
04.09.2023
48 min
1976

Most programmers agree that testing should be an integral part of the development process to avoid possible errors after the code is written. Methodologies such as test-driven development (TDD) and behavioral design (BDD) have become the standard, where a large number of tests are performed during each development phase. Surprisingly, this approach is often only applied to non-security tests, perhaps because security is not always a priority. However, we consider this to be illogical. Security tests are as important as others and should be done regularly. This does not mean that you need to perform penetration testing every time you make changes to your code.

A different approach to thinking is needed here. Security measures should be naturally integrated into the code delivery process and applied at every change, and this will be the subject of our section. Each section of this chapter, although independent, will be permeated by a common theme: how to integrate various security tests into the code delivery process. Unlike previous topics, this may require targeted security planning. However, by applying it to your day-to-day work, you will gain a better understanding of the security of your software before it goes into production. Before going into these aspects in more detail, let’s define what the code delivery process is.
A code delivery process (or pipeline) is an automated mechanism for deploying software to a production (or any other) environment. This may seem like a complicated thing, but in fact it is quite the opposite. Imagine you have the following delivery process.
Make sure all files have been committed to Git.
Build the app from the master branch.
Run all unit tests and make sure they pass.
Run all application tests and make sure they pass.
Run all integration tests and make sure they pass.
Run all system tests and make sure they pass.
Run all accessibility tests and make sure they pass.
Deploy to a production environment (if all previous steps have been successfully completed).
The first two steps are to include all the files in the build and make sure the code compiles. Phases 3 through 7 test various aspects of quality, and the last phase is deployed in a production environment (if all the previous ones have been successfully completed). Regardless of how this process is performed, manually or automatically, its main task is to prevent software defects from entering the deployed system.
If you choose to use a build server, you have an automated version of this process, the code delivery pipeline (see Figure 8.1).
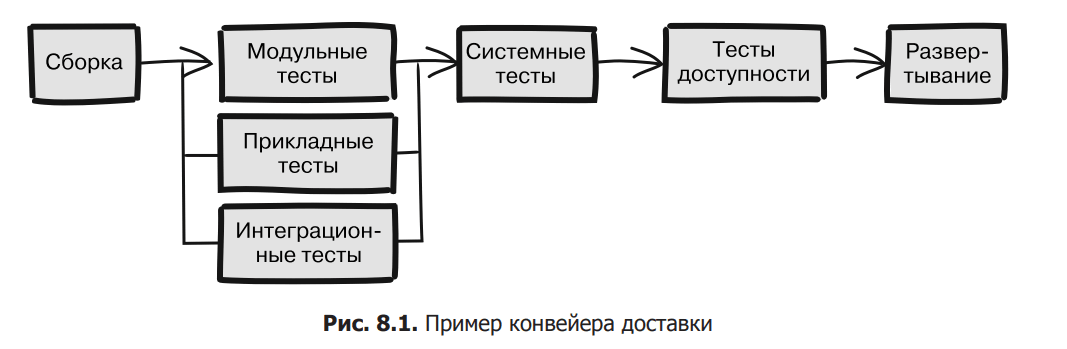
As shown in the figure, the unit, application, and integration tests are executed in parallel, while the rest of the steps are executed sequentially. Automating this process is optional, but allows you to simplify the transition between different stages. It would be interesting to discuss how best to implement it, but we are primarily interested in the reasons why this process should be automated.
Using a delivery pipeline ensures a consistent process—no one can purposefully skip a step or bypass the process of deploying code to a production or other environment. This ensures that security is constantly reviewed during development. Incorporating security tests into your pipeline will give you instant feedback and insight into how secure your software is. This dramatically improves code quality, so let’s look at how to ensure design-level security with unit tests.
When you provide security at the design level with unit tests, you need to look at things a little differently than we’re used to. TDD helps you focus on the functionality of your code, not on what it shouldn’t do. This is a good but unfortunately half-baked strategy. If you only care about what your code is supposed to do, it’s easy to forget that unplanned behavior is often a security weakness.
Imagine that you expect to receive a phone number as input. But if it is implemented as a string, its definition will be much broader than the definition of a phone number. As a result, you will automatically accept any string input. This is a security weakness that makes an injection-based attack possible. Thus, there is a need for an alternative testing strategy that covers not only what the code should do, but also what it should not do.
To check objects, we recommend using four different types of tests (Table 8.1). This way you can be sure that the code really does what you need and unwanted behavior is excluded.

To give you an idea of how to apply these tests, let’s consider an example in which confidential information about a patient’s medical history is sent by email. Designing and testing such a domain primitive may seem trivial, but the logic and methods involved are universal and applicable to any object you create.
Imagine a hospital with a complex computerized accounting system. This important system includes everything from medical charts to prescriptions to X-rays and handles thousands of transactions every day. Doctors and nurses use it in their daily work, including when discussing confidential patient information. Communication takes place by e-mail, and in order to ensure the safety of personal data of patients, it is very important not to allow them to be sent to e-mail addresses outside the domain of the hospital.
It is a natural strategy to configure email servers to only accept addresses that are in the correct domain. But what if this configuration changes or is lost when upgrading to a new version? In this case, you will unknowingly start receiving e-mails with invalid addresses – such a security hole can have dire consequences. A smarter solution would be to combine the configuration of the e-mail server with a mechanism for rejecting invalid addresses at the system level. This will provide deep security, which will make the system more resistant to attacks, since the attacker will have to bypass several defense mechanisms at once. But for this you need to understand the rules of working with e-mail addresses inside the hospital.
In Chapter 1, you learned that talking to experts helps you gain a deeper understanding of a subject area. The same applies to the hospital. It turns out that the rules for dealing with e-mail addresses in this context are not at all what you might expect.
The e-mail address specification, RFC 5322, allows a fairly wide range of characters that can be contained in a valid address. Unfortunately, this definition cannot be used in a hospital setting, as several legacy systems limit the set of symbols available, and this must be taken into account. As a result, domain experts decided that a valid postal address can only contain letters, numbers and periods. The total length is limited to 77 characters and the domain name must be hospital.com.
In addition, there are several other requirements.
The format of the e-mail address must be local part@domain.
The length of the local part must not exceed 64 characters.
Subdomains are not allowed.
The minimum length of the postal address is 15 characters.
The maximum length of the postal address is 77 characters.
The local part can only contain alphabetic characters (a – z), numbers (0 – 9) and a single dot.
There cannot be a dot at the beginning and at the end of the local part.
At first, given the loose definition in RFC 5322, you might be tempted to think of an email address as a string. But the requirements of the domain rules say that it is better to create a primitive EmailAddress domain. Unit tests can be used as a starting point for design to ensure compliance with domain rules. Let’s check the normal behavior.
When testing for normal behavior, you should focus on input that clearly conforms to domain rules. For EmailAddress, this means that the input must have a valid length (between 15 and 77 characters), hospital.com as the domain, and a local part consisting of only letters (a to z), numbers, and no more than one period. That way, we can be sure that when we receive normal input, our implementation will work as it should. Listing 8.1 shows an example of how to test for normal behavior.
EmailAddress. The test is executed using JUnit 5, the build process is quite interesting in the sense that it uses a stream of input values (valid mail addresses) bound to a deferred test, a dynamic test. A live test differs from a regular test in that it is determined at runtime rather than at compile time. This gives the ability to dynamically create test cases depending on the parameters entered, as in the following list. In addition, parameterized test construction is often preferred in situations where assumptions need to be validated because input values can be easily added and removed without changing the test logic.

