
04.09.2023
48 min
1976

Mutable state is an important aspect of the system. In fact, many of them are designed specifically for state changes, as in the case of the online bookstore in Chapter 2. The system tries to track various state changes: placing books in the cart, paying for orders, sending books to customers. If the state does not change, nothing interesting will happen. From a technical point of view, a state variable can be represented in various ways. We’ll look at some of them and demonstrate our better approach, the entity-specific design model modeled in Chapter 3. Because entities contain state that represents your domain, it’s important that they follow business rules when created.

Entities can be created in a conflicting state, which can cause software bugs and security vulnerabilities that are difficult to identify. However, complying with all the restrictions when creating can be a difficult task. Difficulty depends on their severity and complexity. We will discuss some techniques suitable for working with state variables in most cases. We start with techniques that satisfy simple constraints and end with the Builder design pattern, which can handle even quite complex situations. When entities are created sequentially, they must be consistent. We’ll illustrate the common pitfalls that threaten your organization’s integrity and advise you on how best to structure your organization to protect it. Let’s start with the different ways to manage state so you can understand why we prefer working with entities. For some programming languages, such as Haskell, there is an interesting concept where all code consists of only immutable structures. However, most languages, including Java, C, C#, Ruby, and Python, use mutable components as objects with internal state.
The main task of most systems is to track how things change. When a suitcase is loaded on board an airplane, it, like the airplane, changes its state. At the same time, new rules that did not exist before the download suddenly come into force. The suitcase can no longer be opened, but now it can be unloaded; The aircraft load is increasing. This is what in computer science is called a state variable. You should monitor your system state changes and make sure they all follow the rules.
If the system you write doesn’t manage change properly, sooner or later you’re going to run into security problems, maybe minor or maybe major. Baggage management system at the airport should keep track of suitcases. If the suitcase is not scanned, it should not get on board the plane, the system is obliged to prevent this. She must also know who owns the luggage and whether the passenger in question is on board. If the passenger does not appear, the luggage must be unloaded, otherwise there are serious security risks.
All of the design approaches discussed in this chapter involve modeling change as an entity (to use DDD terminology). As described in Chapter 3, DDD defines an entity as something that has a stable identifier and state that can change during its lifetime. A good example of this is luggage at the airport. It can be checked in, scanned, loaded on board and unloaded back, But in our understanding, it is the same suitcase whose status changes. Entities are the preferred means of implementing mutable state, but let’s briefly consider the alternatives (Figure 6.1).
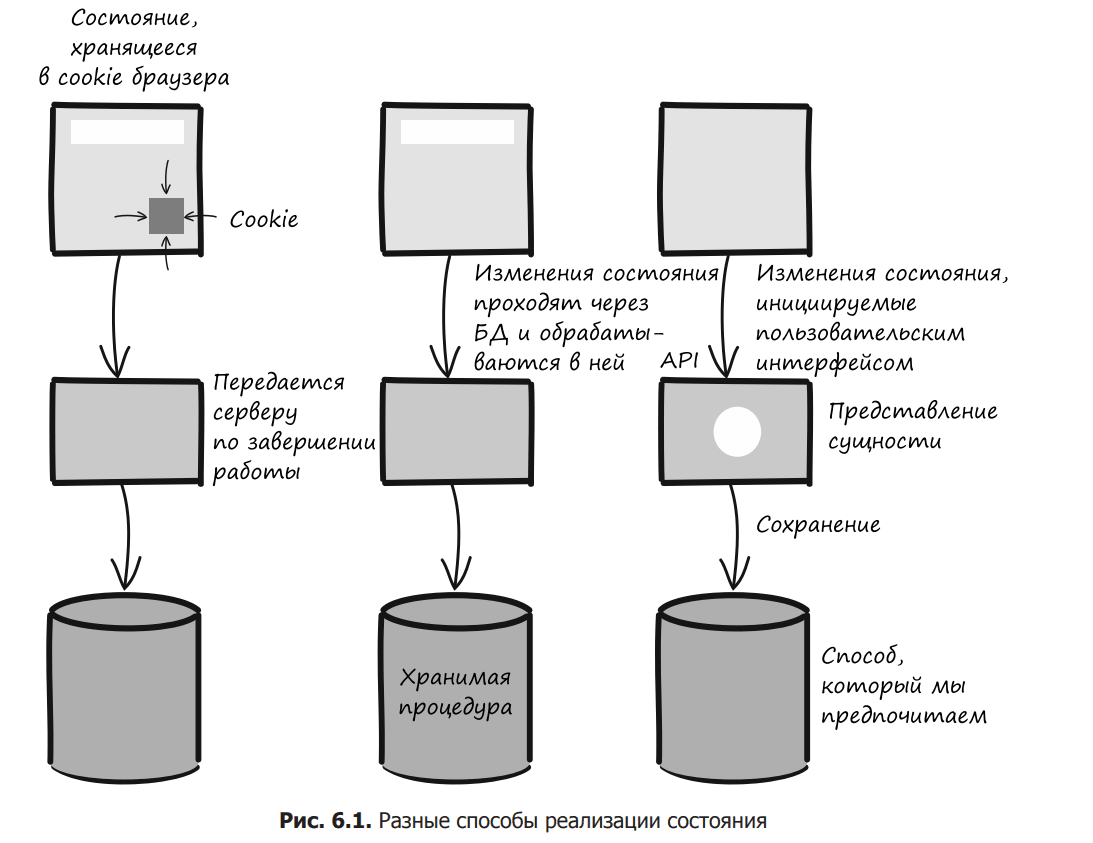
During system design, state changes can be tracked and handled in a variety of ways.
You can store state inside a cookie.
You can make changes to the database directly using SQL or stored procedures.
You can use a program that downloads the state from the server, updates it, and sends it back.
All these approaches are quite feasible and have different advantages. But, unfortunately, many systems use a messy mixture of them. It’s risky. If the responsibility for storing and managing state changes is distributed among many different components, there is a danger that these components will not work well together. It is small logical contradictions that make security holes possible. Therefore, we prefer an architecture in which it is easy to understand which states are valid and which changes are possible in each of them.
In our experience, to ensure secure state management, it is best to model it as DDD-style entities. In the process of modeling, it is necessary to select the most important concepts. Perhaps, to better understand the rules, a suitcase, a flight and a passenger will do, or perhaps it is worth considering this situation from the point of view of check-in, loading and people who got on board. In the first case, the business rule may sound like this: “The suitcase must be on the same flight as the passenger who registered it.” In the second case, the rule can be rephrased: “Only checked suitcases belonging to passengers on board can be loaded.” You will probably agree that the first sentence is easier to read, so it should form the basis of your model. But as you saw in Chapter 3, sometimes it pays to spend time learning about other models, and sometimes it pays to get a better understanding of the subject area, as the example in Chapter 2 showed.
