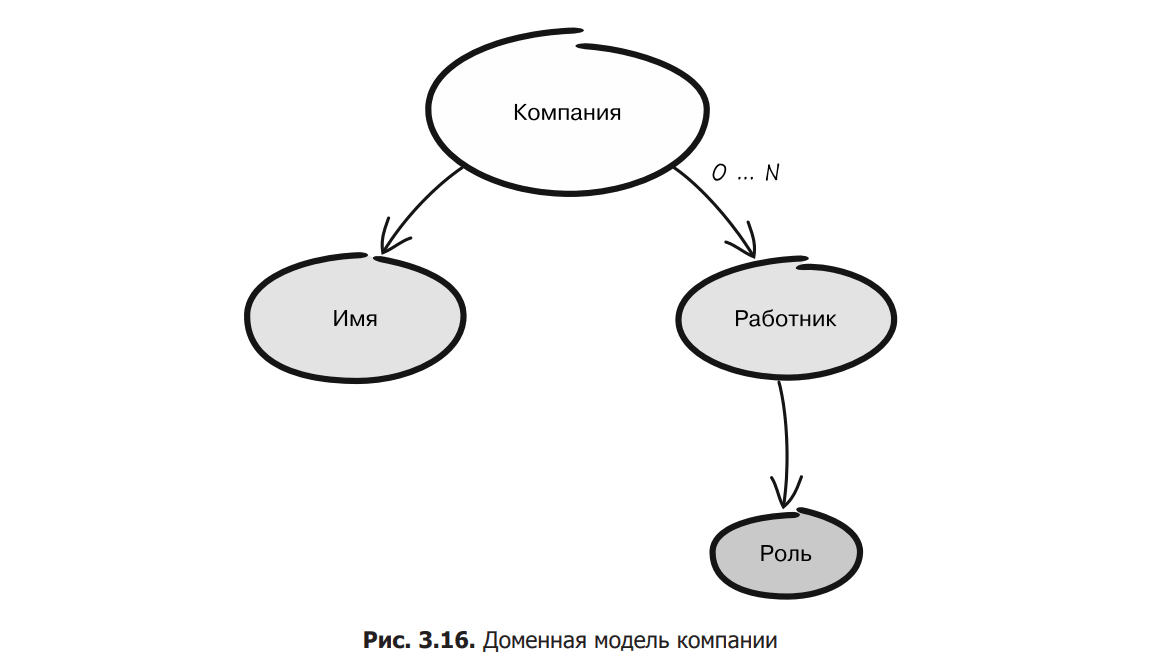
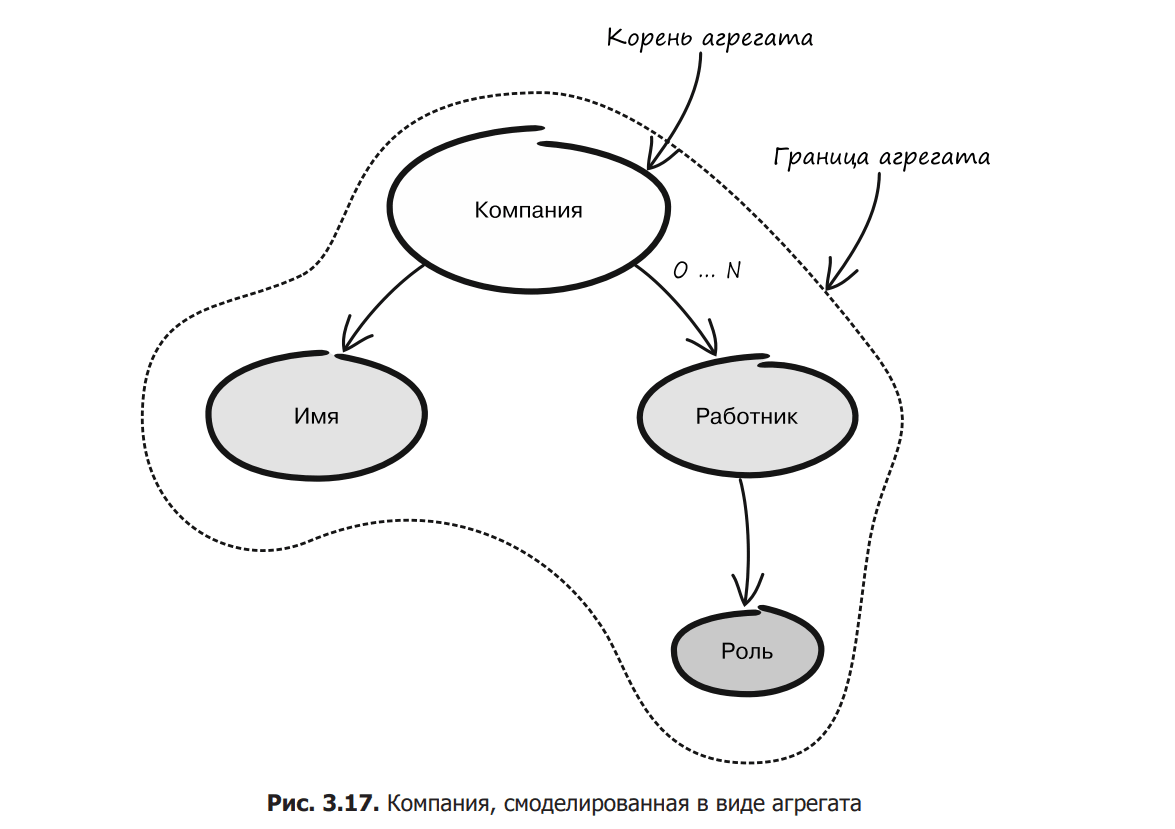
The demo model consists of a company and its employees. We will make the company a business entity because it must be globally identifiable. It has a name, but it’s just a value, so let’s think of it as a value object. Employees work in the company. Each of these clearly has an ID, so it will also be modeled as an entity. The employee always belongs to the company, so he will be its child. Each employee has a certain role, but it is also a value, so it will be represented by a value object. The final model is shown in fig. 3.16.