Running this test allows you to start designing the EmailAddress object. According to the rules of the domain, in the local part, only letter characters, numbers and a period are allowed. This makes things a bit more complicated, but Listing 8.2 shows a solution that implements this requirement using a regular expression (regexp). The domain name must be hospital.com, which does not allow any other domains to be accepted.
However, testing for normal behavior is only one step in creating a secure EmailAddress object. You also need to make sure that addresses close to semantic boundaries are handled as we expect. For example, how do you know that addresses longer than 77 characters are rejected or that the address cannot start with a dot? This is the reason to create a new set of tests that will test the behavior of the boundaries.

In Chapter 3, we discussed how important it is to understand the semantic boundaries of a context and how data can automatically change its meaning when crossed. The semantic boundary of a domain object is often a combination of simple structural rules, such as length, size, or number, and complex domain rules. Take, for example, a shopping cart on a web page modeled as an entity. It is allowed to add a certain number of products and change the contents of the basket until the order is placed. But after that, the order becomes unchanged and updates are prohibited. Due to the transition between states, the order crosses the semantic boundary, since open and placed orders have different meanings. This needs to be checked as there are often security issues around these borders.
Let’s go back to EmailAddress and the hospital. It is necessary to make sure that the architecture really meets the boundary conditions described in the domain rules. Fortunately, testing can be made a little easier because these rules don’t require complex transitions between states like in the shopping cart example. All requirements are structural, including length limits and allowed characters. This is quite easy to check. In the table 8.2 lists the boundary conditions that must be checked.
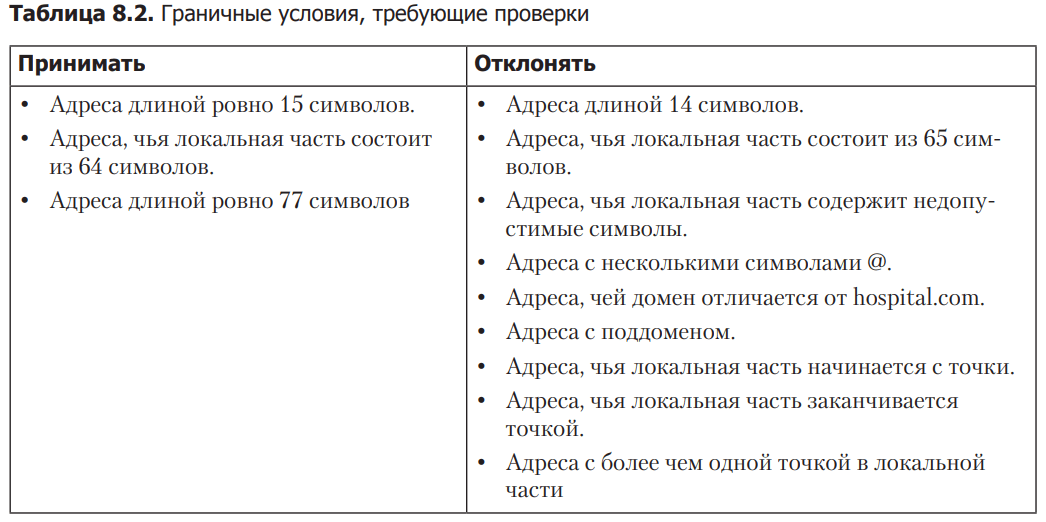
Having this list will allow you to start developing unit tests that test edge behavior on a case-by-case basis. Listing 8.3 shows an example of how this can be implemented using JUnit 5. The first test, should_be_accepted, checks whether an address is accepted if it is part of the hospital.com domain and is between 15 and 77 characters long. The second test, should_be_rejected, is slightly longer and is designed to reject input that is out of scope (for example, it might be too short, too long, contain invalid characters, or have an invalid domain name).

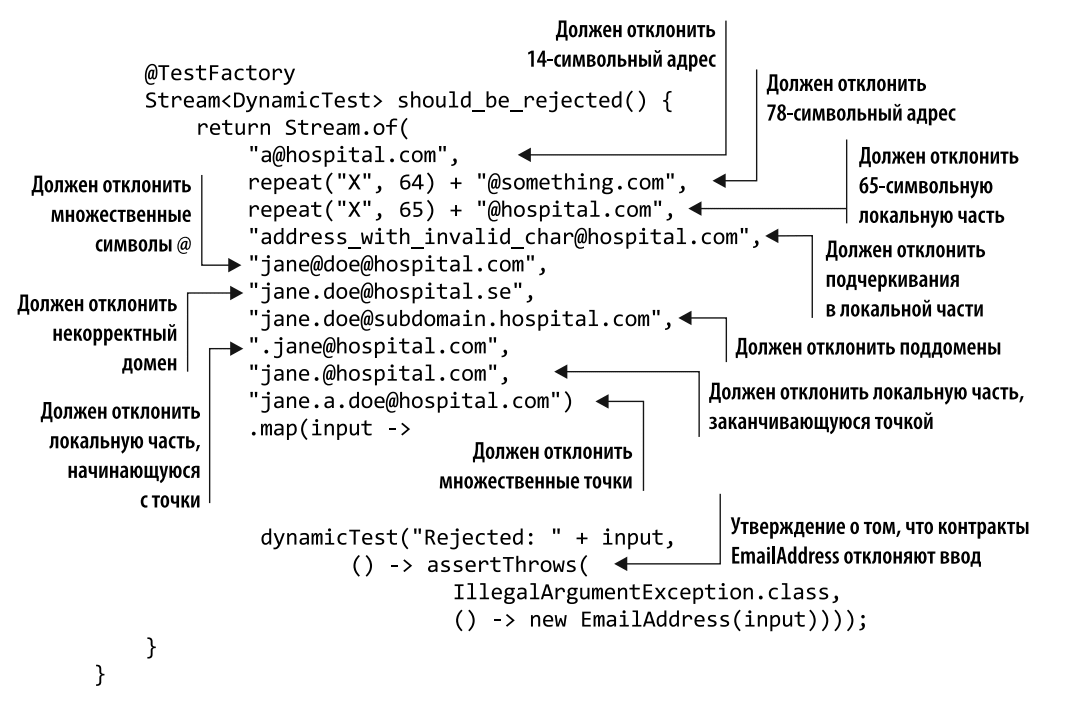
Running this test shows that the implementation of EmailAddress is too weak. Regular expression ^[a z0 9]\+\.? [a z0 9]\+@\bhospital.com$ is a little simplified, with no limit on the length of the local part and the total length of the address.
Listing 8.4 shows an updated version of EmailAddress that checks the length separately before applying the regular expression. As you already know from Chapter 4, you should always perform lexical parsing before processing your input. This can be done directly in the regular expression using a positive forward check, but we intentionally skipped this step because the length check ensures that the parsing is safe regardless of what characters are in the input. However, in more complex situations, the parser should be protected by preliminary lexical parsing.
With the addition of a separate length check, our implementation actually looks robust. Unfortunately, this is where most developers stop testing because the result seems acceptable. But from the point of view of security, this is not enough.
You need to make sure that malicious input cannot break the verification mechanism. For example, the EmailAddress model is highly dependent on how regular expressions are interpreted. That’s fine, but what if there’s a weakness in the regexp module that causes a certain input to fail, or a certain input takes an extremely long time to process? Getting rid of this kind of problem is the purpose of the last two types of tests – Checking for incorrect and extreme input. Let’s see how to do them on the EmailAddress object.

