
04.09.2023
48 min
1977

Failure to effectively manage variable state can lead to various problems. For example, this can lead to serious security issues for an airplane that departs with the luggage of a passenger who never boarded. As the complexity of entities increases, it becomes more difficult to control their state, especially when that state has many complex transitions. In such cases, design patterns are needed to help reduce this complexity. Additionally, managing the complex mutable states of entities can be difficult to implement in code. This especially becomes a problem when different parts of the code try to modify the same entity at the same time.

Techniques controlling this complexity must resolve these conflicts. In our further study, we will address these issues by distinguishing between single-threaded environments such as EJB containers and multi-threaded environments. In this section, we’ll take a detailed look at four design patterns that can help simplify complexity management. The first two of them concern single-threaded environments: partially immutable entities and state objects. Next, we’ll look at entity snapshots that work well in multi-threaded environments. Finally, we’ll look at the “Entity Relay” design pattern, which aims to reduce conceptual complexity in any environment, both single-threaded and multi-threaded.
During the first introduction to object-oriented programming, students learn to implement entities in the form of objects with mutable data fields. In Listing 7.1, for example, you can see how the balance field is updated and how to check if there are enough funds in the account to protect this transaction.

However, this code is not safe in a multi-threaded environment. Imagine we have a $100 account that has two withdrawals at the same time: $75 from an ATM and $50 from an automatic money transfer. The balance check performed during the second withdrawal procedure may occur before the first procedure has time to reduce it.
Take a look at this sequence of events.
The ATM withdrawal procedure checks the balance ($100 > $75) – everything is fine, let’s continue.
The automatic money transfer procedure checks the balance ($100 > $50) – everything is fine, let’s continue.
The ATM withdrawal procedure calculates the new balance: $100 – $75 = $25.
The ATM withdrawal procedure updates the balance – $25.
The automatic funds transfer procedure calculates the new balance: $25 – $50 = -$25.
The automatic money transfer procedure updates the balance: -$25.
Since these two threads are not executed sequentially one after the other, but simultaneously, the balance check was skipped. In the second agreement, the balance was checked before the first was completed, so it did not affect anything and did not protect against cost overruns.
This is an example of the so-called racial condition. The situation can get worse: if the events happen in the order of 1, 2, 3, 5, 4, 6, the ending balance will be incorrect – $50. Even though $125 was withdrawn from the account with an initial balance of $100, there are still funds left in the account (can be checked).
To solve this problem, we must either create a protective environment that ensures that only one thread accesses an entity at any given time, or design entities in such a way that they can handle multiple concurrent threads properly. A single-threaded security environment can be created in many different ways. One of the simplest is to execute each client request and then load the entity object in a separate thread. This way you ensure that only one thread is working on each entity instance. If two streams work with the entity (data) at once, then two instances of it change simultaneously, each in its own stream. At the same time, the resolution of conflicts falls on the transactional database system.
Another approach is to use a framework like Enterprise JavaBeans, EJB, which takes care of the entity load/save cycle. In this case, it is the framework that ensures that only one thread can access an entity at any given time, and at the same time minimizes traffic to the database. Installation sharing is configuration dependent. Probably the most modern way to create a single-threaded environment is to use an actor system such as Akka. In Akka, a business entity can reside inside an actor, which ensures that transaction threads access it one at a time.
Multithreaded environments are typically used when entity instances are stored in a shared cache, such as Memcached, to avoid database interactions. When a thread wants to access an entity, it first looks for it in the cache. In this case, the entities must be designed to work correctly even with several simultaneous threads. The traditional (ancient and bug-tolerant) way to achieve this is to add semaphores to the code that synchronize the threads with each other. In Java, the low-level implementation of this approach is represented by the synchronized keyword.
There are many other options and frameworks available to you, but in any case it will not be easy to guarantee the correct behavior. To begin with, let’s simplify mutable states in a single-threaded environment by using partially immutable entities.
If the data is mutable, there is always a risk that some piece of code will change it. And sometimes these changes can be unwanted: for example, a bug crept into the code or someone discovered a vulnerability and launched an attack. If individual components being modified are not safe, it makes sense to reduce the number of such components. Our experience shows that even in situations where change is initiated by the actors themselves, it is useful to look at individual parts of them and ask yourself: “Does this particular part need to change?”
Let’s return to the Order class and this time pay attention to the attribute with the client ID, custid. It is not necessary to change customer IDs: it would be strange if a basket of books collected by one customer suddenly became the property of another. The very fact that such a feature exists creates potential security issues. Imagine that the order has already been paid for, but not yet shipped. If at this point the attacker manages to change the customer ID associated with this order, he will effectively steal the purchased product. This cannot be allowed.
To effectively prevent these problems at design time, entities can be partially immutable. To do this, ensure that the customer ID is assigned only once and cannot be changed after that. Listing 7.2 shows an example where private end modifiers are used in the custid attribute of the Order class. This forces us to initialize the custid field in the constructor and does not allow us to change it after that. Each time the getCustid method is called, it returns the same reference that points to the CustomerID object. In this list, CustomerID is a domain primitive and must be constant.