After discussing the character of the employee with relevant experts, you realized that he does not need to be identified outside the company. A work object can have a local identifier. You also noticed that some roles can only be assigned to specific employees. For example, a company can have only one technical director. The same goes for many other roles. To preserve these invariants, the company’s business entity must manage the process of assigning roles to employees. It follows that the company and all its subsidiaries must be modeled as an aggregate. The root of the division will be the company itself. The result is shown in fig. 3.17.
This means that the company can be referenced externally because it is globally identified, but the employee can only be accessed through the root of the collection, i.e. the company itself. The same applies to assigning roles to employees. This is done using a method owned by the company. Since all operations on the aggregate are controlled by its root, maintaining the invariants associated with workers becomes a fairly simple task.
In this chapter, you learned the basics of the fundamental building blocks used to create domain models in DDD. We’ve covered quite a bit of material and it may take some time to properly absorb all of this information. Next, we’ll talk about bounded contexts, another important concept from the world of DDD that you should understand before moving on to the rest of the chapters in this book.
The Bounded Context design pattern is another interesting concept that defines the scope of a domain model. It plays an important role not only in DDD, but also in security. Using limited contexts as a basis for analysis helps to better understand sophisticated attacks. To make sure of this, you need to understand this concept correctly, so let’s first dive into the semantics of a single language.
Semantics of one language
In DDD, the single language is considered to be spoken by everyone and always and which ensures clarity and mutual understanding (Fig. 3.18).
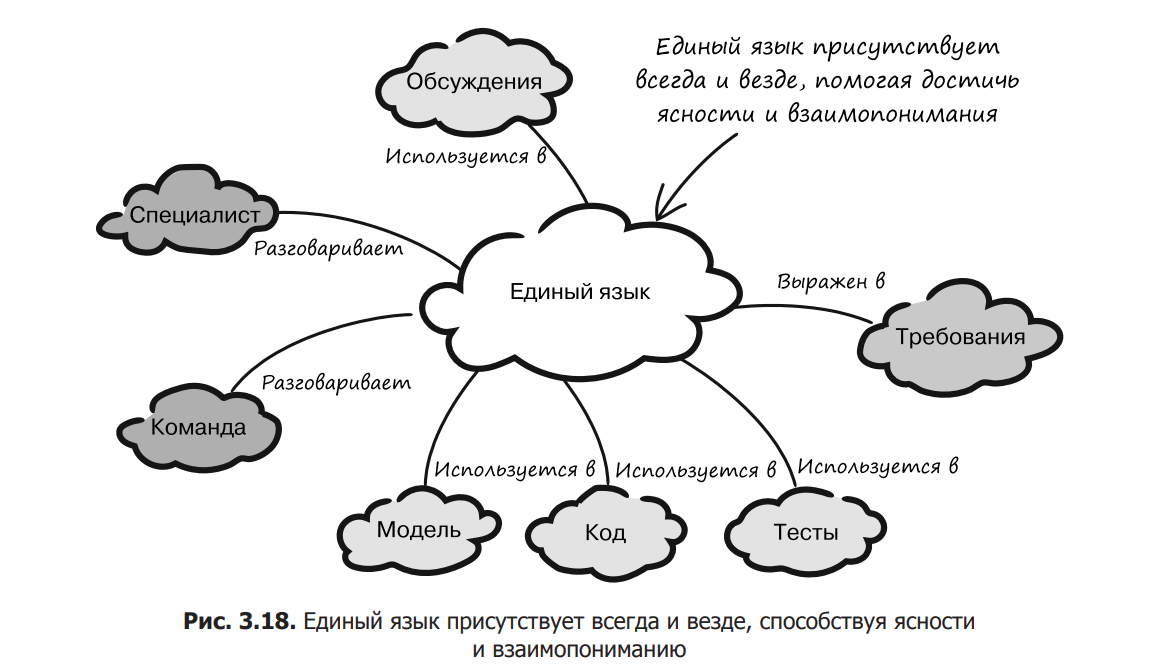
Because we say “everything”, “always” and “everywhere”, it is easy to think that we are talking about a single language with terms, operations and concepts that cover the entire field of business, but this is absolutely not the case. Anyone who has tried to implement such a language knows that this idea is doomed to failure due to its excessive complexity. And the reason for this lies in semantics.