Before designing tests with incorrect input, you need to understand what it is. In general, any login that does not comply with the domain rules may be considered invalid. But from a security point of view, we are also interested in checking the input data, which can cause some damage – immediately or later. For some reason, null values, empty strings, and unusual characters have such an effect on many systems.
Listing 8.5 illustrates how to test EmailAddress using invalid input. The input data is a series of addresses with unusual characters, null values, and data that appears to be correct at first glance. This kind of testing increases the likelihood that your model will actually be resistant to simple injection attacks that exploit weaknesses in the validation logic.

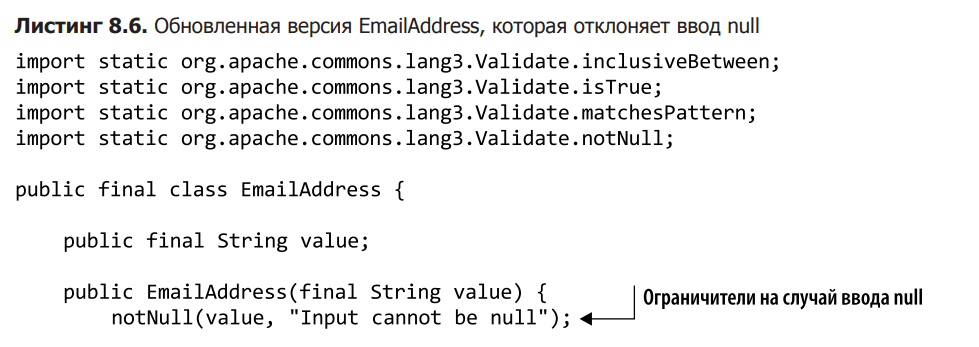
After running the boundary tests, everything looked as if the EmailAddress object was designed quite well. However, testing using invalid input has shown that a null value causes the implementation to fail when value.length() is called. Listing 8.6 presents an updated version of EmailAddress in which null is purposefully rejected by the non-null contract.