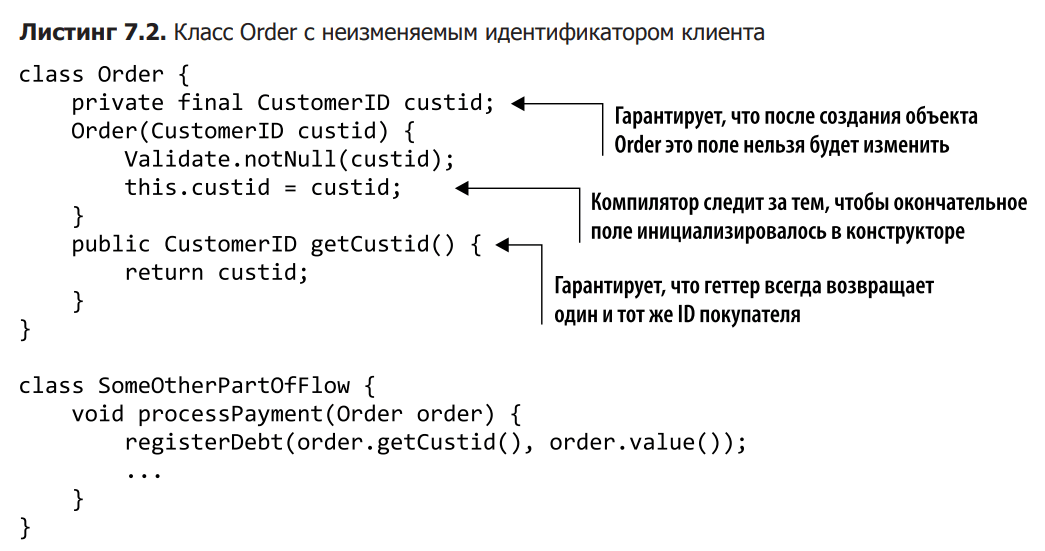
If you look closely at this code, it becomes clear that the getCustid method does not contain anything interesting and can be replaced by direct access to the field. Listing 7.3 shows how to do this safely. The reference in the data field cannot be changed, and the CustomerID object it points to is also immutable. If the processPayment method directly accesses the order.custic field, it cannot do anything dangerous with it.

An interesting feature of this code is that we used the help of the compiler to ensure the integrity of the custid data field. Any attempts to change this attribute will be aborted at compile time and will not terminate at runtime.
ADVICE. If you have attributes that should not change, make the entities partially immutable to avoid breaking integrity.
You already know that data fields can be protected by encapsulation, as shown in Section 6.3, or made partially immutable. Now let’s turn to a less obvious aspect of entities: their allowed behavior can vary depending on what state they are in.
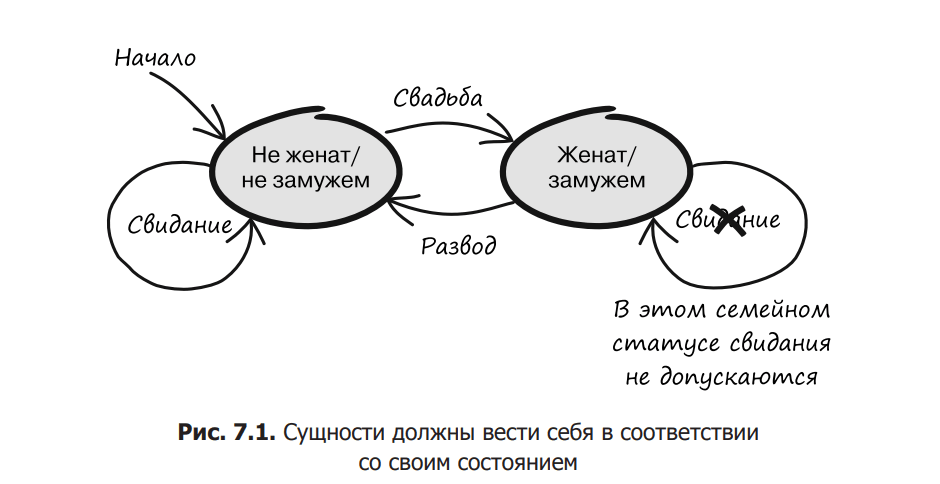
Working with subjects is complicated by the fact that some actions are not allowed in certain states. In fig. 7.1 Marital status options are shown: single and married. Most of us would agree that dating while not married is acceptable behavior. However, after the wedding, dating should be stopped, unless it is a man. Of course, a married person can always divorce and become single again, in which case he will again have the opportunity to go on dates and remarry / remarry. But marriage is impossible if a person is already married. In the same way, a single person cannot divorce.
Of course, this is a rough model. It doesn’t take into account polygamy or cases where even single/single people can’t date, like if they’re engaged or in a committed relationship. However, this is a clear example of the fact that it is not always possible to perform certain actions with entities.
Back to the software, it must be designed to adhere to these rules for organizations, otherwise there could be security issues: for example, a bookstore might ship an item that hasn’t been paid for. And this is not such a rare situation. Incompleteness, incorrectness or complete absence of the state management mechanism of the business entity can be found in almost any code base of significant size.
The reason for the security problems is that there are often no state change rules, or they are implicit and vague. In many cases, it appears that no deliberate design effort was made, and the rules emerged in the codebase gradually and most likely haphazardly.
In code, this is often expressed either as rules embedded in utility methods or as conditional expressions in entity methods. Listing 7.4 shows the first option. There is a rule: if the boss is married, the conversations he has outside of working hours should not turn into acquaintances. This rule is followed by the afterwork method in the Work class, not by the Person class.