A term or concept may have the same name in different parts of the subject area, but its meanings may differ. Take, for example, the word “package”. If you ask someone in shipping what it means, they’ll tell you it’s packaging, but if you ask an IT guy the same question, they’ll tell you it’s a way to logically group files in the codebase. The term “package” is used here and there, but with different semantics. An attempt to express this in one language is unlikely to be successful, as this would require the creation of a new term that includes both meanings. The obvious solution here would be to use two parallel languages instead of one single language with imprecise semantics. Now let’s see how one language relates to models and bounded contexts.
The relationship between the language, the model, and the bounded context becomes obvious when viewed from the perspective of semantics. A model is an abstraction of a subject area in which there are concepts, relations and terms of one language. This closely connects the language and the model with each other – and not only due to terms and relationships, but also at the level of semantics: the concept’s belonging to the model should have the same meaning as in the language, and vice versa.
The model remains consistent if the semantics of its terms, operations and concepts do not change. However, with any change in semantics, the model breaks down and the boundary of the context becomes obvious. This is very important to understand, because this is where the meaning of a term can change just because it has crossed a border. This means that everything inside the context corresponds to the semantics of the model, and outside the same terms can have different semantics. It sounds quite logical, but a little abstract.
Let’s look at an example where we describe a single language, create a model, and use it to define a semantic context boundary.
Defining a bounded context can begin with the analysis of a single language. Take, for example, the following dialogue between a developer and a delivery specialist.
Developer: What characterizes the order?
Specialist: The order contains both salable and non-salable items.
Developer: Not quite clear. What do you mean by unsold products?
Specialist: These are the products that are added to the sold product when the package is sent to its destination.
Developer: Oh, I see. Are these products without a price?
Specialist: No, no! All goods have a price, but those that do not sell have zero, so they are added for free.
Developer: Hmm, ok. It sounds logical.
At this stage, there is still a lot of confusion, but we can already highlight important terms and express them in the form of a draft version of the domain model (Fig. 3.19).
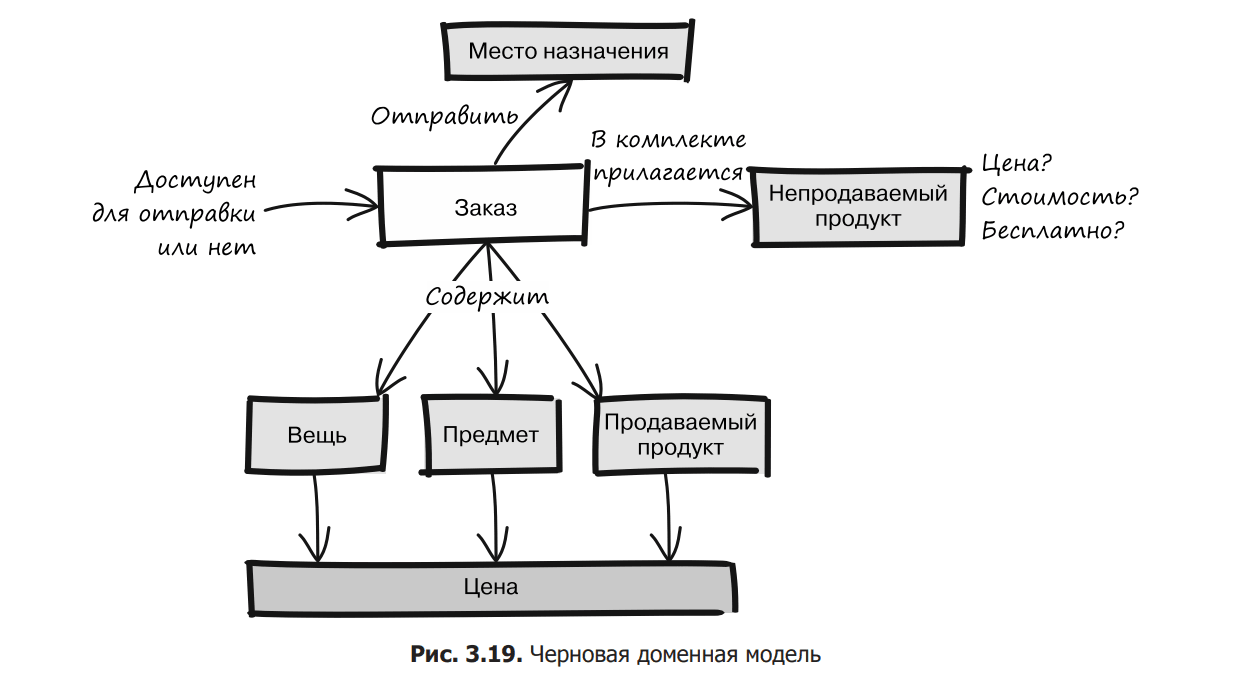
One of the key principles of a common language is to avoid ambiguities, as they create a lot of confusion and misunderstandings. This can be seen in fig. 3.19, where the model has many ambiguous and repetitive concepts. Let’s go back to the previous dialog and see how our language and model evolve.