Extreme input testing consists of identifying weaknesses in the architecture that cause the program to crash or behave unpredictably when handling extreme values. For example, entering a huge input can degrade performance, cause memory leaks, and other undesirable consequences. Listing 8.7 shows how to test EmailAddress using a provider lambda and input between 10,000 and 40,000,000 million characters. This clearly violates the rules of the domain, but we are not interested in them here, we rather want to see how the verification logic behaves when parsing such input data. Ideally, the input should be rejected, but using an incomplete validation algorithm can lead to all kinds of crazy situations.
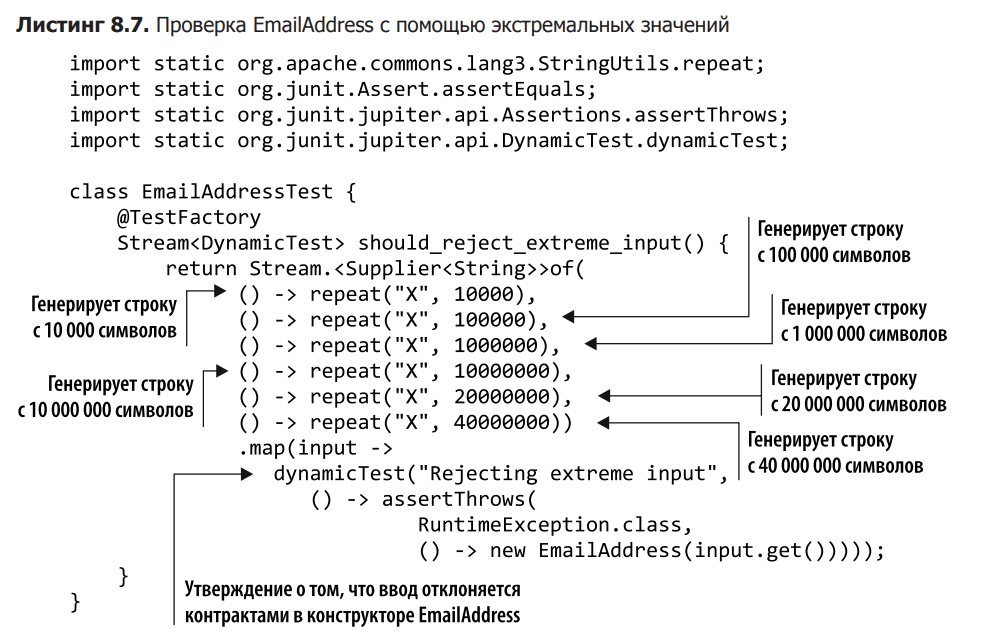
As shown by running tests with extreme input, the EmailAddress model is working properly. The input is actually rejected, but things could have been different. In Chapter 4, we talked about how validation checks are performed and how to check the length of the input before parsing the content. Listing 8.7 is an example of how important this is.
Length checking may seem redundant, but without it, extreme input degrades performance so much that the app almost stops working. The thing is, if the expressions don’t match, the regexp module jumps to the character that precedes the potential substring you’re looking for and starts over. If the input is large, this results in a catastrophic performance penalty due to the huge number of return operations.
This concludes our discussion of the EmailAddress example and how to think about developing secure unit tests. But this is only one of the stages of ensuring security at the design level. Another approach is to keep only the features you want to see in the production environment. And that brings us to the next topic, which is how to test the functionality of switches.
Continuous delivery and deployment are increasingly recognized as best software development practices. As a result, functionality switches are widely used in system development. Feature switching is a technique that allows developers to build and deploy new features at a high pace, safely and in a controlled manner. It’s a useful tool, but it can quickly become complicated if overused. Depending on which functions you switch, errors in the switching mechanism can lead not only to incorrect business behavior, but also to serious security issues (as you will soon see for yourself).
When you use functionality switches, you should understand that they affect the behavior of your application. Behavior, like everything else, needs to be tested with automated tests. This means that you have to test not only the code of the function in your application, but also the switches themselves. Before we get into how this is done, let’s look at an example that clearly shows why this type of validation is important.
Danger of poorly designed circuit breakers
This is the story of a team of experienced developers and an unfortunate incident with feature switches that led to the disclosure of sensitive data in a public API. This could have been avoided if the developers had provided automated tests to check the switches. If you’re not familiar with the concept of function switches, don’t worry—you’ll have a chance to learn about it before we move on to the rest of this section.
Team members worked together for some time, got used to each other properly and released working software at a high pace. The team used many different techniques borrowed from continuous delivery, and the code was written using TDD (test-driven development). In addition to this, they created a large delivery pipeline that ensured that only properly working features reached the production environment.
The team has been working on a number of new features. One of the first steps they did was to add a functionality switch that allowed new features to be turned on and off. This switch was used when running local tests on the developer computer and CI server, as well as when testing a deployed instance of the system in a test environment. The new functionality was delivered via a public API, and in its final form, it had to have appropriate authentication and authorization mechanisms so that only certain users could access the new API endpoints. Authorization had to be based on new access rules that were being developed by another team and had not yet been deployed. But these rules were not mandatory for checking other aspects of business conduct. This allowed the team to continue working while other developers completed their part of the system. In the production configuration, the switch for features that are not yet ready is disabled so that they are not available in the public API. It was to remain disabled until the new functionality was completed and all acceptance tests were completed.
At some stage of development, a switch in the industrial configuration was accidentally turned on. This happened due to a mistake made by one of the team members when merging some changes in the configuration files. The number of switches used in the application gradually increased, and their configuration became quite difficult. It wasn’t easy to find a subtle bug, and it’s one of those mistakes that any of the developers could have made. As a result, the new functionality became available in the public API, but without any authorization mechanisms, as they have not yet been implemented. This made the new endpoints available to almost everyone. Fortunately, the team quickly discovered and fixed the configuration error before anyone could take advantage of the new features in a production environment.
If public endpoints are discovered by an attacker, significant damage can be done to the company. And although this story ended well, we can still make an interesting observation: no one checked whether the switch configuration was working as intended. If the team had automatically checked the behavior of each switch, this incident could have been avoided.
We wanted to share this story with you to give you a real-life example of how feature switching can cause some pretty serious problems if not implemented properly. We are now ready to consider the process of testing functionality switches from a security perspective.
A full study of the topic of switching functionality is beyond the scope of this book. To understand why and how switches should be tested, we think it’s best to start with a brief introduction to the subject. If you are already familiar with function switches, you can use this section to refresh your memory.
According to the principle of operation, switches are functionally similar to an electric switch. They allow you to turn certain features of your software on and off—similar to how we turn a light on or off (Figure 8.2). In addition to turning features on and off, switches can also be used to switch between different features, allowing you to choose different behaviors.
As you work on new features, you can turn them on and off when you need to run tests or deploy your application to a test environment. This gives you full access to new features while they are being developed, while allowing you to disable or deactivate that functionality when the app is deployed in a post-test or production environment. The ability to turn individual features on and off gives you complete control over when they become available to end users.
Another advantage of using feature switches is that they allow you to develop capabilities in the master branch of the version control system, rather than in a separate long-running branch. Many see this as a prerequisite for applying the best aspects of continuous integration and, as a result, continuous delivery (another reason why feature switches are becoming increasingly popular with developers).
There are several types of function switches. Some are used to toggle features that are still in development, while others are used to enable and disable capabilities in industrial environments based on runtime settings such as the time, date, or certain properties of the current user. Switches can also be implemented differently. The simplest procedure is to modify the code to include or exclude certain parts of the codebase, as shown in Listing 8.8.

As you can see, this code switches between the old and new functionality. Old functions are called using the callOldFunctionality method. When they are enabled, you need to disable the new functionality by commenting out the callNewFunctionality method. If you want to use new functions, you should repeat this procedure, but in reverse: comment out the callOldFunctional method and call callNewFunctional as in the usingNewImplementation list.
A more complex switch can be controlled, for example, by the power of the configuration that is provided when the program is launched. Listing 8.9 shows an example where functionality depends on the feature.enabled system property. If you want more dynamic switches, you can control them at runtime as some kind of administration mechanism.

