
05.09.2023
32 min
1469

In this book, the topic of security is considered from an unusual angle. Instead of using the classic approach where security is the focus, we decided to make software design the main topic. This may sound a bit strange at first, but given that vulnerabilities are often caused by bad architecture, discussing security from a design perspective is much more appealing. What if a significant number of vulnerabilities could be avoided by applying good design practices and good practices? This would radically change our views on software development and would become a reason for choosing certain architectural solutions. Thus, exploring how software design relates to security is the main goal of the book.

This means that you will not find here a discussion of such classic security aspects as buffer overflows, the shortcomings of cryptographic hash functions, or the choice of an appropriate authentication method. Instead, you’ll learn why certain architectural decisions are important from a security perspective and how they can be used to build software with deep security In the first part, we’ll set the context for the book. You will learn how we approach software security, development and the relationship between them. We will analyze where problems usually occur and what can be done about it. These aspects and examples of what we mean by reliable software will be discussed in the first part. In this section. Security as an integral property of the system. Design and its role in ensuring safety. Improved security through good architecture. Defense against the Billion Laughs attack.
Imagine starting work on a typical software project. You assemble a team of developers, testers and specialized specialists and begin to formulate key requirements. In consultation with stakeholders, we outlined a list of important parameters: performance, security, maintainability and ease of use. As with many software projects, quality is the first priority, time to market is critical, and you need to stay within your budget. You decide to be proactive and add security tasks to your to-do list, and some members of your team choose security libraries to use in the project code. After the initial planning, you take on the implementation of tasks and business functions. The team is motivated and produces results at a good pace.
You understand that you always need to take care of security, but it prevents you from focusing on other tasks. Also, you’re still spending most of your time on code that isn’t called directly over the web, so the web security libraries you planned to use aren’t quite right. At the same time, security-related tasks are becoming less important than business functions. After all, time is running out, and if you fail to implement the features that users want, system security won’t matter. Business functions generate revenue and no user will thank you for adding CSRF tokens to the login form. In addition, lower priority tasks can always be postponed until later.
As a developer, the responsibility for security seems like a burden you’d rather be rid of. Do you believe that the company should hire security specialists and make them an integral part of the development team. Developers specialize in writing good code, building scalable architectures, and using continuous delivery, not magic spells that can protect against evil hackers in black hoodies. You have never understood the mystery that security creates and have always preferred to create rather than destroy. The project must move forward, so you focus on the highest priorities and the implementation of new opportunities.
After some time, your software is ready for release. The future of the project can develop in different ways. For example, you can conduct a security audit and a penetration test. The final report will show that there are some serious vulnerabilities that need to be fixed before the code can be deployed in an industrial environment. This drags you out for weeks or even months, ultimately resulting in lost revenue. If you are unlucky, you will have to rewrite the entire program from scratch to solve the problems, and as a result, stakeholders will decide to shut down your project.
There is also the possibility that security testing will never be performed and you will deploy the application in an industrial environment. Users will start using your service and everything will be fine until one day you read in the news that your service has been hacked and all the data has been leaked. Users whose trust you won with such difficulty will start to leave your service faster than rats – a sinking ship.
Penetration tests are performed to identify potential security holes in a system.
Why do security-related tasks always get a lower priority?
Why are developers generally not interested in security?
Experts never tire of reminding developers about security, so why isn’t everyone doing it?
Why don’t managers understand that their team needs security experts as much as testers?
Authors of books and experts have long been talking about the need to pay more attention to security. But, unfortunately, we regularly see news about the hacking of various systems. Something is clearly wrong here.
IMPORTANTLY. To build secure software efficiently and easily, you may need to change the way you think.
But what if there was another approach to software security that would avoid many of the problems we see in our industry today? We believe that in order to effectively and easily develop secure applications, you need a mindset that may not be comfortable for you, and that focuses not on security, but rather on design.
It may seem counterintuitive at first, but in this chapter you’ll learn what we mean by design and why it’s so important to security. We will discuss some of the shortcomings of the traditional approach to software security and show how to overcome them at the architectural level. We’ll also provide some examples of how these ideas are applied in real-world settings to familiarize you with some of the concepts covered in the following chapters.
Security should be seen as an aspect of the system, not just another function. However, it is not uncommon for security to be described as a set of features. The difference with this approach is that, even if these features help to solve certain security issues, it does not mean that the product as a whole is secure. To illustrate this, let’s start with a historical example. Consider one of the earliest known bank robberies and show that security features like good locks are useless if the door has weak hinges. In this example, the security measures in place did not prevent the robbery, so the security requirements were not met.
It was May 25, 1854, the night shortly before the robbery of the Swedish Ost-Gotha bank. A corporal and ex-farmer named Nils Strid and his companion, a blacksmith, Lars Ekström, walk silently towards the bank. The front door of the bank branch is locked, but the key hangs outside on a nail – you just need to know where to look.
The bank’s management also spent money on high-quality vault locks that are virtually impossible to break. But it is not difficult for the blacksmith to pull out the hinges and open the storage door from the other side. These two criminals managed to steal everything stored in the bank – 900,000 riksdaler (the official Swedish currency at the time). This amount is difficult to compare with modern money, but its equivalent is somewhere between 5 and 10 million dollars.
For years, it was one of the biggest heists in history. A similar amount was stolen only in 1963, during the robbery of a train on the Bridgow Bridge railway bridge in Buckinghamshire, England. In Sweden, the robbers left behind a three-riksdaler note and a note with a funny rhyming poem:

In addition to being an interesting historical event, this robbery is also interesting from a security point of view, both in a legal and a technical sense. The legal aspect is that it has led to the adoption of new laws that dictate a certain degree of protection for banks. These laws have forced financial institutions to pay attention to security and follow certain guidelines. The first of them, adopted in 1855, was one of the earliest examples of regulation in the field of security. From a technical point of view, the robbers took advantage of the bank’s weaknesses: the door of the branch was locked, but the key was not well hidden, the vault had good locks, but the door hinges could be torn out.