Developer: I’m a little confused by the terminology. Maybe we can agree on the use of some common terms?
Specialist: Of course. Do you already have something specific in mind?
Developer: Apparently we only have products. Maybe we will stop using words like “objects”, “things”, “sold” and “unsold”?
Specialist: Okay, that sounds logical. From now on, we will call all these products.
Developer: “Included” and “included” are the same thing, right?” Expert: Yes, let’s just use “attached” then.
Developer: What about price and value?
Specialist: It’s the same thing. Let’s stop at the price.
Developer: Why should we care if a product is free or not?
Specialist: You are right. Let’s not use the word “free” anymore.
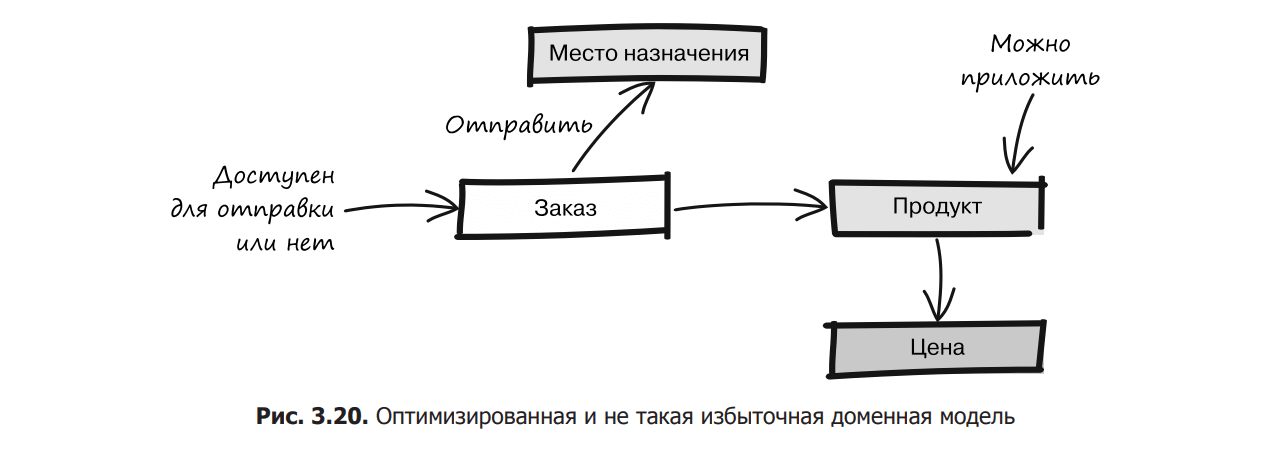
As a result of the distillation process, we got a much more concise language and an optimized model of the subject area (Fig. 3.20).
But sometimes distillation can reveal missing terms, as shown below.
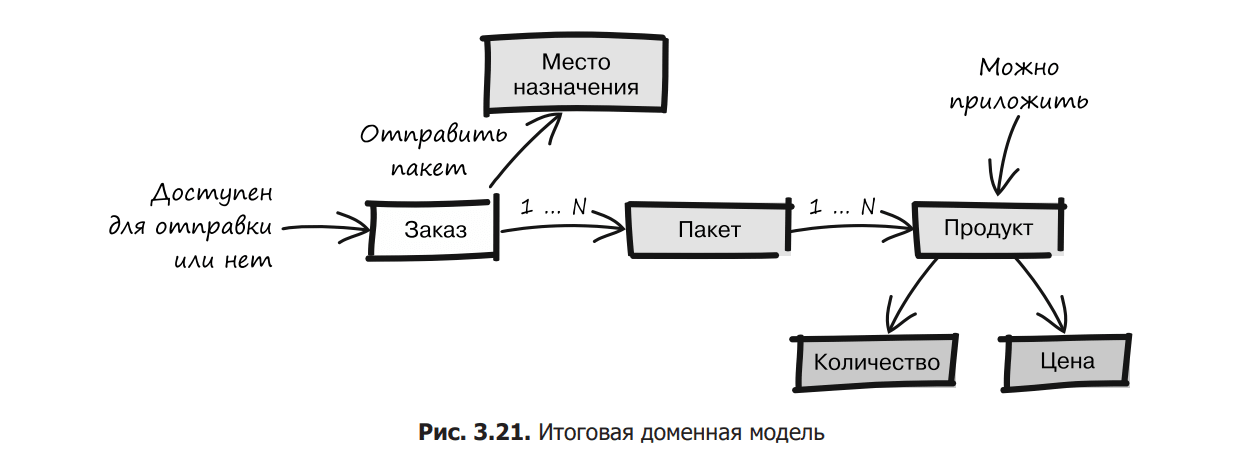
Developer: Can the order contain one or more products?