Regardless of what switches you use or what mechanisms the switch is based on, you need to understand that it changes the behavior of the application. After changing the state of the switch, the system behaves differently. Using this approach allows you to create alternative execution paths in it, which, like any other, should be tested with as many automated tests as possible. Since switching features can have negative security implications, it must be done correctly. So, we have considered the basics of the functionality of the switches. Now let’s talk about how you can test them using automated tests.
Functionality switches will inevitably complicate your code. The more switches you add to your app, the more complex it becomes, especially if the switches depend on each other. Try to minimize the number of switches in use at any given time. If there is no such possibility, it remains only to learn to cope with additional difficulties.
Along with the complexity, the probability of error increases. When it comes to security, even a simple mistake can have serious consequences. For example, exposing unfinished functionality in a public API can cause various security issues, ranging from direct financial losses to leaking confidential data.
By developing automated tests that test the performance of each switch and adding them to your delivery pipeline, you insulate yourself against unexpected behavior. Because the tests run automatically and in every build, they also allow regression testing for future changes, avoiding random errors. At the beginning of this chapter, we looked at a situation where a defective code merge caused some API endpoints to become public. This could have been prevented if the developers had provided automated tests that would have prevented new functionality from being included in the industrial environment.
Always try to make the functionality testing of switches automatic rather than manual. Automated tests are the most reliable and predictable way to test the correctness of not only switches, but also any other aspect of code behavior. In some exceptional situations, test automation is too expensive for manual testing. For manual verification, be sure to implement it as a separate step in your delivery pipeline. That way, you’ll remember to test before confirming that your code is ready to deploy to a production environment, because you can’t accidentally skip a step in the pipeline.
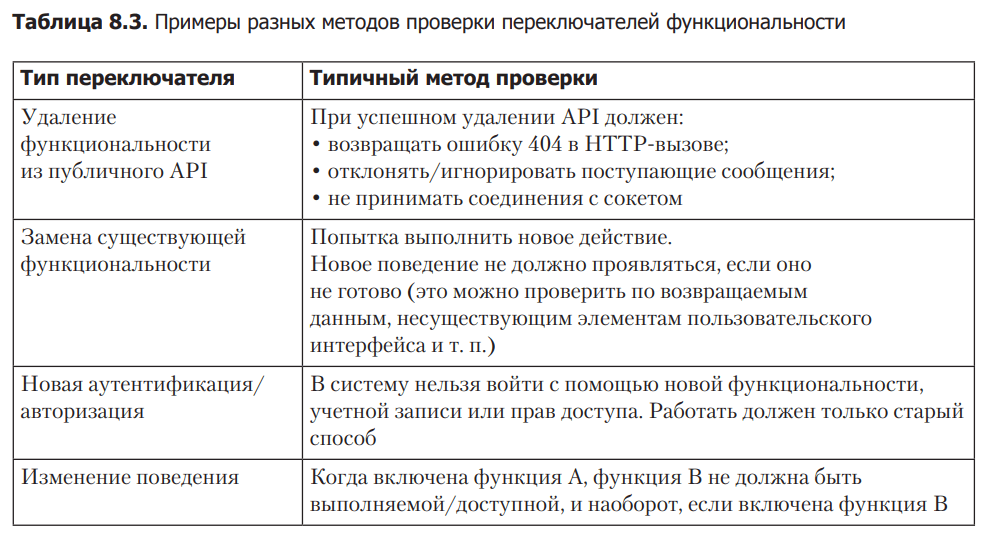
In the table 8.3 shows several examples of how to check the correct operation of different types of switches. These are just basic guidelines, and verification is often not that simple. However, this should give you a general idea of how to test the switch with an automated test.
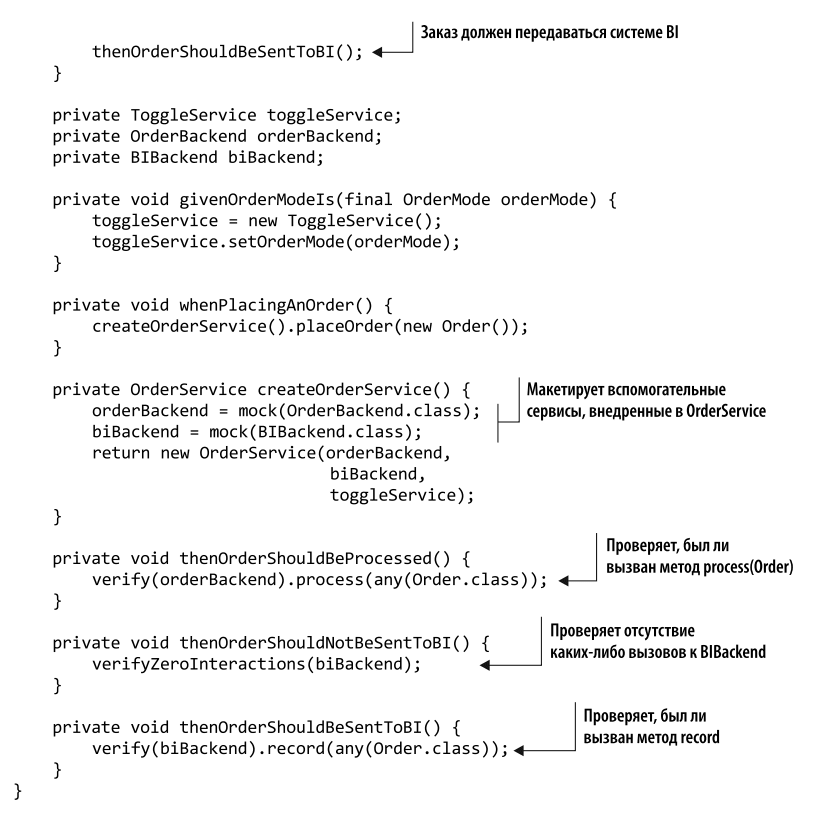
Listing 8.10 shows an example of a slightly more realistic OrderService class that allows you to place orders. This class has been extended with the new ability to send data about a placed order to a business intelligence (BI) system. This feature is enabled and disabled using ToggleService, a hypothetical library for managing functionality toggles. Each time the placeOrder method is called, the OrderService object checks the current order mode (new or old) and behaves accordingly.


Listing 8.11 shows an example of writing tests for this switch. We do not test the behavior of the original functionality, which consists in placing an order and sending data to the BI system. Our tests verify that the correct aspects of the behavior are fired depending on the state of the switch. If the order has the OLD mode, it must be sent for processing, but nothing needs to be transferred to the BI system. If you use the NEW order mode, in addition to processing, data about it must be sent to the BI system. Layouts are used to check the interaction between auxiliary services (BI system server code and order processing). If this is your first time using mock objects in tests, don’t worry. In this example, they simply allow you to check whether support calls are being made.

So you now know why you need to test switches and have seen some examples of how to do it. Before we finish looking at functionality switches, there is one more thing to discuss: dealing with a large number of switches and the fact that the switching process can be audited.
If you are using multiple switches, you should try to test all combinations of them, especially if some of them affect the others. But even if there is no direct connection between them, all combinations should be tested, as they can be connected indirectly. Indirect attachment can occur at any stage of development. As you can imagine, the need to check a large number of switches can quickly turn into a real combinatorial nightmare. The more switches there are, the more likely you are to do something wrong, and the more important it is to test them. This is one reason why you should always use as few switches as possible.
There is an opinion: when analyzing risks (estimating how much the risks are reduced when testing all combinations compared to testing only a few) it is not necessary to test all combinations. This approach may seem logical, but it is based on the assumption that you are capable of evaluating security flaws that you are not aware of. If you know about them, they’ve probably already been fixed. We recommend that you check all switch combinations. And so that testing is not too complicated, the number of switches in the code base should be reduced.
Switches are subject to audit
When using runtime switches, remember how important it is to ensure safe access to their mechanisms. Switches of this type affect the behavior of applications in industrial environments, so access to the mechanisms you use to change their state must be exclusively authorized. It is also worth considering whether it is necessary to record changes in the state of the switch for later revision. You should always be able to find out who used which switch in a production environment and when.
Functionality switches are becoming increasingly popular, and we expect them to be seen as a natural aspect of the software development process in the future. This will make circuit breaker inspection automation play an even more important role and need to be integrated into your delivery pipeline. We advocate the use of feature switches as they greatly improve the development process. We believe that their advantages clearly outweigh the disadvantages – you just need to be aware of potential problems and ways to solve them. In the next section, we will talk about how to start writing automated tests aimed at testing security mechanisms and vulnerabilities.
Most developers would agree that security testing is very important and should be done regularly. But in reality, most software projects never conduct security audits or penetration testing. Sometimes this is explained by the fact that the software is almost not exposed to risk, and sometimes the developers simply do not pay enough attention to security. Another common reason for not having such tests, in our experience, is that penetration testing is often considered too laborious and expensive.
Security testing is usually time-consuming because many checks are not easily automated. The main difficulty is that the experience and knowledge of a security specialist is needed to identify potential defects and weaknesses in the application.
The work done in penetration testing (and the benefits it brings) is in some ways no different than conventional exploratory testing. Humans can perform tasks and offer logical reasoning at a level still inaccessible to computers. Trying to replace live testers with automated tests is unrealistic, and we’re not saying you should strive for it. In this chapter, you’ll learn how to write tests that allow you to perform limited penetration testing as part of your delivery pipeline.
Security tests are just tests
It should be understood that security tests are no different from any others (Fig. 8.3). The only difference is that the developers for some reason prefer to use the word “security” in their name. If you know how to write regular automated tests to verify behavior and detect software bugs, you can apply the same principles to security testing.
Are you handling failed login attempts correctly? Write a test for this.
Does your online forum have adequate protection against XSS? Write a test that tries to inject malicious data.
Once you understand that there is nothing magical about security testing, you can start testing different aspects of security and finding vulnerabilities with automated tests.