If you look at the code again, you will notice something strange. Inadmissibility of dating in marriage is a general rule. However, in this codebase, we implemented it as if it applied specifically to the post-production scenario. It would be better to describe, as a rule, when you can go on a date. In our case, it would be more logical to place it inside the dates method of the Person class.
In real projects, we regularly encounter entities that look like ordinary structures (classes with closed data fields, setters and getters). In such cases, it is necessary to observe the rules of conduct of the business entity at the level of service methods. But as the code evolves, enforcement of these rules becomes inconsistent. Some of them are not followed by all system components. In addition, it is difficult to understand which rules apply in a particular situation. To do this, you need to analyze all code fragments that use the entity and find conditional expressions that prevent violations of the rules. In short, this approach has no practical mechanisms for tracking which rules apply to an entity.
The difficulties of auditing go hand in hand with the difficulties of testing. Imagine you want to write a unit test that ensures that a married manager cannot go on a date. To do this, you need to test the conditional expression in the post-processing method, that is, create mockups of any of its dependencies, such as a database connection. And also provide test data. This includes boss and employee objects (the latter is a subordinate with whom the boss can meet). Finally, you need to make sure that the post-job method is actually reporting inconsistent relationships, so you need to mock up the logging structure and look for the bad egg string in the log entries. And if there’s a coffeeBreak method elsewhere in the codebase, you’ll have to do the same for it so that the manager doesn’t go on a date with anyone during the short break. This isn’t the easiest way to test the “married boss shouldn’t date” rule.
It would be better if the methods of the business entity itself dealt with compliance with state rules. But even this approach can lead to dangerous inconsistencies. Listing 7.5 shows another version of the dating code. Here, before allowing the manager to go on a date, the Person class checks his marital status (note the if statement in the date method).

This approach is definitely a step in the right direction. At least the business rules are now inside the Person class. An invitation to a date can happen both outside of work and during a short break, but the same code always performs the check. This reduces the risk of inconsistencies that could lead to security holes.
Unfortunately, public administration is still implicit, or, to put it mildly, confusing. We often see if assertions scattered throughout the code deep inside entity methods. When analyzing the history of code changes, it is usually found that they were added one after the other to handle some special cases. Sometimes the combination of all these rules turns out to be a logically contradictory model.
Obviously, implementing state as conditional expressions placed in utility or entity methods is not the best architectural solution. But is this problematic from a security point of view? So. The fact that an entity allows the use of a method that should not be available in this state can serve as a starting point for mounting an attack that exploits this flaw. For example, if new items are mistakenly allowed to be added to an order that has already been paid for, an attacker could take advantage of this to get free items.
Let’s return to the online bookstore. Before submitting the order, you need to make sure that you have paid for it. Listing 7.6 shows what this logic would look like if it were placed in the processOrderShipment method outside of the Order class.

There is one small if statement in processOrderShipment that prevents unpaid items from being shipped, and it belongs to some other class. It’s easy to imagine that as more and more code is added, this check will be missed or broken. If you don’t make sure you pay for your order before it’s shipped, your customers will have a loophole that will allow them to avoid paying for the items they ordered. And if they find out, you could suffer a serious financial loss as you watch a sudden flood of unpaid goods being shipped out of the warehouse. If you skip processing entity status, you can actually create a security hole.
Online gambling and easy money
Gaming sites often organize promotions, offering visitors bonus points or free games. Many try to turn them into real money that could be withdrawn. To do this, they take their points, play a little with variable success, then add a few more points in the hope that sooner or later the system will not be able to distinguish between real money and bonuses. Thus, many gambling sites suffered real financial losses.
The best way to combat such attacks is with sites where these situations have been specifically modeled as a set of entities that logically and seamlessly cover the relevant rules. Can I use bonus points in the game? Can they be removed, and if so, in what quantity? Bonus points are not just a sum of money, but a complex entity with many states.
We recommend that you design and implement entity state as a separate class. This allows you to use the state object as a helper object of the delegated entity. Any access to the entity is first checked against this object.
Let’s return to the example of marital status. Listing 7.7 shows what the MaritalStatus helper object looks like. It contains rules related to marital status, but nothing more. For example, in the dates method, a call to the Validate frame helps to enforce the rule about not being able to date a married man.
These auxiliary objects have concise code. An example of a family state is practically the simplest possible state diagram. It gets a bit more complicated if you provide support for live/dead states by adding a private boolean variable alive, which is initially true. When a person dies, he is set on falsehood, and after that the meaning of the marital field loses all meaning.

Having live/dead logic at its core will likely lead to multiple assertions that will make the code less readable and testable and weaken security over time. Alternatively, the same logic could be added to the MaritalStatus helper class, in which case the code would still be easy to maintain. A direct consequence of the brevity of the auxiliary object is the ease of testing. Code Listing 7.8 shows several possible tests that check whether the MaritalStatus object matches the rules.

Notice how easy this code is to read. The test should_allow_dating_after_divorces clearly says that in case of marriage and subsequent divorce, you can go on dates again. This is facilitated by the fact that the classes are named according to concepts that exist in the subject area, such as “marital status” – MaritalStatus.
Now let’s see how this representation of the state can be woven into the essence. In Listing 7.9, we allow the Person entity to check the MaritalStatus helper object at the start of each public method to determine if the call is valid.