This story is a vivid example of the organization of security in the form of a set of functions – locks and hinges. High-quality locks gave a sense of security, but in themselves did not provide any security. A good lock is not enough if the key hangs on a nail or if the door to the storage room is fastened on weak hinges. Instead of considering security as a set of individual elements, it is better to consider it as an integral property of the system.
If management considered security to be an inalienable property of its institution, it would ask the question: “How to prevent people from withdrawing money from the bank?”. And the answer won’t just be a lock – security measures will include storing the key elsewhere or checking for other ways to break the vault door. The owners of the bank could come up with something new, for example, an alarm system. They could invent the robbery prevention mechanisms that appeared in the next century, but they would not rely on a single door lock.
Now let’s step back from the nineteenth century into the modern world of software development and see how these different approaches to security relate to your current projects. In the next section, we’ll show you how to stop looking at security as a separate element and start looking at it as an intrinsic property of the system.
Software is often described as a set of features, that is, what can be done with a particular product. For example: this is a program that allows you to share shopping lists; it’s a site where you can upload photos so other people can view and comment on them; This is a program for creating presentations. This kind of description is also used in formal contexts.
Many methodologies focus on what the system should do, that is, on the functional side. The Rational Unified Process (RUP) continues to have a major impact on software development and focuses on functionality in the form of use cases. Other considerations, such as response time or required power, fall into the secondary category of additional specifications. In the agile community, the dominant format for describing what needs to be done in the next sprint (or equivalent) is a user story that goes something like this: “I, user so-and-so, want such-and-such an opportunity to get such-and-such benefit.” . With this emphasis on capabilities (what the system does), it’s no surprise that security is often described along these lines: we need a login page, we need a fraud detection module, we need logging.
Security experts John Willander and Jens Gustavsson conducted research on how people describe and define security. They selected the main program initiatives financed from the budget. It was found that in 78% of cases, security was directly related to capabilities.
Of course, some security features have benefits, both visible and hidden. An example of visible benefits is a quality authentication mechanism that allows customers to be sure that their access and communication are protected. But the problem is that when we describe security as a set of functions, we often forget the main thing. Let’s try to rephrase the user story related to security so that security becomes an integral property of the system.
Imagine a photo storage site with an authentication mechanism. If you try to squeeze this mechanism into the user’s functional history format, it goes something like this: “As a user, I need a login page that will allow me to access uploaded photos.”
Although security is described as an opportunity, most stakeholders are concerned about it in general. If you implement only this functionality, you can achieve the goal set in the history of the login page. However, having a login page alone does not provide the necessary security. The fact that no one really wants such a page may seem obvious, But feature-oriented user stories have happened many times.
Imagine you and your team are creating a login page. After authentication, the user is redirected to their photos, which include a very awkward pose.jpg. The user can click on the link to download the image. Let’s complicate the situation and imagine that another user has a direct link to this photo (Fig. 1.1). How do you like it? You’ve implemented your plan since you have a login page with the functionality described, but you missed something important, didn’t you?
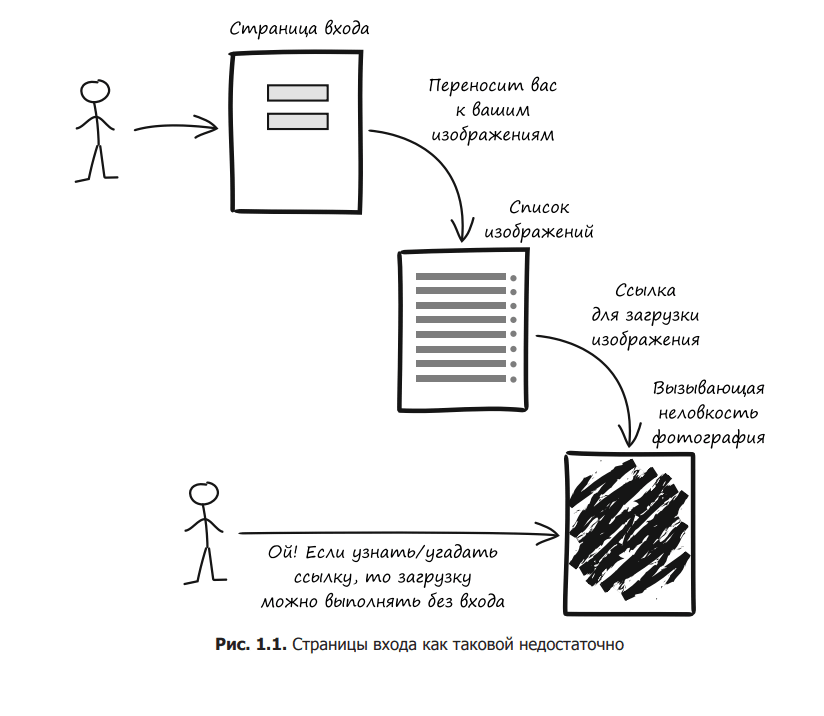
Looking back, we realize that the goal was not the login page per se. The goal was that only the owner could view and download the image and no one else. A login page is only required to comply with this rule. The user should not be able to get the image bypassing this page.
Now you can rephrase your wish as follows: “As a user, I want my images to be accessible through the login page, and for these images to remain private.” This wording reflects concerns that stakeholders initially expressed about the login page.
It’s better not to mention the login page at all: “As a user, I want access to all my uploaded images to be authenticated and the images to remain private.”
The meaning of the user’s desire was not to have an element of security, but to satisfy a certain requirement – in this case privacy (hidden storage). When implementing this story, it was important to understand that changing code that only applies to one way of accessing images is not enough. All access paths must be secured, miss just one and the requirement will not be met.
To get real security, you need to stop thinking of it as a set of possibilities. Security should be seen as a requirement that covers different functions.
We have already mentioned privacy as an aspect of security. But security is not only about hiding things from prying eyes. In this book we will talk about other aspects. To begin with, let’s list the terms related to security issues.
In classic information security, there are usually three main requirements: confidentiality, integrity, availability (CIA).
Privacy. Most commonly mentioned when discussing security and hiding things that should be public. One example of sensitive information is your medical record.