Let’s talk in more detail about what checks a security tester performs. Some of them are more or less mandatory in the sense that they are always carried out, regardless of the purpose of the test. Many of these checks can be classified as basic “hygiene” and your application should always pass them. As it turned out, many of them are not so difficult to implement in the form of automated tests. It is usually easy to test automation, which manual implementation brings little benefit. Turning them into automated tests not only allows you to run them as you see fit, but also allows you to focus on more complex testing. Providing malicious data to search for flaws in input processing, such as SQL injections or buffer overflow attacks, is a good example of an everyday task that can be automated.
To make it easier for you to understand what functions need to be tested and how to structure the test automation process, let’s divide security tests into two main categories: applications and infrastructure (Table 8.4). In addition to these two security-specific categories, there are also subject-related tests. We already covered them in the first part of the chapter, and as you already know, they also help make the system more secure.
Next, we will talk about the mentioned categories of tests.

For application and infrastructure testing, there are a number of tools to consider. For example, you can apply a port scanner to the server where the application is deployed. Similarly, a web testing tool can scan a web application or execute prepared use cases, helping to identify vulnerabilities. You can also use tools to scan your code for vulnerable third-party dependencies. Any unexpected results should cause the test to fail and the delivery pipeline to stop.
These tests take quite a long time, so you can make them less frequent than other tests in your pipeline. If you have other long-running checks, such as nightly performance tests, it’s a good idea to run the scan tools before or after they finish.
With the popularization of cloud computing, the concept of infrastructure as code (IaC) is becoming more common. The main idea of IAC is the ability to declaratively describe the infrastructure. This can be anything from servers and network topologies to firewalls, routing, and so on. This has several advantages, one of which is deterministic configuration, which allows the entire infrastructure to be replicated as many times as needed. It also makes it much easier to use a version control system to keep track of all changes to your infrastructure, no matter how small or large.
All this sounds strange from a security point of view. You not only minimize the risk of human error, but also get the opportunity to automatically check the correct operation of your infrastructure. Because all changes are stored in version control, you can track any of them, and the automated nature of IaC means that changes can be tested before being sent to a production environment.
Imagine you are updating your firewall. Before applying changes to a live environment, deploy them to a post-test environment. Ideally, this should be done in parallel to replicate the entire infrastructure. After you’ve created a postmortem environment, you can run automated security tests on it to ensure that functionality hasn’t been accidentally changed and that the changes you’ve made have the intended effect. After that, you can safely deploy the changes to the production environment. If you are already using IaC or intend to move in this direction, you should definitely familiarize yourself with the possibilities that this approach provides from the point of view of security of the architecture.
Application in practice
By writing security-focused tests and adding them to your pipeline, you can solve many of the underlying problems. And if you add to this the automatic execution of existing tools, then you get a simplified penetration test that can be run as often as needed, as needed. This area is still actively developing, and we will be following it with interest in the coming years in the hope that the existing tools will become more mature and accessible to both developers and testers.
At this point, you’ve learned the basics of automating targeted security testing. In the next section, we’ll talk about why accessibility plays an important role and how it relates to secure software development.
There is an opinion that the classic properties – confidentiality, integrity and availability – refer only to information security, but they are also important in the design of secure software. For example, confidentiality means protecting data from being read by unauthorized users, while integrity means ensuring that data is changed in an authorized manner. What about accessibility? Many developers easily grasp this concept, but have difficulty testing it, since it is based on the idea that data should be available when authorized users need it.
Imagine that you have a fire and you dial the phone number of the rescue service, but you cannot get through. The number is dialed correctly, but the control room is overloaded with false calls. It is bad! Another less serious example is when you try to buy a ticket online for a concert of a popular band, but the site crashes or becomes unavailable. Most often, the cause of such problems is not malicious activity, but the fact that everyone is trying to buy tickets at the same time: visitors to the site did not intend to do anything bad, but the result turned out to be no better than with a targeted attack.
Thus, any application should be involved in accessibility testing. But how to implement it in practice? To do this, you can simulate a denial of service (DoS attack), which allows you to see the behavior of the system before and after the data becomes unavailable. In this case, everything starts with the assessment of the operating margin.
Estimating operating margin is an attempt to understand how much load an application can handle before it loses its ability to serve customers satisfactorily. To do this, it is common practice to analyze memory consumption, CPU usage, response time, etc. This can also help to understand the behavior of the application before it crashes and reveal weak points in its architecture.
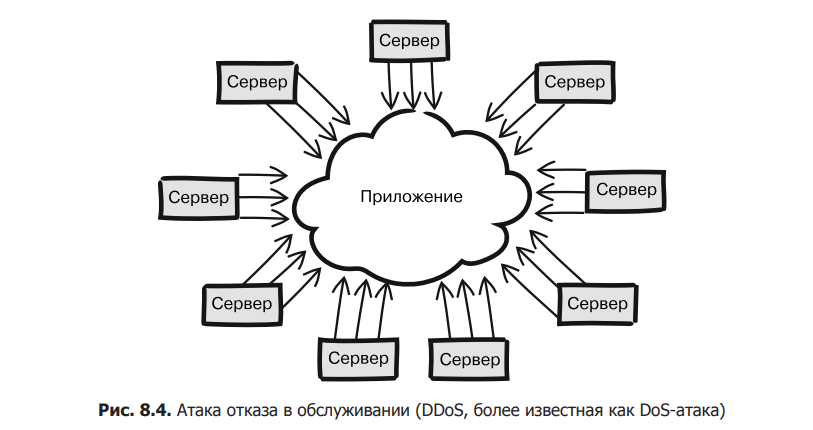
In fig. Figure 8.4 shows an example of a DDoS (DDoS) attack in which many different servers simultaneously send a huge number of requests to an application. Regardless of the number of requests and the load they generate, the main goal is to limit the availability of application services. When discussing DDoS attacks, the more general term DoS is often used. The main difference between these two concepts is that a DoS attack is performed not from several servers, but from one. But its task is the same, and from now on we will consider the terms DDoS and DoS interchangeable.
By simulating a DoS attack, you can easily get an idea of how well your application scales and how it behaves before it no longer meets availability requirements. It should be noted that no matter how well the system is arranged, sooner or later it will fail if the attack turns out to be massive enough. It follows that it is practically impossible to design a system that would be 100% resistant to DoS attacks. But if you’re trying to identify weaknesses in your architecture, evaluating its operating margin is a good strategy.
There are several commercial products and open source alternatives for load testing applications. One example is Bees with Machine Guns, a utility for creating EC2 server instances on Amazon Web Services that attack an application by sending it thousands of simultaneous requests. Listing 8.12 shows how to configure eight EC2 instances that will send 100,000 requests 500 at a time to a website.