Specialist: Exactly. But for an order without products, the package is unlikely to be needed.
Developer: Package?
Specialist: Ah, sorry. The package in which the order is sent is called a parcel.
Developer: Okay, that sounds logical. But how do we know how many products to send in a package?
Specialist: The number of units of each product is specified in the order.
Developer: Yes, I see. Let’s add “quantity” and “package” to our unified language and model.
After this refinement (Fig. 3.21), the developer and the specialist are quite sure that they have a common vision and understanding of the order.
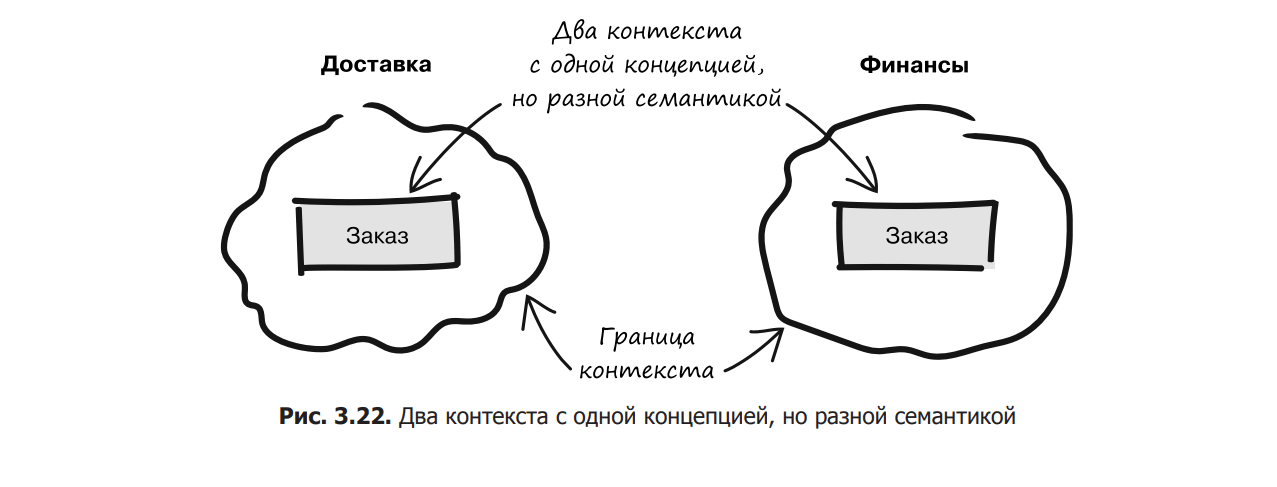
But how deeply does the model penetrate the organization? When did this model no longer fit the business? The answers to these questions are key to defining the boundary of the context. The developer starts asking around, and it seems that there is a mutual understanding in the delivery department. But, turning to a specialist from the financial department, the developer suddenly discovers a violation of the model.
Developer: Please take a look at our order model.
Finance Specialist: Of course. The model looks logical, but you seem to have missed many important concepts.
Developer: Really? Please explain.
Financial specialist: There is no information about payment and deadlines. I also don’t see the reserved amount.
Developer: Yes. It looks like we are using different order definitions. Thank you for your time.
As soon as the semantics of the model is violated, the boundary of the context becomes obvious. Having discovered exactly where the contradictions arise, the developer quickly realizes that in the spheres of finance and delivery, the order means different things. This will tell you where the context boundary is. We can illustrate this in the form of two separate contexts, each of which represents the concept of ordering with a different meaning (Fig. 3.22).
But what if we need to interact and pass commands between contexts? Are there other similar concepts with different semantics? This brings us to the next topic, which is the interaction between contexts.
A context boundary is of interest from a security perspective. Let’s think about how the interaction between contexts happens. When data crosses a boundary, it automatically acquires the semantics of one language and the model of another context. It follows that inaction in this process creates a risk of vulnerabilities. And while this may seem obvious, problems of this kind are surprisingly common.