One of the advantages of subjects is that everything we know about the state and the changes taking place in it is concentrated in one place. We also prefer to implement mutable state using a class that contains both data and associated behaviors (in the form of methods). This approach will be illustrated many times not only in this chapter, but also in the next chapter, which is devoted to simplification.
There are an infinite number of ways to design objects, and we’ll share methods and techniques to help make your architecture and code understandable and secure. Later in this chapter, we’ll learn how to build and maintain organizations in a consistent state that doesn’t compromise business integrity. First, let’s look at creating entities safely.
An organization that violates the rules of doing business is a security concern. This is especially relevant for entities at the time of their creation, so it is necessary that the creation mechanism first guarantees their consistency. This advice may seem obvious, but sometimes it is perceived as a formality, and its results can be deplorable.
One of our colleagues once worked with a large Asian bank. It discovered several security vulnerabilities, but they were all dismissed as minor technical flaws. It wasn’t until he managed to create an account without an owner that the problem began to be taken seriously. A bank account without an owner is something unheard of, and the very fact of its existence could cost the bank its license. The problem was immediately reported to senior management, who assigned it the highest priority.
A non-compliant entity is a security risk, and in our experience the best way to deal with it is to insist that all entity objects must be consistent at creation time. In this section, we will show the dangers of the most common mistake, the no-argument constructor, and consider some workarounds. In addition, we will discuss different ways to create an entity, from the simplest to the most advanced. Increasing the complexity of constraints leads to the complication of the creation procedure. If your restrictions are banal, a simple procedure will suffice. Let’s start with the elementary case of using a constructor without arguments. It is so simple that it is practically useless. At the end, the scheme of the “Builder” design, designed for use in the most difficult situations, will be demonstrated.
Entities often represent information that is stored and changed over a long period of time, so they are often stored in a database. When a relational database is used in conjunction with an object-relational mapping (ORM) such as JPA or Hibernate, confusion can arise that leads to poor and unsafe architectural decisions. We will talk about how to use such frameworks without compromising security.
The introductory example of this chapter is taken from the field of finance, but the problem extends to other fields as well. Entities that are conflicting immediately after creation are found in the code of different projects. Many of them have something in common: creating objects using a constructor that takes no arguments.
The easiest way to create an entity is undoubtedly to use a constructor. What could be easier than calling a constructor with no arguments? The problem is that such constructors rarely ensure the creation of completely consistent and ready-to-use objects.
If you think about it, a constructor without arguments is something strange. It promises to create not just an object, but an object for which no attributes need to be specified. For example, if you take a car, it will not have a color, number of doors, or even a brand. As a last resort, if any of these attributes are set, they will have a default value that should apply to all cars when they are created. In practice, constructors without arguments do not perform their direct duties – they do not create consistent objects ready for use.
We often encounter entities for which there is some sort of convention to create: first a constructor with no arguments is called, followed by a series of setter methods that initialize the object and prepare it for use. But there is nothing in the code that would guarantee compliance with this agreement. And, unfortunately, it is often forgotten or performed incorrectly, which leads to the appearance of contradictory entities.
CAREFULLY. If an entity has a constructor with no arguments, it most likely means that its initialization is based on a setter. And this becomes a potential source of problems. Setter-based initialization can be incomplete, and incomplete initialization makes objects inconsistent.
Let’s see what code we often come across. In Listing 6.1, you see an Account class with several attributes: a bank account must have a number, an owner, and an interest rate. It can have an optional credit limit, which allows the account holder to borrow a certain amount, and a reserve account (more often an accumulation account), from which funds are withdrawn if necessary, so that the balance on the main account does not become zero or negative. In the AccountService.openAccount method, it shows how this constructor is intended to be used with no arguments. Following the constructor, the setter methods are called sequentially to fill the Account object with data.