Whichever product you choose, heavy system testing in your delivery pipeline is an effective way to identify weaknesses that can be exploited in an industrial environment.
But a successful DoS attack does not require thousands of simultaneous requests. Availability can also be undermined in more sophisticated ways, such as through domain rules that are not immediately apparent.
When you run domain rules, you are effectively running a DoS attack, in which those rules are executed according to business requirements, but with malicious intent. To illustrate this, consider the example of a hotel with generous cancellation policies.
In order to provide a high level of customer service, the hotel manager has decided to fully refund the reservation price if the reservation is canceled on the day of arrival before 16:00. This allows for a lot of flexibility, but what if someone makes a special reservation and doesn’t show up? Will this result in the room being unavailable, causing the hotel to lose potential customers? Undoubtedly, this is how a domain DoS attack works. The cancellation policy allows you to book all rooms and cancel the reservation at the very last moment without any payment. In this way, an attacker can block rooms of a certain type or send customers to a competing hotel.
Such attacks may seem fictional and unlikely, but something similar has already happened several times in reality. For example, the taxi aggregator company Lyft once accused its competitor Uber of trying to cause financial damage by ordering and canceling more than 5,000 rides in San Francisco. Another case occurred in India, where Uber sued its competitor Ola for ordering 400,000 mistaken rides.
Modeling this behavior in tests may seem silly, but using domain rules with malicious intent helps to better understand the weaknesses of the domain model. The knowledge gained in this way can be invaluable when designing alerts that are triggered in response to a restriction violation or some user action, or when using machine learning to detect malicious activity. But availability testing is only one of the things to consider when implementing security mechanisms in your delivery pipeline. Another is to understand how the application’s configuration affects its behavior, especially from a security perspective. And this brings us to the next topic – to check the correctness of the setting.
In today’s software development, general-purpose functionality is often implemented through configuration: taking an existing library or framework that allows you to enable, disable, and change functionality without having to write code yourself. In this section, we’ll talk about why you need to validate your configuration and how you can use automation to protect yourself from security flaws caused by incorrect configuration settings.
If you’re building a web application, you probably don’t want to spend time writing your own HTTPS implementation to serve web requests or developing a homegrown ORM framework to work with a database, both of which are easy to get wrong. Instead of developing common functions yourself, you can use existing libraries or frameworks. For most developers, this will be a smart decision, as plugging in common functionality with external tools allows you to focus on the unique aspects of your business.
But even if you decide to create your own implementation of shared functionality, you’ll likely want to develop it as a library so that other teams can use it in their applications. Regardless of which approach you choose, some critical functionality of your application will be provided by external code and managed through configuration. And while these are typical features, they can play a leading role in the security of your application. It follows that configuration errors can be the direct cause of security problems. You can effectively fight them with the help of automated tests.
Let’s look at each of these reasons and try to understand where they come from and why you need to use automated tests to prevent them.
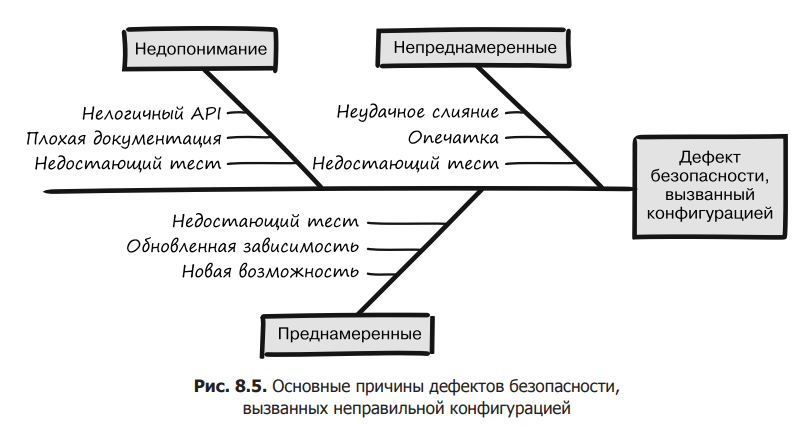
Unintentional changes
The ability to manage functionality with the help of configuration makes the life of developers much easier. This not only speeds up the development process, but also makes the app more secure. Using well-known open source real-time implementations that are controlled by the community will almost certainly be safer than writing your own libraries. Creating secure software is a difficult task even for the most experienced professionals.
When capabilities are controlled through configuration, application behavior can be easily changed. Even for significant changes, it may be enough to edit one line in the configuration. And while it’s easy to change behavior, it’s just as easy to accidentally make unwanted changes. Imagine that you mistakenly edited a line in your configuration or made a mistake in the name of a string parameter, as a result of which the behavior of the program has changed imperceptibly, although no exceptions or errors occur during its operation. If you’re unlucky, this will make the app more or less vulnerable. Or maybe even more unlucky, and then this vulnerability will be discovered only after getting into an industrial environment.
We need a security mechanism capable of detecting many problems caused by inadvertent configuration changes. Creating automated tests that test the capabilities and behaviors included in configurations is a relatively cost-effective and simple way to implement such a mechanism.
Deliberate changes
Unwanted side effects that make an app unsafe can occur more than just random changes. Sometimes a deliberate change can also cause similar problems.
Imagine you are implementing a new feature and as part of the process you need to make some configuration changes. You test how the app works (ideally by adding new automated tests as we just discussed) and continue working on the new feature. However, during the behavior change test, you didn’t notice that the rest of the program started behaving differently. Perhaps the configuration you edited was the result of a previous security audit or penetration test, or was intended to protect some vulnerabilities. In the process of modifying it, you disabled these security mechanisms, leaving the application vulnerable.
Involuntary changes in the behavior of one part of the system when editing another is not uncommon. This looks like making an unintentional change, but it’s worth noting that in this case, you as the developer are not doing anything wrong.
Unintentional changes are a mistake, so you may be under the illusion that you can avoid them by being more careful or making the process more rigorous. But in this case, you change the code deliberately and correctly. You can even provide automated tests for the changes you make. These tests can protect against unintended changes to newly implemented functionality, but if there are no tests for existing functionality, intentional changes will break the program’s behavior. This must be kept in mind when working with existing codebases for which, due to historical reasons, not many tests have been written.
Misunderstanding of the configuration
The third main cause of configuration errors is a lack of understanding of how this mechanism is used. Basically, it’s what happens when you think you’re adjusting one aspect of a behavior when you’re actually changing something else. This can easily happen if the configuration API of the library used was designed with some ambiguity.
Integers, magic strings, and negated assertions are typical signs of a poorly defined configuration API. When you encounter such an interface, make it a rule to add a test that verifies that the configuration does what you want it to do.
How to avoid vulnerabilities in other parts of the program? How do you ensure that the intent and unwritten rules behind critical configuration don’t disappear as the code evolves? As we mentioned, an effective solution is to write automated tests that validate the expected behavior and use them for regression testing in the delivery pipeline.
If you are not familiar with this kind of configuration testing, you can use the concept of hotspots. A hotspot is a piece of configuration that controls behavior that directly or indirectly affects the security state of the system. So that you have an idea of what such hot spots usually look like, in the table. 8.5 Examples of functionality that require automated tests are listed.
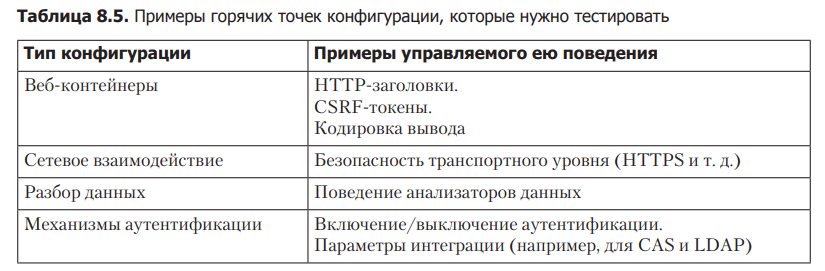
Our experience shows that it is often quite easy to create automated tests for functionality that is controlled by configuration and is of interest from a security perspective. For example, it’s easy to write a test in a web application that checks that HTTP headers are correct or that a form uses CSRF tokens. Such tests are best created during application development, but due to their simplicity of writing, they are fairly easy to add to an existing codebase.
There are arguments for and against automating configuration-driven functionality testing. One argument against this approach is that testing the configuration is like testing a setter method that sets a simple value and is thus of little use. This may be true for some types of configurations, but not the one we’re discussing here.
The configuration to be tested changes the behavior of the application. Just as you write tests that validate implemented behavior, it’s equally important to test the behavior you configure. Once you understand that it’s not the configuration itself that’s being tested, but the resulting behavior, you’ll understand why this is so important.
In addition to custom aspects of behavior, it is important to check for implicit aspects that appear when using a library or framework. Implicit behavior is behavior that occurs without adding any configuration. This is sometimes called the default behavior. Since there is no configuration, we may not even know that we have important functionality to test. To prevent this from happening, you should navigate through the settings that are used in your tool by default.
For example, most modern web frameworks and libraries make it easy to create HTTP-based APIs or REST-based web services. There are countless projects that developers can use to declaratively describe HTTP endpoints. These kinds of tools can increase your productivity, because they allow you to focus on business logic, ignoring the template and boilerplate code. Being able to write clean and concise code is usually due to the smart default behavior of your framework. By following the default configuration, you’ll write the least amount of code. This is great for tutorials and small prototypes, but for real projects that are very meaningful to your organization, you need to be clear about the default settings. In many cases, these settings increase the security of the application, but sometimes they can represent a trade-off between security and ease of use. If you’re not aware of these trade-offs, you can unwittingly make your code vulnerable.
Imagine you are developing an HTTP service. This could be some sort of REST API or some other HTTP based API. To reduce the number of attack vectors, a good security solution is to include only those HTTP methods that the API requires. If your endpoint needs to serve data to clients in response to HTTP GET requests, you should make sure that it does not return normal responses when accessed using any other HTTP methods. Instead, it may return a 405 Forbidden or 501 Not Implemented method status code to inform clients that the requested HTTP method is not supported. The more HTTP methods an endpoint responds to, the greater the likelihood of vulnerabilities. For example, TRACE is an HTTP method known to be used in cross-site tracing (XST) attacks, so it should only be enabled when necessary.
Listing 8.13 shows how to write a test that ensures that only certain HTTP methods are enabled for an endpoint. It’s worth noting that this is a simplified example, the actual implementation will depend on how the API under test is designed and what endpoint is included. You should also pay attention to whether custom HTTP methods are allowed and whether authentication is enabled.