Integrity. Means that in cases where it is important, the information should not be changed, or the changes should be made in certain approved ways. An example of integrity is the counting of voting results. Security in this context provides protection against manipulation. with voices
Accessibility. This means that data must always be at hand and access to it must be provided in a timely manner. Firefighters need to know what’s on fire, and they need that information immediately. If they receive it late, it may be too late and the security requirement will not be met.
For any piece of data, all three factors can be important, but most often their violation has different consequences. Take, for example, a medical card. Disclosing your medical history (breach of privacy) will make you feel irritated or even angry. If there are errors in the data (violation of integrity), it can be dangerous for your health. If you are in an ambulance and do not have a medical card (violation of accessibility), the consequences can be fatal.
Or take your bank records. It’s annoying if you can’t find your balance (availability) when you pay your bills. If the balance became known to outsiders (privacy), this is a reason for anger. But if your retirement savings suddenly evaporate (integrity), that’s a disaster.
Later, these three factors were joined by one more: traceability (T) is the need to know who accessed or changed the data and when. After some scandals in the financial sector and health care, this has become an important issue. This type of audit is an integral part of the European Union regulation called the General Data Protection Regulation (GDPR), which came into force in 2018. For example, according to the GDPR, access to personal data must be monitored and stored in a permanent audit log. We will use the terms “confidentiality,” “integrity,” “availability,” and “traceability” throughout the pages of this book to explain what kind of security we are talking about.
Taking care of security, rather than its individual elements, greatly improves the quality of the system, but at the same time puts developers in a difficult position: how to ensure security in the software you write? It is not easy to make sure that there are no errors. For this, developers must constantly take care of security. But there is another way to do this, and that is to incorporate security into the workflow and design process.
Writing software is far from a trivial task. A developer must have skills in a wide range of areas. You are expected to have expertise in a variety of areas, from programming languages and algorithms to system architecture and agile methodologies. These disciplines permeate different areas of knowledge and can be markedly different from each other, but when discussing them, the same term is constantly mentioned – “design”. What meaning do we attach to this word?
We believe that the term “design” is generally used quite loosely and can mean different things depending on who and what you’re talking about. In our opinion, design is an extremely important concept in software development. Therefore, it is quite logical to start with your own definition of design, which will be applied in the future. Understanding this will help you navigate the discussions and concepts presented here.
When developing software, you constantly have to make decisions about what code to write to solve existing problems. You choose syntax, constructs, and algorithms, structure your code, and determine the direction of execution. If you are using an object-oriented approach, you will need to decide what you want your object model to look like and how its elements will interact with each other. If you use the functional programming style,
You need to determine what behaviors should be passed as functions and make sure they are clean, without side effects. All these decisions can be considered part of the design.
While writing the code, a lot of attention is paid to how the business logic will be presented – the functionality that makes the software unique. You will think carefully about how to implement this logic and how to make its maintenance transparent and easy. If your responsibilities have anything to do with domain modeling, you’ll spend a lot of time developing and optimizing your model, as well as planning how it should be expressed in code. Even if the implemented logic is no more complex than a regular conditional expression, you still need to make an informed decision. For example, you can consider aspects such as readability or performance and, depending on your preferences, choose how the expression will appear in code. Based on your experience and knowledge, you consciously make decisions that are appropriate for the software you create. Such decision-making can be considered as part of the design process.
As your code base evolves, you break your code into packages or modules to make it clearer and easier to use, while still getting desired features like consistency and loose coupling. You can use such techniques and concepts as interfaces, dependency inversion, and immutability, while trying not to violate the principle of Liskov’s substitution. You can also try extracting and isolating some functionality to make it more visual or to make it easier to test. In this way, you write code and perform refactoring—a redesign that results in improvements to your application.
If your code interacts with other software (for example, you’re developing a service in a microservice architecture), you’ll need to think about how to define your service’s public API so that it works seamlessly, is easy to use, and supports version control. You should also pay attention to how to ensure its stability and responsiveness when interacting with other services and how to achieve acceptable uptime. At a higher level, it is probably necessary to take into account the fact that the service must fit into the general architecture of the system. All the different decisions you make are part of one whole – your software design process. All the activities described earlier are related to coding.
We said that they are all part of the design process, but if you think about it, which ones are related to design and which ones are not?
Are API planning and system architecture analysis typical examples of design?
Can modeling of the subject area be considered design?
Is the choice between whether or not to use the final keyword in the declaration of an object’s field a matter of design?
If you ask ten people what software development activities are considered design, you will likely get ten different answers. Many will probably cite domain modeling, API planning, applying design patterns, and system architecture as obvious examples, in part because this is a more traditional view of what design is. Few would say that the software design process is serious Thinking about how to write an if statement or a for loop.
So what is considered part of the design process? The answer is simple: everything related to development. A system or software component as a result of design can be called stable (that is, functioning, and this does not mean that it stops developing) only after its implementation and deployment in real conditions. In other words, domain models, modules, APIs, and design patterns are just as important in design as field and method declarations, if statements, and hash tables. All this affects the stability of the final product.
All these aspects of development have something in common: they require conscious decision-making. Any activity related to informed decision-making is part of the software development process. This, in turn, means that design acts as a guiding principle on which a system is built, and it can be applied at all levels, from code to architecture.
In this chapter, you learned how software design should be viewed and what we mean by it in this book. Next, we will talk about the traditional approach to software security and some of its shortcomings.
Observing what is happening in the software development world, we have realized that many people come to the following conclusion: to avoid vulnerabilities, security should be given the highest priority when writing code. Anyone involved in this process must be properly trained and experienced in software security. Let’s call this view the traditional approach to software security. As a rule, it includes certain tasks and actions that must be performed by developers (Fig. 1.2).