Offloading state management to a separate object makes entity code much more robust and resilient to minor breaches of business integrity, such as when a customer avoids paying for orders before shipping them. Separate state objects are recommended when you have at least two states with different rules and transitions between them are not trivial. We probably wouldn’t use this approach to represent the state of a light bulb (on/off, transition is always possible and changes state). But for any more complex cases, we recommend using a separate state object.
As mentioned, representing an entity as a mutable object works well in single-threaded environments. But if there are a lot of threads, you’ll have to actively use the synchronized keyword in your code so that they don’t mess up your state. Unfortunately, this causes other problems, such as bandwidth limitations and potential deadlocks. Next, let’s look at another design approach that works well in multi-threaded environments.
Let’s move on to multi-threaded environments, in which an instance of an entity can be accessed by several threads at the same time. In a high-performance solution where response time plays a key role, database queries should be avoided. This typically applies to stock trading, streaming, multiplayer gaming applications, and highly responsive websites. In such situations, the time required to retrieve information from the database will make it impossible to return quick answers. Instead, entities should be stored in memory as often as possible, using, for example, a shared cache such as Memcached. All threads that need to work with the entity take data from the cache, which separates the representation of the entity across threads. This minimizes response time and increases capacity, but requires additional effort when designing entities: they must behave properly in a multithreaded environment.
To solve this problem, you can add many synchronized keywords to your code, but this will cause many threads to have to wait for each other and will reduce the system throughput dramatically. Worse, it can lead to a deadlock where two threads wait for each other indefinitely. But we can solve this problem with another design scheme, by representing entities as snapshots.
An entity does not necessarily have to be represented in code as a mutable class. Instead, you can create snapshots of it that allow you to view and act on it. It is easiest to describe it with a metaphor.
Imagine that you have an old friend whom you haven’t seen in a long time. You live in different cities, but keep in touch with the photo sharing site. You regularly look at photos taken by a friend and follow the changes in his life. He can change his hair or move to a new house, and he naturally grows up or ages like any other person. Despite the changes in all these attributes, your friend’s personality remains the same. You observe various events in his life and keep in touch, but you never meet in person (Fig. 7.2).
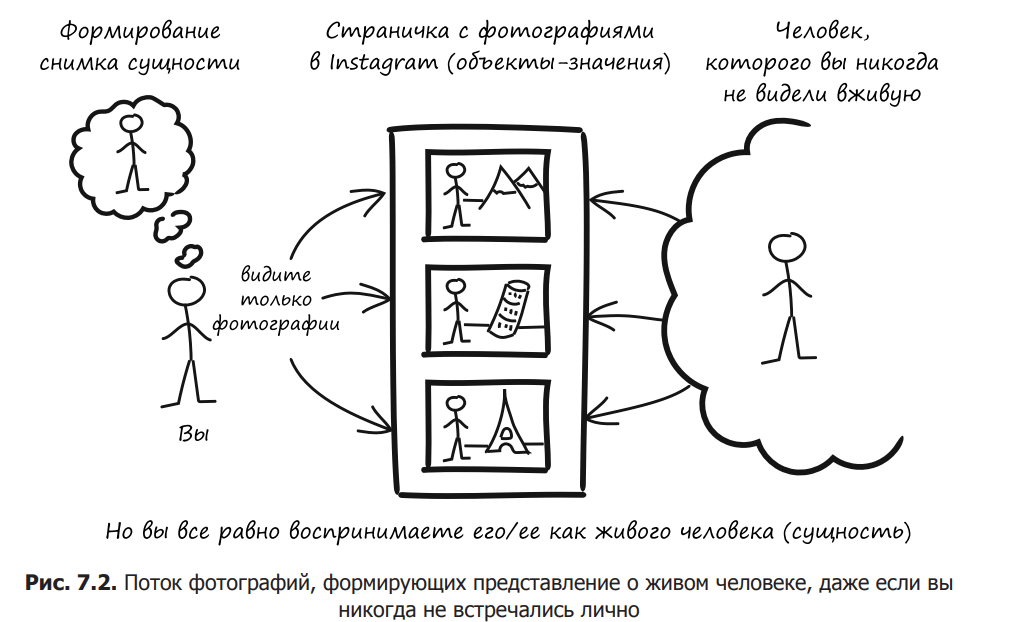
What about photos? Can you call them your friend? Of course not. These are just pictures of your friend. Each photo depicts him at a certain moment in time. A photo can be copied and thrown away, and you don’t care if it’s a copy or an original. Your friend is still living his life in a distant city.
Entity Snapshots work in a similar way. In an online store, orders are created when customers buy something. Each order has a significant lifetime and changes as the customer adds items to it, chooses a payment method, etc. Theoretically, the state can be stored in the database. But when the code wants to get it, you take a snapshot of it and format it as the OrderSnapshot class is an immutable representation of the corresponding entity. This is shown in Listing 7.10. This code provides a snapshot of what the order looks like when you request it.
Even if the essence of order still exists at the conceptual level, it is not expressed as a mutable class in code. Instead, the OrderSnapshot class provides the necessary information about the entity so that you can visualize it in an online store GUI, for example. The idea behind the snapshot concept is that the domain service goes to the database, taking a camera with it, and comes back with a photo that captures the order at a certain point in time. OrderSnapshot is not just a trivial reporting object: like a classic entity, it contains interesting domain logic. For example, it is able to calculate the total number of goods in the order and make sure that it corresponds to the assortment allowed for shipment.