Ironically, the main reason for this may be trying to follow the DRY (Don’t Repeat) principle. Andrew Hunt and David Thomas define this principle as follows:
Each piece of knowledge must have a single, consistent and authoritative representation within the system.
Hunt, A., Thomas, D. The Pragmatic Programmer (Addison-Wesley, 2003)
Many interpret it as avoiding syntactic duplication, which occurs, for example, when manually copying code, but this principle is also applied to semantics. And this brings us back to the common language.
A single language requires that the semantics of a domain model be unique across contexts. But if you follow the syntactic interpretation of the DRY principle, the method of data exchange between contexts suddenly turns from a semantic issue into a technical one. And that’s a huge problem, because if you apply common models to reduce code duplication, and some of the concepts in those models mean different things, it makes possible all kinds of crazy problems, including security holes. To illustrate this, let’s go back to the example of the shipping and financing contexts, but this time we’ll try to reduce syntactic duplication by using a generic model.
Concepts such as order, product, and price are used in the fields of shipping and finance. The case for having a common model is really compelling because it reduces duplication. But for this it is necessary to borrow a few more concepts from the financial sphere (Fig. 3.23).
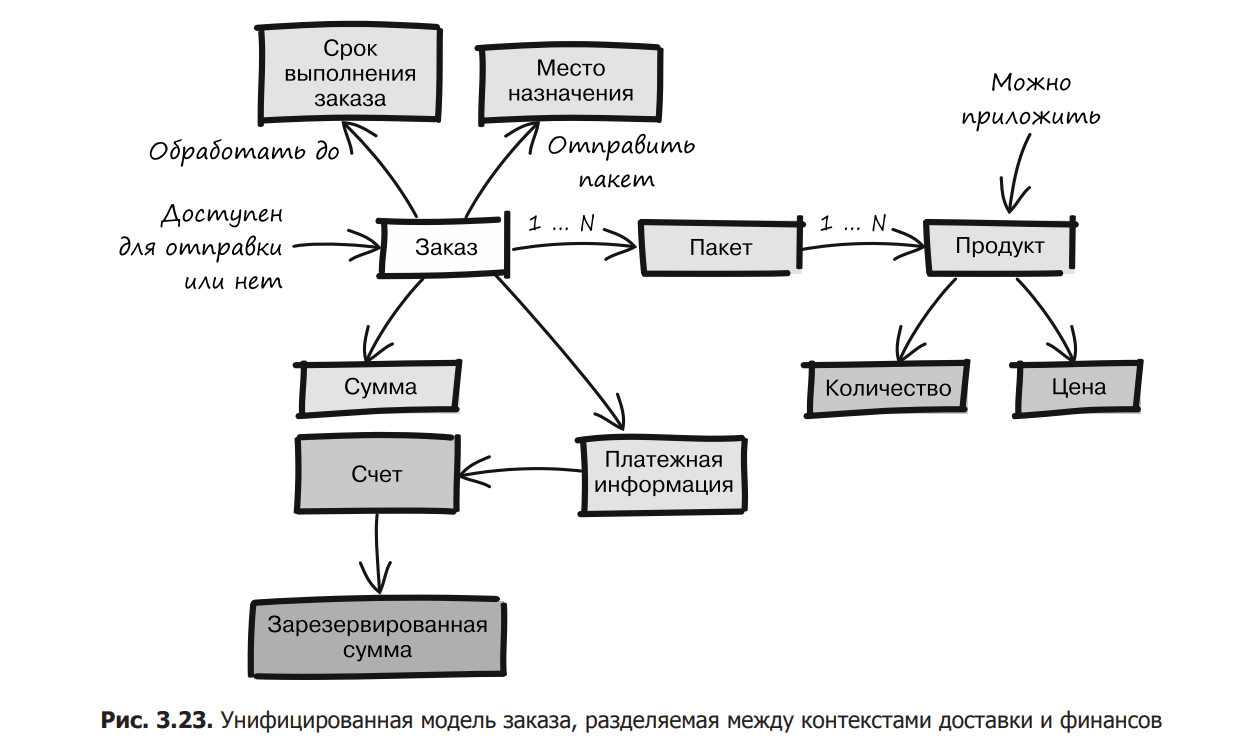
At first glance, the use of a unified model turned out to be a great success. The only visible drawback is that the model came out saturated, with several additional concepts. But let’s see what happens when a new business requirement arises in the context of shipping.
Specialist: To simplify customs declarations for international shipments, we need to indicate the actual value of the parcel.
Developer: Good. But what do you do with the included products in this case?
Specialist: We used to make the product free by artificially setting its price to zero, but we can’t do that anymore.
Developer: Exactly. Maybe we just remove the dummy price?
Specialist: Yes, the package cost is the sum of all prices, so it should work.
Developer: And then subtract the prices of the added items from the total, right?