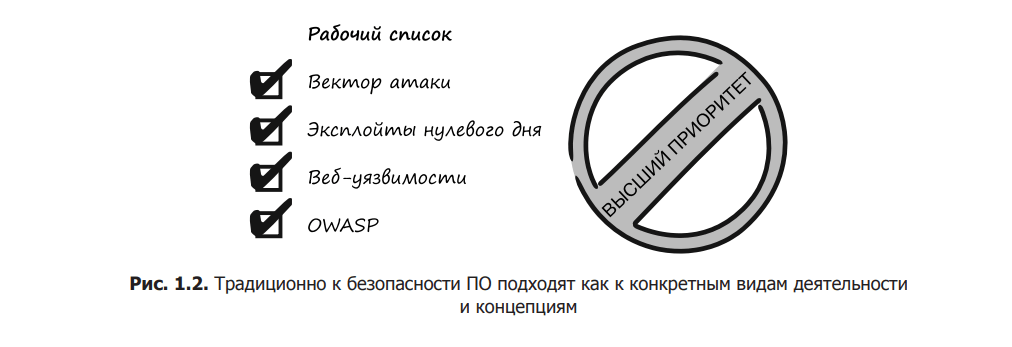
Developers should be familiar with cross-site scripting (XSS), understand low-level protocol vulnerabilities, and know the OWASP list of security risks[1] by heart. Testers should be familiar with basic penetration testing techniques and domain experts should be able to discuss relevant issues and make decisions about software security.
The downside of this approach is that, for a number of reasons, it makes it easy to build software that is secure enough to withstand the harsh realities of industrial environments. If it was successful, vulnerabilities would be less common and we wouldn’t have to deal with huge security holes caused by the same vulnerability over and over again. Let’s take a closer look at some of the weaknesses of this approach to better understand why it doesn’t produce the desired results and why we believe it has a better alternative.
Imagine you have a simple domain object that represents a user in a typical web application, and the user’s name is displayed on the page. This is a fairly simple object that only contains an ID and a username. But, despite this simplification, our experience shows that such objects can often be found in the code. The implementation is shown in Listing 1.1.
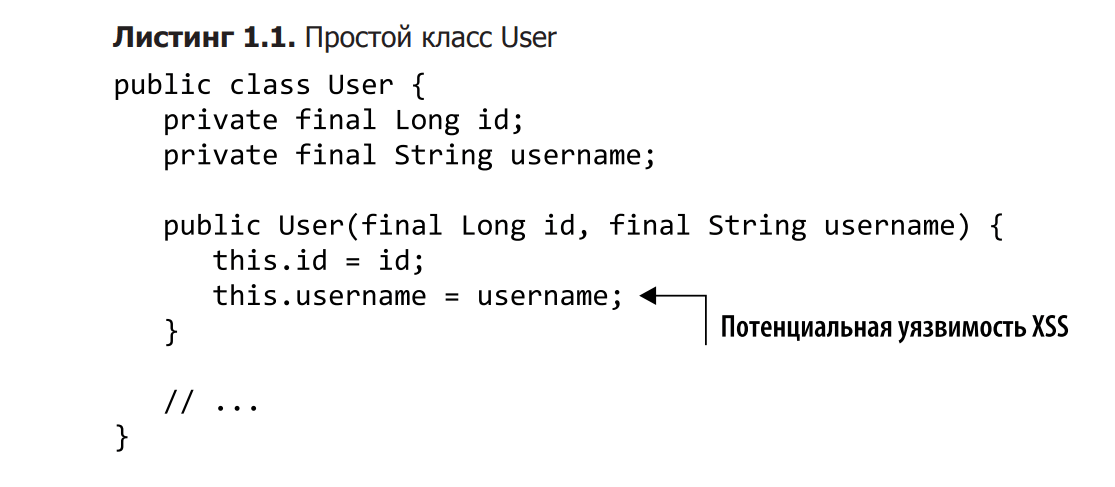
If you look at this user view, you can see potential security issues. For example, any string value is accepted as a username, making XSS attacks possible. An XSS attack occurs when an attacker uses a web application to send malicious code to another user. This code, for example, can be in the form of a client script in JavaScript. If an attacker enters something like <script>alert(42);</script> as a login when signing up to a service, the browser may display a window with the number 42 as the username later when that name is displayed on some web page. program page
To mitigate this vulnerability using the traditional approach, you can add explicit security-oriented input validation. Data validation, for example, can be implemented in the form of filters that analyze the data of all forms in a web application and make sure that it does not contain malicious XSS code. But the same thing could be done directly in the domains class. If you prefer to validate the input in the User class, see Listing 1.2 for what this might look like.
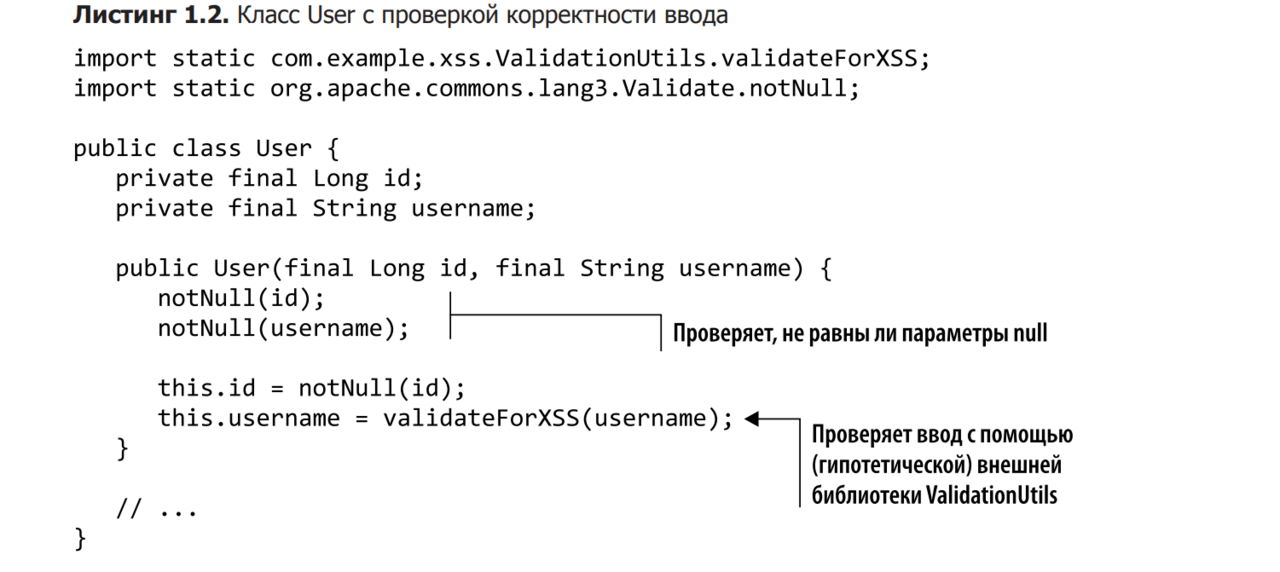
In this listing, you can see how we include a hypothetical security library that allows you to check strings for possible XSS attacks. We also decided to make sure that none of the constructor parameters are null to make the validation even better.