But what about the essence itself? Can it exist without a variable class? Maybe, but on a conceptual level – just like your friend from another city who you’ve never met in person. You don’t interact with the entity directly, but only get snapshots of its state. The only place where an order is represented as a state variable is in the database: it is a row in the Orders table and corresponding rows in the OrderLines table.
We have shown how a mutable entity can be represented by immutable snapshots. But if it is a real entity, it should be able to change its state. How can this be achieved if its representation is unchanged?
We need some mechanism to modify the entity (that is, its internal data). To do this, you can provide a domain service to which you will send updates. Listing 7.11 shows that the OrderService domain service has a new addOrderItem method that is responsible for updating the entity.

The addOrderItem method checks the conditions to ensure that the change is valid and updates the internal data using SQL commands sent directly to the database or data storage structure in use. This approach provides high availability because you avoid read-only locks, which supposedly occur much more often than writes (ie data changes). Write operations that may require locking are separated from reads, which avoids security issues associated with data unavailability.
The downside of this approach is that it goes against some of the principles of object orientation, especially the recommendation to place data and associated behavior as close as possible to each other, preferably in the same class. Here, we split the entity into parts by placing read operations in a value object of one class and write operations in a domain service of another class. Architecture often requires compromises. In such cases, high availability may be so important that it is worth sacrificing, for example, certain principles of object-oriented programming.
This idea is not as strange as you might think. A similar approach is used in other situations, sometimes in a slightly different form. The Command Request Responsibility Segregation (CQRS) design pattern and the single writer principle, proposed by Greg Young and Martin Thompson, respectively, share similar characteristics.
Entity snapshots support not only availability, but also integrity. Since the snapshot is unchanged, the state of the view cannot be incorrect in principle. A normal entity with methods that change its state is prone to this kind of error, but snapshots are not. Of course, there is code to change the internal data, which can also be flawed, but at least the snapshot used to represent the state of the entity cannot be changed.
The concept of an entity that doesn’t have its own class certainly goes against standard object-oriented programming practices and may seem counterintuitive. For those who think in terms of OOP categories, having the definition of entity data in one place and the mechanisms for updating the same data in another must be inconvenient. However, there are situations with tight capacity and availability requirements (be it high-traffic websites or a hospital where staff must have instant access to patient medical records) where we think entity snapshots should be considered.
When it comes to security, another interesting benefit of using snapshots comes in situations where different privileges are required to read and modify data. If you only need to display the state of the data (for example, when the user is browsing the cart), a method that gets it will suffice. Similarly, you will need a suitable method for changing data (for example, when adding a product to the cart). In classic OOP, an entity has methods to support both reading and writing. However, when displaying data, the client code also has access to methods for writing it. There is a need for some other security mechanism that monitors changes made to the entity and suppresses them in read-only situations.
When you use entity snapshots, client code that needs to read something only has access to the immutable snapshot and cannot call change methods. Only clients who are allowed to make changes will be able to access the domain service intended to update the entity. Therefore, this design pattern also ensures data integrity in some common scenarios. Therefore, in an environment where different threads access the same entity (perhaps even simultaneously), snapshots are an effective way to ensure high availability and integrity.
So far, we have explored two architectures, one of which works well in single-threaded environments and the other in multi-threaded environments. However, the level of complexity can increase for another reason: when an entity has many different states. It can be inconvenient to work with more than ten states, but an alternative approach can often be taken – to represent complex states as a chain of entities.
Many formations have a small number of individual states that are fairly easy to understand. For example, the family state in one of the previous examples has only a few states and transitions between them (Fig. 7.3).
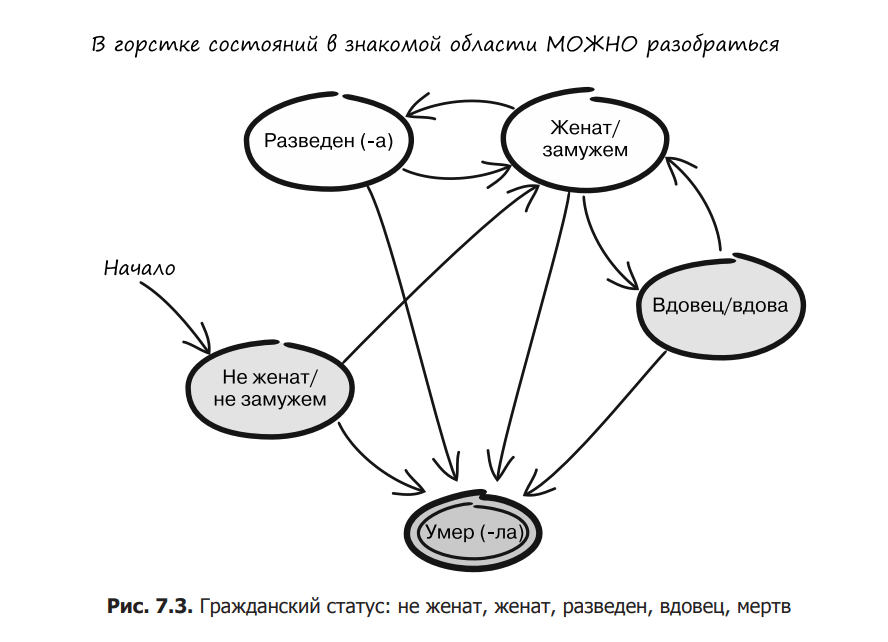
A state diagram of this size is easy to understand. This would also be easy to implement using the separate state object discussed in Section 7.2.