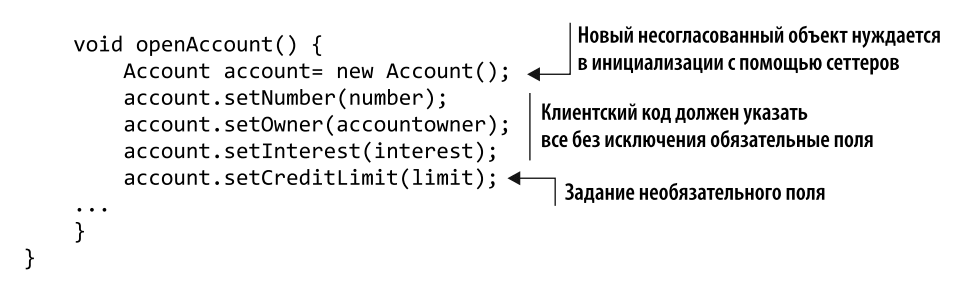
This approach allows you to create a completely empty object with subsequent filling of mandatory fields. However, there is no guarantee that the Account object will be able to meet even the most fundamental and important business constraints. Moreover, this approach is unreliable, as it is necessary to re-perform all actions when creating each object. If conditions change, updating the code will become a nightmare. Imagine, For example, as part of the International Anti-Corruption Initiative, many countries have special financial provisions for politicians. For example, government officials are more prone to corruption and bribery because of their influence. Each account must have information about whether it belongs to a policy.
Imagine that you are working with the Account class and, according to the new requirements, it must have an additional field boolean political exposedPerson. Also, it must be set manually each time an entity is created. Now you have to find each section with the new Account() constructor in your code and make sure that setPolitical ExposedPerson is called in them as well.
The compiler will not report an error like it would if you added the parameter to the constructor’s argument list. A well-designed set of tests should be able to detect a bug, but our experience is that codebases with no-argument constructors rarely provide such tests. Unfortunately, with each new attribute, some pieces of code will be skipped, and they may be different each time. Usually, over time, this process leads to inconsistencies in the code base, in the security of which holes appear sooner or later.
If you’re using an object-relational mapping framework such as JPA (Java Persistence API) or Hibernate, you may feel compelled to use no-argument constructors for your entities. The exercises for these frameworks always start by creating an entity this way, and it seems like the code should be written that way. But it is not quite so. If you’re working with such a framework, you have two options to avoid the security problems common to no-arg constructors: either separate the domain model from the storage model, or make sure that the storage framework can’t access conflicting objects.
The first option is to distance yourself from the storage model at the conceptual level. If you do this, the storage model will be in a separate package with the other infrastructure code. When receiving records from the database, the framework loads them into storage model objects. We then use these objects to create domain objects that will then handle business logic calls. This gives you complete control over the creation of any domain objects, while keeping all JPA annotations in a separate package with the storage model.
If you don’t make this distinction and map domain objects directly using a storage framework, you’ll need to use that framework very carefully. In our experience, this style is quite common and can be safe, so we’d like to share a few tricks to help you.
Storage frameworks like Hibernate and JPA really need no-argument constructors. The fact is that these frameworks must create objects when receiving records from the database. To do this, they purposefully create an empty object and fill it with information using reflection. So they first need a constructor with no arguments. However, it doesn’t have to be public – both Hibernate and JPA can work fine with private constructors. Also, these frameworks don’t require setter methods to embed data—if you specify the storage style in private field annotations, they can apply the mapping by initializing those fields directly.
All required fields as constructor arguments
Consider a simple solution to the security problems caused by conflicting entities: instead of a no-argument constructor that does not pass enough information for consistent creation, we use a constructor that accepts all the necessary data (Figure 6.2).
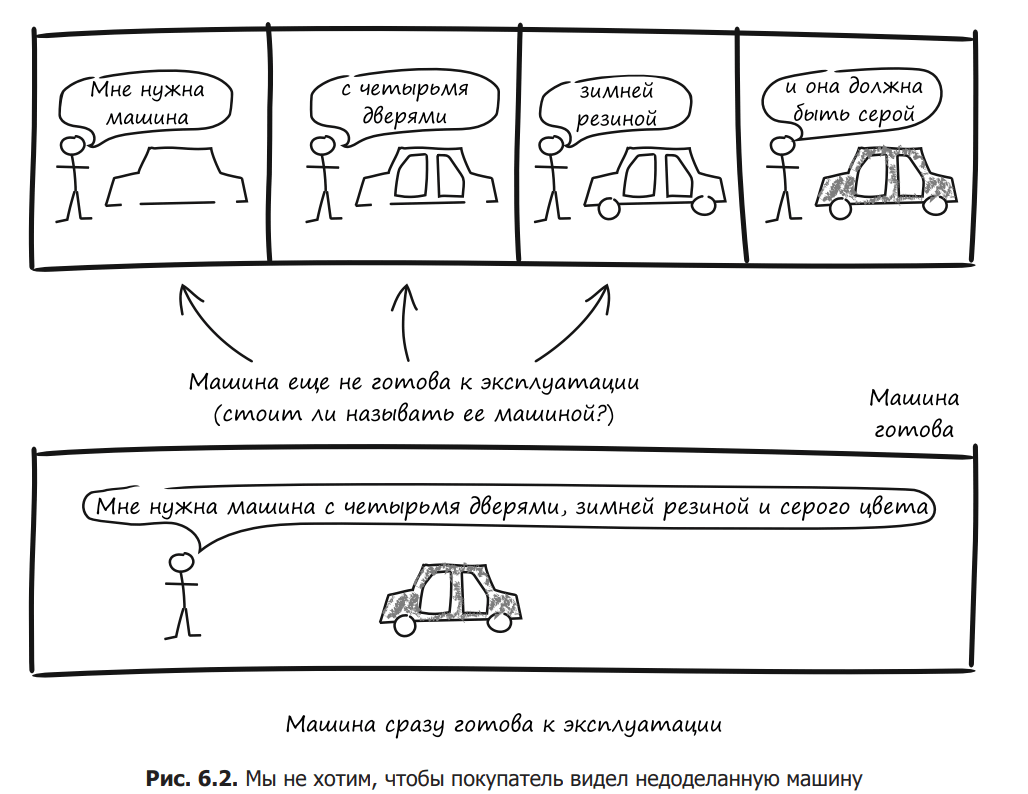
Let’s expand the constructor parameter list to include all the information we need. At this point, you don’t need any options with additional information. Ensure that the entity is created in a fully consistent state. Optional data can be specified after creation by calling individual methods.
Listing 6.2 shows the result of applying this approach to the previous example with the Account class. The constructor needs to pass the account number, owner information, and interest rate, which are required attributes. Additional credit limit and reserve account attributes are not included in the list of constructor arguments and are specified later by calling separate methods.