This method of protecting software is widely used, but it has several problems, including the following:
The developer has to directly deal with the vulnerability and at the same time focus on solving business problems.
Every developer should be a security professional.
The person writing the code is supposed to be able to foresee any vulnerabilities that may appear now and in the future.
Let’s analyze each of these points and see what is wrong with them.
The first problem is that we are singularly focused on security. When a developer writes code, his main focus is always on the functionality he is trying to implement. If he also has to take care of security, it can distract him from his main duties. In the event of such a conflict, security always comes second. There are several reasons for this, which we will talk about in detail in subsection 1.4.2.
The next challenge is that every developer should be a security professional, but not everyone has the ability or desire to specialize in this area, just as not everyone can be an expert in JVM performance or user experience. And if developers are not very security aware, the software they create will reflect their level of knowledge and skill.
In the future, developers may need a deep knowledge of software security, just as the ability to write good unit tests is more or less a must these days. But the current state of our industry is such that such expectations are somewhat unrealistic.
Even if your software is written by a team of security experts, you still need to accept the fact that creating countermeasures is only possible for those vulnerabilities that you already know about. However, you must have a deep understanding of not only the vast number of attack vectors that you are familiar with, but also the vulnerabilities that no one knows about. You have to grasp the incomprehensible, so to speak. Once you understand this dilemma, it will become clear to you that it creates additional difficulties when writing secure software.
The “safety first” approach has been around since time immemorial, and we’ve all used it. Sometimes it was successful, but often we felt that something was missing and there had to be another, better way to build secure apps. We believe that design contributes to the success of writing truly secure code. And by focusing on design, you can avoid many of the shortcomings of the approach we’ve covered in this chapter.
We do not claim that security is important and that you should keep it in mind when developing software. However, we believe that instead of using a traditional approach to security, we can turn to an alternative that gives the same or even better results when it comes to what the finished project will look like (Figure 1.3).
Instead of making security one of the most important elements of development, you can focus on design, striving for the highest standards. By shifting the focus to design, you can achieve a high degree of security without constantly thinking about it.
Let’s go back to the User class example in the previous section and see how we might approach its design-focused implementation. First, you need to ask your domain experts about the meaning of the username in the context of the current application (Figure 1.4).
After discussing this issue, you come to the conclusion that the username should contain only the characters [A-Za-z0-9_-] and consist of 4-40 characters. This is dictated by what is considered a common username in the application being created. You exclude the < and > characters because they can be part of an XSS attack if the username is displayed in a browser. Rather, In this example, you decided that the < and > characters could not be part of a valid name, so you excluded them.
A little research with domain experts allowed us to gain a deeper understanding of the current context and, as a result, develop a more accurate username definition. Listing 1.3 shows the new User class.
Listing 1.3. User class with domain restrictions.

Now, when you look at the User class, you see a lot of logic related to the username. This fact, along with the fact that you had to discuss the username in considerable detail with domain experts, is an indication that the username should be explicitly represented in the domain model. This is partly due to the importance of this concept, but it is equally important that the extraction of logic occurs according to the principle of high coherence.
With that in mind, you can put the logic in a separate Username class that encapsulates all of your username knowledge. A new class applies all domain rules at creation. This new object is called a domain primitive (or domain primitive, more about it in Chapter 5). Listing 1.4 shows how the User class will look when the code is moved to the new Username class.
Code listing 1.4. A user class with a domain value object.

By focusing on the design, you were able to learn more details about the user and their name. This made it possible to create a more accurate domain model. You also notice that the concepts of the current model have become so important that they need to be moved to separate objects. As a result, you gain a deeper understanding of your domain while protecting yourself from the XSS vulnerabilities we discussed earlier: <script>alert(42);</script> can no longer be entered because it is an invalid username. And you haven’t even thought about security yet! With some thought, the restrictions on usernames could probably be made even tighter, but design will remain at the fore.
NOTE. A clear focus on design allows you to write more secure code than a traditional approach to software security.
So, we got to know the shortcomings of the traditional approach and saw how to apply design to create secure software. Some of the concepts covered in this chapter will be covered in detail in Chapter 3. It will introduce the basic concepts of domain design that are relevant to this book. Then, in Chapters 4 and 5, we describe the fundamental programming constructs that help achieve security. Now let’s take a look at the benefits of security by design and explain why we believe this approach provides better results than the traditional approach to software security.
Using a simple User class as an example, it was shown how design can improve the security of the development process. We also noted that by focusing on design, it is possible to achieve a level of software security that equals, and sometimes exceeds, the traditional approach. But on what basis can it be said that this approach is better than the traditional one?
We believe that if the main focus of development is on design, security can be transformed from an imposed requirement to a natural aspect of the process. We are also convinced that it allows not only to overcome or avoid many disadvantages of the traditional approach, but also to obtain certain advantages.
The main reasons for this are as follows.
Software design is the main thing that interests developers, it is the basis of their skills. This makes it easy to implement the concept of safety by design.
By focusing on design, business and security issues will have equal priority in the eyes of both developers and subject matter experts.
By choosing appropriate design concepts, non-security professionals can write secure code.
Focusing on a subject area can automatically eliminate many security issues.
Let’s discuss the rationale behind these benefits in more detail. In the next section, you’ll learn why we believe design-driven development is better than a traditional approach.
Design is a natural aspect of software development
Software developers are taught from day one that good design is essential. Creating a well-designed app that does the job is something to be proud of. This makes design a natural aspect of software development.
Many developers find it difficult to understand all the details of complex vulnerabilities, so they consider themselves non-security professionals. Security is not their prerogative. However, most developers understand and value design, and if it can be used to ensure security, then it turns out that anyone can create secure software.