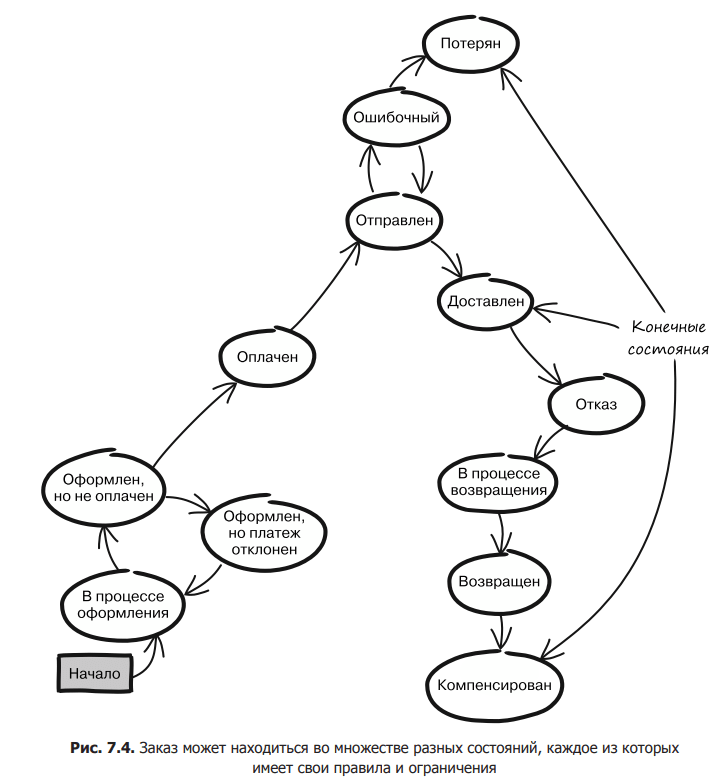
Sometimes the entity state diagram becomes so large that it is not so easy to understand. It may have been designed that way from the beginning, but more often than not it’s the result of a long history of change. When the changes were first made, they were most likely considered minor fixes, but over time they accumulated and led to many conditions. It is quite possible to imagine that initially orders in the online book store had two states: “received” and “sent”. But after some time, their diagram could take this form (Fig. 7.4).
Sometimes it is difficult to understand all the possible states and transitions of such an entity, even if you have their scheme in front of your eyes. Implementing these states in code with the confidence that each of them obeys different rules would be a nightmare. If such an entity is a separate class, its code becomes so complex that inconsistencies can creep in that are difficult to detect. If your order status chart is similar to the one shown in fig. 7.4, you must do something. It is necessary to break it into parts. Five states can be controlled. Ten states are still tolerant. But juggling 15 states is just too risky. And it is in such cases that we recommend using the entity chain.
The basic idea of entity relaying is to break the lifecycle of an entity into phases, each of which should represent a different entity. When the phase is over, the entity disappears and another entity takes its place, as in a relay. Consider, for example, Figure 7.5, where a person’s life is illustrated in two ways: first, as a single entity that passes through many states, and then as a chain of entities.
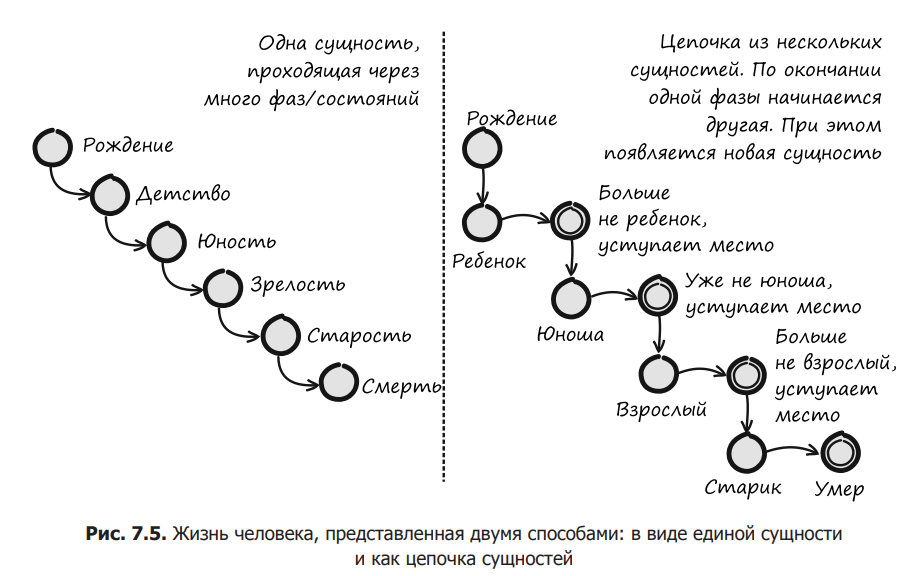
In the left part of fig. 7.5 We see the life of a person presented as a single entity: a person is born and remains a child for several years; then the period of adolescence begins, after which a person becomes an adult with all the resulting consequences; Then comes aging and death. A person can be considered one and the same entity that passes through the following states: birth, childhood, youth, maturity, old age and death.