The constructor argument list contains only required fields, so we expect none of them to ever be null. Appropriate checks can be added to the constructor.
History of getter/setter naming conventions in JavaBeans In Listing 6.2, you gave setters and getters names that better reflect their role in the domain. As mentioned in the previous section, there is a misconception that getters and setters are necessary for data storage frameworks to work properly. It does not. They can be replaced by field annotations. Frameworks like Hibernate and Spring Data JPA implement reflection which allows them to find private fields. For this reason, we don’t need public methods named in a specific way.
We’d also like to tell you where the getter/setter naming convention came from. They were developed in 1996 as part of the JavaBeans specification. The main idea behind this project was to create a framework that would allow vendors to provide off-the-shelf components known as beans. These components could be purchased separately and assembled together using graphical tools. However, this concept proved unsuccessful and its specification ceased development after the release of version 1.01. However, there are strange rules about using the set and getting prefixes in names. For some reason, they have become commonplace. The more interesting side of this framework was the mechanism of interaction of components using events, but unfortunately, it did not gain such popularity.
Apart from the naming conventions for setters and getters, the JavaBeans specification can be considered dead. We do not see much benefit in following rules that have lost their original purpose. We prefer to name methods in code according to the traditional object-oriented idea, according to which methods are associated with actions in a domain: for example, an object may have a method to handle the messages it receives.
We gradually move from elementary objects that have only the necessary attributes to more complex conditions, possibly with additional attributes. It will be inconvenient to pass all this to the constructor as arguments. You’ve probably already had to deal with constructors consisting of 20 parameters. In addition, it is difficult for the designer to comply with all the conditions that apply to several attributes at once.
The Builder design pattern is required for reliable creation of the most complex entities. But before getting acquainted with it, let’s consider another interesting way of creating objects with mandatory and additional fields, which helps to make the code on the client side readable. It is about smooth interfaces.
Creating complex entities with many constraints requires a more powerful tool. We’ll talk about the Builder design pattern in a moment, but to make it easier for you to understand, let’s look at a design style that makes client code easier to read and correct. It’s about a smooth interface.
The name for this style was proposed in 2005 by Eric Evans and Martin Fowler, although it traces its roots to the Smalltalk community of the 1970s. A free interface was created so that the code can be read as if it were natural language text, and this is often achieved through unification techniques.
To illustrate this style, let’s put it into practice and show how it affects the code needed to prepare the entity. Listing 6.3 shows the Account class adapted to provide a free interface. The constructor remains the same, but note the methods for additional fields – credit limit and reserve account. These methods return a reference to the modified instance of the object itself. In AccountService.openAccount you can see how this allows client code to call methods in a chain so that the code can be read almost like plain text.


When using fluid interfaces, the code certainly does not look like what we are used to: it is easier to read. But this style has its drawbacks. Most importantly, it violates a variation of the Command-Query Separation (CQS) principle, which requires that a method be either a command or a query.
It is usually interpreted as follows: the command should change the state without returning anything, and the request should return the response without changing anything. In the free interface example, the with* methods change the state but do not use void as the return type. This may not be the most serious violation, but it is definitely not worth ignoring.
Free interfaces are good in situations when you want to specify the object at the time of its creation, step by step (first the credit limit, then the reserve account). However, after each step, the object must remain consistent. Liquids alone are not sufficient to enforce complex restrictions. By itself, this approach does not support constraints that span multiple properties at once, for example, if an object must have either a credit limit or a reserve account, but not both. In such situations, we will use free interfaces in combination with the Builder pattern. But first, let’s look at what complex constraints might look like.