If you focus on design, security starts to concern everyone around you, not just specialists. This approach eliminates the conflict between business functions and security issues, as they merge into a single entity. This reduces the cognitive load on the developer and allows you to avoid one of the disadvantages of the traditional approach.
Business and security issues are given equal priority
One of the disadvantages of the traditional approach is that security is considered a separate activity. As a result, security starts to conflict with other important aspects that you are trying to devote time to, such as business functions, scalability, testability, maintainability, etc. Security-related tasks are added to the overall task list and prioritized for the rest of the required functionality.
In the prioritization process, there is no indication that security should occupy a special place among other tasks. On the contrary, it is often observed that security does not receive the attention it deserves.
There are several reasons for that.
Both developers and business professionals have a poor understanding of security.
For the reasons discussed earlier, developers often feel that security is not their business.
Even if you are well versed in security, it is very easy to neglect it in favor of functionality, treating it as if it can be put off for later.
The idea of introducing security not immediately, but after some time, has one nuance: this idea may turn out to be unrealistic if the necessary aspects of security require radical changes in the architecture. This is similar to why it is usually difficult or impossible to delay the adoption of scalability or abandon public storage.
By focusing on design and domain knowledge (as in the previous example with the User class), you have avoided several situations where security should have taken precedence over other planned tasks. Now you don’t have to choose between security features and business capabilities. You simply implement features specific to your domain.
Finally, we note that the emphasis on design makes security more accessible not only to specialists, but also to other interested parties. This is a result of the fact that you find it easier to discuss the challenges you face, see the value they bring, and prioritize them if those challenges are related to your subject area rather than specific vulnerabilities.
Another interesting benefit of a design-based approach to security is that anyone can write secure code without much effort. And it’s not that they analyze attack vectors and think about how malicious data can affect the system, rather, dangerous concepts just don’t make it into the architecture. To illustrate this, consider the Username class from Listing 1.4, whose invariants ensure that only valid usernames are accepted.
Is it justified to use this complex type instead of a regular string?
When communicating with specialized experts, most developers recognize the importance of presenting business concepts as accurately as possible. Username is not just an arbitrary sequence of any characters, it is a clearly defined concept with a certain meaning and role in the subject area. Presenting it in the form of a standard String class will be not only bad, but also a completely wrong design decision. And understanding this automatically prompts the developer to choose accurate and correct implementations, regardless of their experience or interest in security.
Domain focus automatically avoids security holes
Security issues are considered scary and difficult, but when you put design first, the complexity suddenly disappears. This is mainly due to the fact that the line between common software defects and security bugs is blurred, if you pay attention to the subject area, and not to the choice of countermeasures.
If you look at the username in Listing 1.4, the main purpose of invariants is not to protect the username from malicious injection, but to pass the valid value of the username. As a result, any malicious input that doesn’t meet this definition is rejected, and the username becomes safe because of the focus on the domain, not because we took care of security. This reduces the risk of security bugs in your code, and in some cases can protect you from holes in third-party products.
As mentioned earlier, adding a more traditional and focused security concern to your design focus will make your code even more secure. This is an important remark, because increased attention to design, although it provides a high degree of security, but never covers all the security requirements of the system (and this is not the goal of this approach). When creating software, it is always necessary to perform penetration testing and active analysis of specific attack vectors and vulnerabilities. Even if focusing on the domain made the username example safe, you still need to do the correct output encoding when it’s displayed on a web page. By focusing on design while taking a universal approach to security, you can create truly secure products.
We have covered quite a lot of material, but it seems to us that before explaining how all this is implemented, it is necessary to understand why. You learned what design is and the basic principles behind the idea that increased attention to design issues can help you develop secure software. You have also seen a simple example of how it works. In the next section, we will look at a slightly more complex Case, which will once again illustrate improving security by design.
When developing software, you often have to make decisions about how data will be presented. Unfortunately, over-generalized data types are usually preferred. For example, representing a phone number as a string may seem convenient at first, but from a security point of view it is a disaster, since a string can contain almost any data, not just what we expect. But developers still prefer strings, and as Listing 1.5 shows, typo protection is often provided only at the variable name level. The register method accepts a phone number, but its argument is of type String, which means it can be anything!

Naturally, this will not help prevent incorrect input. The solution is to use strict domain types with rules, as shown earlier in the User and Username example. But strict types are only half the battle.
If you look at Username, you’ll notice that the logic in the constructor includes notBlank and length checks that are performed before applying the regular expression. This is extremely important from a security perspective, and we’ll explain why in Chapter 4.
In the meantime, just keep in mind that the checks must be done in this order.
Length check. Is the input length within the expected range?
Lexical content check. Does it contain the correct input characters and is it properly encoded?
Syntax check. Is the input format correct?
So far we’ve only looked at simple checks, but that doesn’t mean they can’t be used in more complex situations. To illustrate this, let’s look at an example that will allow you to learn how to safely handle XML. At first glance, it has little in common with the previous examples, but you will see that the same principles allow parsing to be reduced to ordinary input validation. Let’s take a look at XML processing.
XML (Extensible Markup Language) is similar to a string in that it can represent almost any type of data. Due to this, it is often used for intermediate presentation of data during interaction between systems. Unfortunately, few people guess that the normalization of data presentation is far from the only application of XML.
Essentially, XML is a full-fledged language based on SGML (Standard Generalized Markup Language). This means that XML has many features that most developers are not interested in. As a result, using this format introduces many security risks to the software. Let’s illustrate this with the example of the “Billion Laughs” attack, which uses the extensibility of XML entities in the parsing phase. This will serve as a foundation for learning about safe recycling
XML. But before we get into the details, let’s remember how internal XML entities work.
Internal XML entities are important constructs that allow you to create simple abbreviations in XML. They are defined in the Document Type Definition (DTD) section and are written as <!ENTITY name “value”>.