Keep in mind that your focus should not be on disabling individual HTTP methods, but on enabling those that are necessary to implement your functionality. But even if the default settings are fine, tests should be performed to verify the appropriate behavior. In future versions of the framework, these parameters may change, and if you have the right tests, you should be able to detect it immediately.
In this chapter, you learned several ways to use the delivery pipeline to automatically check various aspects of security. Some of the approaches we discussed required a greater focus on security than other concepts presented in the book. If you were already familiar with these techniques, we hope you were able to look at them a little differently. In the next section, you’ll learn how to safely handle exceptions and apply various design concepts to avoid many of the problems associated with traditional error handling.
By separating tests into normal, boundary value, invalid, and extreme input tests, you can integrate security mechanisms into your unit test suites.
The regular expression engine can perform inefficient backtracking, so you should check the length of the input passed to it.
Functionality switches can cause security vulnerabilities. You can combat this by testing the switching mechanisms using automated tests.
A good and practical approach is to create a test for each switch you add. You should also test all possible combinations of them.
Beware of the combinatorial complexity that occurs when there are too many switches. To avoid this, it is best to keep the number of switches to a minimum.
The switching mechanism itself is the subject of audit and accounting.
Implementing automated security tests into your build pipeline can allow you to run limited penetration tests as often as you like.
Availability is an important security aspect to consider in any system.
Simulating DoS attacks helps to better understand weaknesses in the overall application architecture.
It is extremely difficult to defend against a DoS attack on domain rules, because only the intention distinguishes it from the normal use of the system.
Many security problems are caused by misconfiguration, which can include changes (intentional or unintentional) or misunderstanding of configuration parameters.
Configuration hotspots are good indicators of the areas that need to be tested first.
You should know how the tools you use behave by default and test that behavior with tests.
We used materials from the book “Security by design”, which was written by Dan Berg Johnson, Daniel Deoghan, Daniel Savano.