The right part of the image shows the same life, but in the form of a chain of entities. A child is born and grows. One day he disappears, and his place is taken by a young man who accepts the baton. After a few years, instead of the young man, an adult appears, who sooner or later gives way to the old man, and he eventually dies. This situation can be considered an alternation of different characters.
We have shown two different views of the same thing. Both of these ideas are equally valid, they pay attention to different aspects and are suitable for different situations. Sometimes it’s useful to switch focus from one approach to another, such as when you have an entity with multiple states. As our experience shows, such a transition can serve as an effective way of working with subjects whose states have gone out of control. The expanded state diagram is divided into phases, each of which is modeled as a separate entity, then the resulting entities form a relay chain. Each entity in the chain manages several states, which allows you to reduce the level of complexity and avoid unnecessary risks.
The effectiveness of the entity relay is explained by the possibility of dividing the overall life cycle of the entity into phases that are modeled sequentially. For this to work correctly, you must not allow a return to a phase that has already been passed. This idea can be applied even if the return occurs, but at the same time the simplicity and bo’ are lost. Most of the advantages that this abstraction gives. Next, we’ll return to the dreaded bookstore order status diagram and show you how to turn it into a more comprehensible entity chain.
Let’s once again consider the excessively complex entity shown in Fig. 7.4, and we will try to model it in the form of a relay of entities. Look for places where one group of states turns into another. Ideally, you should not be able to return to the first group after you leave it. In fig. Figure 7.6 shows one of the options for state separation.
As you can see, a complex scheme of online ordering can consist of two stages: before and after payment. Let’s call the first phase pre-order and the second phase final. These stages should be developed as separate entities. Two runners participate in our relay race: the first starts the race (preliminary order), and the second, taking the baton from the first, finishes (final order). The final order is the result of payment in advance.
If we look again at the state diagram shown in fig. 7.6, you can see another place that meets these requirements – when the recipient refuses the delivered parcel. The difference is that not all delivered orders are rejected, only some. However, this is a good place to break down the state diagram. Remember that the rejected order does not appear automatically, but only after the recipient refuses it.
As a result of transformations, we get a simpler configuration. As shown in fig. 7.7, we no longer have a single whole with a huge number of states. Instead, we are dealing with three rather simple entities.
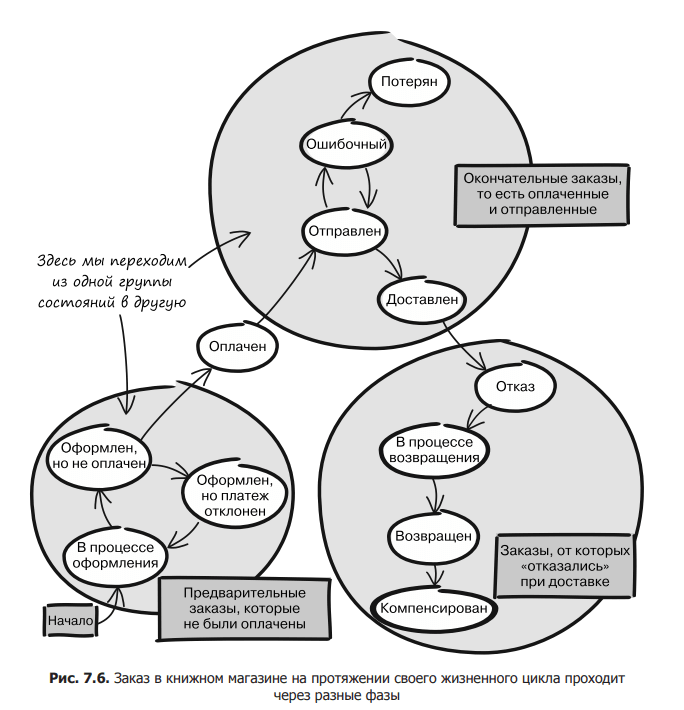
Each of the three entities (preorder, final order, and rejected order) has four or five possible states, so it will be quite simple to implement them separately. Using the previous state object model, you can safely implement all three entities.
Let’s briefly dwell on transitions – passing the baton between entities in the chain. When a pre-order is placed and paid for, it moves to its final “paid” status. At this point, in its initial “paid” state, a final order arises. The baton passes from the pre-order, which has reached its goal, to the final order, which is just starting its race. A similar situation occurs when the essence of a “young person” passes into the state of “no longer a young person”, as a result of which the essence of an “adult” arises. And just as adults cannot return to adolescence, the final order cannot be returned to the original “paid” state.