Complex constraints imposed on an entity can apply to multiple attributes at the same time. If one attribute has a certain value, the other is restricted in some way. Changing the first attribute affects the constraints of the second. Such non-trivial constraints often take the form of invariants or properties that must remain true throughout the object’s life cycle. Invariants must be observed from the moment of creation and during all changes in the state of the object[1].
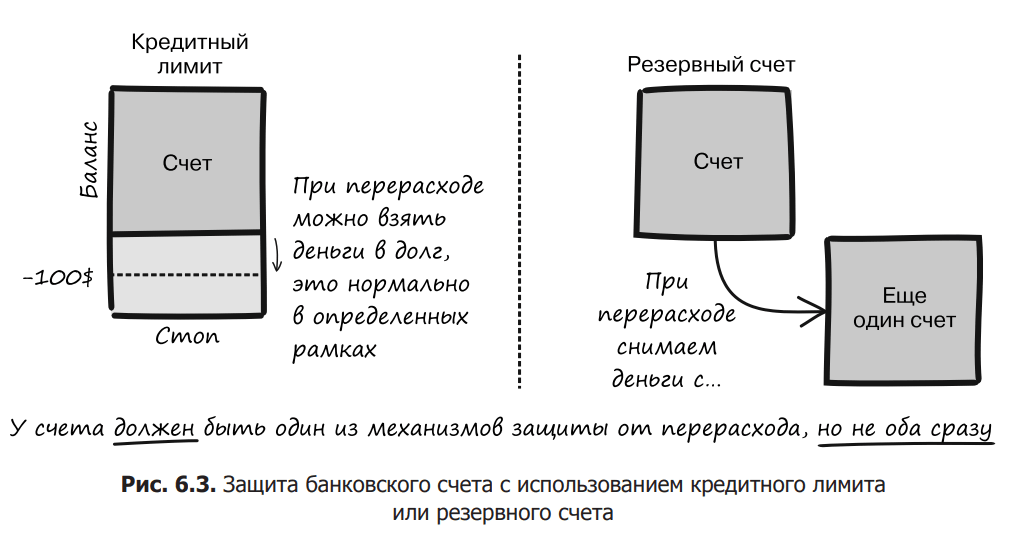
In the bank account example, there are two optional attributes: credit limit and reserve account. Both of these can be part of a complex constraint. Consider the situation when the object must possess one of these attributes, but not both at once (Fig. 6.3).
As a diligent programmer, you should never allow invariants to be violated in an object. We prefer to collect all such invariants into a specific method that can be called if we want to make sure that the object is in a consistent state. Specifically, it is called at the end of any public method before returning control to the caller. Listing 6.4 has a checkInvariants method that contains these checks. It ensures that either the credit limit or the reserve account is established, but not both at the same time. If this condition is not met, Validate.validState throws an IllegalStateException.

There is no need to call this method from outside Account, since, from the perspective of an external observer, objects of this class should always be consistent. But why need a method that tests something that should always be true? Note the small point in the previous statement: invariants must always be observed from the perspective of external code.
After the method returns control to the caller outside the object, all invariants must be fulfilled. However, during the operation of the method, areas may arise where the invariants are not satisfied. For example, when switching from a credit limit to a reserve account, there may be a short period of time during which the credit limit has already been withdrawn and the reserve account has not yet been established. This point is illustrated in Listing 6.5: after creditLimit is reset, but before backbackAccount is set, the Account object does not enforce its invariants. But since the processing is not yet complete, the invariants are not violated. The method still has a chance to correct the situation before returning control to the subscriber.

Combining the check method with a free interface greatly simplifies the code. However, in some situations this is not enough. The main tool in solving this problem is the “Builder” design template, which will be discussed in the next section.
You already know that to create an object in a consistent state, you just need to add all its mandatory fields to the constructor, and initialize the optional fields using setters. But if the restrictions apply to several optional attributes, this will not help.
Let’s look again at an example where a bank account must have either a credit limit or a reserve account, but not both. We would like to create the object incrementally, but in such a way that all constraints are satisfied before it is accessed by other code. This is exactly what the Builder template does.
The main idea of this pattern is to encapsulate the complex procedure of creating an entity inside another object, the constructor. In fig. Figure 6.4 shows how this approach allows you to hide the production of the car until it is fully ready. When the build is complete, the car becomes available.
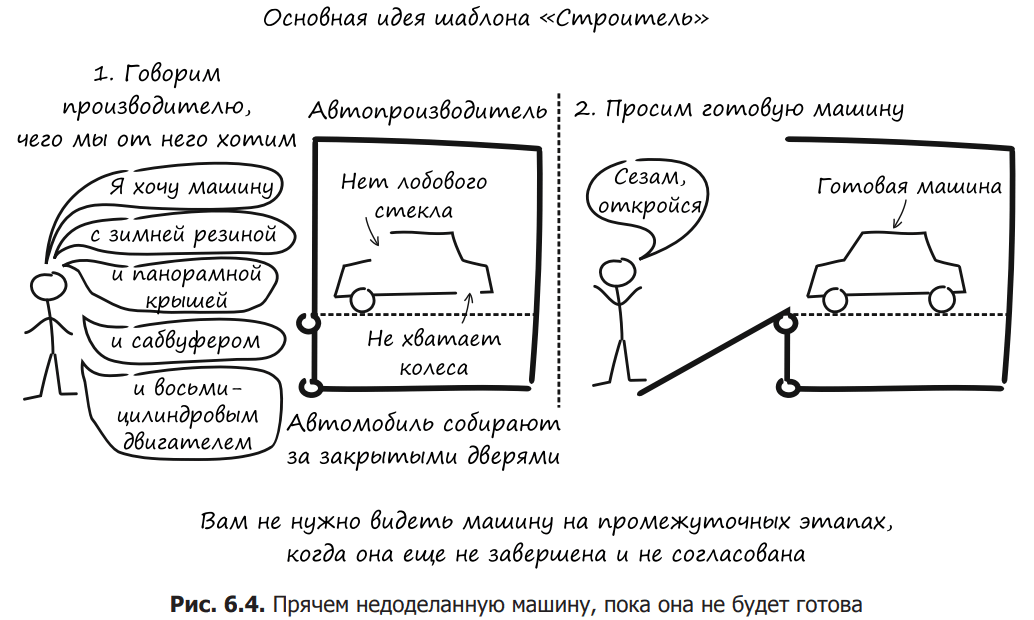
Let’s go back to the bank account example and see how it looks in code. Listing 6.6 shows the client code. First, we create an AccountBuilder object, do some manipulations with it (we ask to create a bank account inside ourselves) and, satisfied with the result, request a ready account in AccountBuilder.