Specialist: No, the bill issued by the finance department shows a reserved amount, so we don’t need to deduct anything.
Developer: Sounds logical. Then I’ll just remove the bogus prices.
It doesn’t take much effort to make the changes and everything works fine at first, but after a while the finance department starts to see strange things. For some reason, the invariant “reserved amount ≥ sum of all prices” is sometimes violated. This issue may seem minor, as it only happens when free products are added. But as a result, a full-scale investigation is being launched. Violation of an invariant is tantamount to order falsification, and this is a serious security hole!
The investigation did not reveal any vulnerabilities, but the fact that a simple change could have such consequences is quite interesting. Further analysis revealed that the real root cause was the use of a single model in two conceptual representations of order. The invariant “reserved amount ≥ sum of all prices” makes sense only in a financial context. But since there is a generic model, the delivery department is forced to adhere to this invariant, even though it makes no sense in this context. This is an obvious problem because it prevents contexts from being independent and owning their own models. But if we do not apply a general model, how do we know which concepts require special attention when interacting across different contexts? The solution is to create a context map.
A context map is a conceptual representation of how different contexts interact. It can be a diagram, a textual description, or simply a mutual understanding between teams. In any case, its key feature is that it helps identify concepts that cross semantic boundaries.
A misfolded card often causes misunderstandings that can lead to security issues. Thus, defining the boundaries of the context is very important, but it is easier said than done. If you don’t know where to start, Conway’s Law is a great solution. In 1968, Mel Conway published an article entitled “How Do Committees Invent?” in which he proposed the following thesis.
Any organization that develops a system (in the broadest sense) will create a project whose structure is a copy of the organization’s relationship structure.
Conway M. How are committees invented? (Datamation, 1968)
It follows that the communication structures that exist in the organization are often reflected in the system architecture. This seems to be related to the way bounded contexts are defined. Many teams tend to organize their work around subsystems, and bounded contexts often follow the same logic. Therefore, the process of dividing workers into teams is a good opportunity to define limited contexts for your map.
To illustrate what a graphical representation of a context map might look like, let’s go back to the delivery and finance departments. To begin with, it will be useful to draw a simple general scheme of interactions within the system during order processing (Fig. 3.24).
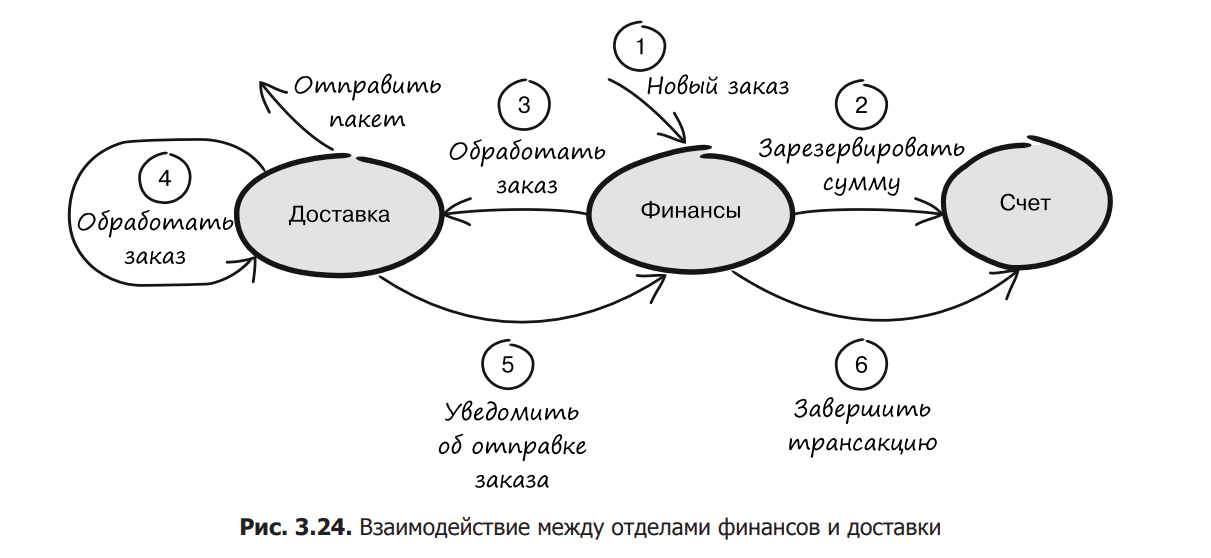
This is how the finance and delivery teams work.
The finance department receives a new order.
The total amount of the order is reserved to the account specified in the payment information.
The finance department forwards the order to the shipping department for processing.
The delivery department processes and ships the order.
The shipping department notifies the finance department of the new status of the order.
The financial department completes the cash transaction.