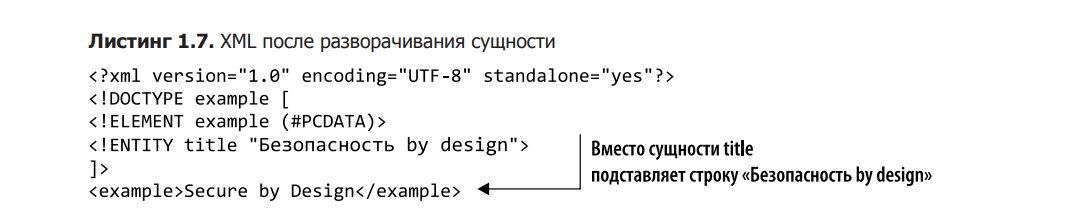
Listing 1.6 shows a simple example of an entity that stands for this book.

When the parser encounters a title entity, it expands the abbreviation and substitutes the value specified in the DTD. The result is an extended XML block without abbreviations.
This is shown in Listing 1.7.
The ability to deploy entities is quite useful, but unfortunately it can be used for attacks. Let’s see how the Billion Laughter attack exploits it.
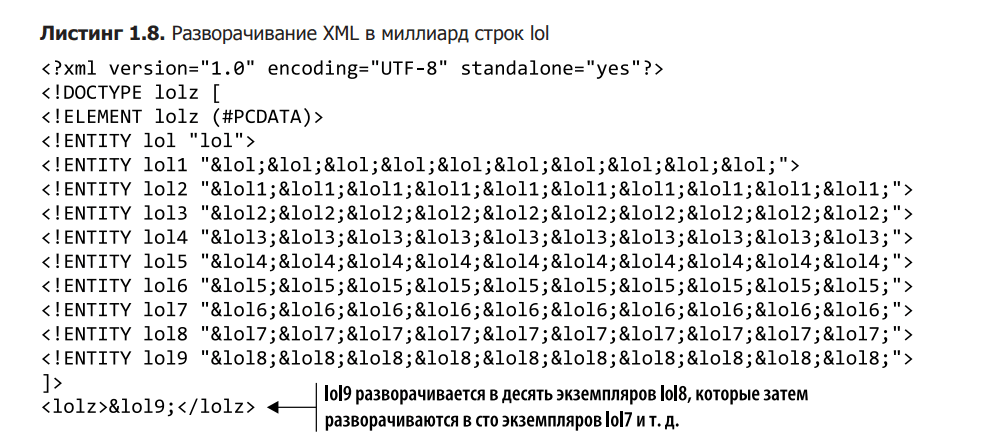
The simplicity of the Billion Laughter attack is matched only by its effectiveness. The basic idea is to exploit the extensibility of XML entities by creating a recursive definition that takes a huge amount of memory as a result of expansion. Listing 1.8 shows an example of an attack based on a small block of XML that is less than 1 KB. Because of this, it passes most validation checks that analyze size or length. When the parser loads the XML document, lol9 expands to ten lol8 instances, which are then expanded to a hundred lol7 instances, and so on, resulting in a billion lines of lol occupying several gigabytes of memory.
Obviously, entities don’t behave as we expect them to, but the very fact that they are part of the XML language makes any parser vulnerable to this kind of attack. Our experience shows that the best defense against this problem is a combination of proper parser configuration and lexical content validation. First, let’s configure the XML parser.
So that the entities do not unfold, you need to understand which parameters depend on how they behave during analysis. And without understanding the internal structure of the analyzer, this becomes a surprisingly difficult task, since each analyzer behaves differently. External resources such as OWASP can be consulted to understand this.
Listing 1.9 shows an example of a parser configuration that, following OWASP guidelines, tries to avoid entity expansion. Quite aggressive options are chosen here, since almost everything related to entities is disabled. For example, disallowing the use of doctype makes entity attacks more difficult, but at the same time affects the overall usability of XML. In these situations, security concerns are often pitted against business needs, and if you decide to relax the configuration, you need to understand the risks involved.

Changing the parser configuration is the recommended approach, but it feels very risky. For example, what if the internal implementation of the analyzer changes or you forget about some parameter? These fears are justified, so it is recommended to use an additional level of security – design.
It seems to us that before approaching the problem of “Billion Laughs” from a design point of view, it is necessary to abandon the idea that the root cause lies in the mechanism of essence expansion. The fact is that this function is in accordance with the XML specification and is not the result of a careful implementation of the parser. It follows that we are not dealing with a structural problem with the XML format, but rather with a receiver-side input validation problem. This in turn means that a malicious XML block, such as Billion Laughs code, must be rejected by the host system before it can even be parsed. It sounds tempting, but is such a solution practical? We confidently answer: yes. Remember the second item in the list, which determines the order of the verification stages – performing lexical analysis. At first glance, this may seem like a complicated operation, but it’s actually not that difficult. This is just the process of converting a stream of symbols into a sequence of tokens without analyzing their meaning and order (this is the task of the analyzer).
Lexical content analysis can be implemented in various ways. Listing 1.10 shows an example of parsing XML using the Simple API for XML (SAX). Using a parser for lexical analysis may seem counterintuitive, but the SAX tool works well for this because it generates an event when a token is detected in the data stream. These events can then be used for content parsing (if we’re interested in synsing) or, as in this case, rejecting an XML document with entities. To achieve this, when an entity is found, the startEntity method of the ElementHandler class immediately throws an exception and aborts the analysis.
Listing 1.10. A simple lexical analyzer for finding XML entities


The result meets our expectations, but the main purpose of lexical analysis is not only to reject entities. This process must also ensure that the XML document has all the necessary elements, otherwise there is no point in parsing it. To illustrate this, imagine that we have a customer object in XML format, with exactly one phone number, one email address, and one home address, as shown in Listing 1.11. Phone number and home address are required, email address is not. It makes sense to start parsing this XML document only if it contains all the necessary elements. Any other combination of elements will be incorrect from the point of view of business requirements and should be rejected by the lexer. This is similar to how we rejected invalid input in the username example.

In order for the XML document to contain all the necessary elements, we need a more advanced ElementHandler class. But before going into details, it should be remembered that lexical analysis allows you to learn only about the existence of elements, but not about their meaning, order of placement or duplication. Therefore, there is a risk that an invalid client XML block will pass lexical validation (for example, with multiple phone numbers or home addresses). And while this looks like a bug, this behavior is exactly what we expect. The fact is that lexical checks combined with semantic checks inevitably turn into parsing, bringing us back to where we started.