If we need a fallback account, we will call FallbackAccount before the build is complete. This template also handles complex cases well. You just need to do some extra constructor manipulation by configuring the product before calling the build to get the final result. No need for a lot of constructors or overloaded methods. You can make your code even more elegant by providing an AccountBuilder object with a free interface so that the withCreditLimit method returns a reference to the constructor itself:
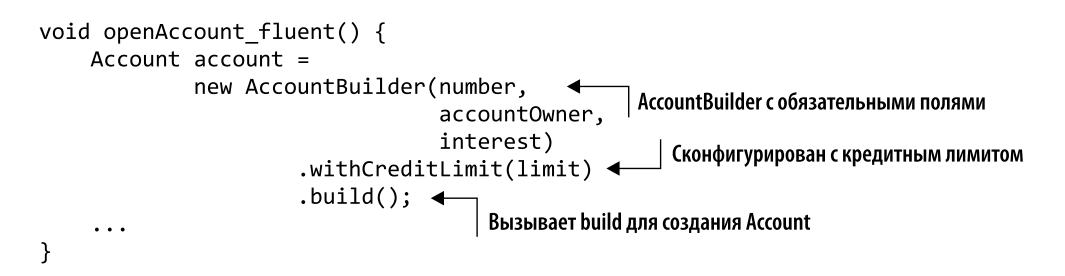
The most difficult part of this design model is the implementation of the builder. AccountBuilder should be able to manipulate the Account object even if it doesn’t match (although this should be avoided at first). But remember: the builder should not leave the product in a contradictory state, as he will no longer be able to work with it from the outside.
A classic solution to this problem is to place both classes (Account and its constructor) in the same module, and then give Account two interfaces: one will be visible to external code, and the other will be able to work with the constructor. It gives results, but sooner or later you will get tired of doing all these steps.
Listing 6.7 shows how to solve this dilemma using Java inner classes. The Builder class is placed inside the Account class and has access to its internal mechanisms without the need to use any special methods. Since Builder is a static class, it can create an incomplete instance of the account using the private constructor and work with it until the external client calls the build method to get the finished Account object.


By making the Account constructor private, we ensure that a bank account can only be created using the Builder class and assembly method. During the creation process, the account object can be conflicted, but that’s okay because only the builder who makes it has access to it. However, at the time of returning the bank account from the developer, all invariants must be satisfied.
When the build() method returns Account to the caller, the constructor must dereference the final result (Account). This is done so that the assembly call does not return another reference to the same instance of the account. After completing the work, the builder self-destructs. Theoretically, from the point of view of object-oriented programming, the concept of inner classes is a little strange, but in this particular situation it turns out to be quite practical.
When dealing with such complex entities as described earlier (with constraints covering various attributes), it is necessary to take care of their relation to the database. ORM frameworks such as JPA and Hibernate allow you to display domain objects directly in the database.
If the domain is small and only one application over which you have full control accesses the database, you can consider the database to be part of a trusted realm. In this case, it can be assumed that the content of the database complies with your business rules and can be safely loaded into the application without validation. This allows you to keep your code simple, but you must also have tight control over your data.
If the subject area is larger or you cannot guarantee that someone else will not gain access to the database, it is recommended that you treat the database as a separate system and verify its contents at boot time. If you directly map your domain entities to a database using an ORM, there may be some nuances. It is possible, but we recommend reading about data storage frameworks.
If you are working with complex constraints, you need to make sure that the invariants are respected after loading the database content. This is what the checkInvariants method is for. It is enough to make sure that it is called at boot time. You can do this by annotating @PostLoad as shown in Listing 6.8. It works in both JPA and Hibernate.