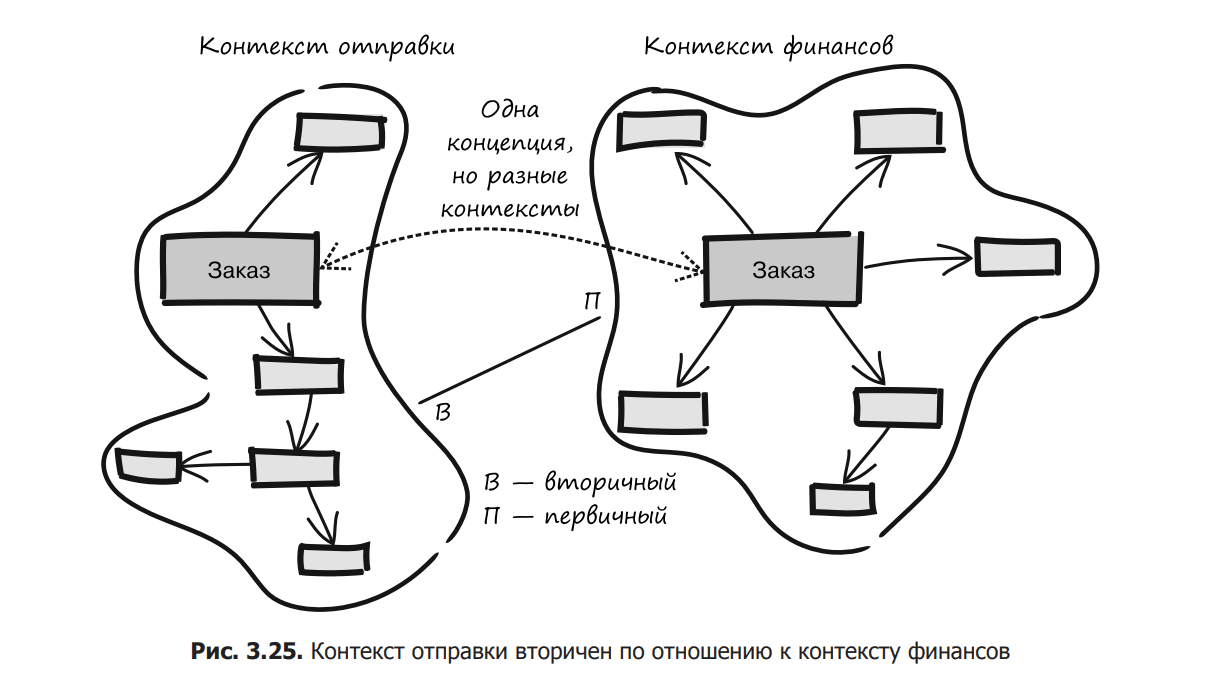
This flowchart can easily be turned into a context map that makes it clear that the delivery context is secondary to the finance context (Figure 3.25). This may seem obvious, but understanding that a finance order needs to be converted into a delivery order is of paramount importance. This attitude clearly indicates the need for clear communication and that teams must work together to succeed.
You should already have a conceptual understanding of why bounded contexts are important and how their maps are created, but we still need to explain how they relate to security. In the following sections, you’ll see how bounded contexts can help you analyze your code for vulnerabilities. For example, in Chapter 9 we will look at fault handling, and in Chapters 12 and 13 we will talk about working with legacy code.
In the next chapter, you’ll learn programming concepts that can improve security by using ideas from this chapter and other areas. You will be able to apply them in your daily work and learn to identify vulnerabilities in your existing code base.
Creating domain models is a good opportunity to gain deep knowledge about the subject area.
The domain model should be a strict and unambiguous representation of the subject area and cover only its most important aspects.
When creating a domain model, we make a choice between many different variants of it.
The domain model forms a language for discussing the system.
Entities, value objects, and aggregates are the main building blocks of your domain model.
An entity contains an identifier that remains constant throughout its life cycle, and can consist of other entities or value objects.
The uniqueness of an entity is always limited to some area that depends on the model.
A value object does not have an identifier, it is determined by its value.
The value object must always remain unchanged and form a coherent concept.
An aggregate is a conceptual boundary that connects other model objects and is responsible for maintaining invariants between these objects.
An aggregate always has a root, which in code usually coincides with the aggregate itself.
The root of the aggregate has a global identifier because it is the only part of the aggregate that can be referenced by other elements of the model.
A single language is used by all team members, including subject matter experts. This ensures understanding.
The domain model is limited by the semantics of a single language.
The context in which the semantics of the model is observed is called limited. Any change in semantics leads to a violation of the model, which allows you to determine the boundary of the context.
Determining the boundary of the context can be started by applying Conway’s law.
Data crossing a semantic boundary is of particular interest from a security point of view, as the meaning of a concept may change when crossed.
We used materials from the book “Security by design”, which was written by Dan Berg Johnson, Daniel Deoghan, Daniel Savano.