With that in mind, let’s look at the updated version of ElementHandler in Listing 1.12. This implementation has several interesting points that are worth paying attention to. First of all, every time the startElement method fires, it checks against a collection that holds all the required elements. It looks quite simple, but there is one subtle nuance that is easy to overlook. For lexical parsing, only the presence of elements matters, so we need a mechanism to ensure that all required elements are present in the XML document in at least one instance. To do this, each detected element is removed from the mentioned collection. And it doesn’t matter if this element is mandatory, the main thing is that it will no longer be in the assembly. After parsing the data stream to the end, the parser must make sure that all the necessary elements are found, for this it checks in the endDocument method whether the collection is not empty.

The second nuance worth mentioning is choosing a liberal search strategy that ignores any optional elements. This may appear to be a potential defect since the customer’s XML block does not meet the parser’s requirements, but this is a conscious decision. According to Postel’s law and the Tolerant Reader design pattern, when systems interact with each other, the implementation of receiving data should be liberal, and the implementation of sending data should be liberal. conservative. This avoids some difficulties in system integration, as the receiving party ignores changes in the data fields. As a result, by ignoring all optional elements, we made lexical analysis robust to minor data changes, such as updating an additional element in the client’s XML block.
This certainly complicates the implementation of the Billion Laughs XML block, but what if entities are required? Would this make lexical analysis useless? Or maybe there is a way to accept subjects that protects against extension attacks? Indeed, there is such a way, but to find out what it is, you need to approach the problem from the other side.
Parser parsing and configuration combat extension attacks by blindly rejecting XML blocks with entities, regardless of whether they are malicious. This approach has a drawback: it only works in situations where XML entities are invalid. In all other cases, a different solution is required. So let’s take another look at the Billion Laughs XML block and try to figure out where the real danger lies.
The main problem is the extension of entities, but that does not in itself make entities unsafe to parse. The real problem is consuming a lot of memory. This means that XML parsing itself is not dangerous – the problem is the size of the final XML document. As a practical solution, we can allow entity expansion but limit the parsing process (eg using memory limits or quotas) to prevent excessive resource consumption.
However, choosing this approach does not automatically protect against resource exhaustion. Even if a single parsing process consumes memory within acceptable limits (because it will be forcibly terminated when the limits are exceeded), the parallel execution of several such processes can cause a situation similar to the “Billion Laughs” attack. Let’s imagine, for example, that parsing processes run in parallel and each of them consumes the maximum amount of resources. At the same time, the total number of occupied resources will be directly proportional to the number of processes, which will significantly load the system. Thus, any part of the system that needs the same resources (such as CPU or memory) will be affected. This suggests an architecture in which parsing is done in isolation, as this reduces the risk of cascading failures. We will discuss this in more detail when discussing the partition design pattern in Chapter 9.
Imposing operational constraints seems like a viable solution, but using lexical analysis and reconfiguring the parser still makes sense. In fact, choosing an architecture that includes all strategies makes the system even more resistant to extension attacks, which brings us to the next topic of deep security.
Most developers would prefer to combat an entity expansion attack with configuration alone. In itself, this decision is not wrong, but it is like building a fence around a house in which the door is not locked. The house remains safe until someone breaks through the fence. This is extremely undesirable. The obvious solution is to lock the door and there is an option to install an alarm inside. This is what security in depth means. Multiple layers of protection make a successful attack much more difficult, even if an attacker manages to bypass one of them.
To better illustrate the implementation of the security-in-depth principle, let’s compare the architecture aimed at protecting the Billion Laughs XML block with a house. After configuring the parser, we built a secure fence around the house. Sometimes, unless you can reject all entity types, this defense is too strong. In such situations, it is better not to get rid of the entire fence at once, but to try to understand what type of entity we need. You can relax the configuration to allow only entities of certain types (for example, only internal entities). This is not an ideal solution, but it allows you to keep the fence around the house.
Parsing ensures that the XML document received by the parser contains the required elements. It’s like we only let people in the house who have a key. As a result, the set of XML blocks that require parsing is significantly reduced — only those that meet business requirements will be parsed. This makes it very difficult to maliciously exploit the parser, as the attack vector is now limited to the XML blocks containing the required elements. What about entities? What if we need to take them?
This is what the last level of protection is for. If you apply operational constraints to the parsing process, you can relax the lexical parsing and pass the entities to the XML parser—it’s like opening a window on the second floor. Operational constraints ensure that the analysis process never takes up too many resources – like a watchdog in a house.
In general, using parser configurations, lexical analysis, and operational constraints, an extension attack can be made much more difficult. This is what security by design is all about: applying architectural decisions as a core tool and mindset to create secure software. In the next section, we will take a closer look at a real-world example that will show how a fragile architecture and lack of domain understanding caused significant financial losses to a large global company and how this could have been avoided using secure design principles.
Security is best viewed as a set of requirements to be met rather than a set of capabilities to be implemented.
It is impractical to make security a top priority. Instead, it is better to find design methods that allow you to make the safest decisions.
Any activity that involves conscious decision-making should be considered part of the software design process.
Design is a guiding principle that defines the device of the system and the methods of its application at all levels, from code to architecture.
The traditional approach to software security does not always produce good results because it requires the developer implementing the business functions to think specifically about vulnerabilities. In this case, every developer should be a security specialist. This assumes that the person writing the code is able to foresee any potential vulnerability that may arise now or in the future.
By focusing your attention on design, you can achieve a high degree of security without having to think about it all the time.
By emphasizing design, you can create more secure code compared to a traditional approach to software security.
Any XML parser is vulnerable to entity attacks because entities are part of the XML language.
Using generic types to represent specific data allows potential security holes to appear.
Choosing an XML parser configuration requires understanding its internal implementation.
Ensuring security by design helps create deep, multi-layered protection.
We used materials from the book “Security by design” written by Dan Berg Johnson, Daniel Deoghan, Daniel Savano.