In this chapter, we showed three ways to create entities in a consistent state: designer with required attributes, smooth interface, and template designer. All three have a common goal: to ensure the consistency of an object after its creation, avoiding the dangerous constructor that takes no arguments.
The Builder pattern allows you to break up the build process into many calls, but we recommend keeping the constructor object’s lifecycle as short as possible—this is the main limitation of all three approaches. What is hidden behind the words “as short as possible” in practice depends on the situation, but in web systems we recommend that the creation be completed in the same request or when the response is returned to the client. If the creation procedure is so complex that you need to interact with the client several times, it is better to introduce a separate initialization state inside the entity.
After you create a consistent entity, you must ensure that its state does not change. Its integrity must not be compromised, otherwise its security will depend on the calling code.
Entities created according to all business rules are good. But it will be even better if they continue to follow these rules. One of the advantages of designing entities as objects is that all important business logic can be encapsulated alongside the data. At this stage, you must ensure that this data is not leaked to your customers and that customers cannot change it to bypass business rules. This is what information security professionals call information integrity protection.
If entity data can be changed without their control, you can be sure that sooner or later there will be a bug or a targeted attack that will cause the data to be changed in violation of the rules. In this case, the poor integrity of subjects becomes a security risk. The basic technique for ensuring entity integrity is to never make mutable state accessible from the outside.
Getters and setters
Most developers would agree that a mutable public data field is a bad idea that is almost taboo to discuss. But to our surprise, many developers provide free access to their fields with an unlimited number of getters and setters. Perhaps from an aesthetic point of view, this approach seems more elegant, but in terms of security it is no better. Let’s understand what the dangers of using getters and setters are.
In Listing 6.9, the paid attribute belonging to the order has the form of a private field. But it can be manipulated from the outside as if it were not protected, since it has an unlimited setter and getter.
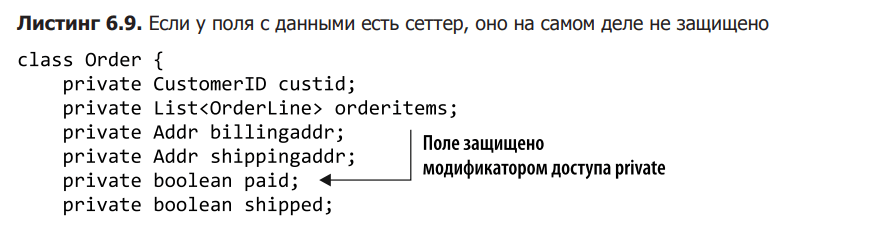
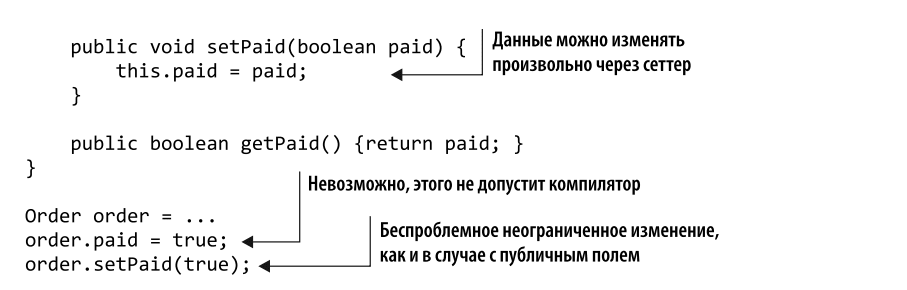
Let’s do some work on this code. We want to protect the payment field from arbitrary changes. A really good first step was to make it private as a logical paid data field in the Order class. But protecting the field itself won’t help if the data is available for arbitrary modifications via the setter. Sometimes setters and getters have special logic that allows for increased security by encapsulating behavior. But Often they provide unlimited access to data fields.
What aspects of behavior make sense to encapsulate? Let’s return to the paid area. Should we allow unlimited changes in its value? Probably not. In this case, you can change it only from false to true and only after receiving the fee. There is no business scenario in which the opposite changes occur.
To make this architectural solution more secure, we can restrict data modification. The obvious way to achieve this is to use setPaid instead, a method designed specifically to mark an order as paid:

Now we can be sure that the paid attribute will only be changed according to business rules. It should be noted that encapsulation consists of combining the data and the rules/interpretations that apply to it, not simply denying direct access to the field.
A business entity must somehow separate its data from its environment. The order entity in Listing 6.9 will sooner or later have to provide a shipping address. The safest way to do this is to isolate the domain primitives, since they are immutable (this was explained in Chapter 5).
Allocating a mutable object carries the risk that a reference to it will be used to change the state it represents. In Listing 6.10, the Person.name attribute is represented by an immutable string, and the Person.title attribute is a modified StringBuffer field. Although similar code is used to access them, there is a fundamental difference between them. When using the immutable name attribute, the Person object preserves its integrity. However, the title attribute that you change allows you to inadvertently change the view that the Person uses to store its state. This violates the integrity of the Person object.

Precisely because mutable objects can be changed in data fields, we recommend instead to use immutable domain primitives not only for fields, but also for arguments and return types.
If for some reason you have to work with the object you’re modifying, one trick you can use is to clone the encapsulated object before returning a reference from the method. This way, your modified object will not be modified by someone else. If external code uses the returned reference, it will only modify the copy of the object, not the original. Listing 6.11 shows how this technique can be applied to java.util.Date.

In most cases, it is not that difficult to avoid splitting mutable objects, as many modern libraries provide good immutable classes. However, there is one exception that often causes problems: collections.
Even if a class is well-designed and doesn’t miss mutable objects, there is one problem area—sets, such as lists or sets. For example, an order object in an online bookstore can contain a list of order items, each element of which describes the purchased book and the number of copies. This list is stored as a List<OrderLine> orderItems data field. Such collections have several nuances that we would like to draw your attention to.
First, this list should clearly not be accessible from the outside. If the OrderItems field is public, anyone can insert their list into it. You also cannot use setters like void setOrderItems(List<OrderLine> orderItems) which do the same thing. Instead of exporting the collection to the outside, allowing clients to work with the list, you need to encapsulate what happens inside the entity.
For example, adding items to a list requires a void addOrderItem(OrderLine orderItem) method. If you need to know the total number of products in the order, you should not return the list to the client so that he can calculate the amount himself – the calculations must be performed inside the nrItems() method. Figuratively speaking, an entity should attract functionality and absorb computation. This will significantly improve the consistency and integrity of business rules over time Data. You may not need to share the list at all, since all operations on it are now inside the entity.
If the external code really needs to work with the list of ordered products, this list must be provided somehow – for example, using a button
List<OrderItem> orderItems(). But this brings us back to a familiar problem. The list is a mutable object, and nothing prevents the client from getting a link to it and changing its content by adding new products or removing existing ones. Listing 6.12 shows the empty addFreeShipping(Order) method that works directly with the list of ordered items.