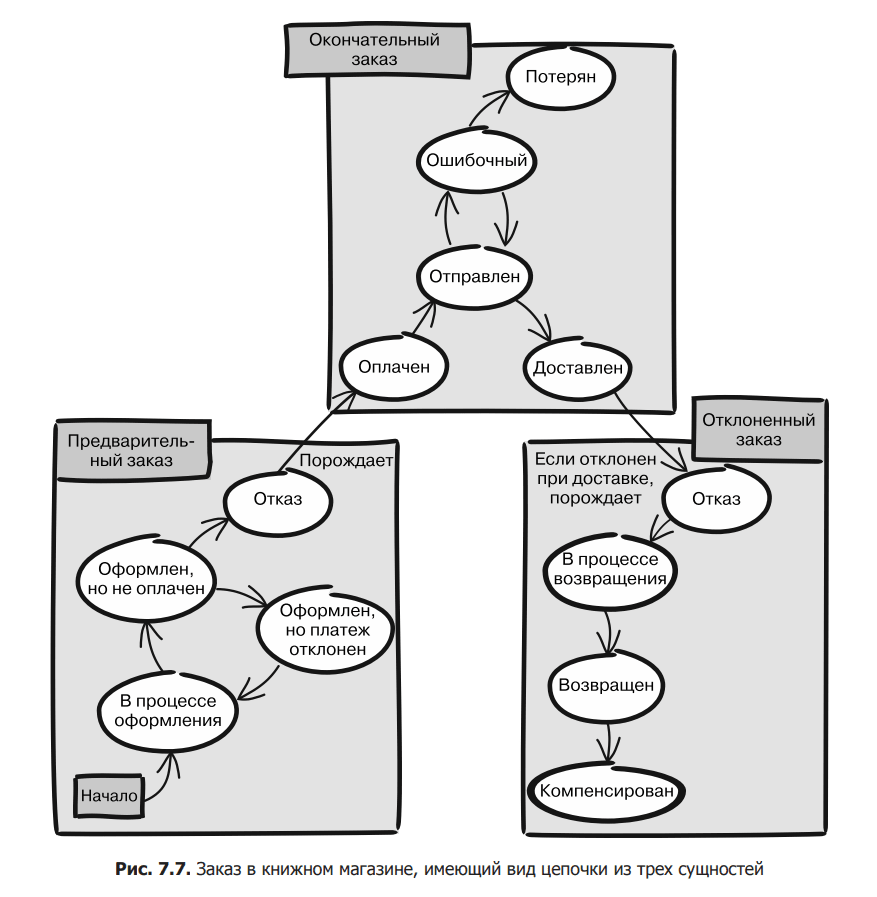
The transition from the final order (paid and sent to the buyer) to rejected is exactly the same, but with one small difference. When a final order reaches its final status of “delivered”, it does not always lead to the next object. A rejected order is possible only if the final order was refused at delivery (for example, no one wanted to sign for it or could not find the specified address). But in most cases, the delivery of the final order does not lead to its rejection.
Such an architectural solution greatly simplifies the writing of code, making it more error-resistant. If the state diagram is large and complex, as shown in fig. 7.4, it is very difficult to make sure that there are no unusual, hidden ways of execution that lead to a violation of business rules. But, having three simpler entities with four or five states for each, as in fig. 7.7, you can easily verify that the code behaves as it should. You dramatically reduce the risk of vulnerabilities. Now let’s return to the theoretical plane and think about when this approach should be used and when not.
For this approach to be useful, three conditions must be met:
In fact, it is too complex;
Impossibility of returning to one of the previous phases;
Arosti transitions from one phase to another with a small number of directed (preferably with one).
If the number of states in your entity is within reasonable limits, there is no point in increasing the complexity level by creating new entities with different names. If you have less than ten states, we do not recommend chaining from an entity. Similarly, it is not recommended to split an entity in two if you can go back from a later phase to an earlier one. The benefit of chain of custody is that once you’re done with an organization, you never go back to it. In the context of our orders example, this happens when the pre-order (still in the checkout stage) is paid for. The result is a final order that cannot be made preliminary again.
The possibility of returning to one of the previous entities is the same as if one runner passed the baton to someone who had already run to him. You lose the simple order of passing the baton from one runner to another until the end of the race. Instead, you get a sort of directed graph where you can reconstruct entities from other phases. All the simplicity of the relay disappears.
If the transition from one entity to another can take different paths, one should consider whether the benefits of such an approach outweigh the costs of its implementation. If an entity can only arise at a certain point in time, it gives us a certain simplicity. If there are several such items, consider changing the model. Is it possible to provide a final state for the phase? If not, then perhaps the two phases should be combined into one.
Finally, you can get a huge state diagram, the transitions in which resemble an intricate ball of yarn. Don’t even try to simplify it with an entity relay, all the design effort will be wasted. The confusion will not go away, even if you pull out a few threads. Instead, we recommend redesigning the model. Meet with relevant experts and discuss the following issues:
What is the real reason that the model turned out to be difficult?
Is all this complexity really justified?
Are real business requirements at the core of every complex architectural solution?
Do these business needs justify the expense of such complexity and possibly insufficient security of the system?
This section discusses several ways to simplify the architecture. In the table Figure 7.1 summarizes the main focus of each approach and the security issues it addresses.

The first architectural decision we considered was to minimize the number of constituent elements. For this, the essence is made as partially unchanged as possible. The next approach, the state object, aims to encapsulate transitions between the states of a single entity and works well in single-threaded environments. If there are many threads, it makes sense to represent the entity as snapshots to prevent conflicts. Finally, if the entity is complex and includes many states, as an alternative approach, it can be modeled as an entity relay, which reduces the number of states that have to be considered simultaneously.
Entities can be designed to be partially immutable.
Code for working with states is easier to test and develop if you take it out into a separate object.
High-capacity, multi-threaded environments require careful design.
Locking mechanisms in the database can limit the availability of entities.
Property snapshots allow you to restore high availability in multi-threaded environments.
Entity relay (when satisfying the conditions of one entity generates others) is an alternative approach to modeling an entity with many states.
We used materials from the book “Security by design”, which was written by Dan Berg Johnson, Daniel Deoghan, Daniel Savano.