In this example, the orderItems method returns a reference to the list that stores the ordered items. The client changes the list directly, and the Order object cannot control the changes. Such situations are quite common, and this is a clear security hole.
To protect this architectural decision, you need to ensure that the data returned by the entity is an immutable copy. For data fields that have primitive types, this is not difficult to do. In the previous example, the isPaid() boolean method returned a copy of the boolean value stored in the field. The receiving party can do whatever they want with it without affecting the Order in any way. Protecting the List<Order_Item> orderItems() field, care should be taken to ensure that the returned copy cannot be used to modify the internal list. A list can be cloned just like we did with Date, but in the case of collections you should use a special trick based on a read-only proxy object.
For cloning collections, so-called copy constructors are usually used instead of the clone method. Each class in the Java collection library has a constructor that takes another collection as an argument and creates a copy of it. Listing 6.13 shows how this works with the orderItems method, which returns a copy of the list of ordered items.
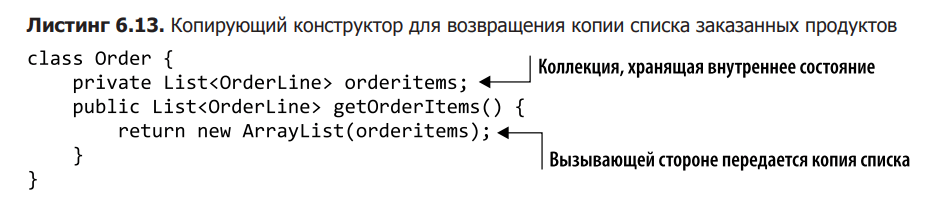
The code that calls orderItems gets a copy of the collection, and any changes are made to it, not to the list inside the order. The downside to this approach is that the calling code can still work with the list and think it’s changing state. This can lead to software errors that are difficult to detect. But, as already mentioned, there is one interesting technique for working with collections.
The Collections utility class contains many useful static methods, one of which is: static <T> List<T> unmodifiableList(List<? extends T> list)
Listing 6.14 illustrates its use. This method returns a read-only proxy object for working with the source list. Any attempt to call the change method from this object will throw an UnsupportedOperationException.

We want to warn you: even though the list cannot be changed from the outside, it cannot be considered immutable. The list of order items can still be modified inside the Order object – for example, we can add a new item to it. This approach prevents customers from making changes, but does not make the list immutable. Either way, by copying the product list or returning an immutable proxy object, you’ve ensured the integrity of the list. It cannot be changed externally, accidentally or intentionally, and that’s what we wanted to achieve when we made the data field private.
With this, we protected the contents of the list, which consists of references to objects. External code cannot delete existing links or add new ones. Now you need to make sure that it is impossible to change the objects themselves. The best way to do this is to make the list items immutable, as described earlier in this section.
The online metal store stored the price of each item sold in the list. This list itself could not be changed from the outside. But its elements were not protected. A customer can add 100 kg of copper wire to the cart at $9 per kg by following the standard procedure. But then he could change the price by $0.01 per 1 kg. The integrity of the list will not help if you do not ensure the integrity of its elements.
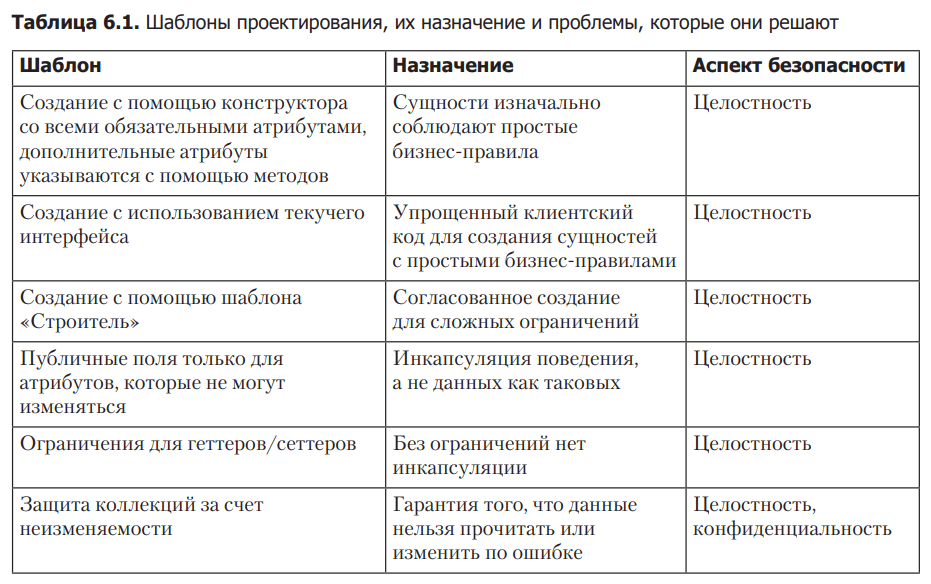
This chapter focused on safely representing mutable state using entities. In particular, we have detailed the important aspects of how to create business entities in a state that complies with business restrictions, and how to maintain their integrity and consistency. Layout templates familiar here are listed in the table. 6.1.
To work with changing states, you should use entities.
Entities must be consistent at creation time.
Constructors that take no arguments are dangerous.
You can use the Builder template to create entities with complex constraints.
You must ensure the integrity of attributes when accessing them.
A private data field with unlimited getters and setters is nothing without a more dangerous public field.
You should avoid splitting variable objects and use domain primitives instead.
Access should not be opened to the entire collection, but to some of its useful qualities.
Collections can be protected by providing access to immutable versions of them.
You must ensure that the data in the collection cannot be changed externally.
We used materials from the book “Security by design”, which was written by Dan Berg Johnson, Daniel Deoghan, Daniel Savano.





